
本文字数:8969;估计阅读时间:23 分钟
作者:Pavel Kruglov
本文在公众号【ClickHouseInc】首发

简介
JSON 已成为现代数据系统中处理半结构化和非结构化数据的首选格式。无论是在日志记录和可观测性 (observability) 应用场景、实时数据流、移动应用存储,还是机器学习管道中,JSON 以其灵活的结构,成为分布式系统中捕获和传输数据的标准格式。
在 ClickHouse,我们早已认识到无缝支持 JSON 的重要性。尽管 JSON 的结构看似简单,但要在大规模环境中高效使用它,却面临着独特的挑战。接下来,我们将简要介绍这些挑战。
挑战 1:真正的列存储
ClickHouse 是市场上最快的分析型数据库之一。要实现这样的性能水平,必须采用正确的数据组织方式。ClickHouse 作为真正的列存储数据库,将表格数据以列的形式存储在磁盘上。这样可以实现最佳的压缩效果,并通过硬件加速,快速执行向量化的列操作,如过滤和聚合。
为了让 JSON 数据也能达到同样的性能,我们需要为 JSON 实现真正的列存储方式,使 JSON 路径像数值类型等其他列类型一样,能够被高效压缩和处理(例如,向量化的过滤和聚合)。
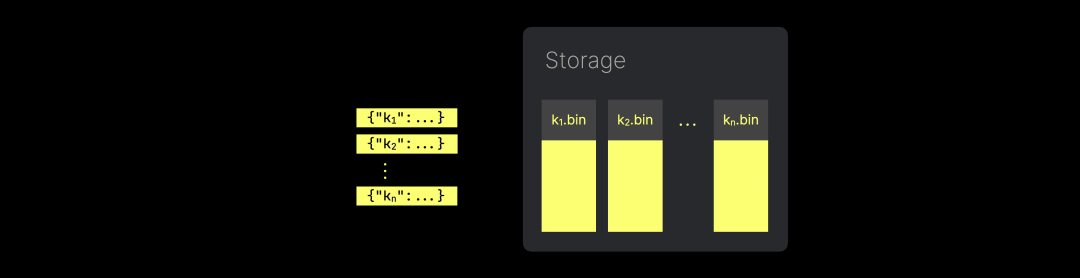
因此,我们不想像下图所示的那样,将 JSON 文档直接存储到字符串列中,并在后续解析:

我们希望将每个唯一 JSON 路径的值以真正的列存储方式保存:

挑战 2:无需类型统一的动态数据处理
当我们能够以真正的列存储方式存储 JSON 路径后,下一个挑战是 JSON 允许相同的路径具有不同的数据类型。在 ClickHouse 中,这些不同的数据类型可能存在不兼容性,且在使用前无法预知。此外,我们需要找到一种方法来保留所有不同的数据类型,而不是将它们统一为最小共同类型。例如,如果某个 JSON 路径 a 的值是两个整数和一个浮点数,我们不希望将它们都存储为磁盘上的浮点数,如下图所示:

这种方法无法保留混合类型数据的原始特性,也无法支持更复杂的场景。例如,如果下次在相同路径 a 下存储的值是一个数组:

挑战 3:防止磁盘上列数据文件的过多增长
以真正的列存储方式保存 JSON 路径,在数据压缩和向量化处理方面确实有优势。然而,如果每当遇到新的唯一 JSON 路径时都创建一个新的列文件,可能会在含有大量唯一 JSON 键的场景中导致磁盘上产生过多的列文件:
这会带来性能问题,因为需要使用大量的文件描述符来管理这些文件(每个文件描述符都占用一定的内存资源),并且由于需要处理的大量文件,合并操作的性能也会受到影响。因此,我们引入了列创建的限制,确保 JSON 存储可以有效扩展,支持 PB 级别数据集上的高性能分析。
挑战 4:密集存储
在包含大量唯一但稀疏 JSON 键的场景中,我们希望避免为那些在特定 JSON 路径上没有实际值的行,冗余存储或处理 NULL 或默认值,如下图所示:
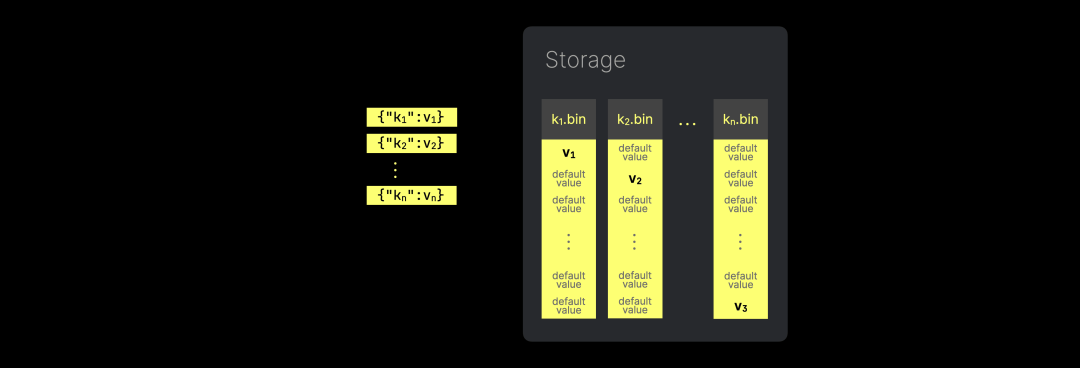
相反,我们希望以密集存储的方式保存每个唯一 JSON 路径的值,避免冗余。这同样能够让 JSON 存储扩展到 PB 级别数据集,并实现高性能的分析。
我们全新且极大增强的 JSON 数据类型
我们非常高兴推出全新升级的 JSON 数据类型,专为高性能处理 JSON 数据而设计,克服了传统实现中的性能瓶颈。
在这篇文章中,我们将详细介绍该功能的构建过程,解决了之前提到的所有挑战和限制,并展示了为什么我们的实现是列式存储中 JSON 支持的最佳选择,具备以下特点:
-
动态数据处理:允许相同 JSON 路径下的值具有不同的数据类型(可能不兼容且无法预知),无需统一为最小公共类型,确保混合类型数据的完整性。
-
高性能列式存储:将任何插入的 JSON 键路径存储为原生、密集的子列,支持高效的数据压缩,并保持经典类型下的高查询性能。
-
可扩展性:支持限制单独存储的子列数量,确保 JSON 存储能够扩展以支持 PB 级别的数据集,并实现高性能分析。
-
灵活调优:支持为 JSON 解析提供指引,例如显式设置 JSON 路径的类型,或指定需要跳过的路径。
接下来,我们将讲解如何通过构建基础组件,来开发这一新型 JSON 类型,这些组件不仅应用于 JSON,还具有更广泛的用途。
构建块 1 - 变体类型 (Variant type)
变体数据类型是我们全新 JSON 数据类型的基础组件。它是一个独立的特性,可以在 JSON 之外使用,允许在同一列中高效存储和读取不同数据类型的值,无需将它们统一为最小公共类型,从而解决了我们遇到的第一个和第二个挑战。
ClickHouse 的传统数据存储方式
在没有变体类型之前,ClickHouse 表的每一列都具有固定的数据类型,所有插入的值必须符合列的数据类型,或被隐式转换为目标类型。
为了更好地展示变体类型的工作原理,下图展示了 ClickHouse 传统的 MergeTree 系列表在磁盘上如何存储具有固定类型的列数据(按数据部分存储):

上图中的表可以通过以下 SQL 代码复现。我们为每一列定义了数据类型,例如列 C1 是 Int64 类型。作为列式数据库,ClickHouse 会将每个列的值以独立的(高度压缩的)列文件形式存储在磁盘上。由于列 C2 是可空类型 (Nullable),ClickHouse 除了正常的列文件外,还会创建一个独立的 NULL 掩码文件,用来区分 NULL 和空值。对于列 C3,上图展示了 ClickHouse 如何通过存储每一行数组大小的文件,原生支持数组的存储。这个大小文件用于计算数组元素在数据文件中的偏移量。
动态数据存储的扩展
通过变体类型,我们可以将表中所有列的数据存储在一个列中。下图(可点击放大)展示了这种列的工作原理,以及它如何基于 ClickHouse 的列存储在磁盘上实现(按数据部分存储):
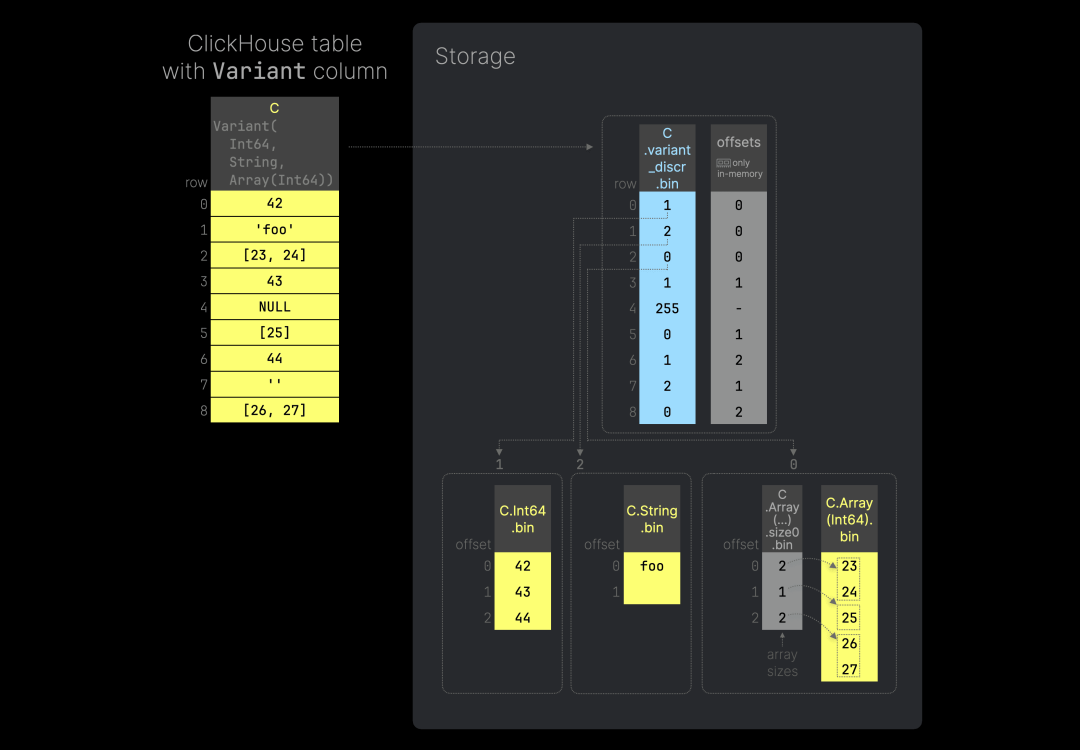
下方的 SQL 代码可以用来重现上图中的示例表。我们将列 C 定义为变体类型,指定其可以存储整数、字符串和整数数组的混合值。对于这样的列,ClickHouse 会将每种具体数据类型的值分别存储在独立的子列中(这些变体类型的子列数据文件与前面示例中的列数据文件几乎相同)。例如,所有整数值存储在 C.Int64.bin 文件中,所有字符串值存储在 C.String.bin 文件中,依此类推。
用于子类型切换的判别器列
为了识别 ClickHouse 表中每一行使用的具体数据类型,ClickHouse 为每种数据类型分配了一个判别器值,并将这些值存储在一个额外的 (UInt8) 列数据文件中(如上图所示的 C.variant_discr.bin 文件)。每个判别器值对应一个已排序的类型名称列表中的索引。判别器值 255 专门用于表示 NULL 值,这意味着变体类型 (Variant) 最多可以支持 255 种不同的具体类型。
需要注意的是,我们不需要一个独立的 NULL 掩码文件来区分 NULL 和默认值。
此外,ClickHouse 提供了一种判别器序列化的紧凑形式,以优化典型的 JSON 场景。
密集数据存储
变体类型的列数据文件采用密集存储方式。这些文件不存储 NULL 值。在包含大量唯一但稀疏 JSON 键的场景中,我们不会为没有真实值的行存储默认值,如上图所示的反例。这解决了我们的第四个挑战。
由于变体类型的数据采用密集存储,我们还需要将判别器列中的行与相应的变体类型列数据文件中的行进行映射。为此,我们使用了一个额外的 UInt64 偏移列(见上图中的偏移量),该列仅在内存中生成,不会存储在磁盘上(可以根据判别器列文件动态生成)。
例如,想要获取上图中 ClickHouse 表第 6 行的值时,ClickHouse 会检查判别器列第 6 行的值,以识别包含请求值的变体类型列文件:C.Int64.bin。然后,通过读取偏移列第 6 行的偏移量值(偏移量为 2),ClickHouse 可以确定请求的值在 C.Int64.bin 文件中的具体位置。因此,ClickHouse 表第 6 行的值为 44。
任意嵌套的变体类型
在变体列中,嵌套的类型顺序没有影响:Variant(T1, T2) 等同于 Variant(T2, T1)。此外,变体类型支持任意深度的嵌套,例如,你可以将变体类型作为另一个变体类型中的子类型。下图展示了这一特性(可以点击放大查看):
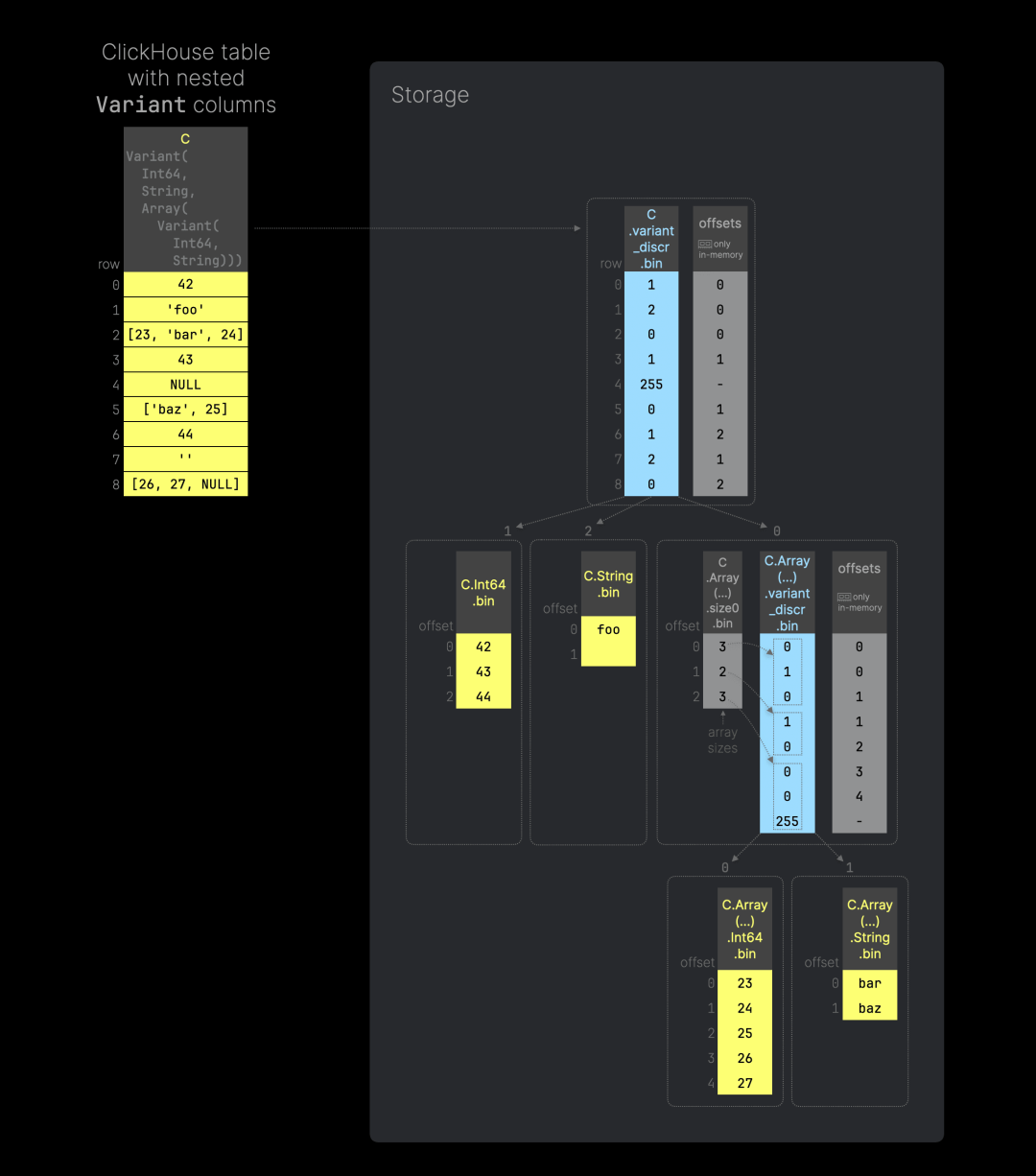
你可以在此处找到用于复现上图的 SQL 代码。这次,我们定义了变体列 C 来存储整数、字符串,以及包含变体值的数组——其中既有整数也有字符串。上图展示了 ClickHouse 如何在数组列的数据文件中嵌套使用我们之前介绍的变体存储方法,从而实现嵌套的变体类型。
读取嵌套的变体类型为子类型
列变体类型支持通过类型名称将某一嵌套类型的值从变体列中读取为子类型列。例如,你可以使用语法 C.Int64 读取上表中所有 Int64 子类型列的整数值:
SELECT C.Int64
FROM test;┌─C.Int64─┐
1. │ 42 │
2. │ ᴺᵁᴸᴸ │
3. │ ᴺᵁᴸᴸ │
4. │ 43 │
5. │ ᴺᵁᴸᴸ │
6. │ ᴺᵁᴸᴸ │
7. │ 44 │
8. │ ᴺᵁᴸᴸ │
9. │ ᴺᵁᴸᴸ │└─────────┘构建块 2 - 动态类型 (Dynamic type)
在变体类型之后,下一步是实现动态类型。与变体类型一样,动态类型也是一个独立的特性,可以在 JSON 上下文之外单独使用。
动态类型是在变体类型基础上的增强,带来了两项关键新功能:
-
无需预先指定类型,就可以在单个表列中存储任意数据类型的值。
-
可以限制作为独立列文件存储的类型数量,部分解决了我们关于列文件数目限制的第三个挑战。
我们将在下面简要介绍这两项新功能。
无需指定子类型
下图(可点击放大)展示了一个包含单个动态列的 ClickHouse 表及其磁盘上的存储方式(按数据部分存储):
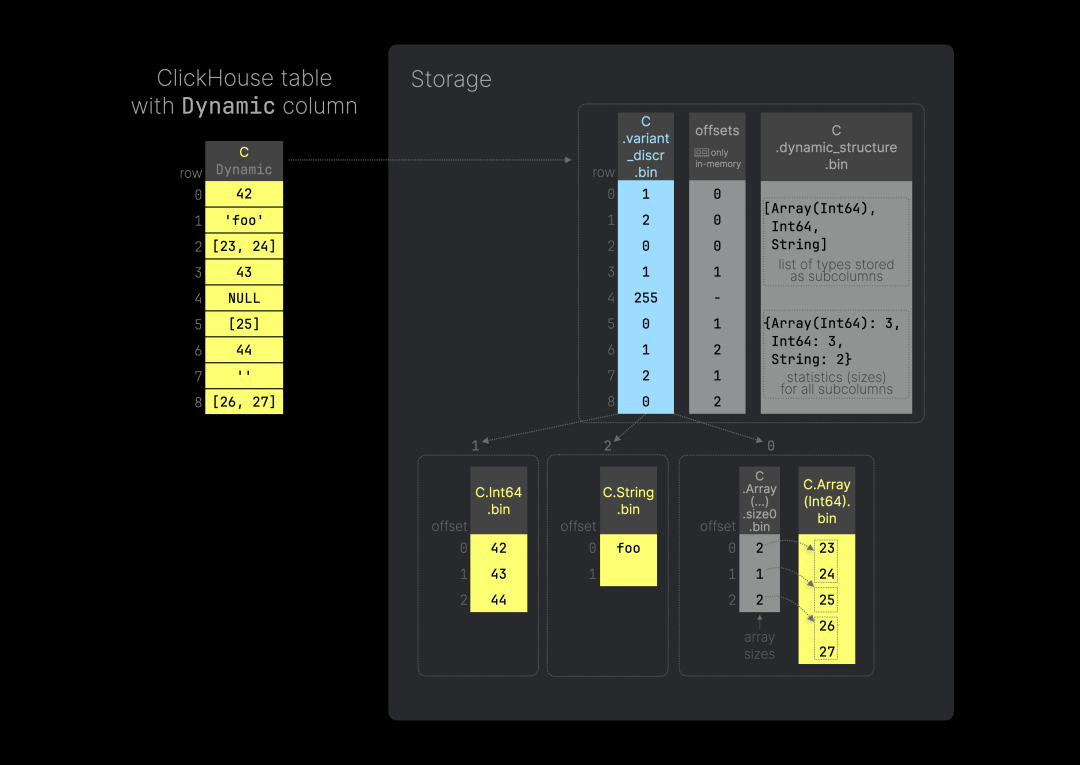
你可以使用以下 SQL 代码来重现上图中的表。我们可以在不预先指定类型的情况下,将任何类型的值插入到动态列 C 中,这与变体类型的使用方式类似。
在内部,动态列的存储方式与变体列类似,但额外包含了关于存储在该列中的类型信息。上图显示,与变体列不同的是,动态列多了一个名为 C.dynamic_structure.bin 的文件,该文件包含子列类型列表以及各类型变体列数据文件大小的统计信息。这些元数据用于读取子列和合并数据部分。
避免列文件过多
动态类型还支持通过指定 max_types 参数来限制存储为独立列文件的类型数量:Dynamic(max_types=N),其中 0 <= N < 255。默认情况下,max_types 的值为 32。当达到设置的类型数量限制时,剩余的类型将存储在一个特殊结构的单列文件中。下图展示了该示例(可点击放大查看):
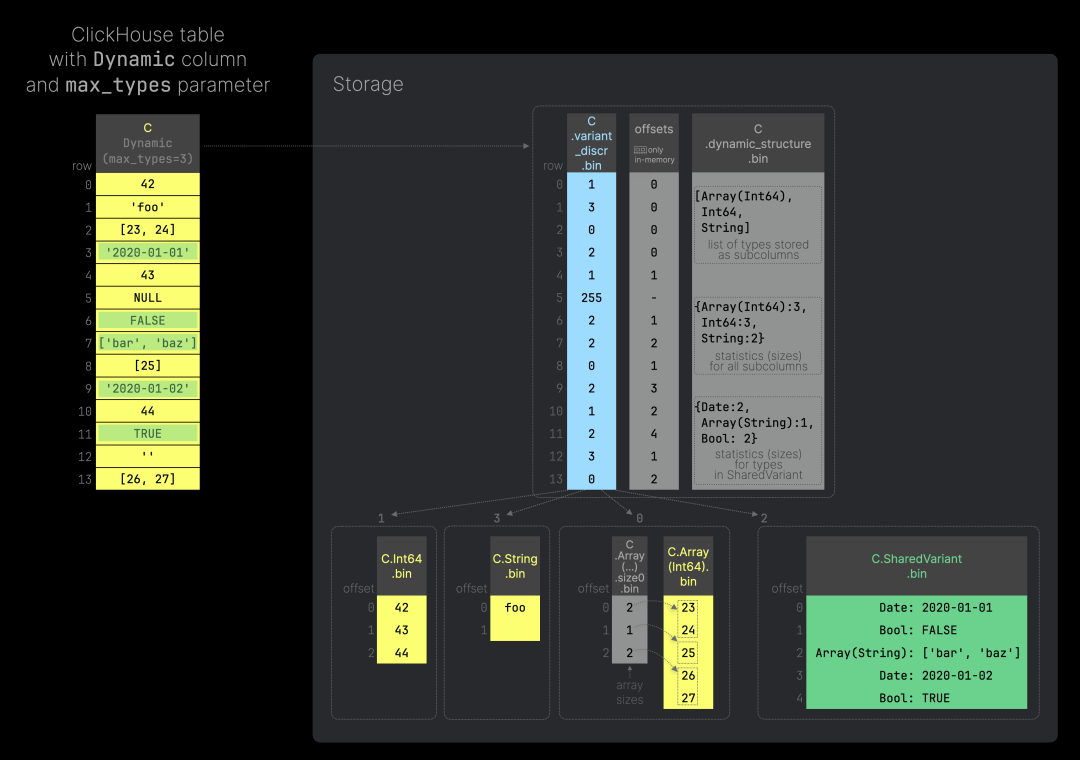
以下是用于生成上图示例表的 SQL 脚本。这次,我们将动态列 C 的 max_types 参数设置为 3。
因此,只有前三种类型被存储在独立的列文件中(这对数据压缩和分析查询非常有效)。所有其他使用的类型(在上图示例表中绿色标记的部分)都存储在一个名为 C.SharedVariant.bin 的单列文件中,该文件的类型为 String。SharedVariant 列中的每一行包含一个字符串值,内含以下数据:<二进制编码的数据类型><二进制值>。使用这种结构,我们可以在单列中存储和检索不同类型的值。
读取动态嵌套类型为子列
与变体类型类似,动态类型也支持通过子列的方式读取单一嵌套类型的值,使用类型名称作为子列进行操作:
SELECT C.Int64
FROM test;┌─C.Int64─┐
1. │ 42 │
2. │ ᴺᵁᴸᴸ │
3. │ ᴺᵁᴸᴸ │
4. │ 43 │
5. │ ᴺᵁᴸᴸ │
6. │ ᴺᵁᴸᴸ │
7. │ 44 │
8. │ ᴺᵁᴸᴸ │
9. │ ᴺᵁᴸᴸ │└─────────┘ClickHouse JSON 类型:集成汇总
在实现了变体类型 (Variant type) 和动态类型 (Dynamic type) 之后,我们构建了所有必要的基础组件,从而在 ClickHouse 的列式存储上实现了全新的强大 JSON 类型,成功应对了之前提到的所有挑战,具备以下关键特性:
-
动态数据处理:支持在同一 JSON 路径下存储不同的数据类型(可能存在不兼容且无法预知),无需统一为最小公共类型,保留混合类型数据的完整性。
-
高性能和密集的列存储:将任意 JSON 键路径以原生子列的方式存储和读取,实现高效的数据压缩,并保持经典数据类型的查询性能。
-
可扩展性:支持限制独立存储的子列数量,确保 JSON 存储可以扩展到 PB 级别数据集,并实现高性能分析。
-
优化调优:支持为 JSON 解析提供优化指引(如指定 JSON 路径的类型、跳过特定路径等)。
我们的新型 JSON 类型可以存储任意结构的 JSON 对象,并通过子列读取每个 JSON 值,路径作为子列进行管理。
JSON 类型声明
新 JSON 类型的声明中包含多个可选参数和提示:
<column_name> JSON(max_dynamic_paths=N, max_dynamic_types=M, some.path TypeName, SKIP path.to.skip, SKIP REGEXP 'paths_regexp')-
max_dynamic_paths(默认值为 1024):指定最多有多少 JSON 键路径可以单独存储为子列。如果超出此限制,所有其他路径将合并存储在一个特殊结构的单子列中。
-
max_dynamic_types(默认值为 32):介于 0 到 254 之间,指定一个 JSON 键路径列中最多可以有多少不同类型存储为独立列文件。如果超过此限制,所有新类型将存储在一个具有特殊结构的列文件中。
-
some.path TypeName:为特定 JSON 路径提供的类型提示。该路径将总是以指定类型存储为子列,并保证其性能。
-
SKIP path.to.skip:提示在 JSON 解析时跳过特定路径。这样的路径不会被存储在 JSON 列中。如果指定路径是嵌套 JSON 对象,则整个嵌套对象都会被跳过。
-
SKIP REGEXP 'path_regexp':一个正则表达式提示,用于在 JSON 解析过程中跳过匹配该表达式的所有路径。这些路径将不会存储在 JSON 列中。
真正的列式 JSON 存储
下图(可点击放大)展示了一个包含单个 JSON 列的 ClickHouse 表,以及该列的 JSON 数据如何高效地基于 ClickHouse 的列式存储实现(按数据部分存储):
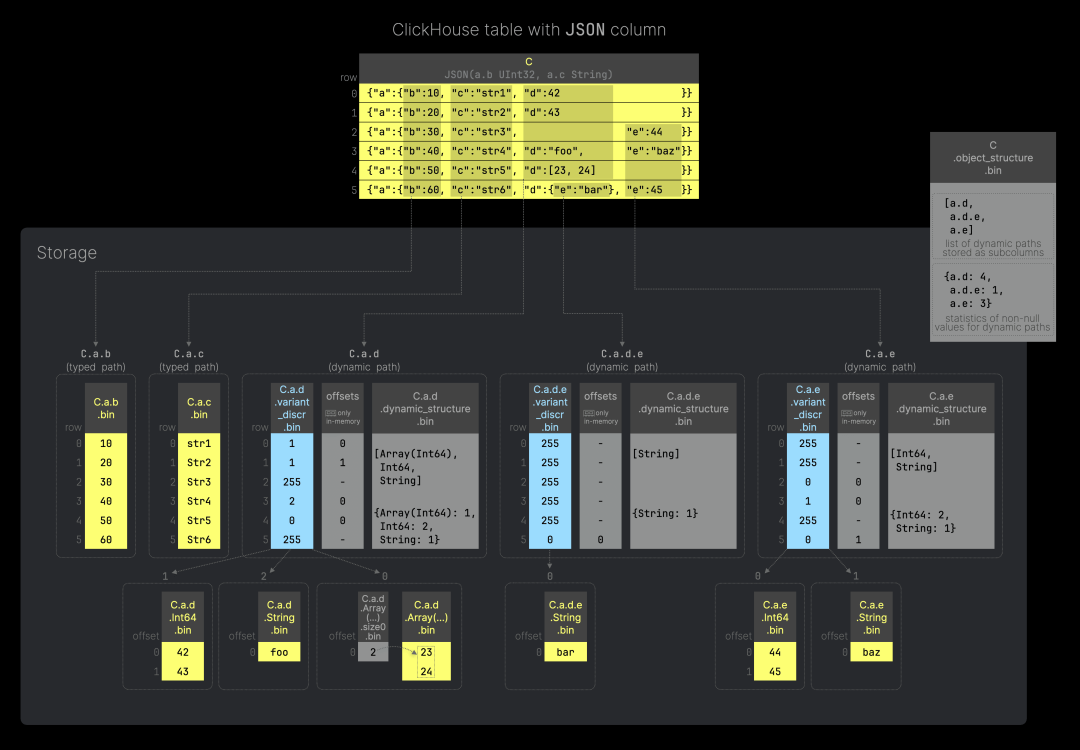
使用下面的 SQL 代码,可以创建与上图一致的表。示例表中的列 C 是 JSON 类型,我们为 JSON 路径 a.b 和 a.c 设置了两个类型提示。
该表列包含 6 个 JSON 文档,每个唯一 JSON 键路径的值会存储在磁盘上。对于具有类型提示的 JSON 路径(见上图中的 C.a.b 和 C.a.c),这些值会作为常规列数据文件存储;而对于可能包含动态变化数据的 JSON 路径(见上图中的 C.a.d、C.a.d.e 和 C.a.e),这些值会作为动态子列存储。对于后者,ClickHouse 使用动态数据类型进行存储。
此外,JSON 类型还使用了一个特殊的文件(object_structure),该文件包含有关动态路径的元数据信息以及每个动态路径非空值的统计信息(在列序列化过程中计算)。这些元数据用于读取子列和合并数据部分。
避免列文件数量过多
为防止在以下场景中出现大量列文件:(1) 单个 JSON 键路径下存在许多动态类型,(2) 存在大量独特的动态 JSON 键路径,JSON 类型引入了以下机制:
(1) 使用 max_dynamic_types 参数(默认值 32),限制在单个 JSON 键路径中存储为独立列文件的不同数据类型数量。
(2) 使用 max_dynamic_paths 参数(默认值 1024),限制以子列形式单独存储的 JSON 键路径数量。
通过这些限制机制,解决了列文件数量过多的第三个挑战。
我们已经在上文展示了(1)的例子。现在,通过下图展示(2)(可点击放大):

以下是生成该图示表的 SQL 代码。与之前的例子类似,我们的 ClickHouse 表中的列 C 为 JSON 类型,我们为 JSON 路径 a.b 和 a.c 设置了类型提示。
此外,我们将 max_dynamic_paths 参数设置为 3。这意味着 ClickHouse 只会将前三个动态 JSON 路径的叶子值作为动态子列存储(使用动态类型)。
带有类型信息和值的动态 JSON 路径(在上图中绿色标记部分)被存储为共享数据——如图中的 C.object_shared_data.size0.bin、C.object_shared_data.paths.bin 和 C.object_shared_data.values.bin 文件。请注意,共享数据文件(object_shared_data.values)的类型为 String。每个条目都是一个字符串值,包含以下数据:<二进制编码的数据类型><二进制值>。
通过共享数据机制,我们还在 object_structure.bin 文件中存储了额外的统计信息(用于读取子列和合并数据部分)。这些统计信息包括共享数据列中最多前 10000 条路径的非空值数据。目前,我们仅为前 10000 条路径存储统计信息。
读取 JSON 路径
JSON 类型支持通过路径名将叶子值读取为子列。例如,表中 JSON 路径 a.b 的所有值可以使用语法 C.a.b 进行读取:
SELECT C.a.b
FROM test;┌─C.a.b─┐
1. │ 10 │
2. │ 20 │
3. │ 30 │
4. │ 40 │
5. │ 50 │
6. │ 60 │└───────┘如果在 JSON 类型声明中没有为请求路径提供类型提示,该路径的值将默认为 Dynamic 类型:
SELECTC.a.d,toTypeName(C.a.d)
FROM test;┌─C.a.d───┬─toTypeName(C.a.d)─┐
1. │ 42 │ Dynamic │
2. │ 43 │ Dynamic │
3. │ ᴺᵁᴸᴸ │ Dynamic │
4. │ foo │ Dynamic │
5. │ [23,24] │ Dynamic │
6. │ ᴺᵁᴸᴸ │ Dynamic │└─────────┴───────────────────┘你还可以使用特殊的 JSON 语法 JSON_column.some.path.:TypeName: 读取 Dynamic 类型的子列:
SELECT C.a.d.:Int64
FROM test;┌─C.a.d.:`Int64`─┐
1. │ 42 │
2. │ 43 │
3. │ ᴺᵁᴸᴸ │
4. │ ᴺᵁᴸᴸ │
5. │ ᴺᵁᴸᴸ │
6. │ ᴺᵁᴸᴸ │└────────────────┘此外,JSON 类型支持通过特殊语法 JSON_column.^some.path: 将嵌套的 JSON 对象作为子列读取,类型为 JSON。
SELECT C.^a
FROM test;┌─C.^`a`───────────────────────────────────────┐
1. │ {"b":10,"c":"str1","d":"42"} │
2. │ {"b":20,"c":"str2","d":"43"} │
3. │ {"b":30,"c":"str3","e":"44"} │
4. │ {"b":40,"c":"str4","d":"foo","e":"baz"} │
5. │ {"b":50,"c":"str5","d":["23","24"]} │
6. │ {"b":60,"c":"str6","d":{"e":"bar"},"e":"45"} │└──────────────────────────────────────────────┘SELECT toTypeName(C.^a)
FROM test
LIMIT 1;┌─toTypeName(C.^`a`)───────┐
1. │ JSON(b UInt32, c String) │└──────────────────────────┘目前,出于性能考虑,点语法不支持读取嵌套对象。数据存储方式使得按路径读取字面值非常高效,但按路径读取所有子对象则需要读取更多数据,可能导致性能下降。因此,当需要返回一个对象时,必须使用 .^ 语法。我们计划在未来统一这两种不同的点语法。
紧凑判别器序列化
在许多场景中,动态 JSON 路径的值大多为相同类型。在这种情况下,动态类型的判别器文件中主要包含相同的类型判别值。
类似地,当存储大量唯一但稀疏的 JSON 路径时,每个路径的判别器文件中主要包含 255(表示 NULL 值)。
虽然这些文件会被很好地压缩,但当所有行的判别值相同时,仍会产生一些冗余。
为了解决这一问题,我们实现了一种紧凑的判别器序列化格式。与常规的 UInt8 值不同,如果目标颗粒中的所有判别器相同,我们只会序列化 3 个值(而不是 8192 个):
-
紧凑格式的指示符
-
颗粒中值的数量
-
判别器的具体值
这一优化可以通过 MergeTree 设置 use_compact_variant_discriminators_serialization(默认启用)进行控制。
这仅仅是开始
在本文中,我们介绍了如何从零开始开发全新的 JSON 类型,首先构建了一些基础组件,这些组件不仅适用于 JSON,还有更广泛的应用场景。
这个新 JSON 类型被设计为替代已经弃用的 Object('json') 数据类型,解决了其局限性并提升了整体功能。
目前,该新实现已作为实验版本发布,供用户测试使用,但功能仍在不断完善中。我们的 JSON 开发路线图还包括一些强大的功能升级,例如在表的主键或数据跳过索引中使用 JSON 键路径。
同样值得关注的是,我们为实现新 JSON 类型所创建的基础组件,已经为扩展 ClickHouse 支持其他半结构化数据类型(如 XML、YAML 等)铺平了道路。
请持续关注我们即将发布的文章,届时我们将展示新 JSON 类型的主要查询功能、基于真实数据的应用案例,以及数据压缩和查询性能的基准测试。同时,我们还会深入剖析 JSON 实现的内部机制,探讨数据在内存中如何高效地合并与处理。
如果您正在使用 ClickHouse Cloud,并希望测试我们的新 JSON 数据类型,请联系支持团队以获取私密预览权限。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求



















