😊文章目录
- 21.说一下事件循环
- 22.ajax是什么?怎么实现?
- 23.get和post有什么区别?
- 24.Promise的内部原理是什么?它的缺点是什么?
- 25.Promise和async await的区别是什么?
- 26.浏览器的存储方式有哪些?
- 27.token存在SessionStorage还是LocalStorage?
- 28.token的登录流程。
- 29.页面渲染的过程是怎样的?
- 30.DOM树和渲染树有什么区别?
😊各位小伙伴们,本专栏新文章出炉了!!!
21.说一下事件循环
事件循环的主要任务是在JavaScript单线程环境下管理任务的执行,JavaScript本身是单线程的,这意味着任何时刻也只能执行一个任务。为了处理并发操作(如网络请求、用户输入等),JavaScript引入了事件驱动的机制。
事件循环的工作流程
- 调用栈:用来存放函数调用的信息。每当一个函数被执行时,就会在调用栈中添加一个条目;当函数执行完毕后,就会从调用栈中移除该条目。调用栈为空表示当前没有正在执行的函数。
- 任务队列:用来存放待执行的任务。当一个任务(通常是异步任务)准备好执行时,会被加入到任务队列中等待执行。
- Web APIs:浏览器提供的API,如
setTimeout、setInterval、fetch、XMLHttpRequest等,这些API通常会执行异步操作,并且在操作完成后将相应的任务放入任务队列。 - 事件循环:不断地检查调用栈是否为空,并且任务队列是否有待执行的任务,如果调用栈为空并且任务队列中有任务,则将任务队列中的第一个任务取出,并压入调用栈中执行。
事件循环的执行流程
- 同步任务:当JavaScript代码执行时,首先会执行所有的同步任务。每个同步任务都会进入调用栈,执行完毕后退出调用栈。
- 异步任务:当遇到异步任务时,如
setTimeout或fetch,这些任务会被委托给浏览器或者其他Web API来处理。一旦异步任务完成,就会生成一个待执行的任务,并将其放入任务队列。 - 检查调用栈:事件循环会持续检查调用栈是否为空,如果调用栈为空,并且此时任务队列中有任务,事件循环会从任务队列中取出第一个任务,并将其压入调用栈中执行。
- 循环队列:上述过程会不断地重复,直到所有任务都执行完毕。
微任务和宏任务
在事件循环的过程中,还需要区分两种类型的任务。
- 宏任务:如
SetTimeout、SetInterval、DOM事件、I/O、UI渲染等。 - 微任务:如
Promise、MutationObserver、process.nextTick等
微任务会在当前宏任务的JS代码执行结束后立即执行,不需要等待下一轮的事件循环,也就是说,每个宏任务的结束阶段,都会先清空所有的微任务队列。
<script>console.log("开始")setTimeout(()=>{console.log("SetTimeout开始执行!")},0)Promise.resolve().then(()=>{console.log("Promise开始执行!")})setInterval(()=>{console.log("setInterval开始执行!")},5)console.log("结束")
</script>
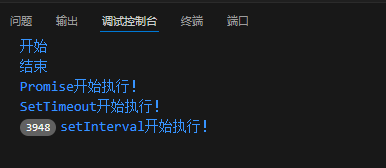
在这个例子中,首先打印开始和结束,因为他们是同步任务,然后Promise的回调会在当前宏任务结束时立即执行,最后,SetTimeout和setInterval的回调会在下一论事件循环中执行。
22.ajax是什么?怎么实现?
Ajax是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新,也就是说可以在不重新加载整个页面的情况下,对页面的某部分进行更新。
Ajax的基本原理
Ajax的核心就是在于使用XMLHttpRequest对象来与服务器通信,当用户触发Ajax请求时,JavaScript会创建一个新的XMLHttpRequest对象,并通过这个对象向服务器发送请求。服务器端收到请求后再进行处理,并返回相应数据。JavaScript再次使用XMLHttpRequest对象获取相应数据,并根据返回的数据更新页面的部分内容。
Ajax的实现
- 使用原生的
XMLHttpRequest
这是最基本的AJAX实现方式,适用于所有浏览器,并且不需要任何外部库。
<script>function ajaxGet(url, callback) {var xhr = new XMLHttpRequest();xhr.onreadystatechange = function(){if(xhr.readyState === 4 && xhr.status === 200){callback(xhr.responseText)}};xhr.open("GET",url,true)xhr.send();}ajaxGet("请求的URL",function(responseText){console.log("响应的内容为",responseText)})
</script>
- 使用
fetchAPI
fetchAPI是一种现代的、更灵活的方式来处理HTTP请求,他返回一个Promise,使得处理异步请求更加简洁。
<script>function fetchGet(url){fetch(url).then(response => response.json()).then(data => console.log(data)).catch(error => console.error("Error",error));}fetchGet("目标URL地址");
</script>
- 使用
JQuery的$.ajax方法
JQuery是一个流行的JavaScript库,他提供了一个非常方便的$.ajax方法来简化ajax请求。
<script>$.ajax({type:"GET",url:'目标URL地址',success:function(data){console.log("成功之后的数据",data)},error:function(error){console.log("Error",error);}})
</script>
- 使用Axios库
Axios是一个基于Promise的HTTP客户端,可以用于浏览器和Node.js
<script>axios.get("目标URL地址").then(response =>{console.log("成功后的数据",response.data);}).catch(error =>{console.log("Error",error);})
</script>
23.get和post有什么区别?
-
数据传输方式
- GET方法
- URL传输:GET方法通过URL传输数据,请求参数附加在URL后面,以问号
?分隔,多个参数之间用&连接。 - 大小限制:由于数据包含在URL中,因此GET请求的数据长度受限于URL的最大长度,不同的浏览器和服务器有不同的URL长度限制,一般不超过几千个字符。
- URL传输:GET方法通过URL传输数据,请求参数附加在URL后面,以问号
- POST方法
- 请求体传输:POST方法通过请求体传输数据,数据不在URL中出现,而是放在HTTP请求的消息体中。
- 大小无限制:POST请求的数据大小没有限制,可以传输大量的数据。
- GET方法
-
数据可见性
- GET方法
- 数据可见:由于数据是包含在URL中,因此GET请求的数据对所有人都是可见的,容易被缓存或记录在浏览历史中。
- POST方法
- 数据隐藏:POST请求的数据不显示在URL中,因此相对私密,不容易被缓存或记录在浏览器历史中。
- GET方法
-
安全性
- GET方法
- 安全性较低:由于数据直接暴露在URL中,GET请求不太适合传输敏感信息(如密码)。
- POST方法
- 安全性较高:POST请求更适合传输敏感信息,因为数据不直接暴露在URL中。但请注意,仅使用POST并不能保证数据安全,还需要结合SSL/TLS加密传输等安全措施。
- GET方法
-
可缓存性
- GET方法
- 可缓存:GET请求可以被浏览器缓存,因此可以加快页面加载的速度。
- POST方法
- 不可缓存:POST请求一般不被缓存,因为每次POST请求都可能包含不同的数据。
- GET方法
24.Promise的内部原理是什么?它的缺点是什么?
Promise是JavaScript用于处理异步操作的一种模式,相较于传统的回调函数,可以很好的避免“回调地狱”。
Promise的状态
一个Promise对象可以处于三种状态之一:
- Pending(待定):初始状态,既不是成功也不是失败
- Fulfilled(已成功):异步操作已完成,并且成功
- Rejected(已失败):异步操作已完成,并且失败
一旦Promise的状态从Pending变为Fulfilled或Rejected,状态就不会再改变。
Promise的构造函数
当创建一个Promise实例时,需要传入一个执行器(executor)函数,这个函数会立即执行,并接受两个参数resolve和reject,这两个参数是函数,用于改变Promise的状态。
<script>new Promise((resolve,reject)=>{//异步操作setTimeout(()=>{//成功的时候调用resolve()resolve("执行成功!");//失败的时候调用reject()// reject(new Error("执行失败!"))},1000)})
</script>
Promise的then方法
Promise对象上的then方法用于注册回调函数来处理成功或失败的状态,then方法可以接受两个参数,分别是onFulfilled和onRejected回调函数:
<script>new Promise((resolve,reject)=>{//异步操作setTimeout(()=>{//成功的时候调用resolve()resolve("执行成功!");},1000)}).then(onFulfilled =>{console.log(onFulfilled); //输出:success},onRejected =>{console.log(onRejected);})
</script>
如果Promise的状态变为Fulfilled,onFulfilled回调函数将会被调,并且可以访问到resolve函数传递的。如果Promise的状态变为Rejected,onRejected函数会被调用,并且可以访问到reject函数传递的值(通常是Error对象)。
Promise的catch方法
catch方法是then(null,rejection)的语法糖,用于捕获Promise在链式调用过程中抛出的任何错误:
<script>new Promise((resolve,reject)=>{//异步操作setTimeout(()=>{reject(new Error("失败了"))},1000)}).catch(error =>{console.log(error); //输出:Error:失败了})
</script>
Promise的finally方法
finally方法用于指定不论Promise最终状态入户都会执行的回调函数:
<script>new Promise((resolve,reject)=>{//异步操作setTimeout(()=>{resolve("成功了")},1000)}).finally(()=>{console.log("finally block")})
</script>
Promise的缺点
尽管Promise提供了许多优势,但也存在一些缺点:
- 错误处理:虽然
Promise通过catch提供了统一的错误处理机制,但如果错误发生在.then回调函数中且没有被捕获,就会成为未处理的拒绝。这可能会导致难以追踪的错误。 - 链式调用:在复杂的异步流程中,
.then的链式调用可能会变得很长,虽然这比传统的回调地狱要好,但仍然可能使得代码难以维护和阅读。 - 不支持取消:一旦创建了
Promise,就无法取消它。
25.Promise和async await的区别是什么?
Promise和async/await都是用于处理JavaScript中异步操作的技术,但他们之间存在一些关键的区别。
- 语法差异
- Promise:使用
Promise时,需要创建一个Promise对象,并通过.then()、.catch()和.finally()等方法来处理异步操作的结果。 - Async/Await:使用
async/await时,可以像编写同步代码一样,通过await关键字等待异步操作的结果。
- Promise:使用
- 可读性和简洁性
- 使用
Promise时,代码通常会形成链式调用,这样让代码看起来更加紧凑。 - 使用
async/await时,代码看起来更像是同步代码,提高了代码的可读性和简洁性。
- 使用
- 错误处理
- 在
Promise中,错误处理通常通过.catch()方法来实现 - 在
async/await中,可以使用try/catch语句来处理错误。
- 在
- 异步控制流
- 在
Promise中,可以使用.then()和.catch()来控制异步操作流程,但有时候链式调用会变得很长,使得代码难以阅读和维护。 - 在
async/await中,可以使用普通的控制流语句(如if、for、while)来控制异步操作的流程,使得代码更加直观
- 在
- 性能和执行时机
Promise是立即执行的,一旦创建就会立即执行,即使是在函数内部创建的Promise也会立即开始执行。async函数也是立即执行的,但await关键字会等待异步操作完成后再继续执行后序代码,如果await后面的操作非常快,那么可能会导致性能上的细微差异。
26.浏览器的存储方式有哪些?
- Cookie
是最早用于存储客户端数据的技术之一。通常用于存储用户的身份认证信息和其他小型信息。可以通过设置过期时间来控制Cookie的生命周期,可以是会话级别的(浏览器关闭后失效),也可以是持久化的(设置具体的过期时间)。
- LocalStorage和SessionStorage
LocalStorage和SessionStorage是HTML5引入的两种本地存储技术,他们提供了比Cookie更大的存储空间。其中,LocalStorage是永久存储,除非用户主动清除或通过JavaScript删除。SessionStorage是会话级别的存储,浏览器关闭后数据会被清除。
- IndexedDB
IndexedDB是一种客户端数据库技术,提供了比LocalStorage和SessionStorage更高级的存储功能,以键值对方式进行存储,支持结构化存储和事务处理。
27.token存在SessionStorage还是LocalStorage?
Token是一种由服务器生成的字符串或对象,用于在客户端和服务端之间传递身份验证信息。它可以包含用户的身份信息,权限信息以及其他相关的信息。
SessionStorag:数据在浏览器会话结束时自动清除,增加了安全性,但是数据会在浏览器关闭后丢失,不适合需要长期保持登录状态的场景。LocalStorage:数据可以持久化存储,适合需要长期保持登录状态的场景,但是数据在浏览器关闭后仍然存在,增加了安全风险。
28.token的登录流程。
- 用户登录:用户在客户端(如浏览器)提交用户名或密码。
- 服务器验证:服务器验证用户凭证,如果验证成功,则生成
access token和可能的refresh token。 - 返回
token:服务器将token返回给客户端。 - 客户端存储
token:客户端将token存储在本地(如LocalStorage、SessionStorage、或者Cookie) - 使用
token请求资源:客户端在后续请求中携带token来请求受保护的资源。 - 刷新
token:如果access token过期,客户端可以使用refresh token向服务器请求新的access token。
29.页面渲染的过程是怎样的?
页面渲染是指浏览器接收来自服务器的HTML、CSS和JavaScript文件,并将其转化为用户可以看到的网页的过程,这个过程涉及到多个步骤,包括下载资源,解析文档,构建DOM树,布局计算,绘制页面以及可能的重绘和回流。
- 下载资源
当用户请求一个网页时,浏览器首先从服务器下载HTML文档。
特点:
- 浏览器发送HTTP请求到服务器。
- 通常按照HTML文档中的
<link>和<script>标签的顺序加载。
- 解析HTML
浏览器开始解析HTML文档,逐步构建DOM树。
特点:
- 逐步构建:浏览器并不是等到整个HTML文档完全下载完才开始解析,而是逐步解析已下载的部分。
- 构建渲染树
在构建DOM树的同时,浏览器还会构建渲染树,渲染树种包含页面中所有可见元素及其样式信息。
特点:
- 样式计算:浏览器解析CSS规则,并将它们应用到对应的DOM节点上。
- 渲染树节点:渲染树种的节点包含了元素的位置、大小和颜色等渲染所需的信息。
- 布局计算
浏览器计算每个元素在页面上的确切位置和大小,这个过程称为布局。
特点:
- 位置和大小:确定原物的几何属性,如宽度、高度、边距等。
- 相对定位:元素的位置可能依赖于其他元素的位置,需要进行递归计算。
- 回流:当页面结构发生变化时,需要重新计算布局。
- 绘制页面
布局完成后,浏览器将页面元素绘制到屏幕上。
特点:
- 重绘:当元素的外观发生变化(如颜色,背景等),但位置和大小不变时,需要重新绘制受影响的区域。
- 执行JavaScript
如果页面中包含JavaScript代码,浏览器会在适当的时候执行这些脚本。
- 重绘与回流
- 重绘:当元素的外观变化(如颜色、背景等)但位置和大小不变时,浏览器绘重新绘制该元素。
- 回流:当页面结构或布局发生变化(如元素的尺寸,位置变化)时,浏览器需要重新计算布局,这个过程称为回流(也叫重排)。
30.DOM树和渲染树有什么区别?
DOM树是一个表示文档结构的树状数据结构,它包含了文档中的所有元素、属性和文本内容。而渲染树是一个包含页面中所有可见元素及其样式信息的数据结构。DOM树主要是用于描述文档的逻辑结构,便于JavaScript操作文档内容,而渲染树则用于计算布局和绘制页面元素。
DOM树的构建始于浏览器开始解析HTML文档,逐步构建直至文档完全解析完毕。渲染树的构建是在DOM树构建完成之后进行,当浏览器解析完CSS样式并将其应用到DOM节点上时,会构成渲染树。
🎨觉得不错的话记得点赞收藏呀!!🎨
😀别忘了给我关注~~😀














![[笔记] ffmpeg docker编译环境搭建](https://i-blog.csdnimg.cn/direct/4ca0ed12c4b4496ebf672e19b0fcd5e7.png)