- 论文:https://arxiv.org/pdf/2410.02525
- 代码:暂未开源
- 机构:康奈尔大学
- 领域:embedding model
- 发表:arxiv

研究背景
- 研究问题:这篇文章要解决的问题是如何改进文档嵌入,使其在特定上下文中的检索任务中表现更好。传统的文档嵌入方法通常直接对单个文档进行编码,但这些嵌入在针对特定用例的检索中可能会失去上下文信息。
- 研究难点:该问题的研究难点包括:如何在嵌入过程中考虑文档及其邻近文档的上下文信息;如何在不同领域之间保持模型的鲁棒性;如何在不增加额外计算和存储需求的情况下实现上下文化。
- 相关工作:该问题的研究相关工作包括统计方法和神经网络方法的文本检索模型。统计方法如BM25可以利用先验语料库统计信息(如逆文档频率IDF)来增强模型的上下文依赖性。神经网络方法如双编码器架构通过端到端学习来改进检索性能,但缺乏对上下文的显式建模。
所谓上下文信息,可以看这个case study:
问题:
密歇根州布雷肯里奇的人口
证词是否可以用于刑事案件哪些案件需要严格审查
州最高法院的职能
爱达荷州的人口是多少
爱荷华州曼森的人口是多少
量刑听证会后会发生什么 弗拉特黑德县的人口
堪萨斯州惠廷的人口
爱达荷州刘易斯顿的人口是多少
如果您没有出席陪审团会怎么样
宾夕法尼亚州克利尔菲尔德县的人口
审判需要多长时间 肯塔基州克林顿的人口
密歇根州伊斯科县的人口
对应的问答也基本全是关于人口的统计结果信息,所以这里的邻近是指相似的查询和相似的文档,而不同于平常理解的那种“上下文”,这是逻辑上的相关,而本文的邻近文档是内容上的邻近,本文提出的方法我认为实际上是增强了检索器对内容相似文档的区分能力。
研究方法
这篇论文提出了两种互补的方法来实现上下文化文档嵌入(Contextual Document Embedding, CDE):一种是对抗性对比学习目标,另一种是新的上下文架构。具体来说,
- 对抗性对比学习目标:首先,提出了一种替代的对抗性对比学习目标,该目标明确地将文档邻居纳入到批处理上下文损失中。具体来说,使用快速查询-文档聚类为每个训练批次生成一组邻居。每个训练更新完全由邻居文档构成,以确保嵌入能够在最具挑战性的上下文中区分文档。公式如下:

2. 上下文架构:其次,提出了一种新的编码器架构,该架构在嵌入过程中显式注入上下文文档的信息。该方法增强了标准的BERT风格编码器,增加了额外的条件,提供了关于邻近文档的聚合文档级信息。公式如下:



实验设计
- 数据收集:实验使用了Nussbaum训练文本嵌入模型元数据集中收集的数据集,包括从维基百科和Reddit等网络资源抓取的24个数据集。训练阶段使用了200M弱监督数据点,监督训练阶段包括1.8M人工编写的查询-文档对,来自HotpotQA和MS MARCO等流行检索数据集。
- 实验设置:实验在一个小型设置中进行,使用六层Transformer,最大序列长度为64,最多64个额外上下文字符。评估在BEIR基准的截断版本上进行。大规模设置中,使用小型实验中找到的最佳设置,在长度为512的序列上训练单个模型,并在完整的MTEB基准上进行评估。
- 参数配置:所有实验都使用Adam优化器,1000步预热到学习率2⋅10−5,并在训练过程中线性衰减到0。序列dropout设置为均匀概率p=0.005。
结果与分析
-
小型设置结果:在对抗性对比学习和上下文架构的改进下,小型设置中的性能优于传统的双编码器训练。结合这两种技术时,性能提升最大。
-
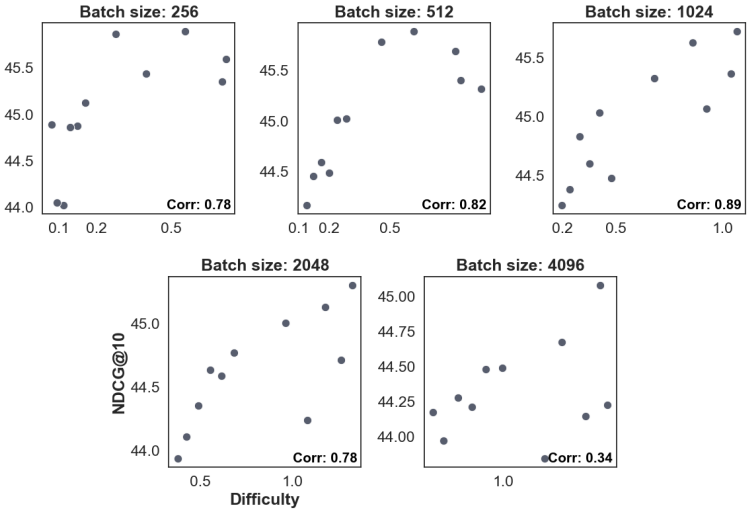
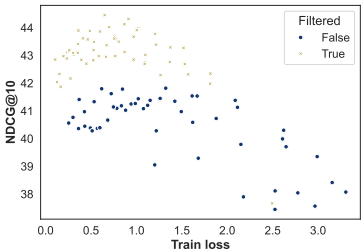
批处理和集群大小的影响:在包含过滤的情况下,较小的集群大小明显优于较大的批处理大小。过滤假阴性显著提高了性能。
-
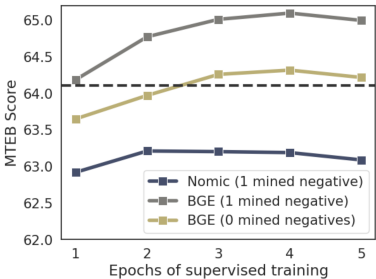
全规模训练结果:在监督数据集上的多轮训练中,最佳性能出现在在BGE元数据集上训练四轮时。尽管最佳模型每个查询使用一个硬负样本,但仍然能够在没有硬负样本的情况下实现最先进的结果。
-
上下文架构的性能:上下文架构在所有下游数据集上的性能普遍匹配或优于双编码器,特别是在ArguAna和SciFact等较小且领域外数据集上提升最大。


总体结论
这篇论文提出了两种改进传统双编码器模型的方法,用于生成嵌入。第一种方法通过重新排序训练数据点使批次更难,从而改进了传统的训练方法。第二种方法提出了一种新的语料库感知架构,允许训练最先进的文本嵌入模型。实验结果表明,这些改进在多个数据集和任务上均取得了最先进的结果。
优点与创新
- 提出了两种互补的方法来实现上下文化文档嵌入:首先是一种新的对比学习目标,该目标明确地将文档邻居纳入到批处理上下文损失中;其次是一种新的上下文架构,该架构将邻居文档信息显式编码到编码表示中。
- 在多个设置中实现了比双编码器更好的性能,特别是在跨域情况下,差异尤为显著。
- 在MTEB基准测试中取得了最先进的结果,且无需硬负样本挖掘、分数蒸馏、特定数据集指令、GPU内示例共享或极大的批量大小。
- 提出了一种新的训练算法,该算法通过快速查询-文档聚类为每个训练批次生成一组邻居,确保嵌入能够在最具挑战性的上下文中区分文档。
- 提出了一种新的上下文编码器架构,该架构在标准的BERT风格编码器基础上增加了额外的条件,提供了关于邻居文档的聚合文档级信息。
- 在不需要额外存储或其他更改的情况下,通过使用语料库信息生成特定于特定领域的文档和查询嵌入。
- 在行业规模上训练时,模型在小(<250M参数)模型上取得了MTEB基准测试的最先进结果。
不足与反思
- 计算资源使用:所有模型均在8个NVIDIA H100 GPU上进行预训练。单个无监督epoch的训练时间约为一天,而上下文架构的单epoch训练时间约为两天。较短序列长度的实验快10-20倍,并且可以在单个GPU上运行。
- 分布式数据并行(DDP)的挑战:作者指出,使用对比损失和DDP设置训练模型可能会非常困难,特别是在聚合样本时,如果任何伪影揭示了模型来自哪个GPU,模型可能会迅速退化到一个次优解。
- 位置性移除:尽管作者使用了带有旋转位置嵌入的BERT版本来避免这个问题,但完全禁用位置性仍然是一个可行的替代方案。
- 上下文大小的影响:作者观察到,随着条件的变化,上下文嵌入在空间中可能会移动,但仍然保持相对接近。
- 未来的工作:包括分析不同打包策略的完整影响,例如昂贵的平衡K-Means或启发式方法如等距K-Means。
实验结果表明,上下文架构在不同规模的数据集和任务上表现如何?有哪些具体的改进?
- 小规模实验结果:在对BEIR基准的缩短版本上的实验表明,上下文架构在对立性对比学习和传统双编码器训练的基础上均有显著提升。结合这两种技术时,性能提升最大。
- 大规模实验结果:在MTEB基准上,使用250M或更少参数的模型,上下文架构在所有下游数据集上均表现出色,特别是在ArguAna和SciFact等较小且领域外的数据集上提升最大。例如,在ArguAna数据集上,上下文架构的NDCG@10评分从基线的54.8提升到81.7。
- 过滤假阴性:实验表明,过滤假阴性显著提高了性能,尤其是在大规模批处理和聚类中。过滤假阴性后,模型在多个数据集上的NDCG@10评分均有显著提升。
- 批处理难度与性能的关系:实验结果显示,批处理难度与下游性能呈强相关性,更难批处理的学习效果更好。通过调整批处理难度,上下文架构能够在不同规模的数据集上实现更好的性能。
总体而言,上下文架构在不同规模的数据集和任务上均取得了显著的性能提升,特别是在领域外数据集上表现尤为突出。








![HelloCTF [RCE-labs] Level 4 - SHELL 运算符](https://img-blog.csdnimg.cn/img_convert/77bc82d42b136204815e76d403692ffc.png)





