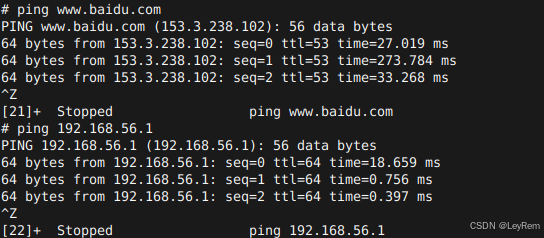
在 MySQL 数据库的操作中,子查询是一个强大而又复杂的工具。今天,我们就来深入探讨 MySQL 如何执行子查询、其性能影响、优化方法以及哪些情况下应避免使用子查询。
一、MySQL 如何执行子查询
-
非相关子查询
- 非相关子查询也被称为独立子查询,它可以独立于外部查询进行执行。MySQL 通常会先执行子查询,得到一个结果集,这个结果集可能会被存储在临时表中(如果结果集较大,可能会存储在磁盘上)。然后,外部查询使用这个临时表中的结果进行进一步的查询操作。
- 例如:
SELECT * FROM table1 WHERE column1 > (SELECT AVG(column2) FROM table2);,这里先计算出table2中column2的平均值,然后table1的查询再利用这个结果进行筛选。
-
相关子查询
- 相关子查询与外部查询相关,子查询的执行依赖于外部查询的值。对于外部查询的每一行,子查询都要重新计算一次。
- 例如:
SELECT * FROM table1 WHERE column1 > (SELECT MAX(column2) FROM table2 WHERE table1.id = table2.id);,这里对于table1的每一行,都要根据该行的id值去计算table2中对应的最大column2值。
二、子查询的性能影响
-
性能开销
- 非相关子查询如果结果集较大,存储临时表可能占用大量内存或磁盘空间,这会增加查询的执行时间。
- 相关子查询由于需要为外部查询的每一行执行一次,可能会导致大量的重复计算,尤其是在处理大型数据集时,性能下降会更加明显。
-
对查询优化器的挑战
- 子查询可能会使查询优化器的工作变得更加复杂。优化器需要考虑如何高效地执行子查询以及外部查询,这可能会导致一些复杂的执行计划,从而影响性能。
三、子查询性能优化方法
-
使用连接替代子查询
- 在很多情况下,可以使用连接(JOIN)来替代子查询,以提高性能。连接通常可以更高效地处理大数据集,并且查询优化器更容易对连接进行优化。
- 例如,上面的非相关子查询例子可以改写成连接的形式:
SELECT t1.* FROM table1 t1 JOIN (SELECT AVG(column2) AS avg_col2 FROM table2) t2 ON t1.column1 > t2.avg_col2;。
-
建立合适的索引
- 为涉及子查询的列建立合适的索引可以显著提高性能。对于非相关子查询,索引可以帮助快速获取子查询的结果集;对于相关子查询,索引可以减少每次子查询的执行时间。
-
避免不必要的子查询
- 有时候,我们可能会在查询中使用多个子查询,这可能会导致性能下降。在设计查询时,应尽量避免不必要的子查询,简化查询逻辑。
四、哪些情况下避免使用子查询
-
处理大型数据集时
- 当处理大型数据集时,子查询可能会导致性能问题。在这种情况下,应考虑使用连接或其他优化方法来替代子查询。
-
复杂的查询逻辑
- 如果查询逻辑非常复杂,包含多个子查询嵌套,可能会使查询难以理解和优化。此时,可以尝试重新设计查询,使用更简单的方法来实现相同的功能。
-
对性能要求高的场景
- 在对性能要求非常高的场景下,如实时交易系统或高并发的 Web 应用,应尽量避免使用子查询,以确保系统的响应速度。
在使用 MySQL 时,要谨慎使用子查询,并考虑其对性能的影响。通过合理的设计查询、建立索引以及选择合适的优化方法,我们可以提高查询性能,确保数据库的高效运行。同时,在某些情况下,我们应避免使用子查询,以获得更好的性能和可维护性。
文章(专栏)将持续更新,欢迎关注公众号:服务端技术精选。欢迎点赞、关注、转发。
个人小工具程序上线啦,通过公众号(服务端技术精选)菜单【个人工具】即可体验,欢迎大家体验后提出优化意见!