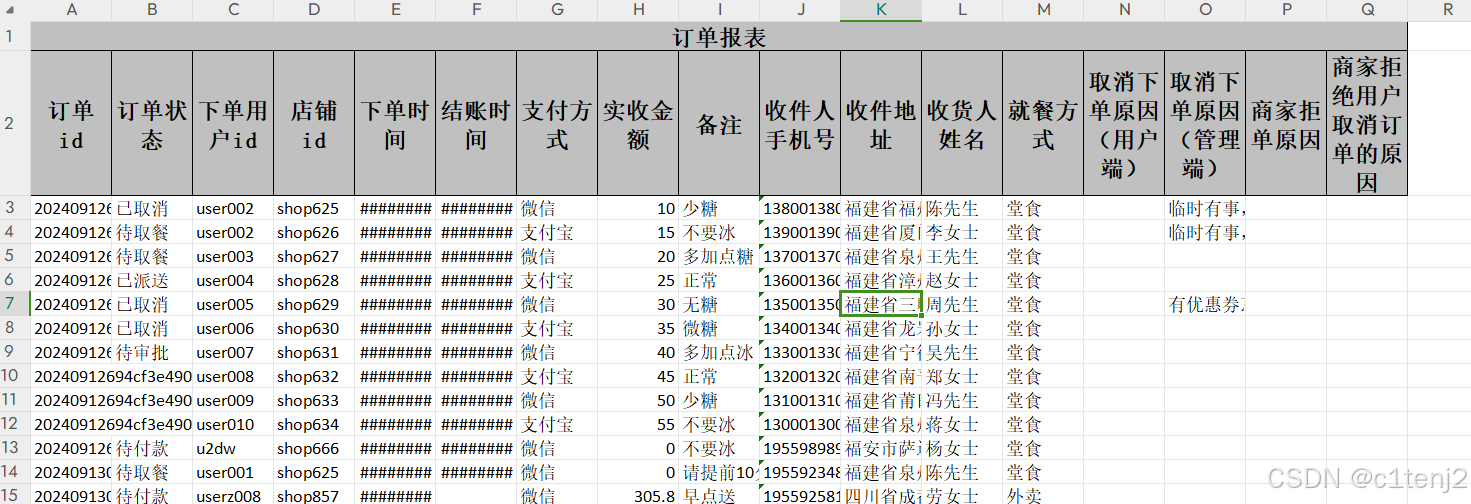
查询一条sql语句的流程
- 连接器:建立连接,管理连接、校验用户身份
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行(MSQL8.0 已删除)
- 解析 SQL:通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型(关键字和非关键字)
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将select中的符号扩展为表上的所有列
- 优化阶段:基于查询成本的考虑,选择查询成本最小的执行计划
- 执行阶段:根据执行计划执行 SQL查询语句,从存储引擎读取记录,返回给客户端

索引下推能够减少二级索引在査询时的回表操作,提高査询的效率,因为它将 Server 层部分负责的事情,交给存储引擎层去处理了。
示例:联合索引age和reward
select * from t user where age >20 and reward = 100000;

索引的分类

B+和 B树的性能区别。
1、单点查询
8 树进行单个索引査询时,最快可以在 0(1)的时间代价内就查到,而从平均时间代价来看,会比 B+ 树稍快一些。
但是 8树的查询波动会比较大,因为每个节点即存索引又存记录,所以有时候访问到了非叶子节点就可以找到索引,而有时需要访问到叶子节点才能找到索引。
B+树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B树更「矮胖」,查询底层节点的磁盘 //O次数会更少。
2、插入和删除效率
B+ 树有大量的冗余节点,这样使得删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点,这样删除非常快,
B+ 树的插入也是一样,有冗余节点,插入可能存在节点的分裂(如果节点饱和),但是最多只涉及树的条路径。而且 B+树会自动平衡,不需要像更多复杂的算法,类似红黑树的旋转操作等。
因此,B+树的插入和删除效率更高。
3、范围查询
B 树和 B+ 树等值査询原理基本一致,先从根节点查找,然后对比目标数据的范围,
最后递归的进入子节点查找。
因为 B+ 树所有叶子节点间还有一个链表进行连接,这种设计对范围查找非常有帮助,比如说我们想知道12月1日和 12 月 12 日之间的订单,这个时候可以先查找到 12月1日所在的叶子节点,然后利用链表向右遍历,直到找到 12月12日的节点,这样就不需要从根节点查询了,进一步节省查询需要的时间。
而B树没有将所有叶子节点用链表串联起来的结构,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 /O 操作,范围查询效率不如 B+ 树,
因此,存在大量范围检索的场景,适合使用 B+树,比如数据库。而对于大量的单个索引查询的场景,可以考虑 B树,比如 nosql 的 MongoDB。
索引失效
- 当我们使用左或者左右模糊匹配的时候,也就是1ike%xx或者 1ike%xx% 这两种方式都会造成索引失效;
- 当我们在查询条件中对索引列使用函数,就会导致索引失效。
- 当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。
- MySQL在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在OR 前的条件列是索引列,而在 OR后的条件列不是索引列,那么索引会失效。
隔离级别
- 读未提交 (READ UNCOMMITTED):允许读取未提交的数据,可能导致脏读。
- 读已提交 (READ COMMITTED):只读取已提交的数据,避免脏读,但可能导致不可重复读。
- 可重复读 (REPEATABLE READ):保证在同一事务中多次读取同一数据结果一致,避免不可重复读,但可能发生幻读。
- 串行化 (SERIALIZABLE):最高的隔离级别,强制事务串行执行,避免幻读,加锁出现冲突时事务必须要等到前⼀个事务执⾏完成,隔离级别越⾼,性能就会下降。
MVCC(Multi-Version Concurrency Control,多版本并发控制)
是数据库管理系统中的一种用于解决并发事务控制问题的机制。它通过维护数据的多个版本来提高并发性能,同时避免了传统锁机制带来的性能瓶颈。
MVCC 主要解决了以下问题:
- 读写冲突问题
传统的锁机制在处理并发读写时,通常会导致阻塞。例如,一个事务正在读取某条数据时,如果另一事务需要更新该数据,读事务可能会被阻塞。MVCC 通过保留数据的多个版本,可以让读操作读取旧版本的数据,而不会被写操作阻塞。
解决:在 MVCC 中,读操作不会阻塞写操作,写操作也不会阻塞读操作,从而提高了读写并发的性能。
- 幻读(Phantom Read)和不可重复读问题
在并发环境下,一个事务在两次查询之间可能会看到其他事务插入或删除的数据,这会导致“幻读”问题。同样,如果事务第一次读取某条数据,之后该数据被另一个事务修改了,那么第二次读取时看到的数据会不同,这就是“不可重复读”。
解决:MVCC 通过每个事务使用一个时间戳来确保事务在执行期间始终读取相同的版本,避免了幻读和不可重复读问题。
- 提高读性能
锁机制在处理并发读写时,往往会降低性能,因为需要获取和释放锁。而 MVCC 允许多个事务同时读取不同版本的数据,而不需要锁住数据。
解决:在 MVCC 中,读操作不需要获取锁,极大提高了读操作的性能。
MVCC 的工作原理(版本链+readview)
● 每条数据的每个版本都有一个对应的时间戳或事务ID。
● 每个事务都有一个开始时间戳,用于确定它可以看到哪些数据版本。
● 读操作读取事务开始时已经存在的版本,不受其他事务写入数据的影响。
● 写操作会生成一个新的数据版本,并将其标记为该事务的写入结果。
版本隐藏列

总结: