一、前言
本篇文章将使用ms-swift去合并微调后的模型权重,通过阅读本文,您将能够更好地掌握这些关键技术,理解其中的关键技术要点,并应用于自己的项目中。
二、术语介绍
2.1. LoRA微调
LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游任务的可训练参数数量。
2.2.参数高效微调(PEFT)
仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本。
2.3.Qwen2-7B-Instruct
是通义千问 Qwen2 系列中的一个指令微调模型。它在 Qwen2-7B 的基础上进行了指令微调,以提高模型在特定任务上的性能。
Qwen2-7B-Instruct 具有以下特点:
- 强大的性能:在多个基准测试中,Qwen2-7B-Instruct 的性能可与 Llama-3-70B-Instruct 相匹敌。
- 代码和数学能力提升:得益于高质量的数据和指令微调,Qwen2-7B-Instruct 在数学和代码能力上实现了飞升。
- 多语言能力:模型训练过程中增加了 27 种语言相关的高质量数据,提升了多语言能力。
- 上下文长度支持:Qwen2 系列中的所有 Instruct 模型均在 32k 上下文中进行训练,Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 还支持最高可达 128k token 的上下文长度。
2.4.模型合并
指的是将多个模型的权重或参数整合到一个新的模型中,形成一个更强大的模型。
模型合并的用途:
- 提升模型性能: 整合不同模型的优势,从而提高模型的精度、鲁棒性等性能指标
- 增强模型泛化能力: 降低过拟合风险,使模型在不同数据集上表现更稳定
- 减少模型尺寸: 减少模型的存储空间和计算量
- 提高模型效率: 提高模型的推理效率
三、前置条件
3.1. 基础环境及前置条件
1. 操作系统:centos7
2. NVIDIA Tesla V100 32GB CUDA Version: 12.2

3. 提前下载好Qwen2-7B-Instruct模型
通过以下两个地址进行下载,优先推荐魔搭
hugging face:https://huggingface.co/Qwen/Qwen2-7B-Instruct/tree/main
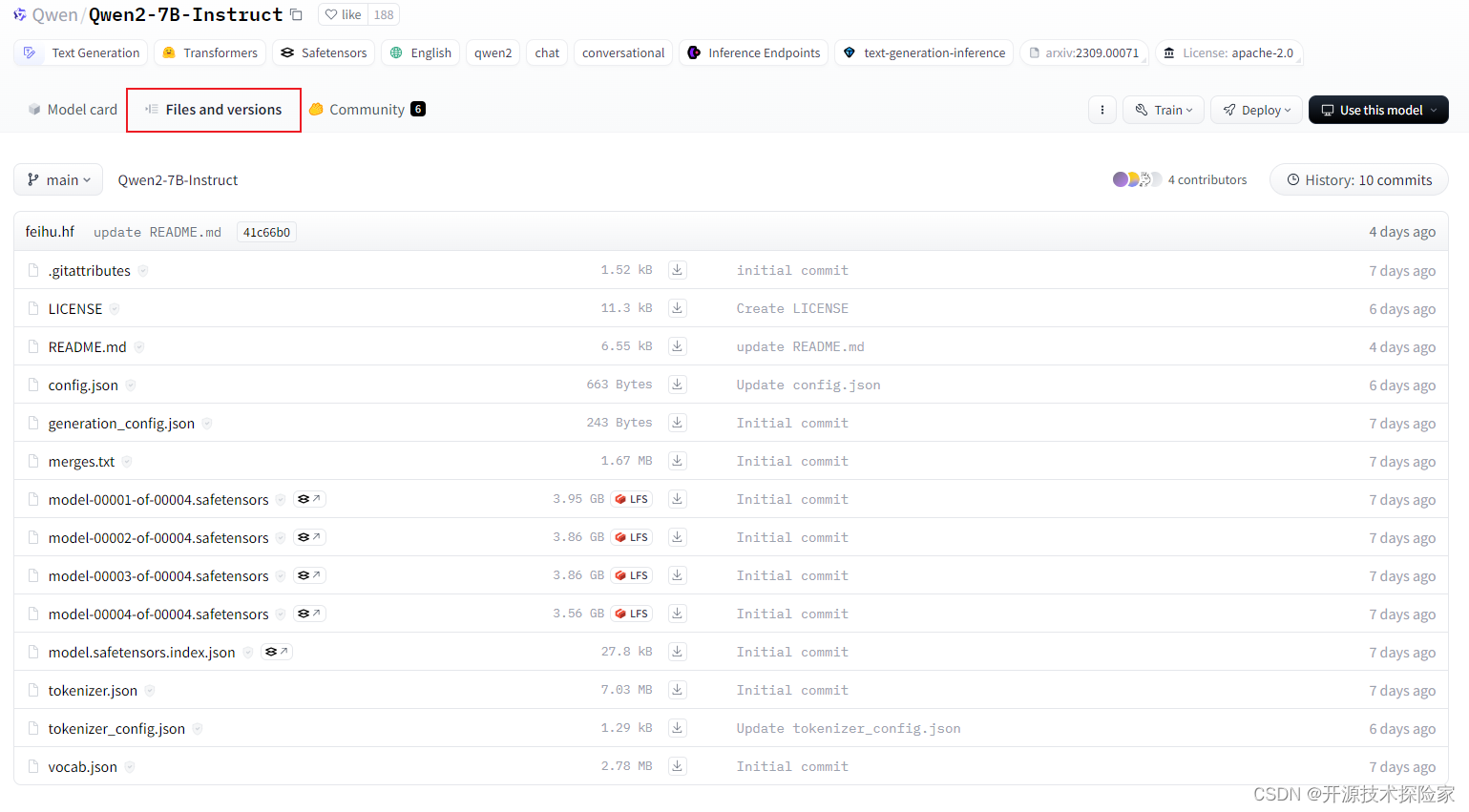
modelscope:git clone https://www.modelscope.cn/qwen/Qwen2-7B-Instruct.git
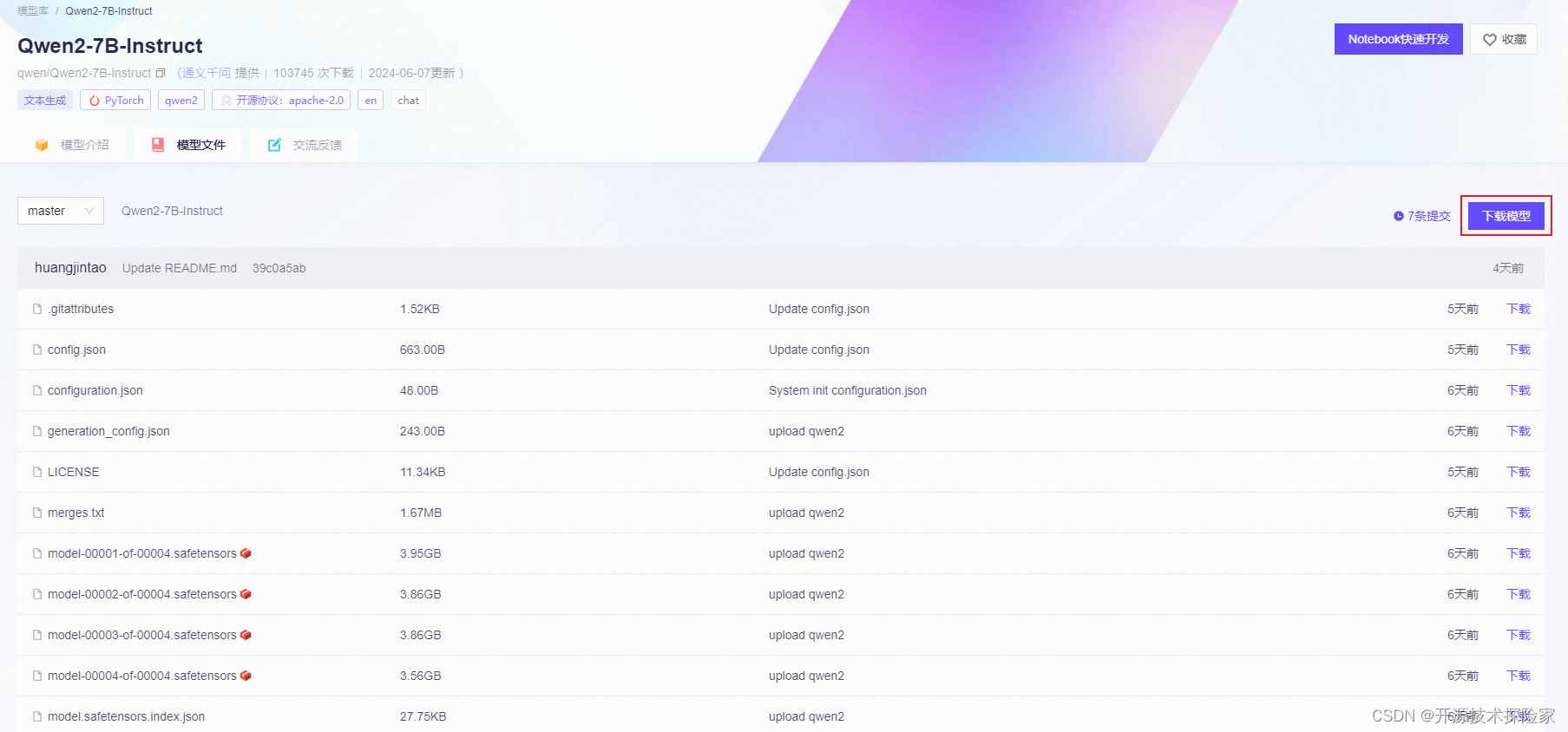
按需选择SDK或者Git方式下载
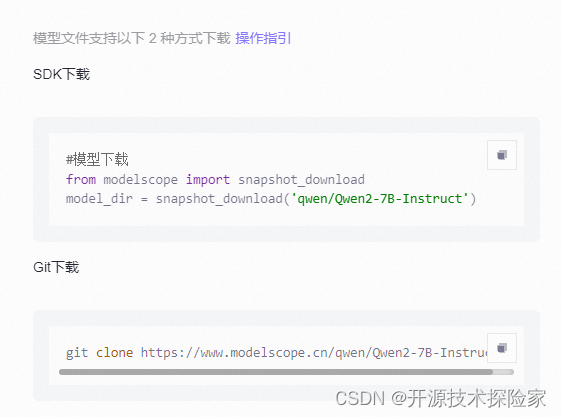
使用git方式下载示例(或者使用git-lfs):
3.2.Anaconda安装
参见“开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(一)”
3.3.安装依赖
通过命令行安装:
conda create --name swift python=3.10
conda activate swift
conda env remove -n swift
pip install 'ms-swift[all]' -U -i https://pypi.tuna.tsinghua.edu.cn/simple通过源码安装:
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]' -i https://pypi.tuna.tsinghua.edu.cn/simple3.4.完成模型微调
参见:开源模型应用落地-qwen2-7b-instruct-LoRA微调-ms-swift-单机单卡-V100(十二)
日志输出情况:
Train: 100%|██████████| 873/873 [09:34<00:00, 1.69it/s]{'eval_loss': nan, 'eval_acc': 0.02320291, 'eval_runtime': 1.6477, 'eval_samples_per_second': 4.855, 'eval_steps_per_second': 4.855, 'epoch': 0.92, 'global_step/max_steps': '800/873', 'percentage': '91.64%', 'elapsed_time': '8m 47s', 'remaining_time': '48s'}Val: 100%|██████████| 8/8 [00:01<00:00, 5.65it/s]9it/s]
[INFO:swift] Saving model checkpoint to /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v1-20240830-151000/checkpoint-873
Train: 100%|██████████| 873/873 [09:36<00:00, 1.51it/s]
[INFO:swift] last_model_checkpoint: /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v1-20240830-151000/checkpoint-873
[INFO:swift] best_model_checkpoint: /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v1-20240830-151000/checkpoint-100
[INFO:swift] images_dir: /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v1-20240830-151000/images
[INFO:swift] End time of running main: 2024-08-30 15:20:25.615625
{'eval_loss': nan, 'eval_acc': 0.02320291, 'eval_runtime': 1.6682, 'eval_samples_per_second': 4.796, 'eval_steps_per_second': 4.796, 'epoch': 1.0, 'global_step/max_steps': '873/873', 'percentage': '100.00%', 'elapsed_time': '9m 36s', 'remaining_time': '0s'}
{'train_runtime': 576.7666, 'train_samples_per_second': 1.514, 'train_steps_per_second': 1.514, 'train_loss': 0.0, 'epoch': 1.0, 'global_step/max_steps': '873/873', 'percentage': '100.00%', 'elapsed_time': '9m 36s', 'remaining_time': '0s'}生成的模型权重:

四、技术实现
4.1.推理时合并
在推理时, 合并LoRA权重并保存
启动合并:
conda activate swift
swift infer --ckpt_dir /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873 --load_dataset_config true --merge_lora true --infer_backend vllm --max_model_len 8192若配置启用vllm,则需要安装vllm依赖
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple可配置参数:
InferArguments(model_type='qwen2-7b-instruct', model_id_or_path='/data/model/qwen2-7b-instruct', model_revision='master', sft_type='lora', template_type='qwen', infer_backend='vllm', ckpt_dir='/data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v1-20240901-141800/checkpoint-873', result_dir=None, load_args_from_ckpt_dir=True, load_dataset_config=True, eval_human=False, seed=42, dtype='bf16', model_kwargs=None, dataset=['qwen_zh_demo'], val_dataset=[], dataset_seed=42, dataset_test_ratio=0.01, show_dataset_sample=-1, save_result=True, system='You are a helpful assistant.', tools_prompt='react_en', max_length=None, truncation_strategy='delete', check_dataset_strategy='none', model_name=[None, None], model_author=[None, None], quant_method=None, quantization_bit=0, hqq_axis=0, hqq_dynamic_config_path=None, bnb_4bit_comp_dtype='bf16', bnb_4bit_quant_type='nf4', bnb_4bit_use_double_quant=True, bnb_4bit_quant_storage=None, max_new_tokens=2048, do_sample=True, temperature=0.3, top_k=20, top_p=0.7, repetition_penalty=1.0, num_beams=1, stop_words=[], rope_scaling=None, use_flash_attn=None, ignore_args_error=False, stream=True, merge_lora=True, merge_device_map='cpu', save_safetensors=True, overwrite_generation_config=True, verbose=None, local_repo_path=None, custom_register_path=None, custom_dataset_info='/data/service/swift/data/custom_dataset_info.json', device_map_config_path=None, device_max_memory=[], hub_token=None, gpu_memory_utilization=0.9, tensor_parallel_size=1, max_num_seqs=256, max_model_len=8192, disable_custom_all_reduce=True, enforce_eager=False, vllm_enable_lora=False, vllm_max_lora_rank=16, lora_modules=[], tp=1, cache_max_entry_count=0.8, quant_policy=0, vision_batch_size=1, self_cognition_sample=0, train_dataset_sample=-1, val_dataset_sample=None, safe_serialization=None, model_cache_dir=None, merge_lora_and_save=None, custom_train_dataset_path=[], custom_val_dataset_path=[], vllm_lora_modules=None)合并结果:
INFO 08-30 17:16:03 model_runner.py:879] Starting to load model /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873-merged...
INFO 08-30 17:16:03 selector.py:217] Cannot use FlashAttention-2 backend for Volta and Turing GPUs.
INFO 08-30 17:16:03 selector.py:116] Using XFormers backend.
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 25% Completed | 1/4 [01:07<03:23, 67.95s/it]
Loading safetensors checkpoint shards: 50% Completed | 2/4 [01:21<01:12, 36.12s/it]
Loading safetensors checkpoint shards: 75% Completed | 3/4 [01:22<00:20, 20.10s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [01:23<00:00, 12.29s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [01:23<00:00, 20.78s/it]INFO 08-30 17:17:27 model_runner.py:890] Loading model weights took 14.2487 GB
INFO 08-30 17:17:29 gpu_executor.py:121] # GPU blocks: 13857, # CPU blocks: 4681
INFO 08-30 17:17:32 model_runner.py:1181] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
INFO 08-30 17:17:32 model_runner.py:1185] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
INFO 08-30 17:17:59 model_runner.py:1300] Graph capturing finished in 27 secs.
[INFO:swift] generation_config: SamplingParams(n=1, best_of=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.0, temperature=0.3, top_p=0.7, top_k=20, min_p=0.0, seed=None, use_beam_search=False, length_penalty=1.0, early_stopping=False, stop=[], stop_token_ids=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=2048, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=False, spaces_between_special_tokens=True, truncate_prompt_tokens=None)
[INFO:swift] system: You are a helpful assistant.
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 881/881 [00:00<00:00, 9162.50 examples/s]
[INFO:swift] val_dataset: Dataset({features: ['query', 'response'],num_rows: 8
})
[INFO:swift] Setting args.verbose: True
[INFO:swift] save_result_path: /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873-merged/infer_result/20240830-171759.jsonl
[INFO:swift] End time of running main: 2024-08-30 17:20:33.961291
[rank0]:[W830 17:20:34.309521566 ProcessGroupNCCL.cpp:1168] Warning: WARNING: process group has NOT been destroyed before we destruct ProcessGroupNCCL. On normal program exit, the application should call destroy_process_group to ensure that any pending NCCL operations have finished in this process. In rare cases this process can exit before this point and block the progress of another member of the process group. This constraint has always been present, but this warning has only been added since PyTorch 2.4 (function operator())合并后的文件:

4.2.单独合并
启动合并:
conda activate swift
swift export --ckpt_dir /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873 --merge_lora true可配置参数:
ExportArguments(model_type='qwen2-7b-instruct', model_id_or_path='/data/model/qwen2-7b-instruct', model_revision='master', sft_type='lora', template_type='qwen', infer_backend='vllm', ckpt_dir='/data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873', result_dir=None, load_args_from_ckpt_dir=True, load_dataset_config=False, eval_human=True, seed=42, dtype='fp16', model_kwargs=None, dataset=[], val_dataset=[], dataset_seed=42, dataset_test_ratio=0.01, show_dataset_sample=-1, save_result=True, system='You are a helpful assistant.', tools_prompt='react_en', max_length=None, truncation_strategy='delete', check_dataset_strategy='none', model_name=[None, None], model_author=[None, None], quant_method='awq', quantization_bit=0, hqq_axis=0, hqq_dynamic_config_path=None, bnb_4bit_comp_dtype='fp16', bnb_4bit_quant_type='nf4', bnb_4bit_use_double_quant=True, bnb_4bit_quant_storage=None, max_new_tokens=2048, do_sample=True, temperature=0.3, top_k=20, top_p=0.7, repetition_penalty=1.0, num_beams=1, stop_words=[], rope_scaling=None, use_flash_attn=None, ignore_args_error=False, stream=True, merge_lora=True, merge_device_map='auto', save_safetensors=True, overwrite_generation_config=True, verbose=None, local_repo_path=None, custom_register_path=None, custom_dataset_info='/data/service/swift/data/custom_dataset_info.json', device_map_config_path=None, device_max_memory=[], hub_token=None, gpu_memory_utilization=0.9, tensor_parallel_size=1, max_num_seqs=256, max_model_len=None, disable_custom_all_reduce=True, enforce_eager=False, vllm_enable_lora=False, vllm_max_lora_rank=16, lora_modules=[], tp=1, cache_max_entry_count=0.8, quant_policy=0, vision_batch_size=1, self_cognition_sample=0, train_dataset_sample=-1, val_dataset_sample=None, safe_serialization=None, model_cache_dir=None, merge_lora_and_save=None, custom_train_dataset_path=[], custom_val_dataset_path=[], vllm_lora_modules=None, to_peft_format=False, to_ollama=False, ollama_output_dir=None, gguf_file=None, quant_bits=0, quant_n_samples=256, quant_seqlen=2048, quant_device_map='cpu', quant_output_dir=None, quant_batch_size=1, push_to_hub=False, hub_model_id=None, hub_private_repo=False, commit_message='update files', to_megatron=False, to_hf=False, megatron_output_dir=None, hf_output_dir=None, pp=1)合并结果:
run sh: `/usr/local/miniconda3/envs/swift/bin/python /usr/local/miniconda3/envs/swift/lib/python3.10/site-packages/swift/cli/export.py --ckpt_dir /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873 --merge_lora true`
[INFO:swift] Successfully registered `/usr/local/miniconda3/envs/swift/lib/python3.10/site-packages/swift/llm/data/dataset_info.json`
[INFO:swift] No LMDeploy installed, if you are using LMDeploy, you will get `ImportError: cannot import name 'prepare_lmdeploy_engine_template' from 'swift.llm'`
[INFO:swift] Start time of running main: 2024-08-30 22:20:48.465926
[INFO:swift] ckpt_dir: /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873
[INFO:swift] Successfully registered `/data/service/swift/data/custom_dataset_info.json`
[INFO:swift] Setting model_info['revision']: master
[INFO:swift] Setting self.eval_human: True
[INFO:swift] Setting overwrite_generation_config: True
[INFO:swift] args: ExportArguments(model_type='qwen2-7b-instruct', model_id_or_path='/data/model/qwen2-7b-instruct', model_revision='master', sft_type='lora', template_type='qwen', infer_backend='vllm', ckpt_dir='/data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873', result_dir=None, load_args_from_ckpt_dir=True, load_dataset_config=False, eval_human=True, seed=42, dtype='fp16', model_kwargs=None, dataset=[], val_dataset=[], dataset_seed=42, dataset_test_ratio=0.01, show_dataset_sample=-1, save_result=True, system='You are a helpful assistant.', tools_prompt='react_en', max_length=None, truncation_strategy='delete', check_dataset_strategy='none', model_name=[None, None], model_author=[None, None], quant_method='awq', quantization_bit=0, hqq_axis=0, hqq_dynamic_config_path=None, bnb_4bit_comp_dtype='fp16', bnb_4bit_quant_type='nf4', bnb_4bit_use_double_quant=True, bnb_4bit_quant_storage=None, max_new_tokens=2048, do_sample=True, temperature=0.3, top_k=20, top_p=0.7, repetition_penalty=1.0, num_beams=1, stop_words=[], rope_scaling=None, use_flash_attn=None, ignore_args_error=False, stream=True, merge_lora=True, merge_device_map='auto', save_safetensors=True, overwrite_generation_config=True, verbose=None, local_repo_path=None, custom_register_path=None, custom_dataset_info='/data/service/swift/data/custom_dataset_info.json', device_map_config_path=None, device_max_memory=[], hub_token=None, gpu_memory_utilization=0.9, tensor_parallel_size=1, max_num_seqs=256, max_model_len=None, disable_custom_all_reduce=True, enforce_eager=False, vllm_enable_lora=False, vllm_max_lora_rank=16, lora_modules=[], tp=1, cache_max_entry_count=0.8, quant_policy=0, vision_batch_size=1, self_cognition_sample=0, train_dataset_sample=-1, val_dataset_sample=None, safe_serialization=None, model_cache_dir=None, merge_lora_and_save=None, custom_train_dataset_path=[], custom_val_dataset_path=[], vllm_lora_modules=None, to_peft_format=False, to_ollama=False, ollama_output_dir=None, gguf_file=None, quant_bits=0, quant_n_samples=256, quant_seqlen=2048, quant_device_map='cpu', quant_output_dir=None, quant_batch_size=1, push_to_hub=False, hub_model_id=None, hub_private_repo=False, commit_message='update files', to_megatron=False, to_hf=False, megatron_output_dir=None, hf_output_dir=None, pp=1)
[INFO:swift] Global seed set to 42
[INFO:swift] replace_if_exists: False
[INFO:swift] merged_lora_path: `/data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873-merged`
[INFO:swift] merge_device_map: auto
[INFO:swift] device_count: 1
[INFO:swift] Loading the model using model_dir: /data/model/qwen2-7b-instruct
[INFO:swift] model_kwargs: {'low_cpu_mem_usage': True, 'device_map': 'auto'}
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [02:05<00:00, 31.46s/it]
[INFO:swift] model.max_model_len: 32768
[INFO:swift] generation_config: GenerationConfig {"do_sample": true,"eos_token_id": 151645,"max_new_tokens": 2048,"pad_token_id": 151643,"temperature": 0.3,"top_k": 20,"top_p": 0.7
}[INFO:swift] PeftModelForCausalLM: 7619.0572M Params (0.0000M Trainable [0.0000%]), 234.8828M Buffers.
[INFO:swift] system: You are a helpful assistant.
[INFO:swift] Merge LoRA...
[INFO:swift] Saving merged weights...
[INFO:swift] Successfully merged LoRA and saved in /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873-merged.
[INFO:swift] Setting args.sft_type: 'full'
[INFO:swift] Setting args.ckpt_dir: /data/model/sft/qwen2-7b-instruct-sft/qwen2-7b-instruct/v0-20240830-152615/checkpoint-873-merged
[INFO:swift] End time of running main: 2024-08-30 22:24:23.811071合并后的文件: