DP:[1] CHI C, FENG S, DU Y, et al. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion[J]. 2023.
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion精读笔记(一)-CSDN博客
哥伦比亚大学突破性的方法- Diffusion Policy:利用Action Diffusion进行视觉运动策略学习-CSDN博客
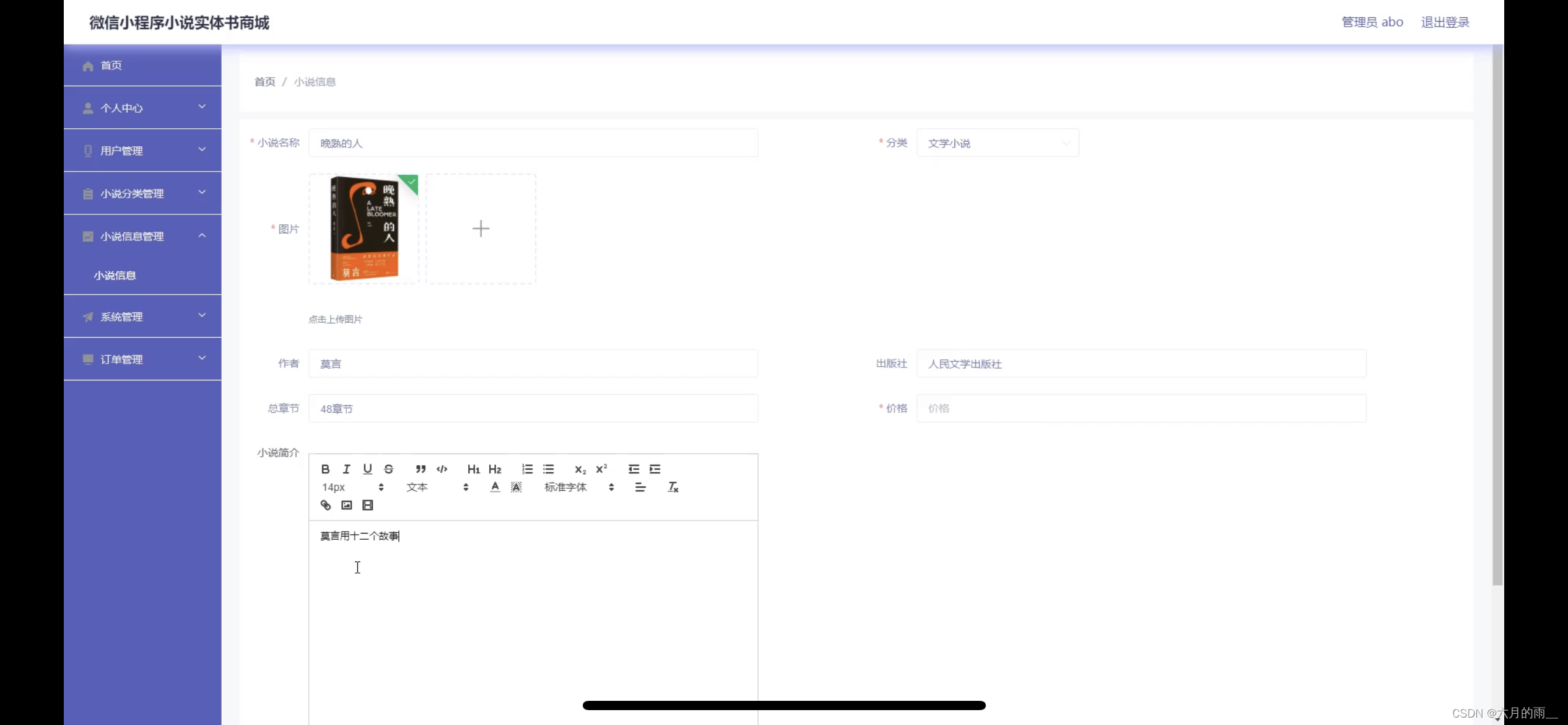
图1。Policy表示。a) 具有不同类型动作表示的显式 policy。b) 隐式 policy 学习以动作和观察为条件的能量函数,并优化最小化能量景观 c) 扩散 policy 通过学习的梯度场将噪声细化为动作。该公式提供了稳定的训练,允许学习的policy准确地建模多模态动作分布,并适应高维动作序列。
图 2. 扩散策略概述 a) 一般公式。在时间步 t,policy 将观测数据
的最新
步作为输入并输出动作
的
步。b) 在基于 cnn 的扩散策略中,FiLM(特征线性调制Feature-wise Linear Modulation)对观察特征
的条件应用于每个卷积层,通道。从高斯噪声中提取的
开始,减去噪声预测网络
的输出,重复k次得到
,去噪动作序列。c) 在基于 transformer 的扩散策略,观察 ot 的嵌入被传递到每个 transformer 解码器块的多头交叉注意力层。每个动作嵌入都被限制为仅使用说明的注意力掩码关注自身和先前的动作嵌入(因果注意力)。


VINN:[1] PARI J, SHAFIULLAH N, ARUNACHALAM S, et al. The Surprising Effectiveness of Representation Learning for Visual Imitation[J].
4. Co-training with Static ALOHA Data
使用模仿学习解决现实世界机器人任务的典型方法依赖于使用在特定机器人硬件平台上为目标任务收集的数据集。然而,这种简单的方法存在漫长的数据收集过程,其中人类操作员在特定的机器人硬件平台上从头开始为每个任务收集演示数据。由于这些数据集中的视觉多样性有限,在这些专业数据集上训练的policies通常对感知扰动(如干扰物和光照变化)不具有鲁棒性[95]。最近,对从不同但相似类型的机器人收集的不同真实世界数据集进行联合训练,在单臂操纵[11,20,31,61]和导航[79]方面显示出有希望的结果。
在这项工作中,我们使用了一个协同训练pipeline,它利用现有的静态aloha数据集来提高移动操作的模仿学习性能,特别是对于手动手臂动作。静态aloha数据集[81,104]总共有825个演示,包括ziploc密封,拿起叉子,糖果包装,撕开纸巾,打开带盖子的塑料杯,玩乒乓球,胶带分发,使用咖啡机,铅笔交付,紧固魔术贴电缆,开槽电池,以及处理螺丝刀。注意,静态aloha数据都是在一个黑色桌面上收集的,两个手臂固定在一起,面向对方。这种设置与移动aloha不同,移动aloha的背景随着移动基座的变化而变化,两个手臂平行地面向前方放置。我们没有对rgb观测数据或静态alohadata的手动操作使用任何特殊的数据处理技术来进行共同训练。
将聚合的静态aloha数据表示为![]() ,将任务m的移动aloha数据表示为
,将任务m的移动aloha数据表示为![]() 。双手动作表示为目标关节位置
。双手动作表示为目标关节位置![]() ,其中包含两个连续的抓取动作,基础动作表示为目标基准线速度和角速度
,其中包含两个连续的抓取动作,基础动作表示为目标基准线速度和角速度![]() 。任务m的移动操作policy
。任务m的移动操作policy![]() 的训练目标为
的训练目标为

其中![]() 是由两个手腕相机RGB观测、一个安装在手臂之间的自中心顶部相机RGB观测和手臂的关节位置组成的观测,L是模仿损失函数。我们以相等的概率从静态ALOHA数据
是由两个手腕相机RGB观测、一个安装在手臂之间的自中心顶部相机RGB观测和手臂的关节位置组成的观测,L是模仿损失函数。我们以相等的概率从静态ALOHA数据![]() 和移动ALOHA数据
和移动ALOHA数据![]() 中采样。我们将批量大小设置为16。由于静态ALOHA数据点没有移动基础动作,我们将动作标签归零,这样两个数据集中的动作具有相同的维度。我们还忽略了静态ALOHA数据中的前置摄像头,因此两个数据集都有3个摄像头。我们仅根据移动ALOHA数据集
中采样。我们将批量大小设置为16。由于静态ALOHA数据点没有移动基础动作,我们将动作标签归零,这样两个数据集中的动作具有相同的维度。我们还忽略了静态ALOHA数据中的前置摄像头,因此两个数据集都有3个摄像头。我们仅根据移动ALOHA数据集![]() 的统计数据对每个动作进行归一化。在我们的实验中,我们将这种联合训练方法与多种基础模仿学习方法相结合,包括ACT[104]、扩散策略[18]和VINN[63]。
的统计数据对每个动作进行归一化。在我们的实验中,我们将这种联合训练方法与多种基础模仿学习方法相结合,包括ACT[104]、扩散策略[18]和VINN[63]。
5. Tasks
我们想强调的是,对于上述所有任务,将对象恢复到相同配置的开环重放演示将实现零整体任务成功(完全不成功)。成功完成任务需要学习的policy做出闭环反应并纠正这些错误。我们认为开环回放过程中的误差来源是移动基站的速度控制。例如,我们观察到,在回放半径为1m的180度转弯的基本动作时,平均误差>10cm。我们在附录a.4中提供了有关此实验的更多详细信息。
6. Experiments
我们的目标是回答实验中的两个核心问题。
(1) 移动ALOHA可以通过联合训练和少量移动操作数据获得复杂的移动操作技能吗?
(2) mobile ALOHA是否可以与不同类型的模仿学习方法一起工作,包括ACT[104]、扩散策略[18]和基于检索的VINN [63]?我们在现实世界中进行了大量的实验来检验这些问题
首先,我们将研究的所有方法都采用“动作分块”[104],其中policy预测未来动作的序列,而不是每个时间步的一个动作。它已经是act和diffusion policy方法的一部分,并且很容易添加到vinn中。我们发现动作分块对于操作至关重要,可以提高生成轨迹的连贯性,减少每一步policy推理的延迟。动作分块也为移动aloha提供了一个独特的优势:更灵活地处理硬件不同部分的延迟。我们观察到移动基地的目标速度和实际速度之间存在延迟,而位置控制臂的延迟要小得多。为了解释移动基座d步的延迟,我们的机器人执行了长度为k的动作块的前k−d个手臂动作和最后k−d个基座动作。
6.1. Co-training Improves Performance
我们从aloha引入的方法act[104]开始,在有和没有联合训练的情况下对其进行所有7项任务的训练。然后,我们评估现实世界中的每个policy,如图3所示,对机器人和物体配置进行随机化。为了计算子任务的成功率,我们将#success除以#attempts。例如,在“提起玻璃和擦拭”子任务的情况下,#尝试次数 #Attempts 等于前一个子任务“抓住毛巾”的成功次数,因为机器人可能会在任何子任务中失败并停止。这也意味着最终成功率等于所有子任务成功率的乘积。我们在表1中报告了所有成功率。每个成功率都是根据20次评估试验计算的,除了cook shrimp有5次。
在联合训练的帮助下,机器人在擦拭酒方面取得了95%的成功,在呼叫电梯方面取得了95%的成功,使用橱柜方面取得了85%的成功。high five方面取得了85%的成功,rinse pan方面取得了80%的成功,push chair方面取得了80%的成功。这些任务中的每一项只需要50次印度支那示威,或者在high five的情况下需要20次。唯一成功率低于80%的任务是烹饪虾(40%),这是一项75秒的长期任务,我们只收集了20个演示。我们发现policy很难用抹刀翻转虾,并将虾倒入与白色桌子对比度较低的白色碗中。我们假设,较低的成功率可能是由于演示数据有限。联合训练提高了7项任务中5项的整体任务成功率,分别提高了45%、20%、80%、95%和80%。对于剩下的两项任务,联合训练和不联合训练的成功率相当。我们发现,对于精确操作是瓶颈的子任务,例如按下按钮、翻转虾和打开水龙头,联合训练更有帮助。在所有这些情况下,复合误差似乎是失败的主要原因,要么来自机器人基础速度控制的随机性,要么来自丰富的接触,例如在flip shrimp过程中抓握抹刀和接触锅。
我们假设,在静态aloha数据集中抓取和接近物体的“运动先验”仍然有利于移动aloha,特别是考虑到手腕相机引入的不变性[41]。我们还发现,共同训练的policy在推椅和擦拭酒的情况下具有更好的泛化能力。对于push chairs,无论是联合训练还是非联合训练,前3把椅子都取得了完美的成功,这在演示中可以看到。然而,当外推到第四和第五把椅子时,联合训练的表现要好得多,分别提高了15%和89%。对于wipe wine,我们观察到共训练的policy在酒杯随机化区域的边界处表现更好。因此,我们假设,鉴于20-50个演示的低数据范围和使用的基于表达变换器 the expressive transformer-based 的policy,联合训练也有助于防止过拟合。
6.2. Compatibility with ACT, Diffusion Policy, and VINN
除了act之外,我们还使用mobile aloha训练了两种最新的模仿学习方法,即扩散策略[18]和vinn[63]。扩散policy训练神经网络以逐步改进动作预测。我们使用ddim调度器[85]来提高推理速度,并将数据增强应用于图像观测以防止过拟合。联合训练数据pipeline与act相同,我们在附录a.3中包含了更多的训练细节。vinn训练了一个视觉表示模型byol[37],并使用它从具有最近邻的演示数据集中检索动作。我们用本体感觉特征增强vinn检索,并调整相对权重以平衡视觉和本体感觉特征的重要性。我们还检索了一个动作块而不是单个动作,并发现类似于赵等人的显著性能改进。对于共同训练,我们只需使用组合的移动和静态数据共同训练BYOL编码器。
在表2中,我们报告了两个现实世界任务的联合训练和无联合训练成功率:擦酒和推椅子。总体而言,扩散政策在推椅上的表现与act相似,两者在联合培训中都获得了100%的成绩。对于wipe wine,我们观察到扩散效果较差,成功率为65%。当接近厨房岛并抓住酒杯时,扩散政策不太精确。我们假设,鉴于其表现力,50次演示不足以进行扩散:之前使用扩散策略的作品往往需要250次以上的演示。对于vinn+chunking,policy的整体表现不如act或diffusion,但仍然达到了合理的成功率,在push chair上为60%,在wipe wine上为15%。主要的故障模式是对lift glass和wipe的不精确抓握,以及在块之间切换时的剧烈运动。我们发现,在检索时增加本体感觉的权重可以提高平滑度,但代价是减少对视觉输入的关注。我们发现,联合培训可以提高扩散政策的绩效,擦拭酒和推椅分别提高30%和20%。这是意料之中的,因为联合训练有助于解决过拟合问题。与act和扩散政策不同,我们观察到vinn的结果喜忧参半,其中联合培训使wipe wine下降了5%,而push chair提高了20%。只有vinn的表示是共训练的,而vinn的动作预测机制没有办法利用域外静态aloha数据,这或许可以解释这些混合结果。
 7. Ablation Studies
7. Ablation Studies
数据效率。在图4中,我们在wipe wine任务上使用act,消除了联合训练和非联合训练的移动操作演示次数。我们考虑了25、35和50个移动aloha演示,并分别对20个试验进行了评估。我们观察到,与仅使用移动aloha数据的训练相比,联合训练可以提高数据效率并持续改进。通过联合训练,用35个领域内演示训练的policy可以比用50个领域内示范训练的无联合训练policy高出20%(70%对50%)。

联合训练对不同的数据混合具有鲁棒性。到目前为止,我们在共训练实验中以相等的概率从静态ALOHA数据集和移动ALOHA任务数据集中进行采样,形成一个训练小批量,共训练数据采样率约为50%。在表3中,我们研究了不同的采样策略如何影响Wipe Wine任务的性能。我们以30%和70%的联合训练数据采样率以及50%的采样率训练ACT,然后分别评估20个试验。我们看到了类似的表现,分别为95%、95%和90%的成功率。该实验表明,协同训练性能对不同的数据混合不敏感,从而减少了在新任务中结合协同训练时所需的手动调整。

联合训练优于预训练。在表4中,我们比较了静态ALOHA数据的联合训练和预训练。对于预训练,我们首先在静态ALOHA数据上训练ACT 10K步,然后用域内任务数据继续训练。我们对Wipe Wine任务进行了实验,并观察到预训练与仅在Wipe Wine数据上训练相比没有任何改善。我们假设网络在微调阶段忘记了对静态ALOHA数据的体验。

8. User Studies
我们进行了一项用户研究,以评估移动ALOHA遥操作的有效性。具体来说,我们衡量参与者学习远程操作看不见的任务的速度。我们在计算机科学研究生中招募了8名参与者,其中5名女性和3名男性,年龄在21-26岁之间。四名参与者之前没有遥操作经验,其余四名参与者的专业知识水平各不相同。他们之前都并没有使用过移动ALOHA。我们首先允许每个参与者与场景中的对象自由交互3分钟。在这个过程中,我们拿出了所有将用于看不见的任务的物体。接下来,我们给每个参与者两个任务:擦酒和使用橱柜。专家操作员将首先演示任务,然后由参与者进行5次连续试验。我们记录每个试验的完成时间,并将其绘制在图5中。我们注意到完成时间急剧下降:平均而言,执行任务所需的时间从46秒下降到28秒(下降39%),从75秒下降到36秒(下降52%)。平均参与者还可以在5次试验后接近专家演示的速度,展示移动ALOHA遥操作的易用性和学习性。
A.2. Example Image Observations
图7展示了在数据收集过程中捕获的Wipe Wine的示例图像。这些图像从上到下按时间顺序排列,来自从左到右列的三个不同的相机角度:顶部以自我为中心的相机、左手腕相机和右手腕相机。顶部摄像头相对于机器人框架是静止的。相比之下,手腕上的摄像头连接在手臂上,可以提供抓取器动作的特写视图。所有相机都设置了固定焦距,并具有自动曝光功能,以适应不同的光线条件。这些相机的分辨率为480×640,帧率为每秒30帧。
图8显示了回放300步(6s)演示结束时末端执行器误差的分布。演示包含一个半径约为1米的180度转弯。在轨迹结束时,右臂会伸出桌子上的一张纸,轻轻地敲击它。然后在纸上标记敲击位置。红叉表示原始轻击位置,红点是同一轨迹的20次回放。在重放基本速度剖面时,我们观察到明显的误差,这是由于地面接触和低级控制器的随机性造成的。具体来说,所有回放点都偏向左侧约10cm,并沿约20cm的线分布。我们发现我们的policy能够在没有slam等显式定位的情况下纠正这些错误。