准备工作
一.OpenAi的Api
1.登录openai

2.点击Develovpers的overview
 ### 3.点击右上角的Login in
### 3.点击右上角的Login in
 ### 4.点击右上角的view apikey
### 4.点击右上角的view apikey
 ### 5.点击Creat new secret key
### 5.点击Creat new secret key
 这样就会得到一个chatgpt的api,请妥善保存这个api,当你关闭这个网页的时候,api就不可再见了。
这样就会得到一个chatgpt的api,请妥善保存这个api,当你关闭这个网页的时候,api就不可再见了。
二. 准备百度云的api
1.登录百度云
2.点击右上角登录或者注册账户即可
3.进入控制台,找到下图所示的语音技术
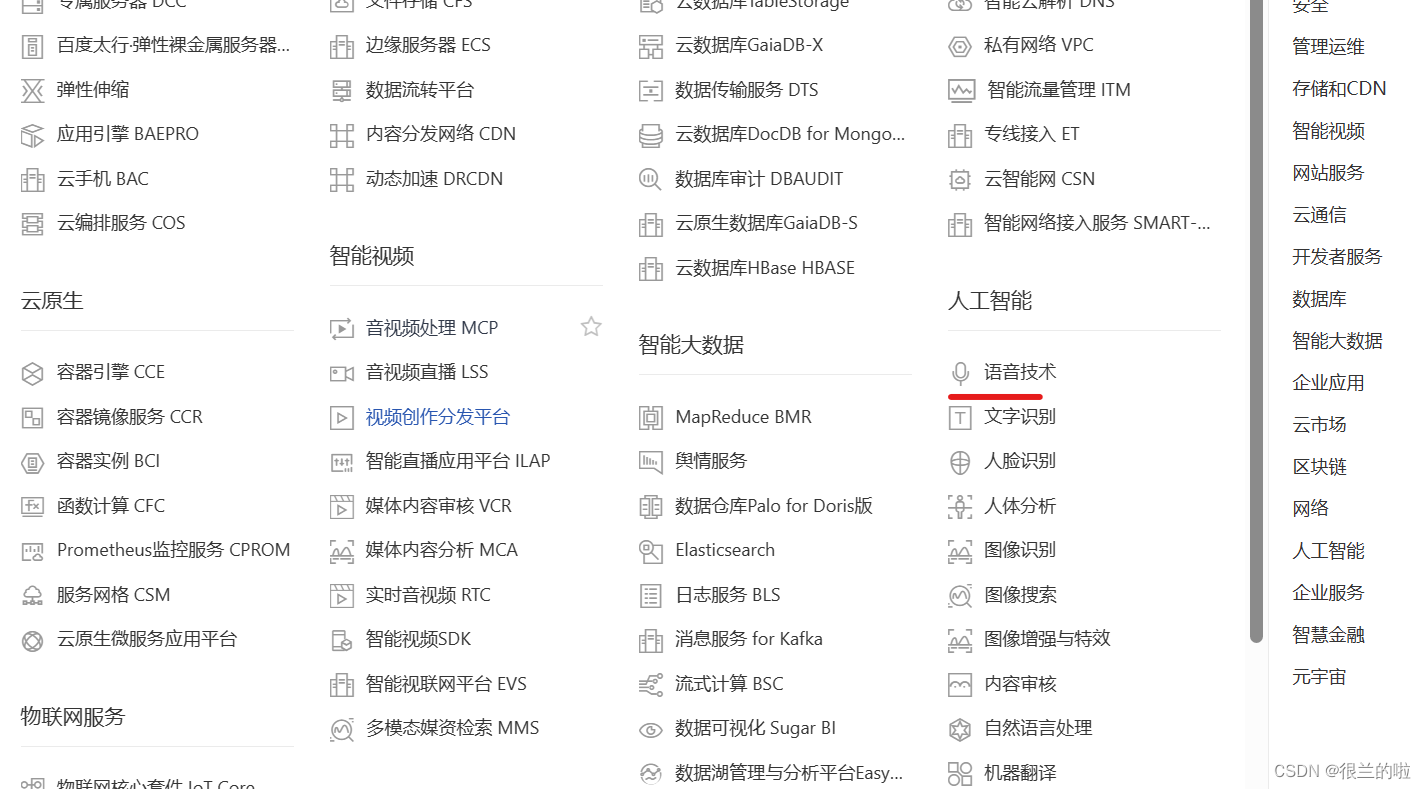 这个一般会有免费的资源赠送,点击领取后再创建资源。注意找到下图所示的AppID,API Key和Screat Key。妥善保存这三个,后面代码中会用到。
这个一般会有免费的资源赠送,点击领取后再创建资源。注意找到下图所示的AppID,API Key和Screat Key。妥善保存这三个,后面代码中会用到。

三.科学上网
这个不细说了,没有的话可以去网上搜一下教程,可能会用到。
代码部分
1.导入必须的库
下载导入下述的库
import speech_recognition as sr
from aip import AipSpeech
import openai
import pygame
import asyncio
import edge_tts
可以直接用pip下载,如果国内下载不成功的话可以试着用下面的命令下载。
pip install xxx(包名) -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
2.更换上面得到的api信息到代码中
APP_ID = 'XXX'
API_KEY = 'XXX'
SECRET_KEY = 'XXX'
openai.api_key = "XXX"
3.完整代码如下(可能需要用到全局代理)
import speech_recognition as sr
from aip import AipSpeech
import openai
import pygame
import asyncio
import edge_ttsAPP_ID = 'XXX'
API_KEY = 'XXX'
SECRET_KEY = 'XXX'allresult=""def rec(rate=16000):"""从系统麦克风拾取音频数据并保存为 wav 格式文件"""r = sr.Recognizer()with sr.Microphone(sample_rate=rate) as source:print("连接到麦克风...")print("请说话进行录音...")audio = r.listen(source) print("正在上传录音文件到百度语音服务...")with open("recording.wav", "wb") as f:f.write(audio.get_wav_data())return 1def listen():"""上传录音文件到百度语音服务,返回语音识别结果"""client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)with open('recording.wav', 'rb') as f:audio_data = f.read()results = client.asr(audio_data, 'wav', 16000, {'dev_pid': 1537})if 'result' in results:print("你说的是:" + results['result'][0])return results['result'][0]else: print("出现错误,错误代码:" , results['err_no'])def chat(prompt):"""与 OpenAI 文本 AI 进行聊天"""openai.api_key = "XXX"prompt = prompttry:response = openai.ChatCompletion.create(model="gpt-3.5-turbo",max_tokens=1024,top_p=1,frequency_penalty=0,presence_penalty=0,temperature=0.5,messages=[{"role": "user", "content": prompt}],timeout={"with":1000},)result = response.choices[0].message.contentprint("AI 回复:" + result)return result except Exception as e:print("API调用失败:", e)return Noneasync def speak(text=""):voice = "zh-TW-HsiaoChenNeural"output_file = "audio.mp3"communicate = edge_tts.Communicate(text, voice)await communicate.save(output_file)print(f"\n已将文本“{text}”转换为语音并保存为文件“{output_file}”。")def play():"""播放语音"""pygame.mixer.init()pygame.mixer.music.load("C:/Users/Emails/Desktop/py/audio.mp3")pygame.mixer.music.set_volume(0.5)pygame.mixer.music.play()while pygame.mixer.music.get_busy():passpygame.mixer.music.unload()# 语音识别并与 AI 进行聊天
def speech():while True:rec() # 保存录音文件:recording.wavtext = listen() # 自动打开录音文件recording.wav进行识别,返回 识别的文字存到textif '结束程序' in text: #这里我设置了一个结束语,说“结束程序”的时候就结束,你也可以改掉return "对话结束"text_1 = chat(text) # 将text中的文字发送给机器人,返回机器人的回复存到text_1asyncio.run(speak(text_1))play() #播放audio.mp3文件if __name__ == '__main__':speech()
4.将其保存为.py文件,点击运行即可
语音播放使用的是edge-tts,所以播放速度达到瓶颈,目前还没想到办法优化。
如果代码运行的过程出错,请查看上述的库是否正确安装。
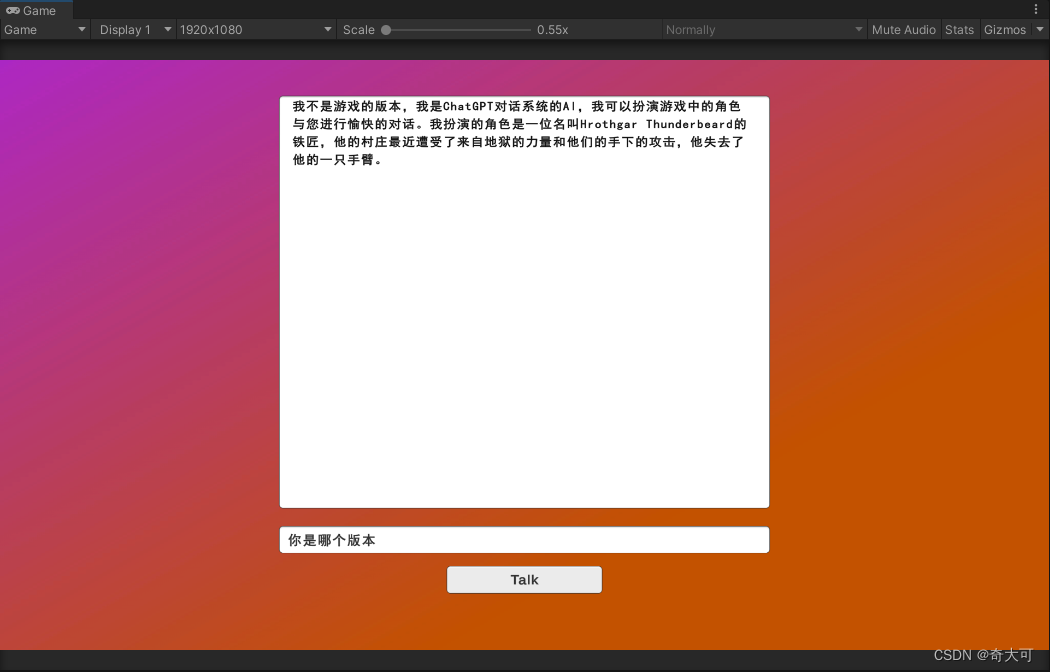
代码正确运行截图如下:
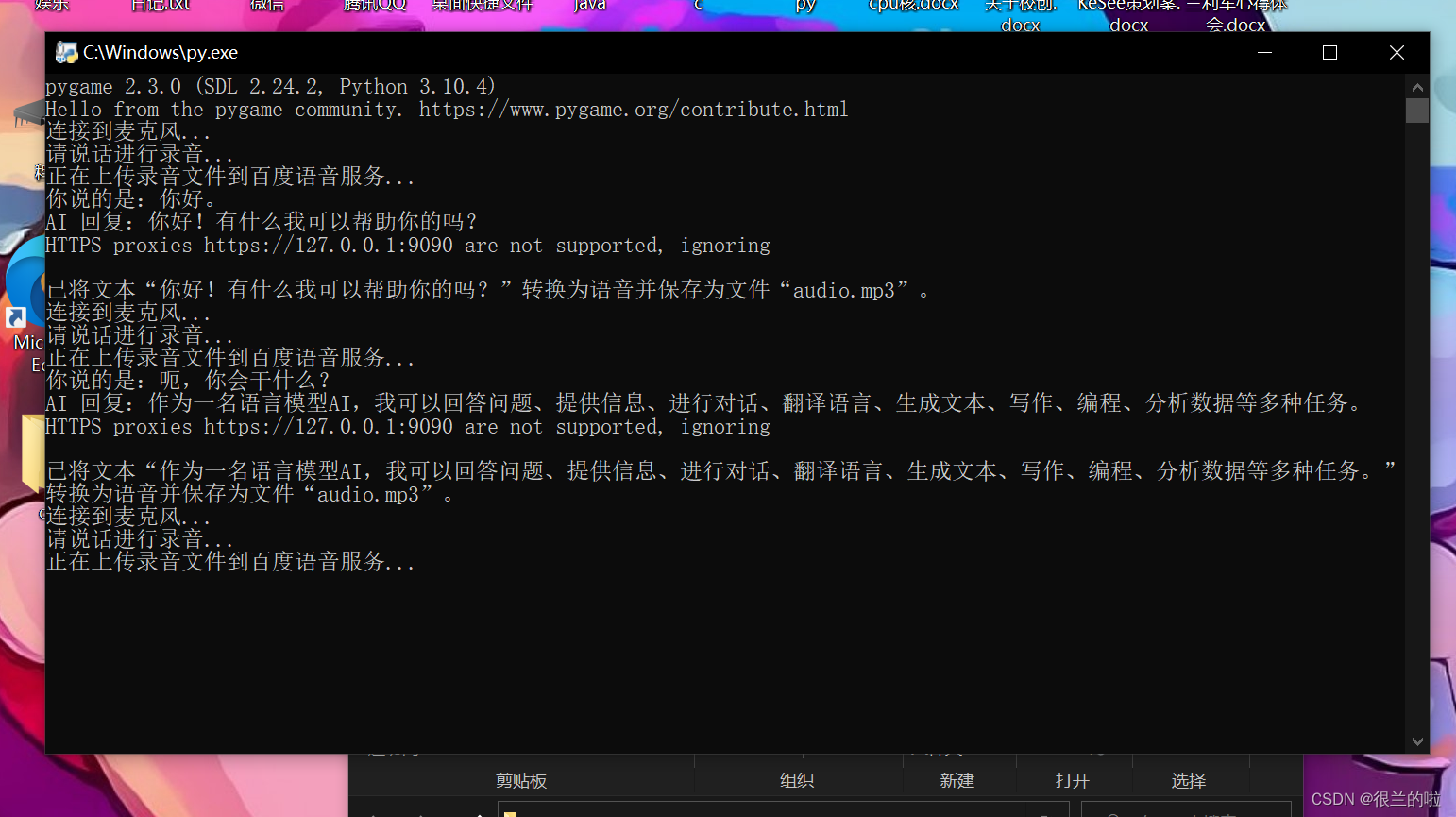 如果有什么好的优化方案,可以直接私我,哥们高强度在线!
如果有什么好的优化方案,可以直接私我,哥们高强度在线!








![[AHK]腾讯实时股票数据接口](https://img-blog.csdnimg.cn/img_convert/63c4353e68b96b789ab1cc39e6212f5e.png)