导语:在OceanBase 2024年开发者大会的技术生态论坛上,阿里云DataWorks团队的高级技术专家罗海伟,详细阐述了一站式大数据开发治理平台DataWorks的能力,并对于如何基于OceanBase和Dataworks构建一站式数据集成、开发以及数据服务进行了深入探讨。本文为演讲的精华内容整理。
DataWorks概要
DataWorks是一站式智能化数据开发与治理平台,支持 MaxCompute/Hologres/AnalyticDB/E-Mapreduce/CDH/CDP 等大数据引擎,为企业构建现代数据仓库、数据湖以及湖仓融合数据架构提供数据平台产品解决方案。
作为阿里巴巴大数据平台建设者,DataWorks 从 2009 年起不断沉淀阿里巴巴大数据建设方法论并产品化,同时与数万家政务、金融、零售、互联网、能源、制造等阿里云客户携手,助力企业数字化升级。目前,DataWorks平台云上日调度任务实例数已超过1700万+。
下图是DataWorks产品模块架构,可以看到,最下面的计算存储引擎层已经包含了对OceanBase的支持。在计算存储引擎之上是数据集成模块,这个模块主要解决数据孤岛问题,比如我们的数据存储在各种异构存储、异构网络中,我们需要把这些数据按照特定的同步策略汇总到数据仓库中,这样才能做后续的数据分析和挖掘。目前,数据集成模块每日同步数据量超过10PB+。
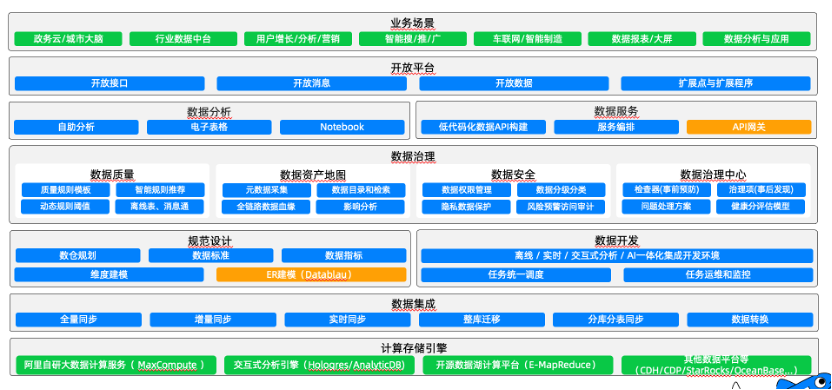
更上一层的数据治理模块中,数据开发是一项重要基础功能,我们在数据开发中可以通过图形化的方式配置数据加工ETL工作流,并且配置工作流调度,配置监控和执行运维。在数据开发上层,有完善的数据治理体系,保证ETL工作流数据安全可靠,并降低数据使用成本。
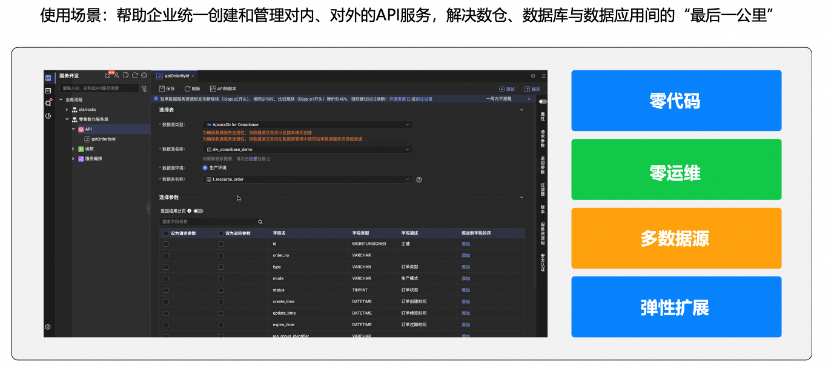
数据服务模块是一个灵活、轻量、安全稳定的数据API构建平台,解决了数据库和数据业务间“最后一公里”的问题。借助其全面的数据服务和共享能力,用户可以统一管理面向内外部的API服务。例如,可以将查询数据表功能快速的生成对应的API,或将已有的API注册至数据服务平台进行统一发布和管理。
DataWorks有良好的开放性,提供了开放API、开放消息等机制,用户甚至可以在DataWorks接入扩展程序,根据扩展程序实现特定业务逻辑。
数据集成作为DataWorks的核心基础模块,我们从六个维度保障数据同步的完整、安全和高效:
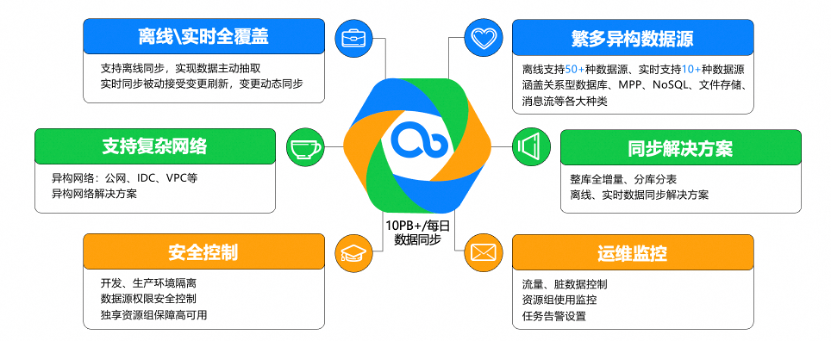
1. 离线/实时全覆盖:考虑到数据同步策略的多样性,DataWorks支持离线同步,实现数据主动抽取;支持实时同步,接受变更刷新,变更动态同步。
2. 支持复杂网络:上云成为主流趋势,云上也存在多种网络场景包括同VPC、跨VPC、跨用户、混合云跨云、IDC到云上等,一个成熟的数据平台需要考虑对各种异构网络如公网、IDC、VPC等的支持,并提供异构网络综合解决方案。
3. 繁多异构数据源:针对不同数据同步场景,用户配置运维任务有不同的诉求,因此,DataWorks会对各种场景提供对应的数据同步解决方案。离线支持50+种数据源、实时支持10+种数据源,涵盖关系型数据库、MPP、NoSQL、文件存储、消息流等。
4. 同步解决方案:整库全量、整库全增量、分库分表,提供离线、实时数据同步解决方案。
5. 安全控制:比如配置一个数据同步数据源,数据源有开发环境、生产环境,我们对数据同步任务引用的数据源做生产和开发环境隔离,以及数据源权限安全控制,另外独享任务执行资源保障高可用。
6. 运维监控:包括流量、脏数据控制;资源组使用监控、任务告警设置。
数据集成 OceanBase 同步原理
数据集成平台如何做数据同步?我们以OceanBase为例进行说明。
在离线批同步中,一个数据同步作业称之为一个Job,Job是逻辑上的一个概念,为了最大化的提高任务运行的吞吐和效率,运行中一个Job会拆变成多个Task,来并发或者并行的完成数据传输业务。每个Task内部有一个Reader组件负责数据读取、并由Writer组件负责数据写出。在OceanBase同步场景中,Reader和Writer底层基于OceanBase SQL来完成数据读取和写出的。这套框架有很好的可扩展性,每增加一种新的Reader或者Writer插件,天然的可以和其他已有存储直接进行交换数据。这个框架体系就是DataX,目前Github上的DataX就是我们 DataWorks 团队对外开源的。
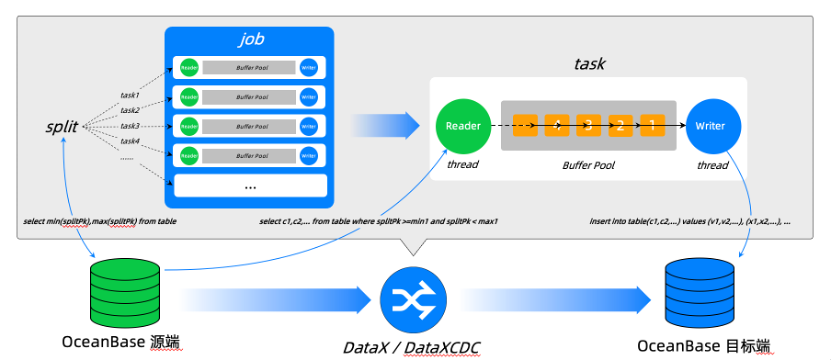
在流同步场景中,OceanBase SQL执行过程中会产生各种日志,比如典型的 Clog或BinLog,我们借助OceanBase的日志代理组件可以获取到Clog以及更友好、方便接入的BinLog数据。下游生态工具可以类似接入MySQL的格式,对接OceanBase并捕获OceanBase增量。OceanBase的增量主要包含两种变更事件类型,一种是DML,包含数据插入、更新、删除,另一种是DDL,包括add column等表结构变更。我们拿到增量数据后会进行分区、聚合、排序,并根据目标端的类型进行翻译重放。例如目标端类型是OceanBase时使用OceanBase SQL重放。
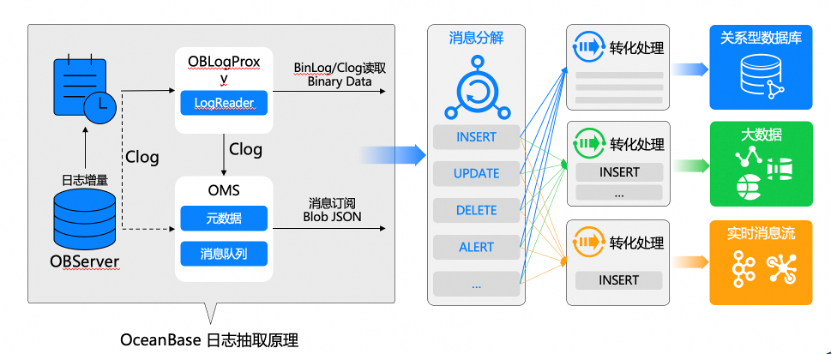
未来一年,DataWorks数据集成主要在四个方面做扩展。第一,整合流批一体同步引擎,维护一套框架,同一套技术栈支持流和批同步,提高研发效能。第二,加大对开源生态的投入,能够复用和集成社区丰富的Connector以及将有价值的Connector回馈给社区。第三,扩展支持DML / DDL / HeartBeat等全事件流的解析及同步。第四,追求极致的性能和成本,资源按需获取弹性扩缩容,增强分布式海量数据同步。
DataWorks x OceanBase 数据开发流程实践
我们介绍下一个经典的大数据开发流程,首先我们需要创建一个数据源,数据源包括各种类型,如数据库、数据仓库、消息队列、对象文件系统等。其次,我们要复制采集数据,创建数据同步作业将各种异构数据汇总到数据仓库或数据湖中,这一步可能涉及异构数据源的打通、网络连通解决、数据同步配置等。比如我们把OceanBase的数据抽取到数据仓库中来,在数据仓库中存储面向数据分析的数据,经过数仓分析后产出一份结果数据,这份数据是面向业务查询的数据。结果数据仍然通过数据集成同步回流到OceanBase,最后通过数据服务模块把OceanBase表里的数据对外暴露成一个数据的API,直接去支撑我们报表应用和大盘。
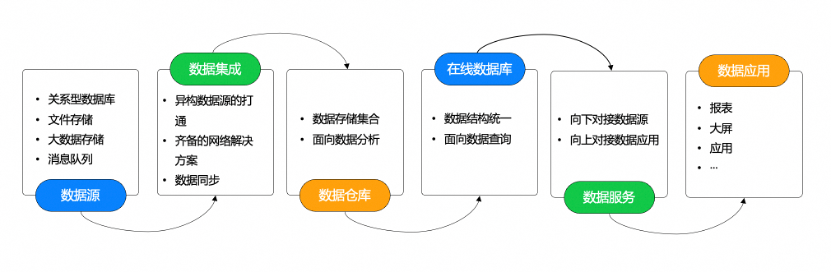
在上述大数据开发流程中,DataWorks对OceanBase都有较为全面的支持,DataWorks与OceanBase云产品已经无缝衔接。我们分别示意介绍如下:
首先,DataWorks支持 OceanBase数据源。数据源配置信息包括连接地址、账密、权限等,这些信息以加密、可靠的方式存储下来,这样的话,DataWorks后续的各个模块可以有复用这套数据源配置。这个数据源网络可能跨地域,如果OceanBase是私有化部署在IDC中也可以支持。

然后,一个典型场景是业务使用OceanBase的OLTP能力支撑线上业务需求,借助其他数仓工具如 MaxCompute 来做业务数据离线周期加工,这时候需要把OceanBase 的全量、增量变更数据同步到 MaxCompute 中。另一个典型场景是我们使用OceanBase的OLAP能力,把在线的MySQL数据全增量同步到 OceanBase 做挖掘分析。这两种场景在 DataWorks 中都可以图形化快捷完成任务配置和管理。配置举例如下:
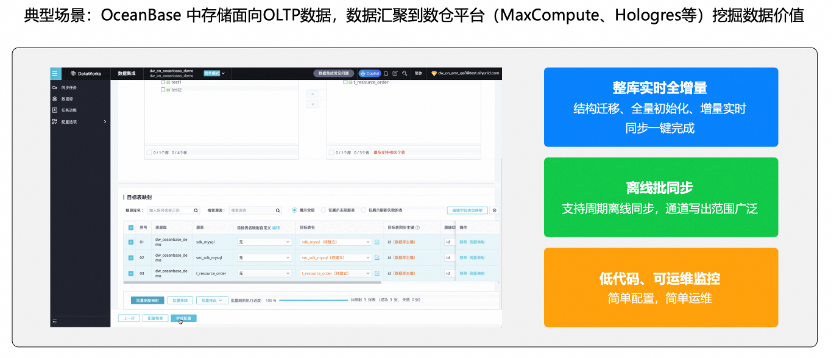
其他任务配置参考:
· 全增量同步到MaxCompute:https://help.aliyun.com/document_detail/175676.html
· 全增量同步到Hologres:https://help.aliyun.com/document_detail/171766.html
然后,DataWorks有一个强大的SQL节点编辑器以及工作流的调度编排系统,我们在DataWorks中增加了OceanBase数据开发节点,这样OceanBase 分析SQL可以和DataWorks已有的其他节点进行无缝连接,成为完整ETL工作流的一个组成部分。

最后,我们使用数据服务将数据对外暴露为API,支撑报表和大盘,配置举例:
OceanBase × DataWorks 的案例
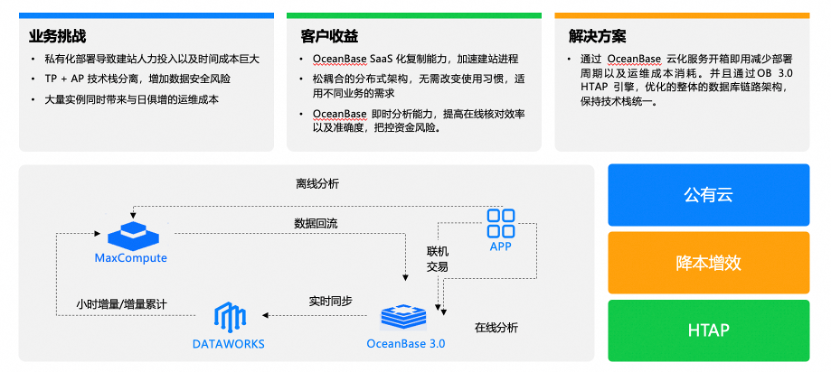
目前,DataWorks已经有非常多成熟案例,其中基于OceanBase的典型案例是蚂蚁银行新加坡分行,在这个环境中实现了OceanBase大集群模式的高效运维管理。
用户借助OceanBase的OLTP和OLAP能力,通过统一模型完成离线分析和在线分析,通过DataWorks实时同步将OceanBase的增量数据,订阅、汇总到MaxCompute。然后在MaxCompute可以做定期离线分析,分析结果回流到在线的OceanBase里,通过数据服务模块可以支撑在线业务查询,在线应用也可以直接触发调用MaxCompute做离线分析。
通过DataWorks和OceanBase强强联合,用户用一套技术架构替代了之前需要部署多种KA组件及复杂运维和服务保障的模式,取得了极高的性价比。
更多关于DataWorks和OceanBase联合解决方案的信息或疑问,欢迎来OceanBase的论坛进行讨论。
OceanBase快速上手:https://open.oceanbase.com/quickStart
OceanBase源码地址:https://github.com/oceanbase/oceanbase