一、Hudi框架概述
Apahe Hudi (Hadoop Upserts delete and Incrementals) 是Uber主导开发的开源数据湖框架,为了解决大数据生态系统中需要插入更新及增量消费原语的摄取管道和ETL管道的低效问题,该项目在2016年开始开发,并于2017年开源,2019年1月进入 Apache 孵化器,且2020年6月称为Apache 顶级项目
官网:Apache Hudi | An Open Source Data Lake Platform | Apache Hudi
一)数据湖Data Lake
数据湖是大数据架构的新范式,以原始格式存储数据,可以满足用户的广泛需求,并能提供更快的洞察力,细致的数据编录和管理是成功实施数据湖的关键。
仓库(WareHouse)是人为提前建造好的,有货架,还有过道,并且还可以进一步为放置到货架的物品指定位置。
1、什么是数据湖
数据湖(Data Lake)和数据库、数据仓库一样,都是数据存储的设计模式。数据库和数据仓库会以关系型的方式来设计存储、处理数据。但数据湖的设计理念是相反的,数据仓库是为了保障数据的质量、数据的一致性、数据的重用性等对数据进行结构化处理。
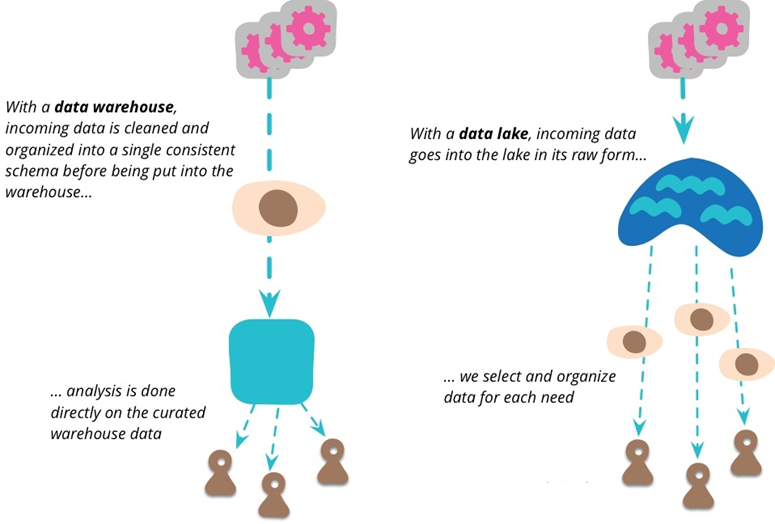
数据湖是一个数据存储库,可以使用数据湖来存储大量的原始数据。现在企业的数据仓库都会通过分层的方式将数据存储在文件夹、文件中,而数据湖使用的是平面架构来存储数据。我们需要做的只是给每个数据元素分配一个唯一的标识符,并通过元数据标签来进行标注。当企业中出现业务问题时,可以从数据湖中查询数据,然后分析业务对应的那一小部分数据集来解决业务问题
数据湖越来越多的用于描述任何的大型数据池,数据都是以原始数据方式存储,知道需要查询应用数据的时候才会开始分析数据需求和应用架构
数据湖是专注于原始数据保存以及低成本长期存储的存储设计模式,它相当于是对数据仓库的补充。数据湖是用于长期存储数据容器的集合,通过数据湖可以大规模的捕获、加工、探索任何形式的原始数据。通过使用一些低成本的技术,可以让下游设施可以更好地利用,下游设施包括像数据集市、数据仓库或者是机器学习模型。
数据湖(DataLake)是描述数据存储策略的方式,并不与具体的某个技术框架关联,与数据库、数据仓库也一样,它们都是数据的管理策略,数据湖最核心的能力包括:
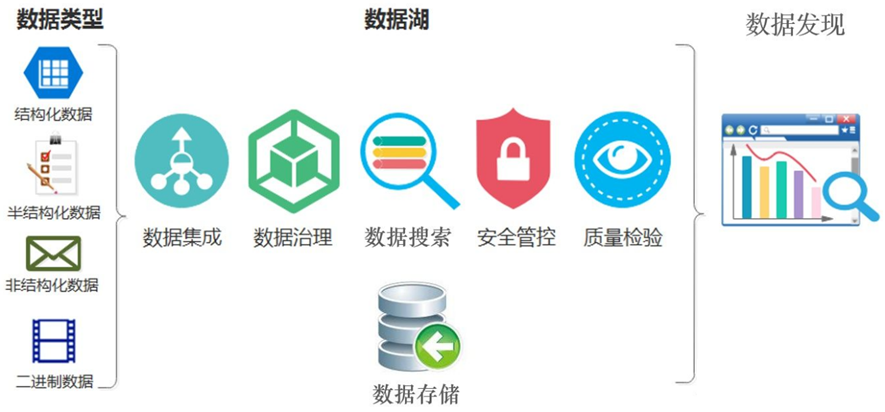
2、数据湖的优点
数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统。它按原样存储数据,而无需事先对数据进行结构化处理。一个数据湖可以存储结构化数据(如关系型数据库中的表),半结构化数据(如CSV、日志、XML、JSON),非结构化数据(如电子邮件、文档、PDF)和二进制数据(如图形、音频、视频)。数据湖有如下几个方面优点:
- 提供不限数据类型的存储;
- 开发人员和数据科学家可以快速动态建立数据模型、构建应用、查询数据,非常灵活;
- 因为数据湖没有固定的结构,所以更易于访问;
- 长期存储数据的成本低廉,数据湖可以安装在低成本的硬件在,例如:在一般的X86机器上部署Hadoop;
- 因为数据湖是非常灵活的,它允许使用多种不同的处理、分析方式来让数据发挥价值,例如:数据分析、实时分析、机器学习以及SQL查询都可以
3、Data Lake vs Data warehouse
数据湖和数据仓库是用于存储大数据的两种不同策略,最大区别是:数据仓库是提前设计好模式(schema)的,因为数据仓库中存储的都是结构化数据。而在数据湖中,不一定是这样的,数据湖中可以存储结构化和非结构化的数据,是无法预先定义好结构的。
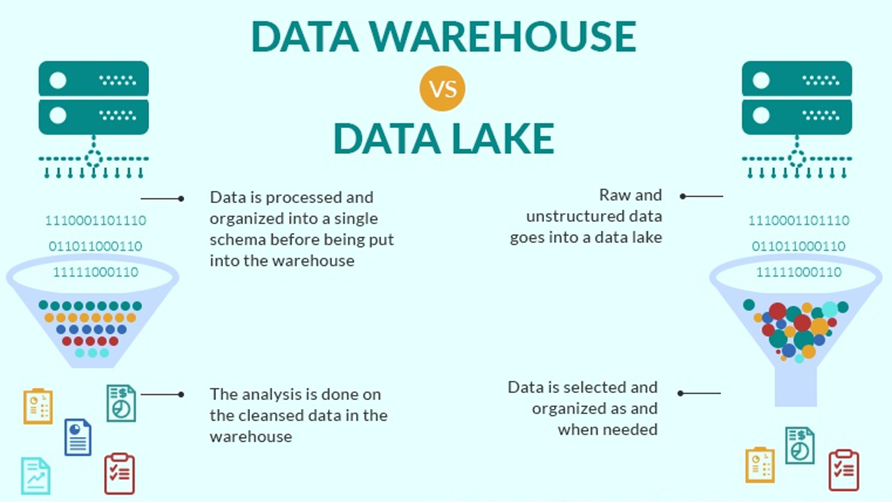
7个方面对比认识数据仓库和数据湖不同点
- 第一点:数据的存储位置不同
- 数据仓库因为是要有结构的,在企业中很多都是基于关系型模型;
- 数据湖通常位于分布式存储,例如Hadoop或者类似的大数据存储中;
- 第二点:数据源不同
- 数据仓库的数据来源很多时候来自于OLTP应用的结构化数据库中提取的,用于支持内部的业务部门(例如:销售、市场、运营等部门)进行业务分析;
- 数据湖的数据来源可以是结构化的、也可以是非结构化的,例如:业务系统数据库、 IOT设备、社交媒体、移动APP等;
- 第三点:用户不同
- 数据仓库主要是业务系统的大量业务数据进行统计分析,所以会应用数据分析的部门是数据仓库的主要用户,例如:销售部、市场部、运营部、总裁办等等。而当需要一个大型的存储,而当前没有明确的数据应用用户或者是目标,将来想要使用这些数据的人可以在使用时开始设计架构,此时,数据湖更适合;
- 数据湖中的数据都是原始数据,是未经整理的,这对于普通的用户几乎是不可用的。数据湖更适合数据科学家,因为数据科学家可以应用模型、技术发觉数据中的价值,去解决企业中的业务问题;
- 第四点:数据质量不同
- 数据仓库是非常重数据质量的,大家现在经常听说的数据中台,其中有一大块是数据质量管理、数据资产管理等。数据仓库中的数据都是经过处理的;
- 数据湖中的数据可靠性是较差的,这些数据可能是任意状态、形态的数据;
- 第五点:数据模式
- 数据仓库在数据写入之前就要定义好模式(schema),例如:会先建立模型、建立表结构,然后导入数据,可以把它称之为write-schema;
- 数据湖中的数据是没有模式的,直到有用户要访问数据、使用数据才会建立schema,可以把它称之为read-schema;
- 第六点:敏捷扩展性
- 数据仓库的模式一旦建立,要重新调整模式,往往代价很大,牵一发而动全身,所有相关的ETL程序可能都需要调整;
- 数据湖是非常灵活的,可以根据需要重新配置结构或者模式;
- 第七点:应用不同
- 数据仓库一般用于做批处理报告、BI、可视化;
- 数据湖主要用于机器学习、预测分析、数据探索和分析;
基于上述内容,可以了解到,数据湖和数据仓库的应用点是不一样的。它们是两种相对独立的数据设计模式。在一些企业中,可能会既有数据湖、又有数据仓库。数据湖并不是要替代数据仓库,而是对企业的数据管理模式进行补充;
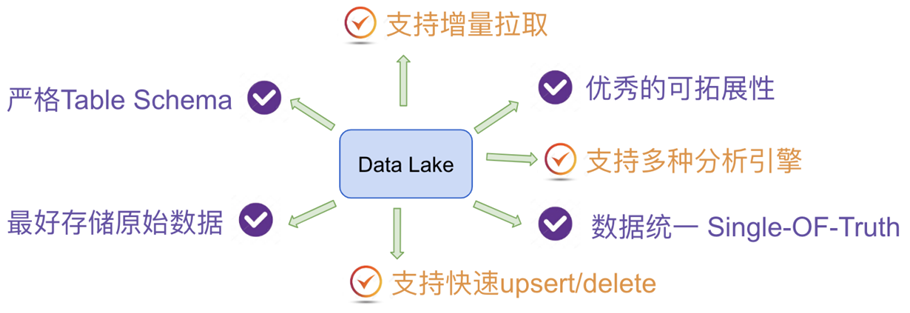
3、数据湖框架
Apache Hudi:提供的fast upsert/delete以及compaction等功能
- 官网:Apache Hudi | An Open Source Data Lake Platform | Apache Hudi
- Hudi 设计目标正如其名,Hadoop Upserts Deletes and Incrementals(原为 Hadoop Upserts anD Incrementals),强调其主要支持Upserts、Deletes和Incrementa数据处理,其主要提供的写入工具是 Spark HudiDataSource API 和自身提供的 DeltaStreamer。
- 支持三种数据写入方式:UPSERT,INSERT 和 BULK_INSERT。其对 Delete 的支持也是通过写入时指定一定的选项支持的,并不支持纯粹的 delete 接口。
4、湖仓一体(Data Lakehouse)
背景概述
Data Lakehouse(湖仓一体)是新出现的一种数据架构,它同时吸收了数据仓库和数据湖的优势,数据分析师和数据科学家可以在同一个数据存储中对数据进行操作,同时它也能为公司进行数据治理带来更多的便利性
- 数据仓库曾一直做为决策支持系统的支撑平台。数据仓库使用良好设计的模式规范数据,例如星形模型、雪花模型和正常范式等。数据仓库无法生成数据所需的洞察。
- Hadoop 生态系统迅速演进,进而出现了称为“数据湖”的非结构化数据存储和处理新范式。数据湖由于缺乏结构和治理,会迅速沦为“数据沼泽”。
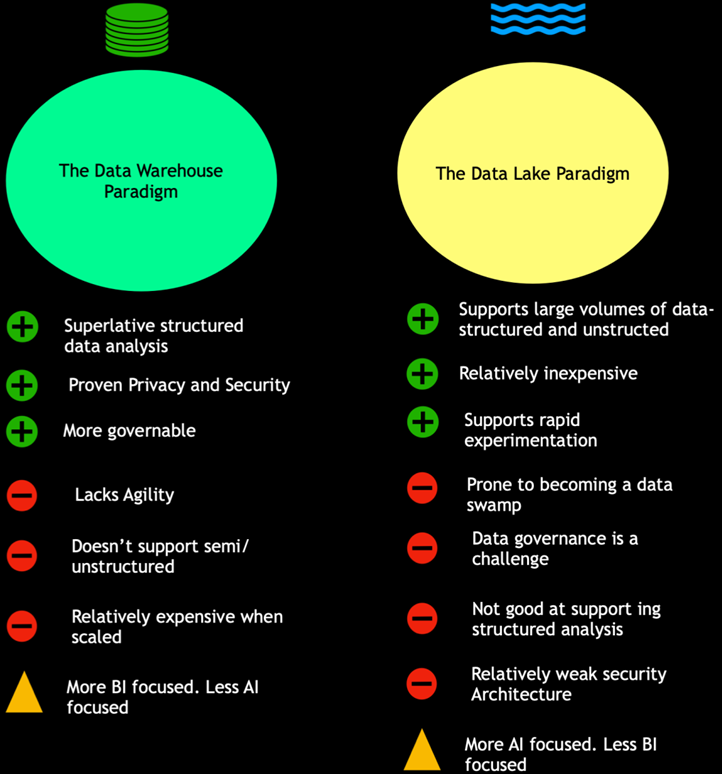
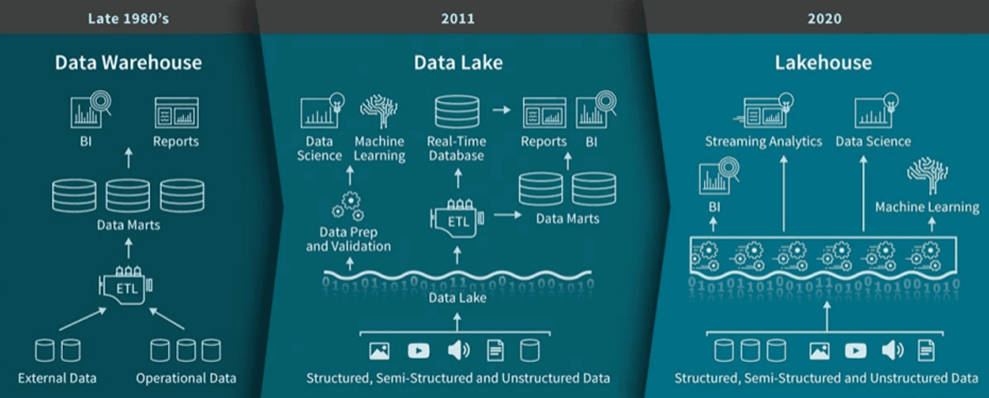
LakeHouse是一种结合了数据湖和数据仓库优势的新范式。LakeHouse使用新的系统设计:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能。如果你现在需要重新设计数据仓库,鉴于现在存储(以对象存储的形式)廉价且高可靠,不妨可以使用LakeHouse。
如下展示,从数据仓库DataWarehouse到数据湖DataLake,再到湖仓一体LakeHouse。
概念定义
湖仓一体架构力图结合数据仓库的弹性和数据湖的灵活性。人们创建数据仓库来支持商业智能,主要用例包括编制报表、发布下游数据集市(Data Marts),以及支持自助式商业智能等。数据湖的概念来自于数据科学对数据的探索,主要用例包括通过快速实验创建和检验假设,以及利用半结构化和非结构化数据等。
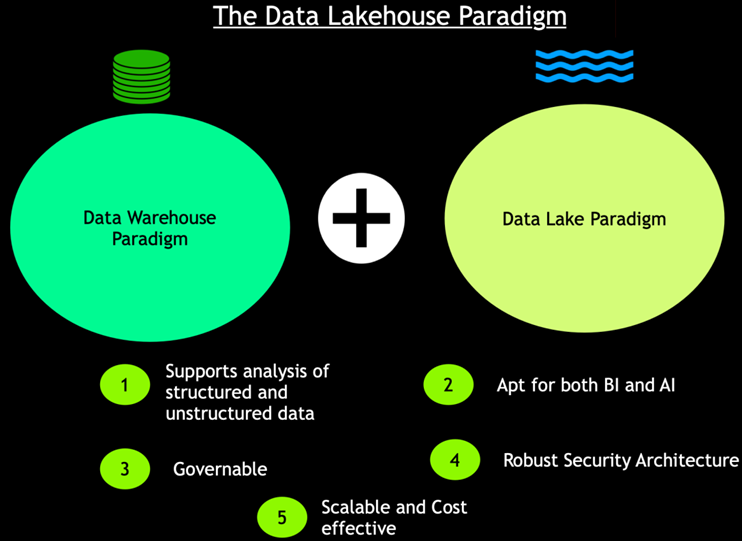
湖仓一体具有以下五个关键特性:
- 支持分析结构化和非结构化数据;
- 适用于分析师和数据科学家,不仅支持报表,而且支持机器学习和人工智能相关用例;
- 数据可治理,避免产生沼泽;
- 架构鲁棒安全,确保利益相关者能正确访问以数据为中心的安全架构;
- 以合理代价实现有效扩展。
架构原则
LakeHouse是一种新的数据管理范式,从根本上简化了企业数据基础架构,并且有望在机器学习已渗透到每个行业的时代加速创新。
LakeHouse的核心设计要素
- 可靠的湖上数据管理
- 支持机器学习与数据科学
- 高性能的SQL引擎
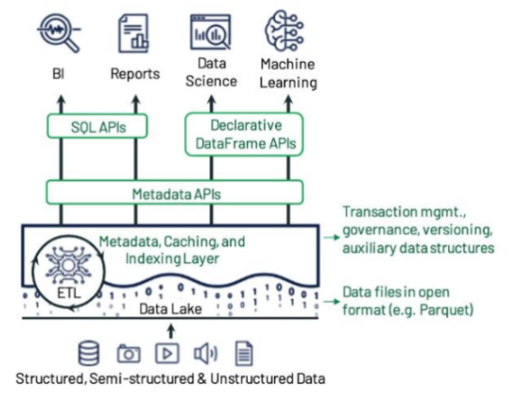
湖仓一体概念架构中,各核心组件通过有效的组织,形成了全新的湖仓一体范式。
l 支持结构化和非结构化数据。无论是类关系数据库那样静态存储,还是以实时数据流方式提供,数据均可转化为洞察。
l 数据抽取(Data ingestion)服务提供多种抽取方式,将数据抽取到数据湖中,既可以满足批处理需求,也可以满足流式加载需求。一条经验法则是,数据抽取中不做任何数据转换。
l 抽取的数据存储在数据湖的原始数据区域,该区域也称为“青铜层”(bronze layer)。数据依照源数据结构进行管理,实现源数据和下游分析的解耦。
l 数据处理(data processing)服务处理原始数据区域中的数据,执行清洗、归并、复杂业务逻辑等操作,并进一步准备好适用于人工智能、商业智能等下游分析的数据格式。
l 数据同时周期性地临时存放在已清洗数据区域,该区域也称为“白银层”(silver layer)。已清洗数据区域避免对数据重复做多次处理。处理完成的数据最终存储在已处理数据区域,该区域也称为“黄金层”(gold layer)。
l 数据都存储在数据湖中,可用于即席分析、机器学习和报表等多种用例。但数据湖不利于结构化报表或自助式商业智能,而数据仓库在此类需求上表现出色。这需要数据存储同时提供数据仓库能力。
l 数据编目(Data cataloging)服务确保所有源数据、数据湖和数据仓库中的数据、数据处理流水线管道以及从湖仓一体中抽取的输出都做了适当的编目,防止湖仓一体变成数据沼泽。
l 数据分析(Analytics)服务提供多种数据用途。数据科学家可创建分析沙箱,运行实验和假设测试。数据分析人员可创建沙箱,触发快速查询并对数据执行即席分析。人工智能和机器学习人员可运行和维护模型。商业智能为用户提供了具有丰富可视化效果的自助式商业智能。
建立真实有效湖仓一体架构,应遵循如下五个关键原则:
l 计算和存储的解耦:首要原则是加入解耦和存储。存储便宜且持久,计算昂贵且短暂。计算和存储的解耦,可使系统灵活地按需升级并扩展计算服务。
l 目标驱动的存储层:数据以多种形态和形式呈现,因此数据的存储方式应具灵活性,以适应数据的不同形态和用途。灵活性包括根据数据的种类及提供方式不同,提供关系层、图数据层、文档层以及 Blob 等多模态存储层。
l 模块化的体系架构:该原则源自于 SOA,确保数据处于核心地位,以围绕数据开展所需服务为关键。基于数据开展数据抽取、处理、编目和分析等不同类型的服务,而不是借助流水线将数据提供给服务。
l 聚焦于功能,而非技术:该原则体现了灵活性。功能的变化缓慢,但技术的变革日新月异。因此一定要聚焦于组件所完成的功能,进而可轻易追随技术的发展而替换旧技术。
l 活动编目(Active cataloging):该项基本原则是避免数据湖沦为数据沼泽的关键。编目上需具有明确的治理原则,有助于确保数据充分记录到数据湖中。
数据是复杂的,并且在不断地发展。业务也在迅速地变化,需求同样再不断地变化,架构必须具备能适应所有变化的灵活性,上述五个架构原则有助于建立切实有效的湖仓一体架构。
二)Hudi介绍
Hudi是Hadoop Upserts anD Incrementals的缩写,用于管理HDFS上的大型分析数据集存储。 Hudi的主要目的是高效的减少入库延时,Hudi是Uber开发的一个开源项目。存储于HDFS上的分析数据集一般通过两种类型的表来提供,即Copy-On-Write Table写时拷贝和Merge-On-Read Table读时合并。

Apache Hudi是在大数据存储上的一个数据集,可以将 Change Logs 通过 upsert 的方式合并进 Hudi;Hudi 对上可以暴露成一个普通的 Hive 或 Spark 的表,通过 API 或命令行可以获取到增量修改的信息,继续供下游消费;Hudi 还保管了修改历史,可以做时间旅行或回退;Hudi 内部有主键到文件级的索引,默认是记录到文件的布隆过滤器,高级的有存储到 HBase 索引提供更高的效率。
1、官方定义
Apache Hudi通过分布式文件系统(HDFS或者云存储)来摄取(Ingests)、管理(Manages)大型分析型数据集。Hudi是可以借助于DFS之上,提供了一些数据提取、管理功能。
一言以蔽之,Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
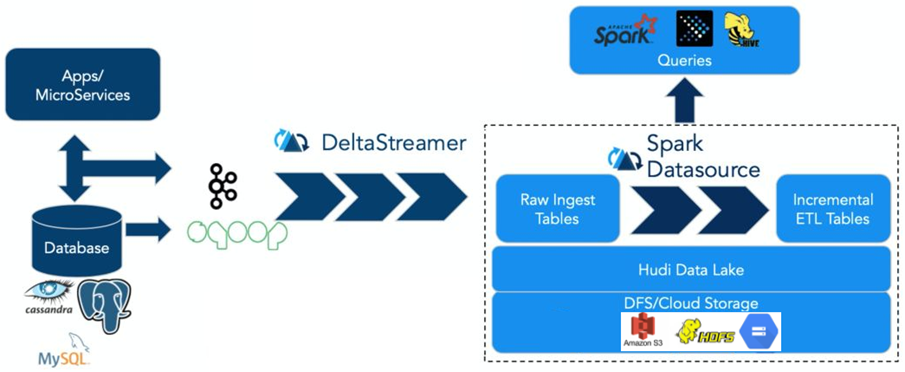
Hudi 数据湖的基础架构:
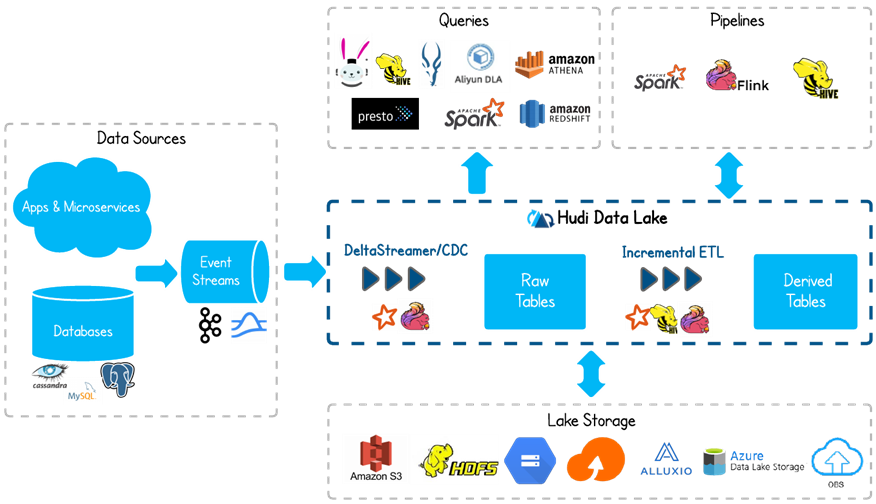
- 通过DeltaStreammer、Flink、Spark等工作,将数据摄取到数据湖的数据存储,例如:可以使用HDFS作为数据湖的数据存储;
- 基于HDFS可以构建Hudi的数据湖;
- Hudi提供统一的访问Spark数据源和Flink数据源;
- 外部通过不同引擎,例如:Spark、Flink、Presto、Hive、Impala、Aliyun DLA、AW
Redshit访问接口
下载地址:https://hudi.apache.org/download.html
2、Hudi特性
Apache Hudi使得用户能在Hadoop兼容的存储之上存储大量数据,同时它还提供两种原语,使得除了经典的批处理之外,还可以在数据湖上进行流处理。
这两种原语分别是:
- Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
- 变更流:Hudi对获取数据变更提供了一流的支持:可以从给定的时间点获取给定表中已updated/inserted/deleted的所有记录的增量流,并解锁新的查询姿势(类别)。
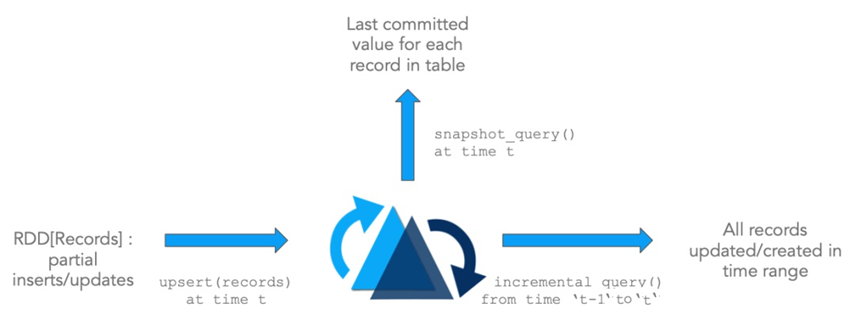
Hudi提供的功能特性如下:
第一、支持使用索引方式Upsert
Upsert support with fast, pluggable indexing
第二、可以原子性的发布数据并支持回滚
Atomically publish data with rollback support
第三、写入和查询使用快照进行隔离,保证数据的一致性
Snapshot isolation between writer & queries
第四、可以用Savepoint进行数据恢复
Savepoints for data recovery
第五、支持基于统计数据管理文件大小和分布
Manages file sizes, layout using statistics
第六、支持对基于行、列的数据进行异步压缩
Async compaction of row & columnar data
第七、支持时间轴元数据进行数据血统追踪
Timeline metadata to track lineage
利用聚类优化数据湖布局
Optimize data lake layout with clustering
可以说,Hudi支持了数据湖的数据存储以及一定的管理功能。
3、应用场景
Apache Hudi作为Uber开源的数据湖框架,抽象了存储层(支持数据集的变更,增量处理);为Spark的一个Lib(任意水平扩展,支持将数据存储至HDFS);开源(现已在Apache顶级项目)。
场景一:近实时摄取(Near Real-Time Ingestion)
- 对于RDBMS摄取,Hudi通过Upserts提供了更快的负载;
- 对于像Cassandra / Voldemort / HBase这样的NoSQL数据库,采用更有效的方法使得摄取速度与较频繁的更新数据量相匹配;
- 对于像Kafka这样的不可变数据源,Hudi也会强制在DFS上保持最小文件大小,从而解决Hadoop领域中的古老问题以便改善NameNode的运行状况。
- 对于所有数据源,Hudi都提供了通过提交将新数据原子化地发布给消费者,从而避免部分提取失败。
场景二:增量处理管道(Incremental Processing Pipelines)
- 通过记录粒度(而非文件夹或分区)来消费上游Hudi表HU中的新数据,下游的Hudi表HD应用处理逻辑并更新/协调延迟数据,这里HU和HD可以以更频繁的时间(例如15分钟)连续进行调度,并在HD上提供30分钟的端到端延迟。
场景三:统一存储分析(Unified Storage For Analytics)
- 将流式原始数据带到数据湖存储中,Hudi能够在几分钟内提取数据,并编写比传统批处理速度快几个数量级的增量数据管道,从而开辟了新的可能性。
- Hudi没有前期服务器基础设施投资,因此可以在不增加运营开销的情况下,对更新鲜的分析进行更快的分析。
场景四:数据删除(Data Deletion)
- Hudi还提供了删除存储在数据湖中的数据的功能,而且还提供了处理大型写放大的有效方法,该写放大是由于用户通过基于user_id(或任何辅助键)的Merge On Read表类型进行的随机删除而导致的。
- Hudi优雅的基于日志的并发控制,确保了提取/写入可以继续进行,因为后台压缩作业可分摊重写数据/强制执行删除的成本。
三)Hudi发展及特性
Apache Hudi代表Hadoop Upserts anD Incrementals,管理大型分析数据集在HDFS上的存储。Hudi的主要目的是高效减少摄取过程中的数据延迟。
1、Hudi发展历史
从2015年提出增量处理数据模型思想开始,到至今Hudi发展成熟,经历如下几个阶段:
- 2015 年:发表了增量处理的核心思想/原则(O'reilly 文章)
- 2016 年:由 Uber 创建并为所有数据库/关键业务提供支持
- 2017 年:由 Uber 开源,并支撑 100PB 数据湖
- 2018 年:吸引大量使用者,并因云计算普及
- 2019 年:成为 ASF 孵化项目,并增加更多平台组件
- 2020 年:毕业成为 Apache 顶级项目,社区、下载量、采用率增长超过 10 倍
- 2021 年:支持 Uber 500PB 数据湖,SQL DML、Flink 集成、索引、元服务器、缓存

国内大部分互联网公司都在使用Hudi数据湖框架,进行数据存储,管理数据。
二、体验Hudi
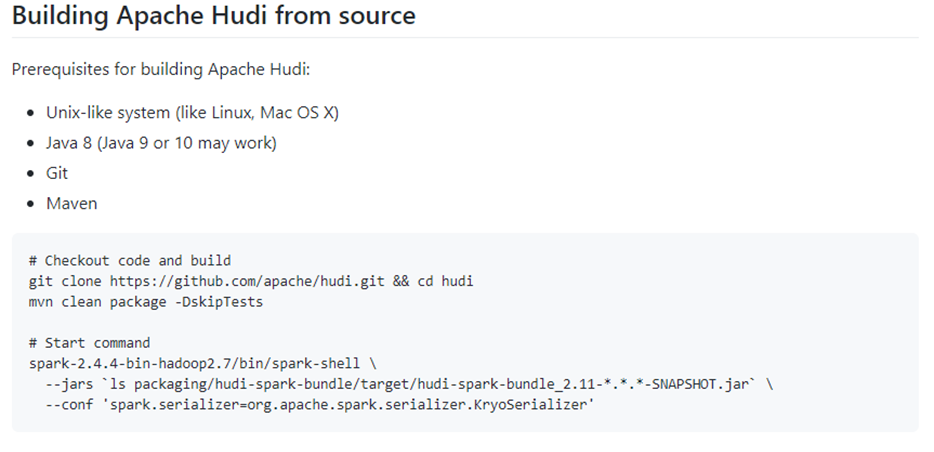
一)编译Hudi
Apache Hudi数据湖框架开发时添加MAVEN依赖即可,使用命令管理Hudi表数据,需要下载Hudi 源码包编译,操作步骤如下。
第一步、Maven 安装
操作上下载和安装Maven,直接将Maven软件包解压,然后配置系统环境变量即可。Maven版本为:3.5.4,仓库目录名称:m2,如下图所示:
配置Maven环境变量以后,执行:mvn -version

第二步、下载源码包
到Apache 软件归档目录下载Hudi 指定源码包:http://archive.apache.org/dist/hudi
wget https://archive.apache.org/dist/hudi/0.9.0/hudi-0.9.0.src.tgz
此外,也可以从Github上下载Hudi源码
https://github.com/apache/hudi
其中说明如何编译Hudi源码:
第三步、添加Maven镜像
由于Hudi编译时,需要下载相关依赖包,需要添加Maven镜像仓库路径,以便下载JAR包。
编辑$MAVEN_HOME/conf/settings.xml文件,添加如下镜像:
<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云spring插件仓库</name><url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror><id>repo2</id><name>Mirror from Maven Repo2</name><url>https://repo.spring.io/plugins-release/</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>UK</id><name>UK Central</name><url>http://uk.maven.org/maven2</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>jboss-public-repository-group</id><name>JBoss Public Repository Group</name><url>http://repository.jboss.org/nexus/content/groups/public</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>CN</id><name>OSChina Central</name><url>http://maven.oschina.net/content/groups/public/</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>google-maven-central</id><name>GCS Maven Central mirror Asia Pacific</name><url>https://maven-central-asia.storage-download.googleapis.com/maven2/</url><mirrorOf>central</mirrorOf>
</mirror>
<mirror><id>confluent</id><name>confluent maven</name><url>http://packages.confluent.io/maven/</url><mirrorOf>confluent</mirrorOf>
</mirror>
第四步、执行编译命令
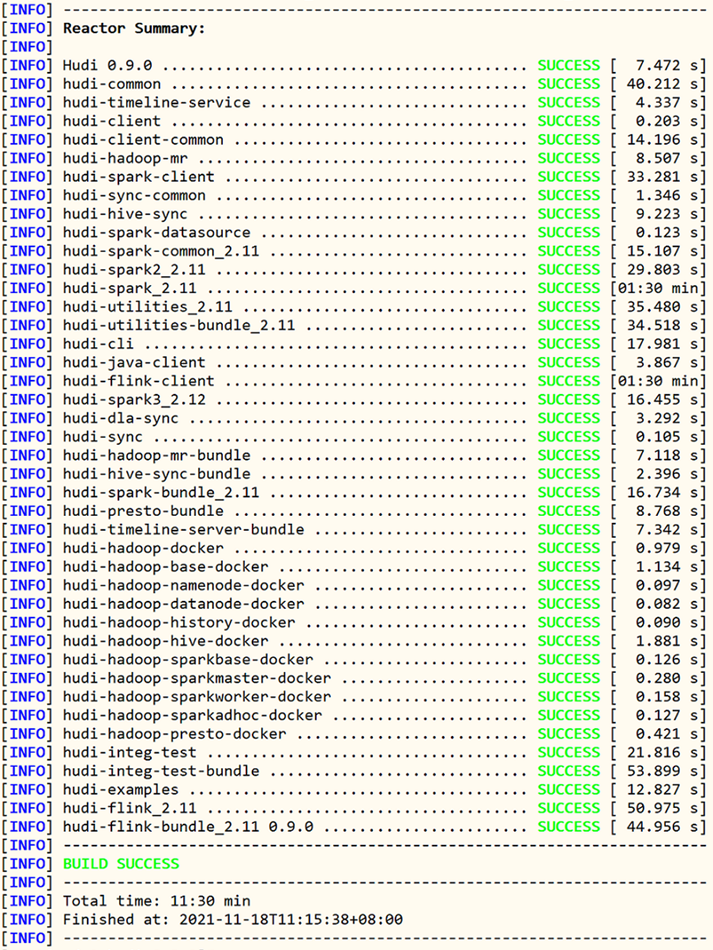
上传下载Hudi源码至CentOS系统目录:/root,解压tar包,进入软件包,执行编译命令:
]# mvn clean install -DskipTests -DskipITs -Dscala-2.12 -Dspark3

编译成功以后,截图如下所示:
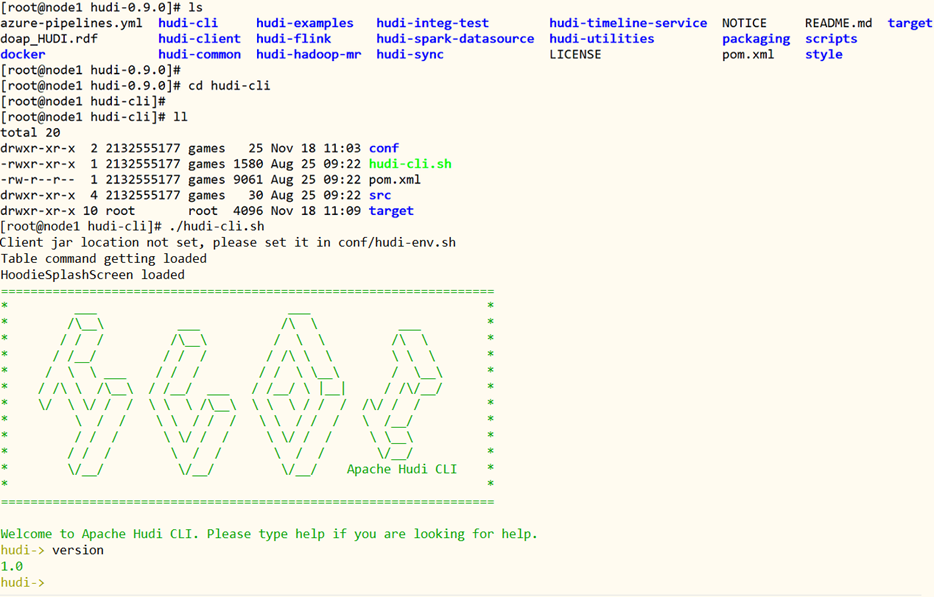
第五步、Hudi CLI测试
编译完成以后,进入$HUDI_HOME/hudi-cli目录,运行hudi-cli脚本,如果可以运行,说明编译成功
三、Hudi核心概念
Hudi数据湖框架的基本概念及表类型,属于Hudi框架设计原则和表的设计核心。
文档:https://hudi.apache.org/docs/concepts.html
一)基本概念
Hudi 提供了Hudi 表的概念,这些表支持CRUD操作,可以利用现有的大数据集群比如HDFS做数据文件存储,然后使用SparkSQL或Hive等分析引擎进行数据分析查询
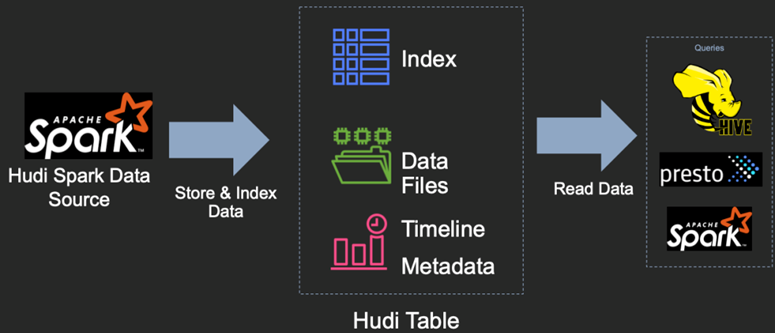
Hudi表的三个主要组件:
- 有序的时间轴元数据,类似于数据库事务日志。
- 分层布局的数据文件:实际写入表中的数据;
- 索引(多种实现方式):映射包含指定记录的数据集
1、时间轴Timeline
Hudi 核心是在所有的表中维护了一个包含在不同的即时(Instant)时间对数据集操作(比如新增、修改或删除)的时间轴(Timeline),在每一次对Hudi表的数据集操作时都会在该表的Timeline上生成一个Instant,从而可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据,有效避免了扫描更大时间范围的数据。同时,可以高效地只查询更改前的文件(如在某个Instant提交了更改操作后,仅query某个时间点之前的数据,则仍可以query修改前的数据)
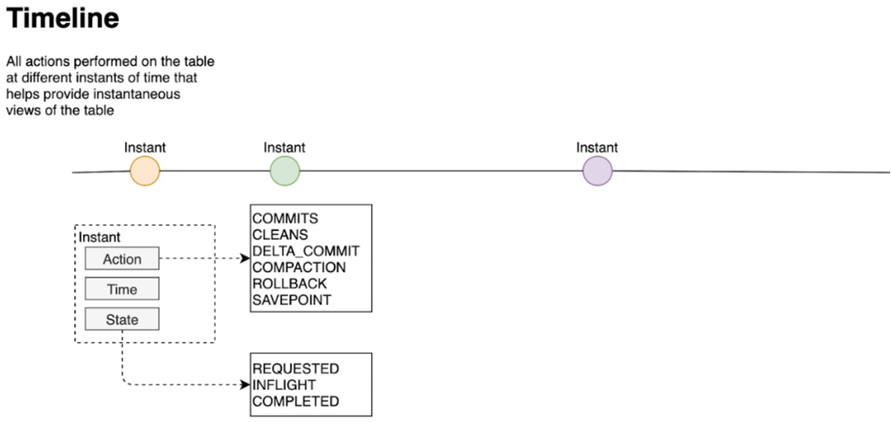
Timeline 是 Hudi 用来管理提交(commit)的抽象,每个 commit 都绑定一个固定时间戳,分散到时间线上。在 Timeline 上,每个 commit 被抽象为一个 HoodieInstant,一个 instant 记录了一次提交 (commit) 的行为、时间戳、和状态。HUDI 的读写 API 通过 Timeline 的接口可以方便的在 commits 上进行条件筛选,对 history 和 on-going 的 commits 应用各种策略,快速筛选出需要操作的目标 commit
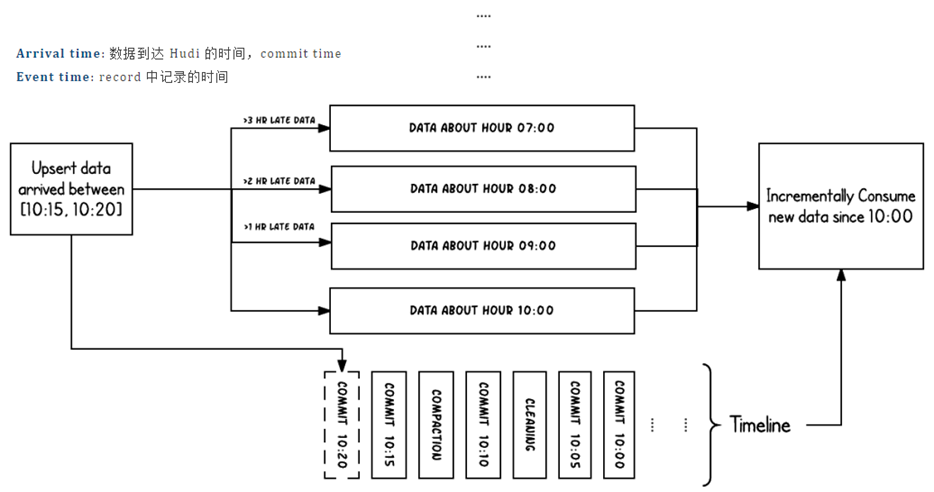
上图中采用时间(小时)作为分区字段,从 10:00 开始陆续产生各种 commits,10:20 来了一条 9:00 的数据,该数据仍然可以落到 9:00 对应的分区,通过 timeline 直接消费 10:00 之后的增量更新(只消费有新 commits 的 group),那么这条延迟的数据仍然可以被消费到。
时间轴(Timeline)的实现类(位于hudi-common-xx.jar中),时间轴相关的实现类位于org.apache.hudi.common.table.timeline包下
hudi的timeline(时间线组成)
1)、Instant action: 在表上执行的操作类型
2)、Instant time: 即时时间,通常是一个时间戳,它按照action的开始时间单调递增
3)、State: 时刻的当前状态
时间线上的Instant action操作类型
(hudi保证在时间线上的操作都是基于即时时间的,两者的时间保持一致并且是原子性的)
1)、commits: 表示将一批数据原子写入表中
2)、cleans: 清除表中不在需要的旧版本文件的后台活动。
3)、delta_commit:增量提交是指将一批数据原子性写入MergeOnRead类型的表中,其中部分或者所有数据可以写入增量日志中。
4)、compaction: 协调hudi中差异数据结构的后台活动,例如:将更新从基于行的日志文件变成列格式。在内部,压缩的表现为时间轴上的特殊提交。
5)、rollback:表示提交操作不成功且已经回滚,会删除在写入过程中产生的数据
6)、savepoint:将某些文件标记为“已保存”,以便清理程序时不会被清楚。在需要数据恢复的情况下,有助于将数据集还原到时间轴上某个点。
时间线上State状态类型
1)、requested:表示一个动作已被安排,但尚未启动
2)、inflight:表是当前正在执行操作
3)、completed:表是在时间线上完成了操作
2、文件管理
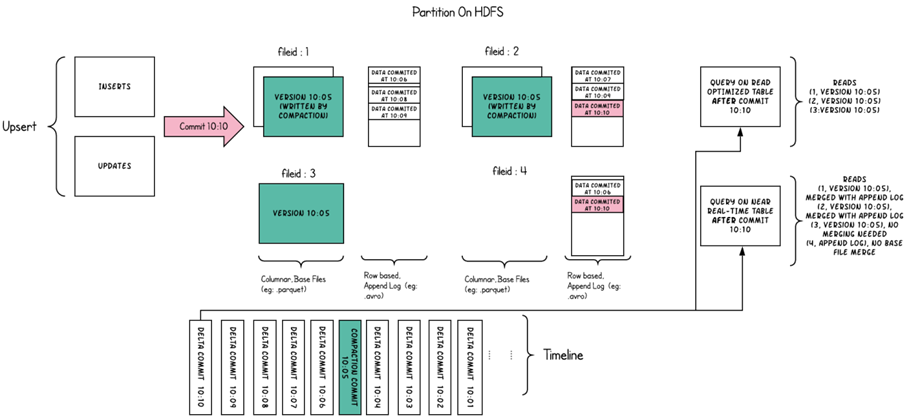
Hudi将DFS上的数据集组织到基本路径(HoodieWriteConfig.BASEPATHPROP)下的目录结构中。数据集分为多个分区(DataSourceOptions.PARTITIONPATHFIELDOPT_KEY),这些分区与Hive表非常相似,是包含该分区的数据文件的文件夹
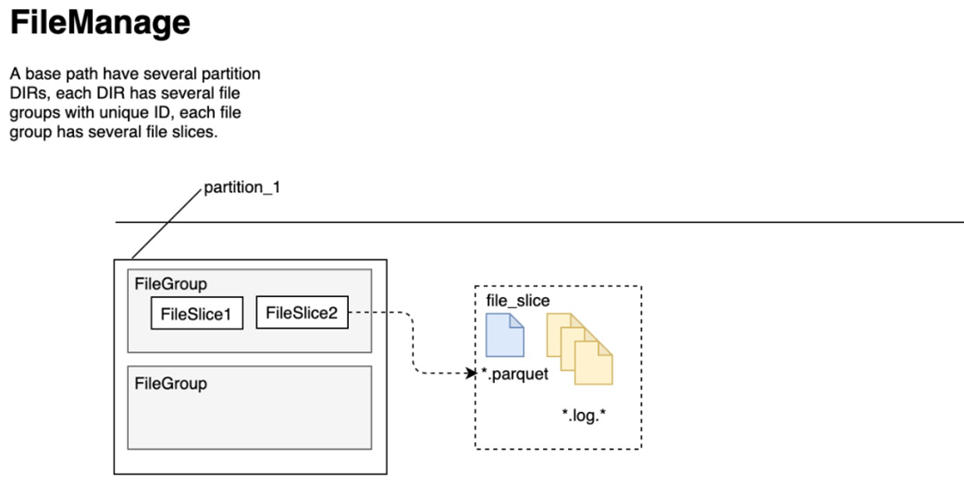
在每个分区内,文件被组织为文件组,由文件id充当唯一标识。每个文件组包含多个文件切片,其中每个切片包含在某个即时时间的提交/压缩生成的基本列文件(.parquet)以及一组日志文件(.log),该文件包含自生成基本文件以来对基本文件的插入/更新
l 一个新的 base commit time 对应一个新的 FileSlice,实际就是一个新的数据版本。
l Hudi 的每个 FileSlice 中包含一个 base file (merge on read 模式可能没有)和多个 log file (copy on write 模式没有)。
l 每个文件的文件名都带有其归属的 FileID(即 FileGroup Identifier)和 base commit time(即 InstanceTime)。通过文件名的 group id 组织 FileGroup 的 logical 关系;通过文件名的 base commit time 组织 FileSlice 的逻辑关系。
l Hudi 的 base file (parquet 文件) 在 footer 的 meta 去记录了 record key 组成的 BloomFilter,用于在 file based index 的实现中实现高效率的 key contains 检测。只有不在 BloomFilter 的 key 才需要扫描整个文件消灭假阳。
l Hudi 的 log (avro 文件)是自己编码的,通过积攒数据 buffer 以 LogBlock 为单位写出,每个 LogBlock 包含 magic number、size、content、footer 等信息,用于数据读、校验和过滤。
Hudi采用MVCC(多版本并发控制)设计,其中压缩操作将日志和基本文件合并以产生新的文件切片,而清理操作则将未使用的/较旧的文件片删除以回收DFS上的空间
表存储路径目录结构
hudi_trips_cow表在HDFS的存储组织(hudi表数据可以存储在hdfs分布式系统,也可以存储在本地)
- .hoodie 文件:由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。 .hoodie文件夹中存放了对应的文件合并操作相关的日志文件
- amricas和asia相关的路径是实际的数据文件,按分区存储,分区的路径key是可以指定的,数据文件使用Parquet文件格式存储,其中包含一个metadata元数据文件和数据文件
- .hoodie_partition_metadata 元数据:里面保存了commit的时间和分区深度信息
数据存储结构
Hudi数据集的目录结构与Hive表示非常相似,一份数据集对应这一个根目录。数据集被打散为多个分区,分区字段以文件夹形式存在,该文件夹包含该分区的所有文件
特点:在每个分区内,文件被组织为文件组,由文件id充当唯一标识。每个文件组包含多个文件切片,其中每个切片包含在某个即时时间的提交/压缩生成的基本列文件(.parquet)以及一组日志文件(.log),该文件包含自生成基本文件以来对基本文件的插入/更新
3、索引index
Hudi通过索引机制提供高效的Upsert操作,该机制会将一个RecordKey+PartitionPath组合的方式作为唯一标识映射到一个文件ID,而且,这个唯一标识和文件组/文件ID之间的映射自记录被写入文件组开始就不会再改变。
Hudi内置了4类(6个)索引实现,均是继承自顶层的抽象类HoodieIndex而来,如下注意:
l 全局索引:指在全表的所有分区范围下强制要求键保持唯一,即确保对给定的键有且只有一个对应的记录。全局索引提供了更强的保证,也使得更删的消耗随着表的大小增加而增加(O(表的大小)),更适用于是小表。
l 非全局索引:仅在表的某一个分区内强制要求键保持唯一,它依靠写入器为同一个记录的更删提供一致的分区路径,但由此同时大幅提高了效率,因为索引查询复杂度成了O(更删的记录数量)且可以很好地应对写入量的扩展。
Hoodie key (record key + partition path) 和 file id (FileGroup) 之间的映射关系,数据第一次写入文件后保持不变,所以,一个 FileGroup 包含了一批 record 的所有版本记录。Index 用于区分消息是 INSERT 还是 UPDATE。
l BloomFilter Index(布隆过滤器索引)
n 新增 records 找到映射关系:record key => target partition
n 当前最新的数据 找到映射关系:partition => (fileID, minRecordKey, maxRecordKey) LIST (如果是 base files 可加速)
n 新增 records 找到需要搜索的映射关系:fileID => HoodieKey(record key + partition path) LIST,key 是候选的 fileID
n 通过 HoodieKeyLookupHandle 查找目标文件(通过 BloomFilter 加速)
l Flink State-based Index(基于状态Index)
n HUDI 在 0.8.0 版本中实现的 Flink witer,采用了 Flink 的 state 作为底层的 index 存储,每个 records 在写入之前都会先计算目标 bucket ID,不同于 BloomFilter Index,避免了每次重复的文件 index 查找。
二)存储类型(表类型)
Hudi提供两类型表:写时复制(Copy on Write,COW)表和读时合并(Merge On Read,MOR)表,主要区别如下:
l 对于 Copy-On-Write Table,用户的 update 会重写数据所在的文件,所以是一个写放大很高,但是读放大为 0,适合写少读多的场景。
l 对于 Merge-On-Read Table,整体的结构有点像 LSM-Tree,用户的写入先写入到 delta data 中,这部分数据使用行存,这部分 delta data 可以手动 merge 到存量文件中,整理为 parquet 的列存结构。

Hudi 是 Uber 主导开发的开源数据湖框架,所以大部分的出发点都来源于 Uber 自身场景,比如司机数据和乘客数据通过订单 Id 来做 Join 等。在 Hudi 过去的使用场景里,和大部分公司的架构类似,采用批式和流式共存的 Lambda 架构,从延迟,数据完整度还有成本 三个方面来对比一下批式(Batch)和流式(Stream)计算模型的区别。
批式模型(Batch)
批式模型就是使用 MapReduce、Hive、Spark 等典型的批计算引擎,以小时任务或者天任务的形式来做数据计算。
l 延迟:小时级延迟或者天级别延迟。这里的延迟不单单指的是定时任务的时间,在数据架构里,这里的延迟时间通常是定时任务间隔时间 + 一系列依赖任务的计算时间 + 数据平台最终可以展示结果的时间。数据量大、逻辑复杂的情况下,小时任务计算的数据通常真正延迟的时间是 2-3 小时。
l 数据完整度:数据较完整。以处理时间为例,小时级别的任务,通常计算的原始数据已经包含了小时内的所有数据,所以得到的数据相对较完整。但如果业务需求是事件时间,这里涉及到终端的一些延迟上报机制,在这里,批式计算任务就很难派上用场。
l 成本:成本很低。只有在做任务计算时,才会占用资源,如果不做任务计算,可以将这部分批式计算资源出让给在线业务使用。但从另一个角度来说成本是挺高的,比如原始数据做了一些增删改查,数据晚到的情况,那么批式任务是要全量重新计算。
流式模型(Stream)
流式模型,典型的就是使用 Flink 来进行实时的数据计算。
l 延迟:很短,甚至是实时。
l 数据完整度:较差。因为流式引擎不会等到所有数据到齐之后再开始计算,所以有一个 watermark 的概念,当数据的时间小于 watermark 时,就会被丢弃,这样是无法对数据完整度有一个绝对的报障。在互联网场景中,流式模型主要用于活动时的数据大盘展示,对数据的完整度要求并不算很高。在大部分场景中,用户需要开发两个程序,一是流式数据生产流式结果,二是批式计算任务,用于次日修复实时结果。
l 成本:很高。因为流式任务是常驻的,并且对于多流 Join 的场景,通常要借助内存或者数据库来做 state 的存储,不管是序列化开销,还是和外部组件交互产生的额外 IO,在大数据量下都是不容忽视的。
增量模型(Incremental)
针对批式和流式的优缺点,Uber 提出了增量模型(Incremental Mode),相对批式来讲,更加实时;相对流式而言,更加经济。
增量模型,简单来讲,是以 mini batch 的形式来跑准实时任务。Hudi 在增量模型中支持了两个最重要的特性:
l Upsert:这个主要是解决批式模型中,数据不能插入、更新的问题,有了这个特性,可以往 Hive 中写入增量数据,而不是每次进行完全的覆盖。(Hudi 自身维护了 key->file 的映射,所以当 upsert 时很容易找到 key 对应的文件)
l Incremental Query:增量查询,减少计算的原始数据量。以 Uber 中司机和乘客的数据流 Join 为例,每次抓取两条数据流中的增量数据进行批式的 Join 即可,相比流式数据而言,成本要降低几个数量级。
在增量模型中,Hudi 提供了两种 Table,分别为 Copy-On-Write和 Merge-On-Read两种
2、查询类型(Query Type)
Hudi能够支持三种不同的查询表的方式(Snapshot Queries、Incremental Queries和Read Optimized Queries),具体取决于表的类型。
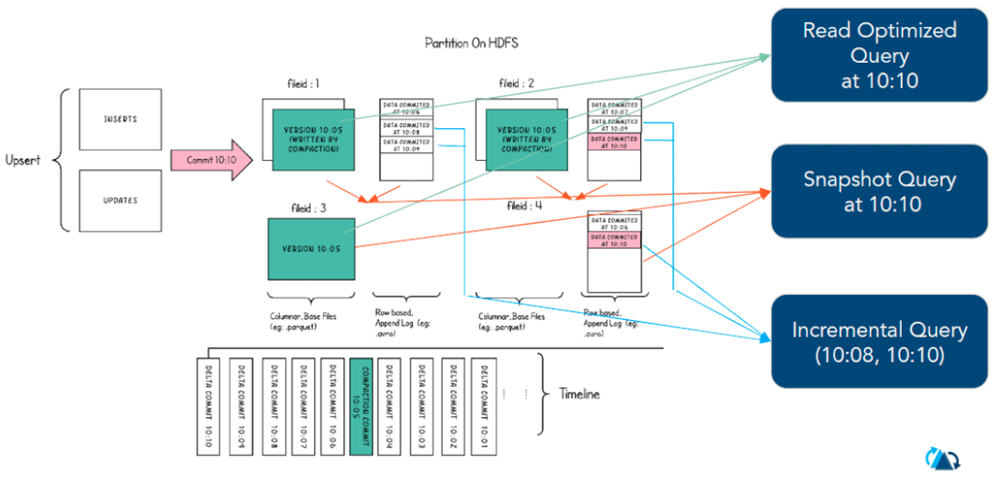
l 类型一:Snapshot Queries(快照查询)
n 查询某个增量提交操作中数据集的最新快照,会先进行动态合并最新的基本文件(Parquet)和增量文件(Avro)来提供近实时数据集(通常会存在几分钟的延迟)。
n 读取所有 partiiton 下每个 FileGroup 最新的 FileSlice 中的文件,Copy On Write 表读 parquet 文件,Merge On Read 表读 parquet + log 文件
l 类型二:Incremental Queries(增量查询)
n 仅查询新写入数据集的文件,需要指定一个Commit/Compaction的即时时间(位于Timeline上的某个Instant)作为条件,来查询此条件之后的新数据。
n 可查看自给定commit/delta commit即时操作以来新写入的数据。有效的提供变更流来启用增量数据管道。
l 类型三:Read Optimized Queries(读优化查询)
n 直接查询基本文件(数据集的最新快照),其实就是列式文件(Parquet)。并保证与非Hudi列式数据集相比,具有相同的列式查询性能。
n 可查看给定的commit/compact即时操作的表的最新快照。
读优化查询和快照查询相同仅访问基本文件,提供给定文件片自上次执行压缩操作以来的数据。通常查询数据的最新程度的保证取决于压缩策略
3、Copy On Write
简称COW,顾名思义,它是在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。正在读数据的请求,读取的是最近的完整副本,这类似Mysql 的MVCC的思想。
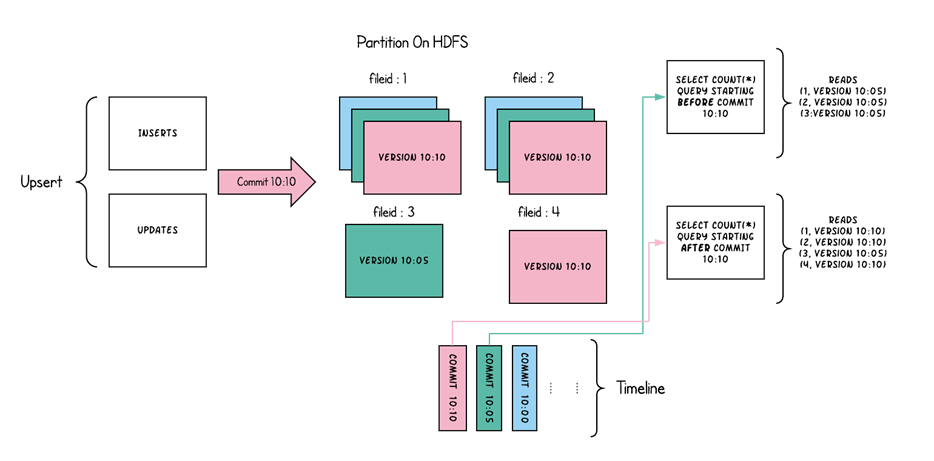
上图中,每一个颜色都包含了截至到其所在时间的所有数据。老的数据副本在超过一定的个数限制后,将被删除。这种类型的表,没有compact instant,因为写入时相当于已经compact了。
l 优点:读取时,只读取对应分区的一个数据文件即可,较为高效;
l 缺点:数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。由于耗时,读请求读取到的数据相对就会滞后;
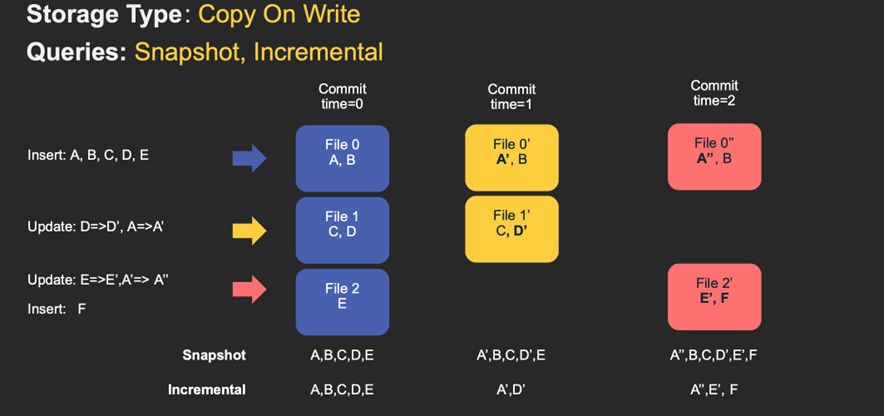
对于这种 Table,提供了两种查询:
l Snapshot Query: 查询最近一次 snapshot 的数据,也就是最新的数据。
l Incrementabl Query:用户需要指定一个 commit time,然后 Hudi 会扫描文件中的记录,过滤出 commit_time > 用户指定的 commit time 的记录。
COW表主要使用列式文件格式(Parquet)存储数据,在写入数据过程中,执行同步合并,更新数据版本并重写数据文件,类似RDBMS中的B-Tree更新。
l 1)、更新update:在更新记录时,Hudi会先找到包含更新数据的文件,然后再使用更新值(最新的数据)重写该文件,包含其他记录的文件保持不变。当突然有大量写操作时会导致重写大量文件,从而导致极大的I/O开销。
l 2)、读取read:在读取数据集时,通过读取最新的数据文件来获取最新的更新,此存储类型适用于少量写入和大量读取的场景。
Copy On Write 类型表每次写入都会生成一个新的持有 base file(对应写入的 instant time) 的 FileSlice。用户在 snapshot 读取的时候会扫描所有最新的 FileSlice 下的 base file
4、Merge On Read
简称MOR,新插入的数据存储在delta log 中,定期再将delta log合并进行parquet数据文件。读取数据时,会将delta log跟老的数据文件做merge,得到完整的数据返回。下图演示了MOR的两种数据读写方式。
MOR表也可以像COW表一样,忽略delta log,只读取最近的完整数据文件。
l 优点:由于写入数据先写delta log,且delta log较小,所以写入成本较低;
l 缺点:需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log 和 老数据文件合并;
对于这类 Table,提供了三种查询:
l Snapshot Query: 查询最近一次 snapshot 的数据,也就是最新的数据。这里是一个行列数据混合的查询。
l Incrementabl Query:用户需要指定一个 commit time,然后 Hudi 会扫描文件中的记录,过滤出 commit_time > 用户指定的 commit time 的记录。这里是一个行列数据混合的查询。
l Read Optimized Query: 只查存量数据,不查增量数据,因为使用的都是列式文件格式,所以效率较高。
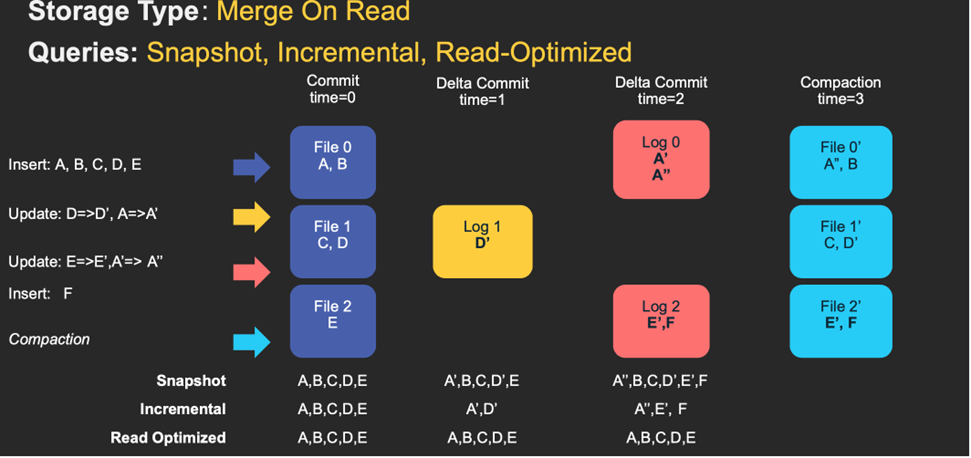
MOR表是COW表的升级版,它使用列式(parquet)与行式(avro)文件混合的方式存储数据。在更新记录时,类似NoSQL中的LSM-Tree更新。
l 1) 更新:在更新记录时,仅更新到增量文件(Avro)中,然后进行异步(或同步)的compaction,最后创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以追加的模式写入增量文件中。
l 2) 读取:在读取数据集时,需要先将增量文件与旧文件进行合并,然后生成列式文件成功后,再进行查询。
5、COW和MOR对比
对于写时复制(COW)和读时合并(MOR)writer来说,Hudi的WriteClient是相同的。
l COW表,用户在 snapshot 读取的时候会扫描所有最新的 FileSlice 下的 base file。
l MOR表,在 READ OPTIMIZED 模式下,只会读最近的经过 compaction 的 commit。
| 权衡 | CopyOnWrite | MergeOnRead |
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |
| Update(I/O)更新成本 | 高(重写整个Parquet文件) | 低(追加到增量日志) |
| Parquet File Size | 低(更新成本I/O高) | 较大(低更新成本) |
| Write Amplification(WA写入放大) | 大 | 低(取决于压缩策略) |
三)数据写操作流程
在Hudi数据湖框架中支持三种方式写入数据:UPSERT(插入更新)、INSERT(插入)和BULK INSERT(写排序)。
l UPSERT:默认行为,数据先通过 index 打标(INSERT/UPDATE),有一些启发式算法决定消息的组织以优化文件的大小
l INSERT:跳过 index,写入效率更高
l BULK_INSERT:写排序,对大数据量的 Hudi 表初始化友好,对文件大小的限制 best effort(写 HFile)
1、UPSERT 写流程
Copy On Write
l 第一步、先对 records 按照 record key 去重;
l 第二步、首先对这批数据创建索引 (HoodieKey => HoodieRecordLocation);通过索引区分哪些 records 是 update,哪些 records 是 insert(key 第一次写入);
l 第三步、对于 update 消息,会直接找到对应 key 所在的最新 FileSlice 的 base 文件,并做 merge 后写新的 base file (新的 FileSlice);
l 第四步、对于 insert 消息,会扫描当前 partition 的所有 SmallFile(小于一定大小的 base file),然后 merge 写新的 FileSlice;如果没有 SmallFile,直接写新的 FileGroup + FileSlice;
Merge On Read
l 第一步、先对 records 按照 record key 去重(可选)
l 第二步、首先对这批数据创建索引 (HoodieKey => HoodieRecordLocation);通过索引区分哪些 records 是 update,哪些 records 是 insert(key 第一次写入)
l 第三步、如果是 insert 消息,如果 log file 不可建索引(默认),会尝试 merge 分区内最小的 base file (不包含 log file 的 FileSlice),生成新的 FileSlice;如果没有 base file 就新写一个 FileGroup + FileSlice + base file;如果 log file 可建索引,尝试 append 小的 log file,如果没有就新写一个 FileGroup + FileSlice + base file
l 第四步、如果是 update 消息,写对应的 file group + file slice,直接 append 最新的 log file(如果碰巧是当前最小的小文件,会 merge base file,生成新的 file slice)log file 大小达到阈值会 roll over 一个新的
2、INSERT 写流程
同样由于Hudi中表的类型分为:COW和MOR,所以INSERT写入数据时,流程也是有区别的。Copy On Write
l 第一步、先对 records 按照 record key 去重(可选);
l 第二步、不会创建 Index;
l 第三步、如果有小的 base file 文件,merge base file,生成新的 FileSlice + base file,否则直接写新的 FileSlice + base file;
Merge On Read
l 第一步、先对 records 按照 record key 去重(可选);
l 第二步、不会创建 Index;
l 第三步、如果 log file 可索引,并且有小的 FileSlice,尝试追加或写最新的 log file;如果 log file 不可索引,写一个新的 FileSlice + base file;
三、Hudi CDC
CDC的全称是Change data Capture,即变更数据捕获,主要面向数据库的变更,是是数据库领域非常常见的技术,主要用于捕获数据库的一些变更,然后可以把变更数据发送到下游。
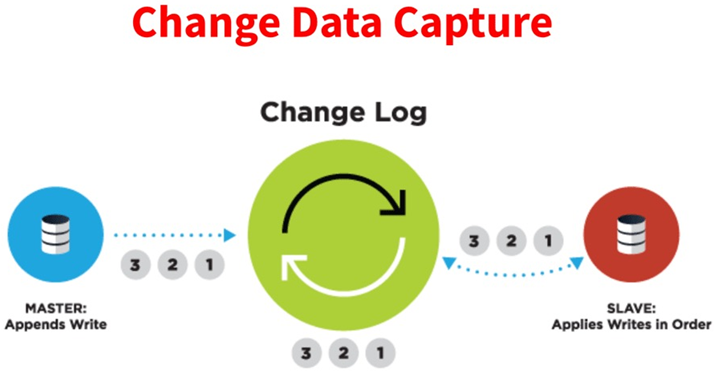
对于CDC,业界主要有两种类型:
一是基于查询的,客户端会通过SQL方式查询源库表变更数据,然后对外发送。
二是基于日志,这也是业界广泛使用的一种方式,一般是通过binlog方式,变更的记录会写入binlog,解析binlog后会写入消息系统,或直接基于Flink CDC进行处理
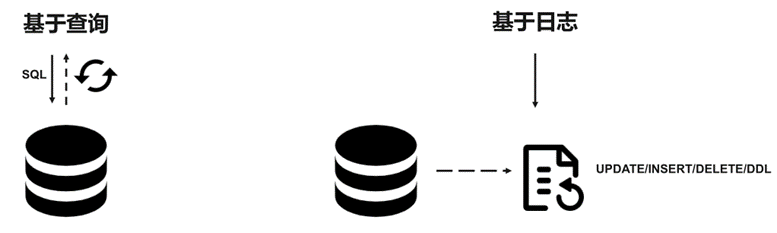
l 基于查询:这种 CDC 技术是入侵式的,需要在数据源执行 SQL 语句。使用这种技术实现CDC 会影响数据源的性能。通常需要扫描包含大量记录的整个表。
l 基于日志:这种 CDC 技术是非侵入性的,不需要在数据源执行 SQL 语句。通过读取源数据库的日志文件以识别对源库表的创建、修改或删除数据。
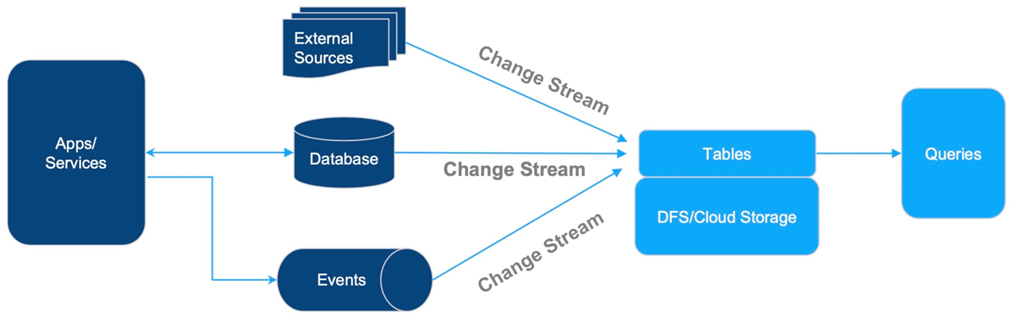
一)CDC入湖
基于CDC数据的入湖,这个架构非常简单:上游各种各样的数据源,比如DB的变更数据、事件流,以及各种外部数据源,都可以通过变更流的方式写入表中,再进行外部的查询分析。
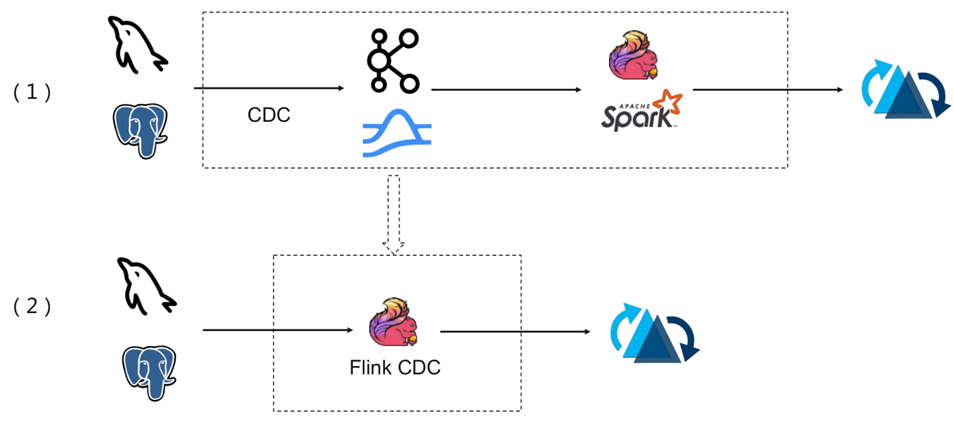
典型CDC入湖的链路:
- 上面的链路是大部分公司采取的链路,前面CDC的数据先通过CDC工具导入Kafka或者Pulsar,再通过Flink或者是Spark流式消费写到Hudi里。
- 第二个架构是通过Flink CDC直联到MySQL上游数据源,直接写到下游Hudi表。
二)Flink CDC Hudi
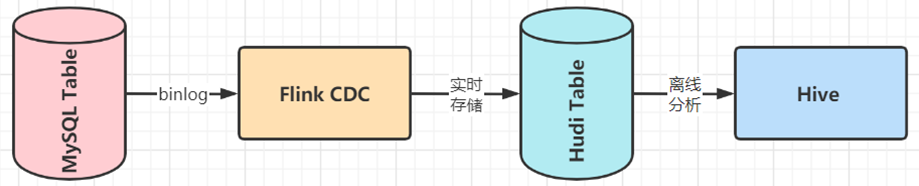
基于Flink CDC技术,实时采集MySQL数据库表数据,进行过ETL转换处理,最终存储Hudi表。
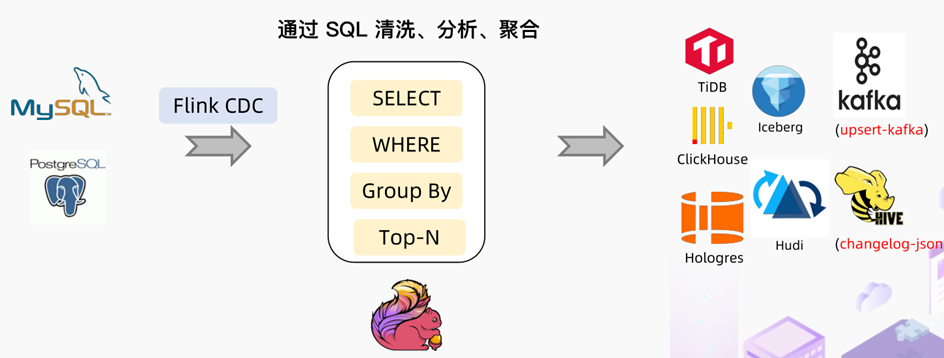
1、业务需求
MySQL数据库创建表,实时添加数据,通过Flink CDC将数据写入Hudi表,并且Hudi与Hive集成,自动在Hive中创建表与添加分区信息,最后Hive终端Beeline查询分析数据
Hudi 表与Hive表,自动关联集成,需要重新编译Hudi源码,指定Hive版本及编译时包含Hive依赖jar包,具体步骤如下。
l 修改Hudi集成flink和Hive编译依赖版本配置
原因:现在版本Hudi,在编译的时候本身默认已经集成的flink-SQL-connector-hive的包,会和Flink lib包下的flink-SQL-connector-hive冲突。所以,编译的过程中只修改hive编译版本。
文件:hudi-0.9.0/packaging/hudi-flink-bundle/pom.xml

l 编译Hudi源码
mvn clean install -DskipTests -Drat.skip=true -Dscala-2.12 -Dspark3 -Pflink-bundle-shade-hive2
编译完成以后,有2个jar包,至关重要:
n hudi-flink-bundle_2.12-0.9.0.jar,位于hudi-0.9.0/packaging/hudi-flink-bundle/target,flink 用来写入和读取数据,将其拷贝至$FLINK_HOME/lib目录中,如果以前有同名jar包,先删除再拷贝。
n hudi-hadoop-mr-bundle-0.9.0.jar,位于hudi-0.9.0/packaging/hudi-hadoop-mr-bundle/target,hive 需要用来读hudi数据,将其拷贝至$HIVE_HOME/lib目录中。
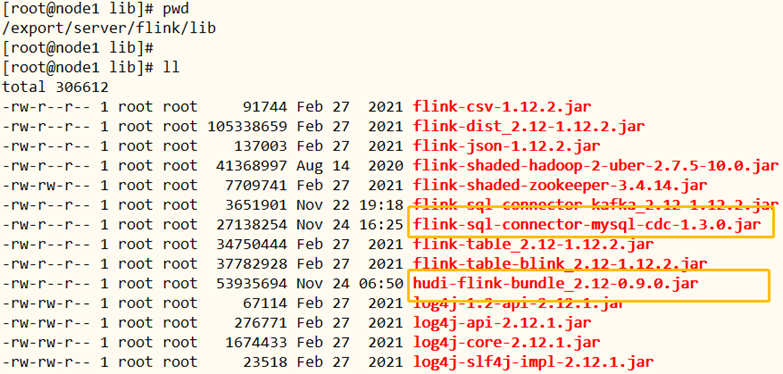
l 将Flink CDC MySQL对应jar包,放到$FLINK_HOME/lib目录中
flink-sql-connector-mysql-cdc-1.3.0.jar 至此,$FLINK_HOME/lib目录中,有如下所需的jar包,缺一不可,注意版本号
2、创建MySQL表
首先开启MySQL数据库binlog日志,再重启MySQL数据库服务,最后创建表。- 第一步、开启MySQL binlog日志
]# vim /etc/my.cnf
在[mysqld]下面添加内容:
server-id=2
log-bin=mysql-bin
binlog_format=row
expire_logs_days=15
binlog_row_image=full
- 第二步、重启MySQL Server
service mysqld restart 登录MySQL Client命令行,查看是否生效。
show master logs;
- 第三步、在MySQL数据库,创建表
-- MySQL 数据库创建表
create database test ;
create table test.tbl_users(id bigint auto_increment primary key,name varchar(20) null,birthday timestamp default CURRENT_TIMESTAMP not null,ts timestamp default CURRENT_TIMESTAMP not null
); 查看表结构
desc test.tb1_users;
3、创建CDC表
先启动HDFS服务、Hive MetaStore和HiveServer2服务和Flink Standalone集群,再运行SQL Client,最后创建表关联MySQL表,采用MySQL CDC方式。
启动HDFS服务,分别启动NameNode和DataNode
-- 启动HDFS服务
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
启动Hive服务:元数据MetaStore和HiveServer2
-- Hive服务
/export/server/hive/bin/start-metastore.sh
/export/server/hive/bin/start-hiveserver2.sh
启动Flink Standalone集群
-- 启动Flink Standalone集群
export HADOOP_CLASSPATH=`/export/server/hadoop/bin/hadoop classpath`
/export/server/flink/bin/start-cluster.sh
启动SQL Client客户端
/export/server/flink/bin/sql-client.sh embedded -j /export/server/flink/lib/hudi-flink-bundle_2.12-0.9.0.jar shell
设置属性
set execution.result-mode=tableau;
set execution.checkpointing.interval=3sec;
创建输入表,关联MySQL表,采用MySQL CDC 关联
-- Flink SQL Client创建表
CREATE TABLE users_source_mysql (id BIGINT PRIMARY KEY NOT ENFORCED,name STRING,birthday TIMESTAMP(3),ts TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'node1.itcast.cn',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'server-time-zone' = 'Asia/Shanghai',
'debezium.snapshot.mode' = 'initial',
'database-name' = 'test',
'table-name' = 'tbl_users'
);
查询表的结构,其中id为主键,ts为数据合并字段。

查询CDC表数据
-- 查询数据
select * from users_source_mysql;
开启MySQL Client客户端,执行DML语句,插入数据
insert into test.tbl_users (name) values ('zhangsan')
insert into test.tbl_users (name) values ('lisi');
insert into test.tbl_users (name) values ('wangwu');
insert into test.tbl_users (name) values ('laoda');
insert into test.tbl_users (name) values ('laoer');
4、创建视图
创建一个临时视图,增加分区列part,方便后续同步hive分区表
-- 创建一个临时视图,增加分区列 方便后续同步hive分区表
create view view_users_cdc
AS
SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') as part FROM users_source_mysql;
查看视图view中数据
select * from view_users_cdc;
5、创建Hudi表
创建 CDC Hudi Sink表,并自动同步hive分区表,具体DDL语句。
CREATE TABLE users_sink_hudi_hive(
id bigint ,
name string,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
part VARCHAR(20),
primary key(id) not enforced
)
PARTITIONED BY (part)
with(
'connector'='hudi',
'path'= 'hdfs://node1.itcast.cn:8020/users_sink_hudi_hive',
'table.type'= 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field'= 'id',
'write.precombine.field'= 'ts',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true',
'hive_sync.mode'= 'hms',
'hive_sync.metastore.uris'= 'thrift://node1.devops.cn:9083',
'hive_sync.jdbc_url'= 'jdbc:hive2://node1.devops.cn:10000',
'hive_sync.table'= 'users_sink_hudi_hive',
'hive_sync.db'= 'default',
'hive_sync.username'= 'root',
'hive_sync.password'= '123456',
'hive_sync.support_timestamp'= 'true'
); 此处Hudi表类型:MOR,Merge on Read (读时合并),快照查询+增量查询+读取优化查询(近实时)。使用列式存储(parquet)+行式文件(arvo)组合存储数据。更新记录到增量文件中,然后进行同步或异步压缩来生成新版本的列式文件。
查看表结构
6、数据写入Hudi表
编写INSERT语句,从视图中查询数据,再写入Hudi表中,语句如下
insert into users_sink_hudi_hive select id, name, birthday, ts, part from view_users_cdc;
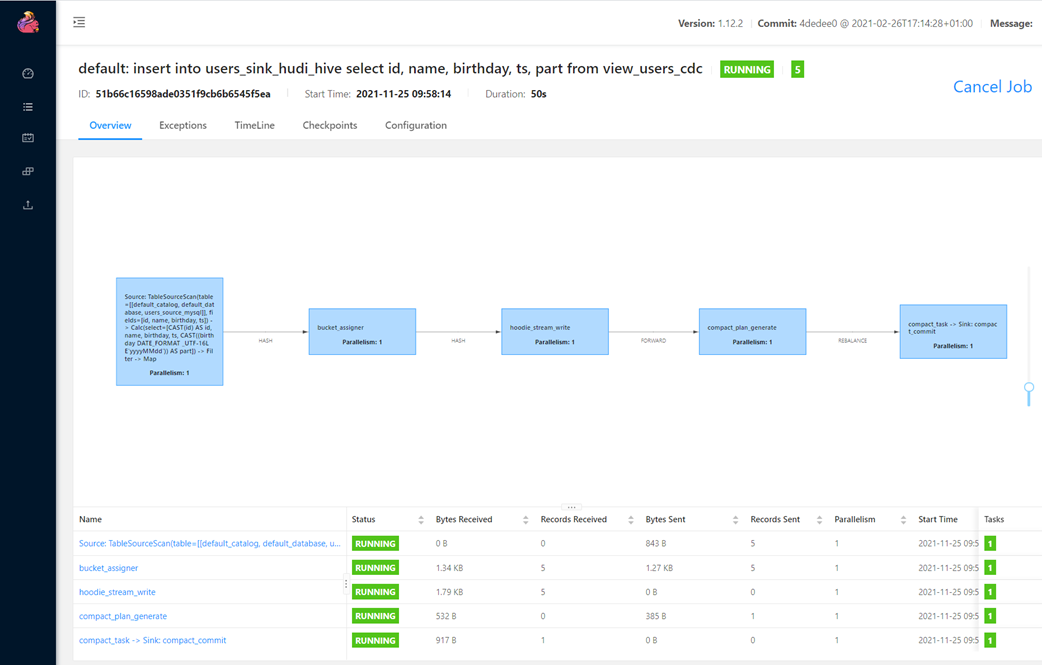
HDFS上Hudi文件目录情况:50070
Flink上执行SQL
select * from users_sink_hudi_hive;
7、Hive表查询
需要引入hudi-hadoop-mr-bundle-0.9.0.jar包,放到$HIVE_HOME/lib下。

启动Hive中beeline客户端,连接HiveServer2服务:
/export/server/hive/bin/beeline -u jdbc:hive2://node1.devops.cn:10000 -n root -p 123456 已自动生产hudi MOR模式的2张表:
- users_sink_hudi_hive_ro,ro 表全称 read oprimized table,对于 MOR 表同步的 xxx_ro 表,只暴露压缩后的 parquet。其查询方式和COW表类似。设置完 hiveInputFormat 之后 和普通的 Hive 表一样查询即可;
- users_sink_hudi_hive_rt,rt表示增量视图,主要针对增量查询的rt表;ro表只能查parquet文件数据, rt表 parquet文件数据和log文件数据都可查;
查看自动生成表users_sink_hudi_hive_ro结构:
CREATE EXTERNAL TABLE `users_sink_hudi_hive_ro`(`_hoodie_commit_time` string COMMENT '', `_hoodie_commit_seqno` string COMMENT '', `_hoodie_record_key` string COMMENT '', `_hoodie_partition_path` string COMMENT '', `_hoodie_file_name` string COMMENT '', `_hoodie_operation` string COMMENT '', `id` bigint COMMENT '', `name` string COMMENT '', `birthday` bigint COMMENT '', `ts` bigint COMMENT '')
PARTITIONED BY ( `part` string COMMENT '')
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES ( 'hoodie.query.as.ro.table'='true', 'path'='hdfs://node1.itcast.cn:8020/users_sink_hudi_hive')
STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION'hdfs://node1.devops.cn:8020/users_sink_hudi_hive'
TBLPROPERTIES ('last_commit_time_sync'='20211125095818', 'spark.sql.sources.provider'='hudi', 'spark.sql.sources.schema.numPartCols'='1', 'spark.sql.sources.schema.numParts'='1',
'spark.sql.sources.schema.part.0'='{\"type\":\"struct\",\"fields\":[{\"name\":\"_hoodie_commit_time\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_commit_seqno\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_record_key\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_partition_path\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_file_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_operation\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"id\",\"type\":\"long\",\"nullable\":false,\"metadata\":{}},{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"birthday\",\"type\":\"timestamp\",\"nullable\":true,\"metadata\":{}},{\"name\":\"ts\",\"type\":\"timestamp\",\"nullable\":true,\"metadata\":{}},{\"name\":\"part\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}', 'spark.sql.sources.schema.partCol.0'='partition', 'transient_lastDdlTime'='1637743860') 查看自动生成表的分区信息:
show partitions users_sink_hudi_hive_ro ;
show partitions users_sink_hudi_hive_rt ; 查询Hive 分区表数据
set hive.exec.mode.local.auto=true;
set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
set hive.mapred.mode=nonstrict ;select id, name, birthday, ts, `part` from users_sink_hudi_hive_ro; 指定分区字段过滤,查询数据
select name, ts from users_sink_hudi_hive_ro where part ='20211125';
select name, ts from users_sink_hudi_hive_rt where part ='20211125';
三)Hudi Client操作Hudi表
进入Hudi客户端命令行:hudi-0.9.0/hudi-cli/hudi-cli.sh
连接Hudi表,查看表信息
connect --path hdfs://node1.devops.cn:8020/users_sink_hudi_hive 查看Hudi commit信息
commits show --sortBy "CommitTime"

查看Hudi compactions 计划
compactions show all