文章目录
- chat bot重大进展
- 基于编码器的预训练模型
- word embedding
- ELMO
- BERT
- GPT:基于解码器的预训练模型
- GPT1:Improving Language Understanding by Generative Pre-Training
- finetune如何实现
- 实验
- GPT2:Language Models are Unsupervised Multitask Learners
- abstract
- 数据集
- GPT3:Language Models are Few-Shot Learners
- abstract
- method
- dataset
- limitation
- InstructGPT
- 提示学习与指令微调
- method
- prompt具体是怎么训练的?
- RM model
- RL model
- 数据集
- 从Word Embedding到Bert模型——自然语言处理中的预训练技术发展史
- GPT,GPT-2,GPT-3 论文精读【论文精读】by李沐
chat bot重大进展
- ToolFormer:可以连API,一部分知识用LLM回复,也可以联网,使用现有的API(比如计算问题)进行解答,避免了LLM训练以后知识库无法更新的短板;
- meta LLaMA:参数量从 70 亿到 650 亿不等,13B参数的 LLaMA 模型「在大多数基准上」可以胜过参数量达 175B的 GPT-3,而且可以在单块 V100 GPU 上运行;
- Visual ChatGPT:可以接受图像输入,进行理解,但是还无法生成图像;多模态的一步进展。
- GigaGAN:10亿参数的GAN网络,在生成效果上媲美diffusion,DALL-E,而且速度也有优势;
- 斯坦福的Alpha:7B参数的模型+52k数据,和open AI175B的模型效果相媲美;
- 谷歌Claude:号称安全性更高
- 微软Copilot:自动生成报表,PPT,写文档,解放(代替)打工人
基于编码器的预训练模型
word embedding
- word embedding:每个单词one-hot编码的向量矩阵,在大语言训练之后,该矩阵可以直接提取出来,作为word embedding提取器,用于计算单词的相似度等;其中提取word embedding的方式word2vec的训练有两种:(1)提供上下文,预测目标单词,CBOW(continuous bag-of-word model);(2)当前单词预测前后的单词。
- 缺点:当同一单词有不同含义的时候无法区分
ELMO
- 在word embedding的基础上,对上下文信息进行编码,对于当前单词提供出来的是word embedding, 双向LSTM前向编码的结果,反向编码的结果(其中后两项有比较强的语义信息)。
BERT
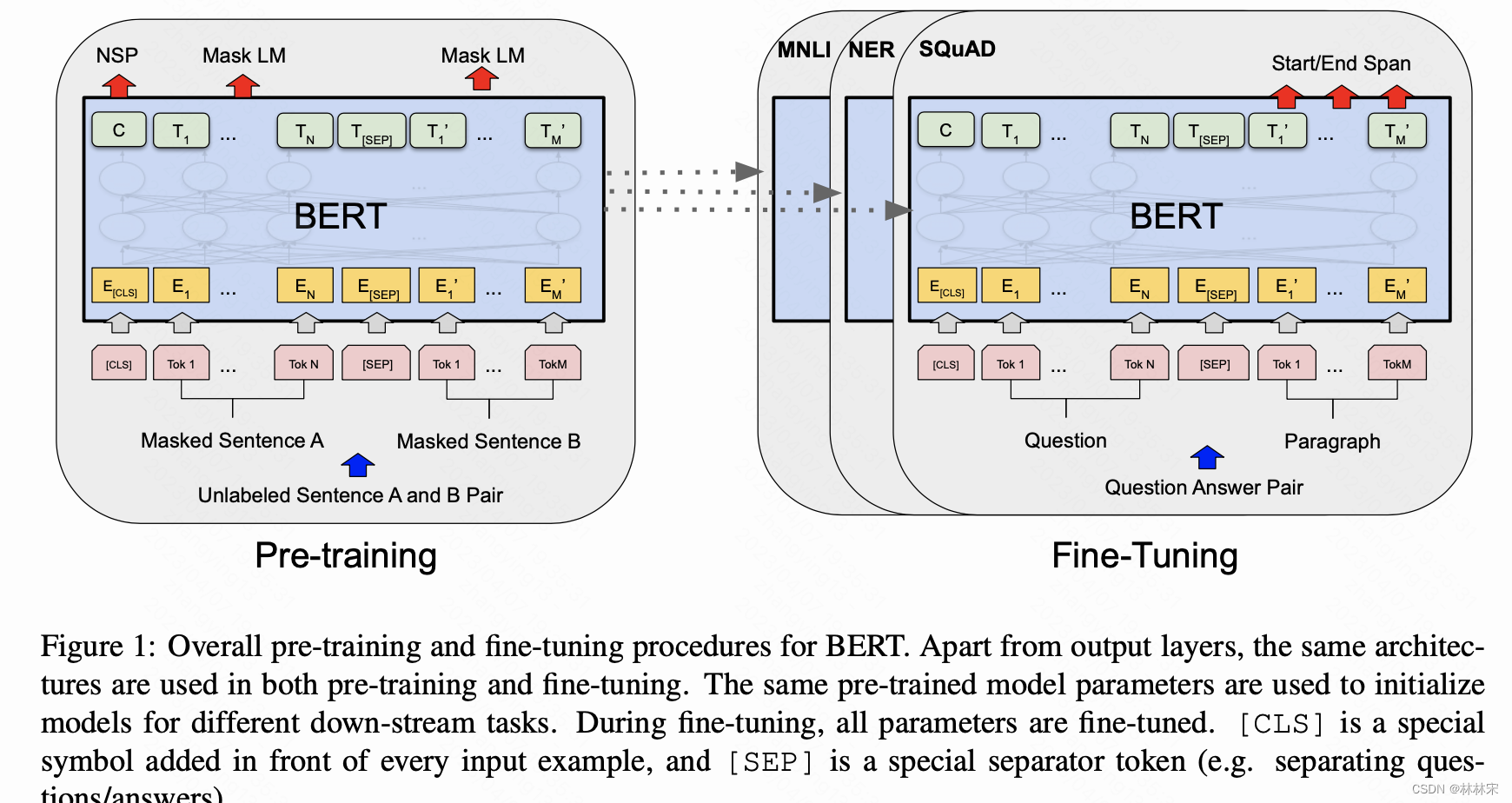
通过掩码语言建模和下一句预测任务,对 Transformer 模型的参数进行预训练。
- 使用transformer结构,且使用了双向编码的结果
- 使用了CBOW的方法,训练的时候,对于一个句子,随机mask一定比例的单词,作为预测目标。(为了避免训练把mask映射,部分mask不是替换成【mask】的方式,而是随机换成其他的单词,或者不做mask)
- in-context学习的能力,对于下游任务,只需要对数据结构作一定的修改,仍然使用此结构,在重多任务上都取得比较好的结果。
GPT:基于解码器的预训练模型
- 使用transformer结构,长距离编码的能力显著优于BLSTM
- 但是只提供了前向编码的结果,没有考虑上下文信息
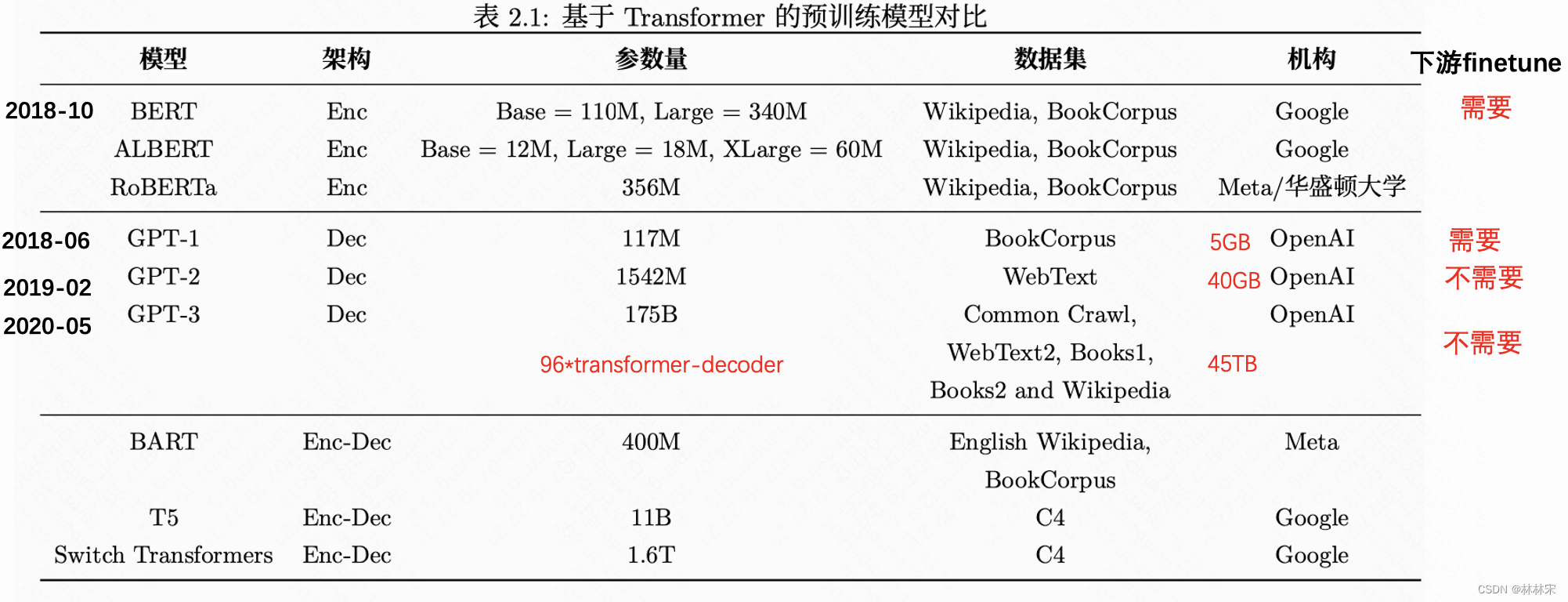
GPT1:Improving Language Understanding by Generative Pre-Training
- 设计逻辑:使用大量无标注的文本进行预训练,训练的时候通过自回归的方式,(x1,x2,x3)预测下一个token x4;然后对特殊任务进行有标签数据的finetune;
- 传统的NLP不同子任务需要设计不同的模型结构,GPT提出可以通过不同的数据构造方式,不需要改变模型结构。
- 无监督数据训练的难点:(1)选择损失函数。——自监督学习(论文中当时称呼的是半监督学习)
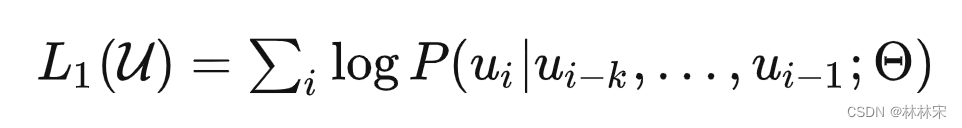
- 模型是transformer-decoder的结构,只能看见前k-1个词,然后预测第k个词;(相对更难的问题)
- BERT是一个完形填空问题,在一个句子中间mask掉某个词,然后该词前后的文本都可见,预测mask的单词内容是什么。
finetune如何实现
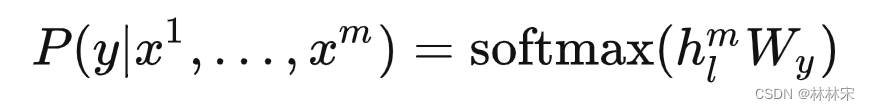
- finetune的任务定义,给定输入序列 [ x 1 , x 2 , . . . , x m ] [x^1, x^2,..., x^m] [x1,x2,...,xm],预测他们对应的label y y y
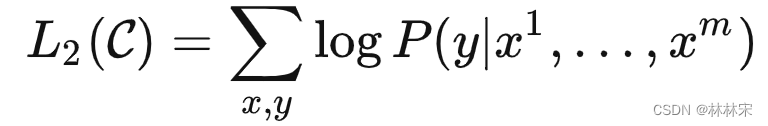
- 该问题对应的loss函数设计
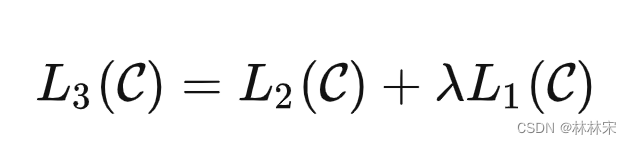
- 真正在训练的时候,把 L 1 L_1 L1 loss也考虑进去,会提升模型的性能。
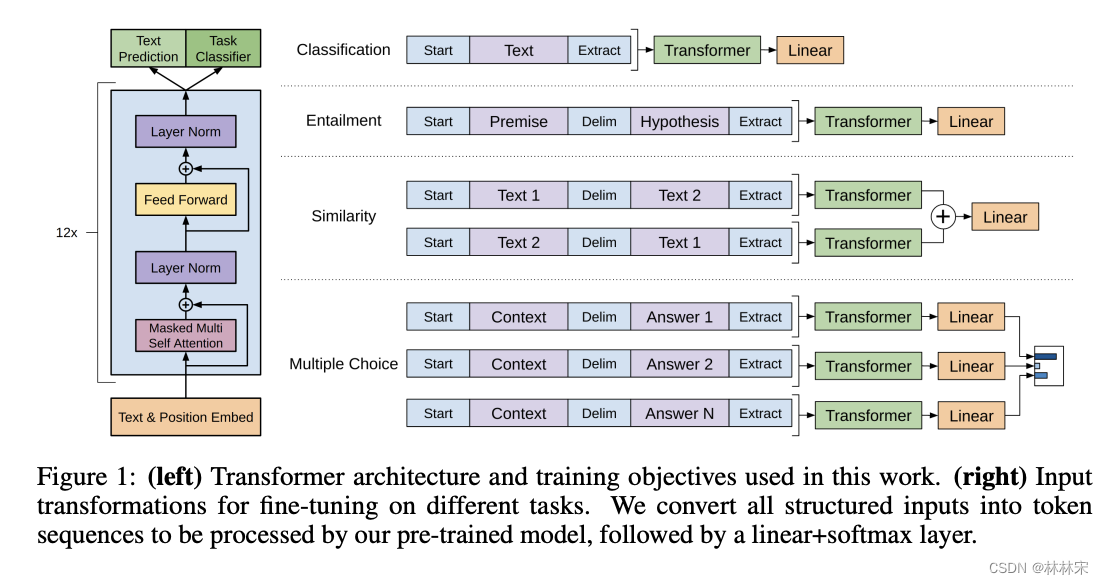
- transformer是预训练的模型,参数freeze;linear是在finetune阶段添加的特定层,与设置的任务有关;对于不同的任务,构造不同形式的输入,但是都送给预训练的transformer中;
- NLP四大经典任务:(1)分类;(2)蕴含关系;(3)相似度计算:a+b=b+a;(4)问答:同一问题,多个备选答案,softmax多分类,计算不同答案的置信度;
实验
- 12层transformer,unit size=768
- 7000本未发表的书,BooksCorpus
GPT2:Language Models are Unsupervised Multitask Learners
abstract
- 模型更大,数据量更多。
- 提出的新意:对于下游任务,不需要额外的finetune,zero-shot的场景可用;预测从GPT1的 P ( o u t p u t ∣ i n p u t ) P(output|input) P(output∣input)到 P ( o u t p u t ∣ i n p u t ; t a s k ) P(output|input;task) P(output∣input;task)
- 提出prompt的使用:因为下游任务不再finetune,不同任务的数据构造方式不一样,像GPT1中出现的起止符,分割符对于模型而言是unseen,会造成问题。为了解决这一问题,给到prompt这样的提示,举例说明((translate to
french, english text, french text)——任务:把英语翻译成法语,英语文本,对应的法语文本。
数据集
-
reddit(美国的新闻聚合网页),选取有三条评论以上的网页;数据集中有类似prompt提示的组合(并非严格的格式一致)。
-
结果:和其他zero-shot的base相比,会好一些;但是和sota的任务对比,只有在生成摘要的任务上达到相近的效果,其他的都还有差距。(但是能看到,随着模型参数的增加,效果是一直在变好的)
GPT3:Language Models are Few-Shot Learners
abstract
- 自回归的大模型,在子任务上不需要finetune;可以生成fake news
- 预训练+finetune存在的问题:(1)子任务仍然需要大量的标注数据;(2)如果微调的任务是unseen的,finetune之后结果好(有可能过拟合了)并不能说明pre-trained model效果好;——如果不允许finetune,效果好才说明是预训练模型效果好。
method


- in-context learning:如上图所示,可以根据给到的任务描述&example&prompt,给出真实的预测结果。上下文范围内的内容理解。
- 存在的问题:不能很好的利用到few-shot的样本(如果样本数量比较多的话)
- 层数增加,每一层的multi-head也要增加。GPT3做成一个宽的模型。大的模型用更大的bs,lr降低(这些有相对应的研究在)。(小模型更容易过拟合,小的bs会引入噪音)
- 分类问题:回答是true/false,代替二分类;
- 问答问题:beam search找到一个最好的答案
dataset
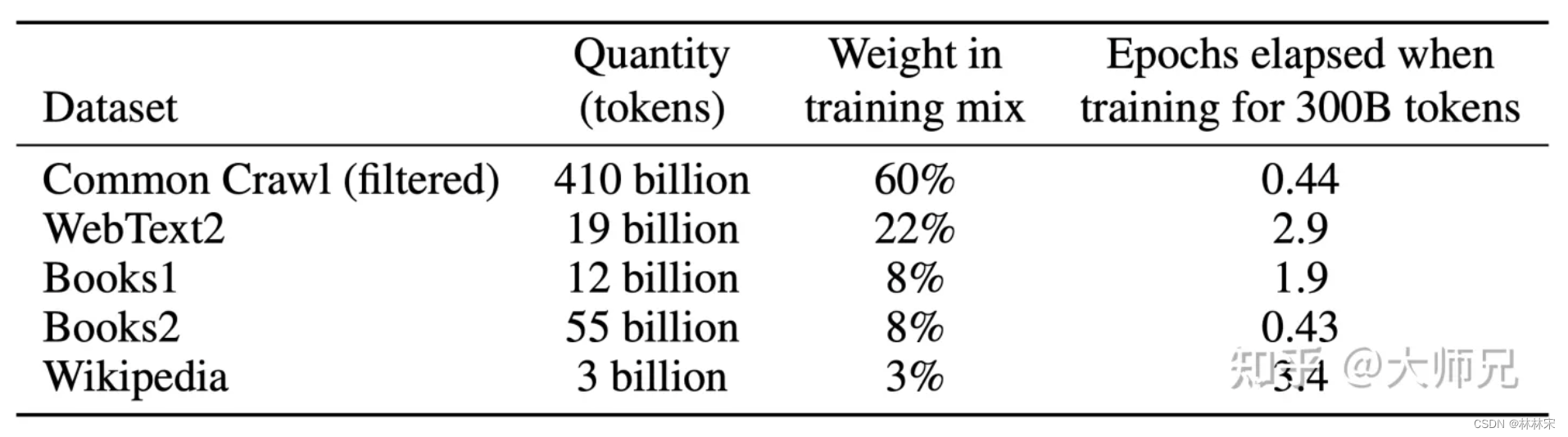
- common crawl:数据清洗:(1)gpt2的reddit数据作为正例,common crawl的数据作为负例,训练二分类分类器;然后设置分类的阈值;(2)去重;
- 已知的高质量数据集
- 不同的数据集进行一定比例的采样,然后再使用
limitation
- (1)长文本会生成重复的文本;
- (2)结构的局限性,只能看到过去的内容;
- (3)预测词的时候均匀的预测,没有对不同的词加weight;
- (4)不确定是从头学习的,还说from search(纯粹拼数据量的大小)
- 模型因为训练集的问题,可能会带有种族,性别的偏见。
InstructGPT
提示学习与指令微调
- prompt learning:构造输入数据的形式,将原来的监督任务变成生成任务。比如”我今天考砸了“,分类任务是判别一种情感概率;提示学习变成,输出”我感觉很_____“,生成内容后,再通过应设函数,将生成内容匹配到分类标签上。编辑输入来深挖模型 自身所蕴含的潜在知识,进而更好的完成下游任务。
- 提示学习还可以用于语境学习,比如“美国的首都是华盛顿, 法国的首都是巴黎,英国的首都是 ____”,适用于推理任务的思维链。
- instruct tuning(指令微调):提示学习的进阶版,模型要做的不仅是生成补全,还需要根据提示/任务要求做出相应的回复。–InstructGPT.可以帮助模型更深层的进行语义理解,当指令到达一定数量级以后,zero-shot就成为可能。
- 请帮我写一首描绘春天的诗词,诗词中要有鸟、花、草。
- 请帮我把下面这句话进行中文分词“我太喜欢 ChatGPT 了!”
method
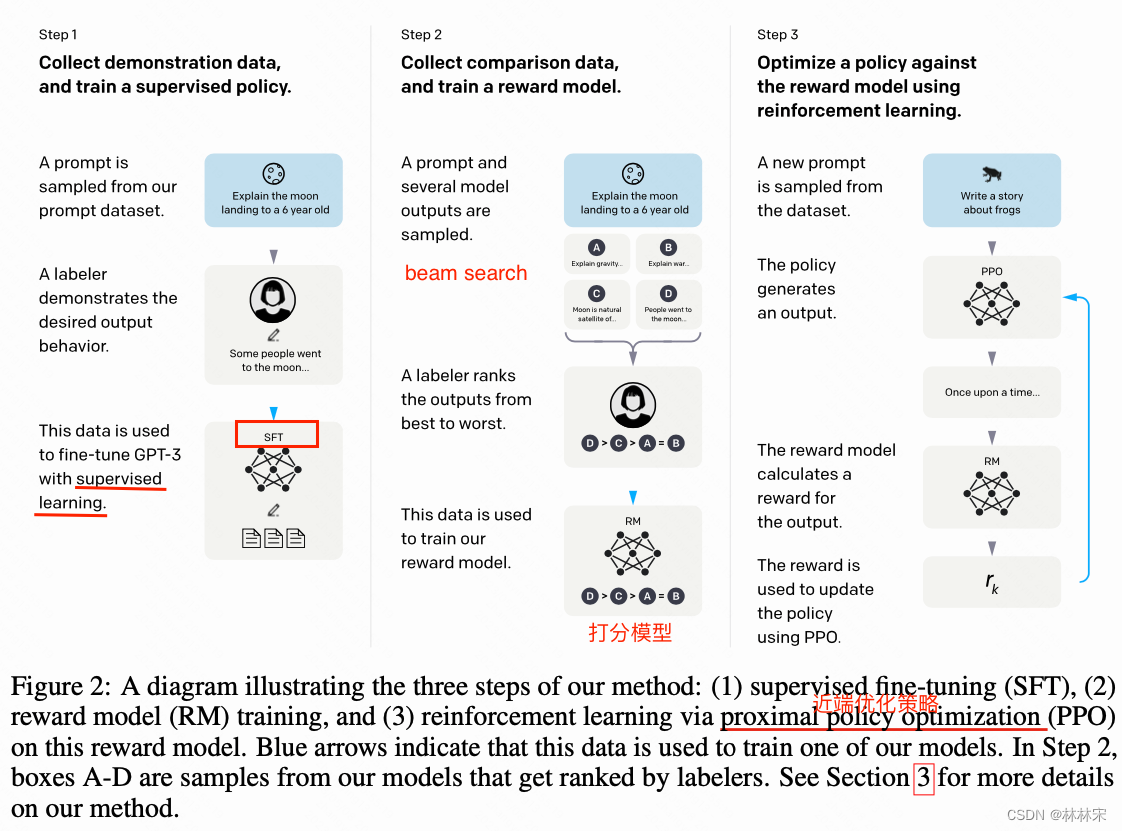
- 训练过程分为三个阶段
- stage 1:使用prompt learning,先人工标注的方法写一些prompt(包括问答,翻译,缩写,扩写等等),训练一个初版模型,放到平台上供用户使用,进而收集更多的prompt,且是真实场景一致的。此过程的模型称之为SFT model。
- 把GPT3这个模型,在标注好的第一个数据集(问题+答案)上面重新训练一次。由于只有13000个数据,1个epoch就过拟合,不过这个模型过拟合也没什么关系,甚至训练更多的epoch对后续是有帮助的,最终训练了16个epoch。
- stage2:除去用户写prompt以外,用各种现有的模型,生成一些prompt的回复,然后人工进行打分&排序,根据排序的结果训练打分模型;此过程的模型称之为RM model
- stage 3:对于没有答案的prompt,prompt送给模型生成结果,送给RM模型打分,将打分结果反馈给生成模型。这一阶段称之为PPO,此过程的模型称之为RL model。
- stage 1:使用prompt learning,先人工标注的方法写一些prompt(包括问答,翻译,缩写,扩写等等),训练一个初版模型,放到平台上供用户使用,进而收集更多的prompt,且是真实场景一致的。此过程的模型称之为SFT model。
prompt具体是怎么训练的?
问题和答案进行拼接,一起送给模型,自回归的方式预测下一个词,之后的词被mask。
RM model
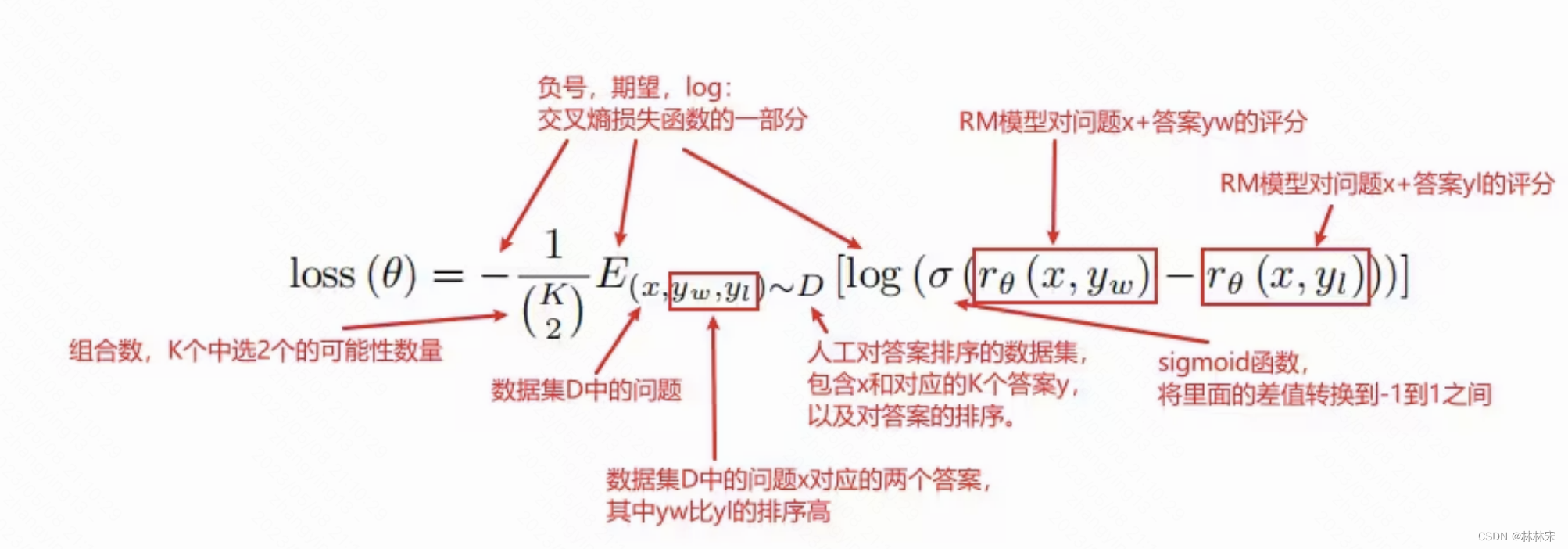
- Pairwise Ranking Loss
把SFT模型最后的unembedding层去掉,即最后一层不用softmax,改成一个线性层,这样RM模型就可以做到输入问题+答案,输出一个标量的分数。
RM模型使用6B,而不是175B的原因:
- 小模型更便宜
- 大模型不稳定,loss很难收敛。如果你这里不稳定,那么后续再训练RL模型就会比较麻烦。
RL model
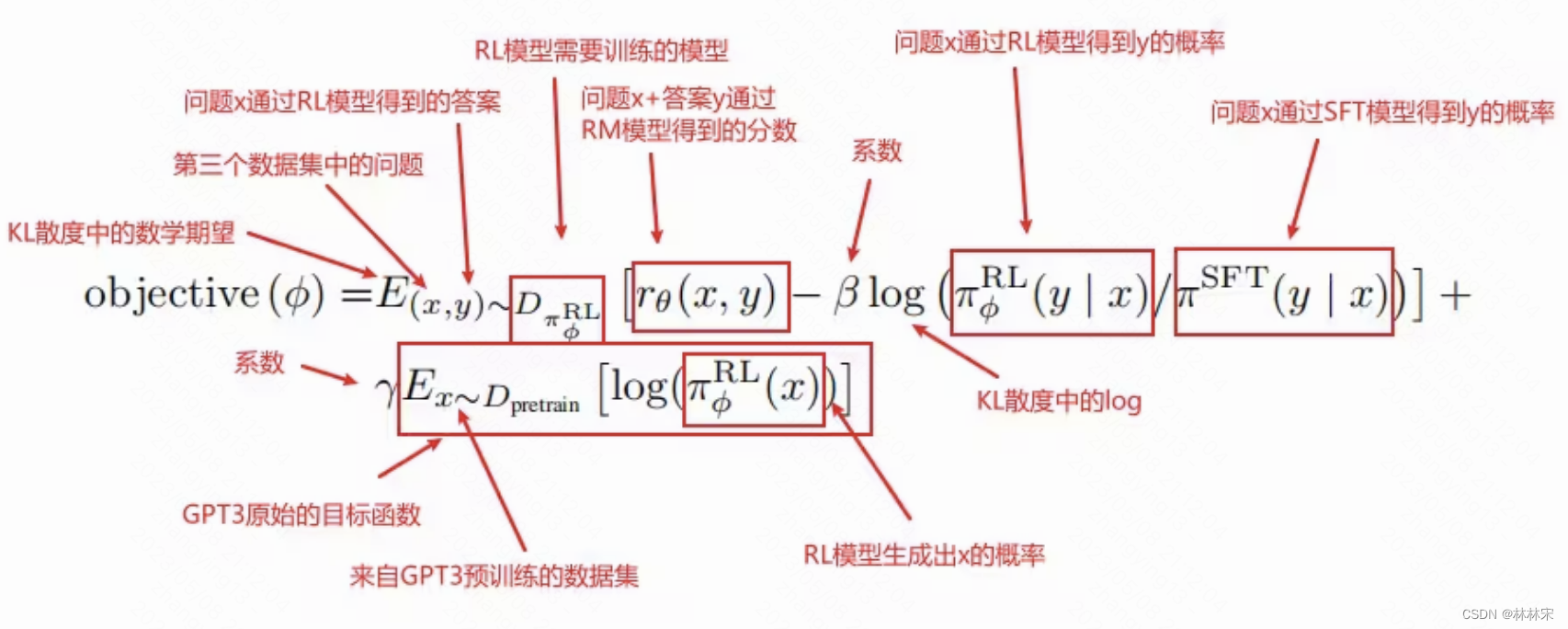
强化学习,模型处于当前状态—做出行动action—模型到达一个新的状态。
损失函数分成三部分:
- 打分部分: r θ ( x , y ) r_{\theta}(x,y) rθ(x,y),对于新模型数据打分要高一些
- KL散度部分:目的是RL模型和之前的模型的差距越小越好
- GPT3预训练部分:目的是不要只对当前的任务进行优化,也需要关注原始数据(语言模型的loss,下一个tokens)
数据集
1、SFT数据集:13000条数据。标注人员直接根据刚才的问题集里面的问题写答案。
2、RM数据集:33000条数据。标注人员对答案进行排序。
3、RF数据集:31000条数据。只需要prompt集里面的问题就行,不需要标注。因为这一步的标注是RM模型来打分标注的。
- 文章附录中有写比较详细的,如何筛选标注人员,以及标注界面的设计,标注方式的定义,这些都是可以直接借鉴的。
- 数据分布和质量是Intruct GPT的核心护城河,数据的信噪比高,因此需要的数据量可以大大减少。

![[简易的网站登录注册,注销退出操作]](https://img-blog.csdnimg.cn/5b9346d144ea4997b9d1cc984866b0a1.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5bCP5pm6UkUw,size_17,color_FFFFFF,t_70,g_se,x_16)