作者: 尚雷5580 原文来源: https://tidb.net/blog/beeb9eaf
注:本文基于 TiDB 官网 董菲老师 《TiDB 数据库核心原理与架构(101) 》系列教程之 《Lesson 01 TiDB 数据库架构概述》内容进行整理和补充。
课程链接: https://learn.pingcap.cn/learner/course/960001
一、TiDB 体系架构
1.1 TiDB 五大核心特性
-
一键水平扩缩容
得益于存储与计算分离的架构,TiDB 支持按需对计算和存储进行在线扩缩容,过程对运维人员透明。 -
金融级高可用
数据通过多副本存储,使用 Multi-Raft 协议同步事务日志。只有多数副本写入成功,事务才会提交,确保数据强一致性。即使少数副本故障,数据仍然可用,且副本位置和数量可按需配置以满足容灾需求。 -
实时 HTAP
TiDB 提供 TiKV(行存储)和 TiFlash(列存储)两种存储引擎,TiFlash 实时从 TiKV 复制数据,确保数据一致性。不同引擎可以部署在不同机器上,实现 HTAP 资源隔离。 -
云原生分布式数据库
TiDB 专为云设计,借助 TiDB Operator 实现云环境下的自动化和工具化部署,支持公有云、私有云和混合云。 -
兼容 MySQL 协议与生态
TiDB 完全兼容 MySQL 协议及常用功能,支持应用快速从 MySQL 迁移,并提供丰富的数据迁移工具。
1.2 TiDB 体系架构图
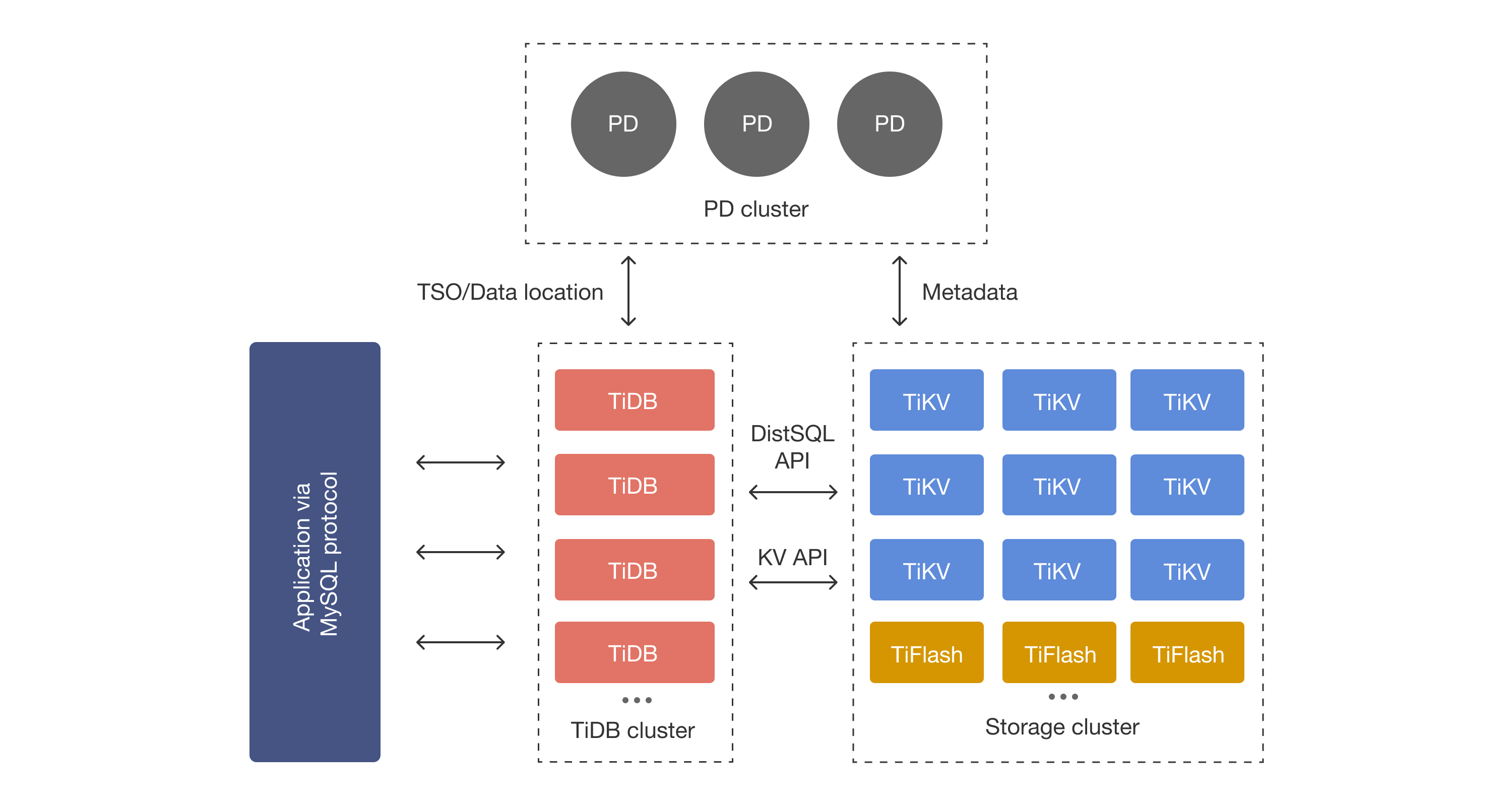
上述TiDB 架构图展示了 TiDB 系统中的各个组件及它们之间的交互方式,核心组件包括 TiDB Server、TiKV、PD(Placement Driver)集群、TiFlash,整个系统旨在支持混合事务和分析处理 (HTAP) 的场景。
<!-- 小贴士 -->在 TiDB V2 版本时,TiDB 引入了 TiSpark 组件,旨在借助 Apache Spark 的分布式计算能力,为用户提供快速处理大规模数据集的分析和查询功能。
从 TiDB 4.0 版本开始,TiFlash 组件被引入,并逐渐成为 TiDB 进行 OLAP 查询的首选工具。TiFlash 通过列存储和 MPP(大规模并行处理) 模式,显著提升了数据分析效率。
TiSpark 是 TiDB 早期的大规模数据分析解决方案,尤其是在 TiFlash 出现之前,它是主要的分布式 OLAP 查询工具。
尽管 TiFlash 后来成为 OLAP 的首选组件,但 TiSpark 并未被取代。它仍在需要复杂分布式计算的场景中使用,尤其是 Apache Spark 提供的丰富数据处理能力,使 TiSpark 在特定应用场景下依然有重要价值。
1.3 各组件核心功能
1.3.1 TiDB Server
在 TiDB 集群架构中,TiDB Server 作为前端的 SQL 处理组件,负责接收并解析来自应用程序的 SQL 请求。TiDB 完全兼容 MySQL 5.7 语法,这使得现有的 MySQL 用户可以无缝迁移到 TiDB,并继续使用他们熟悉的 SQL 语句进行操作。TiDB Server 的一个重要特性是**无状态**设计。数据不存储在 TiDB Server 上,而是存储在 TiKV/TiFlash 集群中。TiDB Server 的任务是处理 SQL 语句的生命周期:包括**解析**语法、**编译**查询、**优化**执行路径,以及生成最终的**执行计划**。生成的执行计划会被下发到 TiKV(TiDB 的分布式存储引擎)执行,确保高效的数据操作。由于 TiDB Server 无状态,它具备出色的**横向扩展性**。在高并发场景下,当大量 session 会话集中访问某个 TiDB Server 节点时,可以通过简单地增加新的 TiDB Server 节点来扩展集群的吞吐能力。这种横向扩展机制可以迅速均衡集群中的负载,减少单个节点的压力,保持系统的稳定性与高效性。
1.3.2 Storage Cluster
TiKV 是 TiDB 的存储引擎集群,负责持久化数据。虽然表结构是通过 SQL 语句如 `CREATE TABLE` 创建的,但数据并非直接以表的形式存储在 TiKV 上。相反,数据表会被 TiDB Server 转换为一个个**存储单元**,这些单元称为**Region**。每个 Region 的大小通常在 96MB 到 144MB 之间,一个表会被切分为多个 Region,分布式存储在 TiKV 集群中。TiKV 使用 **Raft 协议** 为每个 Region 提供高可用性。默认情况下,每个 Region 会有三个副本,分布在不同的节点上,以确保数据的可靠性。根据实际需求,副本数量可以灵活配置,例如配置为五副本来提高容错能力。Raft 协议保证了即使部分节点出现故障,数据仍然可用。TiKV 集群具备良好的**水平扩展性**,当存储需求增加或减少时,可以通过增加或减少 TiKV 节点的数量实现**弹性扩展**或**缩容**,满足业务需求的动态变化。此外,TiKV 实现了**分布式事务**和**多版本并发控制(MVCC)**,使其能够处理高度一致性和复杂事务的场景。关于分布式事务的细节将在后续章节中深入探讨。TiFlash 是 TiDB 生态中的另一种存储引擎,它存储的数据与 TiKV 相同,同样基于 Region 的结构。然而,TiKV 采用**行存**的存储方式,而 TiFlash 则是**列存**。列存擅长处理大规模的分析型查询,特别适用于需要对大表进行统计分析的场景。
1.3.3 PD Cluster
PD(Placement Driver) 是 TiDB 集群的核心组件之一,通常被称为 TiDB 集群的“大脑”,其主要职责是管理集群的**元数据信息**。可以通过一个例子来说明:假设表 T 的数据被切分成多个 Region,这些 Region 分布在多个 TiKV 或 TiFlash 节点上,PD 负责记录这些 Region 与存储节点之间的对应关系,这些信息即为**元数据**,并存储在 PD 集群中。当 TiDB Server 解析、编译并优化完一条 SQL 语句后,生成的执行计划需要查询表 T1 的数据。此时,TiDB Server 首先会向 PD 查询表 T1 的元数据信息,以确定该表的数据分布在哪些 TiKV 或 TiFlash 节点上。PD 还负责管理 TiDB 中的**全局时间戳**。每条 SQL 语句在执行时都会获取一个**TSO(Timestamp Oracle)**,这是一个唯一且单调递增的时间戳,用于标识 SQL 语句的开始时间。与传统的时、分、秒表示不同,TSO 像一个不断增长的计时器,确保了 SQL 执行的全局顺序。在事务处理中,每个事务有两个关键的 TSO:一个是**开始 TSO**,另一个是**提交 TSO**,这两个时间戳帮助保证了分布式事务的正确性和一致性。在后续章节中,我们将深入讨论 PD 的工作原理和实现细节。
二、各组件核心作用介绍
2.1 TiDB Server 核心作用
TiDB Server 作为 TiDB 的核心组件,主要职责包括:
- 处理客户端连接
- 解析与编译 SQL 语句
- 关系型数据与 KV 转换
- 执行 SQL 语句
- 执行在线 DDL 操作
- 垃圾回收
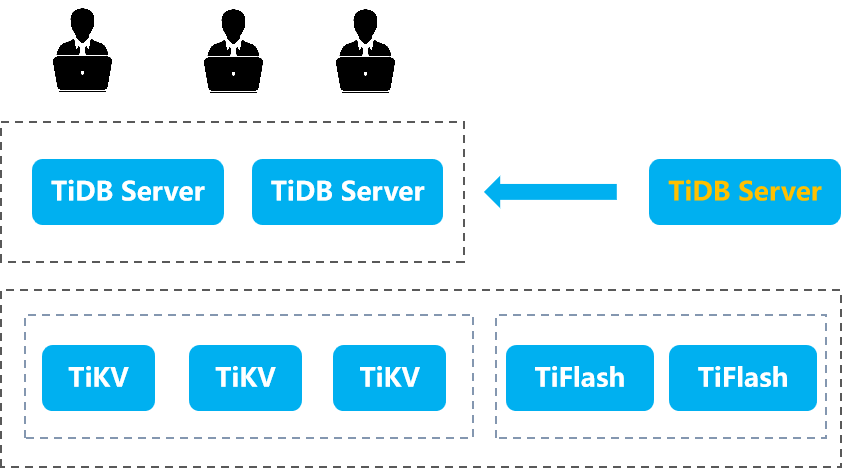
当用户发起会话连接 TiDB 时,首先到达的是 TiDB Server。TiDB Server 作为 SQL 请求的前端处理组件,当会话数激增,导致节点资源不足时,可以通过**动态扩容**来增加 TiDB Server 节点,从而分担负载。由于 TiDB Server **不存储数据**,扩容可以快速有效地分流各节点的会话压力。而在会话数量下降时,还可以灵活地**回收节点**,以提高资源利用率。对于一条 SQL 语句,TiDB Server 不会立即执行,而是首先对 SQL 进行**解析**和**编译**,生成一个**执行计划**。执行计划类似于一个操作指南,指引 TiDB 该如何执行 SQL,例如是否应该使用索引或进行全表扫描。TiDB Server 的角色就是将 SQL 转换为执行计划,随后通过该计划在后端的 TiKV 或 TiFlash 上执行数据操作。在数据插入过程中,TiDB Server 还负责将表数据转换为**键值对(key-value)\**格式。与传统数据库逐行存储不同,TiDB 以键值对的方式组织数据。TiDB Server 将表数据转换为键值对后,分发到 TiKV 或 TiFlash 存储引擎中,后者会将这些键值对进一步组织成多个\**Region**,以实现分布式存储。此外,TiDB Server 还处理一系列的 **DDL(数据定义语言)** 操作,如建表、创建索引等。值得注意的是,TiDB 的 DDL 操作不会阻塞线上业务,确保了系统的高可用性和稳定性。TiDB Server 另一个重要功能是**垃圾回收(GC)**。当 TiKV 或 TiFlash 中的表数据经历多次更新时,会产生大量历史版本数据。随着历史版本的增加,存储占用会不断扩大,并且可能导致查询性能下降。为此,TiDB Server 会定期(默认每 10 分钟)对 TiKV 和 TiFlash 中的历史数据进行清理,删除不再需要的旧版本记录,进而提升查询性能并减少存储开销。
<!-- 小贴士 -->TiDB 使用 MVCC(多版本并发控制) 来实现事务。新写入的数据不会直接覆盖旧数据,而是保留多个版本,并通过时间戳区分。为了避免历史数据积累,垃圾回收(GC) 机制用于清理不再需要的旧版本数据。
GC 机制:
1) GC Leader 选举: 一个 TiDB 实例会被选举为 GC Leader,负责控制集群中的 GC 操作。
2) 定期触发: GC 默认每 10 分钟触发一次。
3) Safe Point 计算: GC 首先计算出一个 safe point(安全时间点),它是当前时间减去 GC life time(默认 10 分钟)。GC 会删除早于 safe point 的过期数据,确保 safe point 之后的快照数据正确。
4) 事务保护: 如果有长时间运行的事务,GC 不会删除该事务开始之前的数据,确保事务的一致性和可用性。
5) 顺序执行:如果一次 GC 运行时间较长,下一轮 GC 不会在当前 GC 结束前启动。
# 注意,不同TiDB 版本,GC机制略有不同,比如从 TiDB 5.0 版本开始,CENTRAL GC 模式(需要 TiDB 服务器发送 GC 请求到各个 Region)已被废弃。自 TiDB 3.0 版起默认的 DISTRIBUTED GC 模式 成为唯一运行模式。此模式下,GC 由各个节点分布式执行,无需集中请求,提高了系统的效率和稳定性。
2.2 TiKV 核心作用
TiKV作为TiDB的一个重要组件,其主要职责如下所示:
- 数据持久化
- 副本的强一致性和高可用性
- MVCC (多版本并发控制)
- 分布式事务支持
- Coprocessor (算子下推)
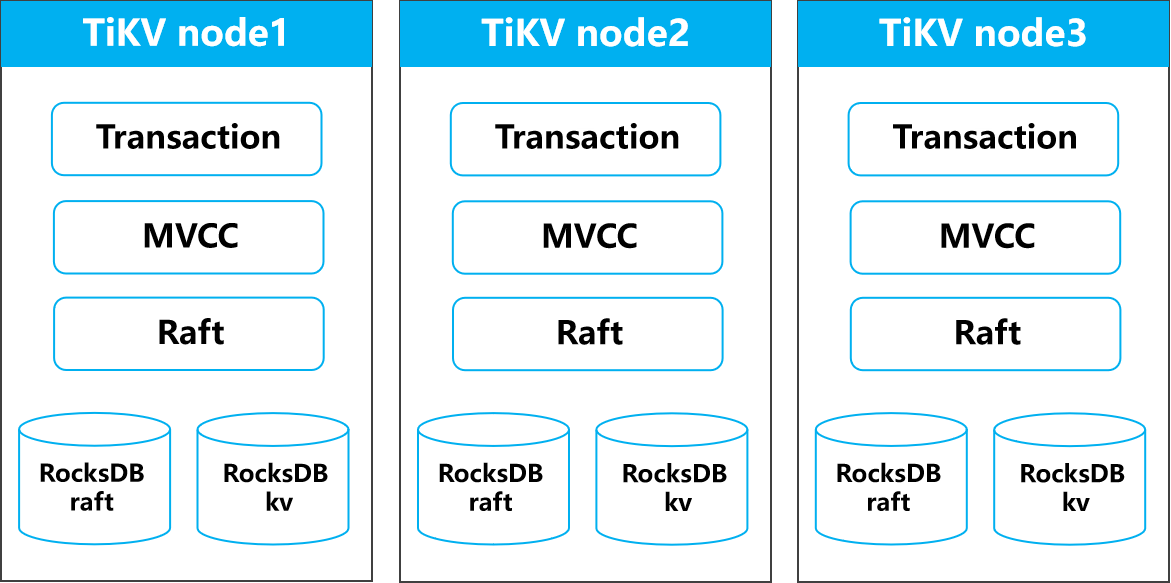
如上图所示,每个 TiKV 节点都包含事务处理层、MVCC 层、Raft 层以及 RocksDB 的存储支持,所有节点协同工作,确保分布式系统中的数据一致性、高可用性和高性能,接下来将分别介绍TiKV节点中个组成成分及TiKV核心功能。
2.2.1 RocksDB
作为一款分布式数据库,TiDB 的核心目标之一是确保**数据持久化**,避免数据丢失。在 TiDB 的存储引擎 TiKV 中,数据持久化是通过底层的 **RocksDB** 来实现的。RocksDB 是 TiKV 的核心存储引擎,每个 TiKV 实例中运行着两个 RocksDB 实例:一个是用于存储用户数据及 MVCC 信息的 **RocksDB kv**(简称 kvdb),另一个是用于存储 Raft 日志的 **RocksDB raft**(简称 raftdb)。
RocksDB kv 和 RocksDB raft:
- RocksDB kv :将表中的数据以 key 的形式存储在 kvdb 中。RocksDB kv 是一个单机的存储引擎,负责管理用户数据。
- RocksDB raft :负责存储对 kvdb 中 key 数据进行增删改操作的指令。在执行任何操作前,修改指令会首先存储在 raftdb 中,然后由 TiKV 将这些修改应用到 kvdb 中。
2.2.3 Raft
由于 TiDB 面向金融级应用,单机 RocksDB 无法满足高可用需求。因此,在 RocksDB 之上增加了 **Raft 协议** 这一层来确保数据的高可用性和一致性。Raft 的核心作用是通过多副本机制保障数据的一致性。每个 **Region**(存储单元,通常大小为 96MB)会在多个 TiKV 节点上存储多个副本,TiDB 默认配置三个副本。在这三个副本中,只有一个副本被选举为 **Leader**,负责读写操作,其余副本为 **Follower**,只能接收 Leader 的更新。当数据发生修改时,Raft 协议会首先将修改应用到 Leader 副本的 rocksdb kv 中,随后将该修改同步到其他两个 Follower 副本。只有当大多数副本确认接收到修改时,修改才算真正成功。通过这种方式,TiDB 实现了数据的**强一致性**和**高可用性**。
<!-- 小贴士 -->
1) 自动化的多副本恢复
在 TiDB v6.1.0 之前,如果由于物理机故障导致多个 TiKV 的 Region 副本丢失,用户需要停机所有 TiKV 并使用 TiKV Control 逐一进行恢复。从 TiDB v6.1.0 开始,这一过程被完全自动化,用户不再需要停机,且恢复过程不会影响其他正常的在线业务。通过 PD Control 触发在线有损恢复数据,大大简化了恢复步骤,缩短了恢复时间,并提供了更加友好的恢复摘要信息。
2) 支持在线修改配置
在 TiDB v6.1.0 之前的版本中,配置参数的变更需要重启整个 TiDB 集群才能生效,这对在线业务造成了一定的影响。而在 TiDB v6.1.0 中,引入了在线修改配置的功能。现在,参数修改后无需重启即可生效,大幅提升了在线业务的灵活性和稳定性。
2.2.4 MVCC
在 Raft 之上,TiKV 实现了**MVCC(Multi-Version Concurrency Control)**,用于解决并发读写问题。MVCC 通过为每个 Key 存储多个版本的数据来实现。当客户端 A 正在写入一个 Key 时,客户端 B 可以同时读取这个 Key 的早期版本,而不会阻塞。这种多版本控制机制避免了读写操作之间的互斥冲突,极大提升了系统的并发性能。TiKV 中的 MVCC 是通过在 Key 后面附加一个版本号来实现的。每次写操作都会生成一个新的版本号,版本号较大的数据会被存放在前面,版本号较小的则存放在后面。通过这种机制,TiKV 能够根据 Key 和版本号查询出不同版本的数据。
2.2.5 Transaction
在高可用、持久化和 MVCC 基础上,TiDB 还实现了**分布式事务模型**,支持**两阶段提交**。TiDB 的事务机制确保了在分布式环境中,即使在多个节点上同时进行事务操作,数据的一致性依然能够得到保障。总结:可以将 TiKV 内部的这些层次结构类比为**TCP/IP 协议栈**。从最基础的 **RocksDB** 单机存储引擎开始,逐层添加协议:Raft 协议确保副本一致性,MVCC 解决并发冲突,分布式事务机制提供了可靠的事务管理。通过这些层次的组合,TiKV 实现了一个完整的、面向分布式场景的高可用数据库系统。
2.2.6 Coprocessor
Coprocessor 是 TiDB 中的一项关键技术,它充分发挥了**分布式计算**的优势。虽然 TiKV 存储引擎的数据分布在多个节点上,且跨节点访问可能会带来一定的网络延迟,但每个节点都配备了 CPU 资源,可以利用这些资源进行**本地计算**,从而减轻 TiDB Server 的计算负载。例如,当执行一个带有条件的查询 `WHERE age > 25` 时,传统数据库架构可能会将所有相关数据从存储引擎中读取到数据库服务器上,再进行条件过滤。而在 TiDB 中,通过 Coprocessor,可以将这个过滤操作下推到各个 TiKV 节点。在每个节点上直接执行 `age > 25` 的过滤操作,只返回符合条件的数据。这不仅减少了网络传输的数据量,还降低了 TiDB Server 的计算压力。除了基本的过滤操作,Coprocessor 还支持其他类型的计算下推,如**投影**(选择需要的列)和**聚合**操作。通过这些下推操作,TiDB 实现了一个**分布式计算模型**,将计算任务分发到多个存储节点上并行处理,从而提升了查询的执行效率。简言之,Coprocessor 利用存储节点的计算资源,使得分布式计算不仅仅是数据的分布式存储,更是在分布式环境中高效地执行计算操作。
<!-- 小贴士 -->
从 TiDB 4.0 版本开始,TiDB 支持下推计算结果缓存功能(Coprocessor Cache)。当该功能开启后,TiDB 实例会在本地缓存下推给 TiKV 的计算结果,从而在特定场景下显著提升查询性能。从 TiDB 5.0 GA 版本起,Coprocessor Cache 被默认开启,使查询过程更加高效。
Coprocessor 是 TiKV 中负责数据读取和计算的核心模块,其实现方式类似于 HBase 中的 Coprocessor 的 Endpoint 功能,也可以与 MySQL 的存储过程进行类比。
TiDB 从 4.0 起支持下推计算结果缓存(即 Coprocessor Cache 功能)。开启该功能后,将在 TiDB 实例侧缓存下推给 TiKV 计算的结果,在部分场景下起到加速效果。
从5.0 GA开始 默认开启 Coprocessor cache 。
TiKV Coprocessor 主要处理的读请求可以划分为以下三类:
DAG(Directed Acyclic Graph)
描述:DAG 是 TiKV 执行物理算子的核心框架,它通过构建一个无环有向图来执行下推的 SQL 计算任务。在存储层执行计算,能够生成中间结果,从而减少 TiDB 的计算负担和网络传输压力。
应用场景:大多数 SQL 查询都会通过 DAG 下推到 TiKV 进行处理,包括表扫描、索引扫描、过滤、聚合和排序等操作。通过分布式执行这些操作,可以显著提升查询效率。
特点:DAG 是 Coprocessor 的核心任务,在实际场景中,它通过在 TiKV 上分布式执行 SQL 任务,有效降低了 TiDB 的计算开销和网络延迟。
Analyze
描述:Analyze 请求用于分析表或索引的数据分布情况,生成统计信息,以帮助 TiDB 优化器做出更高效的查询计划。
应用场景:当执行 ANALYZE TABLE 命令时,TiDB 将分析任务下推到 TiKV,统计数据包括表的行数、列的数据分布以及直方图等。这些统计信息会被持久化并供优化器使用,从而生成更优的执行计划。
特点:Analyze 请求对查询性能优化至关重要,尤其是在数据频繁更新的场景下。优化器依赖最新的统计信息,确保查询计划能够最大化利用现有资源。
CheckSum
描述:CheckSum 请求用于在数据导入或迁移后验证数据一致性。它通过计算表的 CheckSum 值,确保数据在不同节点或存储引擎之间的一致性。
应用场景:CheckSum 通常用于数据迁移后的验证。例如,在使用 TiDB Lightning 导入大量数据后,CheckSum 可以确保导入数据与源数据完全一致。
特点:CheckSum 提供了一种有效的数据一致性校验机制,尤其适用于数据导入和跨存储引擎操作,确保数据完整准确。
# 更多关于Coprocessor的内容可参考 《TiKV 源码解析系列文章(十四)Coprocessor 概览》 和 《TiKV 源码解析系列文章(十六)TiKV Coprocessor Executor 源码解析》 两篇文章
2.3 PD 核心作用
Placement Driver(PD)是 TiDB 数据库的核心组件,主要职责包括:
- 存储 TiKV 集群的元数据
- 分配全局 ID 和事务 ID
- 生成全局时间戳(TSO)
- 收集集群信息并进行调度
- 提供 TiDB Dashboard 服务
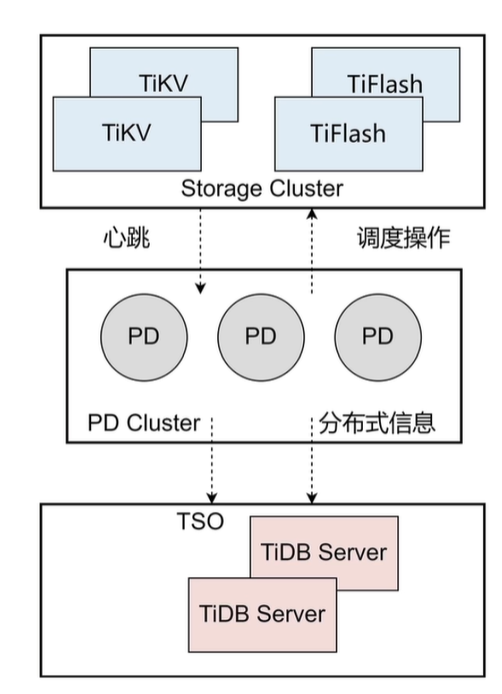
当 SQL 语句在 TiDB Server 中执行时,首先需要了解目标数据在哪些 TiKV 节点上存储。这些**元数据信息**由 PD 组件管理,PD 会向 TiDB Server 提供相应的信息,指引其前往正确的 TiKV 节点获取表 T 的数据。此外,PD 还负责分配诸如表 ID、事务 ID 等**全局唯一标识符**。每条用户发起的 SQL 语句在开始执行时,都需要生成一个**TSO(Timestamp Oracle)**,即一个全局时间戳。PD 通过其授时功能生成 TSO,并将其提供给 TiDB Server。对于事务操作,TSO 同样用于记录事务的开始时间和提交时间,确保在分布式系统中事务的顺序性和一致性。在 TiKV 中,表的数据是分布式存储的。随着表的增删改操作增多,某些表的 Region 可能会过度集中在某个 TiKV 节点上,导致该节点的负载不均衡,产生性能瓶颈。为了避免这种情况,TiKV 节点会定期向 PD 汇报其状态,包括 Region 的分布和读写压力等信息。PD 会根据这些信息进行**负载调度**,将某些 Region 迁移到负载较低的 TiKV 节点上,从而平衡集群中的数据分布和访问压力。
PD 还提供了 TiDB Dashboard ,一个集成的可观测性工具。通过 PD,用户可以监控集群的运行状况,包括热力图、TOP SQL 等重要的监控指标,这有助于运维人员快速发现并解决性能瓶颈。
<!-- 小贴士 -->
每个 Raft Group 的 Leader 会定期向 PD 发送心跳包,汇报 Region 的状态。心跳信息主要包括以下内容:
1) Leader 的位置
2) Followers 的位置
3) 掉线副本的数量
4) 数据的读写速度
PD 通过这些心跳消息持续收集集群的状态信息,并基于这些数据做出调度决策。
2.4 TiFlash 核心作用
TiFlash 是 TiDB 的一个核心组件,其主要职责包括:
-
异步复制
-
数据一致性
-
列存储提高分析查询效率
-
业务隔离
-
智能选择优化查询
TiDB 集群的数据默认存储在 TiKV 中,并以三副本的形式确保数据的高可用性和一致性。与此同时, TiFlash 也会维护一份与 TiKV 数据一致的副本。不同于 TiKV 的行存储,TiFlash 采用 列存储 ,以便更高效地支持分析型(OLAP)工作负载。尽管存储方式不同,TiFlash 的数据始终与 TiKV 保持一致,通过实时复制机制,TiKV 中的数据修改会及时同步到 TiFlash。
在 TiDB 中,**TiKV** 更适合处理**事务型负载(OLTP)**,而 **TiFlash** 的列存优势使其更适合处理**分析型负载(OLAP)**。引入 TiFlash 的目的是增强 TiDB 在分析性业务场景中的性能,并且通过数据的分离存储,TiFlash 还能够实现业务的隔离,避免 OLTP 和 OLAP 任务相互干扰。TiDB 的智能优化器具备**智能选择**功能,能够根据 SQL 语句的类型和负载预测,决定是否在 TiKV(OLTP)或 TiFlash(OLAP)中执行查询。对于复杂的分析性查询,优化器会自动选择 TiFlash 执行,从而提升分析性能。当然,用户也可以通过手动设置,在 TiDB Server 中指定 SQL 在特定存储引擎中运行,以满足不同场景下的业务需求。通过同时支持 OLTP 和 OLAP,TiDB 实现了 **HTAP(Hybrid Transactional and Analytical Processing)**,兼具事务处理和分析处理能力,为用户提供了统一的存储和计算平台,适应多样化的业务需求。
三、附录(TiSpark介绍)
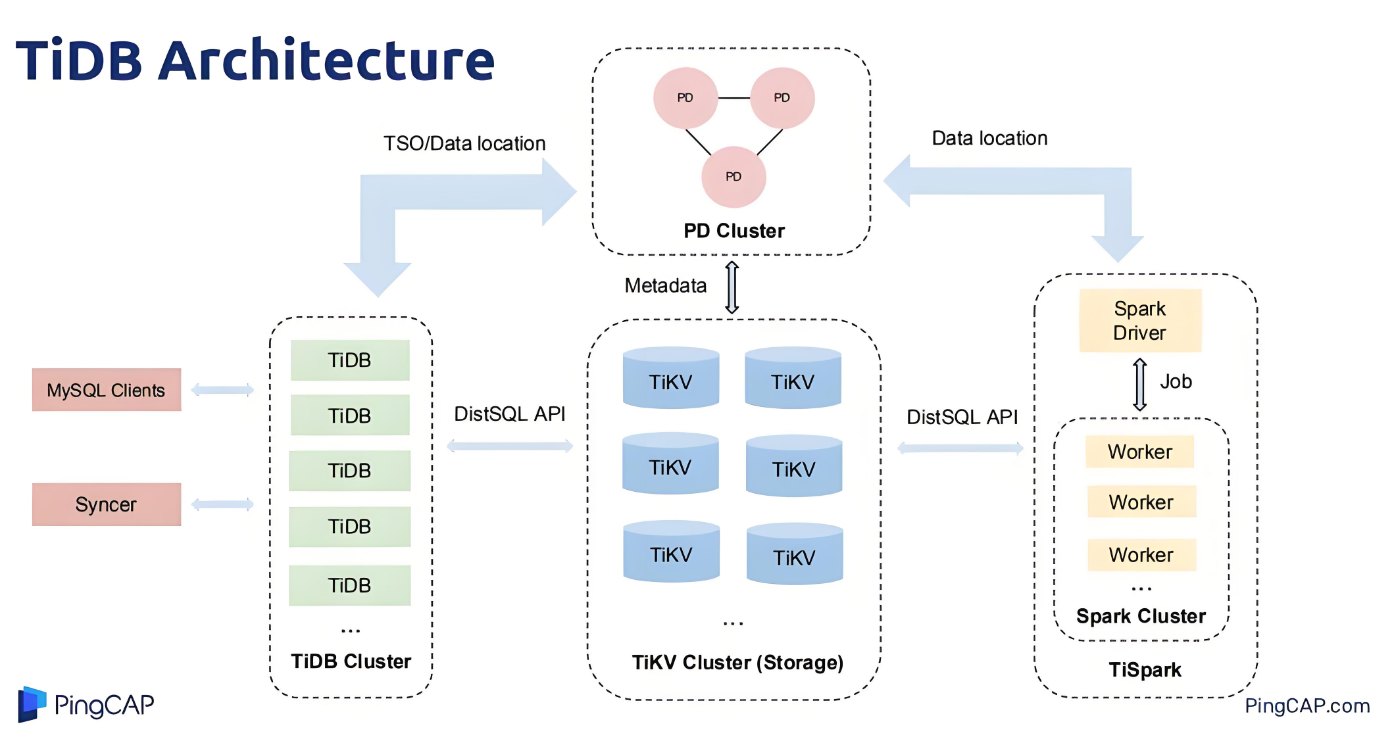
上图是TiDB V2 版本体系架构图,在该图中,可以看到 TiDB 体系架构中含有 TiSpark组件,没有TiFlash组件。
TiSpark 是 TiDB 从 V2 版本 开始引入的分布式计算组件,利用 Apache Spark 的计算能力,提供大规模数据集的快速分析和查询功能。随着 TiDB 4.0 引入 TiFlash 组件,TiSpark 的部分功能逐渐被 TiFlash 替代,尤其在 OLAP 查询上,TiFlash 成为首选。然而,TiSpark 仍然在复杂分布式计算场景中发挥作用,特别是 Apache Spark 提供的丰富数据处理能力,依然是 TiDB 生态中的重要工具。
TiSpark的最要职责如下:
- 分布式数据分析 TiSpark 允许用户直接在 TiDB 和 TiKV 的数据上运行分布式计算任务,支持大规模并行计算,提升数据分析效率,无需将数据导出。
- 读取 TiKV 数据 TiSpark 可直接读取 TiKV 中的数据,利用 Spark 分布式引擎执行查询和分析,实现高效的数据读取和下推计算。
- 与 TiDB SQL 的无缝集成 支持同时使用 TiDB SQL 和 Spark SQL 查询同一数据集,结合 TiDB 的事务能力和 Spark 的分析能力,提供事务与分析的混合处理。
- 支持复杂 SQL 查询 TiSpark 支持复杂 SQL 查询,如 JOIN、GROUP BY、FILTER、ORDER BY 等,并可将部分计算任务下推到 TiKV,提升查询性能。
- 高效的分区和分片管理 自动获取 TiKV 的分区和分片信息,确保 Spark 任务高效并行处理,利用 TiKV 的存储结构减少数据传输。
- 支持 HTAP 场景 TiSpark 支持 HTAP 场景,在处理事务负载的同时进行大规模分析,保证分析与事务数据的一致性。
- 优化器与 Spark Catalyst 集成 集成 Spark Catalyst 优化器,智能优化查询执行计划,选择最佳执行路径,进一步提升性能。
- 与 TiFlash 协作 随着 TiDB 4.0 引入 TiFlash,TiSpark 的部分功能逐渐被 TiFlash 替代。TiFlash 专为 OLAP 设计,通过列存储和 MPP 模式显著提升分析任务的性能。