在这里,我们将尝试全面深入地掌握成功实施 RAG 所必需的不同主题。以下是示例 RAG 架构。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
让我们从“文本拆分”的概念开始。
在这里,我们可能需要考虑根据某种类型的文本拆分方法将输入数据加载并转换为不同的块。让我们从不同的文本拆分方法开始,并比较所有这些方法的不同向量存储。
从高层次上讲,文本拆分器的工作原理如下:
- 将文本拆分成小的、语义上有意义的块(通常是句子)。
- 开始将这些小块组合成更大的块,直到达到一定的大小(由某个函数测量)。
- 一旦达到该大小,就将该块作为自己的文本,然后开始创建具有一定重叠的新文本块(以保持块之间的上下文)。
这意味着你可以沿着两个不同的轴自定义文本分割器:
- 如何分割文本
- 如何测量块大小
1、使用 RAG 的实用代码示例
导入库:
import osfrom langchain.text_splitter import (CharacterTextSplitter,RecursiveCharacterTextSplitter,SentenceTransformersTokenTextSplitter,TextSplitter,TokenTextSplitter,
)
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings本节导入脚本所需的模块和类。这些包括文本分割器、文档加载器、向量存储和嵌入。langchain_community 和 langchain_openai 库用于加载文档、将其分割成可管理的块并创建嵌入。
目录设置:
# Define the directory containing the text file
current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_dir, "books", "romeo_and_juliet.txt")
db_dir = os.path.join(current_dir, "db")代码定义了脚本的当前目录、文本文件 (romeo_and_juliet.txt) 的路径以及将保存向量存储的目录 (db 目录)。
文件存在性检查:
# Check if the text file exists
if not os.path.exists(file_path):raise FileNotFoundError(f"The file {file_path} does not exist. Please check the path.")代码检查指定的文本文件是否存在。如果不存在,它会引发 FileNotFoundError,从而停止脚本并提供错误消息。
加载文本内容:
# Read the text content from the file
loader = TextLoader(file_path)
documents = loader.load()TextLoader 类用于将文本文件的内容加载到脚本中。此内容存储在 documents 变量中。
定义嵌入模型:
# Define the embedding model
embeddings = OpenAIEmbeddings(model="text-embedding-3-small"
) # Update to a valid embedding model if needed代码设置了嵌入模型,将文本数据转换为数值向量。此特定模型 (text-embedding-3-small) 用于嵌入文本数据,可根据需要进行更新。
创建和持久化向量存储的函数:
# Function to create and persist vector store
def create_vector_store(docs, store_name):persistent_directory = os.path.join(db_dir, store_name)if not os.path.exists(persistent_directory):print(f"\n--- Creating vector store {store_name} ---")db = Chroma.from_documents(docs, embeddings, persist_directory=persistent_directory)print(f"--- Finished creating vector store {store_name} ---")else:print(f"Vector store {store_name} already exists. No need to initialize.")此函数检查指定目录中是否已存在向量存储。如果不存在,它将使用提供的文档和嵌入创建并保存一个新的向量存储。向量存储保存在 db_dir 目录中,名称由 store_name 提供。
2、拆分文本
现在,本文最重要的是如何拆分输入语料库数据。在这里,我们将研究拆分数据的不同方法,并检查它们的输出。
2.1 基于字符的拆分
# 1. Character-based Splitting
# Splits text into chunks based on a specified number of characters.
# Useful for consistent chunk sizes regardless of content structure.
print("\n--- Using Character-based Splitting ---")
char_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
char_docs = char_splitter.split_documents(documents)
create_vector_store(char_docs, "chroma_db_char")文本被拆分成 1000 个字符的块,块之间有 100 个字符的重叠。此方法可确保块大小一致,而不管文本的内容结构如何。生成的块存储在名为 chroma_db_char 的向量存储中。
2.2 基于句子的拆分
# 2. Sentence-based Splitting
# Splits text into chunks based on sentences, ensuring chunks end at sentence boundaries.
# Ideal for maintaining semantic coherence within chunks.
print("\n--- Using Sentence-based Splitting ---")
sent_splitter = SentenceTransformersTokenTextSplitter(chunk_size=1000)
sent_docs = sent_splitter.split_documents(documents)
create_vector_store(sent_docs, "chroma_db_sent")文本根据句子被拆分成块,每个块最多包含 1000 个字符。此方法可确保块保持语义连贯性。生成的块存储在名为 chroma_db_sent 的向量存储中。
2.3 基于标记的拆分
# 3. Token-based Splitting
# Splits text into chunks based on tokens (words or subwords), using tokenizers like GPT-2.
# Useful for transformer models with strict token limits.
print("\n--- Using Token-based Splitting ---")
token_splitter = TokenTextSplitter(chunk_overlap=0, chunk_size=512)
token_docs = token_splitter.split_documents(documents)
create_vector_store(token_docs, "chroma_db_token")根据标记(例如单词或子词)将文本拆分为块。此方法在使用具有严格标记限制的转换器模型时特别有用。生成的块存储在名为 chroma_db_token 的向量存储中。
2.4 基于字符的递归拆分
# 4. Recursive Character-based Splitting
# Attempts to split text at natural boundaries (sentences, paragraphs) within character limit.
# Balances between maintaining coherence and adhering to character limits.
print("\n--- Using Recursive Character-based Splitting ---")
rec_char_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
rec_char_docs = rec_char_splitter.split_documents(documents)
create_vector_store(rec_char_docs, "chroma_db_rec_char")此方法尝试在自然边界(例如句子或段落)处拆分文本,同时遵守字符限制。它在保持一致性和将块保持在指定大小之间取得平衡。生成的块存储在名为 chroma_db_rec_char 的向量存储中。
2.5 自定义拆分
# 5. Custom Splitting
# Allows creating custom splitting logic based on specific requirements.
# Useful for documents with unique structure that standard splitters can't handle.
print("\n--- Using Custom Splitting ---")class CustomTextSplitter(TextSplitter):def split_text(self, text):# Custom logic for splitting textreturn text.split("\n\n") # Example: split by paragraphscustom_splitter = CustomTextSplitter()
custom_docs = custom_splitter.split_documents(documents)
create_vector_store(custom_docs, "chroma_db_custom")本节定义了一个自定义文本分割器,可根据特定要求(在本例中为按段落)分割文本。此方法适用于标准分割器可能无法很好地处理的独特结构的文档。生成的块存储在名为 chroma_db_custom 的向量存储中。
3、查询
查询向量库:
# Function to query a vector store
def query_vector_store(store_name, query):persistent_directory = os.path.join(db_dir, store_name)if os.path.exists(persistent_directory):print(f"\n--- Querying the Vector Store {store_name} ---")db = Chroma(persist_directory=persistent_directory, embedding_function=embeddings)retriever = db.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 1, "score_threshold": 0.1},)relevant_docs = retriever.invoke(query)# Display the relevant results with metadataprint(f"\n--- Relevant Documents for {store_name} ---")for i, doc in enumerate(relevant_docs, 1):print(f"Document {i}:\n{doc.page_content}\n")if doc.metadata:print(f"Source: {doc.metadata.get('source', 'Unknown')}\n")else:print(f"Vector store {store_name} does not exist.")此函数使用用户定义的查询来查询特定的向量存储。它会检查向量存储是否存在,根据查询检索相关文档,然后显示结果以及任何元数据。
查询执行:
# Define the user's question
query = "How did Juliet die?"# Query each vector store
query_vector_store("chroma_db_char", query)
query_vector_store("chroma_db_sent", query)
query_vector_store("chroma_db_token", query)
query_vector_store("chroma_db_rec_char", query)
query_vector_store("chroma_db_custom", query)代码定义了一个查询(“朱丽叶是怎么死的?”),并使用它来查询每个先前创建的向量存储。它为每个存储调用 query_vector_store 函数,检索并显示相关文档。
以下是完整的代码,供您参考。
import osfrom langchain.text_splitter import (CharacterTextSplitter,RecursiveCharacterTextSplitter,SentenceTransformersTokenTextSplitter,TextSplitter,TokenTextSplitter,
)
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings# Define the directory containing the text file
current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_dir, "books", "romeo_and_juliet.txt")
db_dir = os.path.join(current_dir, "db")# Check if the text file exists
if not os.path.exists(file_path):raise FileNotFoundError(f"The file {file_path} does not exist. Please check the path.")# Read the text content from the file
loader = TextLoader(file_path)
documents = loader.load()# Define the embedding model
embeddings = OpenAIEmbeddings(model="text-embedding-3-small"
) # Update to a valid embedding model if needed# Function to create and persist vector store
def create_vector_store(docs, store_name):persistent_directory = os.path.join(db_dir, store_name)if not os.path.exists(persistent_directory):print(f"\n--- Creating vector store {store_name} ---")db = Chroma.from_documents(docs, embeddings, persist_directory=persistent_directory)print(f"--- Finished creating vector store {store_name} ---")else:print(f"Vector store {store_name} already exists. No need to initialize.")# 1. Character-based Splitting
# Splits text into chunks based on a specified number of characters.
# Useful for consistent chunk sizes regardless of content structure.
print("\n--- Using Character-based Splitting ---")
char_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
char_docs = char_splitter.split_documents(documents)
create_vector_store(char_docs, "chroma_db_char")# 2. Sentence-based Splitting
# Splits text into chunks based on sentences, ensuring chunks end at sentence boundaries.
# Ideal for maintaining semantic coherence within chunks.
print("\n--- Using Sentence-based Splitting ---")
sent_splitter = SentenceTransformersTokenTextSplitter(chunk_size=1000)
sent_docs = sent_splitter.split_documents(documents)
create_vector_store(sent_docs, "chroma_db_sent")# 3. Token-based Splitting
# Splits text into chunks based on tokens (words or subwords), using tokenizers like GPT-2.
# Useful for transformer models with strict token limits.
print("\n--- Using Token-based Splitting ---")
token_splitter = TokenTextSplitter(chunk_overlap=0, chunk_size=512)
token_docs = token_splitter.split_documents(documents)
create_vector_store(token_docs, "chroma_db_token")# 4. Recursive Character-based Splitting
# Attempts to split text at natural boundaries (sentences, paragraphs) within character limit.
# Balances between maintaining coherence and adhering to character limits.
print("\n--- Using Recursive Character-based Splitting ---")
rec_char_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
rec_char_docs = rec_char_splitter.split_documents(documents)
create_vector_store(rec_char_docs, "chroma_db_rec_char")# 5. Custom Splitting
# Allows creating custom splitting logic based on specific requirements.
# Useful for documents with unique structure that standard splitters can't handle.
print("\n--- Using Custom Splitting ---")class CustomTextSplitter(TextSplitter):def split_text(self, text):# Custom logic for splitting textreturn text.split("\n\n") # Example: split by paragraphscustom_splitter = CustomTextSplitter()
custom_docs = custom_splitter.split_documents(documents)
create_vector_store(custom_docs, "chroma_db_custom")# Function to query a vector store
def query_vector_store(store_name, query):persistent_directory = os.path.join(db_dir, store_name)if os.path.exists(persistent_directory):print(f"\n--- Querying the Vector Store {store_name} ---")db = Chroma(persist_directory=persistent_directory, embedding_function=embeddings)retriever = db.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 1, "score_threshold": 0.1},)relevant_docs = retriever.invoke(query)# Display the relevant results with metadataprint(f"\n--- Relevant Documents for {store_name} ---")for i, doc in enumerate(relevant_docs, 1):print(f"Document {i}:\n{doc.page_content}\n")if doc.metadata:print(f"Source: {doc.metadata.get('source', 'Unknown')}\n")else:print(f"Vector store {store_name} does not exist.")# Define the user's question
query = "How did Juliet die?"# Query each vector store
query_vector_store("chroma_db_char", query)
query_vector_store("chroma_db_sent", query)
query_vector_store("chroma_db_token", query)
query_vector_store("chroma_db_rec_char", query)
query_vector_store("chroma_db_custom", query)一些查询的输出:
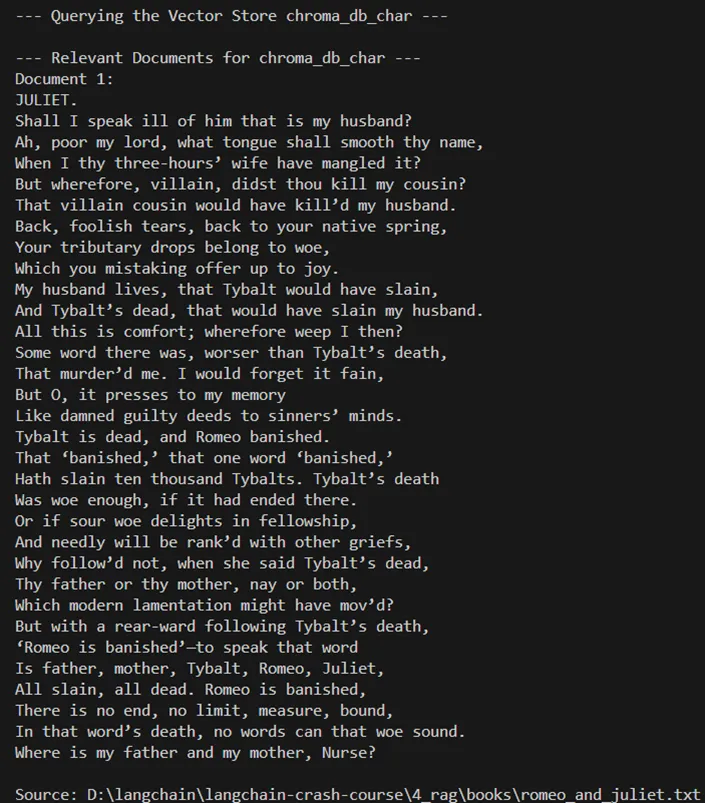
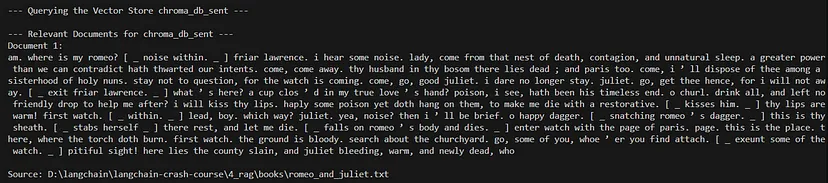
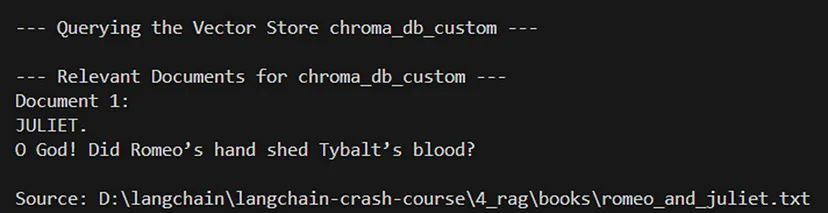
此代码提供了一种全面的文档处理、拆分、矢量化和查询方法。它允许尝试不同的文本拆分方法,并演示如何使用 Chroma 矢量存储来存储和查询文本嵌入。
原文链接:RAG文本拆分深入研究 - BimAnt