前言
在实际的流计算业务场景中,我们会发现,数据和数据的计算往往都和时间具有相关性。
举几个例子:
- 直播间右上角通常会显示观看直播的人数,并且这个数字每隔一段时间就会更新一次,比如10秒。
- 电商平台的商品列表,会显示商品过去24小时的销量、或者总销量
- 阅读CSDN博客会显示总的阅读量,并且会持续更新
归纳总结可以发现,这些和时间相关的数据计算可以统一用一个计算模型来描述:每隔一段时间,计算过去一段时间内的数据,并输出结果。这个计算模型,就是时间窗口。
时间窗口类型
时间窗口计算模型具备三个重要的属性:
- 时间窗口的计算频次,即 隔多久计算一次
- 时间窗口的大小,即 计算过去多久的数据
- 时间窗口内数据的处理逻辑
举例来说,每隔1分钟计算商品过去24小时的销量。时间窗口的计算频次就是1分钟,时间窗口的大小是24小时,窗口数据的处理逻辑是 对商品销量求和。
Flink 提供了三种时间窗口的类型
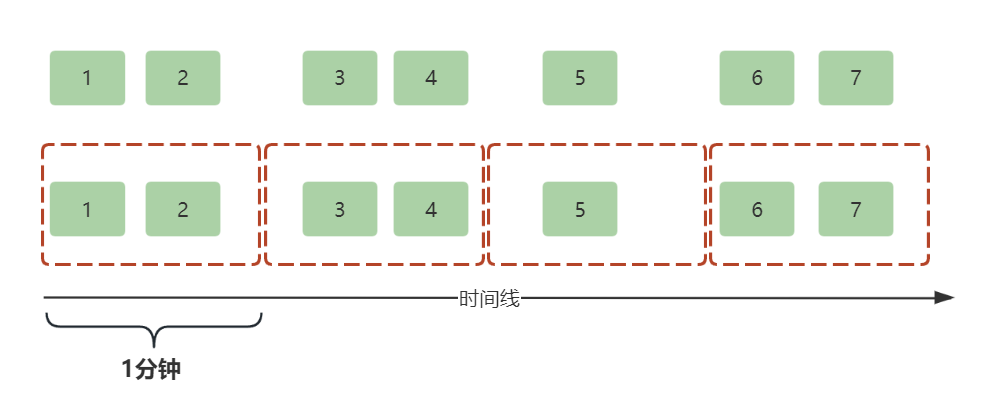
滚动窗口(Tumble Window)
滚动窗口的特点是:时间窗口大小和计算频次相同!
顾名思义,滚动窗口就像一个车轮一样滚滚向前,因为窗口大小和计算频次相同,所以窗口是紧密相连的,窗口内的数据不会重复计算。
举个例子,每隔1分钟计算商品过去1分钟的销量。
如下示例程序,每隔5秒计算过去5秒的订单销售额:
public class TumblingWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.addSource(new SourceFunction<Order>() {@Overridepublic void run(SourceContext<Order> sourceContext) throws Exception {while (true) {Threads.sleep(1000);Order order = Order.mock();sourceContext.collectWithTimestamp(order, order.createTime);sourceContext.emitWatermark(new Watermark(System.currentTimeMillis()));}}@Overridepublic void cancel() {}}).keyBy(i -> i.itemId).window(TumblingEventTimeWindows.of(Duration.ofSeconds(5L))).sum("orderAmount").print();environment.execute();}@Data@NoArgsConstructor@AllArgsConstructorpublic static class Order {public String itemId;public long orderAmount;public long createTime;static Order mock() {return new Order("001", ThreadLocalRandom.current().nextLong(100), System.currentTimeMillis());}}
}
这里采用滚动窗口计算模型,窗口大小和计算频次均是5秒,运行作业后,控制台会每隔5秒输出一次总销售额
1> TumblingWindow.Order(itemId=001, orderAmount=250, createTime=1722344630342)
1> TumblingWindow.Order(itemId=001, orderAmount=270, createTime=1722344635388)
1> TumblingWindow.Order(itemId=001, orderAmount=147, createTime=1722344640407)
1> TumblingWindow.Order(itemId=001, orderAmount=253, createTime=1722344645430)
......
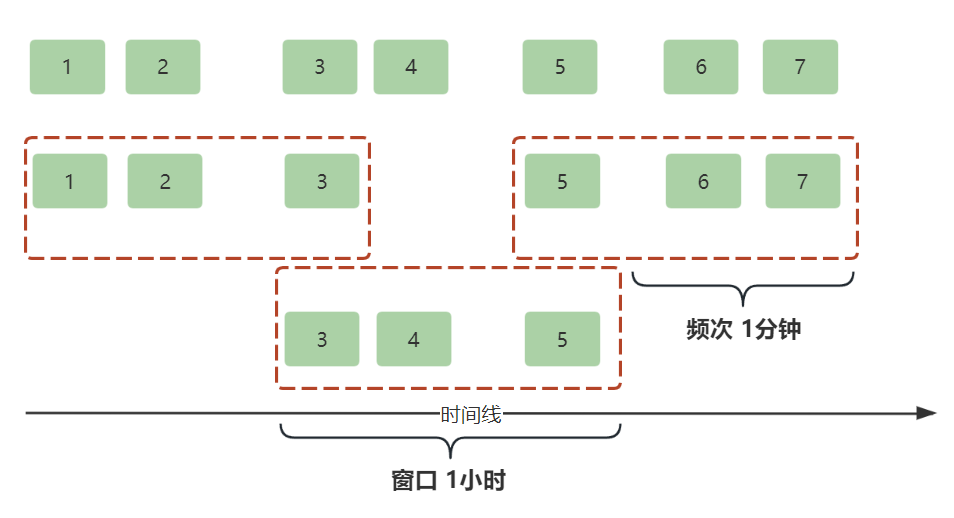
滑动窗口(Sliding Window)
滑动窗口的特点是:时间窗口大小和计算频次不相同,如果窗口大小大于计算频次,就会导致数据被重复计算;如果窗口大小小于计算频次,就会导致数据被漏计算;如果二者相等,那就是滚动窗口了。
举个例子,每隔1分钟计算商品过去1小时的销量。窗口大小为1小时,计算频次为1分钟,因此数据会被重复计算多次。
如下示例程序,每隔1秒计算过去5秒的订单销售额,部分订单会被重复计算多次:
public class SlidingWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.addSource(new SourceFunction<TumblingWindow.Order>() {@Overridepublic void run(SourceContext<TumblingWindow.Order> sourceContext) throws Exception {while (true) {Threads.sleep(1000);TumblingWindow.Order order = TumblingWindow.Order.mock();sourceContext.collectWithTimestamp(order, order.createTime);sourceContext.emitWatermark(new Watermark(System.currentTimeMillis()));}}@Overridepublic void cancel() {}}).keyBy(i -> i.itemId).window(SlidingEventTimeWindows.of(Duration.ofSeconds(5L), Duration.ofSeconds(1L))).sum("orderAmount").print();environment.execute();}
}
作业运行后,控制台每秒会输出一次过去5秒的销售额。
会话窗口(Session Window)
会话窗口的窗口大小和计算频次非常灵活,可以动态改变,每次都不一样。当窗口隔一段时间没有接收到新的数据,Flink就认为会话可以关闭并计算了,等下一次有新的数据进来,就会开启一个新的会话。这里的“隔一段时间”就是值会话窗口的间隔(Gap),这个间隔可以固定设置也可以动态设置。
举个例子,读书类APP都会有的一个功能,就是统计用户的阅读时长。用户必须有持续的动作,APP才会认为用户是真的在阅读,反之用户长时间没有操作,APP会认为用户已经离开,此时不会再统计阅读时长。
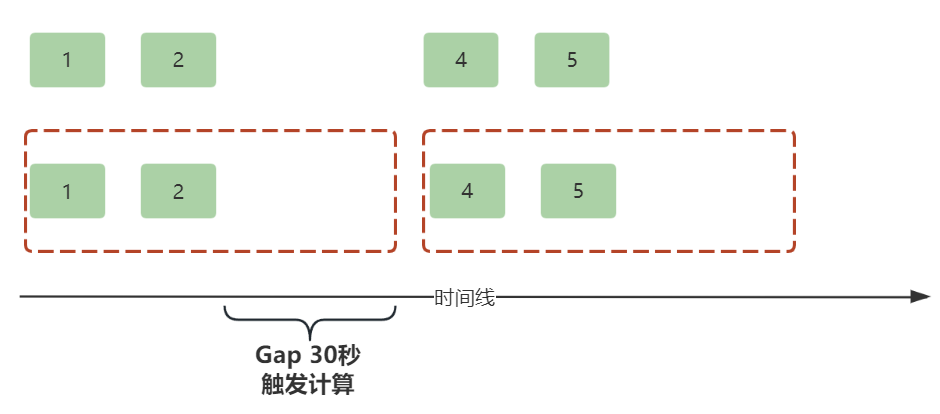
如下示例,随机5秒内模拟一次用户行为,会话窗口间隔设置为3秒,超过3秒认为用户离开,关闭窗口并统计用户阅读时长。
public class SessionWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.addSource(new SourceFunction<UserAction>() {@Overridepublic void run(SourceContext<UserAction> ctx) throws Exception {while (true) {UserAction userAction = UserAction.mock();ctx.collectWithTimestamp(userAction, userAction.time);ctx.emitWatermark(new Watermark(System.currentTimeMillis()));// 随机5秒内 用户才会有新的操作Threads.sleep(ThreadLocalRandom.current().nextLong(0L, 5000L));}}@Overridepublic void cancel() {}})// 超过三秒没有收到用户新的动作,认为用户离开,关闭窗口并计算.windowAll(EventTimeSessionWindows.withGap(Duration.ofSeconds(3L))).aggregate(new AggregateFunction<UserAction, UserReadingTime, UserReadingTime>() {@Overridepublic UserReadingTime createAccumulator() {return new UserReadingTime();}@Overridepublic UserReadingTime add(UserAction userAction, UserReadingTime userReadingTime) {// 记录窗口内的用户阅读开始和结束时间userReadingTime.userId = userAction.userId;if (userReadingTime.startTime == 0L) {userReadingTime.startTime = userAction.time;}userReadingTime.endTime = userAction.time;return userReadingTime;}@Overridepublic UserReadingTime getResult(UserReadingTime userReadingTime) {return userReadingTime;}@Overridepublic UserReadingTime merge(UserReadingTime userReadingTime, UserReadingTime acc1) {return null;}}).addSink(new SinkFunction<UserReadingTime>() {@Overridepublic void invoke(UserReadingTime value, Context context) throws Exception {System.err.println("用户" + value.userId + " 阅读了 " + (value.endTime - value.startTime) + " ms");}});environment.execute();}@Data@AllArgsConstructor@NoArgsConstructorpublic static class UserAction {public Long userId;public long time;public static UserAction mock() {return new UserAction(1L, System.currentTimeMillis());}}@Data@AllArgsConstructor@NoArgsConstructorpublic static class UserReadingTime {public Long userId;public long startTime;public long endTime;}
}
运行Flink作业,控制台随机输出用户的阅读时长
用户1 阅读了 3240 ms
用户1 阅读了 9414 ms
用户1 阅读了 138 ms
用户1 阅读了 2960 ms
时间语义
时间语义和时间窗口息息相关。
Flink 提供了三种不同的时间语义,分别是:处理时间、事件时间、摄入时间。
在不同的时间语义下,针对同样的数据,Flink 分配的时间窗口是不一样的。
举个例子,我们要统计某个商品过去1分钟的销量,这是个典型的一分钟大小的时间窗口。用户在 09:00:50 下了一笔订单,中间由于网络延时等原因,Flink 在 09:01:01 才收到这笔订单数据,恰巧此时 Flink 因为自身作业压力宕机崩溃,在 09:02:10 才恢复作业,该笔订单数据随即被 keyBy 分组发送给下游算子处理。
这个例子中的三个时间点,刚好对应了 Flink 的三种时间语义:
- 事件时间:事件发生的时间,通常数据本身会携带一个时间戳,即例子中的 09:00:50
- 摄入时间:Flink 数据源接收数据的subTask算子本地时间,即例子中的 09:01:01
- 处理时间:Flink 算子处理数据的机器本地时间,即例子中的 09:02:10
事件时间
事件时间是最常用的,在事件时间语义下,数据本身通常会携带一个时间戳,Flink 会根据该时间戳为数据分配正确的时间窗口。
因为事件时间是不会改变的,所以在事件时间语义下,Flink 窗口计算的结果始终是一致的,数据是清晰明确的。
但是,事件时间语义 会带来另一个问题。事件的产生是顺序的,但是数据在传输过程中,可能会因为网络拥塞等种种原因,到达 Flink 时乱序了。此时,Flink 如何处理这些乱序数据就是个麻烦事儿了。
举个例子,还是统计商品过去1分钟的销量,Flink 先是接收到事件时间为 09:00:30 的订单数据,此时将其分配到 [09:00,09:01] 窗口缓存起来,接着接收到了 09:01:30 的订单数据,此时 [09:00,09:01] 窗口可以关闭并计算了吗?显然不能,因为数据乱序到达的原因,谁也不能保证 Flink 待会不会收到 09:00 分钟产生的订单。
那怎么办呢?[09:00,09:01] 窗口总不能一直不关闭吧。为了解决这个问题,Flink 引入了 Watermark 机制,这里不做介绍。
使用事件时间对应的窗口分配器是:
- TumblingEventTimeWindows 基于事件时间的滚动窗口
- SlidingEventTimeWindows 基于事件时间的滑动窗口
- EventTimeSessionWindows 基于事件时间的会话窗口
如下示例,每秒生成一个带时间戳的随机数,数据用 Flink 自带的 Tuple2 封装,同时用 TumblingEventTimeWindows 让 Flink 基于事件时间语义来分配 5秒 的滚动窗口。运行 Flink 作业,控制台每隔5秒会输出前5秒的随机数之和。
public class TumblingWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.addSource(new SourceFunction<Tuple2<Long, Long>>() {@Overridepublic void run(SourceContext<Tuple2<Long, Long>> sourceContext) throws Exception {while (true) {Threads.sleep(1000);// f0是随机数 f1是时间戳Tuple2<Long, Long> tuple2 = new Tuple2<>(ThreadLocalRandom.current().nextLong(100), System.currentTimeMillis());sourceContext.collectWithTimestamp(tuple2, tuple2.f1);sourceContext.emitWatermark(new Watermark(System.currentTimeMillis()));}}@Overridepublic void cancel() {}}).windowAll(TumblingEventTimeWindows.of(Duration.ofSeconds(5L))).sum(0).print();environment.execute();}
}
控制台输出
// subTask任务ID 数字和 时间戳
19> (108,1722432788302)
20> (308,1722432790305)
21> (324,1722432795346)
总结一下,如果业务要按照事件发生的时间计算结果或分析数据,那么只能选事件时间语义。通常情况下,事件时间也确实更有价值。例如,利用Flink分析用户的行为日志,用户具体在什么时间点做了哪些行为,会更有分析价值,至于 Flink 是什么时候处理这些日志的,对业务方来说并不重要。因为事件时间具有不变性,所以基于事件时间统计的结果总是清晰明确的,缺点是数据到达Flink是乱序的,处理迟到数据会给Flink带来一定的压力。
摄入时间
摄入时间是指数据到达 Flink Source 算子的本地机器时间,它为处理数据流提供了一种相对简单而直观的时间参考,算是在 事件时间 和 处理时间 中间做了一个折中。
摄入时间具备一定的优势。一方面,它避免了事件时间的乱序问题,相较于事件时间具备更高的处理效率;另一方面,相较于处理时间而言,它具备不变性,计算产生的结果也会更加准确。
摄入时间适用于那些对时间精度要求不是特别高,但又希望时间能够相对反映数据进入系统先后顺序的场景。
如下示例,使用摄入时间语义计算过去5秒窗口生成的随机数之和。因为用的是摄入时间,所以无须发送 Watermark,数据本身也无须携带时间戳。
public class IngestionTimeFeature {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// 采用摄入时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);environment.addSource(new SourceFunction<Tuple1<Long>>() {@Overridepublic void run(SourceContext<Tuple1<Long>> sourceContext) throws Exception {while (true) {Threads.sleep(1000);sourceContext.collect(new Tuple1<>(ThreadLocalRandom.current().nextLong(100)));}}@Overridepublic void cancel() {}}).keyBy(IN -> "all").timeWindow(Time.of(5L, TimeUnit.SECONDS)).sum(0).print();environment.execute();}
}
处理时间
处理时间语义是指数据实际被处理的时间,也就是数据到达Window算子时subTask机器的本地时间。
因为 处理时间语义 完全依靠算子的机器本地时间,所以时间窗口在划分数据和触发计算,都只需要依靠本地时间来驱动,性能是最好的,延迟低,适用于对高性能和延迟敏感的业务。
同样的,处理时间语义也有它的劣势。因为采用的是subTask算子的本地时间,所以数据的时间其实是具备不确定性的。举个例子,订单数据在 09:00:01 被算子接收,它会被分配到 [09:00,09:01]窗口,假设此时该subTask作业故障宕机,等到 09:10:00 才恢复,Flink 重新消费这条数据,它又会被分配到 [09:10,09:11] 窗口,产出的数据就会不一致。因此在使用处理时间语义时,要保证业务方能接受这种因为异常情况导致的计算结果不符合预期的场景。
如下示例,采用处理时间语义,因为是采用subTask本地时间,所以同样也不需要发送 Watermark。
public class ProcessTimeFeature {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// 采用处理时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);environment.addSource(new SourceFunction<Tuple1<Long>>() {@Overridepublic void run(SourceContext<Tuple1<Long>> sourceContext) throws Exception {while (true) {Threads.sleep(1000);sourceContext.collect(new Tuple1<>(ThreadLocalRandom.current().nextLong(100)));}}@Overridepublic void cancel() {}}).windowAll(TumblingProcessingTimeWindows.of(Duration.ofSeconds(5L))).sum(0).print();environment.execute();}
}
尾巴
Flink 具有丰富的时间语义,包括事件时间、处理时间和摄入时间。事件时间基于数据本身携带的时间戳,处理时间基于系统处理数据的本地时钟,摄入时间则是数据进入 Flink Source算子的时间。
时间窗口是 Flink 处理流式数据的重要方式,Flink 提供了 滚动窗口、滑动窗口、会话窗口 三种窗口类型。滚动窗口有固定大小且不重叠,滑动窗口大小固定且可重叠,会话窗口根据数据间隔来划分。合理选择时间语义和时间窗口,能更准确有效地处理和分析流式数据。

















![[LeetCode] 232. 用栈实现队列](https://i-blog.csdnimg.cn/direct/1ac8c57e121d4a20a8eb2767d93d934d.png)