项目概述
名字解释 缩写: pdf2tx-MM
pdf file transfer to text content with Multi-threads and Multi-translators
pdf2tx-MM 是一个基于 Flask 的 Web 应用程序,提供将 PDF 文件中的内容提取、翻译并展示。使用者上传 PDF 文件,应用程序将对其进行 OCR 识别,提取文本内容,并使用指定的翻译引擎(如 Google 、Microsoft 翻译)将文本翻译成目标语言(中文简体,与繁体)。处理完成后,用户可以查看原文和译文的对比。
Added on 9oct.24 7pm. 这个项目的的代码有小改动如下:
升级 (P8.1)
8oct.24
使用jieba,可以对中文进行自然语言识别
对日文翻译,使用janome库,对日文使用自然语言分割,提高翻译准确
程序可以识别PDF是文本(langdetect),还是图片,图片才调用OCR
翻译过程并行化(ThreadPoolExecutor)
翻译结果加入 传统中文
可以下载翻译的文本
放弃ZhipuAI做为翻译机,因为在测试时,总是出发敏感词检测。
进度算法改为:考虑页数
————————————————版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/davenian/article/details/142797522
所有代码、有关的Docker安装文件,在下面的文章链接中保存,QNAP Container APP上部署是成功的。
原文链接:Project-8.1 pdf2tx-MM https://blog.csdn.net/davenian/article/details/142797522
原因
P6项目: pdf2tx 运行时间太久,工作在单线程,对大PDF文件会造成运行Container的NAS宕机。所以,对P6: <Project-6 pdf2tx> Python Flask 应用:图片PDF图书的中文翻译解决方案
使用P7 ipdf2tx 代码提速:<Project-7 ipdf2tx> Python flask应用 在浏览器中提交 PDF图片 转换 文本PDF,同时保留图像 多进程 OCR 详细的安装准备环境
目的
缩短执行时间与对系统的占用:
用多任务方法来提升OCR速度
用提供语言范围,使OCR提高识别效率
注册了Azure的账号,建立了一个翻译资源(Pricing Tier free, Limit 5M/月),实现可以翻译机功能
提高翻译质量:
利用NLTK库,对语言进行分割
使用Azure资源(比GoogleTranslator 快了35秒,遇到输出有排版问题...)
功能简介
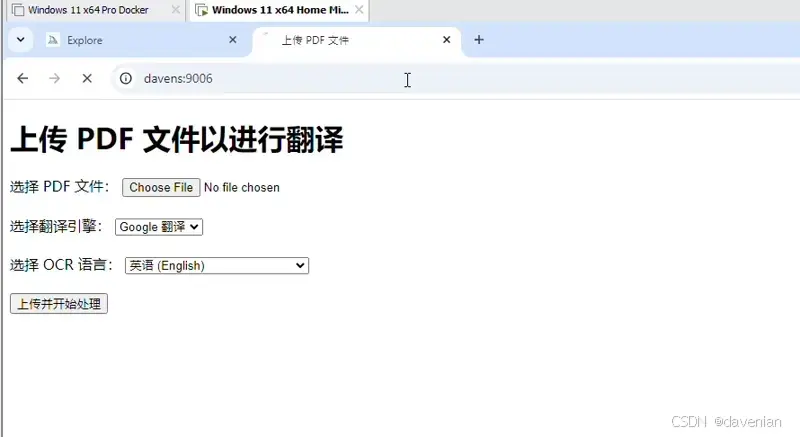
- PDF 文件上传:用户可以通过网页上传需要处理的 PDF 文件。
- OCR 识别:应用程序使用 Tesseract OCR 将 PDF 文件中的内容转换为可编辑的文本。
- 多语言支持:支持多种 OCR 语言,如英文、简体中文、繁体中文等。
- 文本翻译:集成了多个翻译引擎(如 Google 翻译、Microsoft 翻译),用户可以选择翻译引擎,将提取的文本翻译成目标语言。
- 进度跟踪:在处理过程中,实时显示处理进度,提供友好的用户体验。
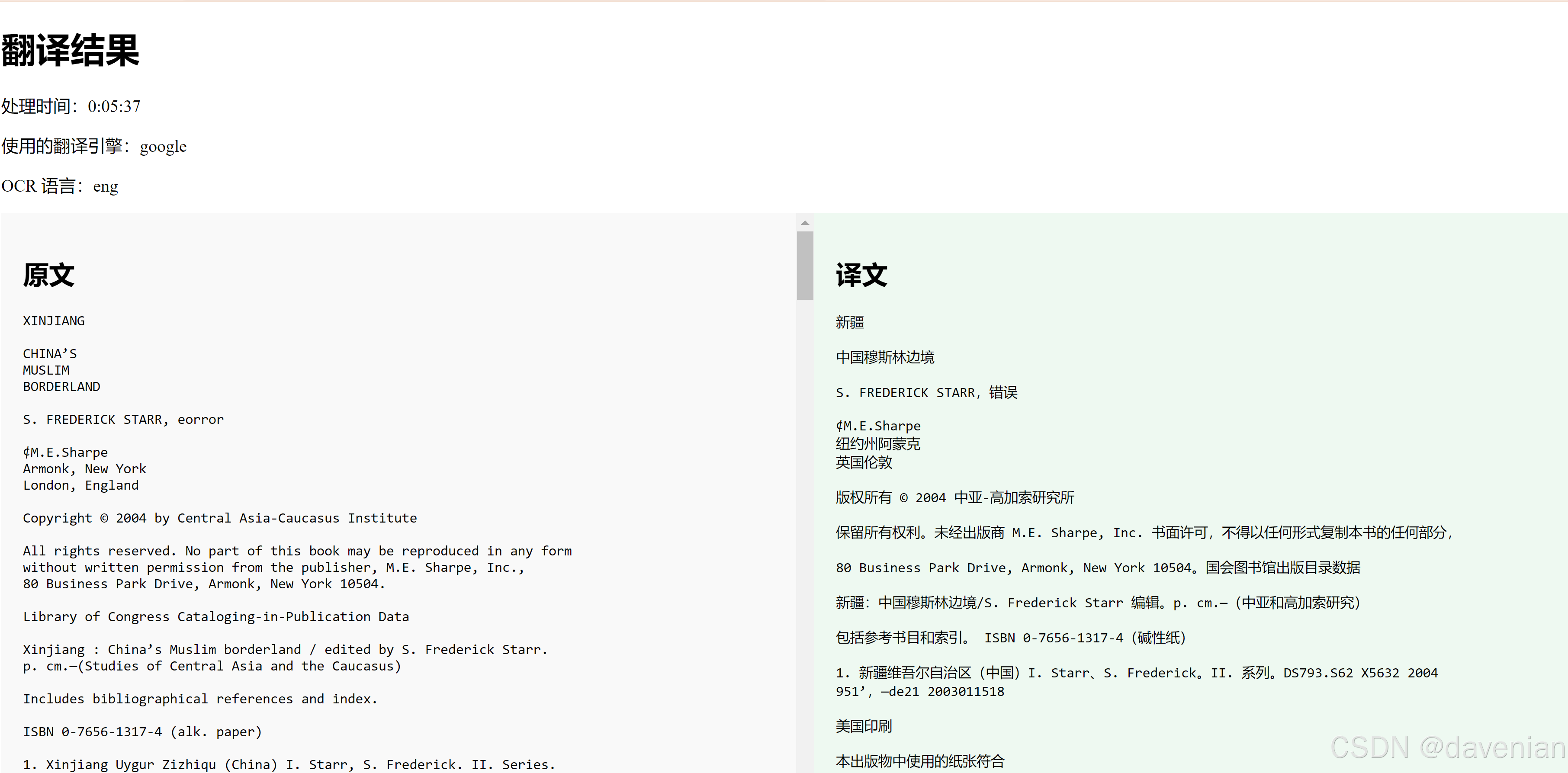
- 结果展示:处理完成后,用户可以在网页上查看原文和译文的对比,方便浏览和校对。
- Docker 部署:提供了 Dockerfile,方便应用程序的容器化部署。
操作与功能展示
注:使用 Windows 11 录屏,用 Acdsee Video Stuido 转为Gif 文件 (用DOS 时,中关村的 CD 带有 acdsee.exe 用来看日本写真,某年的黑五买了这软件包,就一直停留在那一年的版本里,升级要花钱的)
代码结构
目录结构
pdf2tx-MM/
├── app.py
├── config.ini
├── requirements.txt
├── Dockerfile
├── templates/
│ ├── upload.html
│ ├── processing.html
│ └── result.html
└── uploads/ # 用于存储上传的文件
程序的逻辑
多进程方式把PDF转为图像
-> OCR提取图片中的文字
->NLTK 分割段落
-> 文字交给翻译器
-> 翻译的结果在网页上显示
同P6, 可能PDF内容未授权,上传代码没有保存内容的功能。
主要组件
1. app.py
应用的主程序,包含了所有的后端逻辑。主要功能有:
- Flask 应用的初始化和配置
- 路由定义:处理文件上传、进度跟踪、结果展示等路由。
- 后台处理函数:包括文件的 OCR 处理和文本翻译。
- 辅助函数:如文件类型检查、OCR 处理、文本翻译等。
2. 模板文件
templates/upload.html:文件上传,提供选择文件、选择翻译引擎和 OCR 语言的选择。templates/processing.html:文件处理的进度页面,实时显示处理进度。templates/result.html:结果页面,会有处理时间、使用的翻译引擎、OCR 语言,以及原文和译文的对比。
3. config.ini
用于存储敏感的配置信息,如 API 密钥和区域信息。格式如下:
[translator]
azure_api_key = YOUR_AZURE_API_KEY
azure_region = YOUR_AZURE_REGION
可能会涉及敏感信息,在用GIT时,应该在config.ini目录下,创建一个 .gitignore (文件第一个字符是“点” dot point . )
文件内容是config.ini , 你不想因Git版本控制,上传的文件。
.gitignore 的使用场景:
- 忽略敏感信息:如密码、API 密钥、配置文件等不应暴露在公共代码库中的文件。
- 忽略临时文件:开发过程中产生的临时文件或日志文件。
- 忽略编译生成文件:如
.exe、.o等编译生成的文件,这些文件不需要放入版本库,且通常是机器特定的。
4. Dockerfile
应用程序的容器化部署: 基础镜像、依赖项安装、环境变量设置等。
关键功能的实现
1. 文件上传与处理
# 允许的文件类型检查函数
def allowed_file(filename):@app.route('/', methods=['GET', 'POST'])
def upload_file():
功能:
- 接收用户上传的 PDF 文件。
- 检查文件类型和有效性。
- 保存上传的文件到指定目录。
- 获取用户选择的翻译引擎和 OCR 语言。
- 生成唯一的任务 ID,启动后台处理线程。
- 重定向到处理进度页面。
2. OCR 识别
def ocr_image(image, lang='eng'):功能:
- 使用 Tesseract OCR 对图像进行文字识别。
- 支持多种语言,用户可以选择 OCR 语言。
3. 文本翻译
def translate_text(text, engine, progress_callback=None, text_lang='eng')功能:
- 将提取的文本进行分句处理,以适应翻译引擎的字符限制。
- 支持多种翻译引擎,用户可以选择使用的翻译引擎。
- 根据 OCR 语言,映射到翻译引擎支持的源语言代码。
- 使用线程池并行翻译,提高翻译速度。
- 提供进度回调函数,实时更新处理进度。
- 实现了重试机制和缓存机制,增强了稳定性和性能。
4. 进度跟踪与显示
功能:
- 使用全局字典
progress和progress_lock记录各个任务的处理进度。 - 在处理过程中,定期更新进度信息。
- 前端页面通过 SSE(Server-Sent Events)与后端通信,实时获取进度更新。
5. 结果展示
@app.route('/result/<task_id>')功能:
- 从全局字典
results中获取指定任务的处理结果。 - 格式化处理时间为
HH:MM:SS格式。 - 将原文、译文、处理时间、使用的翻译引擎和 OCR 语言传递给模板。
安装与配置
环境准备
| OS | Python | Python必要库 | 库组件 |
| Windows 11 23H2 | 3.12.3 | NLTK | punkt, popular, punkt_tab |
| QNAP Container | unstructured | #NLTK需要 | |
| pytesseract | tesseract-ocr-chi-sim | ||
| pdf2image | |||
| werkzeug | |||
| #库都为最新版 | deep_translator | ||
| Flask |
安装 python:3.12.3-slim
安装必要的库和工具:
- Flask(Web 框架)
- pytesseract(OCR 库)
- pdf2image(将 PDF 页面转换为图像)
- NLTK(自然语言分割,为翻译整句提升质量)
- deep_translator(翻译机)
- tesseract-ocr(需要系统安装,还有训练后的语言DATA,参考P7文章)
- unstructured (非结构化 数据处理 nltk调用)
- 先在Windows 11上实现,再实现Linux Docker,以下是在Windows 11上的操作。 Linux 如果有字体、字库问题,在P1里有提及安装 pytz
因为重复,以下纯引用P7文章内容
<Project-7 ipdf2tx> Python flask应用 在浏览器中提交 PDF图片 转换 文本PDF,同时保留图像 多进程 OCR 详细的安装准备环境-CSDN博客
pytesseract(OCR 库)
项目:https://github.com/UB-Mannheim/tesseract/wiki
Windows 11有安装包下载(我写这篇时的最新版本):https://github.com/UB-Mannheim/tesseract/releases/download/v5.4.0.20240606/tesseract-ocr-w64-setup-5.4.0.20240606.exe如果想得到更准确识别,还有训练过的语言包下载:GitHub - tesseract-ocr/tessdata: Trained models with fast variant of the "best" LSTM models + legacy models
我下载了简体中文包:chi_sim.traineddata,这个比安装文件自带的大多了41MB,我又下载了english 包。
下载后,文件放到:C:\Program Files\Tesseract-OCR\tessdata
(如果你安装它在上面目录)Linux可以用sudo来安装,如:
sudo apt-get update
sudo apt-get install tesseract-ocr
sudo apt-get install tesseract-ocr-chi-sim
添加路径
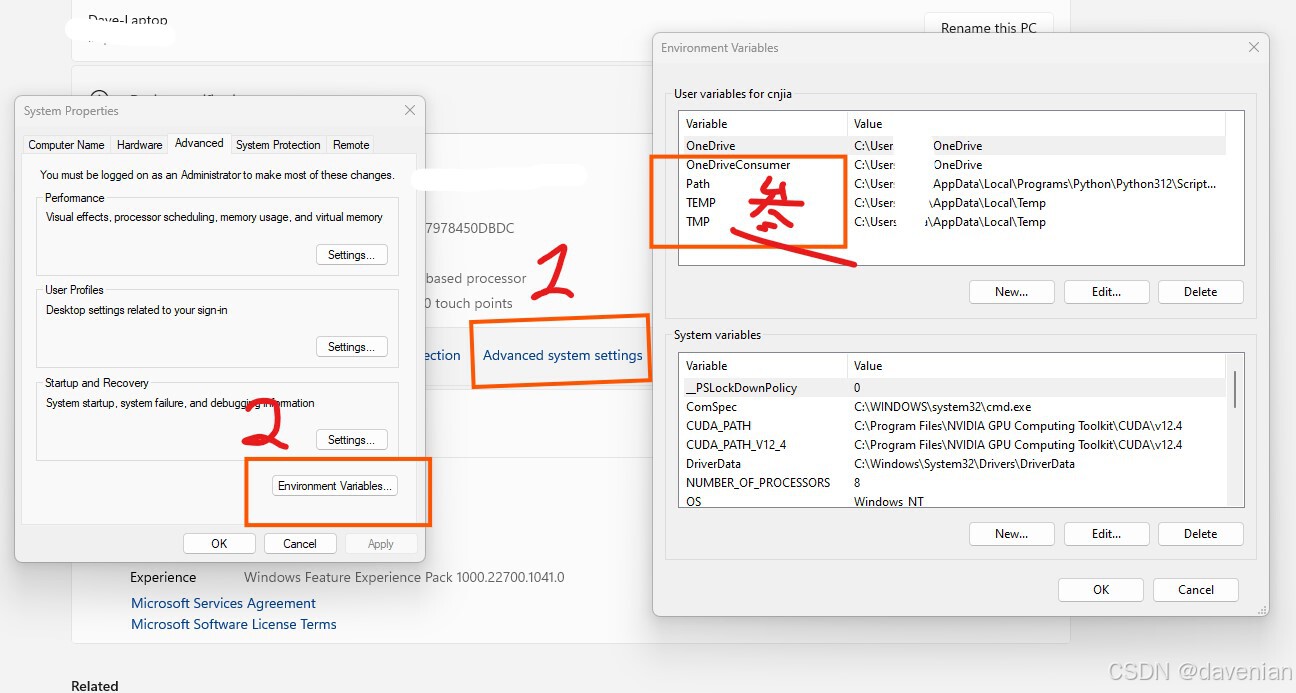
NLTK 库
参考:https://www.nltk.org/install.html#
安装NLTK后,还要安装 NLTK数据, P8主要用 punkt
python -m nltk.downloader punkt我曾以为安装了NLTK后,就有punkt. 但运行时报错:
"INFO:werkzeug:127.0.0.1 - - [07/Oct/2024 18:18:17] "GET /progress/4235df2a-faf3-4b28-a45d-bd94a53fa91b HTTP/1.1" 200 -
ERROR:root:处理失败:
**********************************************************************Resource punkt_tab not found.Please use the NLTK Downloader to obtain the resource:>>> import nltk>>> nltk.download('punkt_tab')For more information see: https://www.nltk.org/data.htmlAttempted to load tokenizers/punkt_tab/english/Searched in:还学着在code中,加入确保下载:
import nltk
nltk.download('punkt', quiet=True)还是报类似错误 (报错信息没有存,印象里是)
在网上看了很多篇,以至于总结出:这帮骗子们。直到看到了GitHut上一个讨论:NLTK Error in partition_pdf(): Resource "punkt_tab" not found #3511
CS50AI Parser - Check50 "nltk.download('punkt_tab')" ERROR
在看完他们的讨论后,我查了我的 Windows 11 上没有 unstructured 库,因为 punkt 调用找不到它,安装unstructured ,还安装了NLTK punkt_tab 数据包, 觉得后者是解决问题的关键。 参数all都放里面打包安装了。
问题解决。
想了解它的,看: unstructured · PyPI
其它没遇到问题,略过...
完整代码
复制代码,环境相同,软件就可以正常工作。这里涉及key,在config.ini文件中填入自己密匙
pdf2tx-MM/
├── app.py
├── config.ini
├── requirements.txt
├── Dockerfile
├── templates/
│ ├── upload.html
│ ├── processing.html
│ └── result.html
└── uploads/ # 用于存储上传的文件
1. app.py
import os
import uuid
import logging
import configparser
from flask import Flask, render_template, request, redirect, url_for, Response
from threading import Thread, Lock
from werkzeug.utils import secure_filename
from pdf2image import convert_from_path
import pytesseract
from deep_translator import GoogleTranslator, MicrosoftTranslator, YandexTranslator
from concurrent.futures import ThreadPoolExecutor
from collections import defaultdict
import time # 导入 time 模块, 显示处理时间用
from datetime import timedelta #在结果页面显示处理时间,格式为 HH:MM
import nltk
#nltk.download('punkt', quiet=True) # 已经安装,用:python -m nltk.downloader popular
# !!!安装NLTK后,还要安装NLTK DATA:python -m nltk.downloader popular 这个示例没有包含 punkt, 需要指定安装。
# 但运行还会报错! 还需要安装 unstructured 库,Y TMD在介绍里没说 f!
from functools import lru_cache# 初始化 Flask 应用
app = Flask(__name__)
app.config['ALLOWED_EXTENSIONS'] = {'pdf'}
app.config['UPLOAD_FOLDER'] = 'uploads'
app.config['MAX_CONTENT_LENGTH'] = 50 * 1024 * 1024 # 50MB# 确保上传文件夹存在
os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True)# 全局变量
progress = defaultdict(int)
results = {}
progress_lock = Lock()# 设置日志 格式
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')# 读取配置文件
config = configparser.ConfigParser()
config_file = 'config.ini'if not os.path.exists(config_file):raise FileNotFoundError(f"配置文件 {config_file} 未找到,请确保其存在并包含必要的配置。")config.read(config_file)try:AZURE_API_KEY = config.get('translator', 'azure_api_key') # Microsoft Azure 需要KEY, 它给了2个,可以循环使用。用一个就行。AZURE_REGION = config.get('translator','azure_region') # 还需要 copied: This is the location (or region) of your resource. You may need to use this field when making calls to this API.# 如果有其他 API 密钥,例如 Yandex,可以在此添加# YANDEX_API_KEY = config.get('translator', 'yandex_api_key')
except (configparser.NoSectionError, configparser.NoOptionError):raise ValueError("配置文件中缺少必要的配置选项。")# 允许的文件类型检查函数
def allowed_file(filename):return '.' in filename and filename.rsplit('.', 1)[1].lower() in app.config['ALLOWED_EXTENSIONS']# OCR 函数,指定语言
def ocr_image(image, lang='eng'):try:text = pytesseract.image_to_string(image, lang=lang)except Exception as e:logging.error(f"OCR 失败: {e}")text = ''return text# 翻译文本函数,支持分段、并行、进度更新、重试和缓存
def translate_text(text, engine, progress_callback=None, text_lang='eng'):# 定义支持的语言映射# Microsoft 翻译 API 的要求,如果要启用自动检测源语言,应将 source 参数设置为 None 或空字符串 '',加入 souce_lang_code变量language_mapping = {'eng': 'en','fra': 'fr','deu': 'de','spa': 'es','ita': 'it','jpn': 'ja','kor': 'ko','rus': 'ru','chi_sim': 'zh-Hans','chi_tra': 'zh-Hant',# 添加其他语言}nltk_lang = language_mapping.get(text_lang)source_lang_code = language_mapping.get(text_lang) #获取源语言代码 if nltk_lang:try:sentences = nltk.sent_tokenize(text, language=nltk_lang)except Exception as e:logging.error(f"NLTK 分句失败,使用默认分割方法:{e}")sentences = text.split('\n')else:# 对于不支持的语言,使用简单的分割方法sentences = text.split('\n')# 定义翻译器实例或函数translators = {'google': GoogleTranslator(source='auto', target='zh-CN'),'microsoft': MicrosoftTranslator(source=source_lang_code,target='zh-hans', api_key=AZURE_API_KEY,region=AZURE_REGION),# 如果需要,将 Yandex 的 API 密钥添加到配置文件中,并在此处使用# 'yandex': YandexTranslator(api_key=YANDEX_API_KEY, target='zh'),# 添加其他翻译器}translator = translators.get(engine)if not translator:raise ValueError(f"不支持的翻译引擎: {engine}")max_length = 5000 # 翻译引擎单次请求的最大字符数# 使用 NLTK 按句子分割文本sentences = nltk.sent_tokenize(text)chunks = []current_chunk = ''for sentence in sentences:if len(current_chunk) + len(sentence) + 1 <= max_length:current_chunk += sentence + ' 'else:chunks.append(current_chunk.strip())current_chunk = sentence + ' 'if current_chunk:chunks.append(current_chunk.strip())translated_chunks = [''] * len(chunks)total_chunks = len(chunks)completed_chunks = 0# 缓存翻译结果@lru_cache(maxsize=1000)def translate_text_chunk(chunk):if callable(translator):return translator(chunk)else:return translator.translate(chunk)# 定义翻译单个块的函数,带有重试机制def translate_chunk(index, chunk):nonlocal completed_chunksmax_retries = 3for attempt in range(max_retries):try:translated_chunk = translate_text_chunk(chunk)translated_chunks[index] = translated_chunkbreak # 成功后跳出循环except Exception as e:logging.error(f"翻译块 {index} 失败,尝试次数 {attempt + 1}: {e}")if attempt == max_retries - 1:translated_chunks[index] = chunk # 最后一次重试失败,使用原文completed_chunks += 1if progress_callback:# 假设翻译过程占总进度的 40%progress = 60 + int(40 * completed_chunks / total_chunks)progress_callback(progress)# 使用线程池并行翻译with ThreadPoolExecutor(max_workers=5) as executor:for idx, chunk in enumerate(chunks):executor.submit(translate_chunk, idx, chunk)translated_text = ' '.join(translated_chunks)return translated_text.strip()# 后台处理函数
# 使用 logging.info 在调试模式中输出所使用的翻译引擎和处理时间
# 在任务开始时,记录开始时间 start_time。
# 在任务结束时,记录结束时间 end_time,计算处理时间 elapsed_time。
# 将 elapsed_time 保存到 results 字典中,以便在结果页面显示
def process_file(task_id, filepath, engine, ocr_lang):global resultstry:start_time = time.time() # 记录开始时间logging.info(f"任务 {task_id}: 开始处理文件 {filepath},使用 OCR 语言 {ocr_lang},翻译引擎 {engine}") # 输出详细信息with progress_lock:progress[task_id] = 10# 将 PDF 转换为图像images = convert_from_path(filepath)total_pages = len(images)extracted_text = ''for i, image in enumerate(images):text = ocr_image(image, lang=ocr_lang)extracted_text += text + '\n'with progress_lock:progress[task_id] = 10 + int(50 * (i + 1) / total_pages)# 翻译文本,传递 progress_callbackdef progress_callback(p):with progress_lock:progress[task_id] = ptranslated_text = translate_text(extracted_text, engine, progress_callback, text_lang=ocr_lang) #确保正确传递 ocr_langwith progress_lock:progress[task_id] = 100# 计算处理时间end_time = time.time()elapsed_time = end_time - start_time # 处理所用的时间,单位为秒# 将处理时间保存到结果中result = {'original': extracted_text,'translated': translated_text,'elapsed_time': elapsed_time, # 添加处理时间'engine': engine, # 添加翻译引擎'ocr_lang': ocr_lang # 添加 OCR 语言}results[task_id] = result# 删除上传的文件os.remove(filepath)logging.info(f"任务 {task_id}: 处理完成,耗时 {elapsed_time:.2f} 秒") # 输出处理时间except Exception as e:logging.error(f"处理失败: {e}")with progress_lock:progress[task_id] = -1# 文件上传路由
@app.route('/', methods=['GET', 'POST'])
def upload_file():if request.method == 'POST':# 检查请求中是否有文件if 'file' not in request.files:return '请求中没有文件部分', 400file = request.files['file']if file.filename == '':return '未选择文件', 400if file and allowed_file(file.filename):# 安全地保存文件filename = secure_filename(f"{uuid.uuid4().hex}_{file.filename}")filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)file.save(filepath)# 获取选择的翻译引擎和 OCR 语言,设置默认值engine = request.form.get('engine', 'google')ocr_lang = request.form.get('ocr_lang', 'eng')# 创建唯一的任务 IDtask_id = str(uuid.uuid4())progress[task_id] = 0# 启动后台处理线程thread = Thread(target=process_file, args=(task_id, filepath, engine, ocr_lang))thread.start()# 重定向到进度页面return redirect(url_for('processing', task_id=task_id))else:return '文件类型不被允许', 400return render_template('upload.html')# 处理页面路由
@app.route('/processing/<task_id>')
def processing(task_id):return render_template('processing.html', task_id=task_id)# 进度更新路由
@app.route('/progress/<task_id>')
def progress_status(task_id):def generate():while True:with progress_lock:status = progress.get(task_id, 0)yield f"data: {status}\n\n"if status >= 100 or status == -1:breakreturn Response(generate(), mimetype='text/event-stream')# 结果页面路由
@app.route('/result/<task_id>')
def result(task_id):result_data = results.get(task_id)if not result_data:return '结果未找到', 404# 获取处理时间elapsed_time = result_data.get('elapsed_time', 0)# 将处理时间格式化为 HH:MM:SSelapsed_time_str = str(timedelta(seconds=int(elapsed_time)))return render_template('result.html', original=result_data['original'], translated=result_data['translated'], elapsed_time=elapsed_time_str,engine=result_data['engine'],ocr_lang=result_data['ocr_lang'])if __name__ == '__main__':app.run(host='0.0.0.0', port=9006, debug=True)
2. config.ini
[translator]
azure_api_key = 5abb1abc4_deleted_half
azure_region = southcentralus
#yandex_api_key = YOUR_YANDEX_API_KEY3. templates 下面的文件
1. upload.html
<!-- templates/upload.html --><!doctype html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><title>上传 PDF 文件</title>
</head>
<body><h1>上传 PDF 文件以进行翻译</h1><form method="post" enctype="multipart/form-data"><label for="fileInput">选择 PDF 文件:</label><input type="file" name="file" accept=".pdf" id="fileInput" required><br><br><label for="engineSelect">选择翻译引擎:</label><select name="engine" id="engineSelect"><option value="google" selected>Google 翻译</option><option value="microsoft">微软翻译</option><!-- 添加其他选项 --></select><br><br><label for="ocrLangSelect">选择 OCR 语言:</label><select name="ocr_lang" id="ocrLangSelect"><option value="eng" selected>英语 (English)</option><option value="chi_sim">简体中文 (Simplified Chinese)</option><option value="chi_tra">繁体中文 (Traditional Chinese)</option><!-- 添加其他语言选项 --></select><br><br><input type="submit" value="上传并开始处理"></form>
</body>
</html>
2. processing.html
<!-- templates/processing.html --><!doctype html>
<html>
<head><title>处理中...</title><style>#progress-bar {width: 50%;background-color: #f3f3f3;margin: 20px 0;}#progress-bar-fill {height: 30px;width: 0%;background-color: #4caf50;text-align: center;line-height: 30px;color: white;}</style>
</head>
<body><h1>文件正在处理中,请稍候...</h1><div id="progress-bar"><div id="progress-bar-fill">0%</div></div><script>var taskId = "{{ task_id }}";var progressBarFill = document.getElementById('progress-bar-fill');var eventSource = new EventSource('/progress/' + taskId);eventSource.onmessage = function(event) {var progress = event.data;if (progress == '-1') {alert('处理失败,请重试。');eventSource.close();window.location.href = '/';} else {progressBarFill.style.width = progress + '%';progressBarFill.innerText = progress + '%';if (progress >= 100) {eventSource.close();window.location.href = '/result/' + taskId;}}};</script>
</body>
</html>
3. result.html
<!-- templates/result.html -->
<!doctype html>
<html>
<head><title>翻译结果</title><style>/* 原有样式保持不变 */.container {display: flex;}.content {width: 50%;padding: 20px;box-sizing: border-box;overflow-y: scroll;height: 80vh; /* 调整高度,给处理时间留出空间 */}.original {background-color: #f9f9f9;}.translated {background-color: #eef9f1;}pre {white-space: pre-wrap;word-wrap: break-word;}</style>
</head>
<body><h1>翻译结果</h1><p>处理时间:{{ elapsed_time }}</p> <!-- 显示处理时间 --><p>使用的翻译引擎:{{ engine }}</p> <!-- 显示翻译引擎 --><p>OCR 语言:{{ ocr_lang }}</p> <!-- 显示OCR 语言 --><div class="container"><div class="content original"><h2>原文</h2><pre>{{ original }}</pre></div><div class="content translated"><h2>译文</h2><pre>{{ translated }}</pre></div></div>
</body>
</html>
安装与配置
Windows 部署
参考上面的环境准备
Docker化部署
Dockerfile
# 使用官方的 Python 3.12.3 slim 版本作为基础镜像
FROM python:3.12.3-slim# 设置环境变量
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1# 设置工作目录 #从P8开始,项目文件在container中位置: /app/<project name>
WORKDIR /app/pdf2tx-mm# 复制应用程序代码到容器中 #从P8开始,项目文件在container中位置: /app/<project name>
COPY . /app/pdf2tx-mm# 安装系统依赖项
RUN apt-get update && apt-get install -y --no-install-recommends \tesseract-ocr \libtesseract-dev \poppler-utils \&& rm -rf /var/lib/apt/lists/*# 如果需要特定的 Tesseract 语言包,例如中文简体
RUN apt-get update && apt-get install -y --no-install-recommends \tesseract-ocr-chi-sim \tesseract-ocr-chi-tra \&& rm -rf /var/lib/apt/lists/*# 安装 Python 依赖项
RUN pip install --no-cache-dir -r requirements.txt# 下载 NLTK 数据
RUN python -m nltk.downloader all# 暴露应用程序运行的端口
EXPOSE 9006# 设置环境变量以指定Flask运行的主机和端口
ENV FLASK_RUN_HOST=0.0.0.0
ENV FLASK_RUN_PORT=9006# 运行应用程序
CMD ["python", "app.py"]
注:#从P8开始,项目文件在container中位置: /app/<project name>
目录要小写 所以系统中 项目名: pdf2tx-mm
requirements.txt
Flask
werkzeug
pdf2image
pytesseract
deep_translator
nltk
unstructured创建与运行Docker镜像
创建Docker镜像
在项目文件目录,运行下面的命令:
[/share/Multimedia/2024-MyProgramFiles/8.pdf2tx-MM] # docker build -t pdf2tx-mm .这个安装过程比较长,有2-3分钟。
运行Docker容器
如以下命令:
[/share/Multimedia/2024-MyProgramFiles/8.pdf2tx-MM] # docker run -d -p 9006:9006 --name pdf2tx-mm_container pdf2tx-mm成功后会看到:
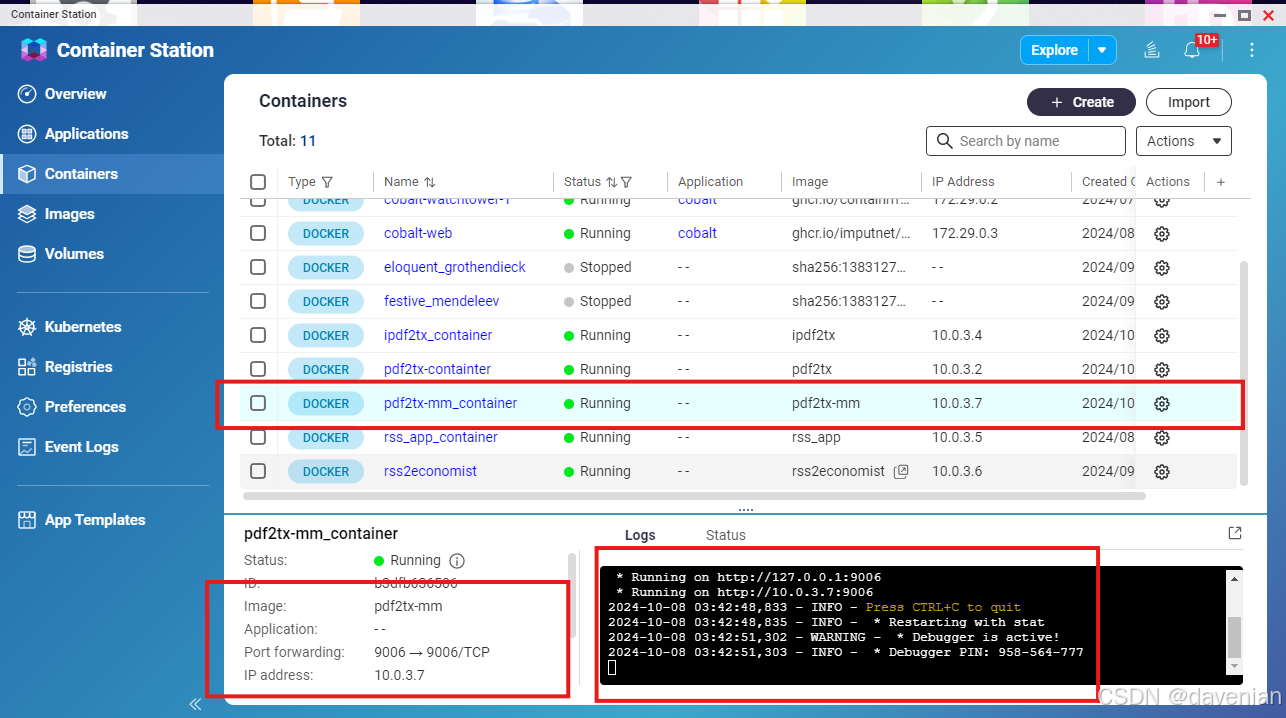
这时Container已经运行,可以用浏览器访问 http://localhost:9006,如演示动图:
总结:
P8是对P6的升级,也是全新的替代,但P8还有更新的地方,比添加更多的翻译机器选项,语言双向翻译,糟糕的界面等。
P6:<Project-6 pdf2tx> Python Flask 应用:图片PDF图书的中文翻译解决方案 链接 给了我解决问题的想法,实践的动力。第一次用到OCR,第一次监控进程,还有见识到了自己的代码是怎么干掉NAS的。
本来新代码中添加 ZhipuAI 做为翻译机,但是:8oct24 Zhipu 对输出的结果敏感词太复杂,比如 国家名 新疆 宗教名 民族名 这种组合就会看到 "系统检测到输入或生成内容可能包含不安全或敏感内容,请您避免输入易产生敏感内容的提 示语,感谢您的配合。"
所以放弃 ZhipuAi 智谱AI updated on 8oct.24 pm