代码获取:https://github.com/qingxuly/hsp_python_course
完结版:Python基础学习完结版
数据容器
基本介绍
- 数据容器是一种数据类型,有些地方也简称容器/collections。
- 数据容器可以存放多个数据,每一个数据也被称为一个元素。
- 存放的数据/元素可以是任意类型。
- 简单的说,数据容器就一种可以存放多个数据/元素的数据类型。
列表(list)
基本介绍
- 列表可以存放多个不同数据类型,即:列表就是一列数据(多个数据)。
- 列表也是一种数据类型。
列表的定义
- 列表的定义:创建一个列表,只要用逗号分隔不同的数据项使用方括号括起来即可,示例如下:
list1 = [100, 200, 300, 400, 500]
list2 = ["red", "green", "blue", "yellow", "white", "black"]
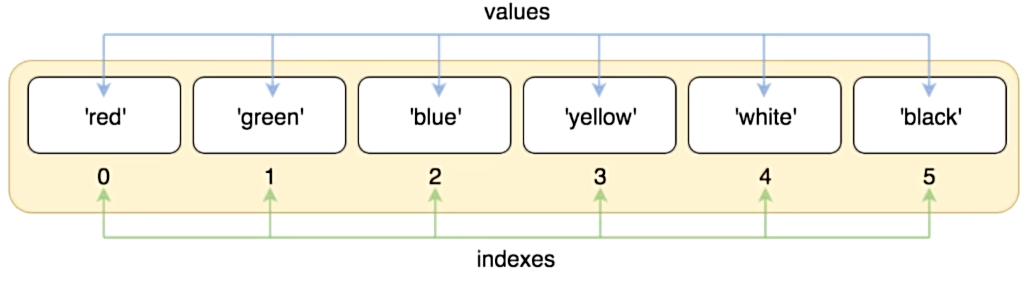
- 列表内存图
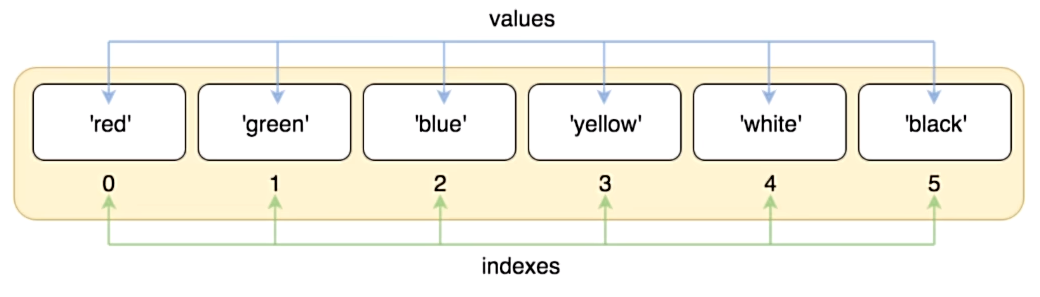
# 列表的定义
list1 = [100, 200, 300, 400, 500]
print(list1)
print(type(list1))
列表的使用
-
列表的使用方法:
列表名 [下标] -
注意:索引是从 0 开始计算的。
list2 = ["red", "green", "blue", "yellow", "white", "black"]
print(list2)
print(f"第三个元素是:{list2[2]}")
列表的遍历
- 简单来说,列表的遍历就是将列表的每个元素以此取出,进行处理的操作,就是遍历/迭代。
# 内置函数 len()可以返回对象的长度(元素个数)。
list_color = ["red", "green", "blue", "yellow", "white", "black"]
index = 0
while index < len(list_color):print(f"第{index + 1}个元素是:{list_color[index]}")index += 1
list_color = ["red", "green", "blue", "yellow", "white", "black"]
for ele in list_color:print(f"元素是:{ele}")
列表解决养鸡场问题
hens = [3, 5, 1, 3.4, 2, 50]
total_weight = 0.0
for ele in hens:total_weight += ele
print(f"总体重:{total_weight} 平均体重:{round(total_weight/len(hens), 2)}")
注意事项和使用细节
- 如果我们需要一个空列表,可以通过
[]或list()方式来定义。
list1 = []
list2 = list()print(list1, type(list1))
print(list2, type(list2))
- 列表的元素可以有多个,而且数据类型没有限制,允许有重复元素,并且是有序的。
list3 = [100, "jack", 4.5, True, "jack"]
print(list3)# 嵌套列表
list4 = [100, "tom", ["天龙八部", "笑傲江湖", 300]]
print(list4)
-
列表的索引/下标是从 0 开始的。
-
列表索引必须在指定范围内使用,否则报 IndexError: list index out of range。
list5 = [1, 2]
print(list5[2]) # IndexError: list index out of range
- 索引也可以从尾部开始,最后一个元素的索引为-1, 往前一位为-2,以此类推。
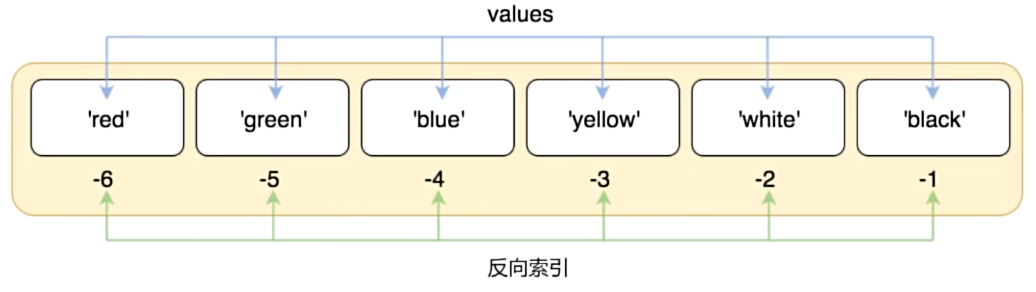
list6 = ["red", "green", "blue", "yellow", "white", "black"]
print(list6[-1])
print(list6[-6])
# 依然不能索引越界
print(list6[-7]) # IndexError: list index out of range
- 通过
列表[索引]=新值对数据进行更新,使用列表.append(值)方法来添加元素,使用del语句来删除列表的元素,注意不能超出有效索引范围。
list_a = ["天龙八部", "笑傲江湖"]
print("list_a:", list_a)
list_a[0] = "雪山飞狐"
print("list_a:", list_a)
list_a.append("倚天屠龙")
print("list_a:", list_a)
del list_a[1]
print("list_a:", list_a)
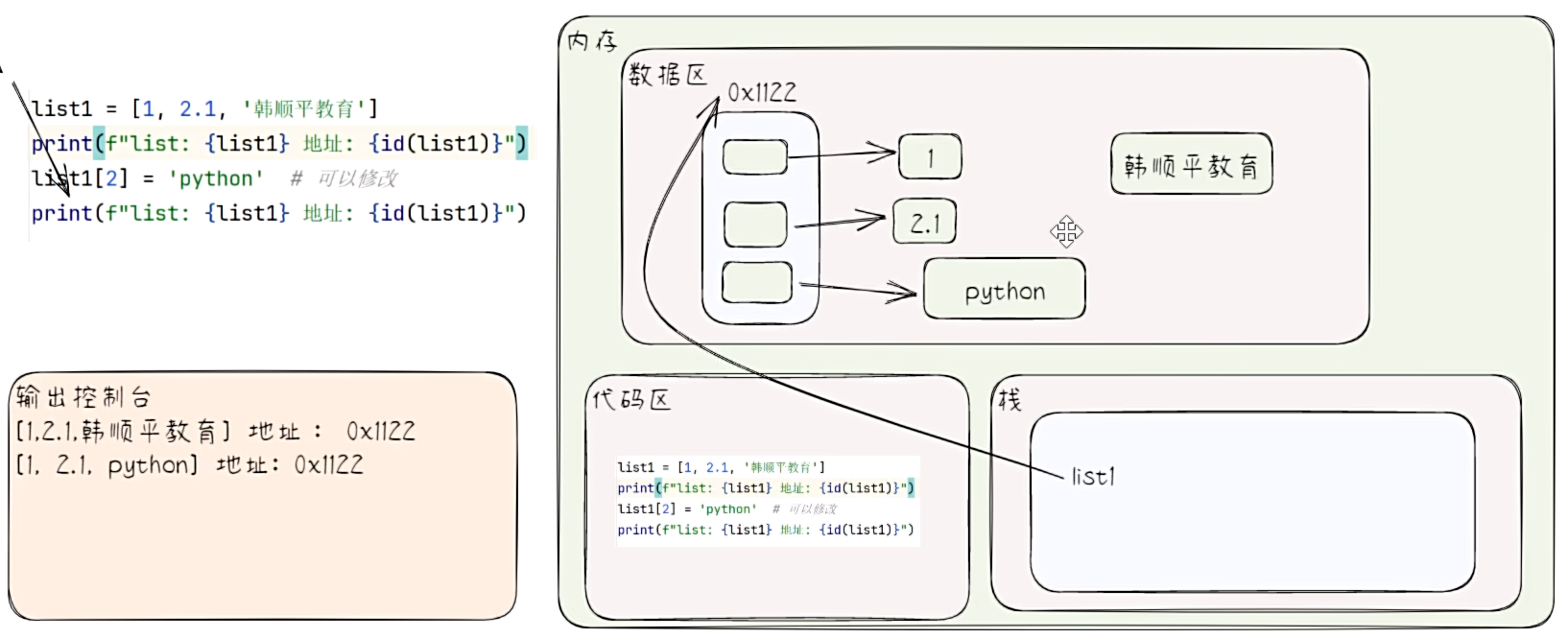
- 列表是可变序列(要注意其使用特点)。
# 列表是可变序列(要注意其使用特点)。
list1 = [1, 2.1, "hsp"]
print(f"list1: {list1} 地址:{id(list1)} 第三个元素地址 {id(list1[2])}")
list1[2] = "python"
print(f"list1: {list1} 地址:{id(list1)} 第三个元素地址 {id(list1[2])}")
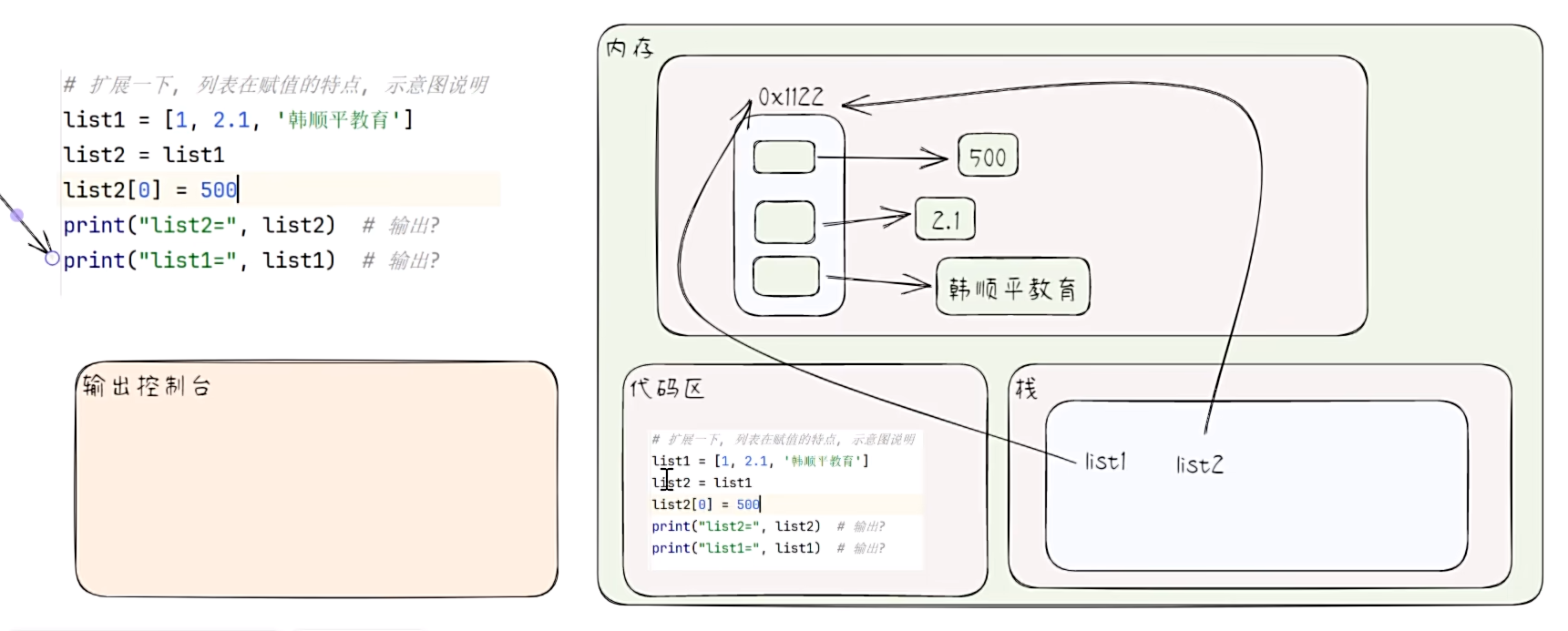
- 列表在赋值时的特点
# 扩展一下,列表在赋值时的特点
list1 = [1, 2.1, "hsp"]
list2 = list1
list2[0] = 500
print("list2:", list2)
print("list1:", list1)
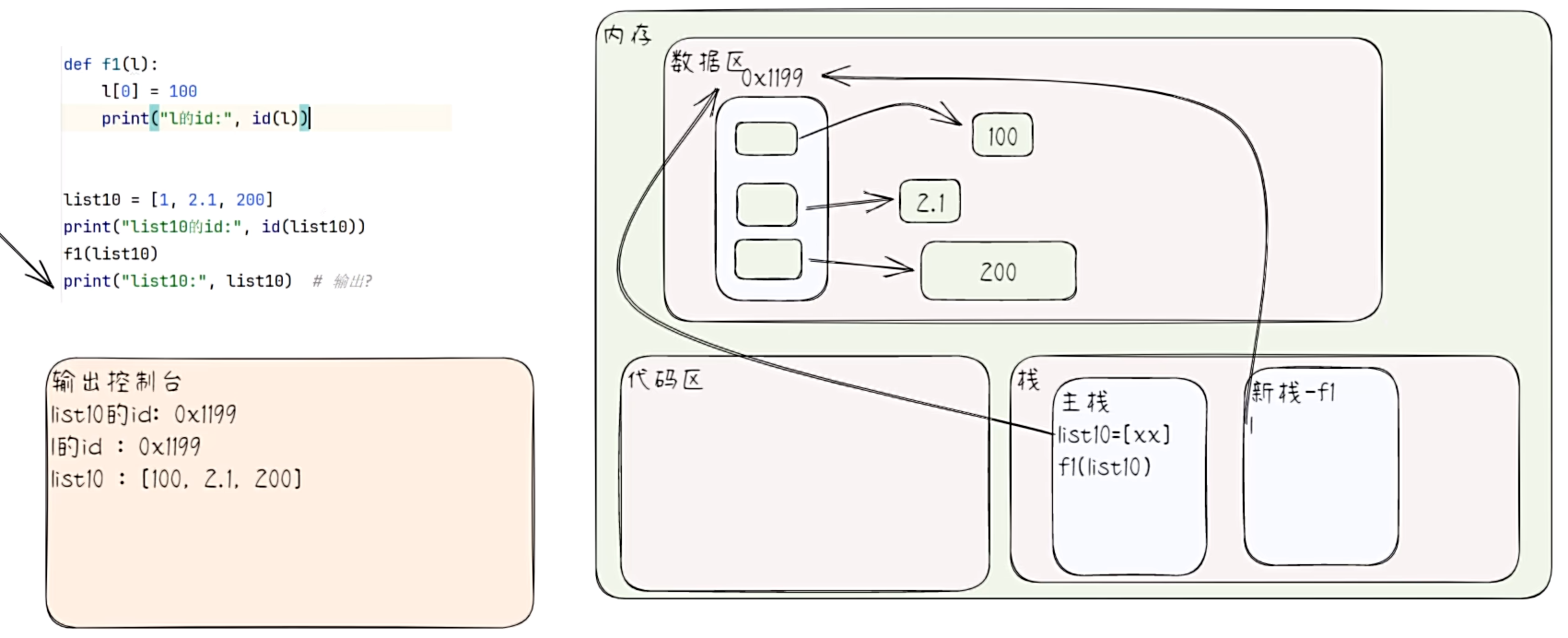
- 列表在函数传参时的特点
# 列表在函数传参时的特点
def f1(l):l[0] = 100print("l的id:", id(l))list10 = [1, 2.1, 200]
print("list10的id:", id(list10))
f1(list10)
print("list10:", list10)
列表的常用操作
- 列表常用操作](https://docs.python.org/zh-cn/3/library/stdtypes.html#lists)
- 常用操作一览
| 序号 | 函数 |
|---|---|
| 1 | len(list):列表元素个数 |
| 2 | max(list):返回列表元素最大值 |
| 3 | min(list):返回列表元素最小值 |
| 4 | list(seq):将元组转换成列表 |
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj):在列表末尾添加新的对象 |
| 2 | list.count(obj):统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj):从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj):将对象插入列表 |
| 6 | list.pop([index =-1]):移除列表中的一个元素(默认最后一个元素),并返回该元素的值 |
| 7 | list.remove(obj):移除列表中某个值的第一个匹配项 |
| 8 | list.reverse():反向列表中元素 |
| 9 | list.sort(key = None, reverse = False):对原列表进行排序 |
| 10 | list.clear():清空列表 |
| 11 | list.copy():复制列表 |
- 演示列表常用操作
# 演示列表常用操作
list_a = [100, 200, 300, 400, 600]
print("list_a 列表元素个数:", len(list_a))
print("list_a 列表最大元素:", max(list_a))
print("list_a 列表最小元素:", min(list_a))# list.append(obj):在列表末尾添加新的对象
list_a.append(900)
print("list_a:", list_a)# list.count(obj):统计某个元素在列表中出现的次数
print("100出现的次数:", list_a.count(100))# list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list_b = [1, 2, 3]
list_a.extend(list_b)
print("list_a:", list_a)# list.index(obj):从列表中找出某个值第一个匹配项的索引位置
print("300第1次出现在序列的索引是:", list_a.index(300))
# 如果找不到,会报错:ValueError
# print("1000第1次出现在序列的索引是:", list_a.index(1000)) # ValueError: 1000 is not in list# list.insert(index, obj):将对象插入列表
list_a.insert(1, 666)
print("list_a:", list_a)# list.pop([index=-1]):移除列表中的一个元素(默认最后一个元素),并返回该元素的值
print(list_a.pop())
print("list_a:", list_a)# list.remove(obj):移除列表中某个值的第一个匹配项 |
list_a.remove(666)
print("list_a:", list_a)# list.reverse():反向列表中元素
list_a.reverse()
print("list_a:", list_a)# list.sort(key=None, reverse=False):对原列表进行排序
list_a.sort()
print("list_a:", list_a)# list.copy():复制列表
list_c = list_a.copy()
print("list_c:", list_a)# list.clear():清空列表
list_a.clear()
print("list_a:", list_a)
- 列表生成式
- 列表生成式就是“生成列表的公式”
- 基本语法
[列表元素的表达式 for 自定义变量 in 可迭代对象]
- 案例演示
# 列表生成式
list_1 = [ele * 2 for ele in range(1, 5)]
print("list_1:", list_1) # list_1: [2, 4, 6, 8]list2 = [ele + ele for ele in "hsp"]
print("list2:", list2) # list2: ['hh', 'ss', 'pp']list3 = [ele * ele for ele in range(1, 11)]
print("list3:", list3)
练习
# 循环从键盘输入5个成绩,保存到列表,并输出。
scores = []
for _ in range(5):score = float(input("请输入成绩:"))scores.append(score)
print(f"成绩情况:{scores}")
元组(tuple)
基本介绍
- 元组(tuple)可以存放多个不同类型数据,元组是不可变序列。
- tuple 不可变是指当你创建了 tuple 时,它就不能改变了,也就是说它没有 append(),insert() 这样的方法,但它也有获取某个索引值的方法,但是不能重新复制。
- 元组也是一种数据类型。
元组的定义
- 创建一个元组,只要把逗号分隔不同的数据线,使用圆括号括起来即可。
# 元组的定义
tuple_a = (100, 200, 300, 400, 500)
print("tuple_a =", tuple_a, type(tuple_a))
元组的使用
- 元组使用语法:
元组名[索引]
# 元组的使用
tuple_b = ("red", "green", "blue", "yellow", "white", "black")
print("第三个元素是:", tuple_b[2])
元组的遍历
- 简单来说,就是将元组的每个元素以此取出,进行处理的操作,就是遍历/迭代。
# while 遍历元组
tuple_color = ("red", "green", "blue", "yellow", "white", "black")
index = 0
while index < len(tuple_color):print(tuple_color[index])index += 1
# for 变量元组
tuple_color = ("red", "green", "blue", "yellow", "white", "black")
for ele in tuple_color:print(ele)
注意事项和使用细节
- 如果我们需要一个空元组,可以通过(),或者 tuple() 方式来定义。
tuple_a = ()
tuple_b = tuple()
print(f"tuple_a : {tuple_a}")
print(f"tuple_b : {tuple_b}")
- 元组的元素可以有多个,而且数据类型没有限制(甚至可以嵌套元组),允许有重复元素,并且是有序的。
tuple_c = (100, "jack", 4.5, True, "jack")
print(f"tuple_c : {tuple_c}")# 嵌套元组
tuple_d = (100, "tom", ("天龙八部", "笑傲江湖", 300))
print(f"tuple_d : {tuple_d}")
- 元组的索引/下标是从 0 开始的。
- 元组索引必须在指定范围内使用,否则报:IndexError: tuple index out of range 。
tuple_e = (1, 2.1, "hsp")print(tuple_e[1])
# 索引越界
print(tuple_e[3]) # IndexError: tuple index out of range
- 元组是不可变序列。
tuple_f = (1, 2.1, "hsp")# 不能修改
# tuple_f[2] = "python" # TypeError: 'tuple' object does not support item assignment
- 可以修改元组内 list 的内容(包括修改、增加、删除等)
tuple_g = (1, 2.1, "hsp", ["jack", "tom", "mary"])
print(tuple_g[3])
print(tuple_g[3][0])# 修改
tuple_g[3][0] = "HSP"
print(tuple_g)
# 不能替换整个列表元素
# tuple_g[3] = [10, 20] # TypeError: 'tuple' object does not support item assignment# 删除
del tuple_g[3][0]
print(tuple_g)# 增加
tuple_g[3].append("smith")
print(tuple_g)
- 索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。
tuple_h = (1, 2.1, "hsp", ["jack", "tom", "mary"])
print(tuple_h[-2])
- 定义只有一个元素的元组,需要带上逗号,否则就不是元组类型。
tuplg_i = (100,)
print(f"tuplg_i : {tuplg_i}", type(tuplg_i))
# 输出 tuplg_i : (100,) <class 'tuple'>tuplg_j = (100)
print(f"tuplg_j : {tuplg_j}", type(tuplg_j))
# 输出 tuplg_j : 100 <class 'int'>
- 既然有了列表,python 设计者为什么还提供元组这样的数据类型呢?
- 在项目中,尤其是多线程环境中,有经验的程序员会考虑使用不变对象(一方面因为对象状态不能修改,索引可以避免由此引起的不必要的程序错误;另一方面一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。可以方便的被共享访问)。所以,如果不需要对元素进行添加、删除、修改的情况下,可以考虑使用元组。
- 元组在创建时间和占用的空间什么都优于列表。
- 元组能够对不需要修改的数据写保护。
元组的常用操作
- 元组常用操作
- 常用操作一览
| 序号 | 操作 |
|---|---|
| 1 | len(tuple):元组元素个数 |
| 2 | max(tuple):返回元组元素最大值 |
| 3 | min(tuple):返回元组元素最小值 |
| 4 | tuple.count(obj):统计某个元素在元组中出现的次数 |
| 5 | tuple.index(obj):从元组中找出某个值第一个匹配项的索引位置 |
# 演示元组常用操作
tuple_a = (100, 200, 300, 400, 600, 200)
print("tuple_a 元组元素个数:", len(tuple_a))
print("tuple_a 元组最大元素:", max(tuple_a))
print("tuple_a 元组最小元素:", min(tuple_a))# tuple.count(obj):统计某个元素在列表中出现的次数
print("100出现的次数:", tuple_a.count(100))
print("200出现的次数:", tuple_a.count(200))# tuple.index(obj):从列表中找出某个值第一个匹配项的索引位置
print("200第1次出现在元组的索引:", tuple_a.index(200))
# 如果找不到,会报错:ValueError: tuple.index(x): x not in tuple
# print("1000第1次出现在元组的索引:", tuple_a.index(1000)) # ValueError: tuple.index(x): x not in tuple# x in s:s中的某项等于x 则结果为True,否则为False
print(300 in tuple_a) # True
练习
"""
定义一个元组:("大话西游", "周星驰", 80, ["周星驰", "小甜甜"])
信息为:(片名, 导演, 票价, 演员列表)
"""tuple_move = ("大话西游", "周星驰", 80, ["周星驰", "小甜甜"])
print("票价对应的索引:", tuple_move.index(80))
# 遍历所有演员
for ele in tuple_move[3]:print(ele)# 删除 "小甜甜", 增加演员 "牛魔王",“猪八戒”
del tuple_move[3][1]
tuple_move[3].append("牛魔王")
tuple_move[3].append("猪八戒")
print(tuple_move)
字符串(str)
基本介绍
- 在 python 中处理文本数据是使用 str 对象,也称为字符串。字符串是由 Unicode 码位构成的不可变序列。
- Unicode 码是一种字符编码。
- ord():对表示单个 Unicode 字符的字符串,返回代表它 Unicode 码点的整数。例如
ord('a')返回整数97。 - chr():返回 Unicode 码位为整数 i 的字符的字符串格式。例如,
chr(97)返回字符串'a'。
- 字符串字面值有三种写法。
- 单引号:‘允许包含有“双”引号’。
- 双引号:“运行嵌入’单’引号”。
- 三重引号:‘’‘三重单引号’‘’,“” “三重双引号” “”,使用三重引号的字符串可以跨越多行——其中所有的空白字符都将包含在该字符串字面值中。
- 字符串是字符的容器,一个字符串可以存放多个字符,比如 “hi-韩顺平教育”。
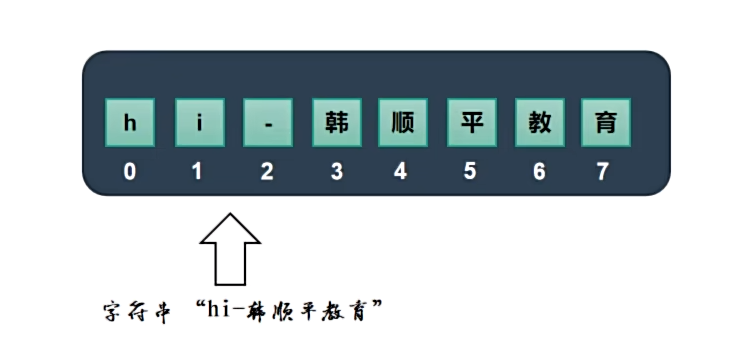
字符串支持索引
- 使用语法:
字符串名[索引]
str_a = "red-green"
print("str_a的第三个值/字符是:", str_a[2], type(str_a[2]))
字符串的变量
- 简单的说,就是将字符串的每个元素依次取出,进行处理的操作,就是遍历/迭代。
# 使用while和for遍历字符串
str_b = "hi-韩顺平教育"
index = 0
while index < len(str_b):print(str_b[index])index += 1for ele in str_b:print(ele)
注意事项和使用细节
- 字符串索引必须在指定范围内使用,否则报: 。索引也可以从尾部开始,最后一个元素的索引为-1,往前一位为-2,以此类推。
- 字符串是不可变序列,不能修改。
str_b = "hi-韩顺平教育"# 通过索引可以访问指定元素
print(str_b[3])
# 不能修改元素
# str_b[3] = "李" # TypeError: 'str' object does not support item assignment
- 在 Python 中,字符串长度没有固定的限制,取决于计算机内存大小。
字符串常用操作
- 字符串常用操作
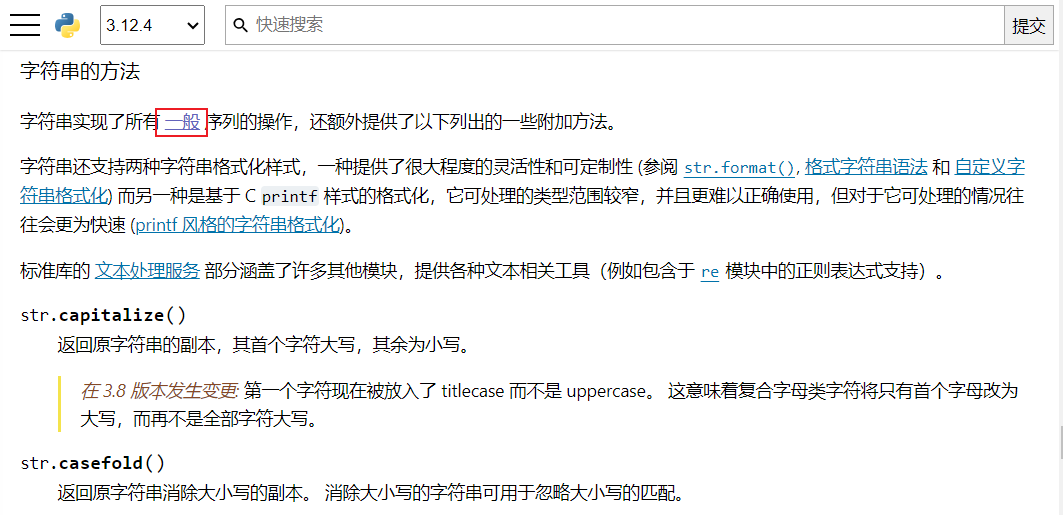
- 常用操作一览
| 序号 | 操作 |
|---|---|
| 1 | len(str):字符串的长度,也就是包含多少个字符 |
| 2 | str.replace(old, new [, count]):返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。如果给出了可选参数 count,则只替换前 count 次出现。 |
| 3 | str.split(sep = None, maxaplit =-1):返回一个由字符串内单词组成的列表,使用 seq 作为分隔字符串。如果给出了 maxsplit,则最多进行 maxsplit 次拆分(因此,列表最多会有 maxsplit + 1 个元素)。如果 maxsplit 未指定或为 -1,则不限制拆分次数(进行所有可能的拆分) |
| 4 | str.count(sub):统计指定字符串在字符串中出现的次数 |
| 5 | str.index(sub):从字符串中找出指定字符串第一个匹配项的索引位置 |
| 6 | str.strip([chars]):返回原字符串的副本,移除其中的前导和末尾字符。chars 为指定要移除字符的字符串 |
| 7 | str.lower():返回原字符串小写的副本 |
| 8 | str.upper():返回原字符串大写的副本 |
# 演示字符串常用操作
str_names = " jack tom mary hsp nono tom "# len(str):字符串的长度,也就是包含多少个字符
print(f"{str_names}有{len(str_names)}个字符")# str.replace(old, new[, count]):返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。如果给出了可选参数 count,则只替换前 count 次出现。
# 说明:返回字符串的副本:表示原来的字符串不变,而是返回一个新的字符串。
str_names_new = str_names.replace("tom", "汤姆", 1)
print("str_names_new:", str_names_new)
print("str_names:", str_names)# str.split(sep=None, maxaplit=-1):返回一个由字符串内单词组成的列表,使用 seq 作为分隔字符串。如果给出了 maxsplit,则最多进行 maxsplit 次拆分(因此,列表最多会有
# maxsplit + 1个元素)。如果 maxsplit 未指定或为 -1,则不限制拆分次数(进行所有可能的拆分)
str_names_split = str_names.split(" ")
print("str_names_split:", str_names_split, type(str_names_split))# str.count(sub):统计指定字符串在字符串中出现的次数
print("tom出现的次数:", str_names.count("tom"))# str.index(sub):从字符串中找出指定字符串第一个匹配项的索引位置
print(f"tom出现的索引:{str_names.index('tom')}")# str.strip([chars]):返回原字符串的副本,移除其中的前导和末尾字符。chars 为指定要移除字符的字符串
# 说明:这个方法通常用于除去前后的空格,或者去掉制定的某些字符
str_names_strip = str_names.strip()
print("str_names_strip:", str_names_strip)
print("123t2om13".strip("123"))# str.lower():返回原字符串小写的副本
str_names = "hspHaHa"
str_names_lower = str_names.lower()
print("str_names_lower:", str_names_lower)# str.upper():返回原字符串大写的副本
str_names_upper = str_names.upper()
print("str_names_upper:", str_names_upper)
字符串比较
- 字符串比较
- 运算符:>,>=,<,<=,==,!=
- 比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的后续字符将不再比较。
- 比较原理:两个字符进行比较时,比较的是其
ordinal value(原始值/码值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr,调用内置函数chr时指定ordinal value可以得到其对应的字符。
# ord()与chr()使用
print(ord('1'))
print(ord('A'))
print(ord('a'))
print(ord('h'))print(chr(49))
print(chr(65))
print(chr(97))
print(chr(104))
# 字符串比较
print("tom" > "hsp")
print("tom" > "to")
print("tom" > "tocat")
print("tom" < "老韩")
print("tom" > "tom")
print("tom" <= "tom")
"""
定义一个字符串,str_names="tom jack mary nono smith hsp"
统计一共有多个人名;如果有"hsp"则替换成"老韩";如果人名是英文,则把首字母改为大写
str.capitalize():字符串首字符改为大写
"""str_names = str("tom jack mary nono smith")str_names_list = str_names.split(" ")
print(f"人名的个数:{len(str_names_list)}")
str_names_re = str_names.replace("hsp", "韩顺平")
print(str_names_re)str_names_upper = ""
for ele in str_names_list:if ele.isalpha():str_names_upper += ele.capitalize() + " "# 去掉两边的" "
str_names_upper = str_names_upper.strip(" ")
print(str_names_upper)
切片
基本介绍
- 切片:从一个序列中,取出一个子序列,在实际开发中,程序员经常对序列进行切片操作。
- 序列:序列是指,内容连续、有序,可使用索引的一类数据容器。
- 上文的列表(list)、元组(tuple)、字符串均可视为序列。
基本语法
- 基本语法:
序列[起始索引:结束索引:步长]- 表示从序列中,从指定的起始索引开始,按照指定的步长,依次取出元素,到指定结束索引为止,截取到一个新的序列。
- 切片操作是前闭后开,即
[其实索引:结束索引),截取的子序列包括起始索引,但是不包括结束索引。 - 步长表示,依次取出元素的间隔。
- 步长为 1:一个一个的取出元素;
- 步长为 2:每次跳过一个元素取出;
- 步长为 3,每次跳过 N-1 个元素取出。
# 字符串切片,截取"hello"
str_a = "hello,world"
print(str_a[0:5:1])# 列表切片,截取["tom", "nono"]
list_a = ["jack", "tom", 'yoyo', "nono", "hsp"]
print(list_a[1:4:2])# 元组切片,截取(200, 300, 400, 500)
tuple_a = (100, 200, 300, 400, 500, 600)
print(tuple_a[1:5:1])
注意事项和使用细节
- 切片语法:
序列[起始索引:结束索引:步长],起始索引如果不写,默认为 0,结束索引如果不写,默认截取到结果,步长如果不写,默认为 1。
str_a = "hello,hspjy"
str_slice01 = str_a[:5:1]
print("str_slice01", str_slice01)
str_slice02 = str_a[1::1]
print("str_slice02", str_slice02)
str_slice03 = str_a[::1]
print("str_slice03", str_slice03)
str_slice04 = str_a[2:5:]
print("str_slice04", str_slice04)
- 切片语法:
序列[起始索引:结束索引:步长],步长为负数,表示反向取,同时注意起始索引和结束索引也要反向标记。
str_b = "123456"
str_slice05 = str_b[-1::-1]
print("str_slice05", str_slice05)str_slice06 = str_b[-1:-6:-1]
print("str_slice06", str_slice06)
- 切片操作并不会影响原序列,而是返回了一个序列。
str_c = "ABCD"
str_slice07 = str_c[1:3:1]
print("str_slice07", str_slice07)
print("str_c", str_c)
练习
# 定义列表 list_name = ["Jack", "Lisa", "Hsp", "Paul", "Smith", "Kobe"]
# 取出前三个名字;取出后三个名字,,并且保证原来顺序
list_name = ["Jack", "Lisa", "Hsp", "Paul", "Smith", "Kobe"]
list_name_f = list_name[0:3:1]
list_name_b = list_name[-1:-4:-1]
list_name_b.reverse()
print(f"前三个名字:{list_name_f}")
print(f"后三个名字:{list_name_b}")
集合(set)
基本介绍
- python 支持集合这种数据类型,集合是由不重复元素组成的无序容器。
- 不重复元素:集合中不会有相同的元素。
- 无序:集合中元素取出的顺序,和你定义时元素顺序并不能保证一致。
- 集合对象支持合集、交集、差集等数学运算。
- 既然有了列表、元组这些数据容器,python 设计者为什么还提供集合这样的数据类型呢?
- 在项目中,我们可能有这样的需求:需要记录一些数据,而这些数据必须保证是不重复的,而且数据的顺序并没有要求,就可以考虑使用集合。
- 回顾:列表、元组的元素是可以重复,而且有序。
集合的定义
- 创建一个集合,只要用逗号分隔不同的数据项,并使用{}括起来即可。
set_a = {100, 200, 300, 400, 500}
basket = {"apple", "orange", "pear", "banana"}
print(f"set_a = {set_a}, basket = {basket}")
print(f"set_a类型 = {type(set_a)}")
print(f"basket类型 = {type(basket)}")
注意事项和使用细节
- 集合是由不重复元素组成的无序容器。
# 不重复元素组成,可以理解成自动去重
basket = {"apple", "orange", "apple", "pear", "orange", "banana"}
print(f"basket: {basket}")# 无序,也就是你定义元素的顺序和取出的顺序不能保证一致
# 集合底层会按照自己的一套算法来存储和取数据,所以每次取出顺序是不变的
set_a = {100, 200, 300, 400, 500}
print(f"set_a: {set_a}")
print(f"set_a: {set_a}")
print(f"set_a: {set_a}")
- 集合不支持索引。
set_a = {100, 200, 300, 400, 500}
# print(set_a[0]) # TypeError: 'set' object is not subscriptable
- 既然集合不支持索引,所以对集合进行遍历不支持 while,只支持 for。
basket = {"apple", "orange", "apple", "pear", "orange", "banana"}
for ele in basket:print(ele)
- 创建空集合只能用
set(),不能用{},{}创建的是空字典。
set_b = {} # 定义空集合不对,这是空字典
set_c = set() # 创建空集合
print(f"set_b: {type(set_b)}")
print(f"set_c: {type(set_c)}")
集合常用操作
- 集合常用操作
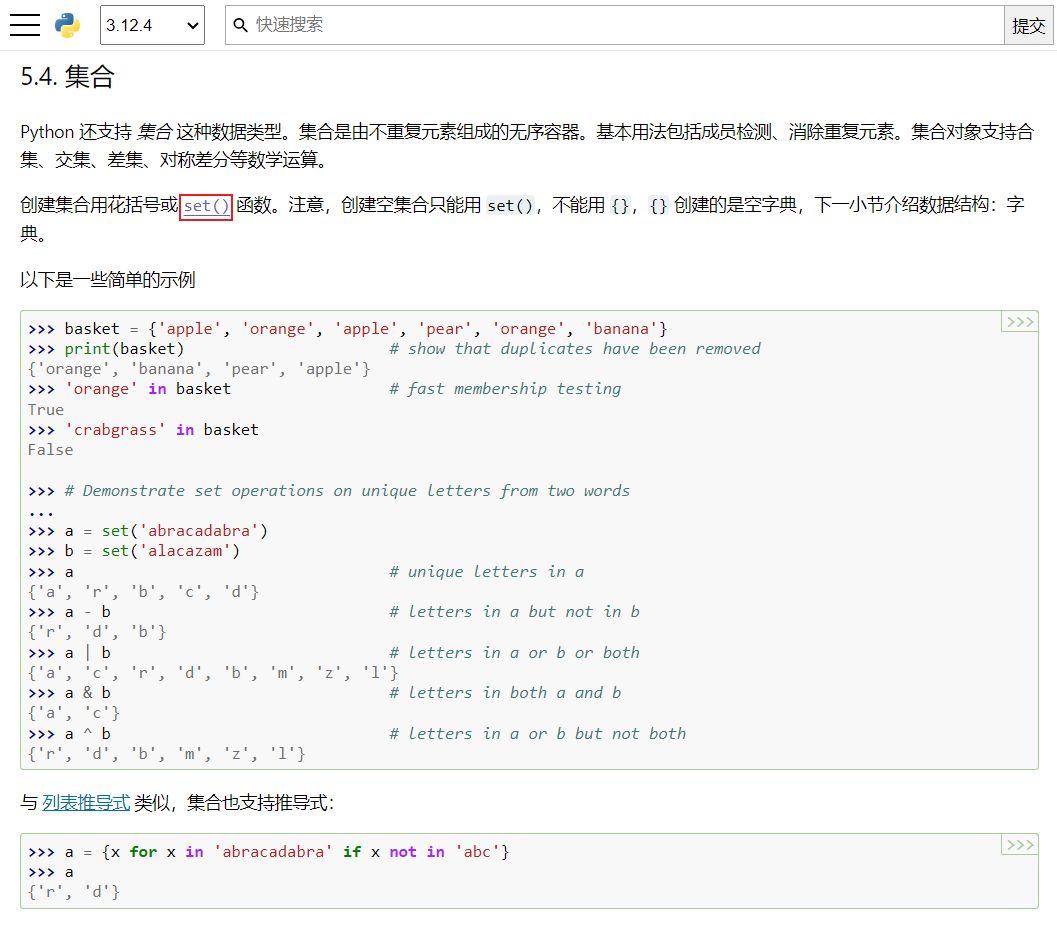
- 集合常用操作一览
| 序号 | 操作 |
|---|---|
| 1 | len(集合):集合元素个数 |
| 2 | x in s:检测 x 是否为 s 中的成员 |
| 3 | add(elem):将元素 elem 添加到集合中 |
| 4 | remove(elem):从集合中移除元素 elem。如果 elem 不存在于集合中则会引发 KeyError |
| 5 | pop():从集合中移除并返回任意一个元素。如果集合为空则会引发 KeyError |
| 6 | clear():从集合中移除所有元素 |
| 7 | union(*others) set | other | … :返回一个新集合,其中包含来自原集合以及 others 指定的所有集合中的元素 |
| 8 | intersection(*others) set & other & …:返回一个新集合,其中包含原集合以及 others 指定的所有集合中共有的元素 |
| 9 | difference(*others) set - other - … :返回一个新集合,其中包含原集合以及 others 指定的其他结合中不存在的元素 |
basket = {"apple", "orange", "apple", "pear", "orange", "banana"}
# len(集合):集合元素个数
print("basket元素个数:", len(basket))# x in s:检测x是否为s中的成员
print("apple" in basket)# add(elem):将元素elem添加到集合中
basket.add("grape")
print("basket:", basket)# remove(elem):从集合中移除元素elem。如果elem不存在于集合中则会引发KeyError
basket.remove("apple")
print("basket:", basket)
# basket.remove("aaa") # KeyError: 'aaa'# pop():从集合中移除并返回任意一个元素。如果集合为空则会引发KeyError
ele = basket.pop()
print("ele:", ele, "type:", type(ele))
print("basket:", basket)# clear():从集合中移除所有元素
basket = {"apple", "orange", "apple", "pear", "orange", "banana"}
print("basket:", basket)# union(*others) <br />set | other | ... :返回一个新集合,其中包含来自原集合以及 others 指定的所有集合中的元素
books = {"天龙八部", "笑傲江湖"}
books_2 = {"雪山飞狐", "神雕侠侣", "天龙八部"}
books_3 = books.union(books_2)
books_3 = books | books_2 # 等价于上一行代码
print("books_3:", books_3)# intersection(*others) <br />set & other & ...:返回一个新集合,其中包含原集合以及 others 指定的所有集合中共有的元素
books_4 = books.intersection(books_2)
books_4 = books & books_2 # 等价于上一行代码
print("books_4:", books_4)# difference(*others)<br />set - other - ... :返回一个新集合,其中包含原集合以及 others 指定的其他结合中不存在的元素
books_5 = books.difference(books_2)
books_5 = books - books_2
print("books_5:", books_5)
books_6 = books_2 - books
print("books_6:", books_6)
集合生成式
- 集合生成式就是“生成集合的公式“
- 基本语法:
{集合元素的表达式 for 自定义变量 in 可迭代对象}。
set1 = {ele * 2 for ele in range(1, 5)}
print("set1:", set1)set2 = {ele + ele for ele in "hsp"}
print("set2:", set2)
- 注意:集合生成式和列表生成式的区别就在于,集生成式使用
{},列表生成式使用[]。
练习
s_history = {"小明", "张三", "李四", "王五", "Lily", "Bob"}
s_politic = {"小明", "小花", "小红", "二狗"}
s_english = {"小明", "Lily", "Bob", "Davil", "李四"}# 求选课学生共有多少人
total = s_history.union(s_politic).union(s_english)
print("总人数:", len(total))# 求只选了第一个学科(history)的学生数量和学生姓名
total_history = s_history.difference(s_politic).difference(s_english)
print("数量:", len(total_history), "姓名:", total_history)# 求只选了一门学科的学生数量和学生姓名
total_politic = s_politic.difference(s_english).difference(s_history)
total_english = s_english.difference(s_history).difference(s_politic)
total_one = total_history.union(total_politic).union(total_english)
print("数量:", len(total_one), "姓名:", total_one)# 求选了三门学科的学生数量和学生姓名
total_three = s_history.intersection(s_politic).intersection(s_english)
print("数量:", len(total_three), "姓名:", total_three)
字典(dict)
基本介绍
- 字典(dict,完整单词是dictionary)也是一种常用的python数据类型,其他语言可能把字典称为联合内存或联合数组。
- 字典是一种映射类型,非常适合处理通过xx查询yy的需求,这里的xx我们称为Key(键/关键字),这里的yy我们称为Value(值),即Key—Value的映射关系。
字典的定义
- 字典的定义:创建一个字典,只要把逗号分隔的不同的元素,用{}括起来即可,存储的元素是一个个的
键值对。
dict_a = {key: value, key: value, key: value ...}
- 通过key取出对应的Value的语法:
字典名[key]。
dict_a [key]
tel = {"jack": 100, "bob": 200}print(f "tel:{tel}, type(tel):{type(tel)}")
print("jack 的 tel:", tel ['jack'])
注意事项和使用细节
- 字典的key(关键字)通常是字符串或数字,value可以是任意数据类型。
字典是以 键 进行索引的,键可以是任何不可变类型;字符串和数字总是可以作为键。 如果一个元组只包含字符串、数字或元组则也可以作为键;如果一个元组直接或间接地包含了任何可变对象,则不能作为键。 列表不能作为键,因为列表可以使用索引赋值、切片赋值或者
append()和extend()等方法进行原地修改列表。
dict_a = {"jack": [100, 200, 300],"mary": (10, 20, "hello"),"nono": {"apple", "pear"},"smith": "计算机老师","周星驰": {"性别": "男","age": 18,"地址": "香港"},"key1": 100,"key2": 9.8,"key3": True
}
print(f "dict_a = {dict_a} type(dict_a) = {type(dict_a)}")
- 字典不支持索引,会报KeyError。
print(dict_a [0]) # KeyError: 0
- 既然字典不支持索引,所以对字典进行遍历不支持while,只支持for,注意直接对字典进行遍历,遍历得到的是key。
dict_b = {"one": 1, "two": 2, "three": 3}
# 遍历方式 1:依次取出 key,再通过 dict [key] 取出对应的 value
for key in dict_b:print(f "key: {key}, value: {dict_b [key]}")# 遍历方式 2:依次取出 value
for value in dict_b.values():print(f "value: {value}")# 遍历方式 3:依次取出 key-value
for key, value in dict_b.items():print(f "key: {key}, value: {value}")
- 创建空字典可以通过
{},或者dict()。
dict_c = {}
dict_d = dict()
print(f "dict_c = {dict_c} dict_c.type = {type(dict_c)}")
print(f "dict_d = {dict_d} dict_d.type = {type(dict_d)}")
- 字典的key必须是唯一的,如果你指定了多个相同的key,后面的键值对会覆盖前面的。
dict_e = {"one": 1, "two": 2, "three": 3, "two": 4}
print(f "dict_e = {dict_e} dict_e.type = {type(dict_e)}")
字典常用操作
- 字典常用操作
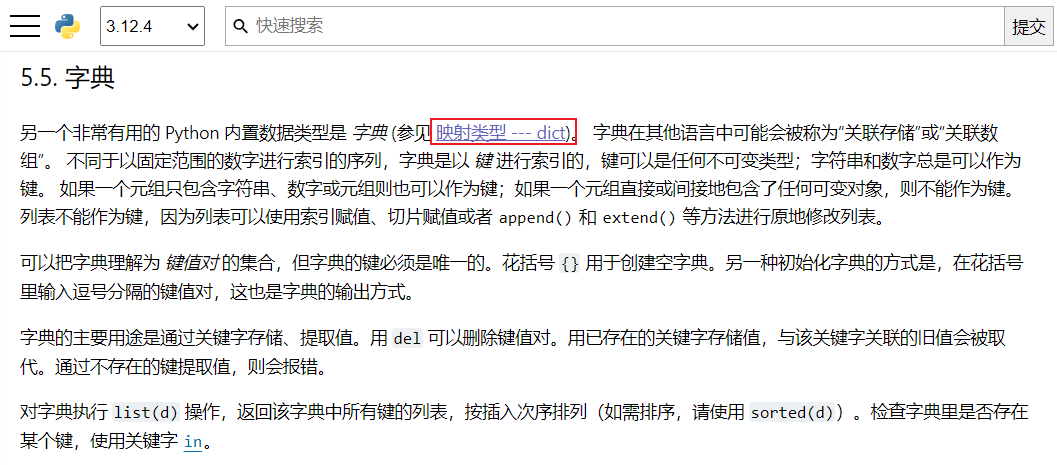
- 常用操作一览
| 序号 | 操作 |
|---|---|
| 1 | len(d):返回字典d中的项数 |
| 2 | d[key]:返回d中以key为键的项。如果映射中不存在key则会引发KeyError |
| 3 | d[key] = value:将d[key]设为value,如果key已经存在,则是修改value,如果key没有存在,则是增加key-value |
| 4 | del d[key]:将d[key]从d中移除。如果映射中不存在key,则会引发KeyError |
| 5 | pop(key[, default]):如果key存在于字典中则将其移除并返回其值,否则返回default。如果default未给出且key不存在于字典中,则会引发KeyError |
| 6 | keys():返回字典所有的key |
| 7 | key in d:如果d中存在键key则返回True,否则返回False |
| 8 | clear():移除字典中的所有元素 |
dict_a = {"one": 1, "two": 2, "three": 3}# len(d):返回字典 d 中的项数
print(f "dict_a 元素个数:{len(dict_a)}")# d [key]:返回 d 中以 key 为键的项。如果映射中不存在 key 则会引发 KeyError
print(f "key 为 three 对应的 value:{dict_a ["three"]}")
# print(f "key 为 four 对应的 value:{dict_a ["four"]}") # KeyError: 'four'# d [key] = value:将 d [key] 设为 value,如果 key 已经存在,则是修改 value,如果 key 没有存在,则是增加 key-value
dict_a ["one"] = "第一"
print(f "dict_a: {dict_a}")
dict_a ["four"] = 4
print(f "dict_a: {dict_a}")# del d [key]:将 d [key] 从 d 中移除。如果映射中不存在 key,则会引发 KeyError
del dict_a ["four"]
print(f "dict_a: {dict_a}")
# del dict_a ["five"] # KeyError: 'five'# pop(key [, default]):如果 key 存在于字典中则将其移除并返回其值,否则返回 default。如果 default 未给出且 key 不存在于字典中,则会引发 KeyError
val = dict_a.pop("one")
print(f "val: {val}")
print(f "dict_a: {dict_a}")
# val2 = dict_a.pop("four") # KeyError: 'four'
val = dict_a.pop("four", "哈哈")
print(f "val: {val}")
print(f "dict_a: {dict_a}")# keys():返回字典所有的 key
dict_a_keys = dict_a.keys()
print(f "dict_a_keys: {dict_a_keys} type: {type(dict_a_keys)}")
for k in dict_a_keys:print(f "k: {k}")# key in d:如果 d 中存在键 key 则返回 True,否则返回 False
print("two" in dict_a)# clear():移除字典中的所有元素
dict_a.clear()
print(f "dict_a: {dict_a}")
字典生成式
- 内置函数zip()
- zip()可以将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,返回由这些元组组成的列表。
- 字典生成式基本语法
{字典 key 的表达式: 字典 value 的表达式 for 表示 key 的变量, 表示 value 的变量 in zip(可迭代对象, 可迭代对象)}
books = ["红楼梦", "三国演义", "西游记", "水浒传"]
author = ["曹雪芹", "罗贯中", "吴承恩", "施耐庵"]
dict_book = {book: author for book, author in zip(books, author)}
print(dict_book)str1 = "hsp"
dict_str1 = {k: v * 2 for k, v in zip(str1, str1)}
print(dict_str1)english_list = ["red", "black", "yellow", 'white']
chinese_list = ["红色", "黑色", "黄色", '白色']
dict_color = {chinese: english.upper() for chinese, english in zip(chinese_list, english_list)}
print(dict_color)
练习
# 一个公司有多个员工,请使用合适的数据类型保存员工信息(员工号、年龄、姓名、入职时间、薪水)
clerks = {"0001": {"age": 20,"name": "贾宝玉","entry_time": "2011-11-11","salary": 12000},"0002": {"age": 21,"name": "薛宝钗","entry_time": "2015-12-12","salary": 10000},"0010": {"age": 18,"name": "林黛玉","entry_time": "2018-10-10","salary": 20000}
}print(f "员工号为 0010 的信息为:姓名-{clerks ['0010']['name']} "f "年龄-{clerks ['0010']['age']} "f "入职时间-{clerks ['0010']['entry_time']} "f "薪水-{clerks ['0010']['salary']}")# 增加
clerks ['0020'] = {"age": 30,"name": "老韩","entry_time": "2020-08-10","salary": 6000
}
print("clerks:", clerks)# 删除
del clerks ['0001']
print("clerks:", clerks)# 修改
clerks ['0020']['name'] = '韩顺平'
clerks ['0020']['entry_time'] = '1999-10-10'
clerks ['0020']['salary'] += clerks ['0020']['salary'] * 0.1
print("clerks:", clerks)# 遍历
keys = clerks.keys()
for key in keys:clerks [key]['salary'] += clerks [key]['salary'] * 0.2
print("clerks:", clerks)# 格式化输出
for key in keys:print(f "员工号为{key}的员工信息如下 年龄:{clerks [key]['age']}"f "名字:{clerks [key]['name']}"f "入职时间:{clerks [key]['entry_time']}"f "薪水:{clerks [key]['salary']}")
print("-" * 60)
for key in keys:clerk_info = clerks [key]print(f "员工号为{key}的员工信息如下 年龄:{clerks [key]['age']}"f "名字:{clerk_info ['name']}"f "入职时间:{clerk_info ['entry_time']}"f "薪水:{clerk_info ['salary']}")
小结
数据容器特点比较
| 比较项 | 列表(list) | 元组(tuple) | 字符串(str) | 集合(set) | 字典(dict) |
|---|---|---|---|---|---|
| 是否支持多个元素 | Y | Y | Y | Y | Y |
| 元素类型 | 任意 | 任意 | 只支持字符 | 任意 | Key:通常是字符串或数字 Value:任意 |
| 是否支持元素重复 | Y | Y | Y | N | Key 不能重复 Value 可以重复 |
| 是否有序 | Y | Y | Y | N | 3.6 版本之前是无序的 3.6 版本之后开始支持元素有序 |
| 是否支持所有 | Y | Y | Y | N | N |
| 可修改性/可变性 | Y | N | N | Y | Y |
| 使用场景 | 可修改、可重复的多个数据 | 不可修改、可重复的多个数据 | 字符串 | 不可重复的多个数据 | 通过关键字查询对应数据的需求 |
| 定义符号 | [] | () | "" 或 '' | {} | {key: value} |
数据容器操作小结
- 通用序列操作。
大多数序列类型,包括可变类型和不可变类型都支持下表的操作。
| 运算 | 结果 |
|---|---|
| x in s | 如果 s 中的某项等于 x 则结果为 True,否则为 False |
| x not in s | 如果 s 中的某项等于 x 则结果为 False,否则为 True |
| s + t | s 与 t 相拼接 |
s*n 或 n*s | 相当于 s 与自身进行 n 次拼接 |
| s [i] | s 的第 i 项,起始为 0 |
| s [i: j] | s 从 i 到 j 的切片 |
| s [i: j: k] | s 从 i 到 j 步长为 k 的切片 |
| len(s) | s 的长度 |
| min(s) | s 的最小项 |
| max(s) | s 的最大项 |
| s.index(x [, i[, j]]) | x 在 s 中首次出现的索引号(索引号在 i 或其后且在 j 之前) |
| s.count(x) | x 在 s 中出现的总次数 |
- 通用转换操作一览。
| 序号 | 操作 |
|---|---|
| 1 | list([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象, 将指定的容器转成列表 |
| 2 | str(容器):将制定的容器转为字符串 |
| 3 | tuple([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象, 将指定的容器转成元组 |
| 4 | set([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象, 将指定的容器转成集合 |
str_a = "hello"
list_a = ["jack", "tom", "mary"]
tuple_a = ("hsp", "tim")
set_a = {"red", "green", "blue"}
dict_a = {"0001": "小倩", "0002": "黑山老妖"}
# list([iterable]):iterable可以是序列、支持迭代的容器或其他可迭代对象,<br />将指定的容器转成列表
print(list(str_a))
print(list(tuple_a))
print(list(set_a))
print(list(dict_a))
print("-" * 60)# str(容器):将制定的容器转为字符串
print(str(list_a))
print(str(tuple_a))
print(str(set_a))
print(str(dict_a))
print("-" * 60)# tuple([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象,<br />将指定的容器转成元组
print(tuple(str_a))
print(tuple(list_a))
print(tuple(set_a))
print(tuple(dict_a))
print("-" * 60)# set([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象,<br />将指定的容器转成集合
print(set(str_a))
print(set(list_a))
print(set(tuple_a))
print(set(dict_a))
- 其它操作说明:请参考官方文档
欢迎关注我的博客,如有疑问或建议,请随时留言讨论。