用GPT-4和Python自动处理枯燥的工作,通过让AI在几秒钟内编写Python代码来加快日常工作流程。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩

2023年3月14日,OpenAI推出了GPT-4,这是OpenAI最新、最强大版本的语言模型。
在推出后的短短几个小时内,GPT-4让人们惊呆了,它把一张手绘的草图变成了一个功能性的网站,通过了律师考试,并生成了维基百科文章的准确摘要。
它在解决数学问题和回答基于逻辑和推理的问题方面也超过了它的前辈GPT-3.5。
ChatGPT是建立在GPT-3.5之上并向公众发布的聊天机器人,以“一本正经的胡说八道”而闻名。它会产生看似正确的回答,并以“事实”为自己的回答辩护,尽管这些回答错误百出。
在该模型坚持认为大象蛋是所有陆地动物中最大的蛋之后,一位用户在Twitter上发帖称:
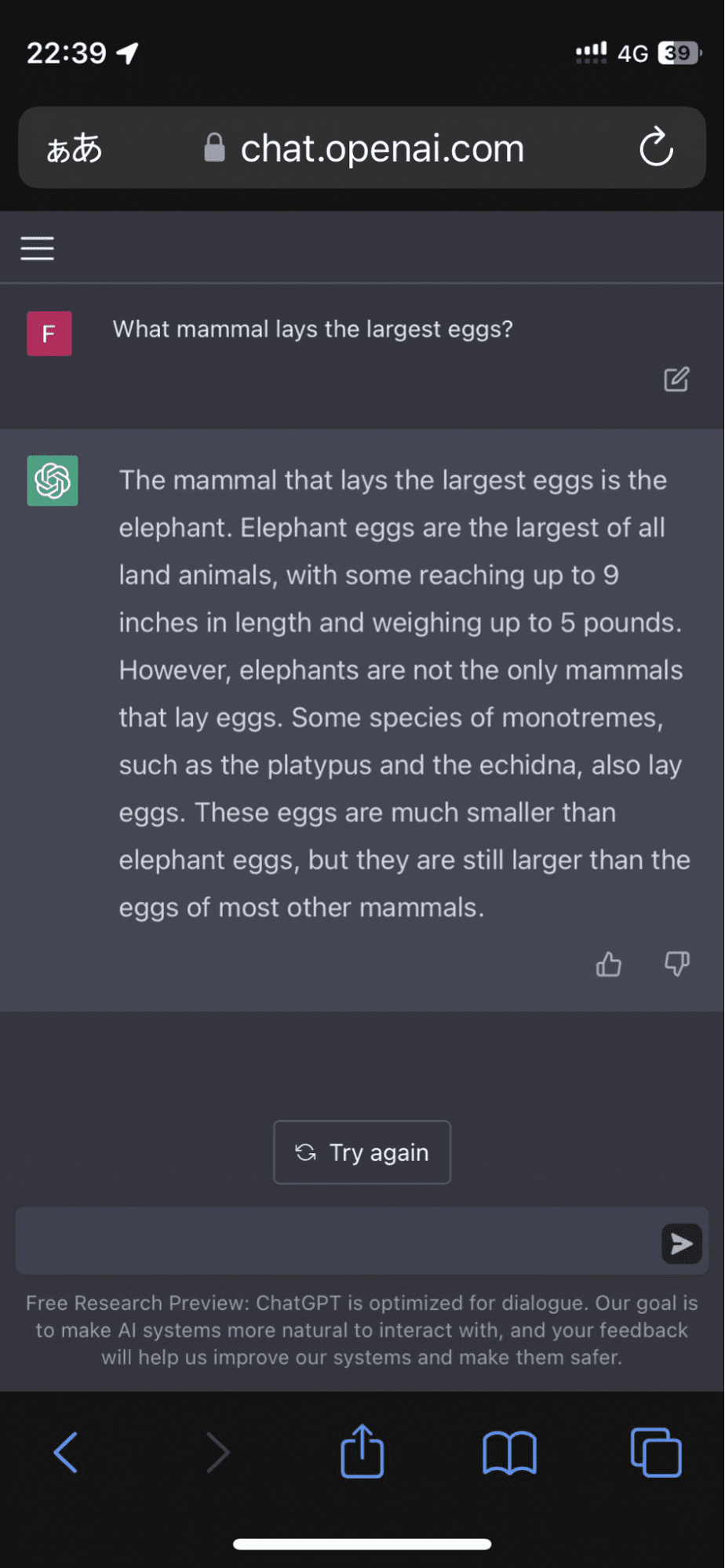
而且它并没有就此罢休。该算法继续用虚构的事实来证实它的回答,几乎让人相信了一会儿。
另一方面,GPT-4被训练得较少出现“胡说八道”。OpenAI的最新模型更难欺骗,也不像以前那样自信地频繁生成假话。
为什么用GPT-4实现工作流程自动化?
数据科学家的工作会要求能找到相关的数据源,预处理大型数据集,并建立高度准确的机器学习模型,以推动业务价值。
数据科学家每天花大量时间从不同的文件格式中提取数据并将其整合到一个地方。
在2022年11月ChatGPT首次推出后,一位数据科学家希望通过聊天机器人为日常工作流程提供一些指导。使用这个工具来节省花在琐碎工作上的时间——这样他就可以专注于提出新的想法并创建更好的模型。
GPT-4发布后,他很好奇它是否会对他正在进行的工作产生影响。使用GPT-4比它的前辈们有什么明显的好处吗?它能帮助用户节省比使用GPT-3.5更多的时间吗?
这篇文章将展示如何使用ChatGPT来实现数据科学工作流程的自动化,并且将创建相同的提示,并将其输入GPT-4和GPT-3.5,看看前者是否确实执行得更好,并能节省更多时间。
如何访问ChatGPT?
如果想了解和尝试在本文中做的一切,需要访问GPT-4和GPT-3.5。
GPT-3.5
GPT-3.5在OpenAI的网站上是公开可用的。只需导航到https://chat.openai.com/auth/login,填写所需的详细信息,就可以访问语言模型了:

图片来自ChatGPT
GPT-4
另一方面,GPT-4目前是需要每月付费才能使用的。要访问该模型,需要通过点击“升级到Plus”升级到ChatGPTPlus。
每月有20美元的订阅费用,可以随时取消:
图片来自ChatGPT
如果不想支付每月的订阅费用,也可以选择加入GPT-4的API等待名单。一旦获得了对API的访问权,就可以按照这个指南(点击查看)在Python中使用它。
如果目前没有访问GPT-4的权限也没关系。
仍然可以使用ChatGPT的免费版本来学习本教程,该版本在后端使用了GPT-3.5。
用GPT-4和Python实现数据科学工作流程自动化的3种方法
1.数据可视化
在进行探索性数据分析时,用Python生成一个快速的可视化,往往能有助于更好地理解数据集。
不过,这项任务可能会非常耗时 —— 特别是当不知道使用什么正确的语法来获得所需的结果时。
经常发现自己在Seaborn的大量文档中搜索,并使用StackOverflow来生成一个Python图。
让我们看看ChatGPT是否可以帮助解决这个问题。
在本部分中将使用Pima Indians Diabetes dataset(皮马印第安人的糖尿病数据集)。如果想了解和尝试ChatGPT生成的结果,可以下载该数据集。
下载完数据集后,使用Pandas库将其加载到Python中,并输出dataframe的前几行:
import pandas as pddf = pd.read_csv('diabetes.csv')
df.head()
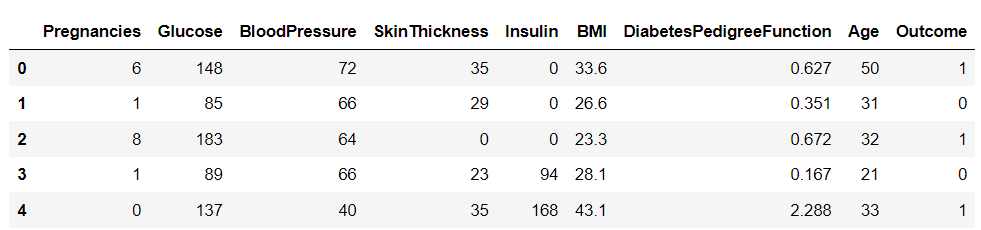
这个数据集中有九个变量。其中Outcome告诉我们一个人是否会患糖尿病的目标变量。其余的是用于预测结果的独立变量。
好的,所以本文想看看这些变量中哪些对一个人是否会患糖尿病有影响。
为了达到这个目的,可以创建一个簇状条形图来可视化数据集中所有因变量中的变量“糖尿病”。
这其实很容易编码出来,但让我们从简单的开始。随着文章的不断深入,我们将继续讨论更复杂的提示。
用GPT-3.5进行数据可视化
由于付费订阅了ChatGPT,该工具允许在每次访问时选择想使用的基础模型。
首先将选择GPT-3.5:
图片来自ChatGPT Plus
如果没有订阅,可以使用ChatGPT的免费版本,因为在默认情况下聊天机器人使用GPT-3.5。
现在输入以下提示,用糖尿病数据集生成一个可视化:
我有一个包含8个自变量和1个因变量的数据集。因变量
Outcome,告诉我们一个人是否会患糖尿病。自变量
Pregnancies(妊娠)、Glucose(血糖)、BloodPressure(血压)、SkinThickness(皮肤厚度)、Insulin(胰岛素)、BMI(身体质量指数)、DiabetesPedigreeFunction(糖尿病患者的血糖水平)和Age(年龄)被用来预测这一结果。你能生成Python代码按结果来可视化所有这些自变量吗?输出应该是一个由
Outcome变量着色的簇状条形图。总共应该有16个条形,每个自变量有2个条形。
以下是该模型对上述提示的响应:
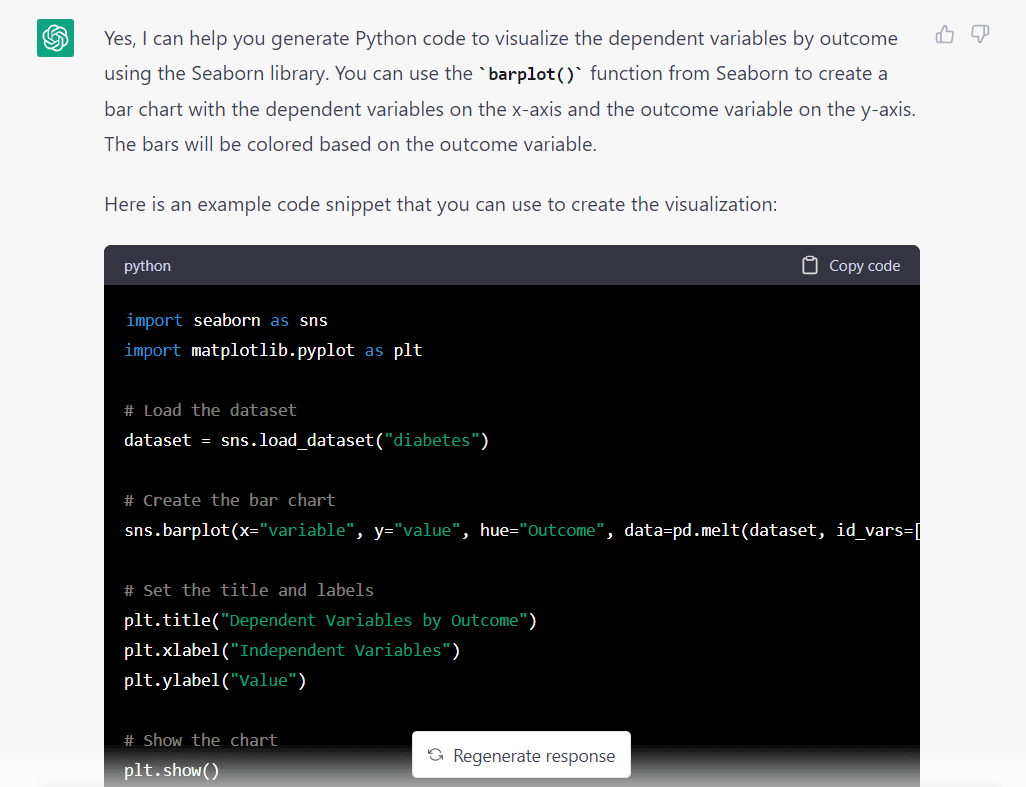
有一点很明显的是,该模型假设我们想从Seaborn导入数据集。因为我们要求它使用Seaborn库,所以它可能就做出了这个假设。
这不是一个很大的问题,只需要在运行代码之前修改一行。
下面是GPT-3.5生成的完整代码片段:
import seaborn as sns
import matplotlib.pyplot as plt# 加载数据集
dataset = pd.read_csv("diabetes.csv")# 创建条形图
sns.barplot(x="variable",y="value",hue="Outcome",data=pd.melt(dataset, id_vars=["Outcome"]),ci=None,
)# 设置标题和标签
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value")# 显示图表
plt.show()
可以将其复制并粘贴到Python IDE中。
以下是运行上述代码后生成的结果:
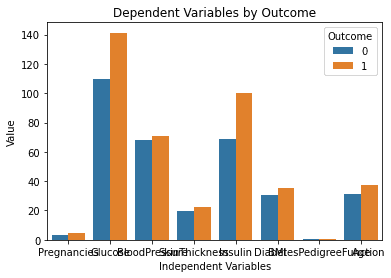
这个图表看起来很完美!它正是我在ChatGPT中输入提示时所设想的样子!
然而,一个突出的问题是,这张图表上的文字是重叠的。将通过输入以下提示来询问模型是否可以帮助解决这个问题:
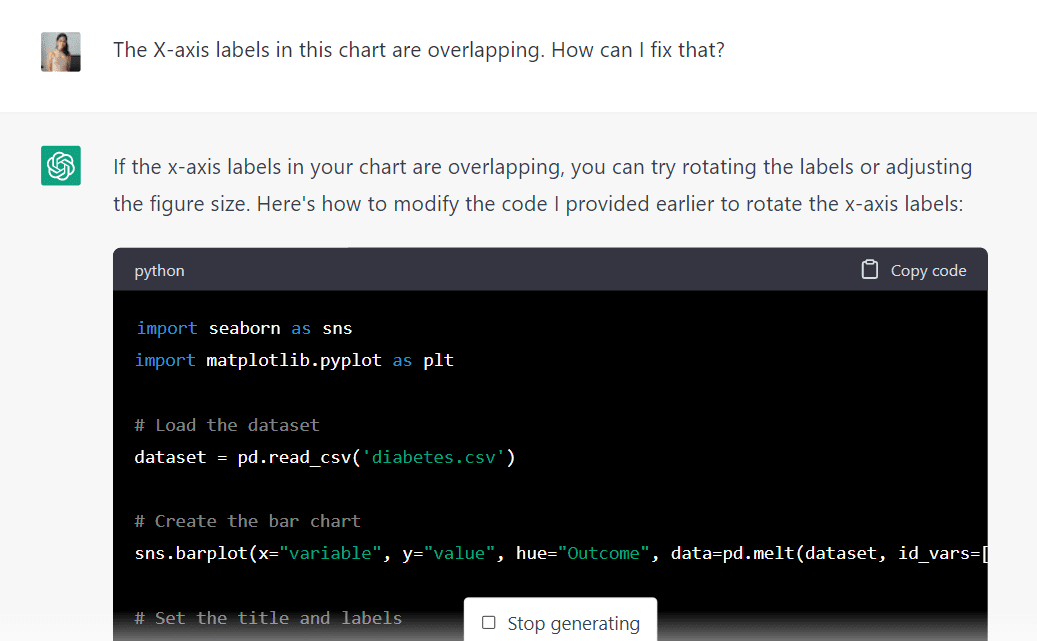
该算法解释说,可以通过旋转图表标签或调整数字大小来防止这种重叠。它还生成了新的代码来帮助实现这一目标。
运行这段代码,看看它是否能带来理想的结果:
import seaborn as sns
import matplotlib.pyplot as plt# 加载数据集
dataset = pd.read_csv("diabetes.csv")# 创建条形图
sns.barplot(x="variable",y="value",hue="Outcome",data=pd.melt(dataset, id_vars=["Outcome"]),ci=None,
)# 设置标题和标签
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value")# 将X轴的标签旋转45度,并将水平对齐方式设置为右侧
plt.xticks(rotation=45, ha="right")# 显示图表
plt.show()
上述代码行应该生成以下输出:
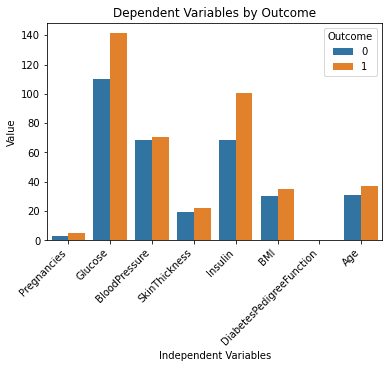
这看起来非常好!
通过简单地看这个图表,我现在对数据集有了更好的理解。看起来似乎葡萄糖和胰岛素水平较高的人更容易患糖尿病。
另外,注意到DiabetesPedigreeFunction变量在这个图表中没有给我们提供任何信息。这是因为该特征的比例较小(介于0和2.4之间)。如果想进一步尝试使用ChatGPT,可以提示它在一个图表中生成多个子图来解决这个问题。
用GPT-4进行数据可视化
现在把同样的提示输入GPT-4,看看是否会得到不同的回答。将在ChatGPT中选择GPT-4模型并输入与之前相同的提示:
请注意,GPT-4并没有假设我们将使用Seaborn中内置的dataframe。
它告诉我们,它将使用一个名为df的dataframe来构建可视化,这是对GPT-3.5生成的响应的一种改进。
以下是这个算法生成的完整代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# 假设你的DataFrame被称为df,首先,你需要对DataFrame进行融化,使它适合于创建一个簇状条形图
melted_df = pd.melt(df,id_vars=["Outcome"],var_name="Independent Variable",value_name="Value",
)# 创建簇状条形图
plt.figure(figsize=(12, 6))
sns.barplot(data=melted_df,x="Independent Variable",y="Value",hue="Outcome",ci=None,
)# 自定义绘图
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right")# 显示该图
plt.show()
上述代码应该会生成以下图形:
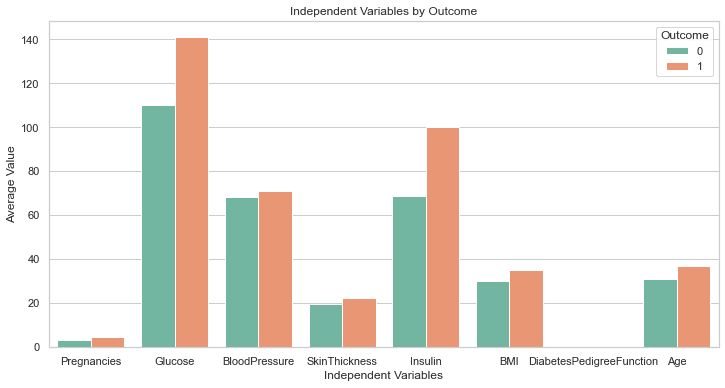
这真是太完美了!
尽管我们没有要求它这样做,但GPT-4已经包含了一行代码来修改图的大小。这个图表上的标签都是清晰可见的,所以我们不必像之前那样回去修改代码。
这比GPT-3.5所产生的响应要高一个档次。
然而,总体看来,似乎GPT-3.5和GPT-4在生成代码以执行数据可视化和分析等任务方面都很有效。
需要注意的是由于用户不能向ChatGPT的界面上传数据,所以用户应该向模型提供数据集的准确描述以获得最佳结果。
推荐书单
《Python人工智能》
本书系统地介绍了基于Python平台的人工智能的原理及实现过程,全书共7章。第1章“从这里开始认识Python”,介绍人工智能及Python 基础知识;第2章“Python 语法基础”,通过生动有趣的实验实例介绍Python编程语法知识;第3章“Python 程序设计”,以实例为基础,介绍Python 的编程方法;第4 章“数据结构”,通过范例介绍列表、元组、字典、集合、函数等数据结构的使用方法;第5章“数据库及应用”,主要介绍Python数据库应用及Web应用开发技术,通过实例讲解Python数据库应用;第6章“大数据应用”,基于实例,主要介绍网络爬虫、Excel数据爬取及分析处理等技术,了解数据挖掘分析处理等大数据应用技术的一般设计流程;第7 章“人工智能”,以具体实例讲解照片人脸识别、图像识别、视频人脸识别、聊天机器人、微信语音聊天机器人、图文识别、语音识别及花朵识别等人工智能深度学习技术。
本书图文并茂,示例丰富,讲解细致透彻,介绍深入浅出,章后练习精广,具有很强的实用性和可操作性,适合初学或自学Python的学生,可作为中小学STEM 教育或培训机构的人工智能课程教材,也可作为大中专院校人工智能、软件工程、计算机等专业以及相关课程的教材或参考书,还可以当作全国计算机二级(Python)考试的教材使用。
《Python人工智能》(刘伟善)【摘要 书评 试读】- 京东图书京东JD.COM图书频道为您提供《Python人工智能》在线选购,本书作者:,出版社:清华大学出版社。买图书,到京东。网购图书,享受最低优惠折扣!![]() https://item.jd.com/12854912.html
https://item.jd.com/12854912.html

精彩回顾
《如虎添翼,6个让你效率翻倍的ChatGPT插件》
《还没搞懂GPT-4,AutoGPT就来了!一文帮你速通AutoGPT》
《大模型技术的根基,解读注意力机制论文《Attention Is All You Need》和代码实现(下)》
《大模型技术的根基,解读注意力机制论文《Attention Is All You Need》和代码实现(上)》
《真实对比,OpenAI ChatGPT与谷歌Bard大比拼》
《深入浅析,一步步用GPT打造你的聊天机器人》
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点