-
问题描述
凌晨跑批出现超时。SQL f0ng33agbpzhs业务需要执行160w次左右。现场人员杀掉该sql,重新发起业务,业务批次成功跑完。
-
问题分析
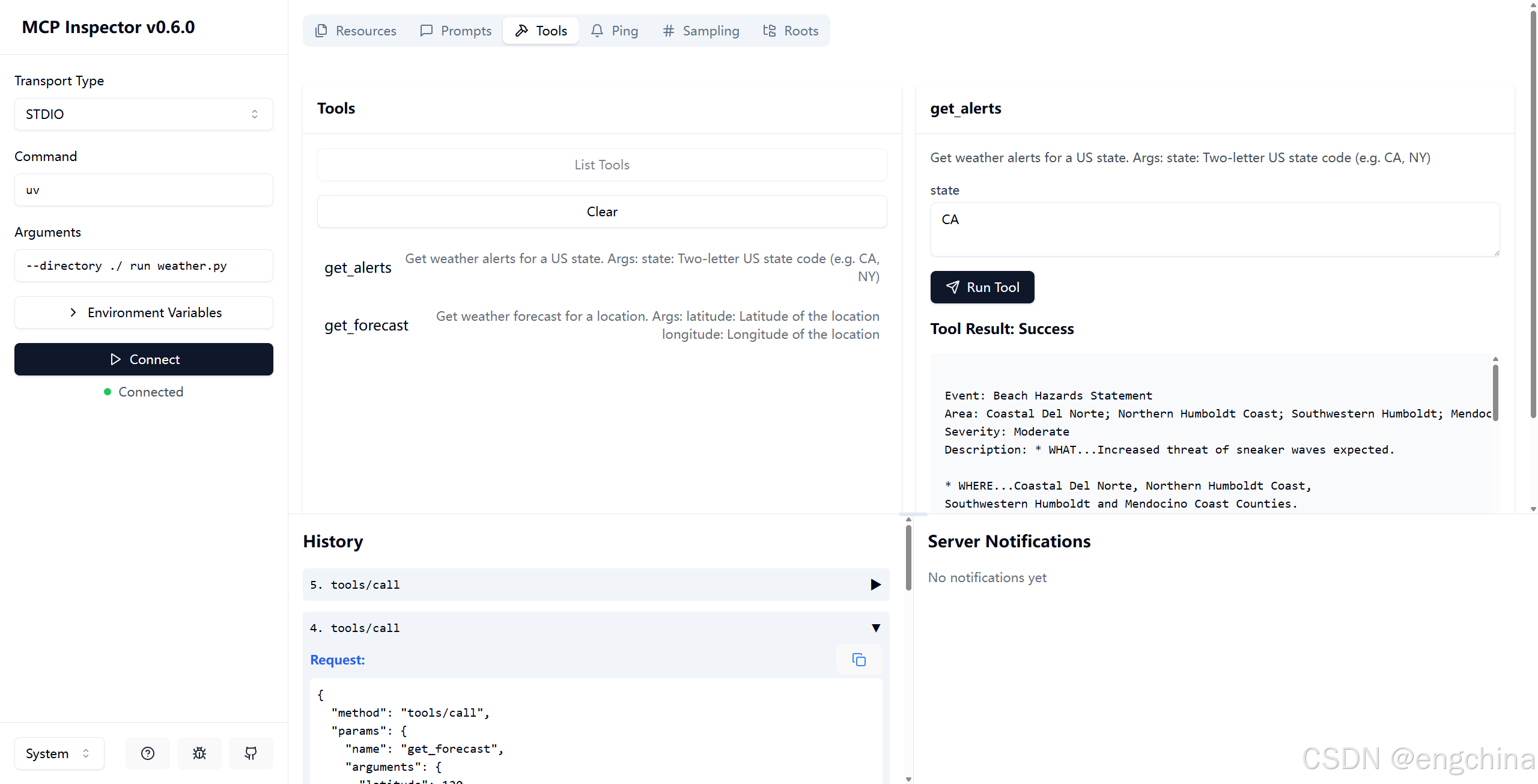
- 总体sql分析
分析对比sql的awrsqrpt,对比昨天3月8日的。

总体执行次数没有变化。Cpu时间、物理读等均在相同量级。
Cluster wait time异常
需要判断该sql是均匀的消耗cluster时间增加,还是某条sql出现的异常
-
- 0点-2点的awr中
等待事件现象诡异,gc current request出现1次,但是等待时间极长。这种情况下,基本可以确定是单条sql的问题,而不是每条sql的缓慢。

对比sql这里,执行146w次,时间6200s

-
- 0点30-1点的awr中
出现该异常等待事件

该sql执行了6w次

-
- 1点-1点30的awr中
该sql执行次数为0,说明该sql已经完全卡住不执行了

-
- 1点30-2点的awr中
该sql执行次数为0,说明该sql已经完全卡住不执行了

-
- 2点-2点30的awr中
该sql执行了800来次,且这个时间段应是人为介入杀连接,重新发起job的时间段

-
-
Bug问题
-
根据现象,发现与bug 14195003现象接近,sql无限等待。文档中未提供补丁的解决方案。
Bug 14195003 Deadlock with "gc current request" and "gc buffer busy" is possible on RAC and wait forever
-
流程梳理
0点前该业务模块启动,在0点30-1点中,该异常bug出现,sql完全hang住。1-2点中间,该sql完全没有执行次数增加。跑批模块告警后,人工介入,在2点-2点30之间,将该会话杀死,并重新发起job。会话杀死解开了该bug死锁,然后又执行了约800次,该模块跑完。
-
建议办法
该bug的行程逻辑是4条进程形成的低概率gc事件死锁。2个节点各持有一个block,然后一致性读另一个节点他持有的block,且两节点上各有一条进程请求其他节点持有的该block的当前块
1、发现时及时杀掉任意4个会话中的一个,死锁即可解除。
2、业务上加强隔离性,该业务模块运行时,屏蔽其他节点涉及该部分业务。