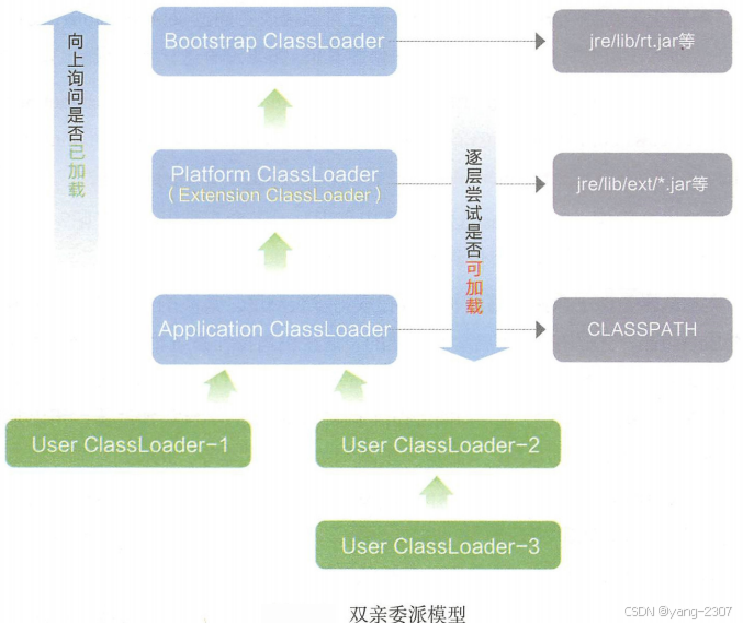
一.前提
为什么要采用跨模态的信息融合?
点云在低分辨率下提供必要的定位和几何信息,而图像在高分辨率下提供丰富的外观信息。 -->因此必须采用跨模态的信息融合
提出的原因?
传统的融合办法可能会由于信息融合到统一表示中的不太完美而丢失很大一部分特定模态的信息。所以为了克服传统融合的限制提出了这篇论文。
关键思想是什么?
不是推导一个融合的单一表示,而是学习和保持两个特定模态的表示,以实现模态间的交互,从而可以自发地实现信息交换和特定模态的优势。
传统的融合办法和本文提出的办法对比?

(a):传统的办法 是将个体的各模态融合成一个单一的混合表示
(b):基于多模态交互的3D检测 通过编码器中的表示交互和解码器的预测交互,可以保持两个特定模态交互
二.主体结构
由两个重要组件组成: 1.具有多模态表征交互的编码器 2.具有多模态预测交互的解码器

1.编码器:多模态表征交互
(1).我们的编码器有多输入多输出结构 生成两个经过精细化处理的表示或图形输出。
(2).输入:以图像透视表征
![]()
和LiDAR BEV表征
![]()
两种模态的表征。
(3).方法:跨模态对应映射和采样为了定义跨模态邻接,我们首先需要在表示
![]()
和
![]()
之间建立像素到像素的对应关系 --> 我们在图像坐标帧c和BEV坐标帧p(Mp→c和Mc→p)之间构建密集映射。

(a).图像-Lidar特征交互 将图像特征中的视觉信号传播到激光雷达BEV特征中
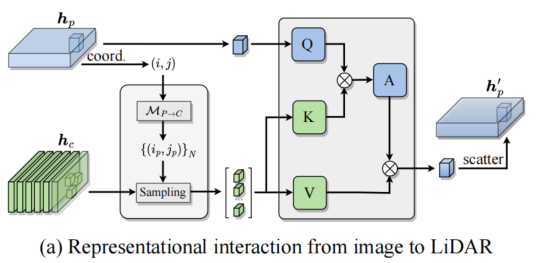
1.从图像到LiDAR BEV坐标帧
![]()
首先将点云每个点(即坐标 coord)投影到多相机图像(i,j)中,再进行采样形成稀疏深度图
![]()
(

)
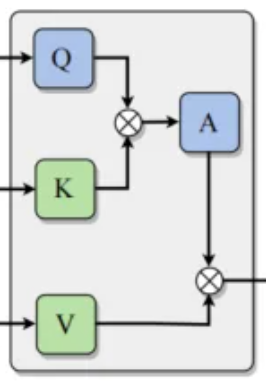
2.这一步完全就是引用的是transformer里面的self-attention 利用qkv的矩阵构建查询,键,值产生attention(是由权重计算得来的)
3.将加权后的特征表示
![]()
散布在LiDAR数据空间
(b).Lidar-图像特征交互
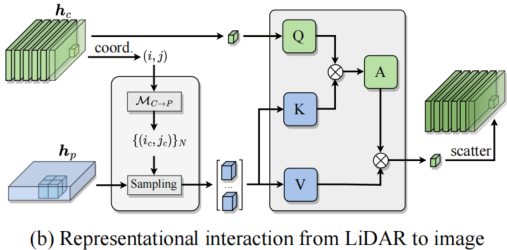
与上述相同
2.解码器:多模态预测交互
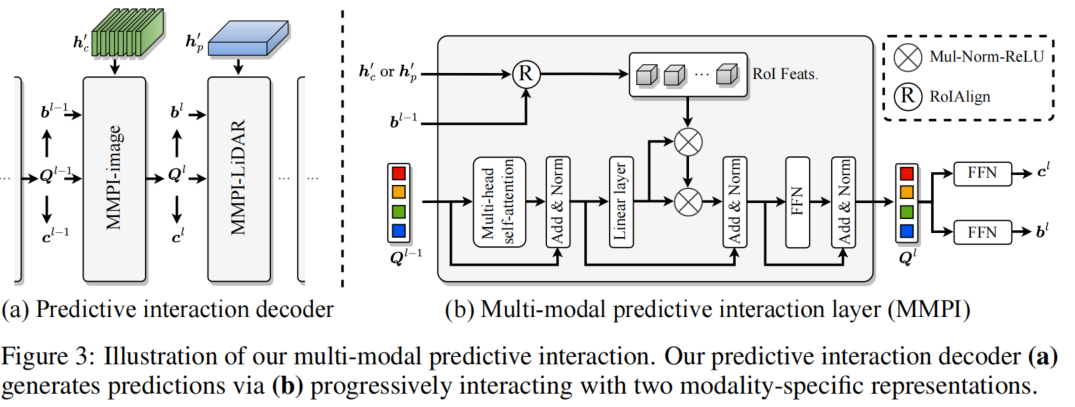
![]()
: 可能代表“边界框”(bounding box),用于表示图像中检测到的对象区域
Q:代表查询
C:代表通道
(a).MMPI-image
1.输入:特征
![]()
通过
![]()
边界框 提取感兴趣的区域 -->可以得到ROI 特征
2.查询特征->输入多头注意力机制 -> 残差连接和层归一化 ->线性层->将区域特征和查询特征->进行乘法-归一化-激活 -> 残差连接和层归一化 -> FFN前馈神经网络
(b).MMPI-LiDAR
同上
三.实验
1.表一:
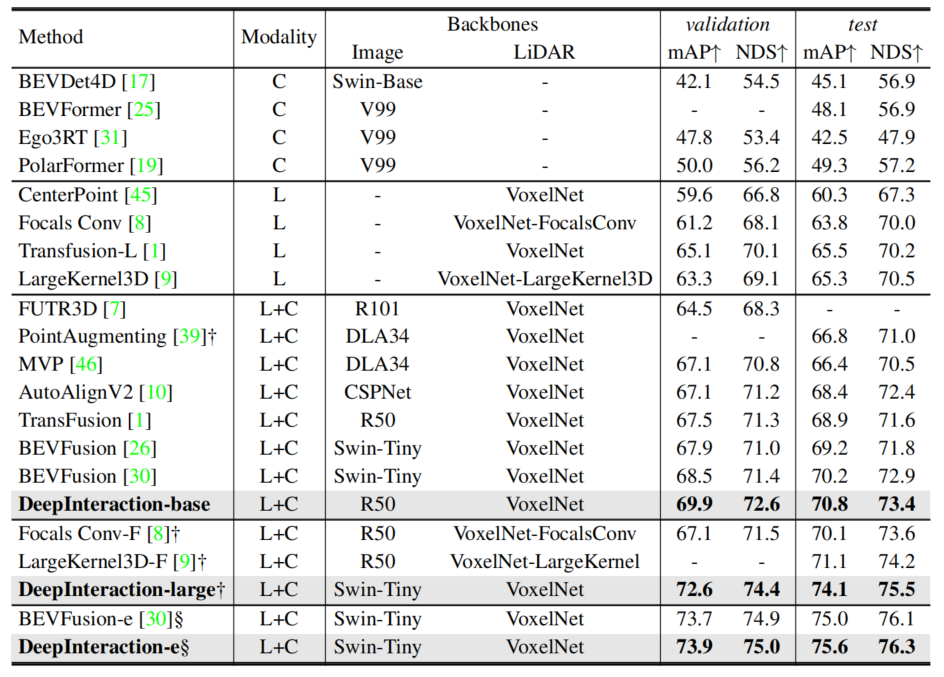
-
表示使用测试时候增强
测试时增强并且使用模型集成
采用了多个
模型
这是一个在nuScenes测试集上最先进的方法比较
DeepInteraction-base (基础版本)在相同的Backbone中它的准确度最高 并且test和val集准确度都差不多
DeepInteraction-large (大规模版本) 在测试时增强的时候 测试集比预测集准确度明显较多(与其他相同情况下的比较下)
- Deeplnteraction-large以相同的TTA和测试时间大大击败了最接近的竞争对手LargeKernel3D-F。
- 我们的集成版本Deepnteraction-e在nuScenes排行榜上的所有解决方案中排名第一。
- 这些结果验证了我们的多模态交互方法的性能优势
2.表二:运行时间比较

FPS: 这个是指分辨率
多视角高分辨率相机图像的特征提取贡献了多模态3D检测器的大部分总体延迟。
3.表三:解码器的消融研究:在nuScenes值计算mAP和NDS

a):比较多模态预测交互(MMPI)和DETR解码器的层 -->来评估解码器层的设计
我认为L和C使用MMPI的效果更好一点
b): 从mAP和NDS的结果来看,使用LiDAR与图像交替的方法(LiDAR-image alternating),在目标检测性能上相对于仅使用LiDAR的方法有一定提升。这可能归因于图像能够提供更多的上下文信息,帮助模型更好地理解场景。
c):解码层增加到5层是最优的
d):在不同的选择下,性能是稳定的,200/300用于训练/测试作为最佳设置。
4.表四:表征相互作用编码器的烧灼研究

- IML:模态内学习 MMRI:多模态表征相互作用
a):编码器设计

MMRI可以显著提高IML的性能 单用的话 MMRI比IML的效果好
b):编码器层数

堆叠编码器层用于迭代MMRI是有益的
c):表征交互和传统的表征融合

Representational fusion:一种传统的特征融合方法,通常通过简单地结合不同模态的特征来进行目标检测
Representational interaction (Ours):表示提出的新方法,强调特征之间的交互作用,可能通过更复杂的方式来融合不同模态的信息
我们提出的效果 新方法更加有效
5.表五:不同激光雷达主干网的评价
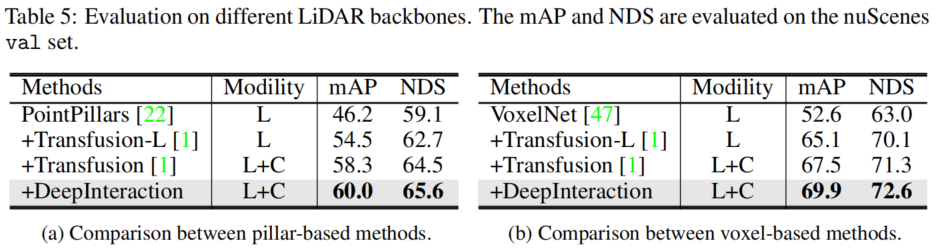
(a):基于柱子的比较 (b)基于体素的比较
1.提出的多模态交互策略DeepInteraction在使用任何一种主干网时都比激光雷达基线表现出一致的改进
2.基于体素的主干网提高5.5% mAP,基于支柱的主干网提高4.4%mAP
3.我们的DeepInteraction在不同点云编码器中的通用性。
6.表六:与激光雷达

我们的融合方法在所有类别上都取得了显著的改进,特别是在微小或稀有物体类别上(自行车+11.8%mAP,摩托车+6.9% mAP,交通锥+9%mAP)