本期求职笔试题目来源大疆硬件逻辑岗,共2道题,涉及知识点包含:时序约束中异步时钟的设置、典型时序优化方法。
33、根据约束关系set_clock_groups -async -group {CLK1CLK3}{CLK2},下图哪些路径会进行时序检查( )(多选题)
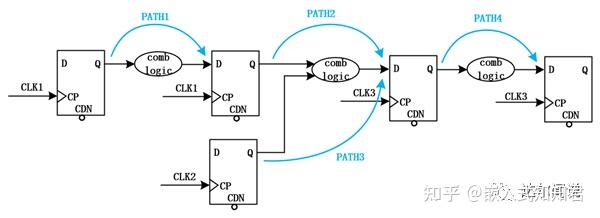
A Path4 B Path2C Path3 D Path1 解析:本题目主要考察了时序约束中异步时钟的设置看到这一串英文大家不禁会联想到中讲过输入延迟约束,没错它们都是用Tcl命令所做的时序约束。而今天这道题目涉及到的是对异步时钟的约束,和set_false_path设置成伪路径的功能类似。我们要想明白题意就要明白set_clock_groups -async -group {CLK1CLK3}{CLK2}这句约束的意思,set_clock_groups是设置禁用识别的时钟组之间的时序分析命令;-async用于指定时钟之间的异步关系,让时序分析工具忽略异步时钟之间的路径;-group后面紧跟指定要忽略时钟之间路径的异步时钟的名字。因为图中CLK1、CLK2、CLK3三个时钟之间彼此都是异步的关系,所以这句话的意思也就很明确了,就是设置CLK1、CLK2、CLK3相互异步的三个时钟之间的路径不进行时序检查。那么我们很快就可以从图中得到答案,PATH2和PATH3路径是不同时钟所作用的两个寄存器,所以PATH2和PATH3路径不会进行时序检查;而PATH1和PATH4路径是同一时钟所作用的两个寄存器,所以PATH1和PATH4路径会进行时序检查,答案选择A和D。
既然和set_false_path和set_clock_groups的功能类似,那我们就来看看它们各自的特点。set_false_path的优势是:灵活、针对性好、便于时序分析和调试。劣势是:①逐条约束会占用大量时间来调试和分析,效率低下。②时序例外的优先级比较复杂,多种时序例外约束共存的情况下,很容易产生意想不到的冲突,进一步增加调试时间,降低效率。③这么做极容易产生臃肿的XDC约束文件,而且时序例外的执行更耗内存,直接导致工具运行时间变长。而set_clock_groups的优势是:简单、快速、执行效率高。劣势是:会掩盖时序报告中所有的跨时钟域路径,容易误伤,不利于时序分析。所以我们不能盲目的只用其中的一种,要具体问题具体分析。set_clock_groups还可以用于解决重叠(单点多个)时钟的问题。重叠时钟是指多个时钟共享完全相同的时钟传输网络,例如两个时钟经过一个MUX选择后输出的时钟,在有多种运行模式的设计中很常见。
34、FPGA相对于ASIC,优势是灵活可编程,不足是可实现的最高频率有限。请介绍一下在FPGA开发中典型的时序优化方法。(问答题)解析:本题目主要考察了时序优化的方法该题目的第一句话完全就是科普,和问题没有什么关系。问题是在第二句话中表达的,我们要思考该从什么角度去找FPGA典型的时序优化方法。1)根据时序分析理论公式优化优化时序的目的是什么?其目的就是为了满足系统正常运行时所需要的建立、保持时间,最终得出两个关键的公式:Sslack(建立时间的余量)= [T_cycle –(Tco + Tdata)+ △T] – T_setup ≥ 0Hslack(保持时间的余量)= [(Tco + Tdata)–△T] – T_hold ≥ 0根据公式可以看出同一系统内的建立时间余量和保持时间余量是一对矛盾体,如果建立时间余量大了,保持时间余量必定会缩小,反之亦然。我们需要做的就是让建立保持时间余量和保持时间余量尽量保持平衡。如果建立时间余量较小或者不满足要求,我们就可以根据公式来分析满足建立时间的要求。我们可以在建立时间余量公式中增加时钟的周期T_cycle,也就是减小时钟T_cycle的频率,但是一般系统时钟在设计之初都是确定的,后期不能修改,所以这个方法不可取。我们可以在建立时间余量公式中减小Tco,但是Tco作为寄存器的固有属性往往都是固定好的,不能改变。我们可以在建立时间余量公式中减小Tdata,怎么减小Tdata呢?我们知道Tdata是寄存器之间路径所造成的延时,其中又包括布线延时和组合逻辑延时,所以我们要尽量减小布线延时和组合逻辑延时,如何降低布线延时和组合逻辑延时呢?(1)减小扇出Fanout,扇出指模块直接调用的下级模块的个数,如果这个数值过大的话,在FPGA直接表现为Net Delay较大,不利于时序收敛。减小扇出的方法有:①寄存器复制,寄存器复制是解决高扇出问题最常用的方法之一,通过复制几个相同的寄存器来分担由原先一个寄存器驱动所有模块的任务,继而达到减小扇出的目的。②Max_Fanout属性,在代码中可以设置信号属性,将对应信号的Max_Fanout属性设置成一个合理的值,当实际的设计中该信号的Fanout超过了这个值,综合器就会自动对该信号采用优化手段,常用的手段其实就是寄存器复制。但最好不要在综合设置中指定,过低的扇出限制会造成设计堵塞反而不利于时序收敛,最好的方法是根据设计中时序最差路径的扇出进行针对性的优化。③BUFG,通常BUFG是用于全局时钟的资源,可以解决信号因为高扇出产生的问题。但是其一般用于时钟或者复位之类扇出超级大的信号,此类信号涉及的逻辑遍布整个芯片,而BUFG可以从全局的角度优化布线。如果不是关键时序路径,而且高扇出网络直接连接到触发器,对扇出超过25K的Net插入BUFG。(2)减小逻辑级数Logic Level,一个Logic Level的延迟对应的是一个LUT和一个Net的延迟,对于不同的器件,不同频率的设计能容纳的Logic Level是不同的,否则会造成时序收敛困难。Logic Levell太大的处理方法就是重定时(Retiming),典型的重定时方法就是流水线,将过于冗长的组合逻辑增加寄存器进行打拍。对于时钟偏斜△T来说因为不确定正负,其对建立时间和保持时间的影响是相反的,所以我们希望|△T|尽可能的小,所以尽量不要用生成时钟,而采用全局时钟,这样才会有更小的|△T|。在实践中,我发现保持时间的问题往往是异步问题产生的。对于一个信号的跨时钟域问题,一般使用双寄存器法(对于慢采快的结绳法这里不讨论)。为了降低MTBF(Mean Time Between Failures,平均无障碍时间),这两个寄存器最好位于同一个Slice中。
2)通过代码风格优化,好的代码风格会更利于时序的优化。(2)时钟管理单元尽量放在顶层,有助于以共享逻辑从而提高性能降低功耗。(3)如果并不需要优先级,尽量将If语句转化为case语句。(4)尽量不要使用Don't Touch这类语句。如今Vivado综合工具已经很完善了,除非代码有问题或者手动复制寄存器,否则一般不会发生电路被综合掉的现象。使用这些语句会覆盖Vivado综合设置,导致电路没有得到充分的优化,给时序收敛造成困难。3)使用EDA开发工具的综合策略优化(1)Vivado综合实现本质是时序驱动的,因此再也没有ISE那种用随机种子综合实现满足时序收敛的工具。通过Vivado在布局布线方面提供了几种不同的策略(directive)组合可以产生上千种不同的布局布线结果.(2)使用Tcl脚本自定义布局布线过程,足以满足需求。Vivado可支持同时运行多个Implementation,为这种“设计时间换取性能”的方法提供了工具上的便利。(3)Implementation里Post-place Phys Opt Design和Post-route Phys Opt Design是没有使能的,工程后期使能这两个配置也能在一定程度上改善时序收敛。






![[极客大挑战 2020]Greatphp1](https://i-blog.csdnimg.cn/direct/92588f59d39e40c491717358e3953446.png)