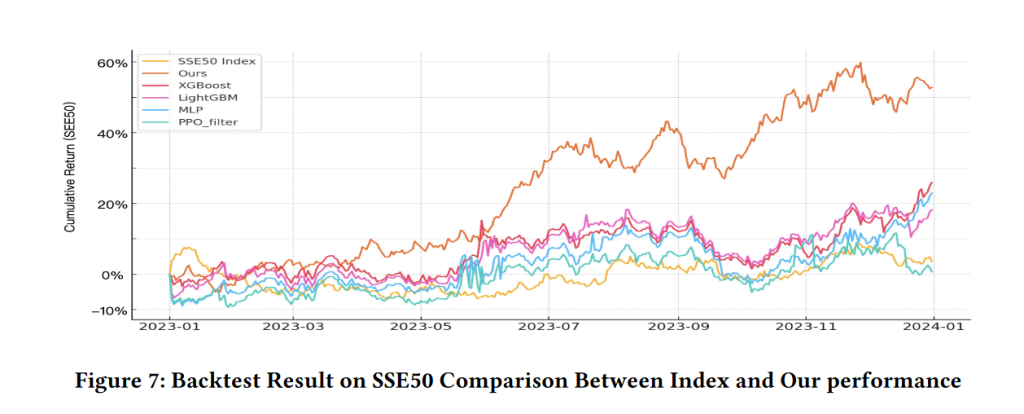
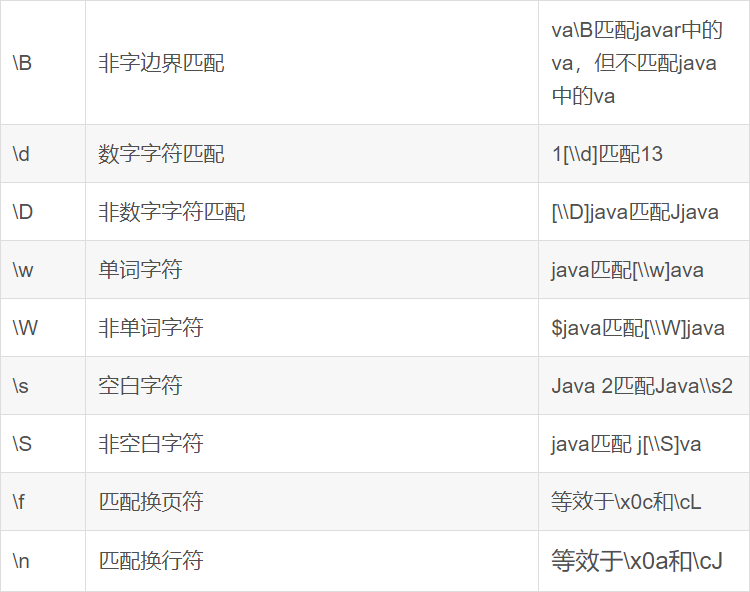
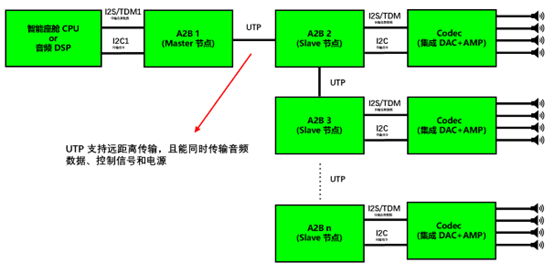
1. 引言
LangChain 简介
LangChain 是一个开源的框架,旨在帮助开发者构建以大型语言模型(LLM)为核心的应用程序。通过提供一系列模块和工具,LangChain 简化了语言模型与外部数据源、计算环境以及其他工具的集成过程,使得构建复杂的自然语言处理应用变得更加高效和便捷。
发展背景与重要性
随着人工智能领域的迅猛发展,大型语言模型在自然语言处理中的应用变得越来越广泛。然而,如何有效地将这些强大的模型应用于实际场景,并与各种数据源和工具进行无缝集成,成为了开发者面临的重大挑战。传统的开发方式往往需要处理大量的底层逻辑和重复性工作,降低了开发效率。
LangChain 的出现正是为了解决这些问题。通过模块化和链式的设计理念,LangChain 提供了一个高度可扩展和灵活的框架,使得开发者可以专注于应用的核心功能,而无需过多关注底层实现。这不仅提高了开发效率,还为快速迭代和创新提供了有力支持。
博客目标与内容概述
本博客旨在深入解析 LangChain 框架的核心原理和设计思想,帮助读者全面了解其内部机制和实际应用方法。我们将从整体架构出发,逐步探讨各个核心组件的功能和工作原理,包括链式调用、记忆系统、提示模板、代理与工具的协同工作,以及与大型语言模型的集成方式。
通过本博客的学习,读者将能够:
- 理解 LangChain 的设计理念和核心组件。
- 掌握如何使用 LangChain 构建复杂的自然语言处理应用。
- 了解如何扩展和定制框架以满足特定需求。
- 获得在实际项目中应用 LangChain 的实战经验。
2. LangChain 框架概述
设计理念与核心思想
LangChain 的设计理念是通过链式结构将大型语言模型(LLM)与外部数据源、工具和计算逻辑相结合,以构建复杂且功能强大的自然语言处理应用。其核心思想包括:
- 模块化设计:将复杂的任务拆分为多个可重用、可组合的模块,使得开发者可以灵活地搭建和扩展应用功能。
- 链式调用:通过定义一系列相互关联的“链”,使数据和处理逻辑能够按照特定的顺序和规则流转,形成清晰的执行路径。
- 上下文记忆:引入记忆机制,允许模型在对话或任务过程中保留和利用先前的信息,提高交互的连贯性和智能性。
- 灵活集成:提供开放的接口和适配层,方便与各种外部工具、API 和数据源进行集成,扩展应用的能力范围。
主要功能与特性
- Chains(链):核心组件,用于串联不同的处理步骤,可以是简单的顺序执行,也可以包含复杂的条件和循环逻辑。
- Memory(记忆):支持短期和长期记忆,允许在任务或会话中存储和检索信息,增强模型的上下文理解能力。
- Prompt Templates(提示模板):提供灵活的模板系统,支持参数化和动态生成,方便构建适合不同场景的模型输入。
- Agents(代理):智能决策模块,能够根据当前状态和目标,动态选择和调用适当的工具或动作来完成任务。
- Tools(工具):可执行的功能单元,封装了具体的操作,如查询数据库、调用 API、执行计算等,供代理和链调用。
- LLMs(大型语言模型)集成:与各种主流的大型语言模型无缝对接,支持 OpenAI、Hugging Face 等平台,方便模型的替换和比较。
- 数据连接器:预置了对常见数据源的支持,如文件系统、数据库、网络请求等,方便数据的获取和存储。
- 错误处理与调试:内置了异常捕获和日志记录机制,帮助开发者及时发现和解决问题。
应用场景分析
- 智能对话机器人:利用记忆和链式调用,实现上下文连贯、逻辑清晰的多轮对话,提高用户交互体验。
- 知识问答系统:结合大型语言模型和外部知识库,提供准确、高效的问答服务,适用于客服、教育等领域。
- 自动化任务执行:通过代理和工具的协作,完成如数据处理、报告生成、信息检索等复杂的自动化任务。
- 内容生成与创作:利用提示模板和模型能力,生成文章、摘要、代码等多种形式的内容,辅助创作和生产力提升。
- 数据分析与决策支持:集成数据源和分析工具,提供智能的数据解读和决策建议,应用于商业分析、科学研究等。
- 多语言翻译与处理:支持多语言模型,处理翻译、跨语言信息检索等任务,促进全球化交流和合作。
- 情感分析与意见挖掘:分析文本或语音中的情感倾向和观点,为市场调研、舆情监控提供支持。
- 个性化推荐系统:根据用户历史和偏好,提供定制化的内容或产品推荐,增强用户黏性和满意度。
3. 架构设计与模块划分
整体架构图解
LangChain 的整体架构旨在将大型语言模型(LLMs)与各种工具、记忆系统和数据源有机结合,以构建强大的自然语言处理应用程序。架构主要由以下核心组件构成:
- Chains(链)
- Memory(记忆)
- Prompt Templates(提示模板)
- Agents(代理)
- Tools(工具)
- LLMs(大型语言模型)
整体架构可以想象为一个多层次的系统,其中 LLMs 位于核心位置,负责生成和理解自然语言。周围的组件如 Chains、Agents 和 Tools 等,为 LLMs 提供了操作流程、外部能力和数据支持。
各模块功能详解
Chain(链)
功能概述:
- 流程控制: Chains 是 LangChain 中的核心流程控制单元,负责串联不同的组件和步骤,定义应用程序的执行逻辑。
- 数据传递: 它们可以传递上下文和数据,从而使不同的模块之间能够共享信息。
- 组合与嵌套: Chains 可以嵌套和组合,构建复杂的流程,例如顺序执行、条件判断和循环等。
关键特点:
- 可重用性: Chains 可以被定义为可重用的模块,在不同的应用场景中复用。
- 灵活性: 支持多种类型的 Chains,如简单链、索引链、对话链等,满足不同的需求。
Memory(记忆)
功能概述:
- 上下文保持: Memory 模块用于在会话或任务中存储信息,使 LLM 能够在后续的交互中引用先前的信息。
- 状态管理: 管理对话的状态和历史,提高模型的连贯性和上下文理解。
关键特点:
- 短期记忆: 保存当前会话的临时信息,适用于单次交互。
- 长期记忆: 维护跨会话的持久性信息,如用户偏好、历史记录等。
Prompt Templates(提示模板)
功能概述:
- 标准化输入: 提供统一的模板来生成 LLM 的输入,确保提示的一致性和质量。
- 参数化与动态生成: 支持在模板中使用占位符和变量,根据上下文动态生成实际的提示内容。
关键特点:
- 灵活性: 开发者可以自定义模板,适应不同的任务需求。
- 可维护性: 通过模板化管理,方便修改和优化提示内容,提高模型性能。
Agents(代理)
功能概述:
- 决策引擎: Agents 负责根据当前的状态和目标,决定下一步的操作,如调用哪个工具或执行何种动作。
- 任务分解: 将复杂的任务分解为更小的步骤,逐步完成。
关键特点:
- 自主性: Agents 可以自主选择最合适的策略和工具来完成任务。
- 可扩展性: 支持自定义代理策略,满足特定的应用场景。
Tools(工具)
功能概述:
- 功能扩展: Tools 是可调用的功能单元,封装了具体的操作,如数据库查询、API 调用、数学计算等。
- 能力增强: 通过工具的集成,使 LLM 能够执行超出其默认能力范围的任务。
关键特点:
- 标准接口: 定义统一的接口,方便代理和链进行调用。
- 丰富性: 内置了多种常用工具,且支持自定义扩展。
LLMs(大型语言模型)
功能概述:
- 核心处理器: LLMs 是整个框架的核心,负责理解输入、生成响应和执行语言相关的任务。
- 模型集成: 支持与各种主流的 LLM 平台集成,如 OpenAI GPT-4、Hugging Face 等。
关键特点:
- 可替换性: 开发者可以根据需要选择或替换不同的模型,比较性能和效果。
- 多任务支持: LLMs 能够处理多种类型的任务,包括文本生成、翻译、总结、问答等。
通过以上模块的有机结合,LangChain 构建了一个功能强大且灵活的框架,使开发者能够高效地创建复杂的自然语言处理应用程序。各个模块既各司其职,又相互协作,为应用程序提供了高度的扩展性和可维护性。
4. 核心原理深度解析
本节将深入解析 LangChain 框架的核心原理,帮助读者理解其内部机制和工作流程。
链式调用机制
链式调用机制是 LangChain 的核心概念之一,通过将多个处理步骤串联在一起,实现复杂任务的流程控制和数据处理。
链的创建与组合
创建链(Chain):
- 单一链: 开发者可以创建一个包含特定功能的单一链,例如文本预处理、模型推理等。
- 自定义链: 利用内置的基础链类,开发者可以自定义链的输入、输出和处理逻辑。
链的组合:
- 顺序组合: 将多个链按照执行顺序串联起来,前一个链的输出作为下一个链的输入。
- 并行组合: 同时执行多个链,将它们的输出合并或选择性地使用。
- 嵌套链: 在一个链的内部调用另一个链,实现更复杂的流程控制。
示例:
from langchain.chains import SequentialChain# 定义两个简单的链
chain1 = SomeChain(...)
chain2 = AnotherChain(...)# 顺序组合
combined_chain = SequentialChain(chains=[chain1, chain2])
数据流转与状态管理
数据流转:
- 输入与输出: 每个链接受输入数据,经过处理后输出结果,供下一个链使用。
- 上下文传递: 数据可以通过上下文对象在链之间传递,保持整个流程的数据连贯性。
状态管理:
- 全局状态: 使用共享的状态对象,保存整个流程需要的公共数据。
- 局部状态: 在链内部维护的临时数据,不对外部暴露。
示例:
# 在链之间传递上下文
context = {'user_query': 'What is the weather today?'}output = combined_chain.run(context)
记忆系统
记忆系统(Memory)使得 LangChain 能够在对话或任务过程中保留和利用历史信息,提升模型的上下文理解和响应能力。
短期记忆 vs 长期记忆
短期记忆(Short-term Memory):
- 特点: 仅在当前会话或任务中有效,不会被持久化。
- 用途: 适用于需要在多轮对话中保持上下文的场景,如聊天机器人。
长期记忆(Long-term Memory):
- 特点: 信息被持久化,可以跨越多次会话或任务。
- 用途: 保存用户偏好、历史记录等需要长期保留的信息。
示例:
from langchain.memory import ConversationBufferMemory# 短期记忆示例
short_term_memory = ConversationBufferMemory()# 长期记忆示例
long_term_memory = ConversationBufferMemory(memory_key='long_term', persist=True)
上下文维护与信息持久化
上下文维护:
- 会话上下文: 通过记忆模块,模型能够理解会话的历史,生成连贯的回复。
- 任务上下文: 在复杂任务中,保持步骤之间的数据一致性和依赖关系。
信息持久化:
- 存储方式: 记忆信息可以被保存到数据库、文件或其他持久化存储。
- 加载与更新: 在新的会话或任务中,记忆模块可以加载已有的信息,并在需要时进行更新。
示例:
# 持久化记忆到文件
memory.save_to_file('memory.pkl')# 从文件加载记忆
memory.load_from_file('memory.pkl')
提示模板(Prompt Templates)
提示模板(Prompt Templates)为生成模型输入提供了灵活且强大的方式,使得提示可以动态适应不同的场景和需求。
模板语法与占位符
模板语法:
- 占位符: 使用
{variable_name}形式的占位符,在运行时替换为实际的值。 - 条件语句: 支持在模板中使用简单的条件逻辑。
示例:
from langchain.prompts import PromptTemplatetemplate = "Translate the following text to {language}:\n\n{text}"prompt = PromptTemplate(input_variables=["language", "text"], template=template)
动态生成与参数化
动态生成:
- 参数注入: 在运行时传入不同的参数,生成适应特定需求的提示。
- 上下文结合: 与记忆系统结合,自动填充上下文信息。
参数化:
- 可重用性: 定义通用的模板,适用于不同的任务和模型。
- 灵活性: 通过改变参数,快速适应新的需求。
示例:
# 使用模板生成提示
final_prompt = prompt.format(language="French", text="Hello, how are you?")# 输出:
# "Translate the following text to French:
#
# Hello, how are you?"
代理与工具的协同工作
代理(Agents)和工具(Tools)的结合使得 LangChain 能够动态地决定执行哪些操作,增强了应用的智能性和灵活性。
代理的决策流程
工作原理:
- 输入解析: 代理接收用户输入或上一步的输出,理解当前的意图和需求。
- 策略选择: 根据预设的策略或模型,决定调用哪个工具或执行何种操作。
- 动作执行: 调用相应的工具或链,完成特定的任务。
类型:
- 基于规则的代理: 使用预定义的规则和逻辑进行决策。
- 基于模型的代理: 利用 LLM 来理解输入并决定下一步动作。
示例:
from langchain.agents import AgentExecutoragent = AgentExecutor.from_agent_and_tools(agent=some_agent, tools=[tool1, tool2])# 运行代理
response = agent.run("Tell me a joke about cats.")
工具调用与扩展方法
工具调用:
- 标准接口: 工具需要实现特定的接口,供代理调用。
- 参数传递: 代理将必要的参数传递给工具,获取结果。
扩展方法:
- 自定义工具: 开发者可以创建新的工具,扩展应用的功能。
- 工具组合: 工具可以相互组合,形成更复杂的功能。
示例:
from langchain.tools import BaseToolclass WeatherTool(BaseTool):def _run(self, query):# 实现获取天气的逻辑return weather_info# 注册工具
tool = WeatherTool(name="weather_tool", description="Provides weather information")
LLM 集成与调用
LangChain 支持与多种大型语言模型集成,提供了灵活的模型适配和协作机制。
模型适配与选择
模型适配:
- 统一接口: LangChain 定义了统一的模型接口,使得不同的 LLM 可以被无缝替换。
- 配置参数: 支持传递模型特定的配置,如温度、最大长度等。
模型选择:
- 多模型支持: 可以根据任务需求选择最合适的模型。
- 模型切换: 在运行时动态切换模型,满足不同的性能和效果要求。
示例:
from langchain.llms import OpenAI, HuggingFace# 使用 OpenAI 模型
llm_openai = OpenAI(model_name="gpt-4")# 使用 Hugging Face 模型
llm_hf = HuggingFace(model_name="bert-base-uncased")
多模型协作机制
协作方式:
- 级联模型: 一个模型的输出作为下一个模型的输入,形成级联处理。
- 并行模型: 同时调用多个模型,对结果进行比较或综合。
应用场景:
- 提高准确性: 结合多个模型的优势,获得更好的结果。
- 容错处理: 当一个模型失败时,备用模型可以提供支持。
示例:
# 定义级联模型链
from langchain.chains import SequentialChainchain = SequentialChain(llms=[llm_openai, llm_hf])# 运行链
final_output = chain.run(input_data)
通过以上对核心原理的深入解析,我们可以看到 LangChain 的设计充分考虑了模块化、可扩展性和灵活性,使得开发者能够高效地构建复杂的自然语言处理应用。在接下来的章节中,我们将探讨如何在实际项目中应用这些原理,并提供具体的案例和代码示例。
5. 工作流程与执行过程
请求处理流程
在 LangChain 框架中,工作流程通常从一个外部请求开始,例如用户的输入或系统的触发。请求处理流程主要包括以下步骤:
-
请求接收与预处理:
- 输入获取: 系统接收来自用户、API 调用或其他外部源的输入数据。这些数据可能是文本、语音或结构化数据。
- 预处理: 对输入数据进行清洗和格式化,确保其符合系统要求。例如,去除多余的空格、校正拼写错误或解析特定的指令格式。
-
上下文构建与记忆加载:
- 上下文信息: 系统结合当前会话的上下文,包括短期记忆和长期记忆,构建一个完整的环境。这样可以让后续的处理步骤更加准确和相关。
- 记忆系统: 从记忆模块中加载相关的信息,如先前的对话历史、用户偏好或任务状态。
-
提示模板生成(Prompt Generation):
- 选择适当的模板: 根据请求的类型和上下文,选择合适的提示模板(Prompt Template)。
- 填充模板: 将具体的参数和上下文数据填充到模板中,生成最终的模型输入。
-
链式调用(Chain Execution):
- 链的选择: 确定需要执行的链,可能是单个链或多个链的组合。
- 链的执行: 按照链的定义,依次调用代理(Agents)、工具(Tools)和大型语言模型(LLMs),完成特定的任务。
-
模型推理与响应生成:
- 模型调用: 将生成的提示输入到 LLM 中,进行推理和生成。
- 结果处理: 对 LLM 的输出进行解析、后处理,得到符合预期的响应。
-
响应发送与结果输出:
- 封装响应: 将处理结果封装成适当的格式,如 JSON、文本或其他协议格式。
- 发送响应: 将结果返回给用户或调用方,完成整个请求的处理。
数据传递与依赖关系
数据在 LangChain 的各个模块之间流动,确保信息在整个处理流程中被正确地传递和处理。
-
数据传递机制:
- 上下文对象: 使用上下文对象(Context)在链、代理和工具之间传递数据,包括输入参数、临时变量和状态信息。
- 参数传递: 各个组件通过明确的参数接口接收和返回数据,确保数据类型和格式的一致性。
-
依赖关系管理:
- 模块间依赖: 链中的某些步骤可能依赖于前一步的输出,必须按照正确的顺序执行。
- 数据完整性: 在数据传递过程中,系统会进行数据校验,防止数据丢失或篡改。
-
共享状态与记忆系统:
- 短期记忆: 在当前会话中,数据可以被暂时存储和共享,供后续步骤使用。
- 长期记忆: 持久化存储重要的信息,供未来的会话或任务使用。
-
数据隔离与安全:
- 作用域控制: 确保数据只在必要的范围内可见,防止数据泄漏。
- 安全机制: 对敏感数据进行加密或权限控制,保障数据安全。
异常处理与容错机制
为了提高系统的稳定性和用户体验,LangChain 提供了完善的异常处理和容错机制。
-
异常捕获:
- 本地异常处理: 在链、代理和工具的内部,对可能发生的异常进行捕获和处理,如网络超时、数据格式错误等。
- 全局异常处理: 对未被捕获的异常,系统会进行统一的处理,防止程序崩溃。
-
错误分类与处理策略:
- 可预期错误: 对于已知的错误类型,提供明确的错误信息和解决方案提示。
- 未知错误: 对于未预料到的错误,记录详细的日志,返回通用的错误信息,防止敏感信息泄露。
-
重试与降级机制:
- 自动重试: 对于临时性错误,如网络波动,可进行一定次数的自动重试。
- 功能降级: 在某些功能不可用时,提供简化的替代方案,确保核心功能的可用性。
-
日志记录与监控:
- 详细日志: 记录系统的运行状态和异常信息,方便后续的调试和分析。
- 实时监控: 结合监控工具,实时跟踪系统的性能和错误,及时发现和处理问题。
-
用户友好性:
- 错误提示: 在发生异常时,提供清晰、易懂的错误信息,指导用户进行下一步操作。
- 反馈机制: 允许用户报告错误或问题,促进系统的持续改进。
-
资源清理与恢复:
- 资源管理: 在异常发生后,及时释放占用的资源,如内存、文件句柄等。
- 状态恢复: 在可能的情况下,恢复到安全的系统状态,避免数据损坏或进一步的错误。
通过上述的流程和机制,LangChain 确保了数据在系统中的高效、可靠传递,并提供了稳健的异常处理能力,为构建健壮的应用程序奠定了基础。
6. 扩展与定制
自定义组件开发
LangChain 框架具有高度的可扩展性,允许开发者根据特定需求创建自定义组件,以增强和扩展应用的功能。
1. 自定义链(Chains)
-
创建自定义链: 开发者可以继承
Chain基类,重写input_keys和output_keys,以及__call__方法,定义自定义的处理逻辑。from langchain.chains import Chainclass CustomChain(Chain):@propertydef input_keys(self):return ["input_data"]@propertydef output_keys(self):return ["output_data"]def __call__(self, inputs):# 自定义处理逻辑output = some_processing_function(inputs["input_data"])return {"output_data": output}
2. 自定义工具(Tools)
-
创建自定义工具: 通过继承
BaseTool类,实现_run方法,定义工具的具体功能。from langchain.tools import BaseToolclass CustomTool(BaseTool):name = "custom_tool"description = "This tool does something special."def _run(self, query):# 实现工具的功能result = some_tool_function(query)return result
3. 自定义代理(Agents)
-
创建自定义代理: 可以基于现有的代理类,或者从头创建新的代理,定制决策逻辑和策略。
from langchain.agents import Agentclass CustomAgent(Agent):def plan(self, **kwargs):# 自定义计划和决策逻辑action = decide_next_action(kwargs)return action
4. 自定义记忆(Memory)
-
创建自定义记忆模块: 继承
BaseMemory类,实现存储和检索机制,满足特定的记忆需求。from langchain.memory import BaseMemoryclass CustomMemory(BaseMemory):def load_memory_variables(self, inputs):# 自定义记忆加载逻辑return {"memory_key": memory_value}def save_context(self, inputs, outputs):# 自定义记忆保存逻辑pass
自定义组件的优势:
- 满足特定需求: 针对特殊的业务逻辑或功能需求,创建高度定制化的组件。
- 提高复用性: 将通用的功能封装为组件,方便在不同的项目中重复使用。
- 增强灵活性: 通过自定义,突破框架的限制,实现更复杂或创新的应用。
插件机制实现
LangChain 提供了插件机制,方便开发者扩展框架的功能,并与社区共享自定义的组件和功能。
1. 插件架构
- 标准接口: 插件需要实现框架定义的标准接口,确保与核心系统的兼容性。
- 插件注册: 通过注册机制,将插件加载到系统中,使其能够被代理、链和工具调用。
2. 开发插件的步骤
- 定义插件功能: 明确插件的作用和功能,例如新的工具、链或记忆模块。
- 实现接口: 根据插件类型,继承相应的基类,并实现必要的方法。
- 添加元数据: 提供插件的名称、描述、版本等信息,方便管理和识别。
- 打包与发布: 将插件打包为可分发的形式,发布到插件仓库或共享给他人。
3. 插件的使用
-
安装插件: 通过包管理器或手动方式,将插件安装到项目环境中。
-
加载插件: 在代码中导入插件,并将其注册到框架中。
from langchain.plugins import PluginManagerplugin_manager = PluginManager() plugin_manager.load_plugin("custom_plugin") -
调用插件功能: 插件的功能可以像内置组件一样被调用和使用。
4. 插件的优势
- 社区贡献: 通过插件机制,开发者可以分享自己的成果,促进社区的发展。
- 功能扩展: 插件可以为框架引入新的特性,满足更多样化的需求。
- 维护便利: 插件的独立性使得其可以单独维护和升级,而不影响核心框架。
与第三方服务的集成方案
为了构建功能丰富的应用,通常需要将 LangChain 与各种第三方服务集成,如数据库、API、云服务等。
1. 集成数据库
-
连接数据库: 使用数据库驱动或 ORM,与 MySQL、PostgreSQL、MongoDB 等数据库建立连接。
import psycopg2connection = psycopg2.connect(host="localhost",database="mydb",user="user",password="password" ) -
创建数据工具: 将数据库操作封装为工具,供代理和链调用。
from langchain.tools import BaseToolclass DatabaseQueryTool(BaseTool):name = "database_query"description = "Queries the database for information."def _run(self, query):cursor = connection.cursor()cursor.execute(query)result = cursor.fetchall()return result
2. 集成外部 API
-
调用 API: 使用
requests等库,调用第三方 API 获取数据或执行操作。import requestsresponse = requests.get("https://api.example.com/data") data = response.json() -
创建 API 工具: 将 API 调用封装为工具或链,集成到应用流程中。
class APITool(BaseTool):name = "api_tool"description = "Fetches data from external API."def _run(self, endpoint):response = requests.get(endpoint)return response.json()
3. 集成云服务
-
使用云 SDK: 利用云服务提供的 SDK,如 AWS、GCP、Azure,与云资源交互。
import boto3s3 = boto3.client('s3') s3.upload_file('file.txt', 'mybucket', 'file.txt') -
创建云服务工具: 将云操作封装为工具,供应用调用。
class S3UploadTool(BaseTool):name = "s3_upload"description = "Uploads files to S3 bucket."def _run(self, file_path, bucket_name):s3.upload_file(file_path, bucket_name, file_path)return "Upload successful"
4. 集成方案的注意事项
- 安全性: 在集成第三方服务时,注意保护敏感信息,如 API 密钥、凭证等。可以使用环境变量或安全配置管理。
- 错误处理: 对外部服务调用可能出现的错误进行处理,防止影响应用的稳定性。
- 性能优化: 考虑网络延迟和服务响应时间,对频繁调用的服务进行缓存或异步处理。
5. 实践案例
- 多语言翻译: 集成第三方翻译 API,实现实时的多语言支持。
- 社交媒体分析: 调用社交媒体平台的 API,获取数据进行分析和处理。
- 自动化运维: 结合云服务 API,实现自动化的资源管理和部署。
与第三方服务的集成,使 LangChain 的应用更加丰富和强大,能够满足各种复杂的业务需求。通过合理的封装和设计,可以将外部服务无缝地融入到框架的工作流程中。
7. 性能优化策略
在构建基于 LangChain 的应用程序时,性能优化是确保系统高效、稳定运行的关键。本节将探讨如何通过提升链执行效率、应用缓存策略以及进行资源管理与负载均衡来优化性能。
链执行效率提升
1. 优化链的结构
- 简化链路:审查链中的每个步骤,去除不必要的环节,减少过多的嵌套和复杂的逻辑。
- 并行处理:对于独立的任务,采用并行执行方式,充分利用多核 CPU 和异步 I/O,提高处理速度。
- 避免阻塞操作:在链中避免使用阻塞式的 I/O 操作,尽可能使用异步方法或异步库。
2. 使用异步编程
- 异步 Chains:利用 Python 的
asyncio等异步编程模型,将链的执行改为异步方式,减少等待时间。 - 异步工具和代理:确保工具(Tools)和代理(Agents)也支持异步操作,以实现全链路的异步执行。
3. 减少模型调用次数
- 合并请求:在可能的情况下,将多个小的模型调用合并为一个大的调用,减少与 LLM 的交互次数。
- 批量处理:对于需要处理大量数据的场景,采用批量处理方式,降低整体的调用开销。
4. 优化提示模板(Prompt Templates)
- 精简提示:编写高效的提示模板,避免冗长或重复的内容,减少模型处理的负担。
- 参数化输入:使用参数化的模板,避免每次生成新的提示文本,提升生成速度。
5. 性能监控与分析
- Profiling:使用性能分析工具(如 cProfile、Pyinstrument)对链的执行进行 Profiling,找出性能瓶颈。
- 日志记录:详细记录链的执行时间、步骤耗时等信息,方便后续的优化和调整。
缓存策略与重复计算避免
1. 缓存模型输出
- 结果缓存:对于相同的输入,缓存 LLM 的输出结果,避免重复调用模型。
- 缓存策略:设定缓存的过期时间和容量限制,使用如 LRU(最近最少使用)等缓存淘汰算法。
2. 缓存中间结果
- 中间数据缓存:在链的执行过程中,缓存中间步骤的结果,防止后续步骤重复计算。
- 数据哈希:对输入数据进行哈希处理,快速判断是否已存在缓存结果。
3. 利用持久化存储
- 持久化缓存:将缓存的数据存储到磁盘、数据库或内存数据库(如 Redis)中,实现跨会话的缓存共享。
- 分布式缓存:在分布式系统中,使用分布式缓存服务,确保缓存的一致性和高可用性。
4. 避免冗余计算
- 去重处理:在数据预处理阶段,去除重复的数据,减少不必要的计算。
- 结果复用:在多次调用中,如果某些计算步骤的输入相同,直接复用之前的结果。
5. 智能缓存失效
- 依赖关系管理:当底层数据或模型发生变化时,及时使相关缓存失效,确保结果的准确性。
- 版本控制:对模型和数据进行版本管理,缓存中记录对应的版本信息,防止使用过期的缓存。
资源管理与负载均衡
1. 有效的资源分配
- 限制并发数:设置系统的最大并发处理数,防止因过载导致的性能下降或系统崩溃。
- 资源隔离:为不同的任务或用户分配独立的资源,避免相互干扰。
2. 负载均衡策略
- 请求分发:在多实例部署中,使用负载均衡器(如 Nginx、HAProxy)将请求均匀地分发到各个实例。
- 动态伸缩:根据系统负载,自动增加或减少实例数量,实现弹性扩展。
3. 内存和存储优化
- 内存管理:监控内存使用情况,及时释放不必要的对象,防止内存泄漏。
- 数据压缩:对大量的数据进行压缩存储,减少内存和磁盘的占用。
4. 异常和故障处理
- 超时设置:对外部调用和长时间运行的任务设置超时,避免资源长期占用。
- 降级策略:在高负载或部分功能失效时,提供简化的服务,保证核心功能的可用性。
5. 监控与报警
- 实时监控:使用监控工具(如 Prometheus、Grafana)实时监测系统的 CPU、内存、网络等指标。
- 报警机制:设置关键指标的报警阈值,及时发现和处理异常情况。
6. 多区域部署
- 地理分布:在多个地理区域部署服务,降低网络延迟,提高用户的访问速度。
- 灾备策略:建立完善的灾难恢复机制,确保在极端情况下系统的可用性。
通过以上策略的应用,开发者可以显著提升基于 LangChain 的应用程序的性能和稳定性。在实际项目中,应根据具体的场景和需求,选择合适的优化方法,不断迭代和完善系统。
8. 实际应用案例
本节将通过具体的案例,展示如何使用 LangChain 框架构建实际应用。我们将探讨以下三个案例:
- 案例一:智能问答系统构建
- 案例二:对话式机器人开发
- 案例三:自动化数据处理流水线
案例一:智能问答系统构建
需求分析
在现代信息社会,用户对快速、准确获取信息的需求日益增长。智能问答系统能够根据用户的自然语言问题,从大量的知识库中检索并生成精确的答案。我们的目标是构建一个智能问答系统,具备以下特性:
- 自然语言理解:能够理解用户提出的问题,包括复杂的句子结构和专业术语。
- 知识库集成:与外部知识库(如维基百科、数据库)集成,提供准确的答案。
- 上下文感知:支持多轮问答,记忆用户先前的问题和系统提供的答案。
实现步骤
-
环境准备
-
安装必要的库:
pip install langchain openai wikipedia -
设置 OpenAI API 密钥:
import os os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
-
-
构建提示模板
-
定义一个提示模板,用于引导模型生成答案:
from langchain.prompts import PromptTemplateprompt_template = PromptTemplate(input_variables=["question", "context"],template="""You are an intelligent assistant. Use the following context to answer the question.Context:{context}Question:{question}Answer:""" )
-
-
创建记忆模块
-
使用短期记忆,保存会话中的上下文:
from langchain.memory import ConversationBufferMemorymemory = ConversationBufferMemory(memory_key="chat_history")
-
-
集成知识库
-
使用
wikipedia库,从维基百科获取相关的上下文信息:import wikipediadef get_wikipedia_context(query):try:summary = wikipedia.summary(query, sentences=5)return summaryexcept wikipedia.exceptions.DisambiguationError as e:return f"Multiple entries found for {query}: {e.options}"except Exception as e:return "Context not found."
-
-
构建链(Chain)
-
创建一个链,整合上述组件:
from langchain.chains import LLMChain from langchain.llms import OpenAIllm = OpenAI(temperature=0.7)qa_chain = LLMChain(llm=llm,prompt=prompt_template,memory=memory )
-
-
处理用户输入
-
定义一个函数,接受用户的问题,生成答案:
def answer_question(question):context = get_wikipedia_context(question)response = qa_chain.run(question=question, context=context)return response
-
-
测试系统
-
运行问答循环:
if __name__ == "__main__":while True:user_input = input("User: ")if user_input.lower() in ["exit", "quit"]:breakanswer = answer_question(user_input)print(f"Assistant: {answer}")
-
关键代码解析
-
提示模板(Prompt Template)
- 我们定义了一个包含
question和context的模板,模型将使用提供的上下文来回答问题。
- 我们定义了一个包含
-
记忆模块
- 使用
ConversationBufferMemory,使系统能够记住之前的对话内容,实现多轮对话。
- 使用
-
知识库集成
- 通过调用
wikipedia.summary(),获取与用户问题相关的背景信息,增强答案的准确性。
- 通过调用
-
链的构建
LLMChain将 LLM、提示模板和记忆模块结合起来,形成一个完整的处理链。
案例二:对话式机器人开发
多轮对话处理
需求分析
构建一个能够进行自然、多轮对话的聊天机器人,具备以下能力:
- 上下文理解:记住对话历史,提供连贯的回复。
- 情感感知:能够识别用户的情感状态,并给予适当的反馈。
- 丰富的交互:支持开放式对话,涵盖各种话题。
实现步骤
-
环境准备
-
安装必要的库:
pip install langchain openai textblob -
设置 OpenAI API 密钥(同案例一)。
-
-
创建记忆模块
-
使用
ConversationBufferMemory保存对话历史:memory = ConversationBufferMemory(memory_key="chat_history")
-
-
情感分析工具
-
使用
TextBlob进行情感分析:from textblob import TextBlobdef analyze_sentiment(text):blob = TextBlob(text)return blob.sentiment.polarity # 返回情感得分
-
-
构建提示模板
-
定义对话式的提示模板:
prompt_template = PromptTemplate(input_variables=["chat_history", "user_input"],template="""The following is a conversation between a user and an assistant.Chat History:{chat_history}User: {user_input}Assistant:""" )
-
-
构建链(Chain)
-
创建对话链:
from langchain.chains import ConversationChainconversation = ConversationChain(llm=llm,prompt=prompt_template,memory=memory )
-
-
处理用户输入
-
定义对话流程,加入情感分析:
def chat():while True:user_input = input("User: ")if user_input.lower() in ["exit", "quit"]:breaksentiment = analyze_sentiment(user_input)if sentiment < -0.5:print("Assistant: I'm sorry to hear that you're feeling this way.")elif sentiment > 0.5:print("Assistant: That's great to hear!")else:response = conversation.predict(user_input=user_input)print(f"Assistant: {response}")
-
情感分析与反馈
-
情感分析
- 使用
TextBlob对用户输入进行情感分析,获取情感得分。
- 使用
-
情感反馈
- 根据情感得分,机器人给予适当的情感回应,提升用户体验。
-
多轮对话
- 通过记忆模块,机器人能够记住对话历史,提供连贯的回复。
案例三:自动化数据处理流水线
数据采集与预处理
需求分析
构建一个自动化的数据处理流水线,能够:
- 数据采集:从网络或其他数据源自动获取数据。
- 数据预处理:对数据进行清洗、格式化等预处理操作。
- 结果生成:基于处理后的数据生成报告或摘要。
实现步骤
-
环境准备
-
安装必要的库:
pip install langchain openai pandas requests
-
-
数据采集工具
-
创建一个工具,负责从 API 获取数据:
from langchain.tools import BaseTool import requests import pandas as pdclass DataFetcherTool(BaseTool):name = "data_fetcher"description = "Fetches data from a given API endpoint."def _run(self, endpoint):response = requests.get(endpoint)data = response.json()df = pd.DataFrame(data)return df
-
-
数据预处理工具
-
创建一个工具,进行数据清洗和格式化:
class DataPreprocessorTool(BaseTool):name = "data_preprocessor"description = "Cleans and preprocesses the data."def _run(self, df):# 示例预处理操作df = df.dropna()df = df.reset_index(drop=True)return df
-
-
结果生成工具
-
使用 LLM 生成数据报告:
class ReportGeneratorTool(BaseTool):name = "report_generator"description = "Generates a report based on the data."def _run(self, df):data_summary = df.describe().to_string()prompt = f"Generate a summary report for the following data:\n{data_summary}"response = llm(prompt)return response
-
-
构建流水线链(Chain)
-
将上述工具组合成一个链:
from langchain.chains import SequentialChaindata_fetcher = DataFetcherTool() data_preprocessor = DataPreprocessorTool() report_generator = ReportGeneratorTool()pipeline = SequentialChain(chains=[data_fetcher, data_preprocessor, report_generator],input_variables=["endpoint"],output_variables=["report"] )
-
-
运行流水线
-
执行数据处理流水线:
if __name__ == "__main__":endpoint = "https://api.example.com/data"result = pipeline.run(endpoint=endpoint)print("Generated Report:")print(result["report"])
-
结果生成与报告
-
数据采集
- 使用
requests获取 API 数据,并转换为 Pandas DataFrame。
- 使用
-
数据预处理
- 对数据进行必要的清洗,如删除缺失值、重置索引等。
-
报告生成
- 将数据摘要传递给 LLM,生成自然语言的报告或总结。
9. 常见问题与解决方案
调试方法与工具
在开发基于 LangChain 的应用程序时,可能会遇到各种问题和挑战。有效的调试方法和工具可以帮助快速定位和解决问题,提高开发效率。
1. 使用日志记录
-
内置日志功能:LangChain 提供了日志记录机制,可以通过配置日志级别来获取不同详细程度的运行信息。
import logging logging.basicConfig(level=logging.DEBUG) -
自定义日志:在关键位置添加自定义日志,输出变量值、执行流程等信息。
logging.debug(f"Current input: {inputs}")
2. 交互式调试
-
使用断点:利用 IDE(如 PyCharm、VSCode)提供的调试功能,在代码中设置断点,逐步执行,检查变量状态。
-
print调试:在代码中插入print语句,输出关键变量和步骤的信息,快速查看程序运行状态。
3. 调试模式
-
启用调试模式:某些组件(如 Chains、Agents)可能提供调试模式,可以输出更详细的执行信息。
chain = SomeChain(debug=True)
4. 模型输出验证
-
查看 LLM 响应:在与大型语言模型交互时,打印或记录模型的输入和输出,检查模型是否按照预期生成结果。
response = llm(prompt) print(f"LLM response: {response}")
5. 第三方调试工具
-
使用调试工具包:如
pdb、ipdb等调试库,提供更高级的调试功能。import pdb pdb.set_trace() -
性能分析工具:使用
cProfile、PyInstrument等工具,分析代码性能,找出瓶颈。
常见错误解析
在使用 LangChain 的过程中,可能会遇到一些常见的错误和异常。以下列出了一些常见问题及其解决方案。
1. 模块未找到错误
-
错误信息:
ModuleNotFoundError: No module named 'langchain' -
解决方案:确保已正确安装 LangChain 库,使用
pip install langchain安装。如果已安装,检查 Python 环境是否正确。
2. API 密钥错误
-
错误信息:
AuthenticationError: No API key provided. -
解决方案:确认已设置正确的 API 密钥,例如 OpenAI 的 API 密钥。
import os os.environ["OPENAI_API_KEY"] = "your-api-key"
3. 输入/输出键不匹配
-
错误信息:
KeyError: 'input_key'或KeyError: 'output_key' -
解决方案:检查 Chains、Tools 等组件的
input_keys和output_keys是否正确匹配。确保传递的参数名称与定义的一致。
4. 超时或网络错误
-
错误信息:
TimeoutError,ConnectionError -
解决方案:检查网络连接,确保能够访问所需的外部服务。对于长时间运行的请求,可以增加超时时间或实现重试机制。
5. 模型调用失败
-
错误信息:
OpenAIAPIError,RateLimitError -
解决方案:检查 API 调用是否超过限制,查看是否需要升级服务计划。实现请求的排队或限流,避免过于频繁的调用。
6. 数据类型错误
-
错误信息:
TypeError,ValueError -
解决方案:确保传递给函数或方法的参数类型正确。例如,传递字符串而非数值,或确保数据结构符合预期。
7. 提示模板错误
-
错误信息:
KeyError(在模板中缺少变量) -
解决方案:检查
PromptTemplate中定义的input_variables,确保在填充模板时提供了所有必要的变量。
8. 记忆模块错误
-
错误信息:记忆无法保存或加载
-
解决方案:检查记忆模块的配置,确保存储位置可用。对于持久化存储,确保有读写权限,路径正确。
社区支持与资源获取
LangChain 拥有活跃的社区和丰富的资源,开发者可以通过以下途径获取支持和帮助。
1. 官方文档
- 网址: LangChain 官方文档
- 内容:详细的 API 文档、教程、示例代码,涵盖框架的各个方面。
2. GitHub 代码仓库
- 网址: LangChain GitHub 仓库
- 内容:源代码、Issue 跟踪、贡献指南。可以提交 Issue 报告问题或提出功能请求。
3. 社区论坛与讨论
- Discord:加入 LangChain 的 Discord 服务器,与其他开发者实时交流。
- Stack Overflow:在 Stack Overflow 上提问,使用
langchain标签。 - Reddit:参与相关的 Subreddit,讨论框架的使用经验和最佳实践。
4. 博客与教程
- 官方博客:定期发布更新、功能介绍和使用指南。
- 第三方教程:社区成员撰写的教程和实践案例,提供不同视角的学习材料。
5. 视频资源
- YouTube 频道:观看演示视频、教学内容,直观了解框架的功能。
6. 社交媒体
- Twitter:关注 LangChain 的官方账号,获取最新动态和公告。
- LinkedIn:加入相关的专业群组,拓展人脉。
7. 培训与活动
- 线上研讨会:参与官方或社区举办的线上活动,学习新特性。
- 线下会议:参加技术大会或沙龙,面对面交流。
8. 贡献与协作
- 开源贡献:参与代码贡献、文档翻译、Bug 修复,提升自身技能。
- 插件与扩展:开发并分享自己的插件或工具,丰富生态系统。
9. 常见问题解答(FAQ)
- 官方 FAQ:查看常见问题列表,快速找到问题的答案。
10. 未来发展与展望
LangChain 的最新版本与特性预览
截至 2023 年 10 月,LangChain 持续发展,推出了多个新版本,不断丰富和强化框架的功能。最新版本的主要特性包括:
-
增强的多模型支持:新增对更多大型语言模型(LLM)的兼容性,包括最新的 GPT 系列模型和其他开源模型,为开发者提供了更广泛的选择。
-
改进的代理(Agent)机制:代理模块引入了更先进的决策算法和策略,提升了任务执行的智能性和效率。
-
插件系统升级:优化了插件机制,使开发和集成自定义插件变得更加容易,促进了社区的协作和生态系统的繁荣。
-
性能优化:通过对核心组件的重构和算法优化,进一步提高了链执行的效率,降低了资源消耗。
-
安全性与合规性:新增了对敏感数据的保护措施,强化了权限管理,确保应用程序符合相关的安全标准和法规要求。
-
文档和社区支持:完善了官方文档,增加了更多示例和教程,社区活动也更加活跃,提供了更强大的支持和资源。
与其他前沿技术的结合
LangChain 的开放性和灵活性使其能够与各种前沿技术相结合,拓展了应用的深度和广度:
-
深度学习框架集成:与 TensorFlow、PyTorch 等深度学习框架结合,支持自定义模型的训练和部署,满足特定领域的需求。
-
知识图谱与符号推理:融合知识图谱技术,增强了模型的知识获取和推理能力,提高了问答和对话系统的准确性。
-
强化学习(Reinforcement Learning):通过引入强化学习算法,特别是人类反馈的强化学习(RLHF),优化了模型的响应质量和用户体验。
-
多模态交互:支持文本、语音、图像等多种数据形式的处理,与计算机视觉和语音识别技术相结合,打造更丰富的交互方式。
-
云计算与边缘计算:与主流云服务平台深度集成,支持云端部署和边缘计算,实现了弹性伸缩和高可用性。
-
区块链与隐私计算:探索与区块链技术的结合,利用智能合约和去中心化的特性,增强数据安全和隐私保护。
未来可能的应用方向
展望未来,LangChain 有望在以下几个方向取得更大的突破:
-
行业垂直解决方案:针对医疗、法律、金融等专业领域,提供定制化的语言模型应用,满足行业特定的复杂需求。
-
情感计算与人机共情:加强对情感和情绪的理解,开发能够与用户产生情感共鸣的应用,如心理健康辅导、情感陪护机器人等。
-
自主学习与自适应系统:构建具备自主学习能力的代理,能够根据环境变化自我调整,应用于智能家居、自动驾驶等领域。
-
教育与培训:在教育领域发挥更大作用,如智能辅导、个性化学习方案、虚拟教师等,提升教育质量和效率。
-
全球化与多语言支持:进一步加强对多语言和跨文化的支持,促进不同语言和文化背景下的交流与合作。
-
伦理与可持续发展:关注人工智能的伦理问题,推动技术的发展符合社会价值观和道德准则,促进人工智能的可持续发展。
通过持续的创新和生态系统的完善,LangChain 将在自然语言处理和人工智能领域发挥更重要的作用,推动技术进步,创造更大的社会和商业价值。
11. 总结
关键要点回顾
通过对 LangChain 框架核心原理的全面解析,我们深入了解了以下关键内容:
-
设计理念与核心思想:LangChain 以链式调用和模块化设计为核心,通过将大型语言模型(LLM)与工具、记忆系统、提示模板等组件有机结合,构建灵活且强大的自然语言处理应用。
-
架构设计与模块划分:框架主要由 Chains(链)、Memory(记忆)、Prompt Templates(提示模板)、Agents(代理)、Tools(工具)和 LLMs(大型语言模型)六大模块组成,各模块职责明确,协同工作。
-
核心原理深度解析:深入探讨了链式调用机制、记忆系统的短期和长期记忆、提示模板的动态生成、代理与工具的协同工作,以及 LLM 的集成与多模型协作机制。
-
工作流程与执行过程:了解了请求处理流程、数据传递与依赖关系,以及异常处理与容错机制,确保应用的稳健性和可靠性。
-
扩展与定制:掌握了如何开发自定义组件、实现插件机制,以及与第三方服务的集成方案,满足特定业务需求,增强应用的功能和灵活性。
-
性能优化策略:学习了提升链执行效率、应用缓存策略避免重复计算,以及资源管理与负载均衡的方法,优化了应用性能。
-
实际应用案例:通过智能问答系统、对话式机器人和自动化数据处理流水线的案例,实践了 LangChain 的核心原理和开发技巧,加深了对框架的理解。
-
常见问题与解决方案:掌握了调试方法与工具、常见错误的解析,以及如何利用社区支持与资源获取,提升了问题解决能力。
-
未来发展与展望:展望了 LangChain 的最新版本与特性、与前沿技术的结合,以及未来可能的应用方向,了解了框架的发展趋势。
对开发者的建议
-
深入理解核心概念:在使用 LangChain 开发应用前,建议花时间深入理解其核心概念和各个模块的功能,这将有助于更有效地设计和实现应用。
-
善用官方资源:充分利用官方文档、教程和示例代码,快速上手并解决开发过程中遇到的问题。
-
积极参与社区:加入 LangChain 的社区论坛、Discord 频道或其他社交平台,与其他开发者交流经验和心得,获取支持和帮助。
-
实践驱动学习:通过实际项目来巩固所学知识,从简单的应用开始,逐步挑战更复杂的项目。
-
关注性能和安全:在开发过程中,注意优化应用的性能,合理管理资源,同时确保数据的安全性和合规性。
-
保持学习热情:技术发展迅速,持续学习新的知识和技能,关注行业动态,保持竞争力。
学习与提升路径
-
基础学习
- 官方文档阅读:系统地阅读 LangChain 的官方文档,了解各模块的使用方法和最佳实践。
- 示例代码实践:运行并研究官方提供的示例代码,动手实践,加深理解。
-
进阶提升
- 源码研究:深入研究 LangChain 的源码,理解内部实现机制,提升编程能力。
- 自定义开发:尝试开发自定义的 Chains、Tools 或 Agents,满足特定需求,增强解决问题的能力。
-
拓展应用
- 跨技术融合:学习如何将 LangChain 与其他前沿技术结合,如深度学习、知识图谱、强化学习等,拓展应用场景。
- 行业应用探索:针对医疗、金融、教育等行业,研究 LangChain 的应用,开发垂直领域的解决方案。
-
社区贡献
- 开源贡献:参与 LangChain 的开源项目,提交代码、文档或 Bug 报告,为社区发展做出贡献。
- 知识分享:撰写博客、教程或举办分享会,传播 LangChain 的使用经验,提升个人影响力。
-
持续学习
- 关注更新与动态:定期关注 LangChain 的版本更新和新特性,保持对框架发展的敏感度。
- 参与培训与活动:参加相关的技术交流会、研讨会和培训课程,拓宽视野,结识同行。
-
项目实践
- 构建实用项目:基于实际需求,开发有价值的应用,如智能客服、数据分析助手等,积累项目经验。
- 团队协作开发:与他人合作开发项目,学习团队协作和项目管理,提高综合素质。
通过以上学习路径,开发者可以全面提升对 LangChain 的理解和应用能力,成为自然语言处理领域的专家,为个人职业发展和行业创新贡献力量。
12. 参考文献与资源
官方文档与教程
-
LangChain 官方文档
LangChain 的官方文档是了解和学习框架的最佳起点,详细介绍了框架的设计理念、模块功能、安装指南和使用方法。文档内容包括:
- 快速入门指南:帮助新手快速上手,了解基本概念和示例。
- 模块详解:深入解析 Chains、Agents、Tools、Memory、Prompt Templates 等核心组件。
- API 参考:提供全面的类和方法说明,便于开发者查阅。
- 示例项目:涵盖各种应用场景的示例代码,供参考和学习。
链接:https://langchain.readthedocs.io/
-
官方教程与博客
官方博客定期发布教程、最佳实践和最新功能介绍,帮助开发者深入理解 LangChain 的使用方式和应用场景。
链接:https://blog.langchain.dev/
-
GitHub 代码仓库
LangChain 的源码和示例项目托管在 GitHub 上,开发者可以:
- 查看最新的源代码,了解内部实现。
- 提交 Issue 和 Pull Request,参与社区贡献。
- 浏览社区维护的插件和扩展。
链接:https://github.com/hwchase17/langchain
社区讨论与优秀项目
-
社区论坛与讨论组
LangChain 拥有活跃的开发者社区,提供了多个交流平台:
- Discord 频道:实时聊天和技术讨论。
链接:https://discord.gg/langchain - 论坛:提问与回答、分享经验、发布项目。
链接:https://discuss.langchain.dev/ - Stack Overflow:使用
langchain标签提问,获得社区支持。
链接:https://stackoverflow.com/questions/tagged/langchain
- Discord 频道:实时聊天和技术讨论。
-
优秀开源项目
社区成员开发了许多基于 LangChain 的优秀项目,涵盖了各种应用场景,如:
- 聊天机器人
- 自动化文档生成
- 智能客服系统
- 数据分析助手
这些项目通常托管在 GitHub 上,开发者可以克隆、学习并在此基础上进行二次开发。
-
技术博客与分享
许多开发者在个人博客、Medium、简书等平台分享了他们在使用 LangChain 过程中的经验、教程和心得:
- 使用 LangChain 构建对话式 AI
- LangChain 与 OpenAI API 的深度集成
- 优化 LangChain 应用的性能技巧
延伸阅读材料
-
大型语言模型(LLM)相关资料
-
研究论文
- Attention is All You Need:Transformer 模型的奠基性论文,了解 LLM 的基础。
链接:https://arxiv.org/abs/1706.03762 - GPT 系列模型论文:深入理解 GPT 模型的架构和训练方法。
- Attention is All You Need:Transformer 模型的奠基性论文,了解 LLM 的基础。
-
书籍
- Natural Language Processing with Transformers:介绍使用 Transformer 模型进行 NLP 任务的实践方法。
-
-
自然语言处理(NLP)经典书籍
- Speech and Language Processing(Daniel Jurafsky, James H. Martin):NLP 领域的权威教材,涵盖广泛的主题。
- Neural Network Methods for Natural Language Processing(Yoav Goldberg):聚焦深度学习在 NLP 中的应用。
-
机器学习与深度学习
- Deep Learning(Ian Goodfellow, Yoshua Bengio, Aaron Courville):深入了解深度学习的理论和实践。
- Pattern Recognition and Machine Learning(Christopher M. Bishop):机器学习的经典教材。
-
在线课程与培训
- Coursera 和 edX 平台上的 NLP 和深度学习课程。
- Fast.ai:提供实践导向的深度学习课程。
-
技术博客与新闻
- OpenAI 官方博客:了解最新的模型和研究动态。
链接:https://openai.com/blog/ - AI 专业媒体:如 Towards Data Science、Medium 上的 AI 专栏。
- OpenAI 官方博客:了解最新的模型和研究动态。
-
行业会议与论文集
- ACL、EMNLP、NAACL 等顶级 NLP 会议的论文,了解前沿研究成果。
- NeurIPS、ICML、ICLR 等机器学习领域的主要会议。
通过利用上述参考文献与资源,您可以:
- 深化对 LangChain 的理解:官方文档和教程提供了全面的指导,帮助您掌握框架的使用方法和最佳实践。
- 获取社区支持:参与社区讨论,向经验丰富的开发者请教问题,分享自己的经验。
- 拓展知识面:通过延伸阅读,了解更广泛的 NLP、机器学习和 AI 知识,为开发更先进的应用奠定基础。
- 紧跟技术前沿:关注最新的研究成果和行业趋势,确保自己的技能和项目保持竞争力。
积极学习和利用这些资源,将有助于您在 LangChain 的开发和应用中取得更大的成功。