早年就在Elasticsearch上看到过机器学习模块,局限于需要开通白金及以上订阅,没有尝试过该模块,OpenSearch在2.6还是哪个版本已经内置该插件。
文章参考:https://opensearch.org/docs/latest/search-plugins/neural-search-tutorial/#top
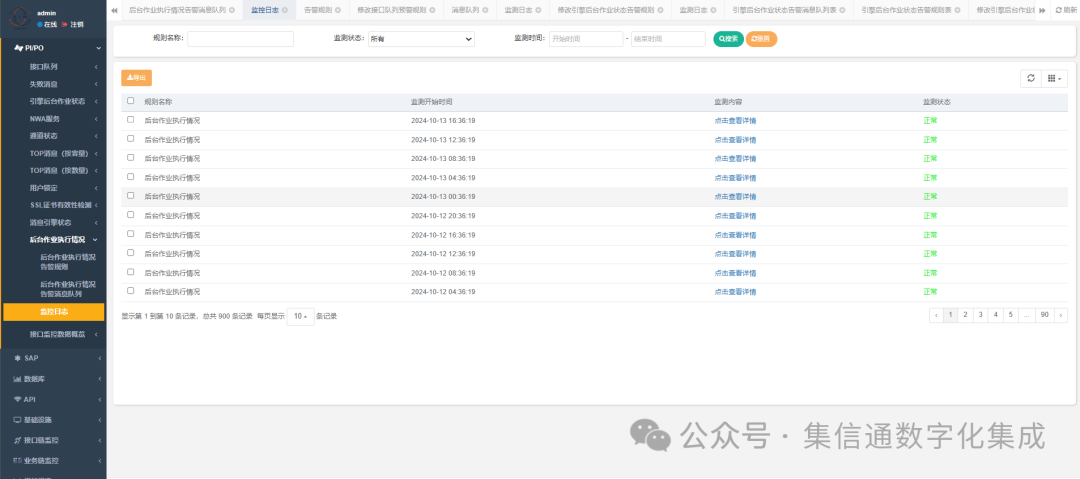
1. 查看插件列表
opensearch-ml就是机器学习插件。
GET /_cat/plugins
node-1 opensearch-alerting 2.17.1.0
node-1 opensearch-anomaly-detection 2.17.1.0
node-1 opensearch-asynchronous-search 2.17.1.0
node-1 opensearch-cross-cluster-replication 2.17.1.0
node-1 opensearch-custom-codecs 2.17.1.0
node-1 opensearch-flow-framework 2.17.1.0
node-1 opensearch-geospatial 2.17.1.0
node-1 opensearch-index-management 2.17.1.0
node-1 opensearch-job-scheduler 2.17.1.0
node-1 opensearch-knn 2.17.1.0
node-1 opensearch-ml 2.17.1.0
node-1 opensearch-neural-search 2.17.1.0
node-1 opensearch-notifications 2.17.1.0
node-1 opensearch-notifications-core 2.17.1.0
node-1 opensearch-observability 2.17.1.0
node-1 opensearch-performance-analyzer 2.17.1.0
node-1 opensearch-reports-scheduler 2.17.1.0
node-1 opensearch-security 2.17.1.0
node-1 opensearch-security-analytics 2.17.1.0
node-1 opensearch-skills 2.17.1.0
node-1 opensearch-sql 2.17.1.0
node-1 opensearch-system-templates 2.17.1.0
node-1 query-insights 2.17.1.0
步骤 1:建立 ML 语言模型
神经搜索需要语言模型来在摄取时和查询时从文本字段生成向量嵌入。
步骤 1(a):选择语言模型
在本教程中,您将使用Hugging Face 的DistilBERT模型。它是 OpenSearch 中可用的预训练句子转换器模型之一,在基准测试中显示出一些最佳结果(有关详细信息,请参阅此博客文章)。您需要模型的名称、版本和维度才能注册它。您可以通过选择与模型的 TorchScript 工件相对应的链接在预训练模型表中找到此信息config_url:
- 模型名称为huggingface/sentence-transformers/msmarco-distilbert-base-tas-b。
- 模型版本是1.0.1。
- 该模型的维数为768。
记下模型的维数,因为在设置 k-NN 索引时需要它。
步骤 1(b):注册模型组
POST /_plugins/_ml/model_groups/_register
{"name": "NLP_model_group","description": "A model group for NLP models"
}
- 此处模型组id返回为
21en15IBr7hYQeyMk7-W
您将使用此 ID 将所选模型注册到模型组。
步骤 1©: 将模型注册到模型组
POST /_plugins/_ml/models/_register
{"name": "huggingface/sentence-transformers/msmarco-distilbert-base-tas-b","version": "1.0.1","model_group_id": "21en15IBr7hYQeyMk7-W","model_format": "TORCH_SCRIPT"
}
- 此处模型id返回为
5Veo15IBr7hYQeyM5b_B
获取模型是否创建完成(任务状态将为COMPLETED)
GET /_plugins/_ml/tasks/5Veo15IBr7hYQeyM5b_B
这里需要注意,模型拉取可能会失败,所以我测试环境使用了离线注册
离线注册
1. 手动下载文件到一个文件服务器
搭建一个nginx,做文件服务器,把下载好的模型文件,放到路径下,通过http访问后,右键该文件,复制下载链接。
2.集群设置
- 配置集群可以设置离线注册
PUT _cluster/settings
{"persistent": {"plugins.ml_commons.allow_registering_model_via_url": true}
}
- 允许机器学习运行在任意节点
PUT _cluster/settings
{"persistent": {"plugins.ml_commons.only_run_on_ml_node": false}
}
- 禁用自动部署
PUT _cluster/settings
{"persistent": {"plugins.ml_commons.model_auto_deploy.enable": "false"}
}
3. 离线注册
POST /_plugins/_ml/models/_register
{"name": "sentence-transformers/msmarco-distilbert-base-tas-b","version": "1.0.1","description": "This is a port of the DistilBert TAS-B Model to sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and is optimized for the task of semantic search.","model_task_type": "TEXT_EMBEDDING","model_format": "ONNX","model_content_size_in_bytes": 266291330,"model_content_hash_value": "a3c916f24239fbe32c43be6b24043123d49cd2c41b312fc2b29f2fc65e3c424c","model_config": {"model_type": "distilbert","embedding_dimension": 768,"framework_type": "huggingface_transformers","pooling_mode": "CLS","normalize_result": false,"all_config": "{\"_name_or_path\":\"old_models/msmarco-distilbert-base-tas-b/0_Transformer\",\"activation\":\"gelu\",\"architectures\":[\"DistilBertModel\"],\"attention_dropout\":0.1,\"dim\":768,\"dropout\":0.1,\"hidden_dim\":3072,\"initializer_range\":0.02,\"max_position_embeddings\":512,\"model_type\":\"distilbert\",\"n_heads\":12,\"n_layers\":6,\"pad_token_id\":0,\"qa_dropout\":0.1,\"seq_classif_dropout\":0.2,\"sinusoidal_pos_embds\":false,\"tie_weights_\":true,\"transformers_version\":\"4.7.0\",\"vocab_size\":30522}"},"created_time": 1676074079195,"model_group_id": "21en15IBr7hYQeyMk7-W","url": "http://192.168.113.85:8080/public/%e5%9f%ba%e7%a1%80%e7%bb%84%e4%bb%b6%e5%ae%89%e8%a3%85%e5%8c%85/Linux/OpenSearch/%e5%b0%8f%e6%a8%a1%e5%9e%8b/sentence-transformers_msmarco-distilbert-base-tas-b-1.0.1-onnx.zip"
}
- 此处返回task id为QVe915IBr7hYQeyMO8Ci,模型id为RVe915IBr7hYQeyMPsAj。
查看注册状态
GET /_plugins/_ml/tasks/QVe915IBr7hYQeyMO8Ci
步骤 1(d):部署模型
POST /_plugins/_ml/models/RVe915IBr7hYQeyMPsAj/_deploy
获取部署状态
GET /_plugins/_ml/models/RVe915IBr7hYQeyMPsAj第 2 步:使用神经搜索提取数据
创建ingest-pipeline
PUT /_ingest/pipeline/nlp-ingest-pipeline
{"description": "An NLP ingest pipeline","processors": [{"text_embedding": {"model_id": "RVe915IBr7hYQeyMPsAj","field_map": {"text": "passage_embedding"}}}]
}
新建索引
PUT /my-nlp-index
{"settings": {"index.knn": true,"default_pipeline": "nlp-ingest-pipeline"},"mappings": {"properties": {"id": {"type": "text"},"passage_embedding": {"type": "knn_vector","dimension": 768,"method": {"engine": "lucene","space_type": "l2","name": "hnsw","parameters": {}}},"text": {"type": "text"}}}
}
导入数据
PUT /my-nlp-index/_doc/1
{"text": "A West Virginia university women 's basketball team , officials , and a small gathering of fans are in a West Virginia arena .","id": "4319130149.jpg"
}PUT /my-nlp-index/_doc/2
{"text": "A wild animal races across an uncut field with a minimal amount of trees .","id": "1775029934.jpg"
}PUT /my-nlp-index/_doc/3
{"text": "People line the stands which advertise Freemont 's orthopedics , a cowboy rides a light brown bucking bronco .","id": "2664027527.jpg"
}PUT /my-nlp-index/_doc/4
{"text": "A man who is riding a wild horse in the rodeo is very near to falling off .","id": "4427058951.jpg"
}PUT /my-nlp-index/_doc/5
{"text": "A rodeo cowboy , wearing a cowboy hat , is being thrown off of a wild white horse .","id": "2691147709.jpg"
}
查看doc1
GET /my-nlp-index/_doc/1
关键字搜索
GET /my-nlp-index/_search
{"_source": {"excludes": ["passage_embedding"]},"query": {"match": {"text": {"query": "wild west"}}}
}
文档 3 未返回,因为它不包含指定的关键字。包含单词rodeo和的文档cowboy得分较低,因为未考虑语义含义。
模型神经搜索
GET /my-nlp-index/_search
{"_source": {"excludes": ["passage_embedding"]},"query": {"neural": {"passage_embedding": {"query_text": "wild west","model_id": "RVe915IBr7hYQeyMPsAj","k": 5}}}
}
这次,响应不仅包含所有五个文档,而且文档顺序也得到了改善,因为神经搜索考虑了语义含义。