
论文标题:SAMformer: Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention
论文链接:https://arxiv.org/abs/2402.10198
代码链接:https://github.com/romilbert/samformer
前言
这篇文章发表于ICML2024,文章要解决的问题、以及思路都很新奇,非常推荐大家阅读。基于Transformer的架构在多变量长期预测方面,仍然不如更简单的线性基线。作者首先通过一个toy线性预测问题,展示了Transformer尽管具有很高的表达能力,但无法收敛到它们的真实解,并且注意力机制是导致这种低泛化能力的原因。
基于这一洞见,提出了一个浅层轻量级Transformer模型,当使用感知锐度优化进行优化时,能够成功地逃离不良局部最小值。通过实证表明,这一结果扩展到了所有常用的现实世界多变量时间序列数据集。特别是,SAMformer超越了当前最先进的方法,并且参数数量显著减少。
本文工作
而事实上近期的研究工作在将Transformer应用于时间序列数据时,主要集中于两个方向:一是提高效率,减少注意力机制的二次计算成本;二是对时间序列进行分解,以便更准确地捕捉其内在的模式。令人意外的是,目前在多变量时间序列预测领域占据领先地位的是更为简单的基于多层感知器(MLP)的模型,其性能明显超过了基于Transformer的方法。这引发了人们对于Transformer在实际应用中价值的思考。
作者认为:这些研究并未特别针对Transformer在训练过程中的不稳定性问题,这一问题在缺乏大规模数据支持时尤为突出。而这恰是其性能落后的原因。作者目标是证明,通过消除训练过程中的不稳定性,Transformer能够在多变量长期预测任务中表现出色。
Toy experiment
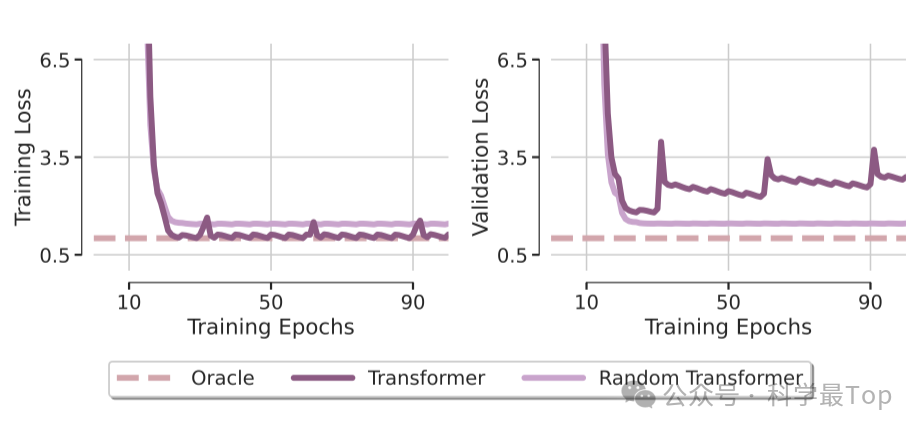
如上图,作者首先展示了两种模型的训练和验证的损失,其中Oracle是理论上的最优解。我们发现,transformer在训练集上几乎和理论最优解一致,这有两种可能,一是transformer效果确实好,二是过拟合。那么我们结合右图看,很明显,transformer在验证集效果不佳,存在明显的泛化能力不足问题。这一部分作者对transformer结构进行了简化,并且设计了实验,详细过程可阅读原文,最终的结论是:Transformer的泛化能力不足主要归咎于注意力模块的训练问题。
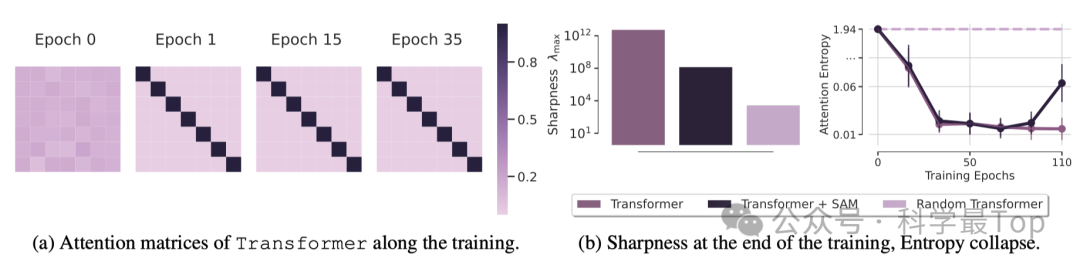
为了深入理解这一现象背后的原理,作者分析了不同训练阶段的注意力矩阵。可以看到,在最初的训练周期之后,注意力矩阵非常接近单位矩阵,并且在此后几乎没有变化,尤其是softmax函数放大了矩阵值之间的差异。这揭示了注意力熵崩溃的现象,也是训练Transformer困难的原因之一。作者还建立了熵崩溃与Transformer损失景观锐度(Sharpeness landscape)之间的关系。Transformer收敛到一个比随机Transformer更锐利的最小值,同时具有显著更低的熵,Transformer的失败归咎于熵崩溃和训练损失的锐度,这里我理解是transformer更容易陷入局部最优。
本文模型
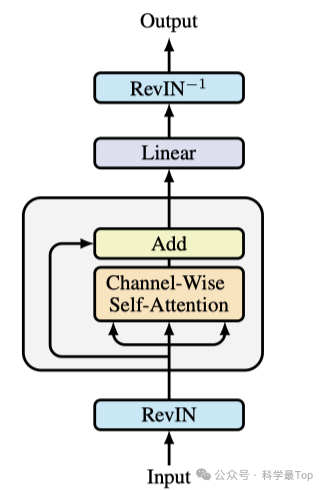
如图所示,SAMformer模型引入了两项关键的改进。首先采用了可逆实例归一化(Reversible Instance Normalization,RevIN)来处理输入X,因为研究表明,这种技术在处理时间序列训练和测试数据之间的偏移问题时非常有效。其次,采用了SAM(Sharpness-Aware Minimization,谷歌在另一篇论文提出的优化方法)优化算法来训练模型,使其能够收敛到更平坦的局部最小值。综合这些改进,得到了图中展示的具有单一编码器的浅层Transformer模型。
SAMformer保留D×D矩阵表示的通道注意力,这与其它模型中使用的L×L矩阵表示的空间(或时间)注意力形成对比。这种方法带来了两个显著的优势:首先,它确保了特征排列的不变性,从而消除了通常位于注意力层之前的定位编码的需求;其次,由于在大多数现实世界数据集中D ≤ L,它能够降低时间和内存的复杂度。因此,通道注意力机制能够评估每个特征在所有时间步上的综合影响。
本文实验
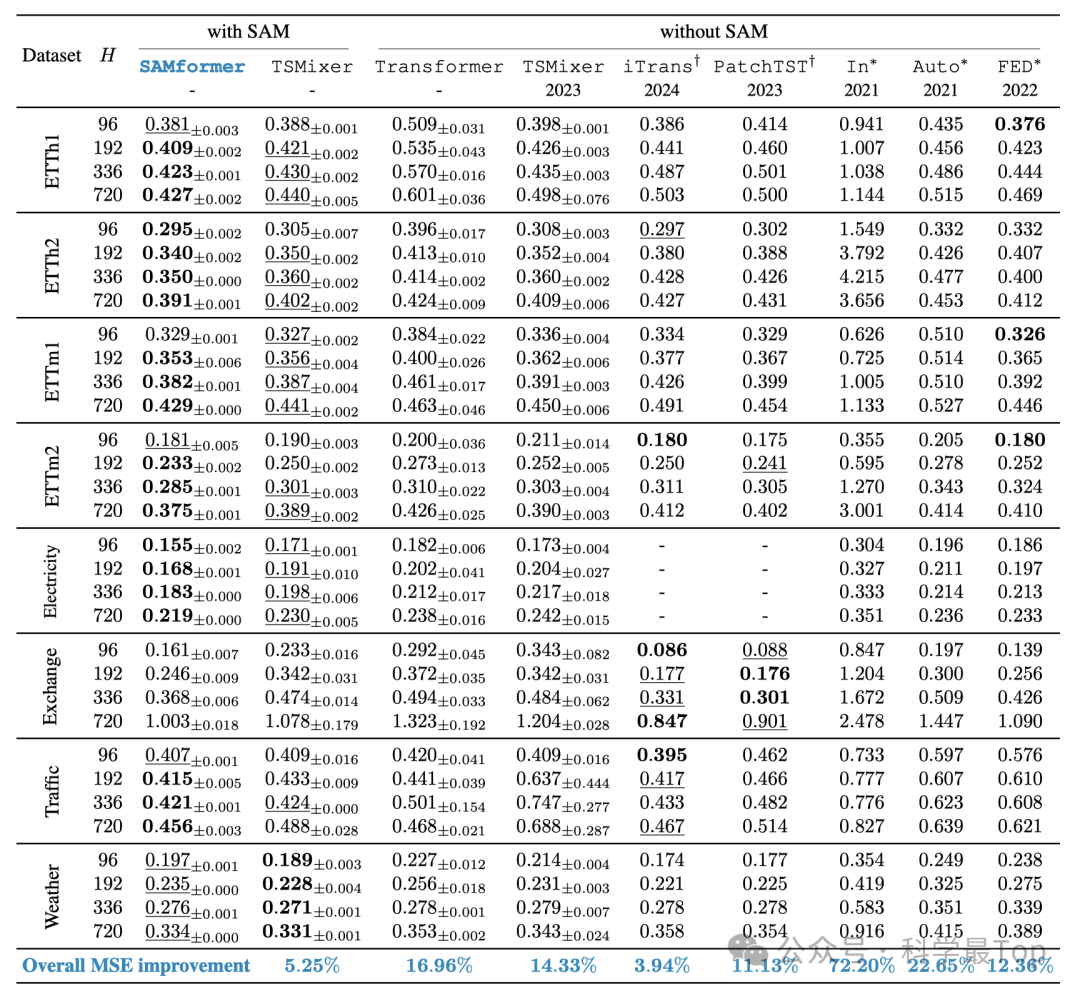
SAMformer在性能上实现了对现有最先进技术的显著超越。在8个数据集中,它比其最接近的竞争对手TSMixer+SAM的性能提升了5.25%,比单独的TSMixer提升了14.33%,比最佳的多变量Transformer模型FEDformer提升了12.36%。此外,与标准的Transformer模型相比,SAMformer的性能提升了16.96%。SAMformer还超越了最近推出的iTransformer,以及专门为单变量时间序列预测设计的PatchTST模型。
大家可以关注我的公众号【科学最top】,第一时间follow时序高水平论文解读!!!




















