本文来自OceanBase热心用户的分享
近期,我们计划将业务数据库从TiDB迁移到OceanBase,但面临的一个主要挑战是如何更平滑的完成这一迁移过程。经过研究,了解到OceanBase提供的OMS数据迁移工具能够支持从TiDB到OceanBase的迁移,并且它还具有数据增量同步的功能,不过需要依赖Kafka的支持。为了确保迁移的顺利进行,我们提前进行了全面的测试,以验证整个数据同步的可行性。以下是我们的测试记录,供大家参考和讨论。
环境介绍
以下各种组件安装过程不详细说明,具体安装过程在各产品官方网站都有详细说明,后面只介绍具体的配置过程
TiDB环境
TiDB版本:v5.4.3
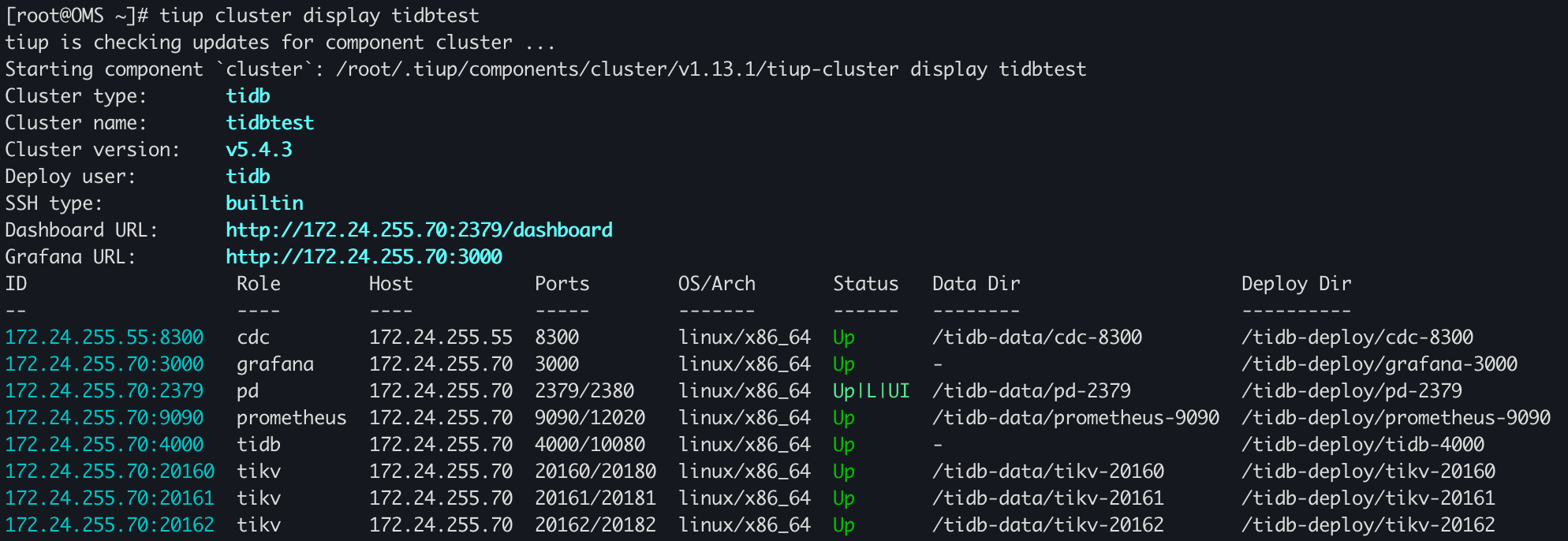
TiDB的部署是在一台单机上混部了TiDB Server、TiKV以及PD,TiCDC单节点部署在另外一台机器上
| 角色 | 机器 | 端口 |
| TiDB Server | 172.24.255.70 | 4000 |
| TiKV | 172.24.255.70 | 20160 |
| TiKV | 172.24.255.70 | 20161 |
| TiKV | 172.24.255.70 | 20162 |
| PD | 172.24.255.70 | 2379 |
| TiCDC | 172.24.255.55 | 8300 |
[root@OB3 bin]# ./cdc cli capture list --pd=http://172.24.255.70:2379
[{"id": "c0769fd8-78fa-4841-8103-586099d8fcf6","is-owner": true,"address": "172.24.255.55:8300"}
]OceanBase环境
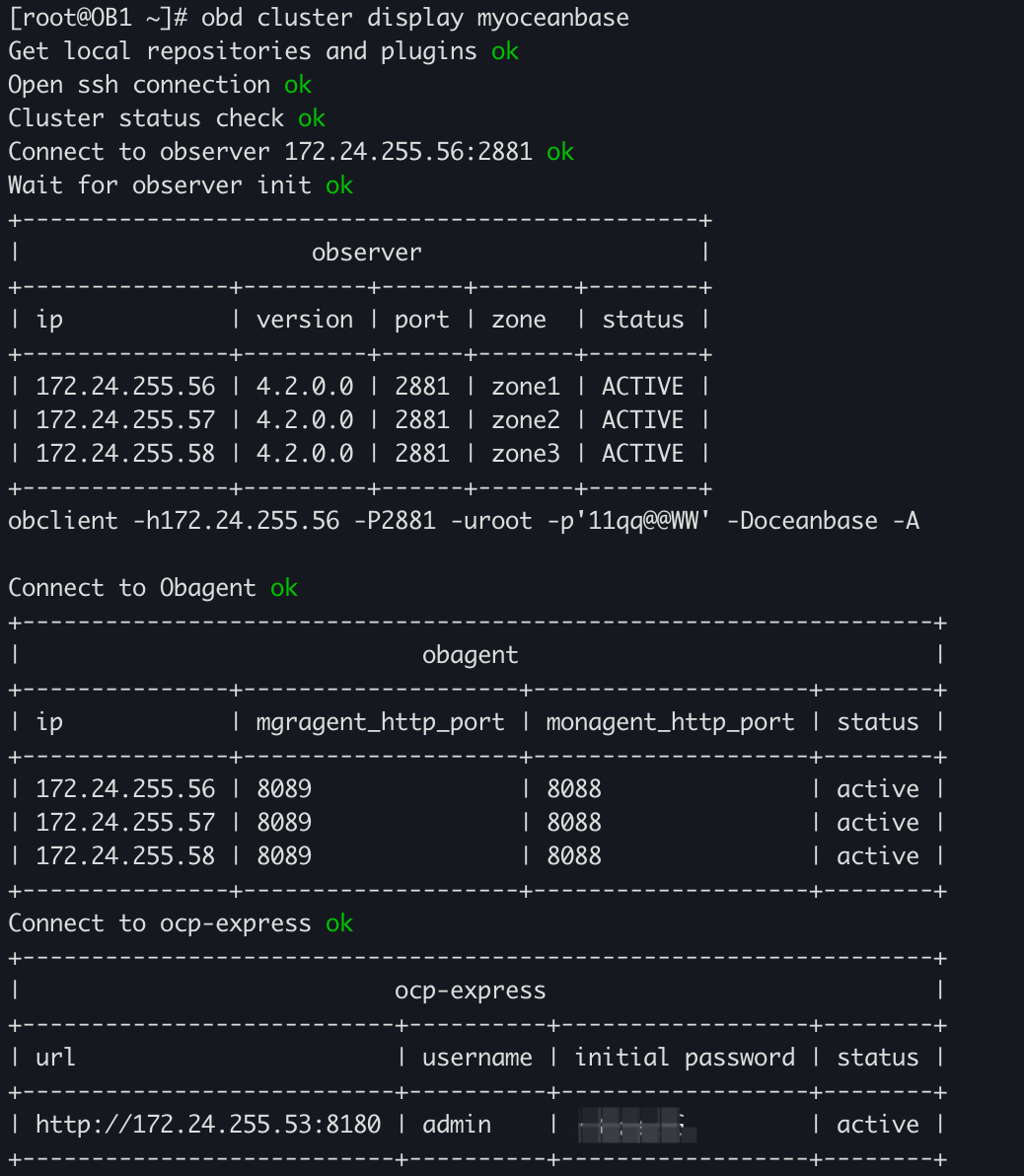
OceanBase版本:V4.2.0_CE
| 角色 | 机器 | 端口 |
| OBServer | 172.24.255.56 | 2881 |
| OBServer | 172.24.255.57 | 2881 |
| OBServer | 172.24.255.58 | 2881 |
| OBProxy | 172.24.255.56 | 2883 |
| OBProxy | 172.24.255.57 | 2883 |
Kafka环境
Kafka版本:3.1.0(TiCDC目前支持的最高版本是3.1.0版本)
Zookeeper版本:3.6.3
这里做测试,所以Kafka和zookeeper都是单机部署,没有采用集群部署,zookeeper用的是3.1.0版本自带的zookeeper,实际效果是一样的。
| 角色 | 机器 | 端口 |
| Kafka:broker | 172.24.255.55 | 9092 |
| zookeeper | 172.24.255.55 | 2181 |
[root@OB3 kafka]# ./bin/kafka-broker-api-versions.sh --bootstrap-server 172.24.255.55:9092 --version
3.1.0 (Commit:37edeed0777bacb3)[root@OB3 bin]# ./zookeeper-shell.sh 172.24.255.55:2181 version
Connecting to 172.24.255.55:2181
ZooKeeper CLI version: 3.6.3--6401e4ad2087061bc6b9f80dec2d69f2e3c8660a, built on 04/08/2021 16:35 GMTOMS环境
OMS版本:V4.1.1_CE
OMS采用的单节点部署
| 角色 | 机器 |
| OMS | 172.24.255.70 |
配置过程
创建TiCDC同步任务
TiCDC支持向mysql兼容、tidb以及Kafka中同步数据,这里因为需要OMS同步TiDB的增量数据,而增量数据是从Kafka中获取,因此需要创建TiCDC到Kafka的同步任务,创建示例如下:
./cdc cli changefeed create --pd=http://172.24.255.70:2379 \
--sink-uri="kafka://172.24.255.55:9092/test-topic?protocol=open-protocol&kafka-version=3.1.0&partition-num=1&max-message-bytes=67108864&replication-factor=1" \
--changefeed-id="simple-replication-task" --sort-engine="unified"这条命令会在TiCDC中创建一个名字为simple-replication-task的同步任务,并且会在Kafka中创建一个名字为test-topic的topic。创建完成之后,会收到如下信息
Create changefeed successfully!
ID: simple-replication-task
Info: {"sink-uri":"kafka://172.24.255.55:9092/test-topic?protocol=open-protocol\u0026kafka-version=3.1.0\u0026partition-num=1\u0026max-message-bytes=67108864\u0026replication-factor=1","opts":{"max-message-bytes":"1048588"},"create-time":"2023-10-09T15:41:57.1669333+08:00","start-ts":444815721665658881,"target-ts":0,"admin-job-type":0,"sort-engine":"unified","sort-dir":"","config":{"case-sensitive":true,"enable-old-value":true,"force-replicate":false,"check-gc-safe-point":true,"filter":{"rules":["*.*"],"ignore-txn-start-ts":null},"mounter":{"worker-num":16},"sink":{"dispatchers":null,"protocol":"open-protocol","column-selectors":null},"cyclic-replication":{"enable":false,"replica-id":0,"filter-replica-ids":null,"id-buckets":0,"sync-ddl":false},"scheduler":{"type":"table-number","polling-time":-1},"consistent":{"level":"none","max-log-size":64,"flush-interval":1000,"storage":""}},"state":"normal","error":null,"sync-point-enabled":false,"sync-point-interval":600000000000,"creator-version":"v5.4.3"}在Kafka中查看topic
[root@OB3 kafka]# bin/kafka-topics.sh --bootstrap-server 172.24.255.55:9092 --list
__consumer_offsets
test-topic这里有的参数简单说明下:
- --pd:指定TiCDC任务同步源端TiDC集群的pd信息
- --changefeed-id:指定同步任务的ID,如果不指定会自动生成
- --sink-uri:同步任务下游地址,需按照下面格式配置,目前 scheme 支持 mysql/tidb/kafka/pulsar:
- [scheme]://[userinfo@][host]:[port][/path]?[query_parameters]
- --sort-engine:指定 changefeed 使用的排序引擎。因 TiDB 和 TiKV 使用分布式架构,TiCDC 需要对数据变更记录进行排序后才能输出。该项支持 unified(默认)/memory/file:
- unified:优先使用内存排序,内存不足时则自动使用硬盘暂存数据。该选项默认开启。
- memory:在内存中进行排序。 不建议使用,同步大量数据时易引发 OOM。
- file:完全使用磁盘暂存数据。已经弃用,不建议在任何情况使用。
- 其他包括:--start-ts、--target-ts、--config配置,具体可参考官网,这里不过多介绍,本次同步任务也未用到。
实际同步到下游配置,是通过sink-uri决定,这里再简单说明下sink-uri中参数含义,在这次创建的任务中--sink-uri参数内容如下:
--sink-uri="kafka://172.24.255.55:9092/test-topic?protocol=open-protocol&kafka-version=3.1.0&partition-num=1&max-message-bytes=67108864&replication-factor=1"
| 参数 | 解析 |
| 172.24.255.55 | 下游 Kafka 对外提供服务的 IP |
| 9092 | 下游 Kafka 的连接端口 |
| topic-name | 变量,使用的 Kafka topic 名字,这里使用test-topic |
| kafka-version | 下游 Kafka 版本号(可选,默认值 2.4.0,目前支持的最低版本为 0.11.0.2,最高版本为 3.1.0) |
| partition-num | 下游 Kafka partition 数量 |
| max-message-bytes | 每次向 Kafka broker 发送消息的最大数据量(可选,默认值 10MB) |
| replication-factor | Kafka 消息保存副本数(可选,默认值 1) |
| protocol | 输出到 Kafka 的消息协议,可选值有 canal-json、open-protocol、canal、avro、maxwell |
- 除了上面这些配置,另外还有加密等配置,这里没有使用加密方式。
另外,OMS 社区版仅支持 TiCDC Open Protocol,不支持其它协议,因此在sink-uri中指定protocol时,必须制定protocol=open-protocol
在以上创建完成之后,在TiDB中创建表并插入数据
MySQL [test]> create table test_table(id int primary key, name varchar(20));
Query OK, 0 rows affected (0.08 sec)MySQL [test]> show tables;
+----------------+
| Tables_in_test |
+----------------+
| test_table |
+----------------+
1 row in set (0.00 sec)MySQL [test]> insert into test_table values(1,'OceanBase');
Query OK, 1 row affected (0.00 sec)可以在Kafka中看到增量信息
[root@OB3 kafka]# ./bin/kafka-console-consumer.sh --bootstrap-server 172.24.255.55:9092 --topic test-topic
Q{"q":"CREATE TABLE `test_table` (`id` INT PRIMARY KEY,`name` VARCHAR(20))","t":3}
Q{"u":{"id":{"t":3,"h":true,"f":11,"v":1},"name":{"t":15,"f":64,"v":"OceanBase"}}}OMS创建数据源
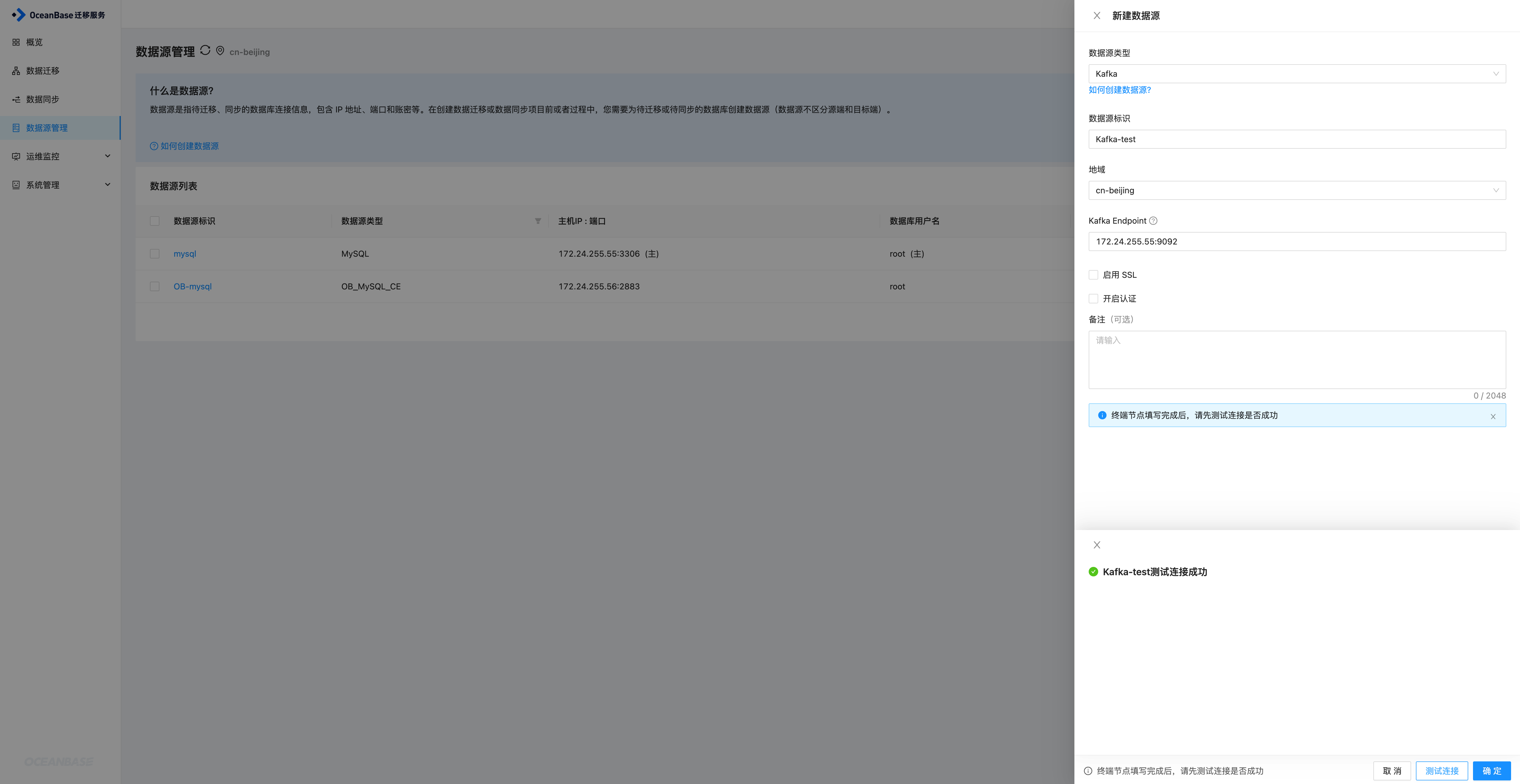
OMS上创建数据源时,需要创建两个数据源,一个是Kafka的,一个是TiDB的,在配置TiDB数据源时,需要关联Kafka数据源,因此这里先创建Kafka数据源。
Kafka数据源
进入到OMS数据源管理页面,新建数据源,选择Kakfa数据源,因为这里未使用SSL和认证,所以取消勾选,填写完成之后测试连接,连接成功之后确定即可添加成功。
TiDB数据源
同样进入到新建数据源页面,选择TiDB数据源,填写对应的信息,同时绑定Kafka,然后关联上一步创建的Kafka即可,选择创建好的test-topic,然后进行连接测试,测试成功之后确定即可添加TiDB数据源
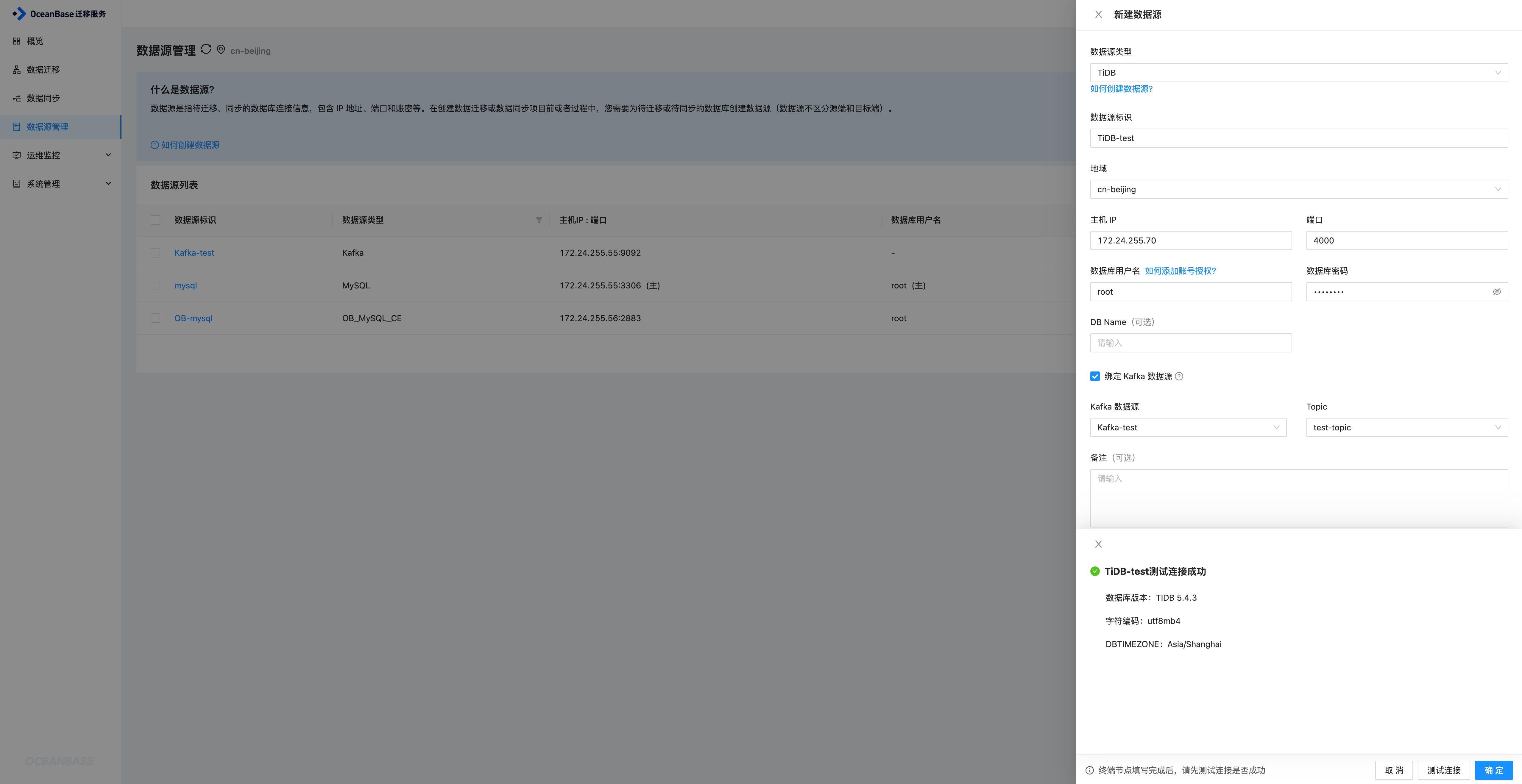
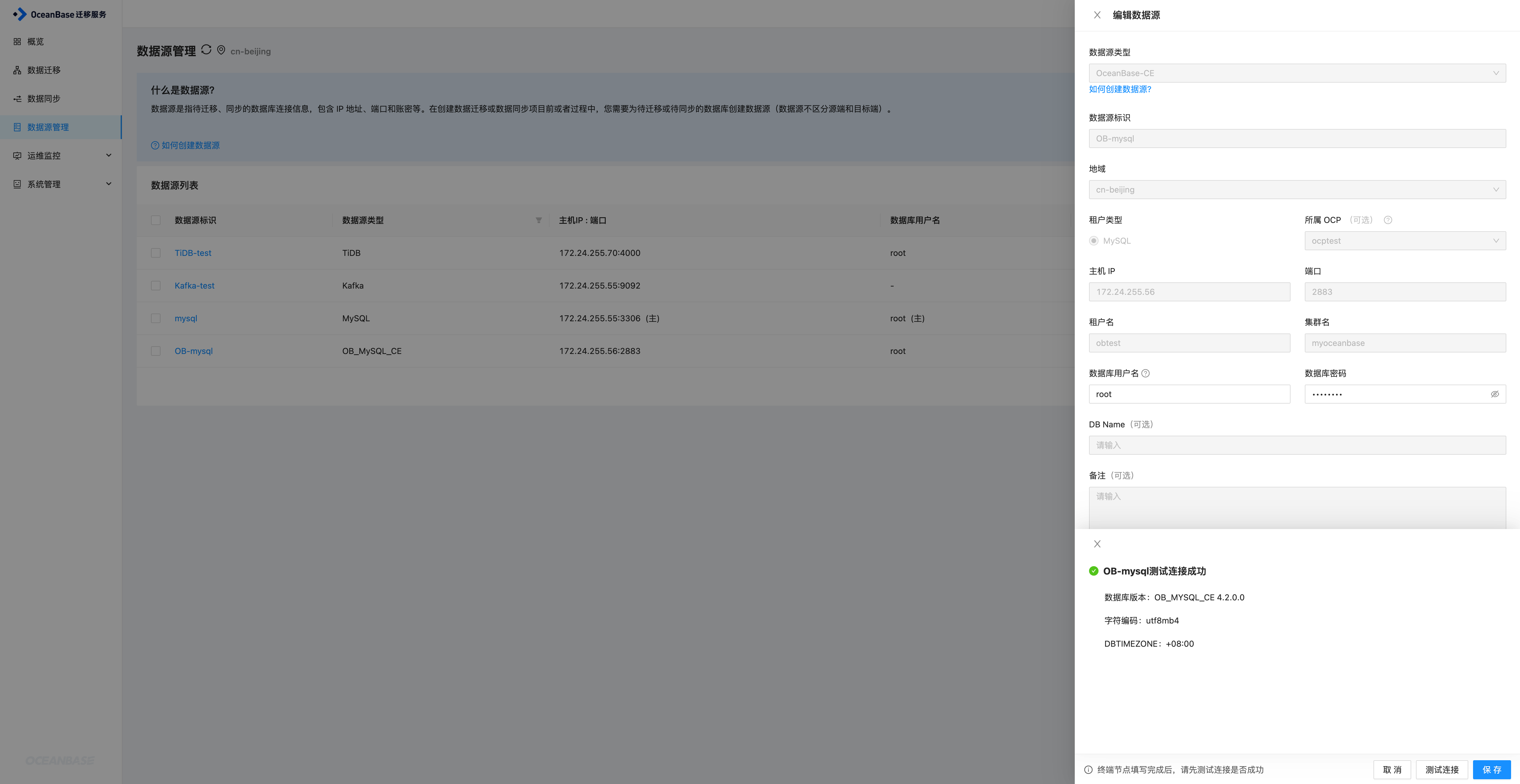
OceanBase数据源
方式基本相同
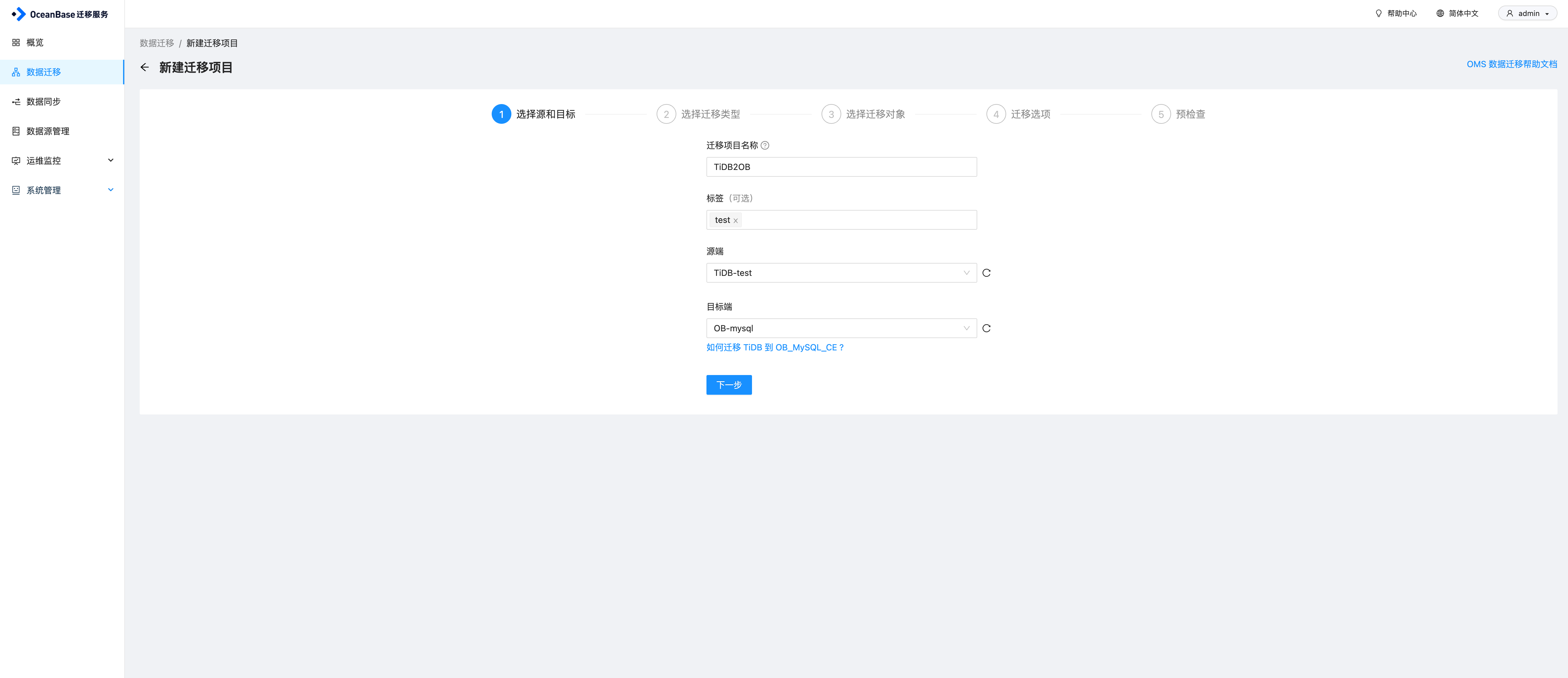
OMS创建迁移任务
在OMS数据迁移页面,点击创建迁移项目,输入项目名称,源和目标之后,点击下一步
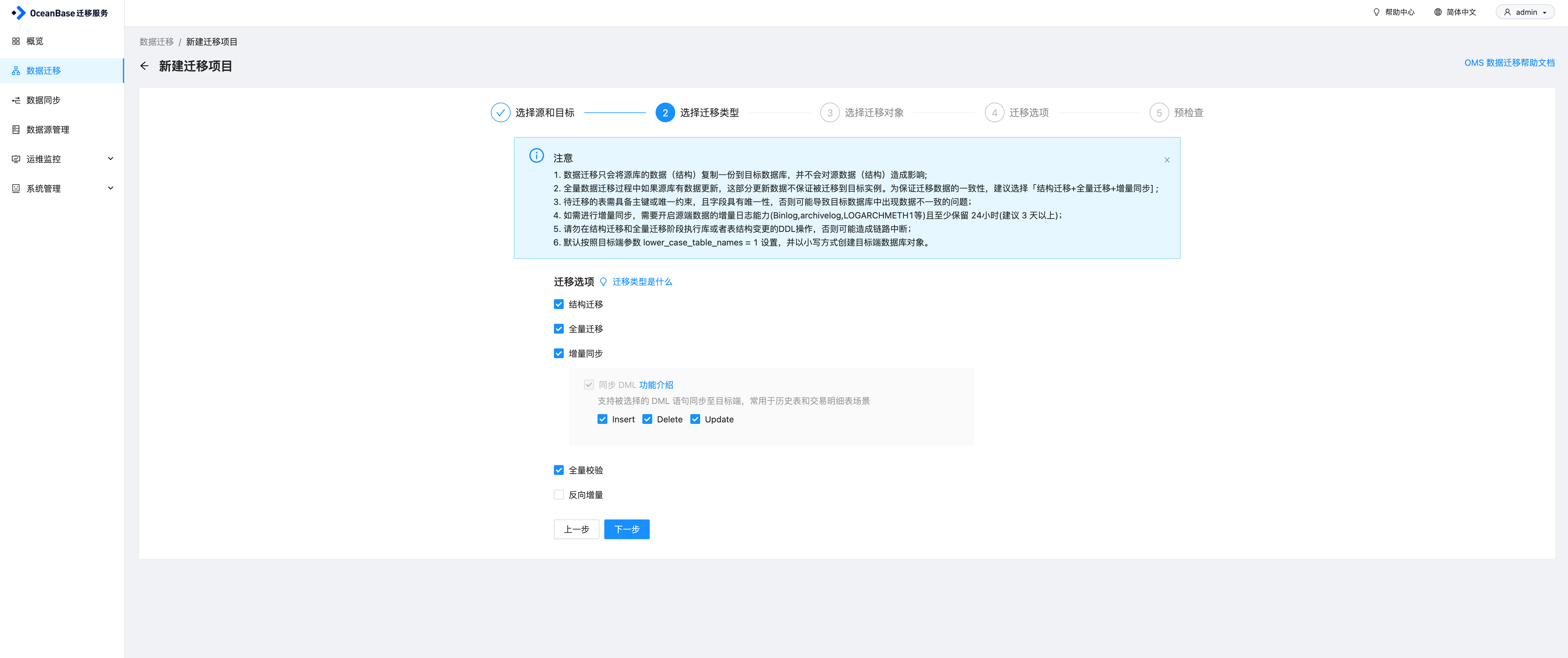
根据需求选择同步任务配置,这里勾选结构迁移、全量迁移、增量同步(Insert、Update、Delete)以及全量校验,注意这里不支持DDL同步,然后点击下一步
选择要同步的对象,这里可以直接指定对象,也可以选择匹配规则。我直接用了匹配规则,test库下所有对象都同步,然后点击校验,预览对象,因为目前TiDB的test库下只有test_table这张表,因此可以看到最终对象这里只显示了test_table,然后继续点击下一步
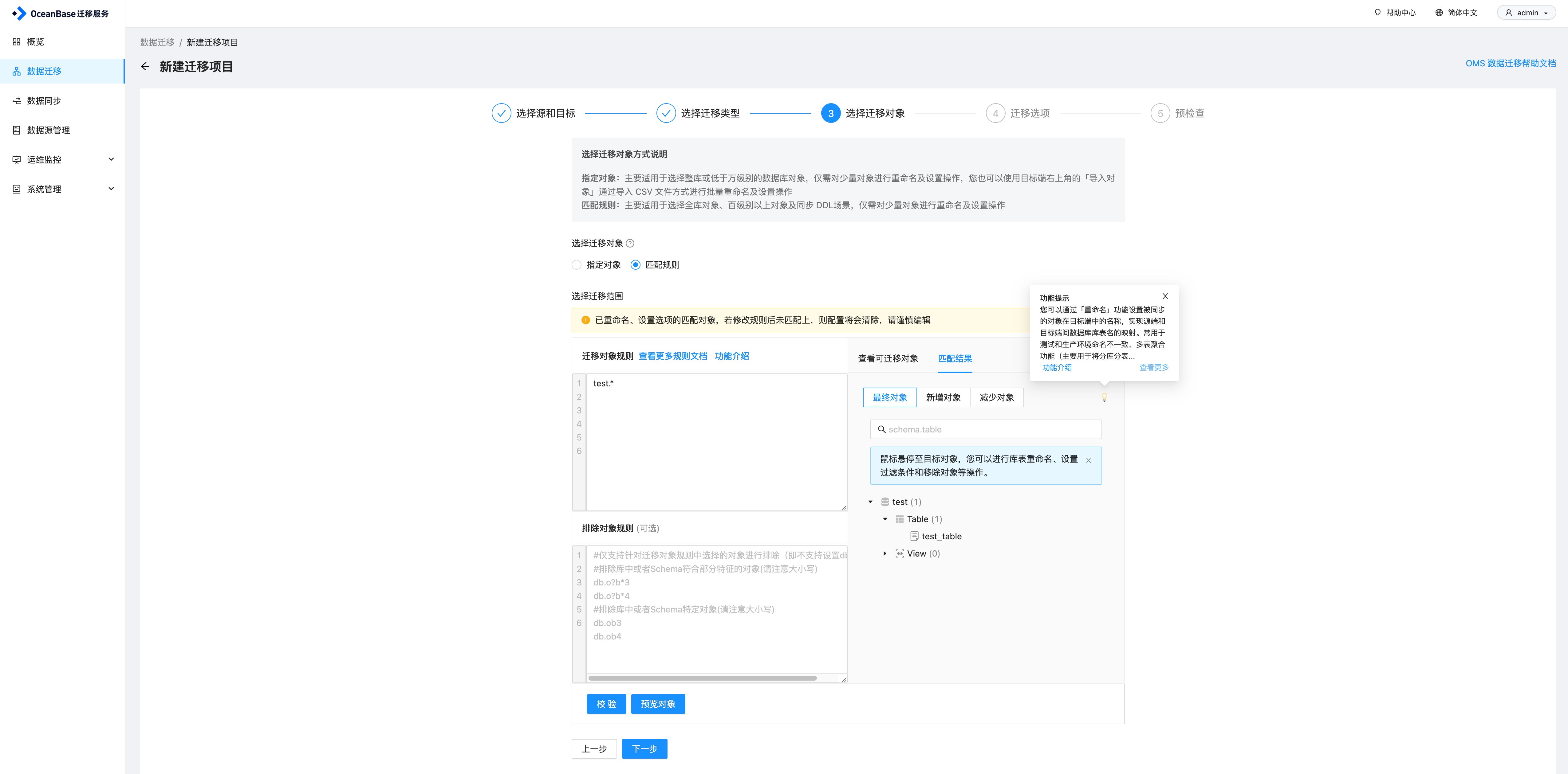
配置迁移选项,这里选择同步和校验的速率,速率越高,对资源的消耗越大。另外有高级配置中,目标端表对象存在记录时处理策略,以及是否允许索引后置,索引后置指OMS在完成对应表全量数据迁移、同步后创建非唯一键的索引,配置完成之后,进行预检查
预检查如果失败,需要检查失败原因,另外对于一些告警,也建议进行修复下,然后再开始同步任务。确认无误之后启动项目即可。

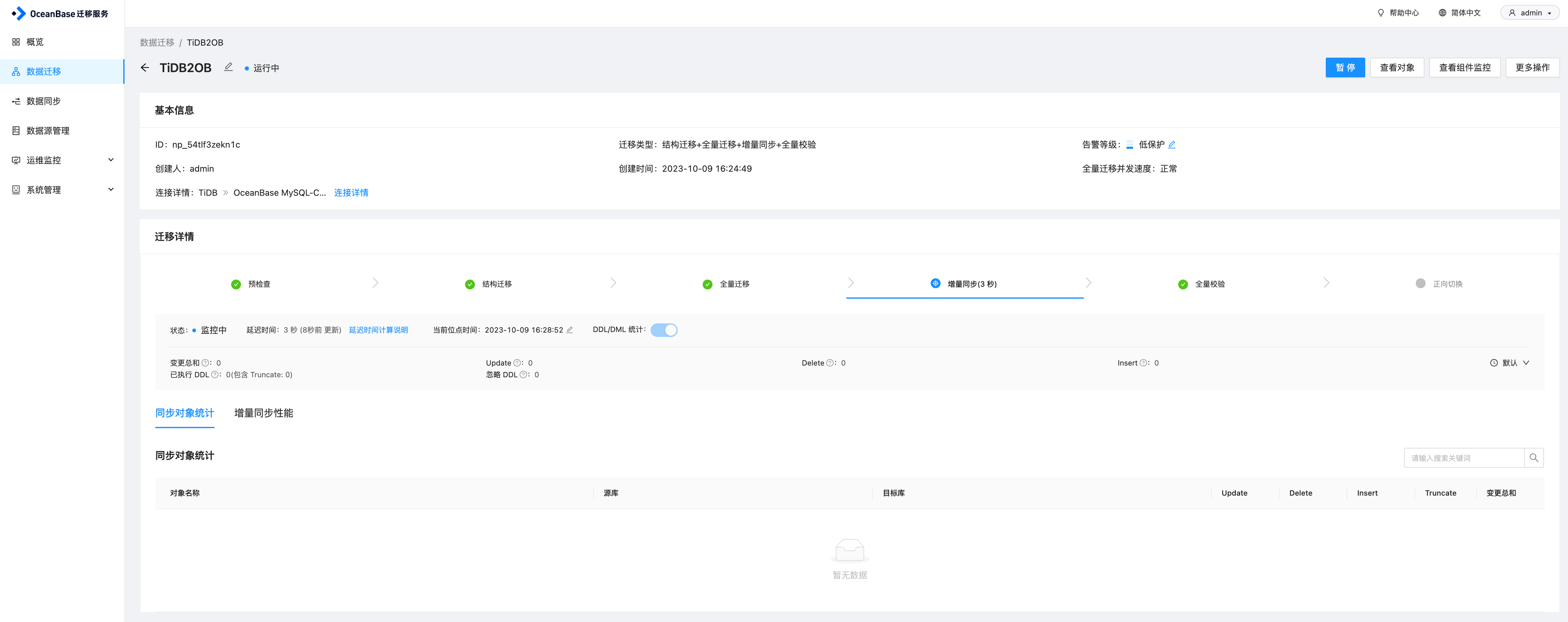
任务启动之后,会先进行全量迁移,即将原表中已有数据先迁移过来,完成之后会继续执行增量同步任务。
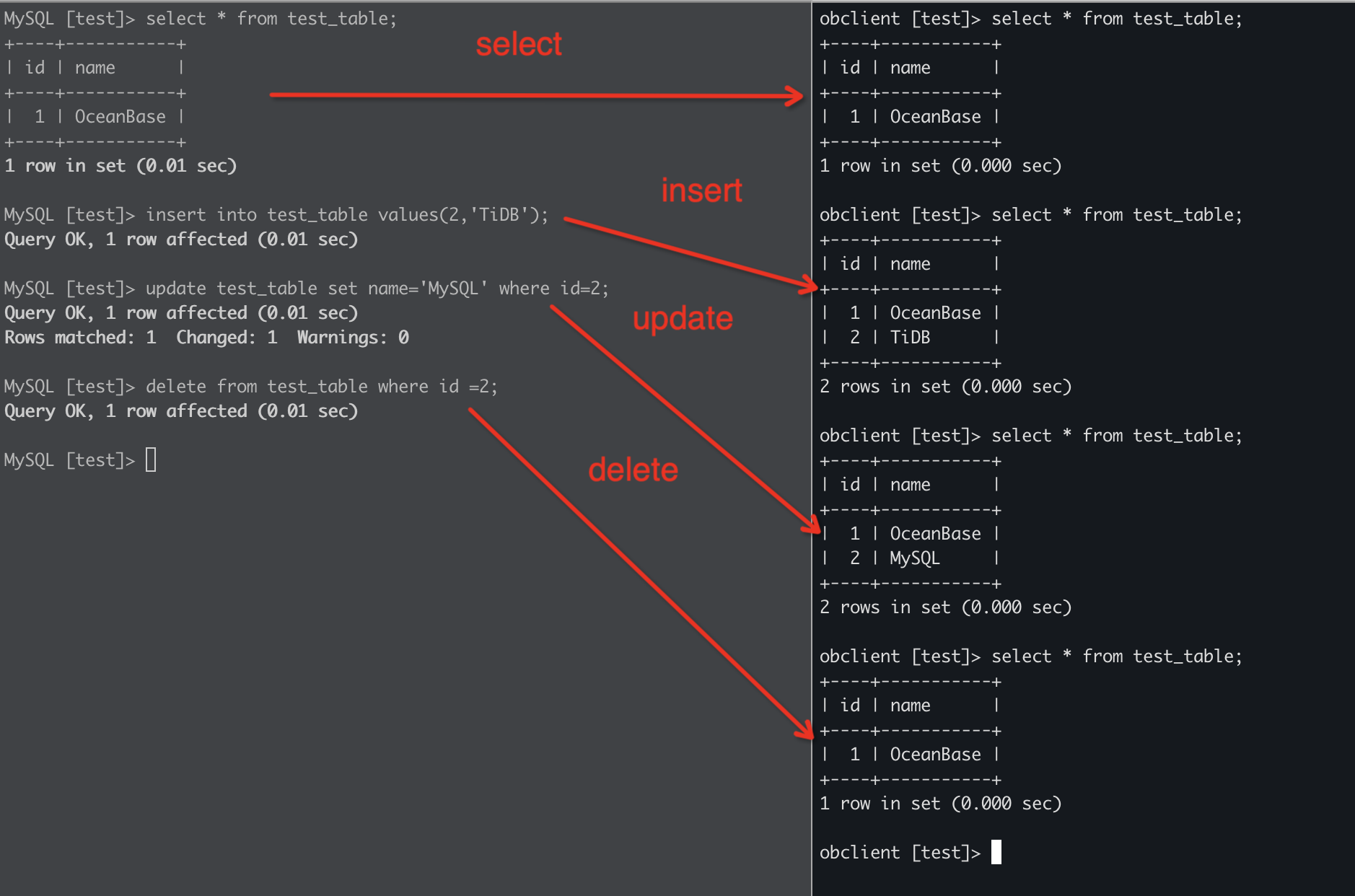
同步测试
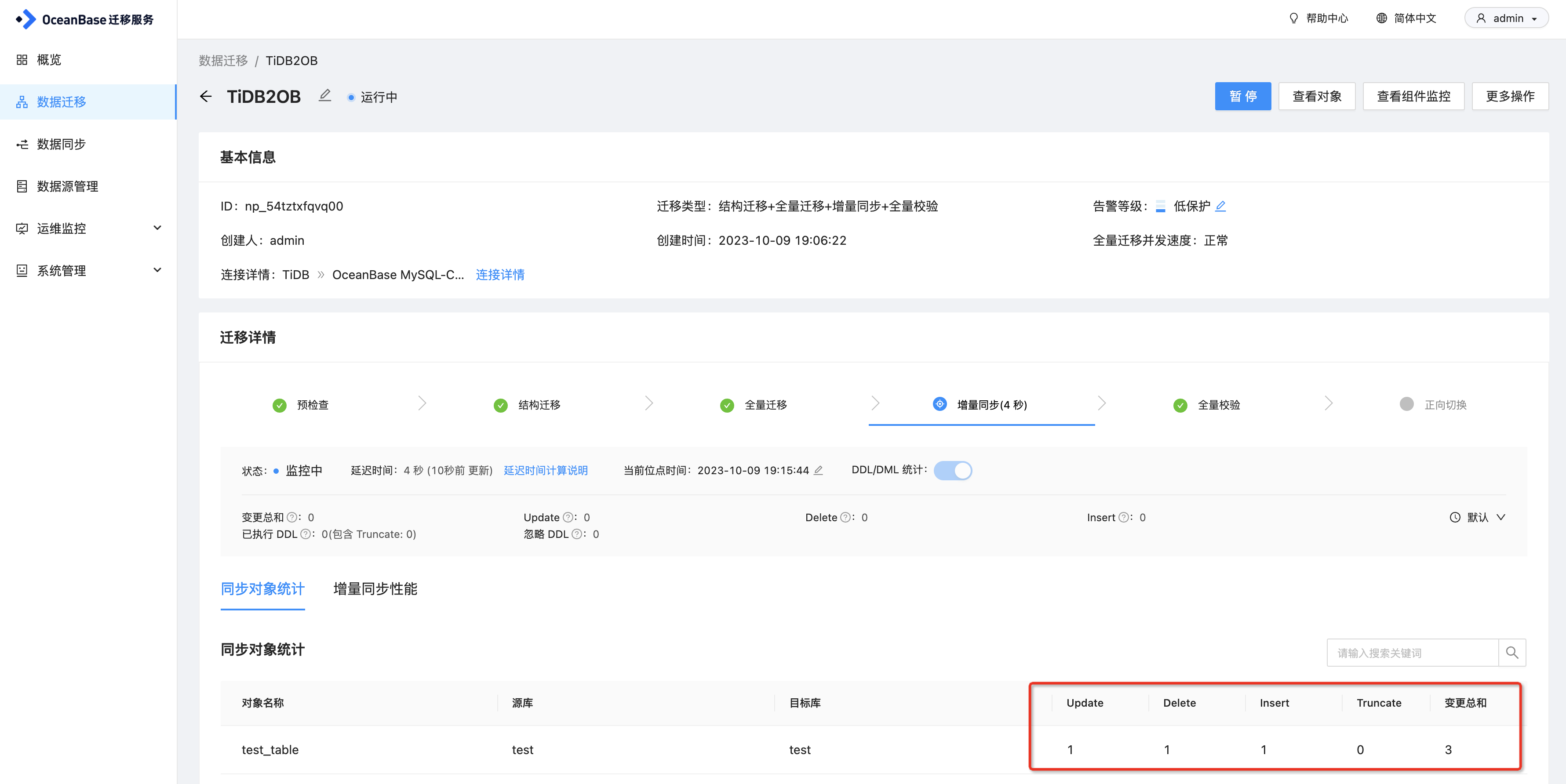
在TiDB端执行insert、update、delete操作,可以看到在OceanBase端同步成功。
另外在OMS上可以看到变更的统计信息