向量检索学习记录
1、Faiss
- Faiss是一个用于高效相似搜索和密集向量聚类的库;(支持单个/多个GPU)
- 官方文档:Home · facebookresearch/faiss Wiki · GitHub
- 安装(如果编译有问题,有些选项需要关下,比如GPU, Python,Test 在CMakeList.txt中
- -DFAISS_ENABLE_GPU=OFF; -DFAISS_ENABLE_PYTHON=OFF
- 安装参考:faiss/INSTALL.md at main · facebookresearch/faiss · GitHub
- feature
- 能够在向量集合中搜索query向量的1st,2nd,3rd,4th....xth近邻
- 支持批量检索
- 用精度换速度。使用速度快10倍或内存少10倍的方法,在10%的情况下给出不正确的结果
- 使用最大内积搜索而不是最小欧式距离(L2)搜索;对其他类型的距离(L1、Linf等)搜索支持也有限
- 各种距离参考:简单理解机器学习中的L1距离,L2距离,L-Inf距离-CSDN博客
- 返回查询点给定半径内的所有元素(range search)
- 索引数据存储在磁盘上而不是内存里???
- 索引二进制向量而不是浮点数向量
- ignore a subset of index vectors according to a predicate on the vector ids.
- 站在巨人的肩膀上,实现了如下算法 Home · facebookresearch/faiss Wiki · GitHub
- https://ieeexplore.ieee.org/abstract/document/1238663 在大型数据集中进行非穷举搜索的关键
- 基于PQ量化压缩的最近邻搜索
- IndexIVFPQR
- 等等
2、PQ量化
- 预训练:2步 cluster(聚类) + assign(分配) (假设原始向量为128维, 切分4段,每段32维度,假设聚类中心数nlist为256)
- cluster-1 把集合中每个128维向量的切分成4个32维的;
- cluster-2 在切分完的每个32维向量组内进行聚类,得到256个聚类中心点(一般是固定的)

- assign-1 由于nlist取256, 那么每个聚类中心可以用8bit表示(2^8 == 256);
- assign-2 那么每个128维的原始向量经过量化编码之后就可以用4个8位表示,如上图右侧
- 有128维压缩成了4维,4维中的每一维数字代表的是当前段所属的聚类中心id

- 对于量化后向量集合进行检索的方式有2种;ADC(非对称距离)及SDC(对称距离),后面的讲解是ADC的检索方式:
- query向量也切分为预训练中的4段,每段计算与预训练好的256个中心的距离【此处为4*256次32维向量的距离运算】,得到query向量与256个聚类中心距离的表; 4*256
- 此时,库的向量已经被量化成4个簇心 ID(assign-2中说的),而query向量的4段子向量与各自的256个簇心距离已经预计算好了,所以在计算两个向量的时候只用查4次表【由于有N个待对比向量,所以此处是4*N次查表】;
- 比如库里的某个向量被量化成了[124, 56, 132, 222], 那么首先查表得到query向量第一段子向量与其ID为124的簇心的距离,然后再查表得到query向量第二段子向量与其ID为56的簇心的距离......最后就可以得到四个距离d1、d2、d3、d4,query向量跟库里向量的距离d = d1+d2+d3+d4。
- 效率对比:所以在提出的例子里面,使用PQ只用4×256次32维向量距离计算加上4xN次查表,而最原始的暴力计算则有N次128维向量距离计算,很显然随着向量个数N的增加,后者相较于前者会越来越耗时;
3、IVFPQ
- IVFPQ(Inverted File + PQ)(传统PQ的检索加速,本质:空间分割+快速定位x个子空间+在x个子空间内进行遍历)
- PQ搜索过程中,会进行全空间遍历,即会遍历库里的全部向量并进行距离计算及查表【4*256次32维向量的距离运算 + 4*N次查表】,效率还可以提高
- IVFPQ优化本质:将全局遍历锁定为感兴趣区域,则可以避免不必要的全局计算及排序;
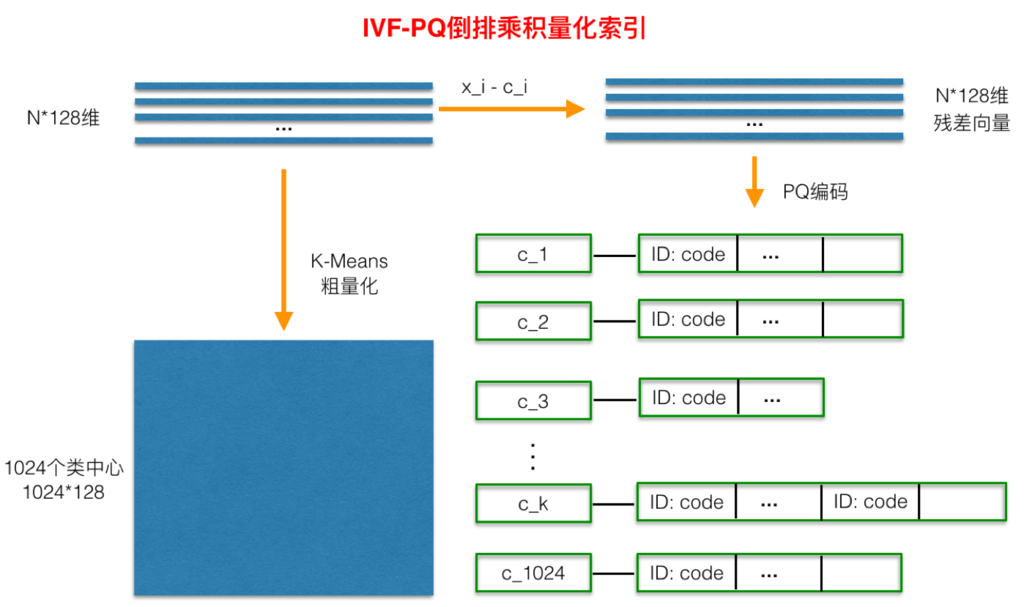
- 实现方式
- 在PQ量化之前,增加了一个粗量化过程
- 直接对库里所有向量做KMeans Clustering,假设簇心个数为1024
- 每来一个query向量,首先计算其与1024个粗聚类簇心的距离,然后选择距离最近的top N个簇
- 对topN个簇下的向量(PQ量化之后的)进行遍历及距离计算,找到最相似的topK
- Faiss具体实现有一个小细节,提高计算精度:就是在计算查询向量和一个簇底下的向量的距离的时候,所有向量都会被转化成与簇心的残差,这应该就是类似于归一化的操作,使得后面用PQ计算距离更准确一点
- 使用IVF过后,需要计算距离的向量个数就少了几个数量级,最终向量检索就变成一个很快的操作
- faiss支持的索引模式
- IndexFlatL2 暴力检索
- IndexIVFFlat
- 为了加快搜索速度,可以将数据集分割成几部分。我们在d维空间中定义Voronoi单元格,并且每个数据库矢量都落入其中一个单元格中。在搜索时,只要查询x所在单元中包含的数据库向量y与少数几个相邻查询向量进行比较。(划分搜索空间)
- IndexIVFPQ
- 有损存储
- 我们看到的索引IndexFlatL2和IndexIVFFlat都存储完整的向量。 为了扩展到非常大的数据集,Faiss提供了基于产品量化器的有损压缩来压缩存储的向量的变体。压缩的方法基于乘积量化(Product Quantizer)。
- 在这种情况下,由于矢量没有精确存储,搜索方法返回的距离也是近似值
4、优化方式
- 量化压缩(压缩特征向量维度)
- PQ乘积量化

6、参考
- 向量检索介绍【硬核系统设计】 分布式向量检索引擎_哔哩哔哩_bilibili
- 百度智能云团队分享(IVF-PQ):向量检索在大模型应用场景的技术和实践
- IVFPQ详细讲解:ANN之乘积量化PQ-CSDN博客
- HNSW https://zhuanlan.zhihu.com/p/673027535
- nmslib 对标faiss, 在hnsw索引类型,表现优于faiss:探索NMSLIB:高效近似最近邻搜索库的宝藏-CSDN博客
- 通用向量检索介绍 十分钟带你入门向量检索技术_nsw算法-CSDN博客
- faiss 原理解析
- Github 15K! 亿级向量相似度检索库Faiss 原理+应用-CSDN博客
- https://zhuanlan.zhihu.com/p/149420699
- https://zhuanlan.zhihu.com/p/357414033
- faiss源码解析
- https://zhuanlan.zhihu.com/p/79589005
- 经典向量检索算法
- https://zhuanlan.zhihu.com/p/712991028
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/458615.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!













![[项目详解][boost搜索引擎#2] 建立index | 安装分词工具cppjieba | 实现倒排索引](https://i-blog.csdnimg.cn/direct/572c7984df9d4a75acc2e60977a66813.png)