整理了AAAI2018 Deception Detection in Videos 论文的阅读笔记
- 背景
- 模型
- 实验
- 可视化
背景
欺骗在我们的日常生活中很常见。一些谎言是无害的,而另一些谎言可能会产生严重的后果。例如,在法庭上撒谎可能会影响司法公正,让有罪的被告逍遥法外。因此,在高风险的情况下准确发现欺骗行为对个人和公共安全至关重要。
人类辨别欺骗的能力是非常有限的。据研究,在没有特殊辅助的情况下,检测谎言的平均准确率为54%,仅略高于随机。相比于静态图像,人类通常更容易从视频中发现微妙的面部表情。图1显示了一个例子:眉毛上升。如果只给出左边的静态图像,人们很难发现眉毛在上升。相比之下,我们可以从右边的图像序列中清楚地看到眉毛在上升,尽管图像流的最后一张图像正好是左边的静态图像。

此外,欺骗是一种复杂的人类行为,受试者试图抑制他们的欺骗证据,从面部表情到手势,从他们说话的方式到他们说的话。因此,一个可靠的欺骗检测方法应该集成来自多个模态的信息。
本文建议使用运动动力学来识别面部微表情。通过一个用于捕获动态运行的两级特征表示器,对于低级特征表示,使用密集轨迹来表示运动和运动变化。对于高级表征,我们使用低级特征训练面部微表情检测器,并使用它们的置信度得分作为高级特征。
模型
本文提出的自动欺骗检测框架如图2所示,包括3个步骤:多模态特征提取、特征编码和分类。

作者通过IDT(改进密集轨迹)来捕获视频特征,这一方法在动作识别方面表现出色。此外,通过Glove和MFCC来提取语言和音频特征。由于每个视频的特征数量不同,作者采用Fisher矢量编码将可变数量的特征聚合到固定长度的矢量上。有关这一部分,这篇文章使用的方法和模型都比较老了,不再赘述。
经过上述步骤,我们就得到了多模态的低级特征。之前的研究表明,面部微表情在预测欺骗行为中起着重要作用,而最能预测面部表情的五种微表情是:皱眉、扬眉、翘唇、撅唇和侧头,如图三所示。基于此,本文使用2015年的一个手工标注微表情检测数据集来训练微表情检测器,然后使用微表情检测器的预测分数作为高级特征来预测欺骗。

在得到上述的微表情检测器后,本文将每个视频分成固定时长的短视频片段,并用微表情标签对这些片段进行标注。形式上,给定一个训练视频集 V = { v 1 ; v 2 , . . . , v N } V = \{v_1;v_2,...,v_N\} V={v1;v2,...,vN},将每个视频分成多个片段,得到训练集 C = { v i j } C=\{v_i^j\} C={vij},标注集 L = { l i j } i ∈ [ 1 , N ] L = \{l_i^j\}\ \ \ \ i\in [1,N] L={lij} i∈[1,N]表示视频id,上标 j ∈ [ 1 , N i ] j\in [1,N_i] j∈[1,Ni]表示剪辑id, N i N_i Ni是视频 I I I的剪辑数, v I j v^j_I vIj的持续时间是一个常数(在我们的实现中是4秒)。 l i j l^j_i lij的维数是微表情的个数。利用视频片段 C C C训练一组微表情分类器,并将分类器应用到测试视频片段 C ^ \hat C C^上,得到预测分数 L ^ = { l ^ i j } \hat L=\{\hat l_i^j\} L^={l^ij}。
然后,分别用我们之前得到的低阶特征和视频级分数向量来训练4个二值欺骗分类器。分别是基于三个模态和混合得分向量。将这四个预测分数定义为 S m i , i ∈ [ 1 , 3 ] S_{m_i},i\in [1,3] Smi,i∈[1,3]和 S h i g h S_{high} Shigh,并得到最终的预测分数 S S S: S = ∑ i α i S m i + α h i g h S h i g h S=\sum_i\alpha_iS_{m_i}+\alpha_{high}S_{high} S=i∑αiSmi+αhighShigh 其中, α i \alpha_i αi和 α h i g h \alpha_{high} αhigh是超参数,总和为1,并通过交叉验证得到。
实验
本文在欺骗检测数据库上评估了该方法。该数据库包括121个法庭审判录像片段。这个试用数据库中的视频是来自网络的不受约束的视频。因此,我们需要处理人物视角的差异、视频质量的变化以及背景噪声,如图4所示。本文使用了来自121个视频数据库的104个视频的子集,其中包括50个真实视频和54个欺骗视频。修剪后的视频要么有明显的场景变化,要么有人工编辑。

首先提供了微表情预测模块的性能。使用15帧/秒的帧率对每个视频剪辑进行采样。微表情检测器使用LibSVM的线性核支持向量机进行训练。结果如表1所示,报告了AUC (precision-recall curve下的面积)。尽管性能并不高,但代表微表情概率的高级特征在最终的欺骗检测任务中仍然提供了良好的性能。由于数据量的问题,使用深度学习的方法来训练检测器不太可行。

对于欺骗检测,作者给出了不同的模态数据的组合结果,这实际上实在进行消融,我们可以观察到,组合所有预测的框架具有最好的效果。

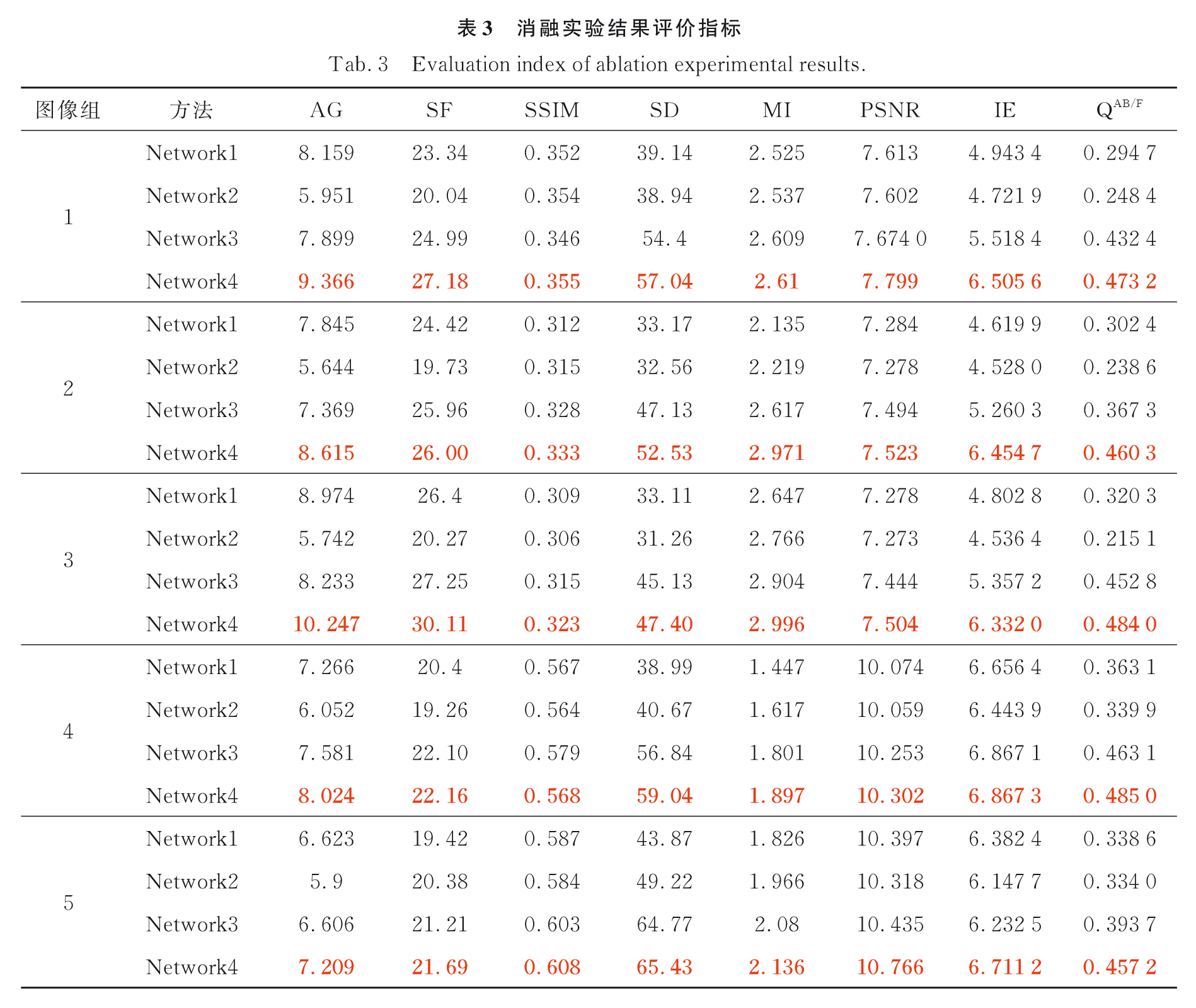
然后,作者又提出了一个有趣的问题,由于高级特征是经过训练的微表情检测器的预测分数,如果使用Ground Truth微表情特征,性能将如何受到影响。在接下来的实验中,我们使用GT微表情特征作为基线,并测试性能随其他特征模态的变化情况。表3显示了用AUC测量的结果:

从表3的结果中,我们可以观察到最高的性能为0.9221 AUC,优于所提出的全自动化系统。这表明,开发更准确的微表情检测方法是未来提高欺骗检测的潜在方向。
可视化
作者还研究了每个微表情的有效性。对于每个微表情,我们通过使用高级微表情评分特征、低级运动特征和其他模式来测试性能,如图5所示。

我们可以观察到,无论是预测微表情还是真实微表情,“扬眉”都比其他微表情更有效。当使用预测的微表情时,“头侧转”也很有帮助,见图5a。这与从真实微表情中得到的结果不同。另一方面,“皱眉”使用地面真值特征比使用预测特征效果更好,可能是因为“皱眉”检测器不够准确,如表1所示。
为了测试人类在这项任务上的表现,作者使用AMT进行用户研究。首先,我们让10个不同的人观看每个视频,并决定他们是否认为视频中的主题是真实的。每个注释者被分配5个不同身份的视频,以确保没有身份特定的偏见用于欺骗预测。我们还记录图像、音频或文本是否对他们的决定有帮助。请注意,这里的决策是使用所有模式做出的。每个视频的投票百分比被用作欺骗的分数。人为预测的AUC为0.8102。这表明这个数据集比以前的研究相对容易,在以前的研究中,人们对这项任务的预测几乎是偶然的。
在做决定时,67:4%的用户依赖于视觉线索,61:3%的时间依赖于音频,70:7%的时间依赖于文本,如图6所示。

对于每个视频,人们可以选择多种有用的模式。从这些数据中,可以观察到注意到人们倾向于根据口头内容做出决定,因为这是一个语义层面的特征。只有一半的人认为音频可以帮助他们做出决定,而在本文的系统中,音频功能是非常有效的。
基于此,本文进行了另一项用户研究,一次只向每个用户显示一种模式,因为当多个信息来源同时可用时,很难判断哪个来源有助于做出最终决定。结果如图7所示。

人类的表现和我们的系统之间存在巨大的表现差距。这表明,尽管人类缺乏仅凭视觉线索预测欺骗行为的能力,但基于计算机视觉的系统明显更好。另一方面,只有音频,人类的表现就像所有形式都可以访问一样好。但是当只提供视频文本时,人类和系统的性能都会显著下降。这表明音频信息对人类预测欺骗行为起着至关重要的作用,而文字记录则没有那么有益。