Orange 是一个基于 Python 的数据挖掘和机器学习库,它提供了一系列可视化工具和算法,用于数据分析、机器学习和数据可视化等任务。
一、主要特点
- 可视化界面:Orange 提供了直观的可视化界面,使得用户可以通过拖放操作构建数据分析流程,无需编写大量代码。这对于初学者和非专业程序员来说非常友好。
- 丰富的算法:包含了各种机器学习算法,如分类、回归、聚类、降维等。同时,还支持数据预处理、特征选择等操作。
- 交互性强:用户可以在可视化界面中实时调整参数,观察算法的效果,从而更好地理解数据和算法。
- 扩展性好:可以与其他 Python 库集成,如 NumPy、Pandas、Scikit-learn 等,以满足更复杂的数据分析需求。
二、简单使用方法
- 安装 Orange
可以使用以下命令安装 Orange:
pip install orange3
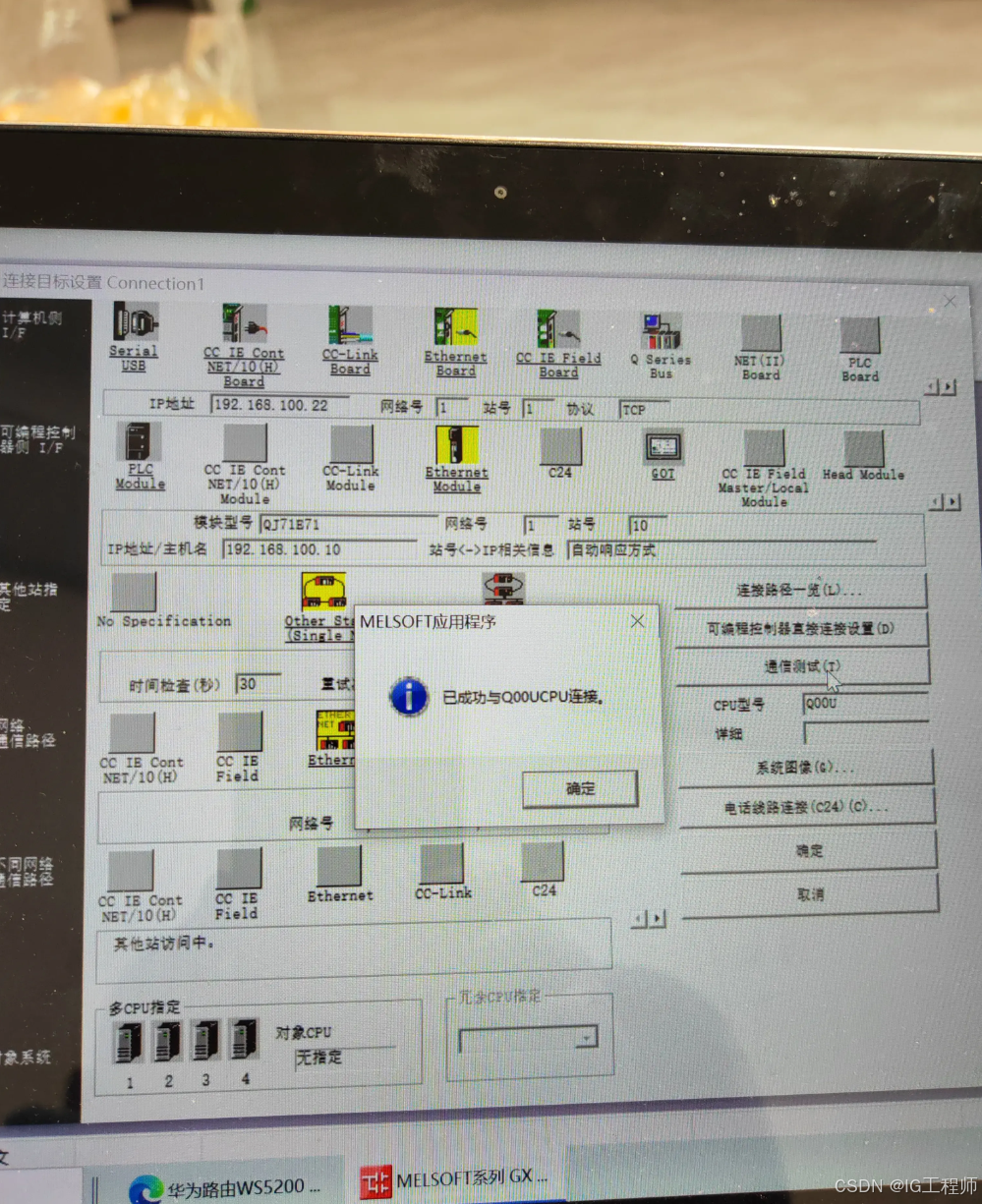
安装完成后,终端内输入命令:orange-canvas 可启动图形界面。
$>orange-canvas

- 导入库
在 Python 脚本中导入 Orange:
import orange
- 加载数据
使用 Orange 的数据加载功能加载数据集。例如,加载一个 CSV 文件:
from orangecontrib.associate.fpgrowth import *data = orange.ExampleTable('your_data.csv')
- 数据可视化
使用 Orange 的可视化工具查看数据。例如,绘制散点图:
from orange.widgets.visualize.owscatterplot import OWScatterPlotscatter = OWScatterPlot()scatter.set_data(data)scatter.show()
- 应用机器学习算法
可以使用 Orange 的机器学习算法进行分类、回归等任务。例如,使用决策树进行分类:
from orange.classification import TreeLearnerclf = TreeLearner()model = clf(data)predictions = model(data)
以上是 Orange 库的简单介绍和使用方法。通过使用 Orange,你可以更轻松地进行数据分析和机器学习任务,尤其是对于那些不熟悉编程的用户来说,它的可视化界面提供了一种便捷的方式来探索和理解数据。也可以通过安装anaconda python环境,使用R、jupyter、orange等工具。
以下是一些 Orange 库的实际应用案例:
案例一:客户分类
一家电商企业拥有大量的客户数据,包括客户的购买历史、浏览行为、年龄、性别等信息。企业希望对客户进行分类,以便更好地了解客户需求,制定个性化的营销策略。
使用 Orange 库可以进行以下操作:
- 加载客户数据到 Orange 中,可以是 CSV 格式或其他常见的数据格式。
- 使用数据可视化工具,如散点图、柱状图等,探索客户数据的分布和特征。
- 应用聚类算法,如 K-Means 聚类,将客户分为不同的群体。通过调整聚类参数,可以得到不同数量的客户群体。
- 分析每个客户群体的特征,例如购买频率、平均消费金额、偏好的商品类别等。
- 根据客户群体的特征,制定相应的营销策略。例如,对于高价值客户群体,可以提供专属的优惠和服务;对于潜在客户群体,可以进行针对性的营销推广。
案例二:疾病预测
医疗机构收集了大量患者的医疗数据,包括症状、检查结果、病史等信息。希望通过数据分析预测患者是否患有某种特定的疾病。
使用 Orange 库可以进行以下操作:
- 整理患者数据,将其转换为适合 Orange 处理的格式。
- 利用数据可视化工具,观察不同症状和检查结果与疾病的关系。
- 选择合适的分类算法,如决策树、随机森林等,对患者数据进行训练和预测。
- 评估模型的性能,如准确率、召回率、F1 值等。
- 根据预测结果,为医生提供辅助诊断建议,提高疾病诊断的准确性和效率。
案例三:图像分类
在计算机视觉领域,需要对大量的图像进行分类。例如,将图像分为不同的物体类别、场景类别等。
使用 Orange 库可以进行以下操作:
- 收集图像数据,并进行预处理,如调整大小、归一化等。
- 提取图像的特征,例如使用深度学习模型提取图像的特征向量。
- 将图像特征数据加载到 Orange 中。
- 应用分类算法,如支持向量机、神经网络等,对图像进行分类。
- 通过可视化工具,观察分类结果的准确性和错误分类的图像,以便进一步改进模型。
这些案例展示了 Orange 库在不同领域的实际应用。通过使用 Orange 的可视化工具和机器学习算法,可以更高效地进行数据分析和模型构建,为决策提供有力支持。
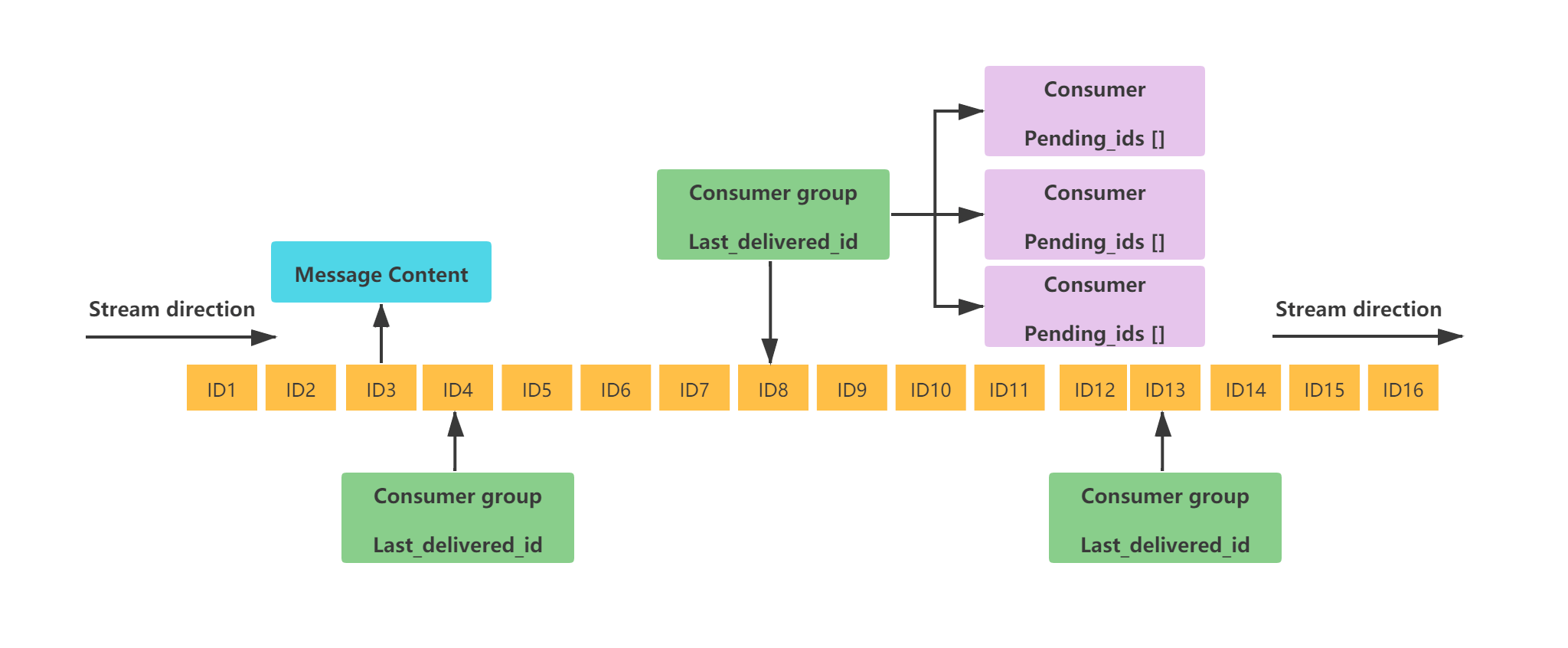
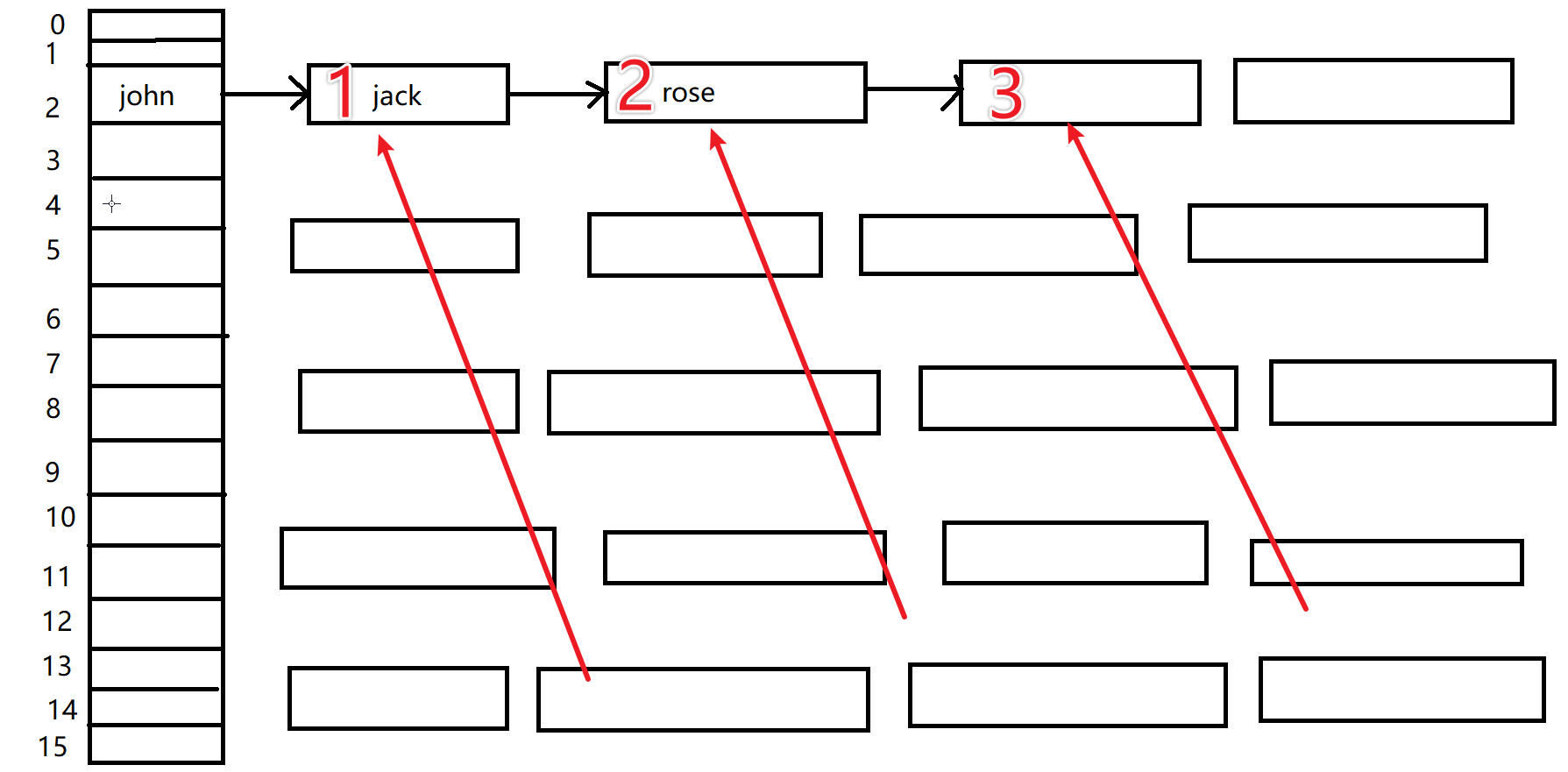












![[ES3]大侠立志传存档解密修改](https://i-blog.csdnimg.cn/direct/cf9aadfde8d34c5abb9753ea37f88100.png)