0. 简介
自动泊车是智能驾驶领域的一项关键任务。传统泊车算法通常采用基于规则的方案来实现。然而,由于算法设计的复杂性,这些方法在复杂的泊车场景中效果欠佳。相比之下,基于神经网络的方法往往比基于规则的方法更加直观且功能多样。通过收集大量专家泊车轨迹数据,并利用基于学习的方法模拟人类策略,泊车任务可以得到有效解决。《ParkingE2E: Camera-based End-to-end Parking Network, from Images to Planning》采用模仿学习的方法,通过模仿人类驾驶轨迹,实现从RGB图像到路径规划的端到端规划。所提出的端到端方法利用目标查询编码器来融合图像和目标特征,以及基于Transformer的解码器来自回归地预测未来路径点。相关的代码在Github中可以看到。

图1:整体工作流程的示意图。我们的模型以环视摄像头图像和目标停车位作为输入,输出预测的轨迹关键点,随后由控制器执行。补充视频材料可在以下链接查看:https://youtu.be/urOEHJH1TBQ。
1. 主要贡献
智能驾驶涉及三大主要任务:城市驾驶、高速公路驾驶和泊车操作。自动代客泊车(AVP)和自动泊车辅助(APA)系统作为智能驾驶中的关键泊车任务,显著提升了泊车的安全性和便捷性。然而,主流的泊车方法往往基于规则,需要将整个泊车过程分解为多个阶段,如环境感知、地图构建、车位检测、定位和路径规划。由于这些复杂模型架构的精细性,它们在紧凑车位或复杂场景中更容易遇到困难。
端到端(E2E)自动驾驶算法通过将感知、预测和规划组件集成到一个统一的神经网络中进行联合优化,减少了跨模块的累积误差。将端到端算法应用于泊车场景有助于减少对人工设计特征和规则的依赖,提供全面、整体且用户友好的解决方案。
虽然端到端自动驾驶已经显示出显著的优势,但大多数研究都集中在模拟上,而没有验证算法在现实世界中的有效性。与城市环境的复杂性和高速公路驾驶的危险性相比,泊车场景的特点是速度低、空间有限且可控性高。这些特点为在车辆中逐步部署端到端自动驾驶能力提供了一条可行的途径。我们开发了一个端到端泊车神经网络,并在现实世界的泊车场景中验证了该算法的可行性。
这项工作扩展了我们之前的工作E2E-Carla,通过提出一种基于模仿学习的端到端泊车算法,该算法已在真实环境中成功部署和评估。该算法接收车载camera捕捉的环视图像,预测未来的轨迹结果,并根据预测的路径点执行控制。一旦用户指定了一个停车位,端到端泊车网络就会与控制器协同工作,自动操控车辆进入停车位,直到完全停好。本文的主要贡献概括如下:
- 设计了一个端到端网络来执行泊车任务。该网络将环视图像转换为鸟瞰图(BEV)表示,并通过使用目标特征来查询图像特征,将其与目标停车位特征相融合。由于轨迹点的顺序性,我们采用基于Transformer解码器的自回归方法来生成轨迹点。
- 将端到端模型部署在实车上进行测试,验证了该网络模型在各种现实场景中的泊车可行性和通用性,为端到端网络的部署提供了有效解决方案。
2. 初步研究:问题定义
我们使用端到端神经网络 N θ N_θ Nθ 来模仿专家轨迹进行训练,并定义数据集:
D = { ( I i , j k , P i , j , S i ) } , (1) \mathcal{D} = \{ ( I_{i,j}^{k}, P_{i,j}, S_{i} ) \}, \tag{1} D={(Ii,jk,Pi,j,Si)},(1)
其中,轨迹索引 i ∈ [ 1 , M ] i \in [1, M] i∈[1,M],轨迹点索引 j ∈ [ 1 , N i ] j \in [1, N_i] j∈[1,Ni],相机索引 k ∈ [ 1 , R ] k \in [1, R] k∈[1,R],RGB 图像 I I I,轨迹点 P P P 和目标槽 S S S。将数据集重新组织为(这里 T i , j T_{i,j} Ti,j是根据端到端神经网络计算得出):
T i , j = { P i , min ( j + b , N i ) } b = 1 , 2 , … , Q , (2) T_{i,j} = \{ P_{i, \min(j+b, N_i)} \}_{b=1,2,\ldots,Q}, \tag{2} Ti,j={Pi,min(j+b,Ni)}b=1,2,…,Q,(2)
D ′ = { ( I i , j k , T i , j , S i ) } , (3) D' = \{ (I^{k}_{i,j}, T_{i,j}, S_i) \}, \tag{3} D′={(Ii,jk,Ti,j,Si)},(3)
其中, Q Q Q 表示预测轨迹点的长度, R R R 表示 RGB 摄像头的数量。端到端网络的优化目标如下:
θ ′ = arg min θ E ( I , T , S ) ∼ D ′ [ L ( T , N θ ( I , S ) ) ] , (4) \theta' = \arg \min_{\theta} \mathbb{E}_{(I, T, S) \sim \mathcal{D'}} \left[ \mathcal{L}(T, N_{\theta}(I, S)) \right], \tag{4} θ′=argθminE(I,T,S)∼D′[L(T,Nθ(I,S))],(4)
其中 L L L 表示损失函数。
3. 基于摄像头的端到端神经规划器
3.1 概述
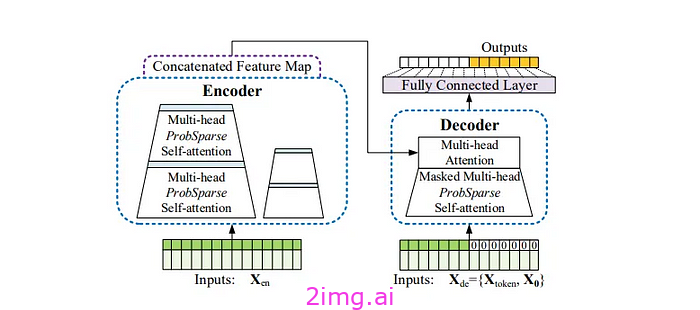
如图 2 所示,我们开发了一种端到端的神经规划器,该规划器以 RGB 图像和目标槽作为输入。所提出的神经网络主要包括两个部分:输入编码器和自回归轨迹解码器。通过输入 RGB 图像和目标槽,RGB 图像被转换为鸟瞰视图(BEV)特征。随后,神经网络将 BEV 特征与目标槽融合,并采用自回归方式通过变换器解码器生成下一个轨迹点。

图 2:我们方法的概述。多视角 RGB 图像经过处理后,其图像特征被转换为鸟瞰视图(BEV)表示。目标槽用于生成 BEV 目标特征。我们使用目标查询将目标特征与图像的 BEV 特征进行融合。随后,我们通过自回归变换器解码器逐一获得预测的轨迹点。
3.2 编码器
我们在鸟瞰视图(BEV)中对输入进行编码。BEV 表示提供了车辆周围环境的俯视图,使自我车辆能够检测停车位、障碍物和标记。同时,BEV 视图在不同驾驶视角下提供了一致的视点表示,从而简化了轨迹预测的复杂性。
3.2.1 相机编码器(这一步就是特征提取+lss前视转鸟瞰的操作)
在 BEV 生成流程的开始,我们首先利用 EfficientNet [22] 从 RGB 输入中提取图像特征 F i m g ∈ R C × H i m g × W i m g F_{img} ∈ \mathbb{R}^{C×H_{img}×W_{img}} Fimg∈RC×Himg×Wimg。受到 LSS [23] 的启发,我们学习图像特征的深度分布 d d e p ∈ R D × H i m g × W i m g d_{dep} ∈ \mathbb{R}^{D×H_{img}×W_{img}} ddep∈RD×Himg×Wimg,并将每个像素提升到 3D 空间。然后,我们将预测的深度分布 d d e p d_{dep} ddep 与图像特征 F i m g F_{img} Fimg 相乘,以获得包含深度信息的图像特征。结合相机的外参和内参,图像特征被投影到 BEV 体素网格中,以生成相机特征 F c a m ∈ R C × H c a m × W c a m F_{cam} ∈ \mathbb{R}^{C×H_{cam}×W_{cam}} Fcam∈RC×Hcam×Wcam。BEV 特征在 x x x 方向的范围表示为 [ − R x −R_x −Rx, R x R_x Rx]m,其中 m 表示米,而 y y y 方向的范围表示为 [ − R y −R_y −Ry, R y R_y Ry]m。