开发团队如何应对突发的技术故障和危机?
在数字化时代,软件服务的稳定性对于企业至关重要。然而,即使是大型平台,如网易云音乐,也可能遇到突发的技术故障。网页端出现502 Bad Gateway 报错,且App也无法正常使用。这类故障不仅影响用户体验,还可能导致公司声誉和经济损失。本文将探讨开发团队如何应对这类危机,如何快速响应、高效解决问题,并从中吸取教训,以提升团队的应急处理能力。

方向一:快速响应与问题定位策略
1. 快速响应的重要性
在技术故障发生时,快速响应是至关重要的。它不仅可以减少直接的经济损失,还能减少对公司声誉的损害。快速响应意味着团队能够迅速识别问题并采取措施,从而最大程度地减少系统停机时间。此外,及时向用户通报情况,可以提高透明度,维护用户信任。
2. 问题定位的策略
实时监控系统
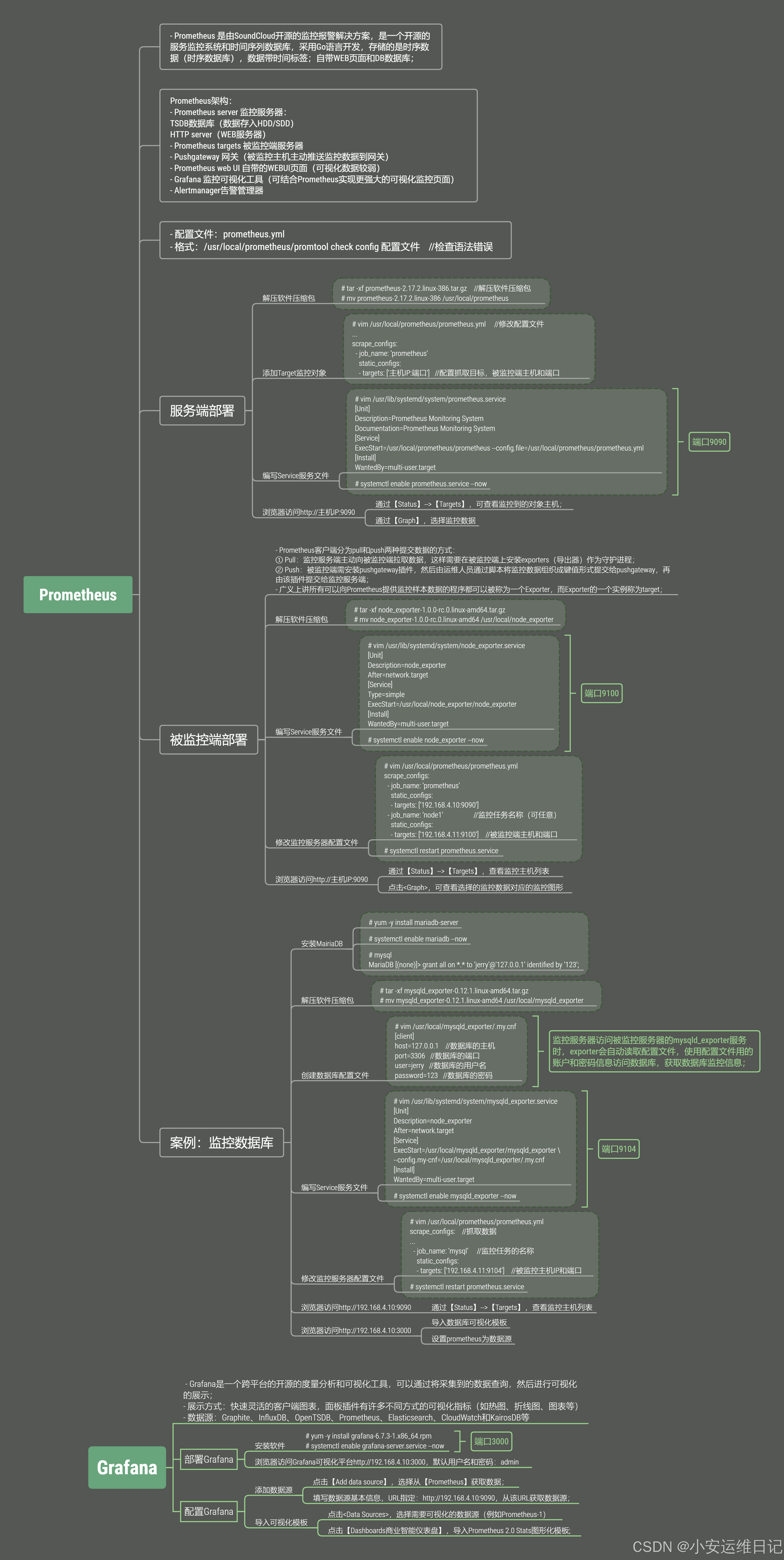
- 监控工具:部署实时监控工具,如Nagios、Zabbix或Prometheus,以监控服务器性能、网络流量和应用程序状态。
- 警报系统:设置警报阈值,一旦检测到异常,立即通知技术团队。
日志分析
- 日志管理:使用ELK Stack(Elasticsearch, Logstash, Kibana)或Splunk等工具来集中管理日志。
- 自动化分析:开发自动化脚本,帮助快速筛选和分析日志数据。
团队协作
- 沟通渠道:建立清晰的沟通渠道和流程,如Slack或JIRA。
- 角色定义:明确每个团队成员的角色和责任,确保快速而有序的响应。
3. 故障排查工具和方法
自动化测试
- 持续集成:实施持续集成(CI)流程,确保代码更改不会引入新的错误。
- 回归测试:定期运行回归测试,以验证系统各部分的稳定性。
版本控制
- 代码审查:利用Git等版本控制系统进行代码审查,快速追踪问题代码。
- 分支管理:合理管理分支,确保快速回滚到稳定版本。
专家系统
- 知识库:构建一个包含历史故障案例和解决方案的知识库。
- 机器学习:应用机器学习算法分析故障模式,预测潜在问题。
4. 案例分析
- 案例研究:分析类似网易云音乐8月19日的故障案例,总结其响应策略和问题定位方法。
- 教训总结:从案例中提取教训,如加强服务器冗余、优化负载均衡等。
5. 技术培训和模拟演练
- 定期培训:对团队进行定期的技术培训,提高他们对监控工具和日志分析的熟练度。
- 模拟故障:定期进行模拟故障演练,检验团队的响应速度和问题解决能力。
通过上述策略和方法,开发团队可以提高对突发技术故障的响应速度和问题定位的准确性,从而更有效地维护软件服务的稳定性和可靠性。

方向二:建立健全的应急预案和备份机制
1. 应急预案的制定
风险评估
- 全面性:系统性地识别所有可能影响系统稳定性的因素,包括硬件故障、软件缺陷、网络攻击等。
- 周期性:定期更新风险评估,以适应技术发展和业务变化。
预案制定
- 针对性:基于风险评估结果,制定针对性的应对策略。
- 灵活性:预案应能适应不同级别的故障和不同类型的问题。
2. 应急演练
定期演练
- 实战模拟:通过模拟真实场景,提高团队的实战应对能力。
- 反馈机制:演练后收集反馈,不断优化预案。
跨部门协作
- 沟通协议:建立清晰的沟通协议,确保信息快速、准确地传递。
- 角色明确:明确各部门在应急预案中的角色和责任。
3. 数据备份和快速恢复
数据备份
- 自动化:实现自动化备份流程,减少人为错误。
- 多地点存储:在不同地理位置存储备份数据,以防单一故障点。
快速恢复
- 灾难恢复计划:制定详细的灾难恢复计划,确保业务连续性。
- 恢复演练:定期进行恢复演练,确保恢复流程的有效性。
4. 重要准备工作
技术培训
- 专业技能:提供专业技能培训,提升团队的技术应对能力。
- 持续教育:鼓励团队成员持续学习,掌握最新的技术和工具。
资源准备
- 硬件冗余:确保有足够的备用硬件,以快速替换故障设备。
- 软件许可:维护软件许可证,确保在需要时能够快速部署。
5. 预案的持续优化
- 技术更新:随着技术的发展,不断更新预案内容。
- 法规遵从:确保预案符合最新的法律法规要求。
6. 预案的可访问性和透明度
- 文档管理:确保预案文档易于访问,格式清晰易懂。
- 全员培训:对所有团队成员进行预案培训,确保每个人都了解其内容。
7. 预案的测试与验证
- 压力测试:通过压力测试验证预案的有效性。
- 漏洞扫描:定期进行系统漏洞扫描,确保预案能够应对潜在的安全威胁。
8. 预案的沟通与教育
- 全员教育:确保所有团队成员都了解预案的基本内容和操作流程。
- 沟通计划:制定沟通计划,确保在危机发生时能够迅速传达信息。
通过这些措施,开发团队可以确保在面对技术故障时,有一个健全的应急预案和备份机制来支持快速、有效的响应。这不仅有助于减少故障带来的影响,也是提升团队信心和用户信任的重要手段。

方向三:事后总结与持续改进
1. 事后复盘
问题复盘
- 根本原因分析:采用"5 Whys"或"鱼骨图"等方法,深入挖掘故障的根本原因。
- 数据驱动:利用日志、监控数据等,确保分析的客观性和准确性。
经验分享
- 团队会议:组织团队会议,讨论故障处理过程中的得失。
- 知识共享:通过内部wiki、邮件列表等形式,将经验教训记录下来,供团队成员学习。
2. 持续改进机制
改进措施
- 行动计划:根据复盘结果,制定具体的行动计划和改进措施。
- 责任分配:明确改进措施的责任人和完成时限。
技术更新
- 技术趋势跟踪:持续关注技术发展趋势,评估对现有系统的潜在影响。
- 定期升级:根据技术发展趋势,定期升级系统组件和软件版本。
3. 培养危机意识
日常培训
- 危机管理培训:定期进行危机管理培训,提高团队对危机的认识和应对能力。
- 案例学习:通过分析历史案例,学习其他团队或公司的成功经验和失败教训。
模拟演练
- 定期演练:定期举行模拟演练,检验团队的应急响应流程。
- 多样化场景:设计多样化的故障场景,提高团队对不同类型危机的适应能力。
4. 建立反馈循环
- 收集反馈:在每次演练和实际故障处理后,收集团队成员的反馈。
- 持续优化:根据反馈不断优化应急预案和响应流程。
5. 强化团队协作
- 跨职能团队:建立跨职能团队,促进不同专业背景的成员之间的协作。
- 沟通技巧培训:提高团队成员的沟通技巧,确保在高压环境下信息的有效传递。
6. 技术债务管理
- 识别技术债务:在复盘过程中识别技术债务,并评估其对系统稳定性的影响。
- 优先级排序:根据技术债务的严重性和修复成本,制定修复计划。
7. 用户反馈的整合
- 用户沟通:在故障发生后,积极与用户沟通,收集用户反馈。
- 产品改进:将用户反馈整合到产品改进计划中,提高用户满意度。
通过这些措施,开发团队不仅能够在危机发生后快速恢复,还能够从中学习和成长,不断提升自身的技术实力和应急能力。这种持续改进的文化将有助于团队在面对未来可能出现的挑战时,更加从容不迫。

方向四:代码案例分析
面对突发的技术故障和危机,开发团队需要采取一系列措施来确保快速响应和有效解决问题。以下是一些具体的步骤和代码示例,展示如何在实际开发过程中应对技术故障。
1. 实时监控和警报系统
实时监控系统可以帮助团队快速发现问题。以下是一个使用Python编写的简单监控脚本示例,它会定期检查服务器的响应状态,并在发现问题时发送警报。
import requests from twilio.rest import Client# 配置信息 ALERT_PHONE_NUMBER = 'YOUR_ALERT_PHONE_NUMBER' TWILIO_SID = 'YOUR_TWILIO_SID' TWILIO_TOKEN = 'YOUR_TWILIO_TOKEN' CHECK_URL = 'https://example.com'# Twilio 客户端初始化 twilio_client = Client(TWILIO_SID, TWILIO_TOKEN)def check_server_status(url):try:response = requests.get(url)if response.status_code != 200:raise Exception(f"Server returned status code: {response.status_code}")except Exception as e:send_alert(str(e))def send_alert(message):twilio_client.messages.create(to=ALERT_PHONE_NUMBER,from_='YOUR_TWILIO_PHONE_NUMBER',body=f"Alert: {message}")# 定期检查 import schedule import timeschedule.every(10).minutes.do(check_server_status, CHECK_URL)while True:schedule.run_pending()time.sleep(1)2. 快速定位问题源头
使用日志分析工具来快速定位问题源头。以下是一个简单的Python日志分析函数,它可以搜索特定错误模式。
import redef analyze_logs(logs, error_pattern):error_messages = [line for line in logs if re.search(error_pattern, line)]return error_messages# 示例日志和错误模式 logs = ["2023-08-19 14:00:00 INFO Starting server...","2023-08-19 14:05:00 ERROR Database connection failed","2023-08-19 14:06:00 INFO User logged in","2023-08-19 14:10:00 ERROR 502 Bad Gateway" ]error_pattern = r"ERROR" errors = analyze_logs(logs, error_pattern) print(errors) # 输出所有错误日志3. 应急预案和备份机制
开发团队应该有一套应急预案和备份机制。以下是一个简单的备份脚本示例,它会定期备份数据库。
import shutil import os from datetime import datetimedef backup_database(source, destination):timestamp = datetime.now().strftime("%Y%m%d%H%M%S")backup_path = os.path.join(destination, f"db_backup_{timestamp}.sql")shutil.copy(source, backup_path)print(f"Database backup created at {backup_path}")# 配置信息 SOURCE_DB_PATH = '/path/to/source/database.sql' DESTINATION_BACKUP_PATH = '/path/to/backup/directory'# 定期备份 import schedule import timeschedule.every().day.at("01:00").do(backup_database, SOURCE_DB_PATH, DESTINATION_BACKUP_PATH)while True:schedule.run_pending()time.sleep(1)4. 事后总结与持续改进
团队应该在每次故障后进行总结,并根据总结结果持续改进。以下是一个简单的Python函数,用于记录和分析故障处理过程。
def record_incident_summary(incident_id, summary, action_taken):with open(f"incident_{incident_id}.txt", "w") as file:file.write(f"Summary: {summary}\n")file.write(f"Action Taken: {action_taken}")# 示例使用 record_incident_summary(1, "Database connection failed due to network issue", "Switched to backup server")这些代码示例提供了一个基础框架,展示了开发团队如何通过技术手段应对突发的技术故障和危机。在实际应用中,这些脚本和函数需要根据具体的业务需求和技术环境进行调整和扩展。
结语
面对突发的技术故障和危机,开发团队需要具备快速响应的能力、健全的应急预案和备份机制,以及持续改进的意识。通过这些措施,团队不仅能够有效地应对危机,还能够从中学习和成长,提升整体的技术实力和应急能力。

希望这篇博客能够为你在安全漏洞中提供一些启发和指导。如果你有任何问题或需要进一步的建议,欢迎在评论区留言交流。让我们一起探索IT世界的无限可能!
博主还写了其他关联文章,请各位大佬批评指正:
1、“微软蓝屏”事件:网络安全与系统稳定性的深刻反思
2、安全漏洞代码扫描
3、Linux系统cpu飙升到100%排查方案
4、Linux常用操作命令、端口、防火墙、磁盘与内存








![World of Warcraft [CLASSIC] the Eye of Eternity [EOE] P1-P2](https://i-blog.csdnimg.cn/direct/40c2276b92274dd9a09cc9d9b0d5eec8.jpeg)





![[C语言]-基础知识点梳理-编译、链接、预处理](https://i-blog.csdnimg.cn/direct/5cc94287a23240a9931d80804c0cfa9d.png)

