统一时序预测模型,上下文长度首次扩展至千级别,适用各类数据集!
=============================================================================================================
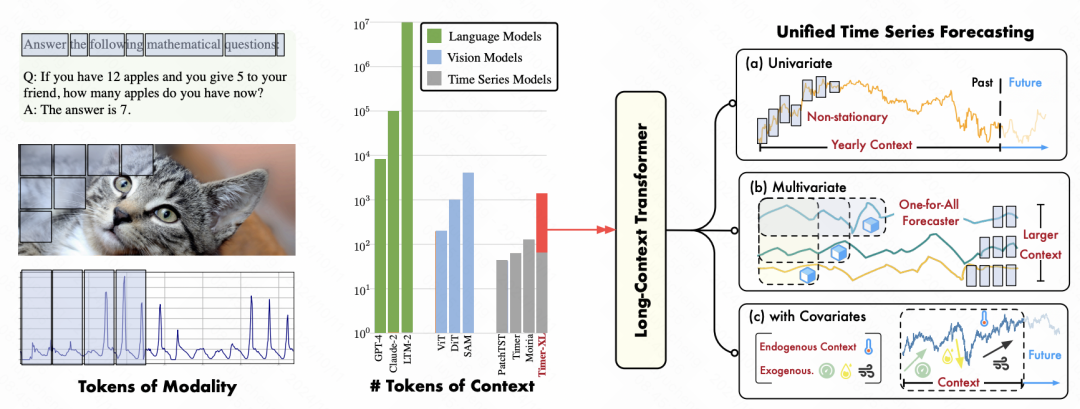
今天给大家介绍一篇清华大学的时间序列预测最新工作,提出了统一的Transformer时序预测模型,能同时处理单变量和多变量时序预测,并将时序预测的上下文长度首次扩充到千级别。
论文标题:TIMER-XL: LONG-CONTEXT TRANSFORMERS FOR UNIFIED TIME SERIES FORECASTING
下载地址:https://arxiv.org/pdf/2410.04803v1

1
背景
构建类似NLP领域的统一大模型是时序预测领域近期研究的焦点。虽然前序已经涌现很多工作,但是这些建模方法只能处理最多几百长度的上下文序列,比如根据历史200个数据点预测未来时刻的序列值。而NLP中的建模可以利用千级别甚至万级别的上下文信息。历史序列长度的不足,导致时序预测模型无法根据完整的、长周期的历史信息进行预测,影响了预测效果。
为了解决上述问题,本文构建了基于Decoder-only Transformer模型的统一时间序列预测模型Timer-XL,可以同时处理单变量和多变量的时序预测,并同时建模变量间关系,对比其他SOTA模型实现了效果提升。
2
Next Token Prediction任务
类似NLP中的语言模型,Timer-XL使用了Next Token Prediction任务进行模型训练。在语言模型中,Next Token Prediction任务的目标是根据前面的token,预测下一个token是什么。在时间序列中,Time-XL将token定义为一个窗口内的时间序列,也就是一个patch作为一个token。优化的目标就变成了预测下一个patch的时间序列,以MSE为目标进行拟合。
上述方式只适用于单变量时间序列。为了扩展到多变量时间序列,Timer-XL采用了多元Next Token Prediction的建模方式。整体可以理解为,每个变量仍然独立的预测下一个token,但是会根据所有变量的历史序列来预测各个变量的下一个token,公式可以表示为如下形式:
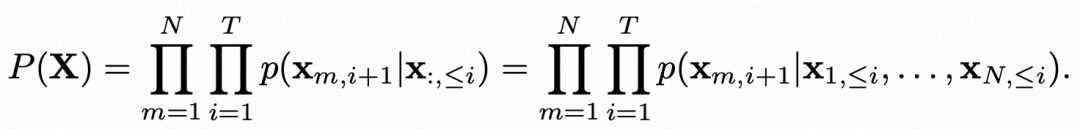
通过这种多变量Next Token Prediction的扩展,模型可以同时建模序列关系和变量间关系,实现了从1D建模到2D建模的扩展。
3
模型结构
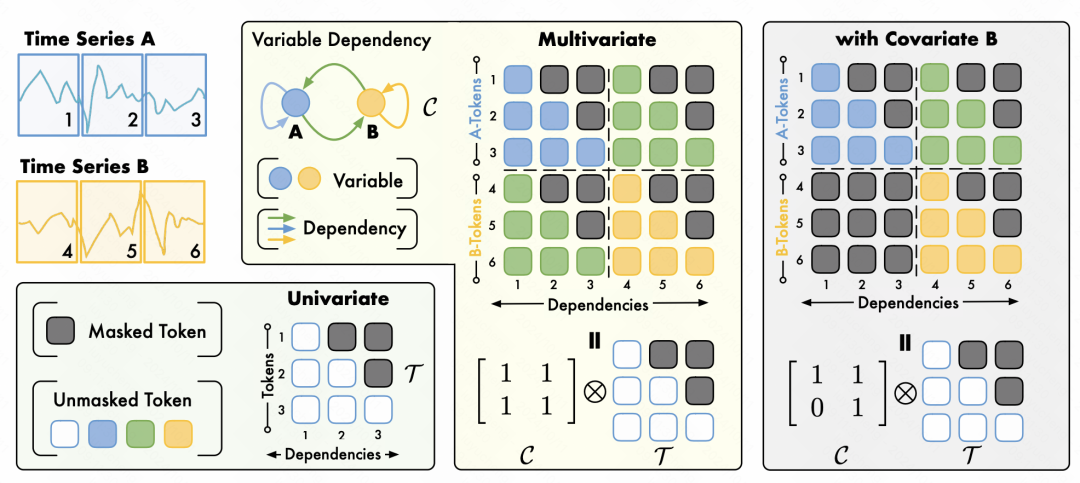
Timer-XL整体基于Transformer Decoder的模型结构,位置编码采用目前主流语言模型使用较多的RoPE。
其中一个核心问题是,引入多元Next Token Prediction任务后,如何构建attention。文中提出了TimeAttention模块,其基本思路也很简单,在预测每一个变量的值时,通过attention mask的方式让其只和各个变量该时刻之前的值进行attention。比如下图中预测A序列的第3个token的值,会和A、B的第一个时刻、第二个时刻的tokne计算attention。
此外,这种attention mask的方式也可以灵活引入变量间关系的建模。比如可以根据两个变量之间是否相互依赖,修改整个attention mask的构造方式,融合时间(序列)和空间(变量间)的关系。
4
实验效果
在实验部分,文中对比了和各类时序预测模型,包括统计模型、深度模型等SOTA方法的效果,本文的整体MSE都取得了较明显的下降。
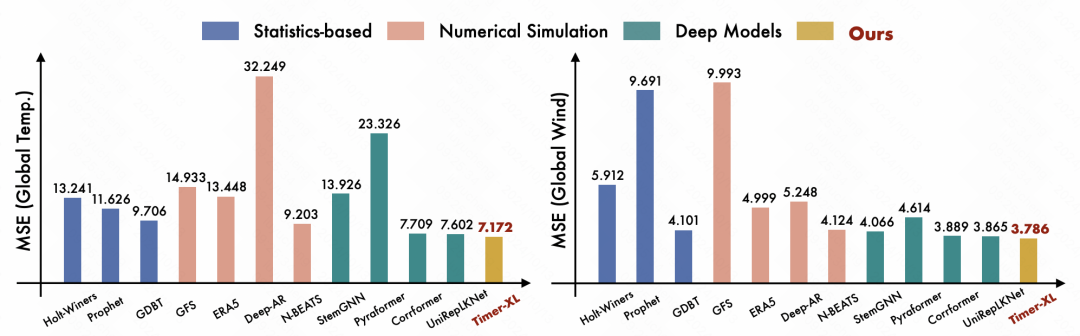
实验部分也重点论证了Timer-XL的通用性,一个模型可以用于各类数据集,包括在训练数据内的数据集,以及非训练数据的数据集,有较强的泛化性。

读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓







![[网络基础]——ICMP(互联网控制消息协议)协议介绍](https://img-blog.csdnimg.cn/img_convert/b617c82dfb68ab67aca9ce7f9944b5b6.jpeg)





![[实时计算flink]CREATE DATABASE AS(CDAS)语句](https://img-blog.csdnimg.cn/img_convert/734493b782f470fdf763af2f785e7e22.png)





