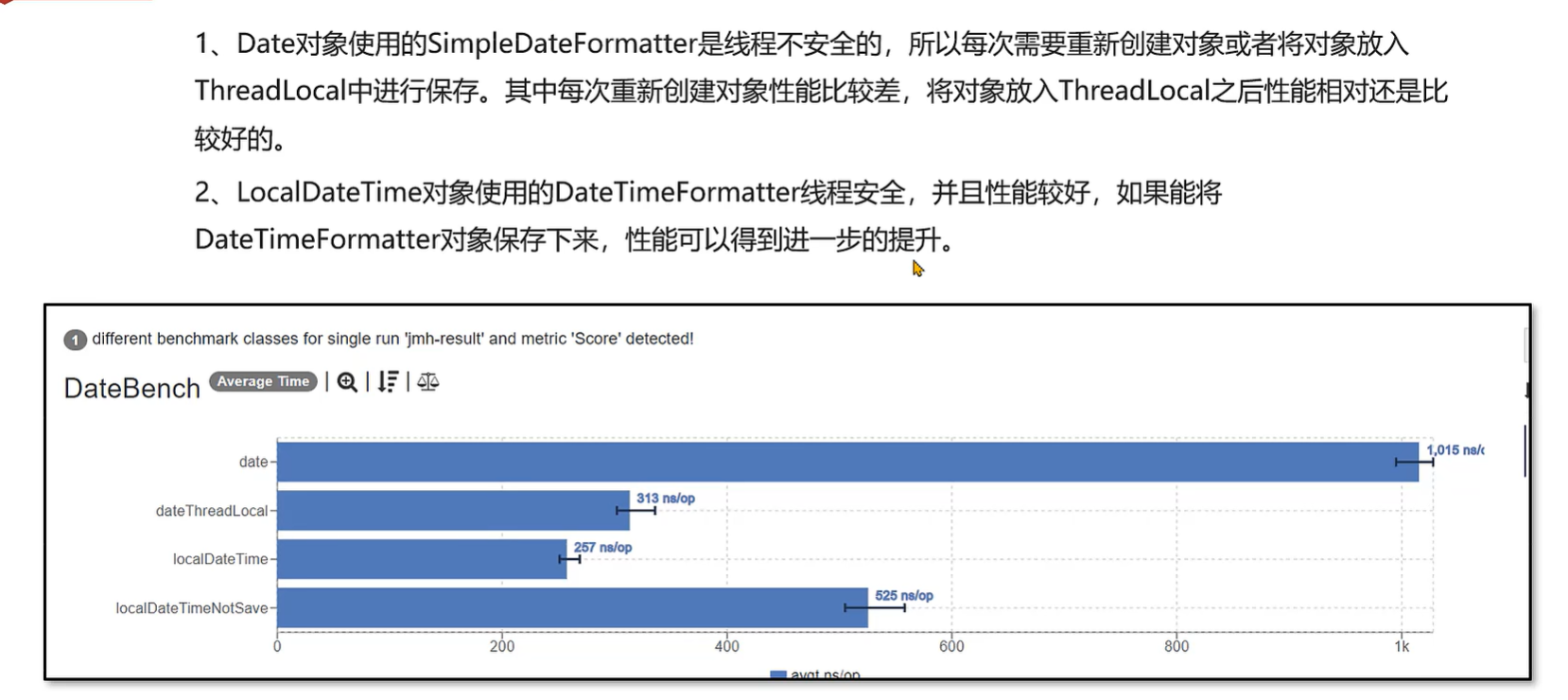
此笔记来至于 黑马程序员
内存调优
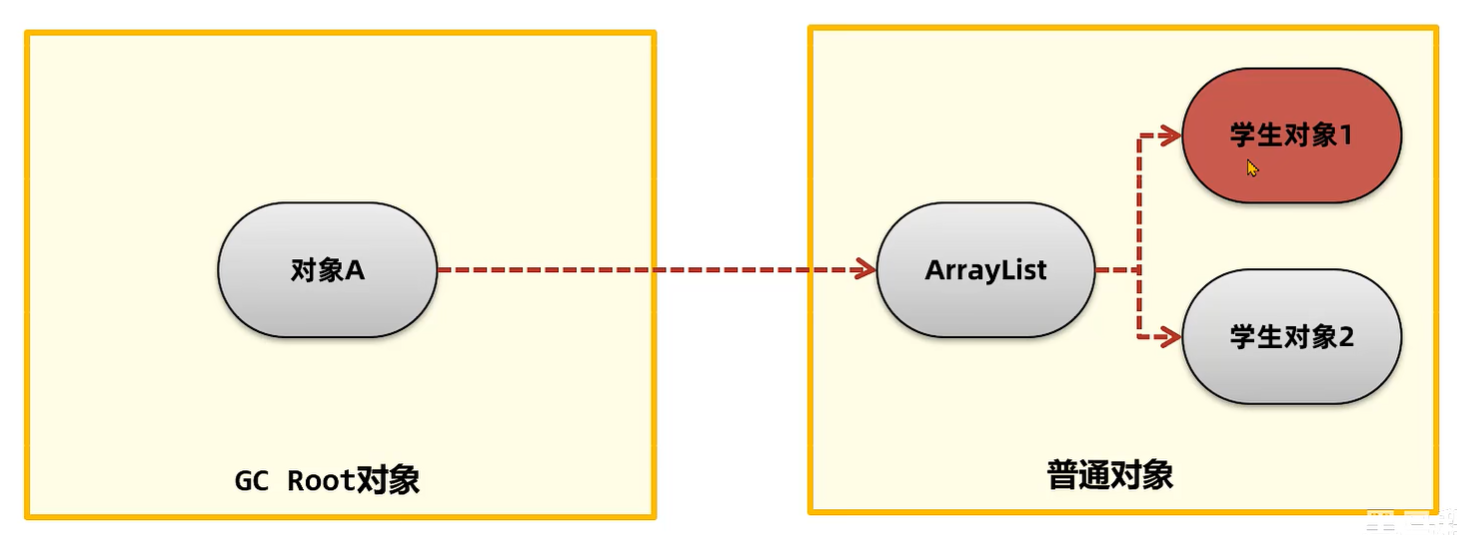
内存溢出和内存泄漏
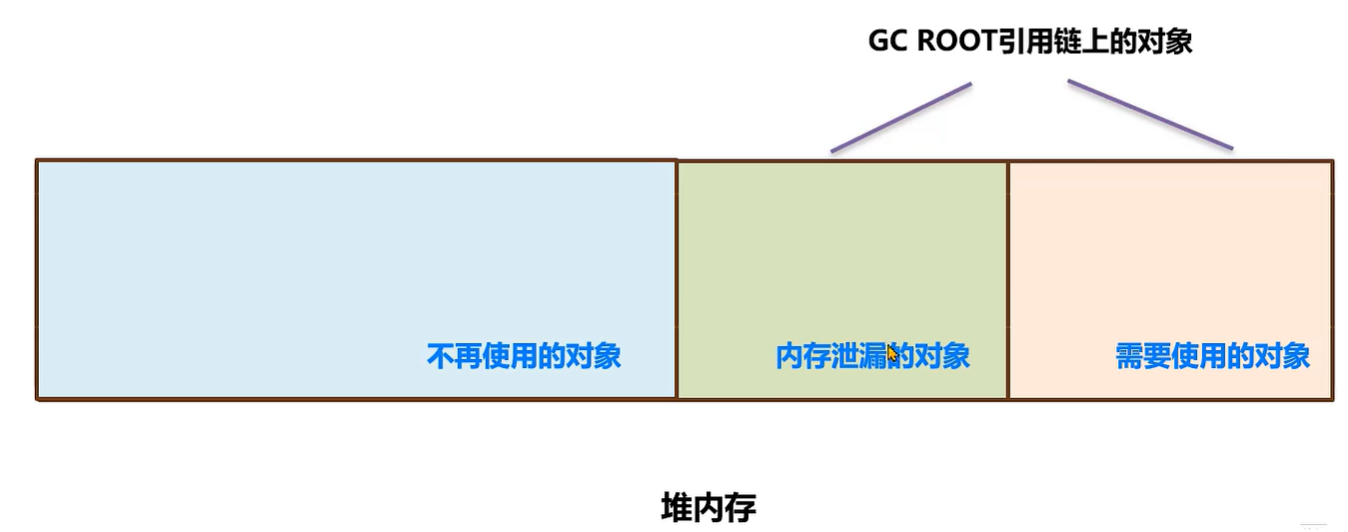
- 内存泄漏(memory leak):在Java中如果不再使用一个对象,但是该对象依然在 GC ROOT 的引用链上,这个对象就不会被垃圾回收器回收,这种情况就称之为内存泄漏。
- 内存泄漏绝大多数情况都是由堆内存泄漏引起的,所以后续没有特别说明则讨论的都是堆内存泄漏。
- 少量的内存泄漏可以容忍,但是如果发生持续的内存泄漏,就像滚雪球雪球越滚越大,不管有多大的内存迟早会被消耗完,最终导致的结果就是内存溢出。但是产生内存溢出并不是只有内存泄漏这一种原因
- 内存泄漏导致溢出的常见场景是大型的 Java后端应用 中,在处理用户的请求之后,没有及时将用户的数据删除。随着用户请求数量越来越多,内存泄漏的对象占满了堆内存最终导致内存溢出。
- 这种产生的内存溢出会直接导致用户请求无法处理,影响用户的正常使用。重启可以恢复应用使用,但是在运行一段时间之后依然会出现内存溢出
- 第二种常见场景是 分布式任务调度系统如 Elastic-job、Quartz 等进行任务调度时,被调度的 Java应用 在调度任务结束中出现了内存泄漏,最终导致多次调度之后内存溢出。
- 这种产生的内存溢出会导致应用执行下次的调度任务执行**。同样重启可以恢复应用使用,但是在调度执行一段时间之后依然会出现内存溢出。**
解决内存溢出的方法
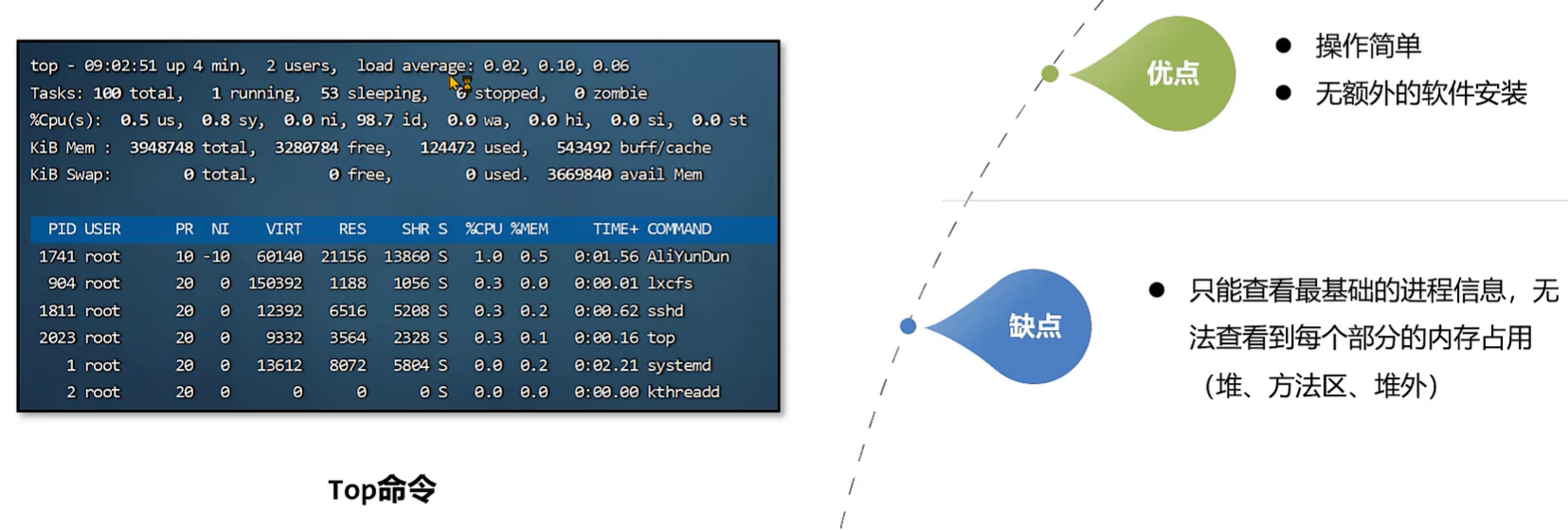
发现问题 - Top 命令
- top命令 是 linux 下用来查看系统信息的一个命令,它提供给我们去实时地去查看系统的资源,比如执行时的进程、线程和系统参数等信息。
- 进程使用的内存为 RES(常驻内存)- SHR(共享内存)
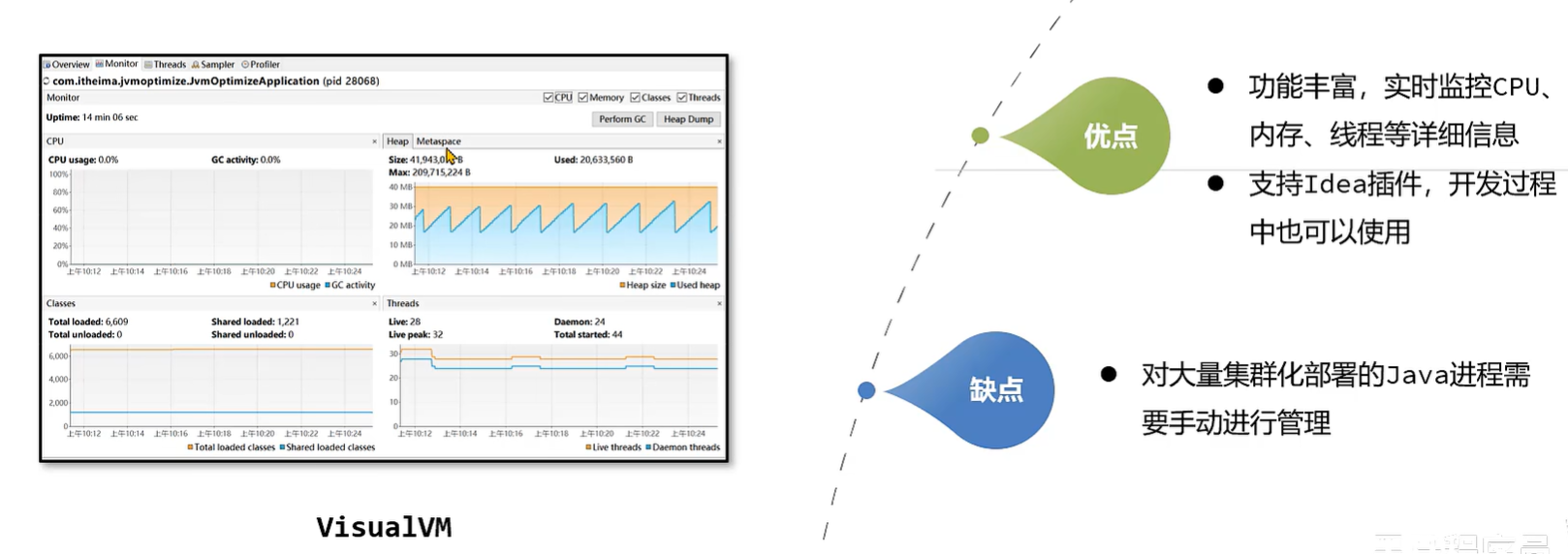
发现问题 - VisualVM
- VisualVM是多功能合一的 Java故障排除工具 并且他是一款 可视化工具,整合了 命令行JDK工具 和 轻量级分析功能,功能非常强大。
- 这款软件在 Oracle JDK 6~8 中发布,但是在 Oracle JDK 9 之后不在JDk安装目录下需要单独下载。
- 下载地址:https://visualvm.github.io/
云服务器配置

只能用于测试环境,因为会有 STW 影响用户体验
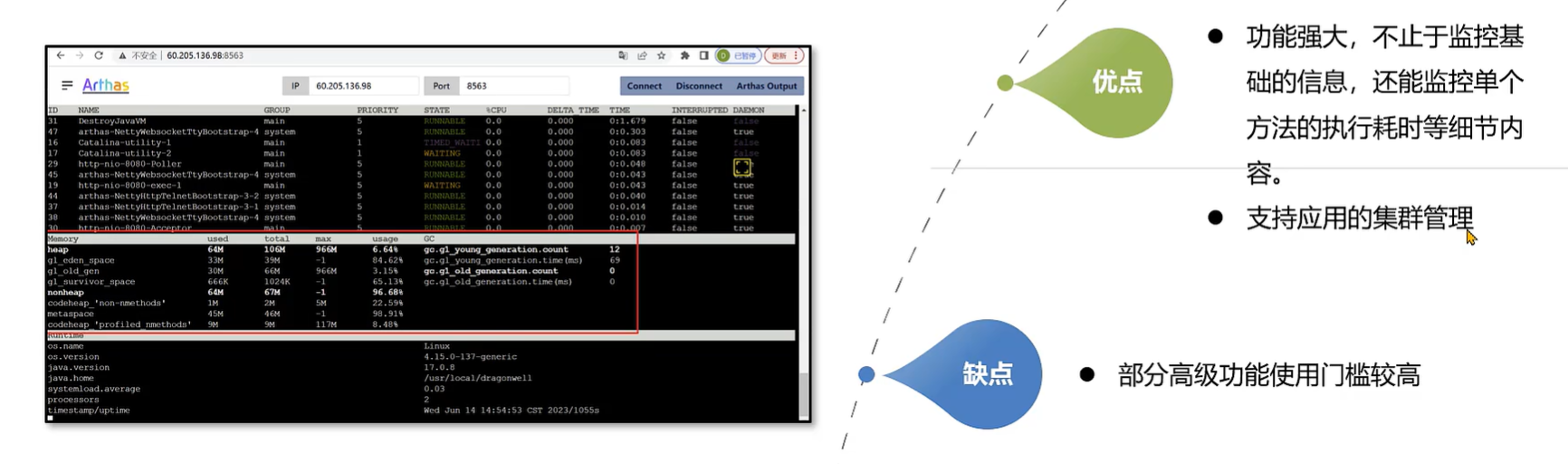
发现问题- Arthas
- Arthas 是一款线上监控诊断产品,通过全局视角实时查看 应用load、内存、gc、线程 的状态信息,**并能在不修改应用代码的情况下,对业务问题进行诊断,**包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。

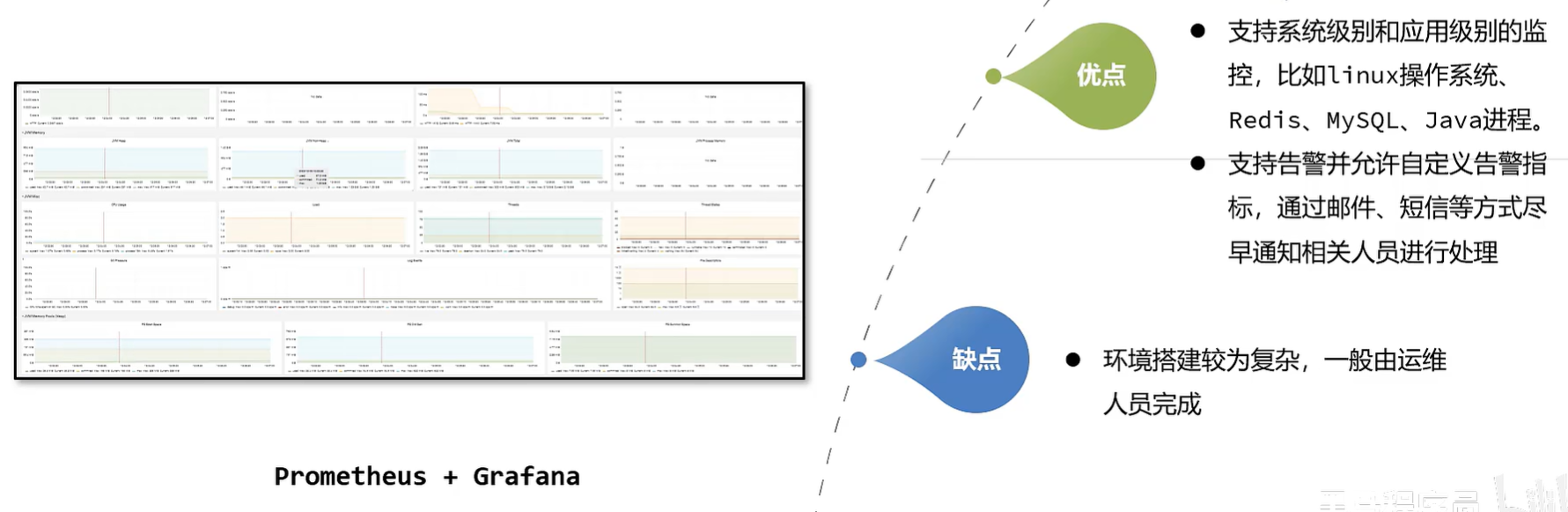
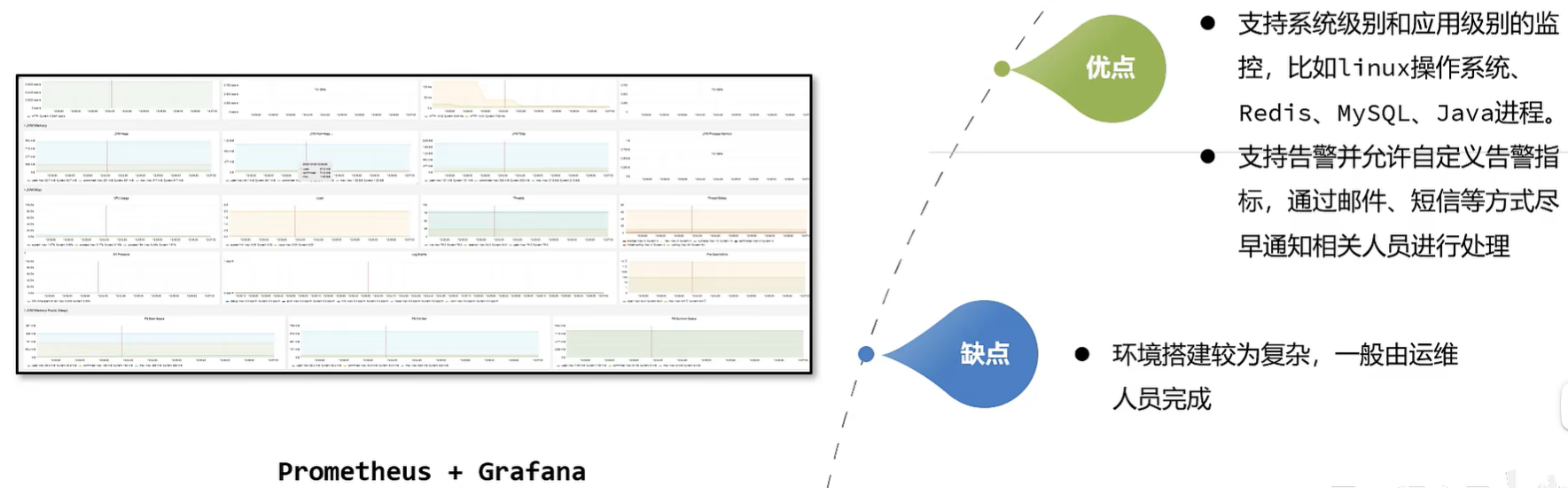
发现问题 - Prometheus + Grafana
- Prometheus + Grafana 是企业中运维常用的监控方案,其中 Prometheus 用来采集系统或者应用的相关数据,同时具备告警功能。Grafana 可以将 Prometheus 采集到的数据以可视化的方式进行展示。
- Java程序员 要学会如何读懂 Grafana 展示的 Java虚拟机 相关的参数。
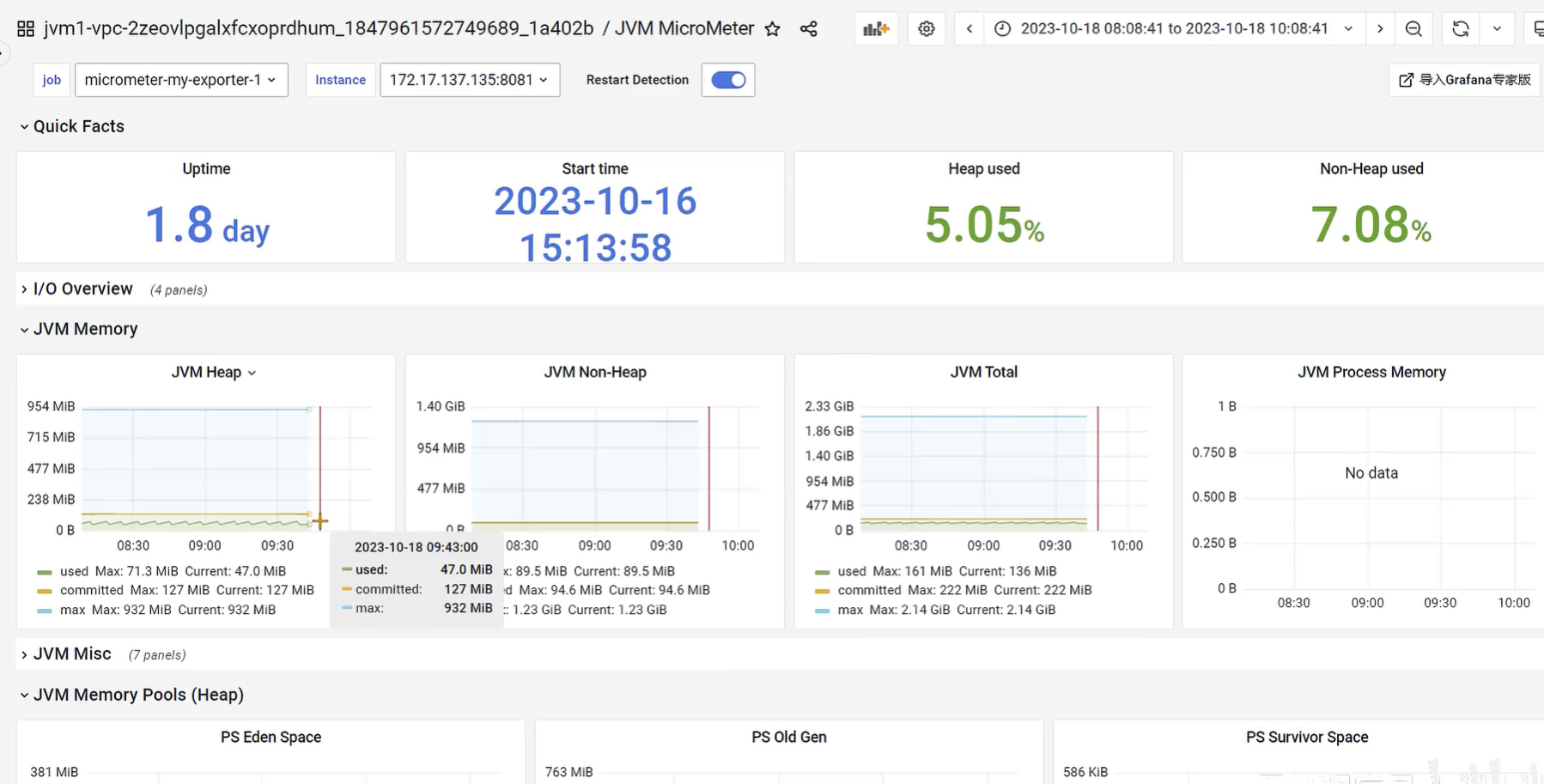
发现问题 - 堆内存状况的对比

产生内存溢出原因一:代码中的内存泄漏(压力测试)

equals() 和 hashcode() 导致的内存泄漏
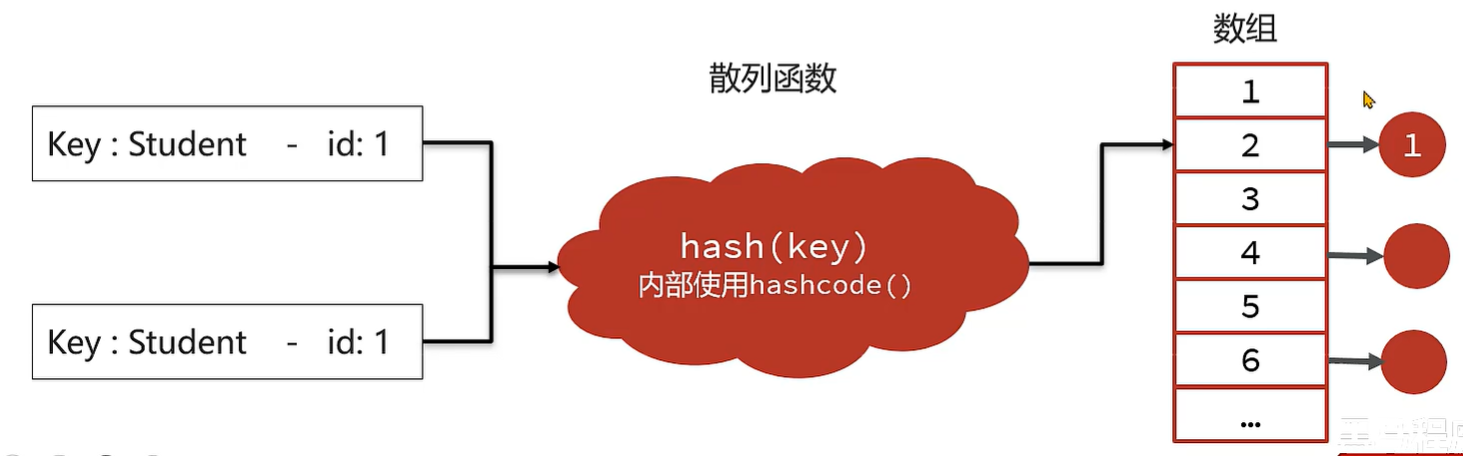
1、以 JDK8 为例,首先调用 hash方法 计算 key 的哈希值,hash方法 中会使用到 key的 hashcode方法。根据 hash方法 的结果决定存放的数组中位置。
2、如果没有元素,直接放入。如果有元素,先 判断key 是否相等,会用到 equals方法,如果 key相等,直接替换value;key不相等,走链表或者红黑树查找逻辑,其中也会使用equals比对是否相同。
1、hashCode 方法实现不正确,会导致相同 id的学生对象计算出来的 hash值 不同,可能会被分到不同的槽中。
2、equals 方法实现不正确,会 导致key在 比对时,即便学生对象的 id是相同的,也被认为是 不同的key。
3、长时间运行之后 HashMap中会 保存大量相同id的学生 数据。
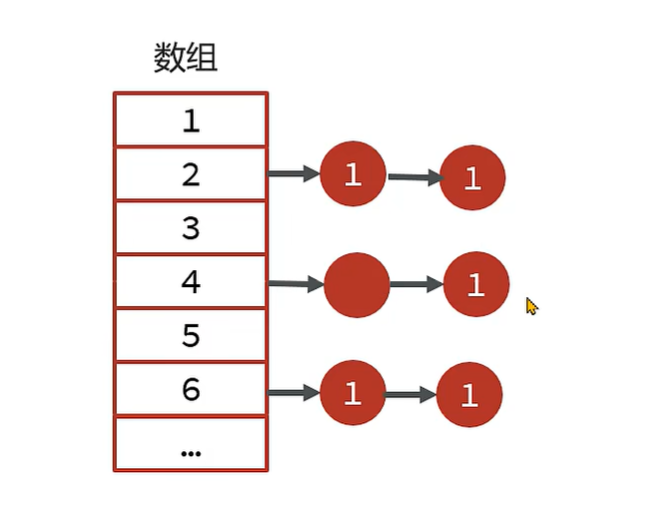
解决方案:
1、在定义新实体时,始终重写 equals() 和 hashCode() 方法。
2、重写时一定要确定使用了唯一标识去区分不同的对象,比如用户的id等。
3、hashmap 使用时尽量使用编号 id 等数据作为 key,不要将整个实体类对象作为 key存放。
案例2:内部类引用外部类
- 1、非静态的内部类默认会持有外部类,尽管代码上不再使用外部类,所以如果有地方引用了这个非静态内部类,会导致外部类也被引用,垃圾回收时无法回收这个外部类。
- 2、匿名内部类对象如果在非静态方法中被创建,会持有调用者对象,垃圾回收时无法回收调用者。
public class Outer {private byte[] bytes = new byte[1024 * 1024]; // 外部类持有数据private String name = "测试";class Inner { // 改为静态内部类就好了 static class Innerprivate String name;public Inner() {this.name = Outer.this.name;}}public static void main(String[] args) throws IOException, InterruptedException {System.in.read();int count = 0;ArrayList<Inner> inners = new ArrayList<>();while (true) {if (count++ % 100 == 0) {Thread.sleep(10);}inners.add(new Outer().new Inner());}}
}
1、这个案例中,使用内部类的原因是可以直接获取到外部类中的成员变量值,简化开发。如果不想持有外部类对象,应该使用静态内部类。
2、使用静态方法,可以避免匿名内部类持有调用者对象。
案例3:ThreadLocal 的使用

import java.util.concurrent.*;public class Demo5 {public static ThreadLocal<Object> threadLocal = new ThreadLocal<>():public static void main(String[] args) {ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(Integer.MAX_VALUE, Integer.MAX_VALUE,keepAliveTime:0,TimeUnit.DAYS, new SynchronousQueue<>());int count = 0;while (true) {System.out.println(++count);threadPlloExecutor.execute(() -> {threadPoolExecutor.set(new byte[1024 * 1024]);// threadLocal.remove(); 线程池一定要释放 threadPoolExecutor });}}
}
案例4:String 的 intern 方法

import java.util.ArrayList;
import java.util.List;public class Demo6_2 {public static void main(String[] args) {List<String> list = new ArrayList<String>();int i = 0;while (true) {// String.valueOf(i++).intern(); // JDK1.6 perm gen 不会溢出list.add(String.valueOf(i++).intern()); // 溢出}}
}
案例5:通过静态字段保存对象

import java.time.Duration;public class CaffineDemo {public static void main(String[] args) throws InterruptedException {Cache<Object, Object> build = Caffeine.newBuilder().expireAfterWrite(Duration.ofMillis(100)).build();int count = 0;while (true) {build.put(count++, new byte[1024 * 1024 * 10]);Thread.sleep(100L);}}
}

产生内存溢出原因二:并发请求问题
-
并发请求问题指的是用户通过发送请求 向 Java应用 获取数据,正常情况下 Java应用将数据返回之后,这部分数据就可以在内存中被释放掉。
-
并发请求问题指的是用户通过发送请求向 Java应用获取数据,正常情况下 Java应用 将数据返回之后,这部分数据就可以在内存中被释放掉。**但是由于用户的并发请求量有可能很大,同时处理数据的时间很长,导致大量的数据存在于内存中,最终超过了内存的上限,导致内存溢出。**这类问题的处理思路和内存泄漏类似,首先要定位到对象产生的根源。
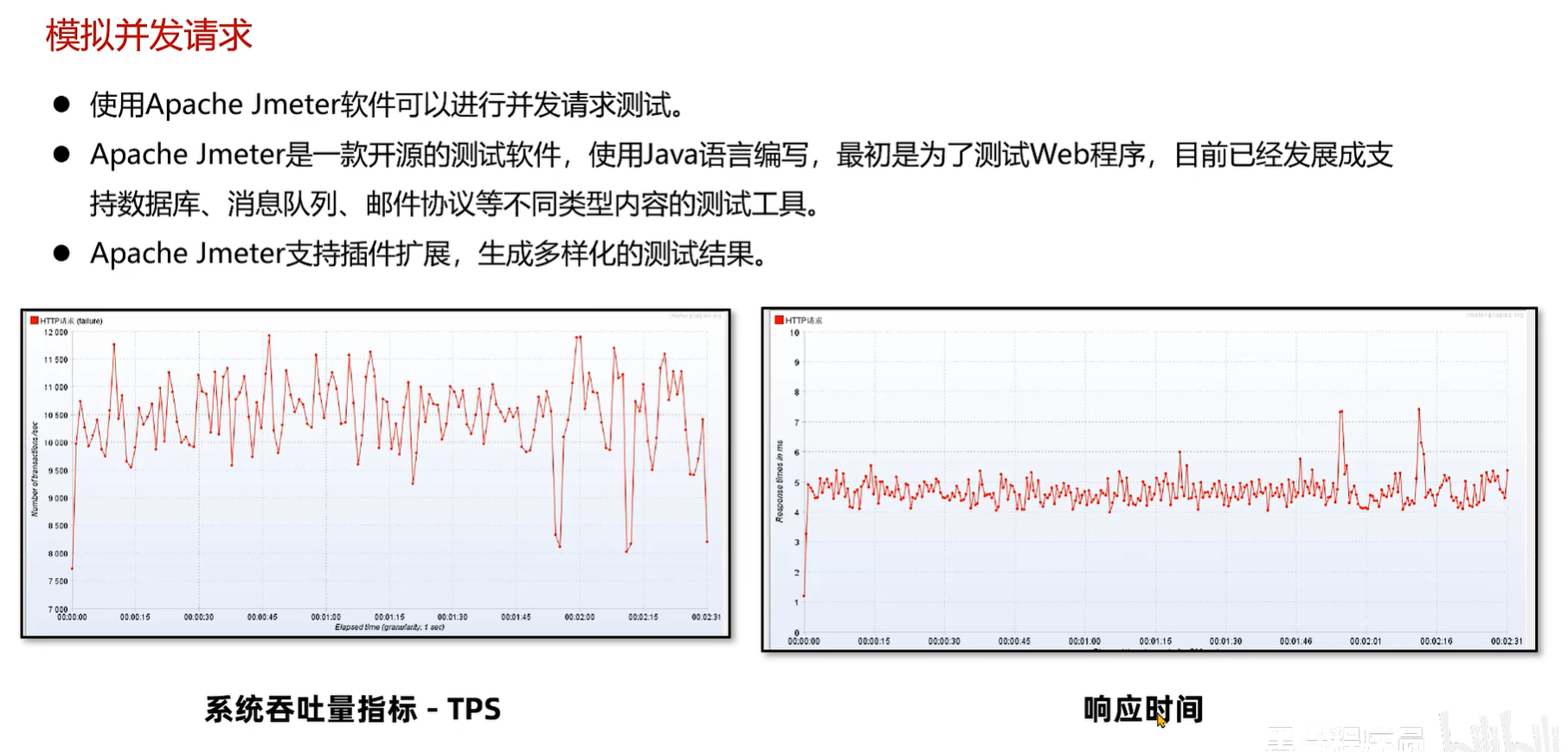
使用 Jmeter 进行并发测试,发现内存溢出问题

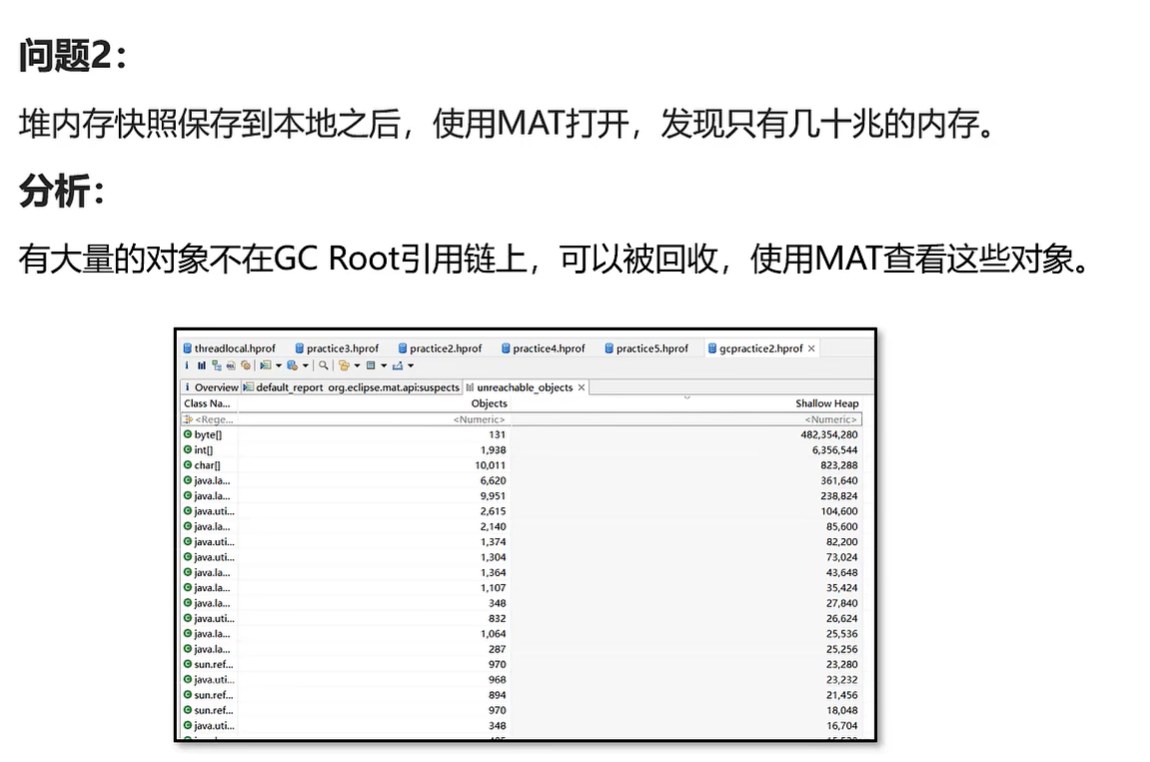
诊断-内存快照
-
当堆内存溢出时,需要在堆内存溢出时将整个堆内存保存下来,生成内存快照(HeapProfile)文件
-
使用 MAT打开 hprof文件,并选择内存泄漏检测功能,MAT 会自行根据内存快照中保存的数据分析内存泄源的根源。
-
生成内存快照的 Java虚拟机 参数:
-XX:+HeapDumpOnOutOfMemoryError:发生 OutOfMemoryError 错误时,自动生成 hprof 内存快照文件。
-XX:HeapDumpPath =:指定 hprof文件 的输出路径。
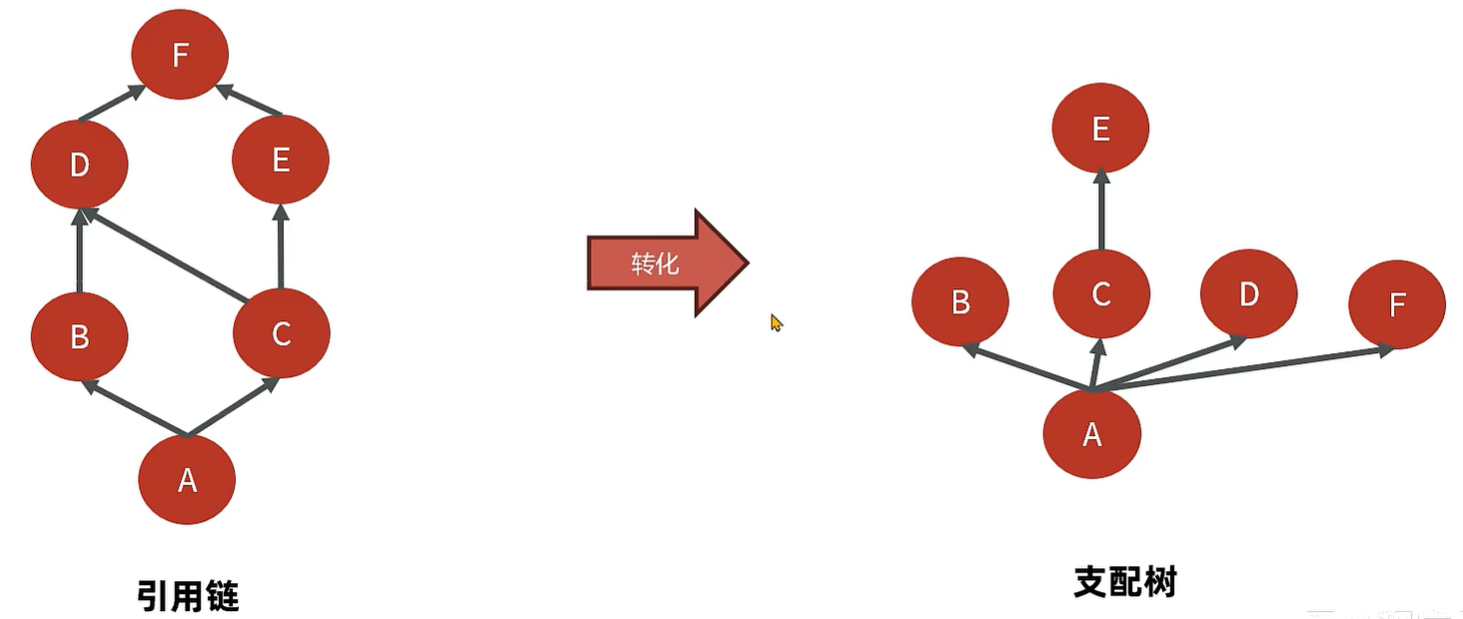
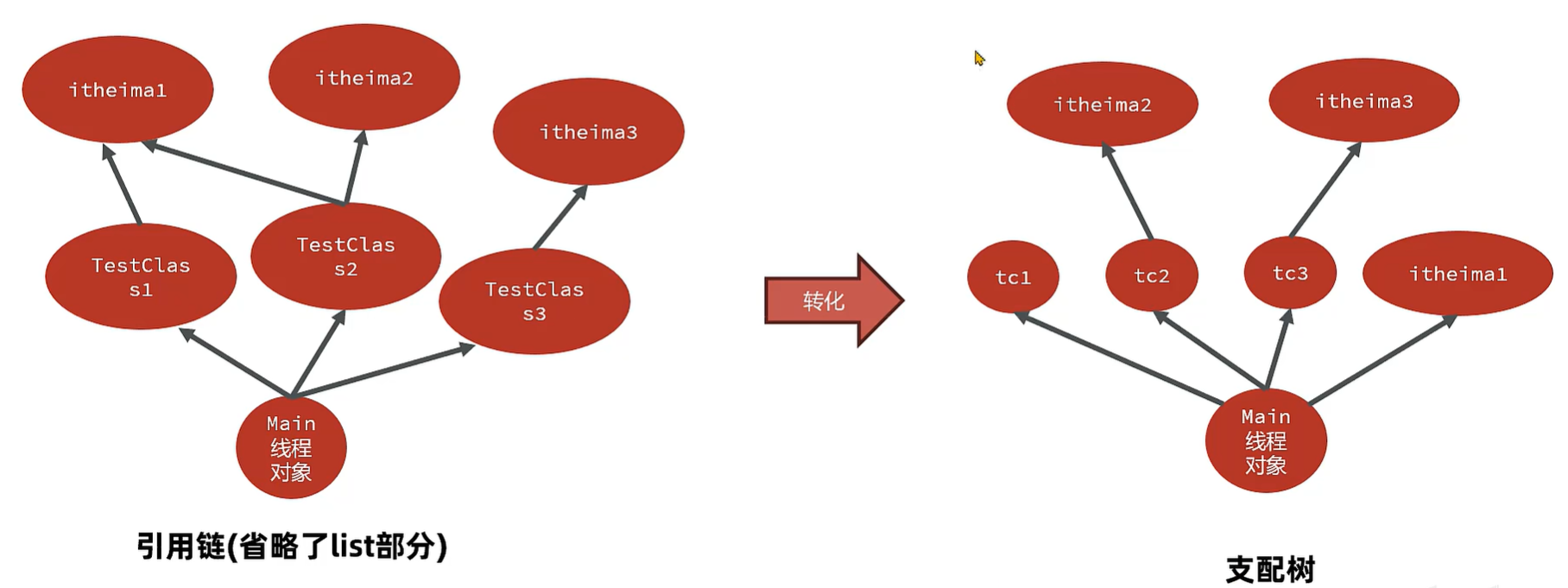
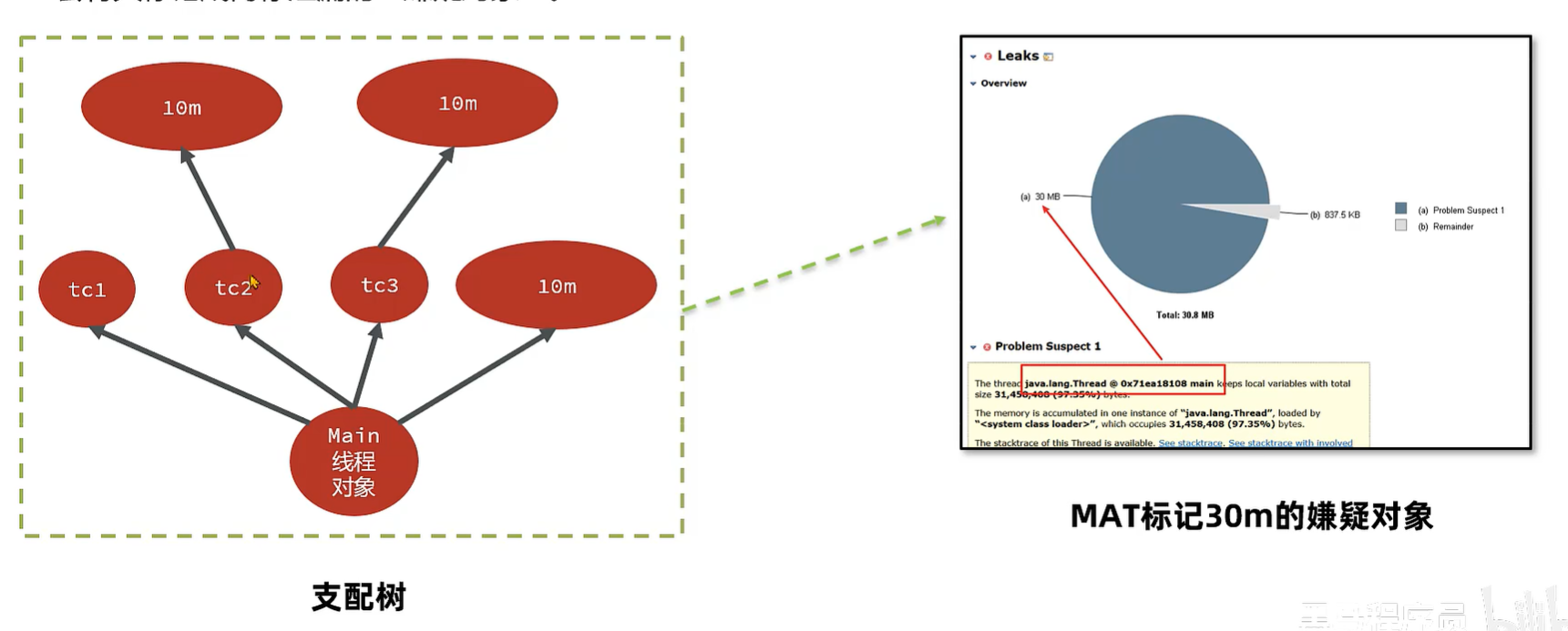
MAT 内存泄漏检测的原理-支配树
- MAT 提供了称为 **支配树(DominatorTree)**的对象图。支配树展示的是对象实例间的支配关系。在对象引用图中,所有指向对象B的路径都经过对象A,则认为 对象A 支配 对象B。
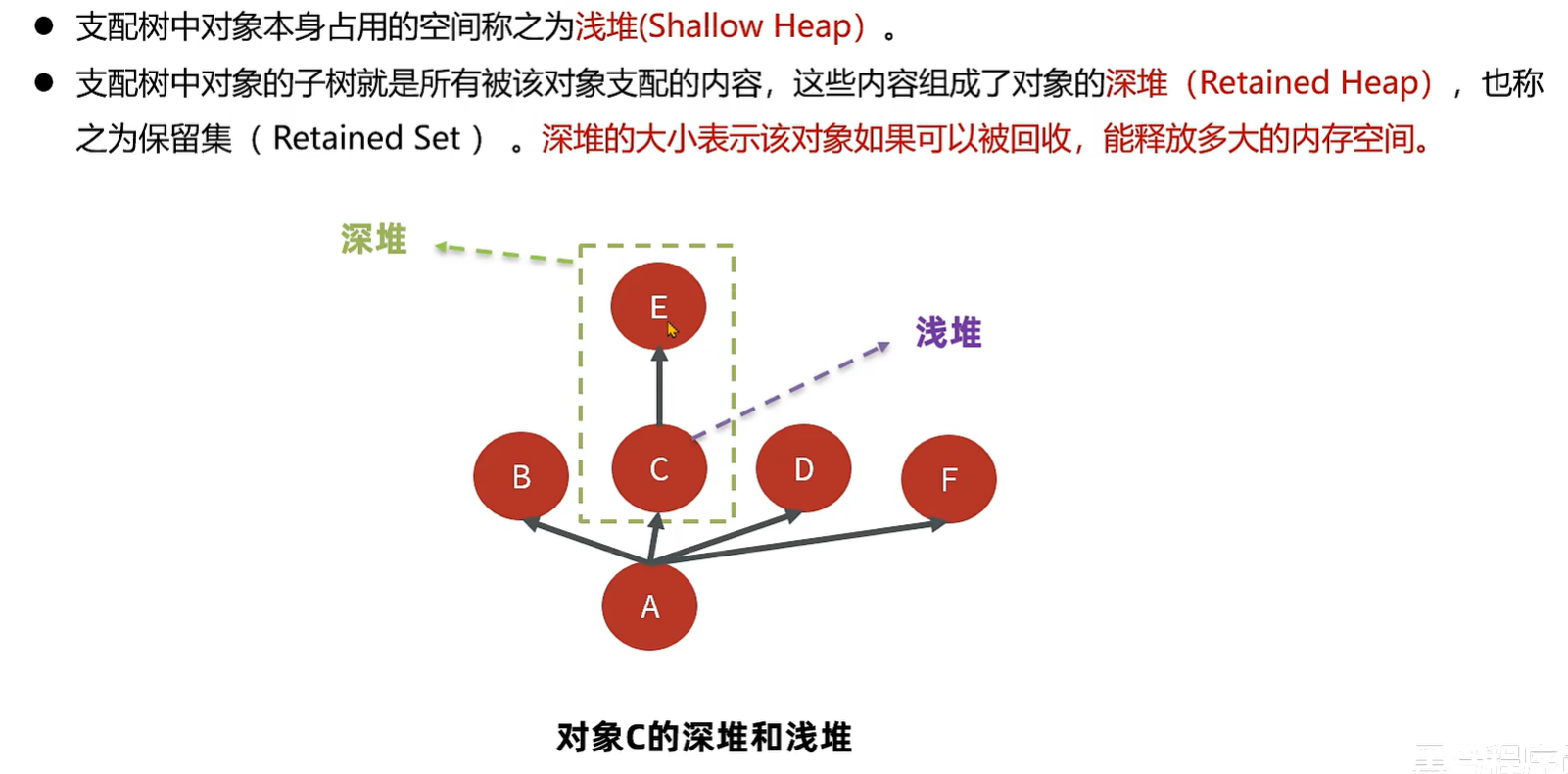
MAT 内存泄漏检测的原理-深堆和浅堆

// -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=D:/jvm/heapdemo.hprof
public class HeapDemo {public static void main(String[] args) {TestClass a1 = new TestClass();TestClass a2 = new TestClass();TestClass a3 = new TestClass();String s1 = "itheima1";String s2 = "itheima2";String s3 = "itheima3";a1.list.add(s1);a2.list.add(s1);a2.list.add(s2);a3.list.add(s3);// System.out.print(ClassLayout.parseClass(TestClass.class).toPrintable());s1 = null;s2 = null;s3 = null;System.gc();}
}
MAT 内存泄漏检测的原理
导出运行中系统的内存快照并进行分析

分析超大堆的内存快照
- 在程序员开发用的机器内存范围之内的快照文件,直接使用 MAT 打开分析即可。但是经常会遇到服务器上的程序占用的内存达到 10G以上,开发机无法正常打开此类内存快照,此时需要下载服务器操作系统对应的 MAT。 下载地址: https://eclipse.dev/mat/downloads.php
案例实战
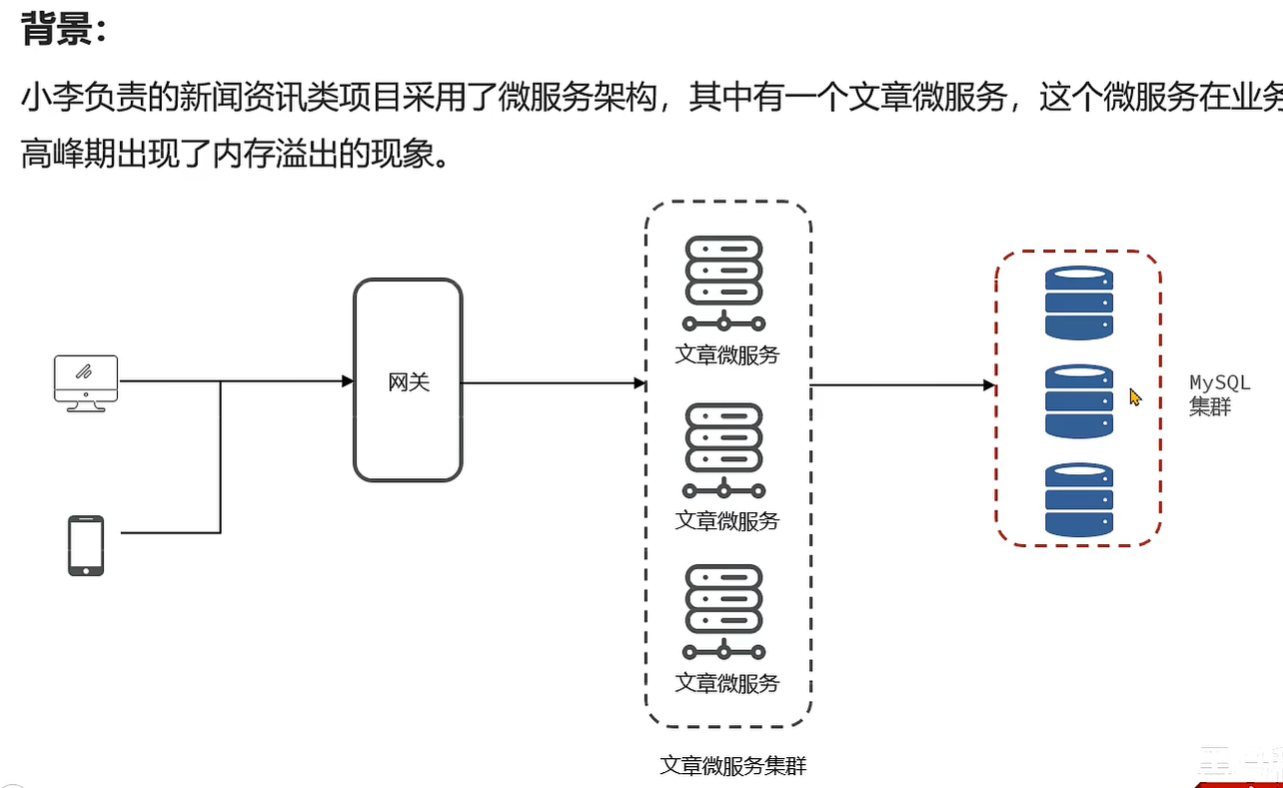
案例1-分页查询文章接口的内存溢出


案例2- Mybatis 导致的内存溢出

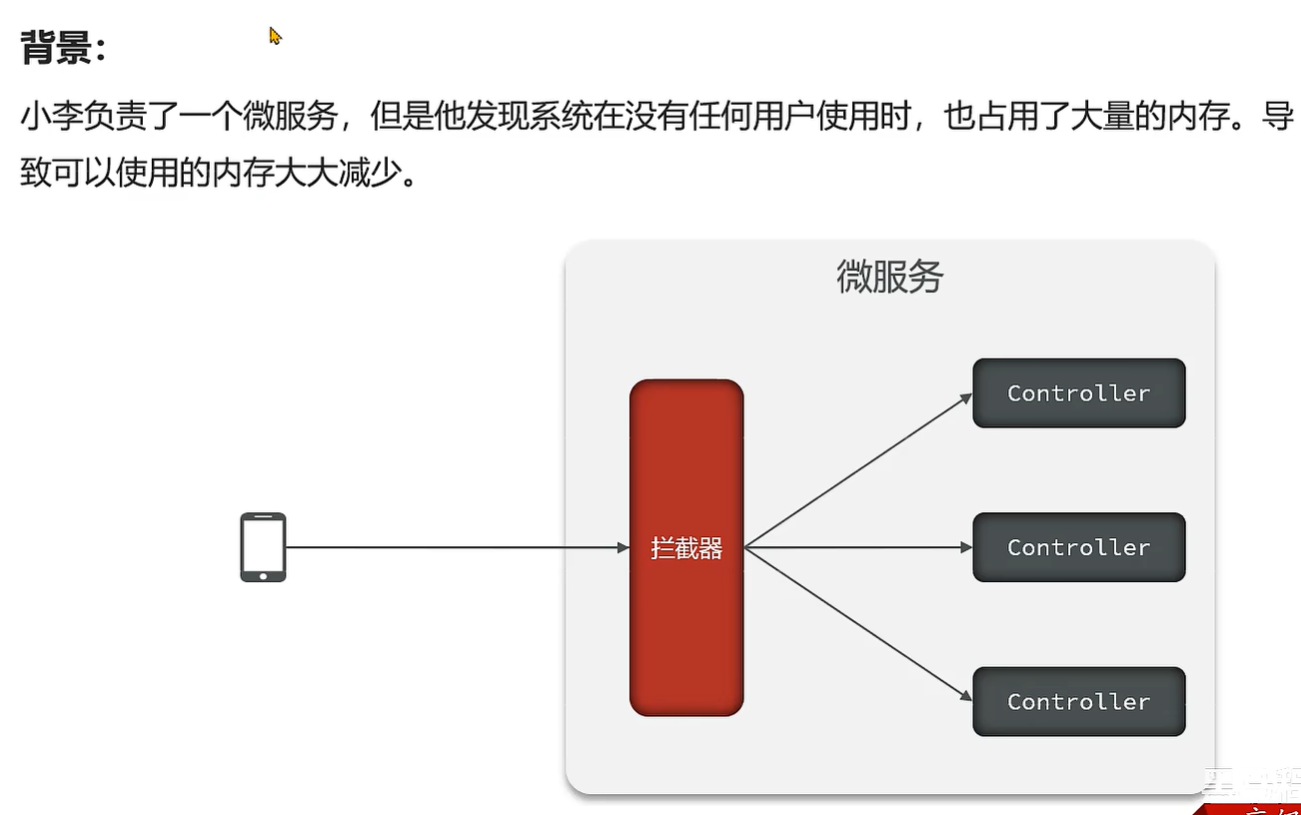
案例3 - 导出大文件内存溢出
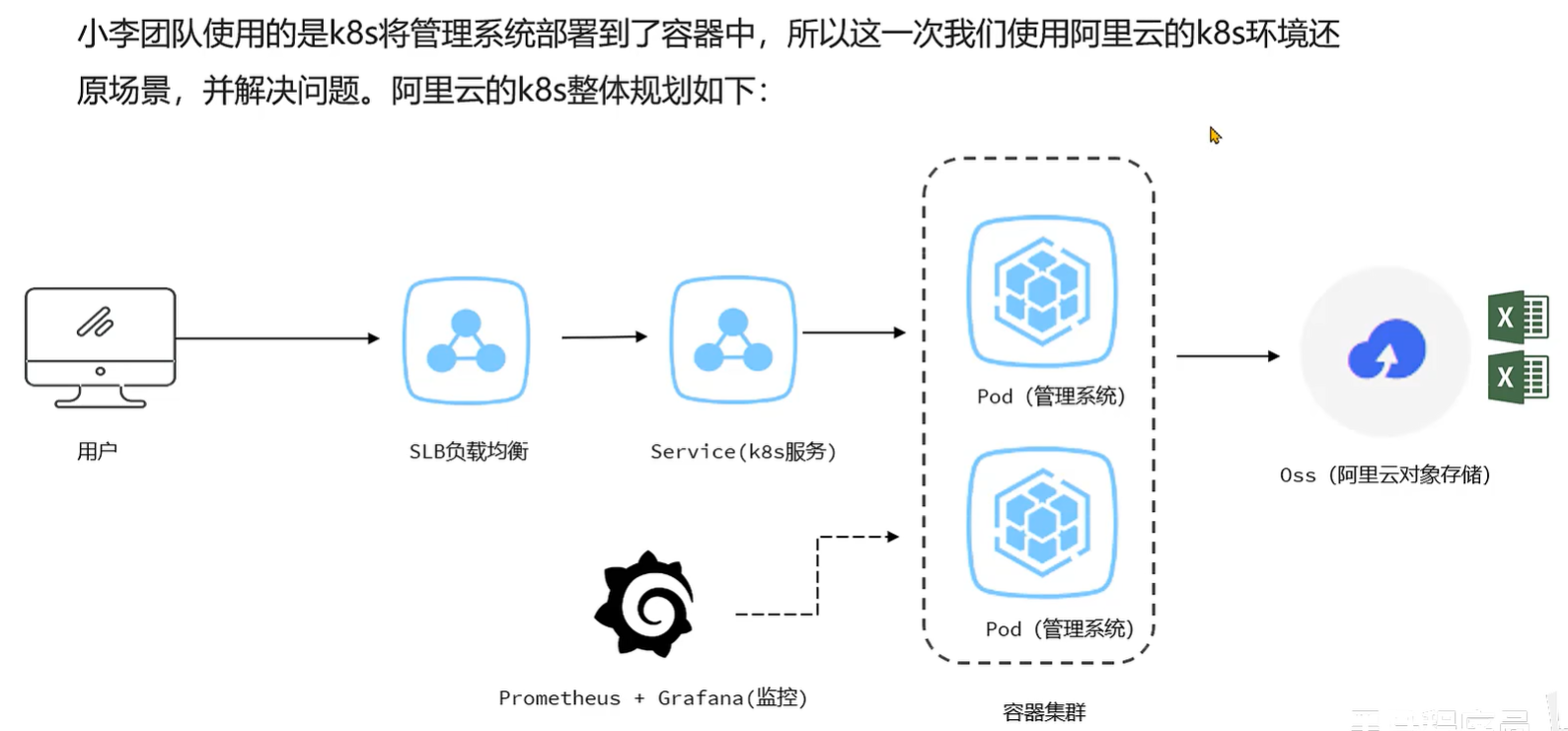

案例4- ThreadLocal 使用时占用大量内存

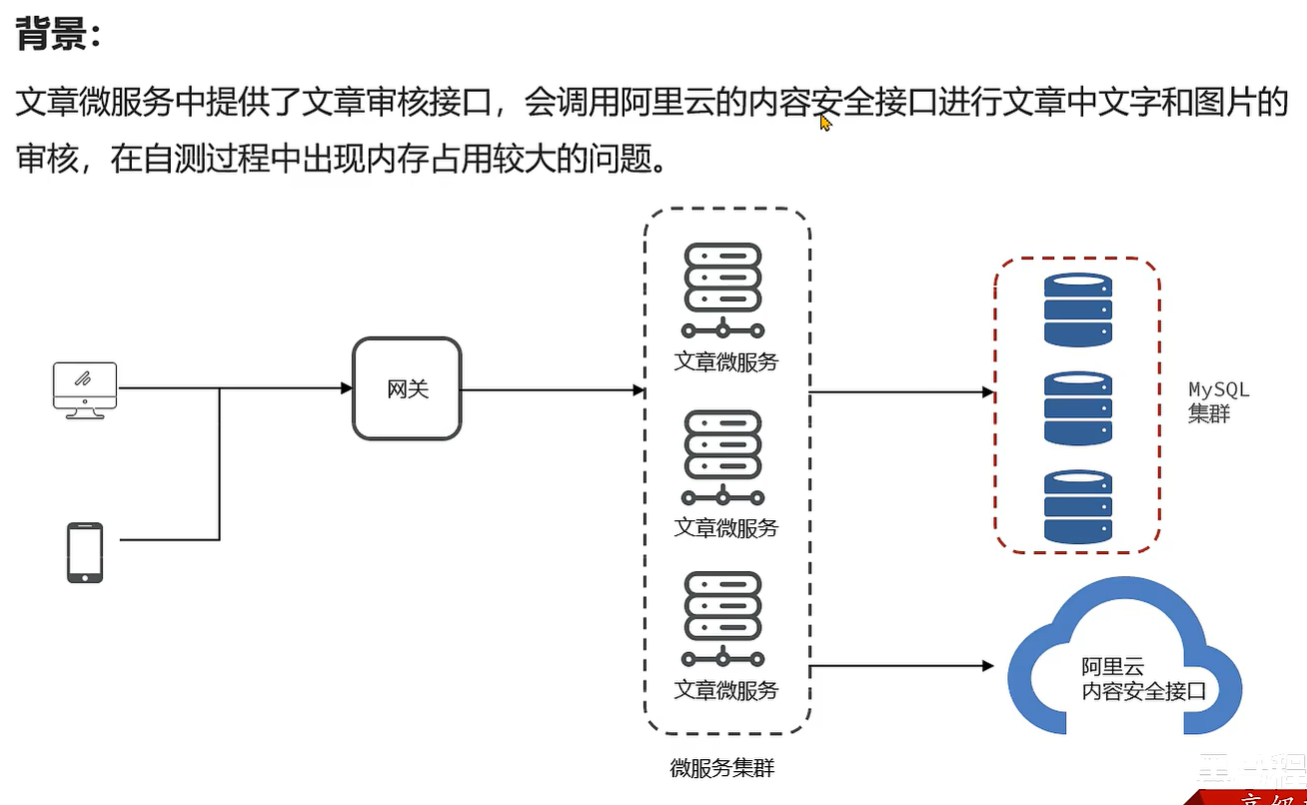
案例5-文章内容审核接口的内存问题
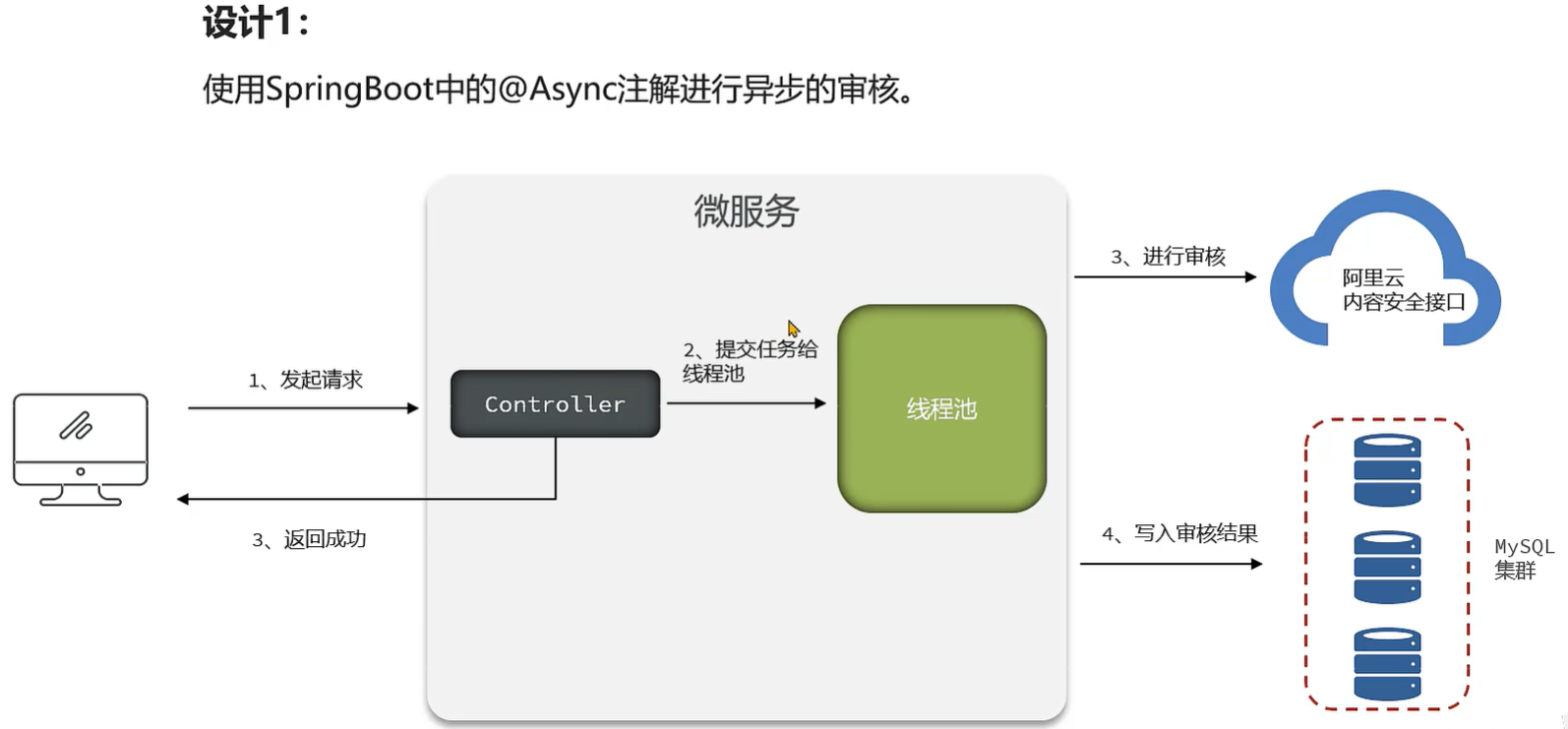
存在问题:
1、线程池参数设置不当,会导致大量线程的创建或者队列中保存大量的数据。
2、任务没有持久化,一旦走线程池的拒绝策略或者服务宕机、服务器掉电等情况很有可能会丢失任务。
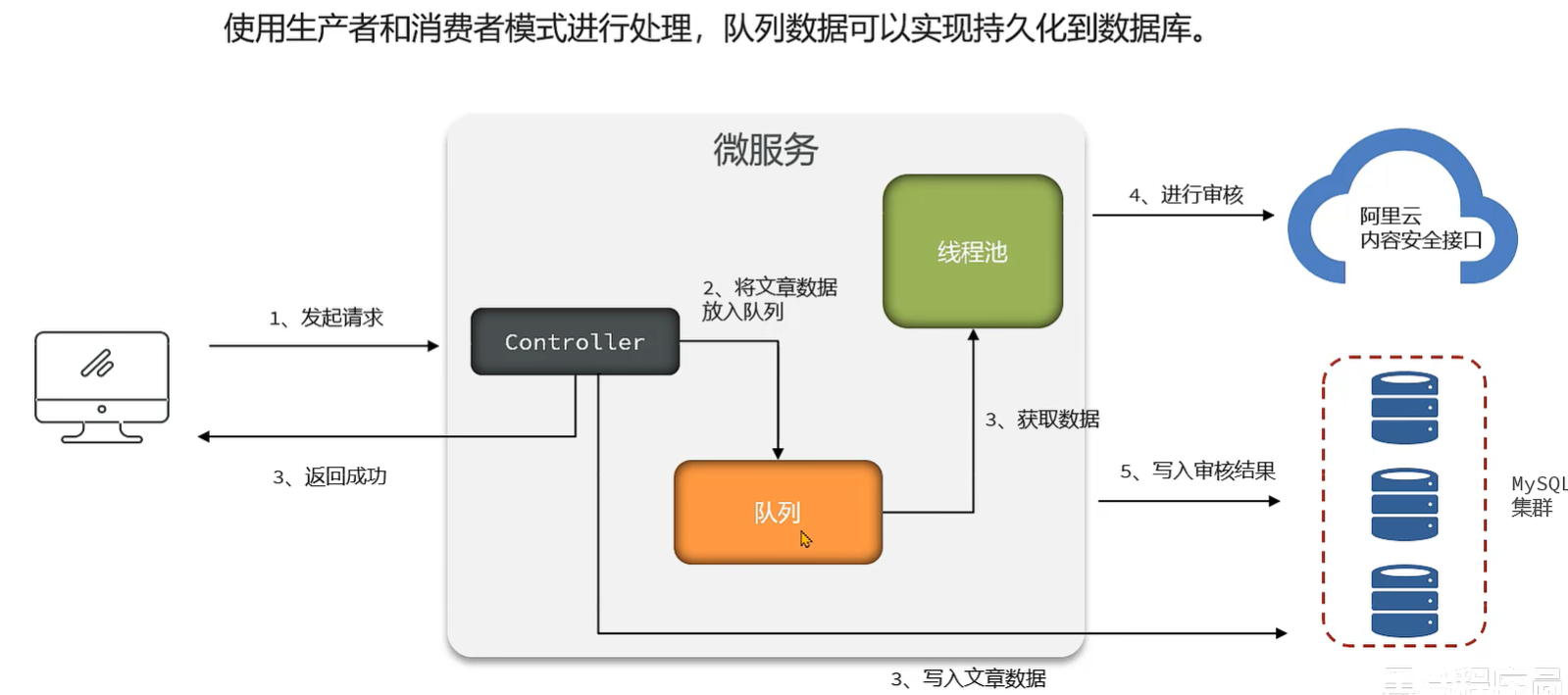
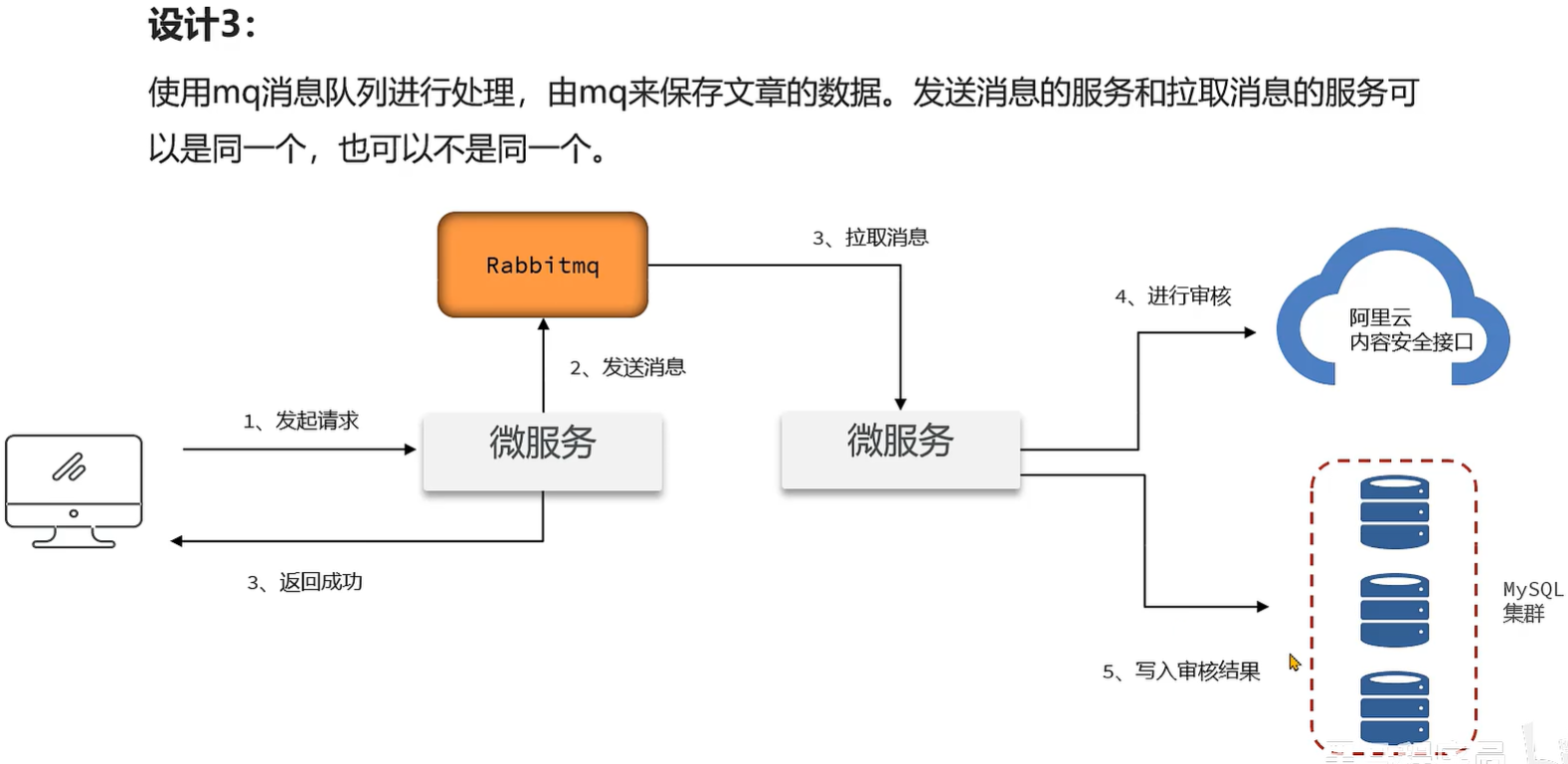

诊断和解决问题 两种方案

在线定位问题 -步骤
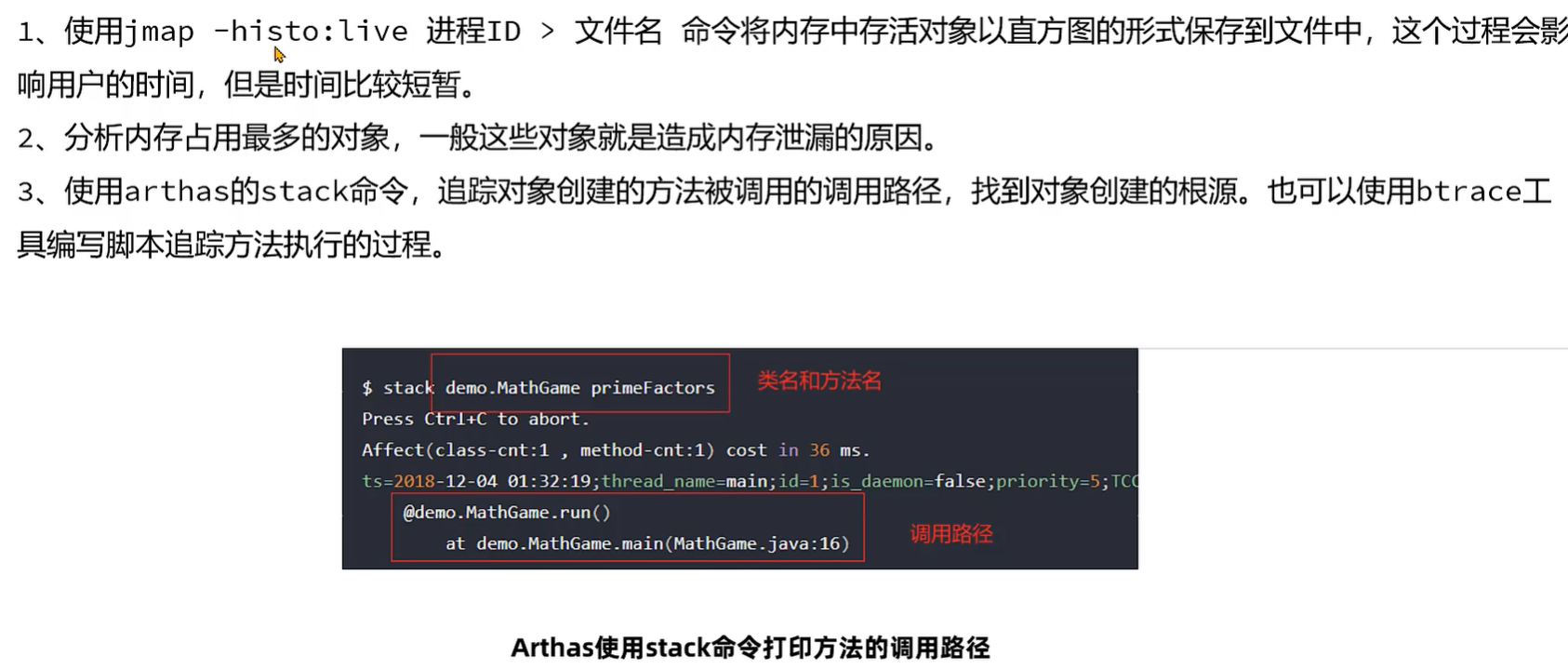
1 在线定位问题 btrace
官网:https://github.com/btraceio/btrace/releases/latest
2、内存溢出有哪几种产生的原因?
1、持续的内存泄漏:内存泄漏持续发生,不可被回收同时不再使用的内存越来越多就像滚雪球雪球越滚越大,最终内存被消耗完无法分配更多的内存取使用,导致内存溢出。
2、并发请求问题:用户通过发送请求向Java应用获取数据,正常情况下Java应用将数据返回之后,这部分数据就可以在内存中被释放掉。但是由于用户的并发请求量有可能很大,同时处理数据的时间很长,导致大量的数据存在于内存中,最终超过了内存的上限,导致内存溢出。
3、解决内存泄漏问题的方法是什么?
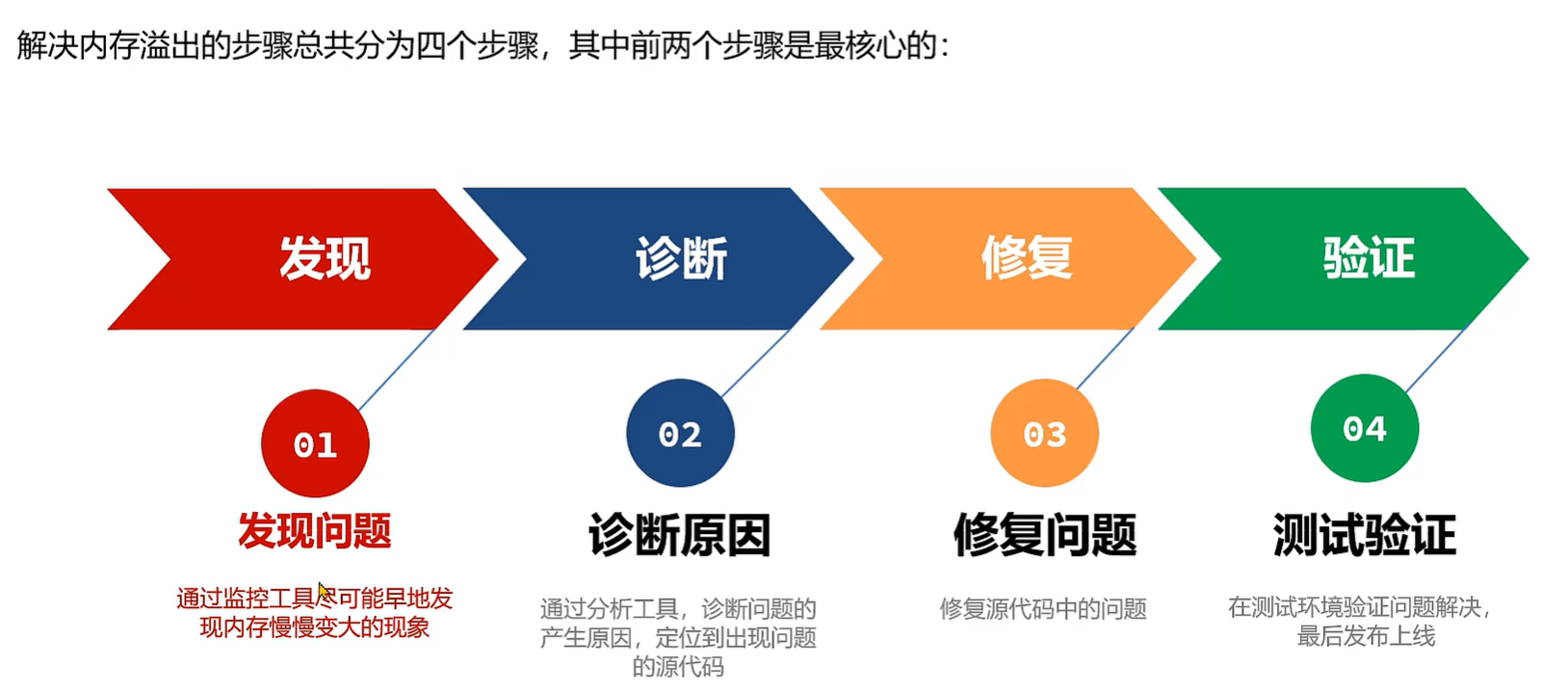
1、发现问题,,通过监控工具尽可能尽早地发现内存慢慢变大的现象。
2、诊断原因,通过分析内存快照或者在线分析方法调用过程,诊断问题产生的根源,定位到出现问题的源代码。
3、修复源代码中的问题,如代码bug、技术方案不合理、业务设计不合理等等。
4、在测试环境验证问题是否已经解决,最后发布上线。
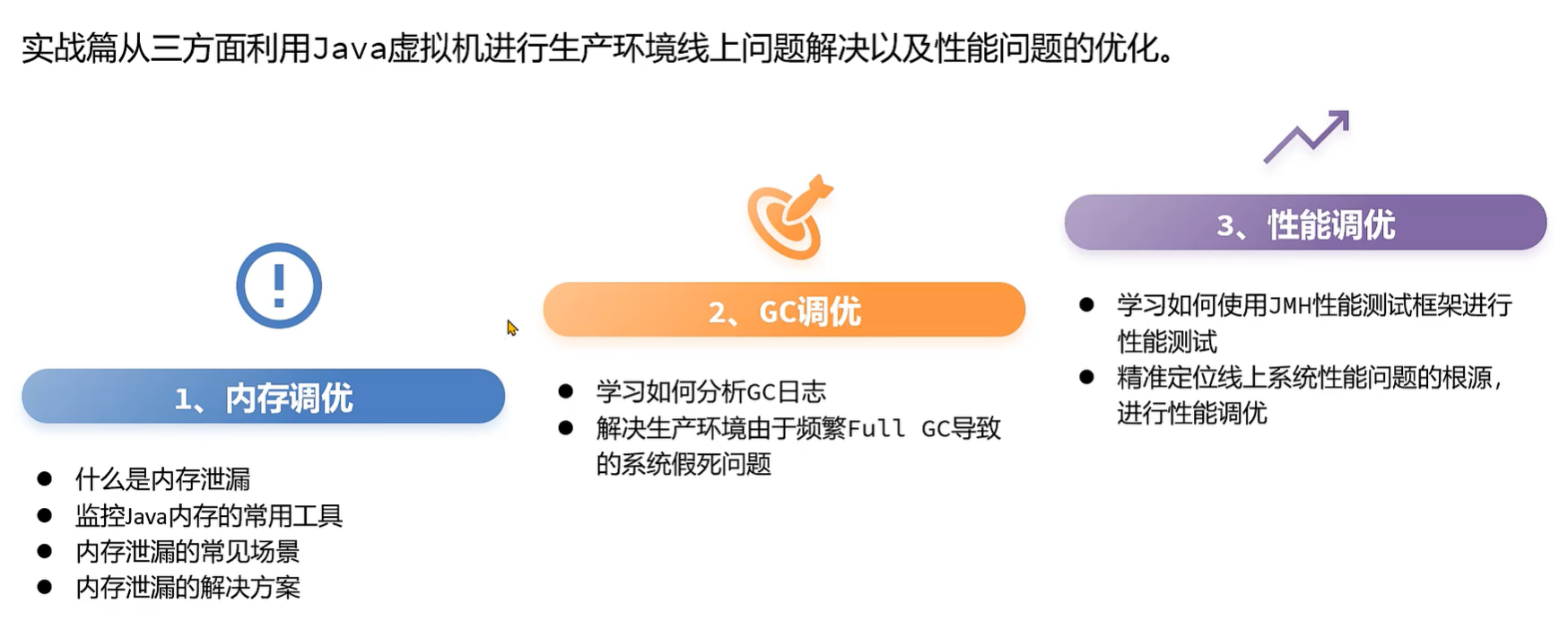
GC 调优
GC调优 指的是对**垃圾回收(Garbage Collection)**进行调优。GC调优的主要目标是避免由垃圾回收引起程序性能下降。
GC调优的核心分成三部分:
1、通用 Jvm参数 的设置。
2、特定垃圾回收器的 Jvm参数的设置。
3、解决由频繁的 FULL GC 引起的程序性能问题。
GC调优没有没有唯一的标准答案,如何调优与硬件、程序本身、使用情况均有关系,重点学习调优的工具和方法。
GC调优的核心指标
所以判断 GC 是否需要调优,需要从三方面来考虑,与 GC算法 的评判标准类似:
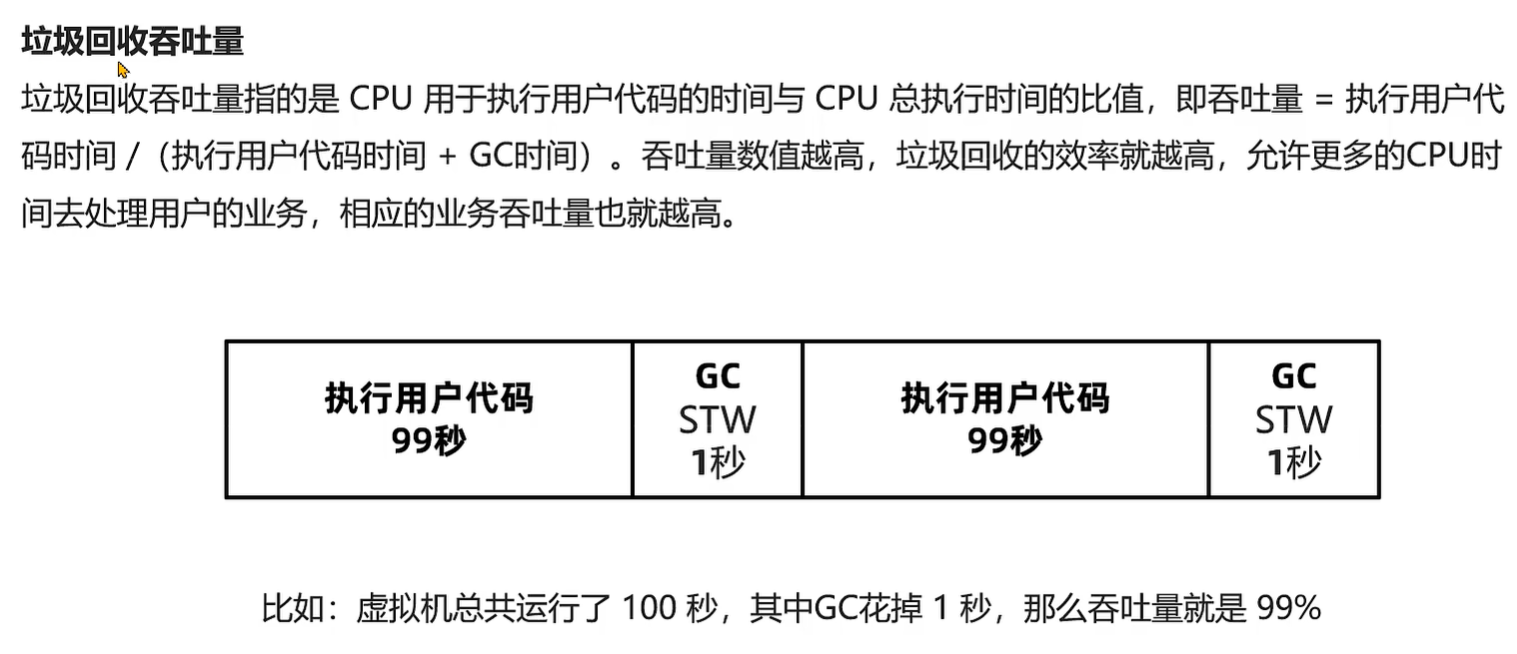
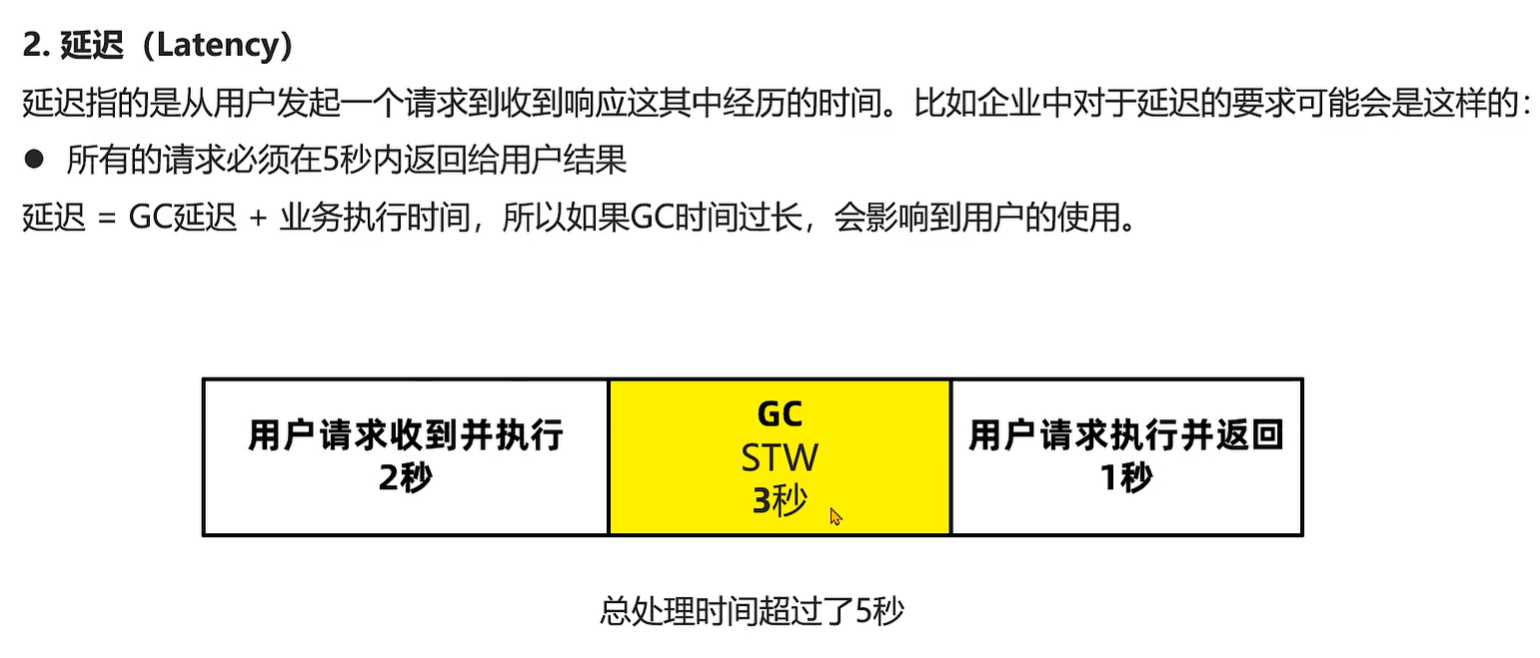
1.吞吐量(Throughput)吞吐量分为业务吞吐量和垃圾回收吞吐量
业务吞吐量 指的在一段时间内,程序需要完成的业务数量。比如企业中对于吞吐量的要求可能会是这样的:
- 支持用户每天生成10000笔订单
- 在晚上8点到10点,支持用户查询50000条商品信息
GC调优 的方法
保证高吞吐量的常规手段有两条:
1、优化业务执行性能,减少单次业务的执行时间
2、优化垃圾回收吞吐量
3.内存使用量
内存使用量指的是 Java应用 占用系统内存的最大值,一般通过 Jvm参数调整,在满足上述两个指标的前提下,这个值越小越好。

发现问题页- jstat 工具
- Jstat工具 是 JDK 自带的一款监控工具,可以提供各种垃圾回收、类加载、编译信息等不同的数据。
- 使用方法为:jstat-gc 进程ID 每次统计的间隔 (毫秒) 统计次数

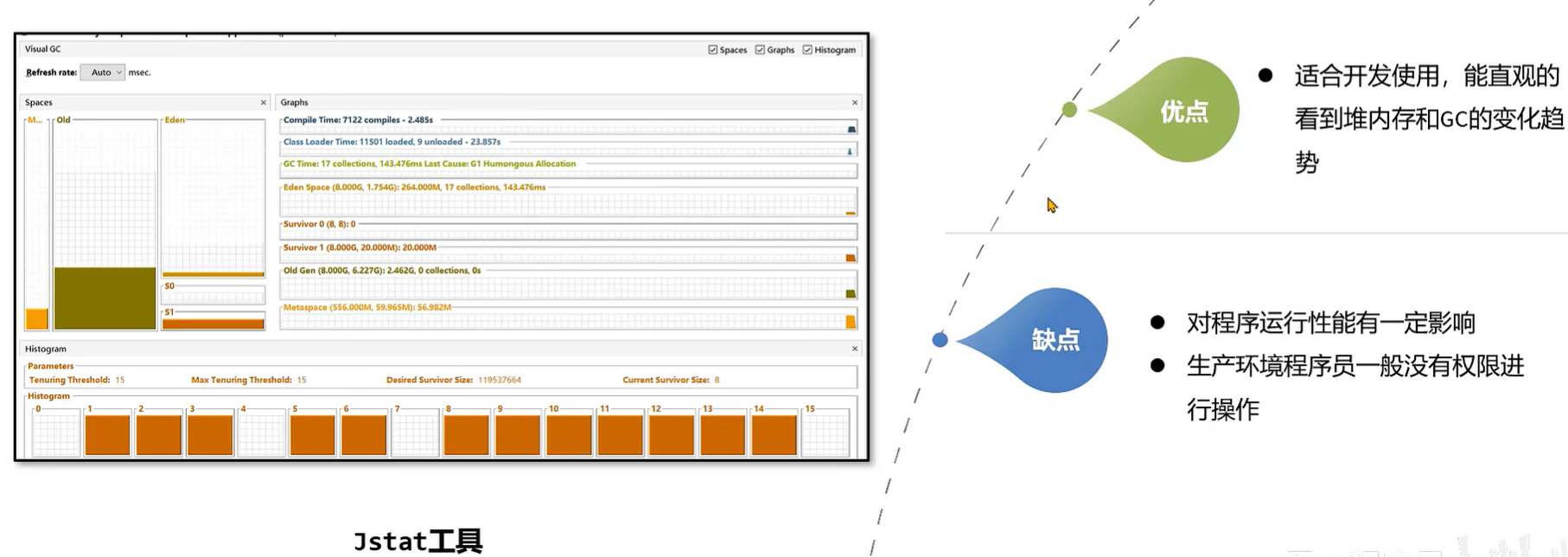
发现问题- visualvm插 件
- VisualVm 中提供了一款 visualTool 插件,实时监控 Java进程 的堆内存结构,堆内存变化趋势以及垃圾回收时间的变化趋势。同时还可以监控对象晋升的直方图。
Prometheus + Grafana
- Prometheus + Grafana 是企业中运维常用的监控方案,其中 Prometheus用来采集系统或者应用的相关数据,同时具备告警功能。Grafana 可以将 Prometheus 采集到的数据以可视化的方式进行展示。
- Java程序员要学会如何读懂 Grafana展示 的 Java虚拟机 相关的参数。
发现问题 -GC 日志
- 通过 GC日志,可以更好的看到垃圾回收细节上的数据,同时也可以根据每款垃圾回收器的不同特点更好地发现存在的问题。
- 使用方法(JDK 8及以下):-XX:+PrintGCDetails -Xloggc:文件名
- 使用方法(JDK 9+):-Xlog:gc*:file=文件名

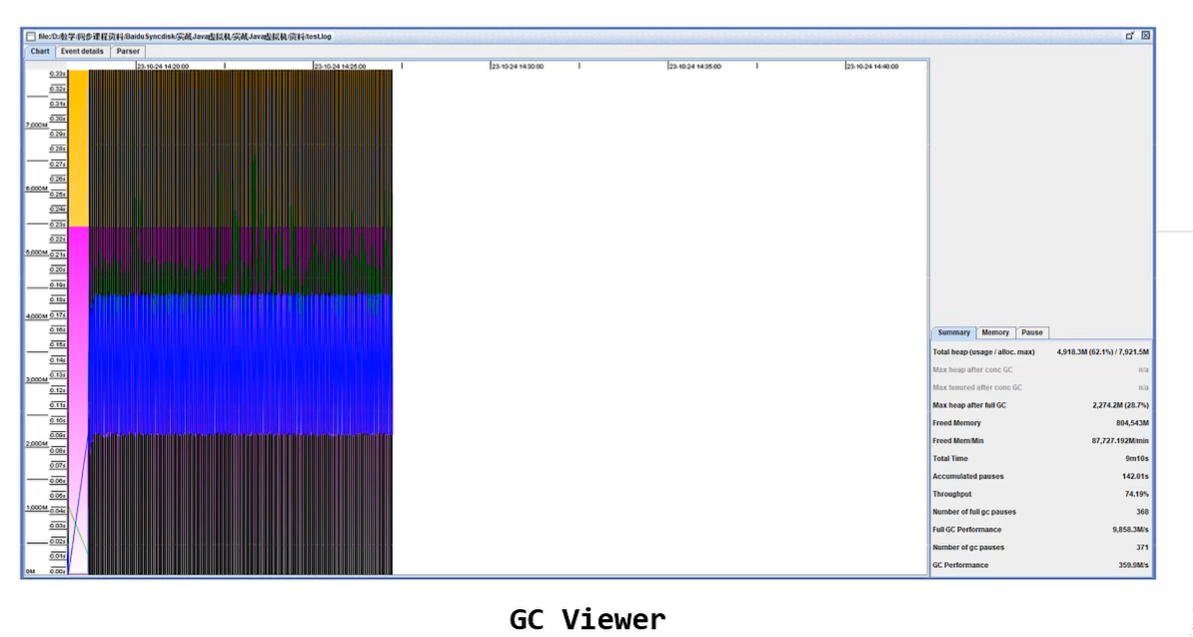
发现问题 - GC Viewer
-
GC Viewer 是一个将 GC日志 转换成可视化图表的小工具
github 地址: https://github.com/chewiebug/GcViewer
-
使用方法:java-jar gcviewer_1.3.4.jar 日志文件.log
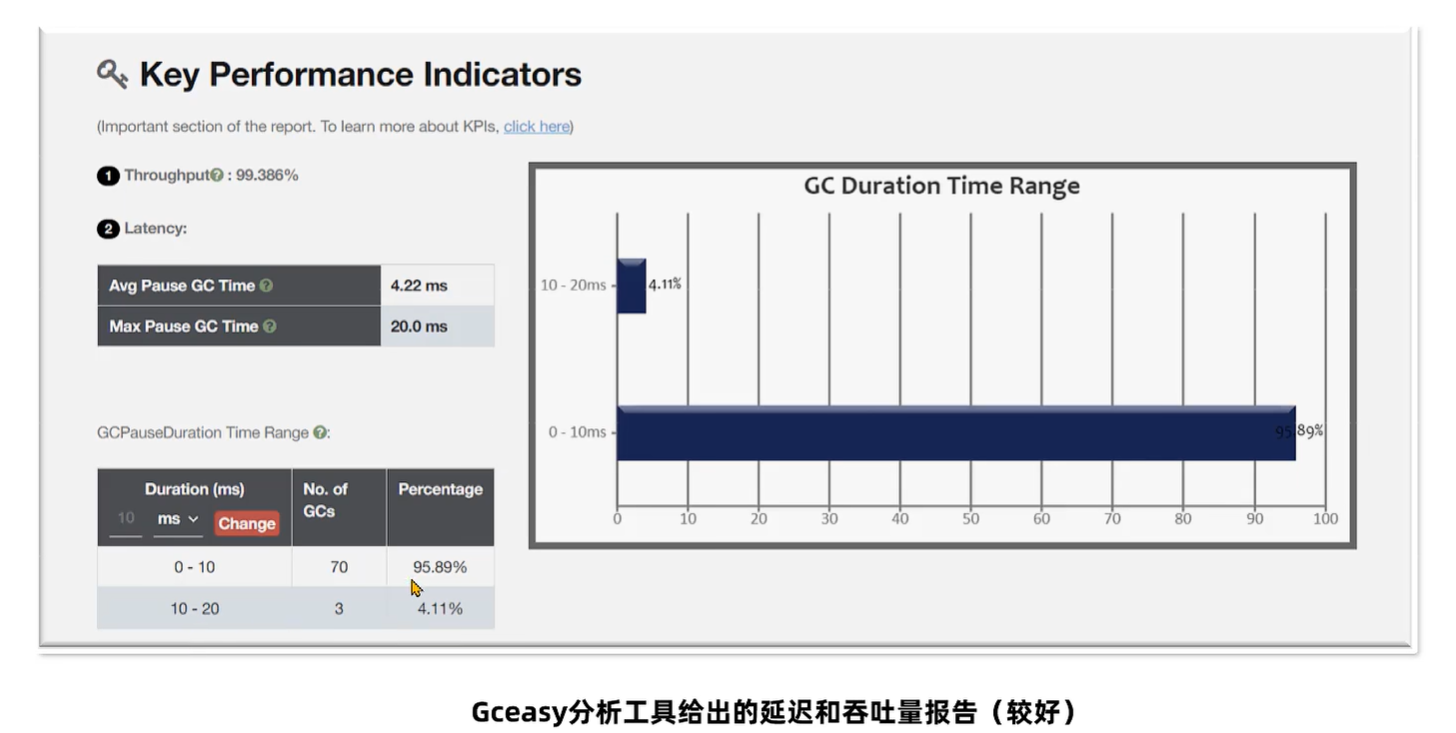
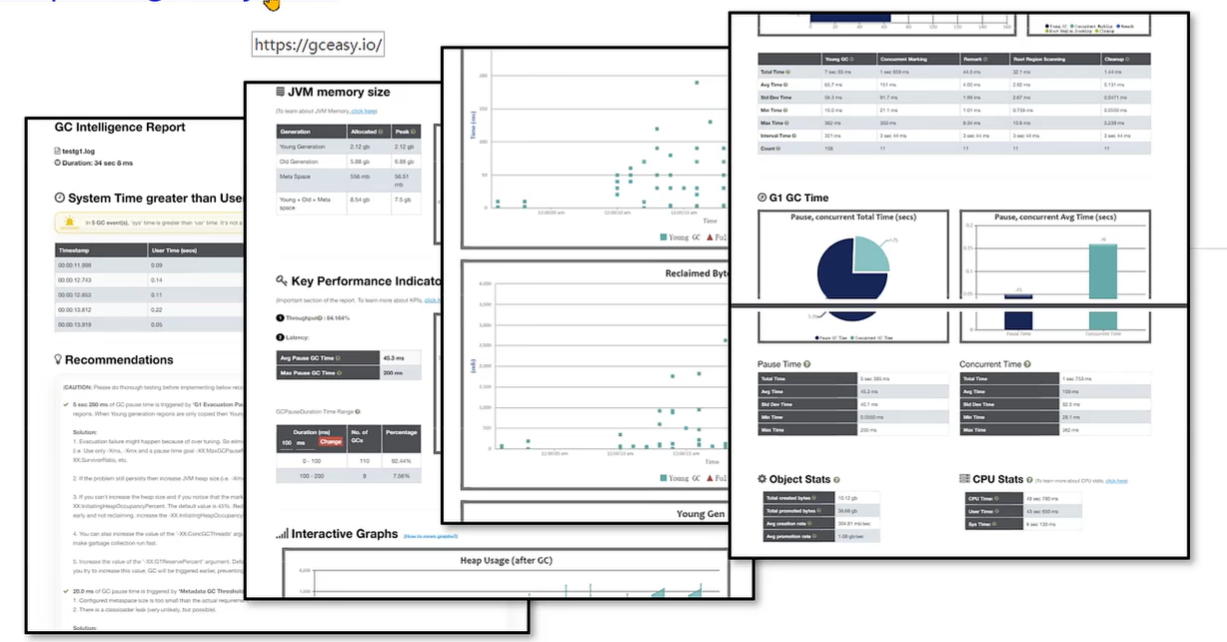
发现问题 - GCeasy
-
GCeaSy是业界首款使用 AI机器学习技术 在线进行 GC分析 和 诊断的工具。定位内存泄漏、GC延迟高 的问题,提供 JVM参数优化建议,支持在线的可视化工具图表展示。
官方网站:https://gceasy.io/
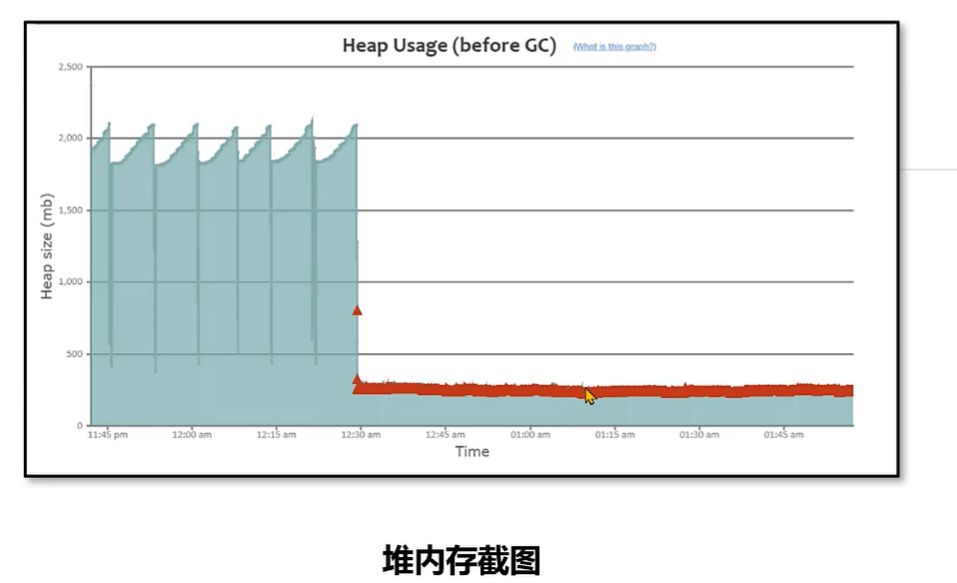
发现问题 - 常见的 GC模式
一、正常情况
特点:呈现锯齿状,对象创建之后内存上升,一旦发生垃圾回收之后下降到底部,并且每次下降之后的内存大小接近,存留的对象较少。
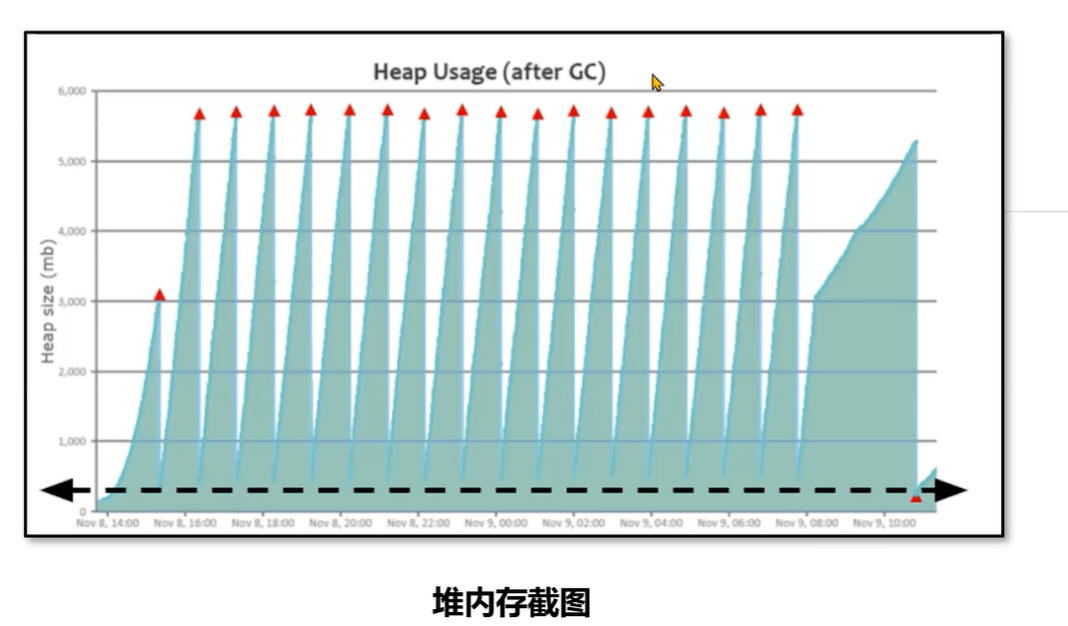
二、缓存对象过多
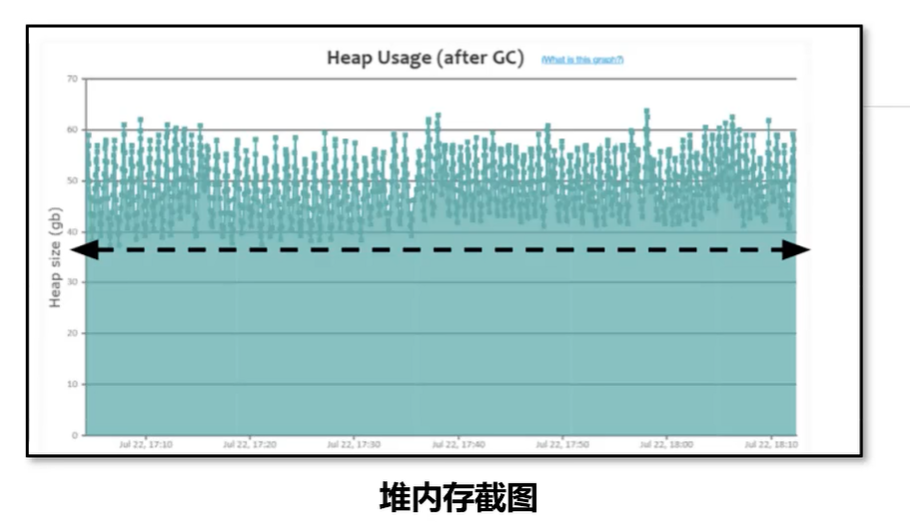
特点:呈现锯齿状,对象创建之后内存上升,一旦发生垃圾回收之后下降到底部,并且每次下降之后的内存大小接近,处于比较高的位置。
问题产生原因:程序中保存了大量的缓存对象,导致 GC 之后无法释放,可以使用 MAT 或者 HeapHero等工具 进行分析内存占用的原因。
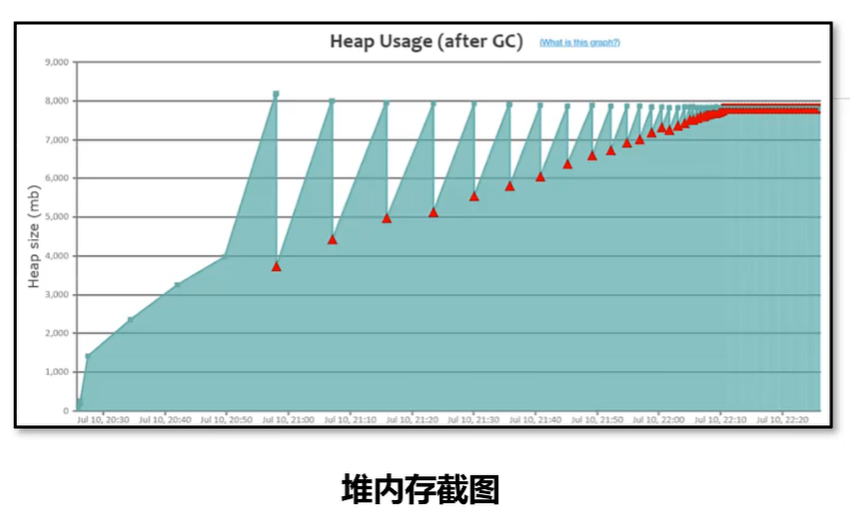
三、内存泄漏
特点:呈现锯齿状,每次垃圾回收之后下降到的内存位置越来越高,最后由于垃圾回收无法释放空间导致对象无法分配产生 outOfMemory 的错误。
问题产生原因:程序中保存了大量的内存泄漏对象,导致 GC 之后无法释放,可以使用 MAT 或者 HeapHero等工具 进行分析是哪些对象产生了内存泄漏。
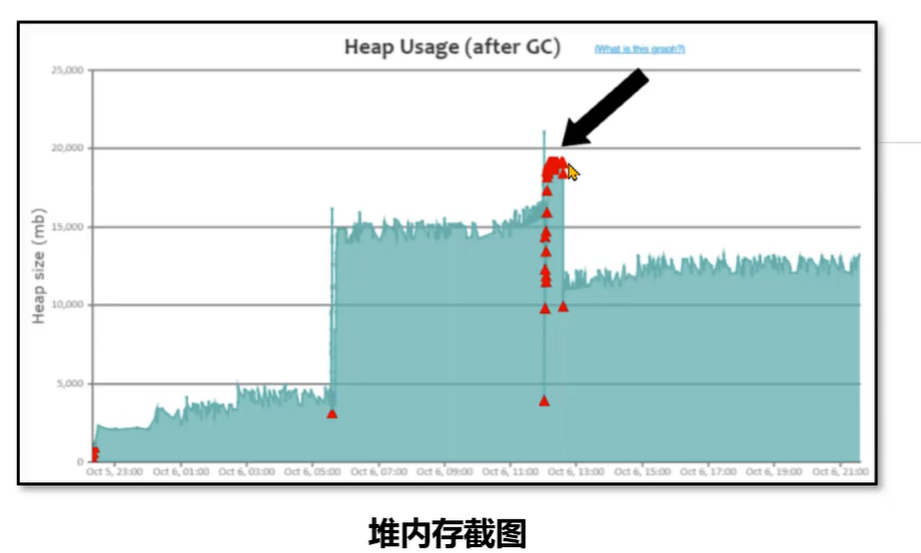
四、持续的 Fu GC
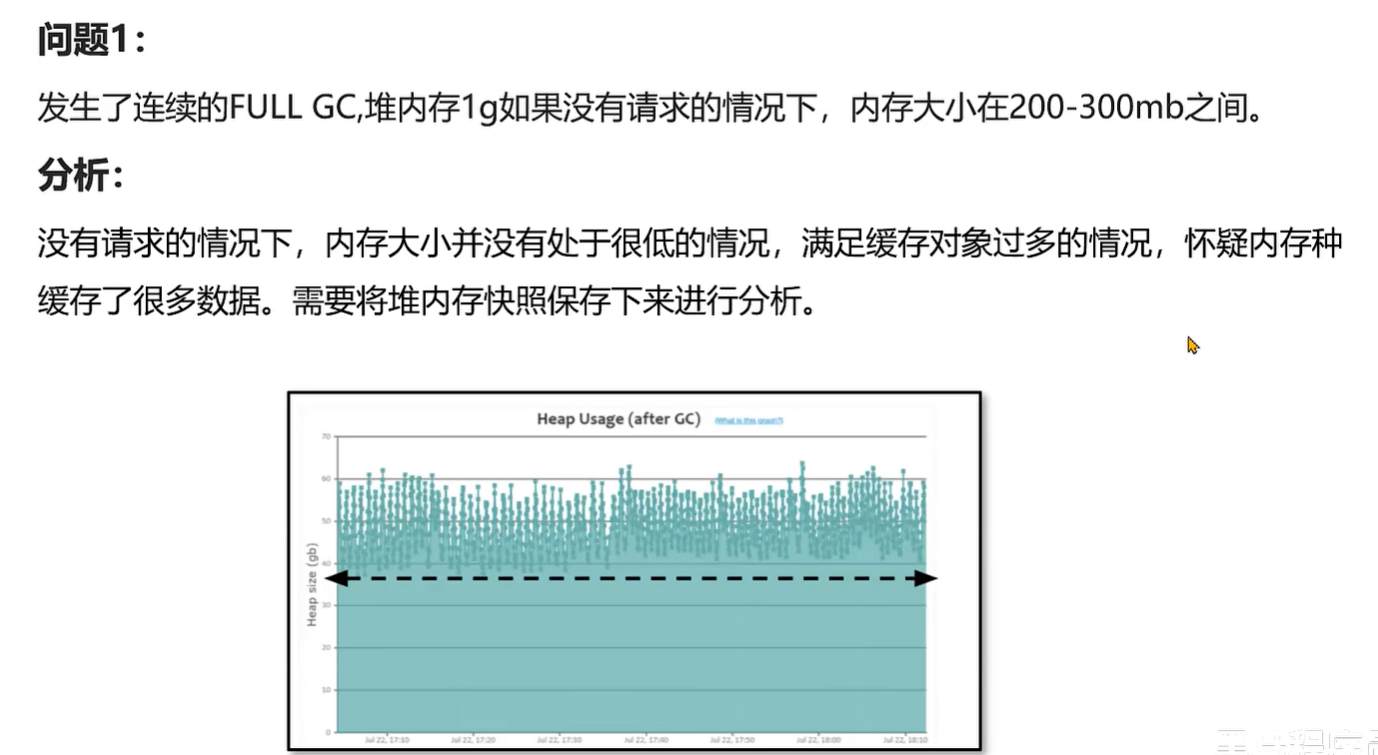
特点:在某个时间点产生多次 FULL GC,CPU使用率 同时飙高,用户请求基本无法处理。一段时间之后恢复正常。问题产生原因:在该时间范围请求量激增,程序开始生成更多对象,同时 垃圾收集 无法跟上对象创建速率,导致持续地在进行 FULL GC。GC分析报告
五、元空间不足导致的 FULL GC
特点:堆内存的大小并不是特别大,但是持续发生 FULL GC。问题产生原因:元空间大小不足,导致持续 FULL GC 回收元空间的数据。GC分析报告
解决 GC 问题的手段
解决GC问题的手段中,前三种是比较推荐的手段,第四种仅在前三种无法解决时选用:

解决问题 -优化基础 JVM参数
参数1:-Xmx 和-Xms
-Xmx 参数设置的是**最大堆内存,**但是由于程序是运行在服务器或者容器上,计算可用内存时,要将元空间、操作系统、其它软件占用的内存排除掉。
- 案例:服务器内存 4G,操作系统+元空间最大值+其它软件占用 1.5G,-Xmx可以设置为 2g。最合理的设置方式应该是根据最大并发量估算服务器的配置,然后再根据服务器配置计算最大堆内存的值。

参数1:-Xmx 和-Xms
-
-Xms用来设置初始堆大小,建议将-Xms设置的和-Xmx一样大,有以下几点好处:
- 运行时性能更好,堆的扩容是需要向操作系统申请内存的,这样会导致程序性能短期下降。
- 可用性问题,如果在扩容时其他程序正在使用大量内存,很容易因为操作系统内存不足分配失败。
- 启动速度更快,Oracle官方文档的原话:如果初始堆太小,Java应用程序启动会变得很慢,因为 JVM 被迫频繁执行垃圾收集,直到堆增长到更合理的大小。为了获得最佳启动性能,请将初始堆大小设置为与最大堆大小相同。
-
参数2 :-XX:MaxMetaspaceSize 和 -XX:MetaspaceSize
- -XX:MaxMetaspaceSize=值 参数指的是最大元空间大小,默认值比较大,如果出现元空间内存泄漏会让操作系统可用内存不可控,建议根据测试情况设置最大值,一般设置为 256m。
- -XX:MetaspaceSize=值 参数指的是到达这个值之后会触发FULL GC(网上很多文章的初始元空间大小是错误的)后续什么时候再触发 JVM 会自行计算。如果设置为和 MaxMetaspaceSize 一样大,就不会 FULL GC,但是对象也无法回收。

参数3:-Xss虚拟机栈大小
如果我们不指定栈的大小,JVM 将创建一个具有默认大小的栈。大小取决于操作系统和计算机的体系结构。
比如 Linu×x86 64位:1MB,如果不需要用到这么大的栈内存,完全可以将此值调小节省内存空间,合理值为256k - 1m之间。
使用:-Xss 256k
参数4:不建议手动设置的参数
由 于JVM底层 设计极为复杂,一个参数的调整也许让某个接口得益,但同样有可能影响其他更多接口。
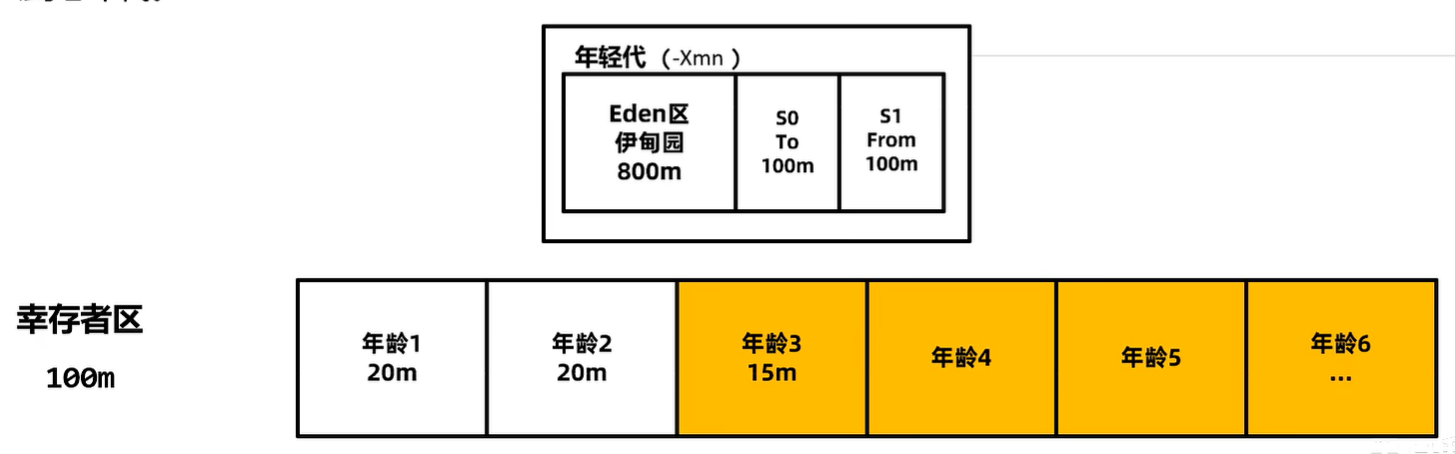
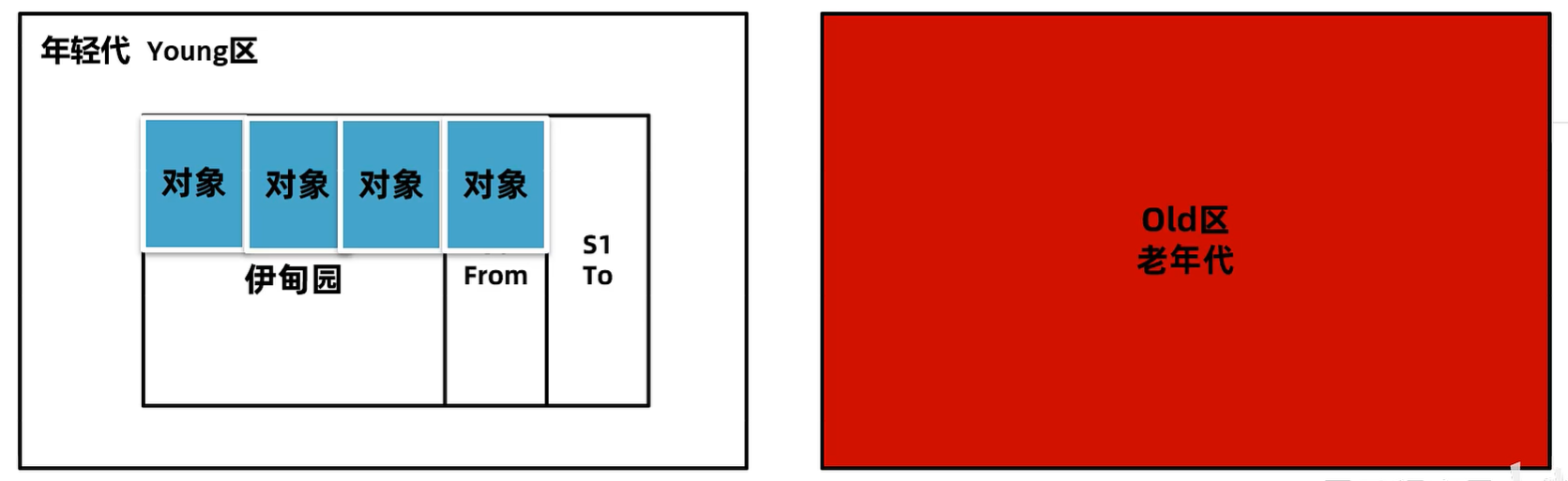
-Xmn 年轻代的大小,默认值为整个堆的 1/3,可以根据峰值流量计算最大的年轻代大小,尽量让对象只存放在年轻代,不进入老年代。但是实际的场景中,接口的响应时间、创建对象的大小、程序内部还会有一些定时任务等不确定因素都会导致这个值的大小并不能仅凭计算得出,如果设置该值要进行大量的测试。G1垃圾回收器尽量不要设置该值,G1会动态调整年轻代的大小。

-XX:SurvivorRatio 伊甸园区和幸存者区的大小比例,默认值为8。
-XX:MaxTenuringThreshold 最大晋升阈值,年龄大于此值之后,会进入老年代。另外 JVM 有动态年龄判断机制:将年龄从小到大的对象占据的空间加起来,如果大于 survivor 区域的 50%,然后把等于或大于该年龄的对象,放入到老年代。
-XX:+DisableExplicitGC
禁止在代码中使用system·gc(), System·gc() 可能会引起FULL GC,在代码中尽量不要使用。使用 DisableExplicitGC参数 可以禁止使用 system.gc() 方法调用。
- -XX:+HeapDumpOnOutOfMemoryError:发生 outofMemoryError错误 时,自动生成 hprof内存快照文件。
-XX:HeapDumpPath=:指定hprof文件的输出路径。
打印 GC 日志
JDK8及之前:-XX:+PrintGCDetails -XX:+PrintGCDateStamps-Xloggc:文件路径
JDK9及之后:-Xlog:gc*:file=文件路径

解决问题优化垃圾回收器的参数
这部分优化效果未必出色,仅当前边的一些手动无效时才考虑
一个优化的案例:
CMS的 并发模式失败(concurrentmodefailure)现象。由于 CMS 的垃圾清理线程和用户线程是 并行进行的,如果在并发清理的过程中老年代的空间不足以容纳放入老年代的对象,会产生并发模式失败。
并发模式失败会导致 Java虚拟机 使用 Serial old单线程 进行 FULL GC 回收老年代,出现长时间的停顿。
@RequestMapping("/fullgc")public class Demo2Controller {private Cache chche = Caffeine.newBuilder().weakKeys().softValues().build();private List<Object> objs = nwe ArrayList<>();private static final int _1MB = 1024 * 1024;// FULLGC 测试// -Xms8g -Xmx8g -Xss256k -XX:MaxMetaspaceSize=512m -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:/test.hprof -verbose:gc -XX+PrintGCDetails -XX:PrintGCTimeStamps// ps + po 50并发 260ms 100并发 474 200并发930// cms -XX:UseParNewGC -XX:UseConcMarkSweepGC 50并发 157ms 200并发 833// g1 JDK11 并发200 248@GetMappin("/1")public void test() throws InterruptedException {cache.put(RandomStringUtils.randomAlphabetic(8), new byte[10 * _1MB]);}
}
解决方案:
- 减少对象的产生以及对象的晋升。
- 增加堆内存大小
- 优化垃圾回收器的参数,比如 -XX:CMSInitiatingOccupancyFraction=值,当老年代大小到达该阈值时,会自动进行 CMS垃圾回收,通过控制这个参数提前进行老年代的垃圾回收,减少其大小。
- JDK8中 默认这个参数值为 -1,根据其他几个参数计算出阈值:
((100 - MinHeapFreeRatio) + (double)(CMSTriggerRatio * MinHeapFreeRatio) / 100.0) - 该参数设置完是不会生效的,必须开启-XX:+UseCMSInitiatingOccupancyOnly参数。
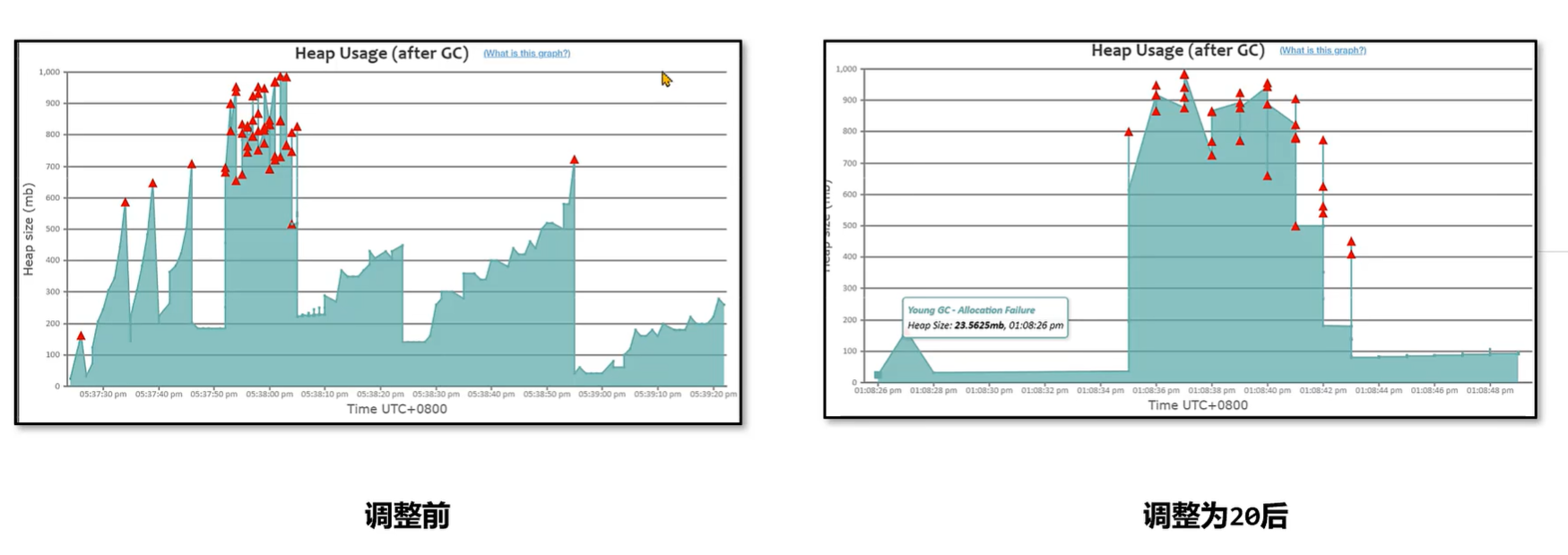
案例实战





性能调优
应用程序在运行过程中经常会出现性能问题,比较常见的性能问题现象是:
- 通过 top命令 查看 CPU占用率高,接近100甚至 多核CPU 下超过100 都是有可能的。
- 请求单个服务处理时间特别长,多服务使用 skywalking 等监控系统来判断是哪一个环节性能低下。
- 程序启动之后运行正常,但是在运行一段时间之后无法处理任何的请求**(内存和GC正常)**
线程转储(Thread Dump)提供了对所有运行中的线程当前状态的快照。线程转储可以通过 jstack、visualvm 等工具获取。其中包含了线程名、优先级、线程ID、线程状态、线程栈信息等等内容,可以用来解决CPU占用率高、死锁等问题。
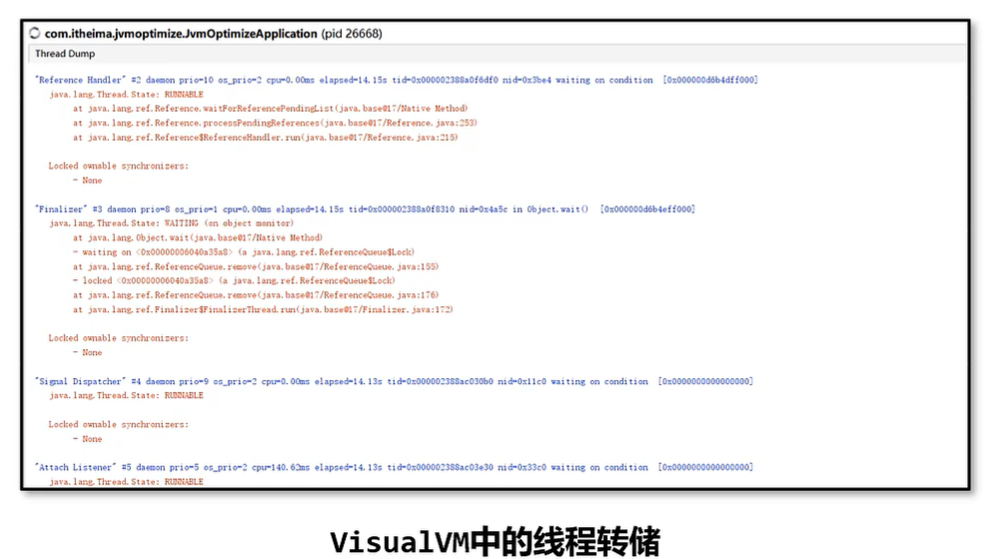
线程转储者(Thread Dump)中的几个核心内容:
**名称:**线程名称,通过给线程设置合适的名称更容易“见名知意”
优先级(prio): 线程的优先级
JavaID(tid): JVM 中线程的 唯一ID
本地ID(nid): 操作系统 分配给线程的 唯一ID
**状态:**线程的状态,分为:
NEW -新创建的线程,尚未开始执行
RUNNABLE -正在运行或准备执行
BLOCKED - 等待获取监视器锁以进入或重新进入同步块/方法
WAITING -等待其他线程执行特定操作,没有时间限制
TIMED_WAITING -等待其他线程在指定时间内执行特定操作
TERMINATED -已完成执行
-
栈追踪:显示整个方法的栈帧信息
线程转储的可视化在线分析平台:
1.https://jstack.review/
2.https://fastthread.io/
案例1:CPU 占用率高问题的解决方案
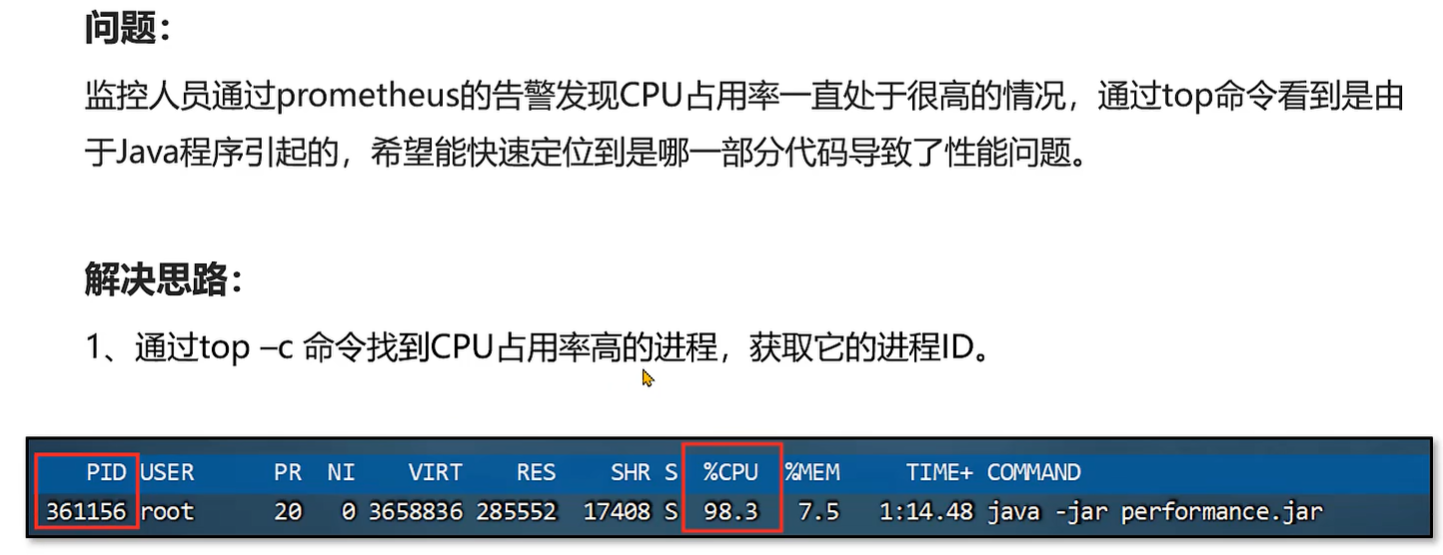
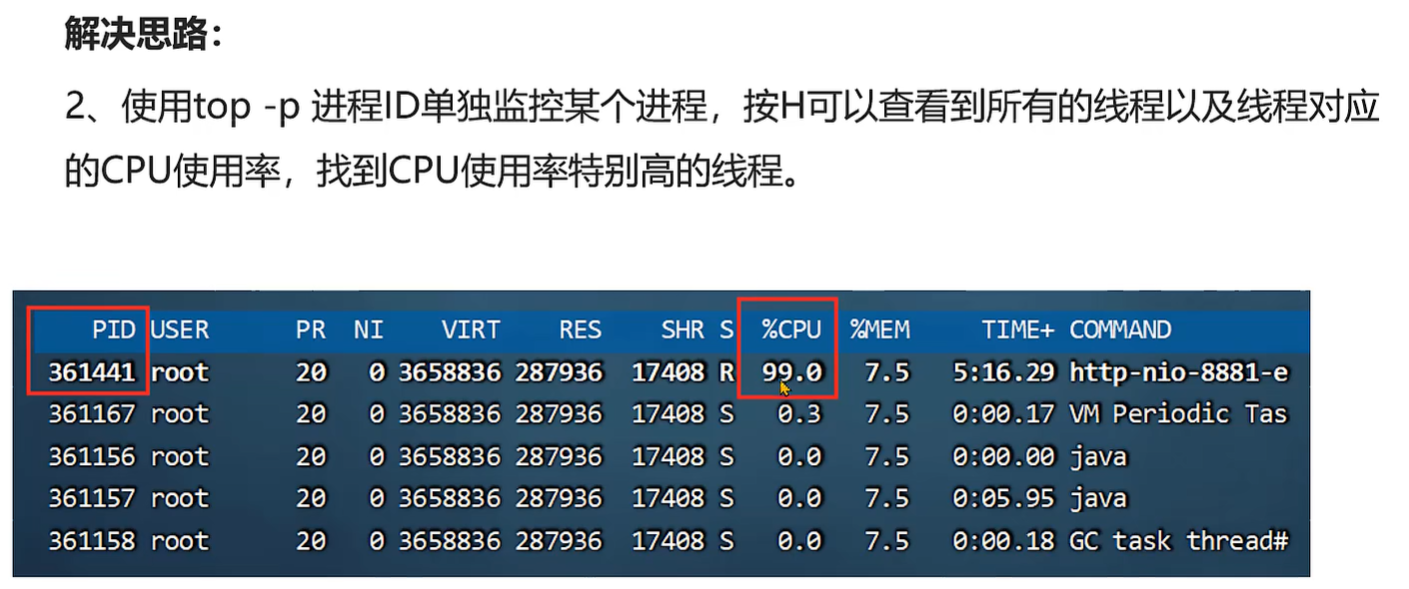
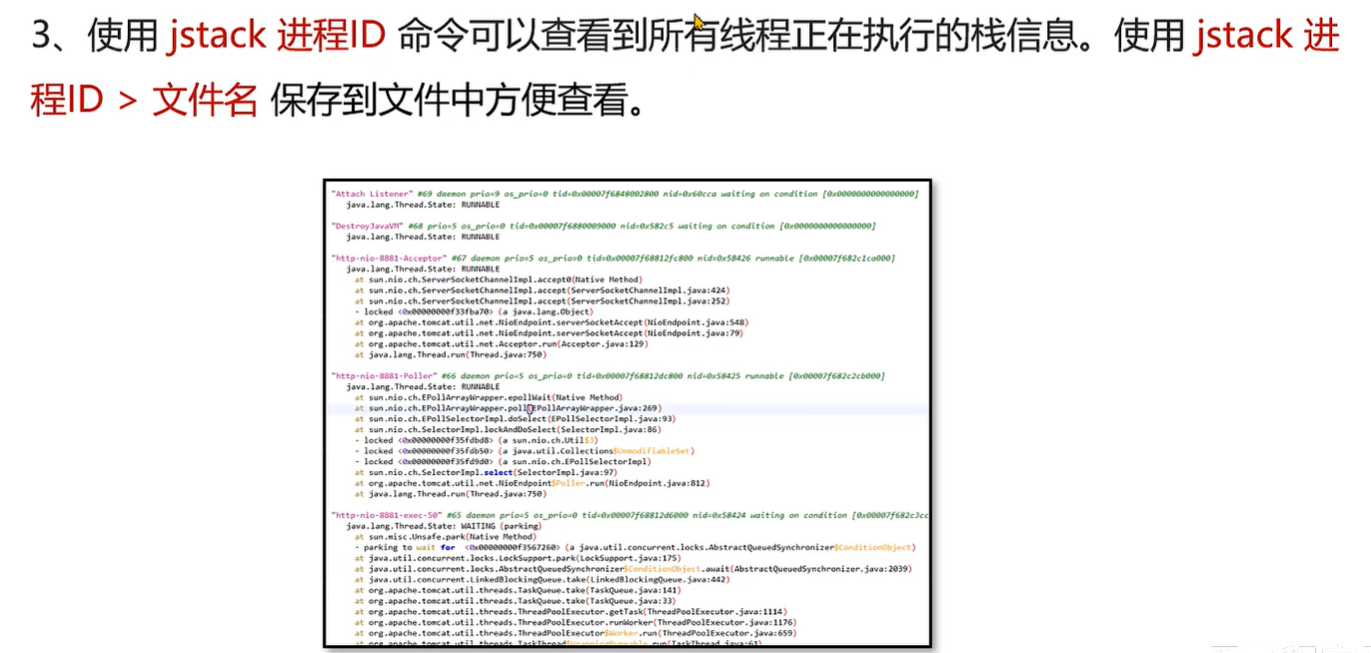
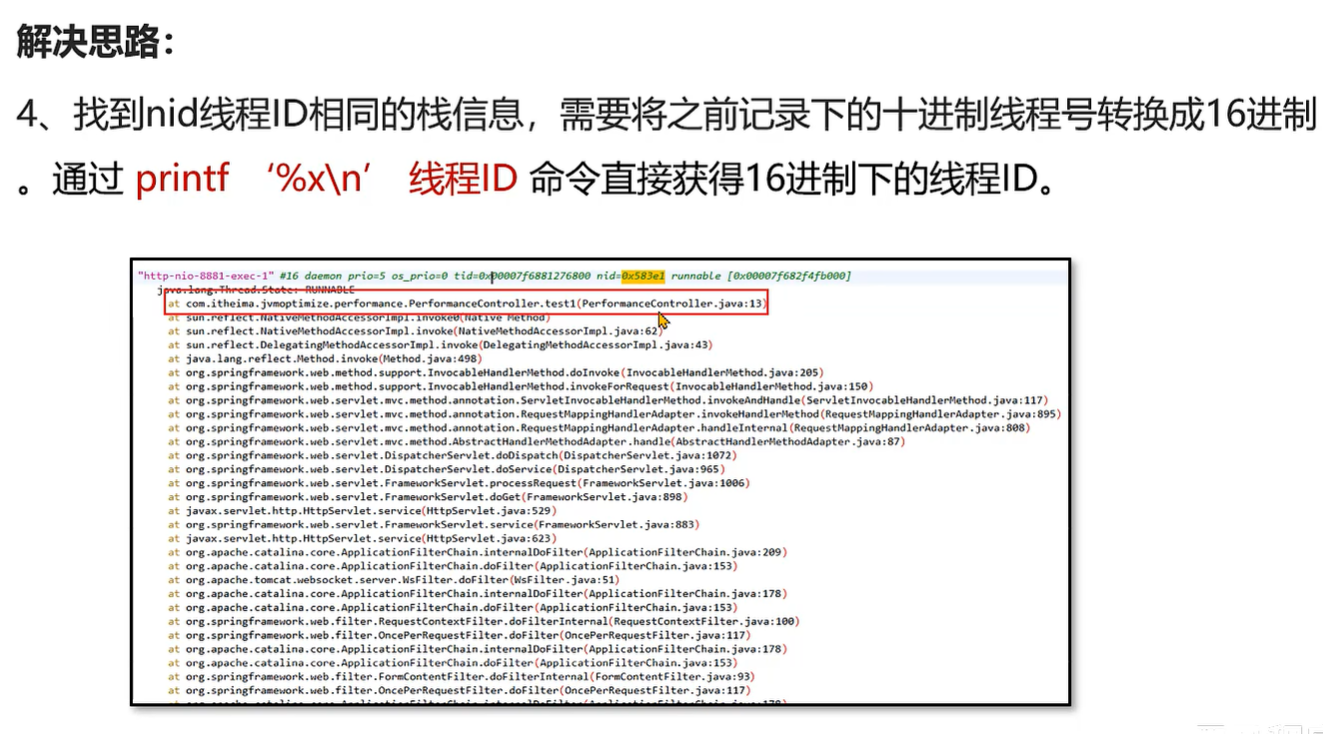


案例2:接口响应时间很长的问题
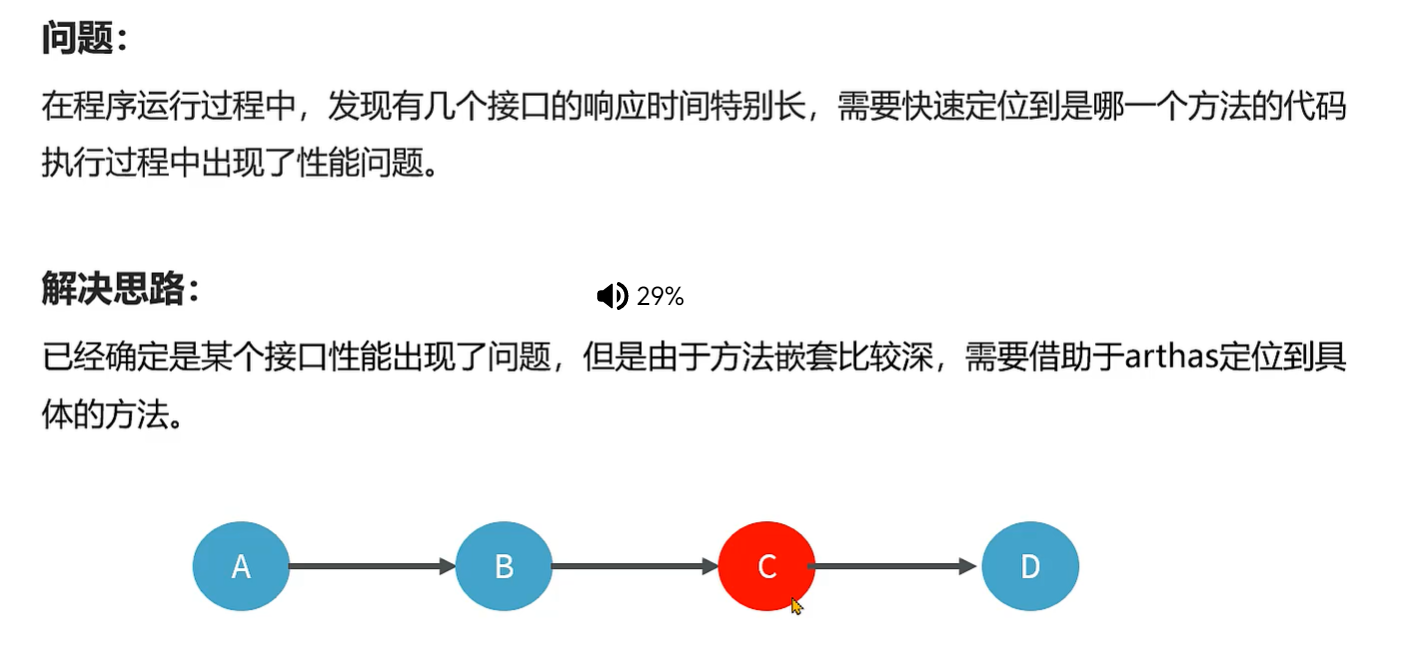
Arthas 的 trace命令
使用 arthas 的 trace命令,可以展示出整个方法的调用路径以及每一个方法的执行耗时。
命令:trace 类名方法名
- 添加–skipJDKMethod false 参数可以输出 JDk核心 包中的方法及耗时。
- 添加‘#cost 〉毫秒值’参数,只会显示耗时超过该毫秒值的调用。
- 添加 -n 数值参数,最多显示该数值条数的数据。
- 所有监控都结束之后,输入 stop 结束监控,重置 arthas增强的对象。
总结:
1、通过 arthas的 trace命令,首先找到性能较差的具体方法,如果访问量比较大,建议设置最小的耗时,精确的找到耗时比较高的调用。
2、通过 watch命令,查看此调用的参数和返回值,重点是参数,这样就可以在开发环境或者测试环境模拟类似的现象,通过 debug 找到具体的问题根源。
3、使用 stop命令 将所有增强的对象恢复。
案例3:定位偏底层的性能问题

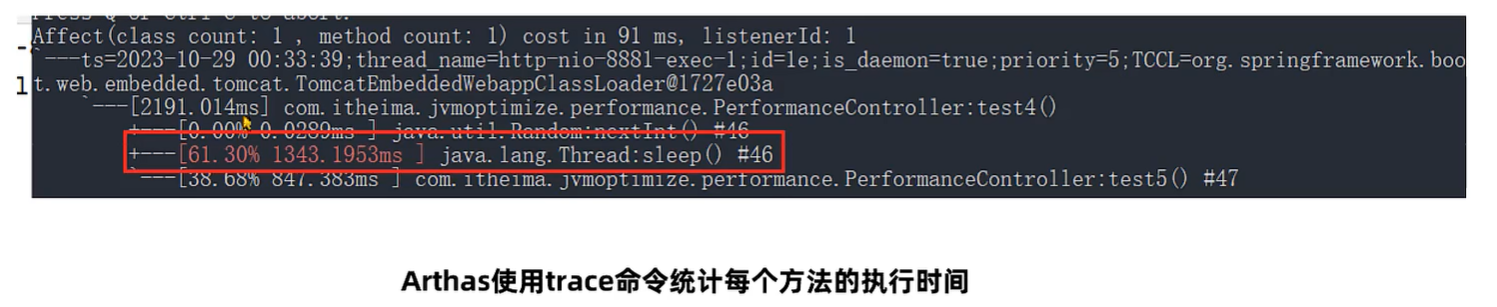
Arthas 的 profile 命令
使用 arthas 的 profile 命令,生成性能监控的火焰图。
命令1: profiler start 开始监控方法执行性能
命令2: profiler stop – format html 以 HTML 的方式生成火焰图
火焰图中一般找绿色部分Java中栈顶上比较平的部分,很可能就是性能的瓶颈。

性能调优解决的问题
应用程序在运行过程中经常会出现性能问题,比较常见的性能问题现象是:
1、通过 top命令 查看 CPU占用率高,接近 100甚至 多核CPU下 超过 100都是 有可能的。
2、请求单个服务处理时间特别长,多服务使用 skywalking等监控系统 来判断是哪一个环节性能低下。
3、程序启动之后运行正常,但是在运行一段时间之后无法处理任何的请求(内存和GC正常)。
案例4:线程被耗尽问题



解决方案:
3、使用 fastthread 自动检测线程问题。https://fastthread.io/
Fastthread 和 Gceasy类似,是一款在线的Al自动线程问题检测工具,可以提供线程分析报告。通过报告查看是否存在死锁问题。

性能调优的方法

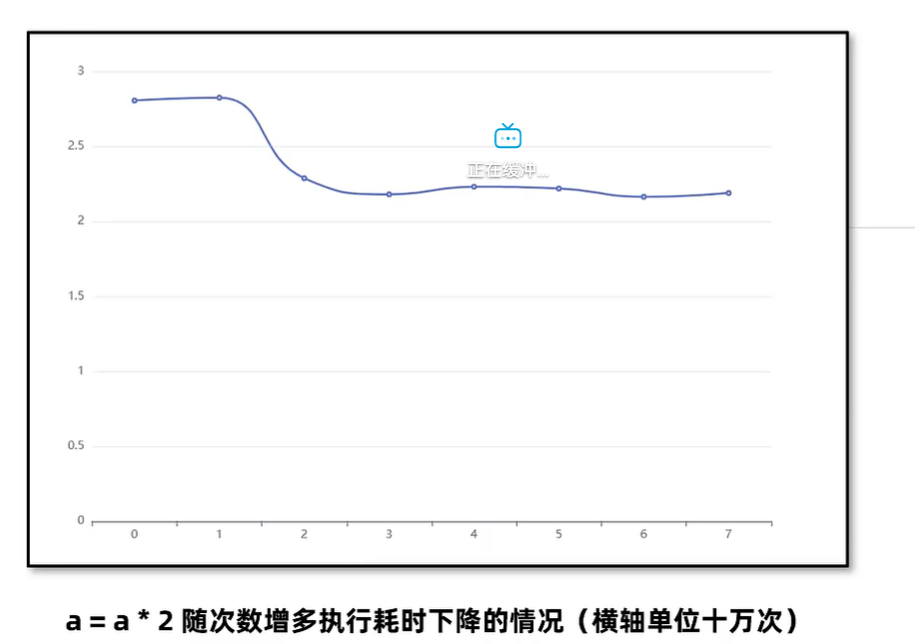
JIT 对程序性能的影响
Java 程序在运行过程中,JIT 即时编译器会实时对代码进行性能优化,所以仅凭少量的测试是无法真实反应运行系统最终给用户提供的性能。如下图,随着执行次数的增加,程序性能会逐渐优化。
OpenJDK 中提供了一款叫 JMH(Java Microbenchmark Harness)的工具,可以准确地对 Java代码 进行基准测试,量化方法的执行性能。
官网地址:https://github.com/openjdk/jmh
JMH 会首先执行预热过程,确保 JIT对代码进行优化之后再进行真正的迭代测试,最后输出测试的结果。
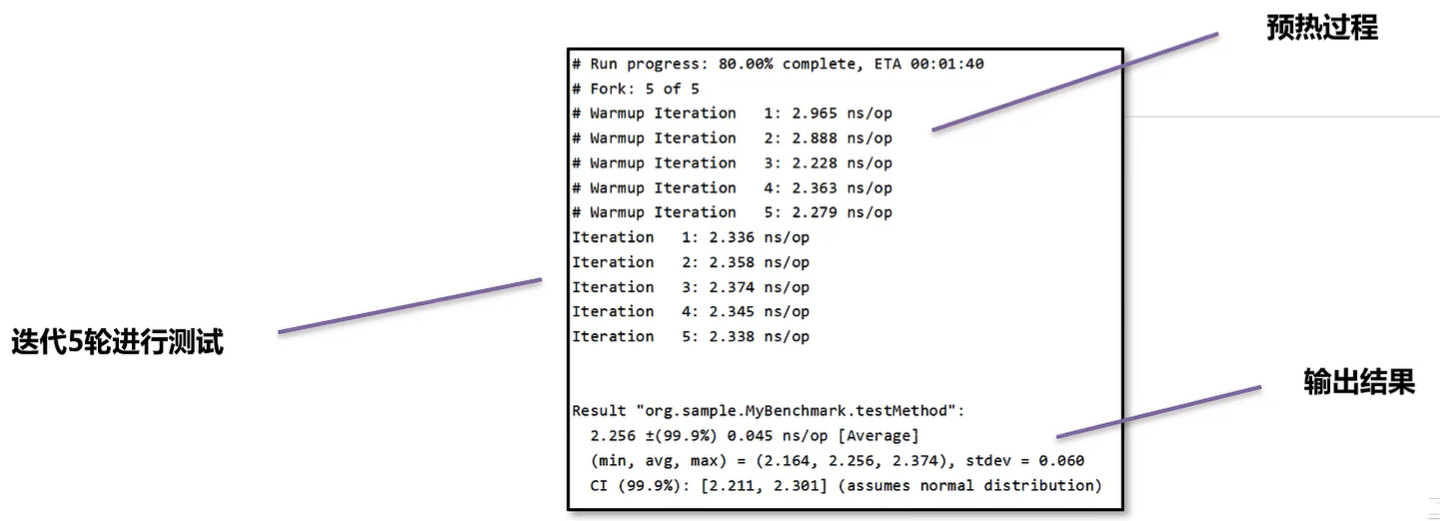

import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.*;// 预热次数 时间
@Warmup(iterations = 5, time = 1)
// 启动多少个线程
@Fork(value=1, jvmArgsAppend= {"-Xms1g", "-Xmx1g"})
// 指定显示结果
@BenchamarkMode(Mode.AverageTime)
// 指定显示结果单位
@OutputTimeUnit(TimeUnit.NANOSECONDS)
// 变量共享范围
@State(Scope.Benchmark)
public class MyBenchmark {@Benchmarkpublic void testMethod() {// place your benchmarked code hereint i = 0;i++;return i;}// 在项目中测试时,尽量打包成 jar 包public static void main(String[] args) throws RunnerException {Options options = new OptionsBuilder();.include(MyBenchmark.class.getSimpleName()).forks(1).build();new Runner(options).run();}
}
编写测试方法,几个需要注意的点:
-
死代码问题
-
黑洞的用法
-
通过 maven 的 verify命令,检测代码问题并打包成 jar包。通过 java -jar target/benchmarks.jar 命令执行基准测试。
测试结果通过 https://imh.morethan.io/ 生成可视化的结果。
案例:日期格式化方法性能测试

总结:日期格式化方法性能测试
案例实战