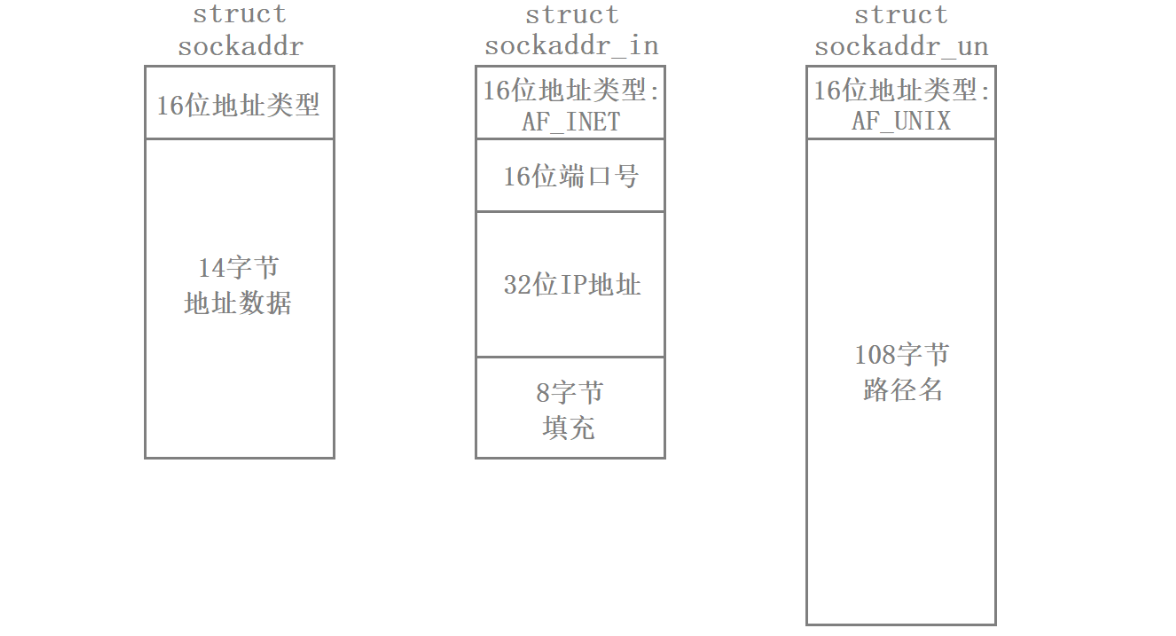
文章目录
- VIT
- CLIP
- SAM
- YOLO系列问题
VIT
介绍一下Visual Transformer?
介绍一下自注意力机制?
介绍一下VIT的输出方式
介绍一下VIT做分割任务
VIT是将NLP的transformer迁移到cv领域,他的整个流程大概如下:将一张图片切成很多个patch,每个patch为16x16的大小,然后将这些patch拉直,并添加一个位置编码,然后将这个向量序列输入到标准的transformer encoder中,这里的transformer encoder由多个transformer 标准块构成,包括multi head attention 然后相加并进行层归一化,以及后面的FFN(前馈神经网络)
FFN层就是feed forward层。他本质上就是一个两层的MLP,第一层会将输入的向量升维,第二层将向量重新降维。这样子就可以学习到更加抽象的特征。
Transformer encoder 的输出和输入一样,有多个输出,我们应该拿哪个输出去做最后的分类呢?所以说再次借鉴BERT,用extra learnable embedding,也就是一个特殊字符叫cls,叫分类字符,它也有一个位置编码0,因为所有的token都在跟所有的token做交互信息,所以第一个class embedding 可以从别的embedding里面学到有用的信息,从而我们只需要根据它的输出做一个MLP Head,做最后的判断。





CLIP
介绍一下CLIP
CLIP的网络结构
CLIP的损失函数
CLIP的优势
CLIP为什么可以做零样本学习
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系,CLIP模型有两个模态,一个是文本模态,一个是视觉模态:
- Text Encoder:用于将文本转换为低维向量表示-Embeding。
- Image Encoder:用于将图像转换为类似的向量表示-Embedding。
在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。这种模型特别适用于零样本学习任务,即模型不需要看到新的图像或文本的训练示例就能进行预测。CLIP模型在多个领域表现出色,如图像文本检索、图文生成等。

模型中使用visual_embedding 叉乘 text_embedding,得到一个[N, N]的矩阵,那么对角线上的值便是成对特征内积得到的,如果visual_embedding和对应的text_embedding越相似,那么它的值便越大。
选取[N, N]矩阵中的第一行,代表第1个图片与N个文本的相似程度,其中第1个文本是正样本,将这一行的标签设置为1,那么就可以使用交叉熵进行训练,尽量把第1个图片和第一个文本的内积变得更大,那么它们就越相似。
[交叉熵]:一种用于衡量两个概率分布之间差异的度量方式。其定义为

,其中P(x)为实际概率分布,Q(x)为预测概率分布。
交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小(相对熵的值越小),两个概率分布越接近
SAM
在NLP的领域中,存在一些被称为基础模型的模型,他们通过预测句子中的下一个词进行训练,称为顺序预测。通过这些基础的模型可以轻松地适应到其他的NLP的任务上,比如翻译或者是文本摘要,这种实现方式也可以称为是零样本迁移学习。其中比较著名的方法就是prompting,通过聊天的形式来进行交互。NLP有效的前提是网络上存在大量的文本,而对于序列的预测,比如说知道一些词然后预测后面的词是什么,这种不需要人工标注的标签就能完成训练。但是问题转化到计算机视觉的任务上,尽管网络上存在数十亿的图像,但是由于缺乏有效标注的mask的信息,所以在计算机视觉的任务上建立这样模型成为了挑战。开门见山,作者首先提出了三个问题。

针对上面提出的3个问题,作者给出的解决方案。作者的目标是通过引入三个相互关联的组件来构建一个分割的基础模型:一个可提示的分割任务、一个通过数据标注提供动力并能够通过提示工程实现一系列任务零样本迁移的分割模型(SAM),以及一个用于收集我们的数据集SA-1B(包含超过10亿个掩码)的数据引擎。
可提示的分割任务和实际使用目标对模型架构施加了约束。具体而言,模型必须支持灵活的提示,需要以分摊的实时方式计算掩码以允许交互式使用,并且必须具备处理歧义的能力。令人惊讶的是,我们发现一个简单的设计就能满足所有这三个约束条件:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将这两个信息源在一个轻量级的掩码解码器中结合起来,预测分割掩码。
图像的编码器:
图像编码器。出于可扩展性和强大的预训练方法的考虑,我们使用了一个经过最小调整以适应高分辨率输入的MAE预训练视觉Transformer(ViT)[33][62]。图像编码器每张图像运行一次,并可在提示模型之前应用,这里使用的mae来进行预训练。
提示词的编码器:
提示编码器。我们考虑两组提示:稀疏提示(点、框、文本)和密集提示(掩码)。我们用位置编码[95]来表示点和框,并将其与每种提示类型的学习嵌入和来自CLIP的现成文本编码器中的自由格式文本相加。密集提示(即掩码)使用卷积进行嵌入,并与图像嵌入进行逐元素相加。
掩码的解码器:
掩码解码器能够高效地将图像嵌入、提示嵌入和输出标记映射到一个掩码。采用了一个经过修改的Transformer解码器块,后面跟着一个动态掩码预测头。我们修改后的解码器块在两个方向上(从提示到图像嵌入和从图像嵌入到提示)使用提示自注意力和交叉注意力来更新所有嵌入。运行两个块之后,我们对图像嵌入进行上采样,并且一个多层感知机(MLP)将输出标记映射到一个动态线性分类器,然后该分类器计算图像每个位置的前景掩码概率。
解决歧义的问题:
解决歧义问题。如果给定一个模糊的提示,模型将平均多个有效的掩码作为一个输出。为了解决这个问题,我们修改了模型,使其能够针对单个提示预测多个输出掩码(见图3)。我们发现,3个掩码输出足以处理大多数常见情况(嵌套掩码通常最多有三层:整体、部分和子部分)。比如上面的剪刀的图像,其实由三个有效的掩码。
我们的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM辅助标注者标注掩码,类似于经典的交互式分割设置。在第二阶段,SAM可以通过提示可能的对象位置自动为一部分对象生成掩码,而标注者则专注于标注剩余的对象,这有助于增加掩码的多样性。在最后阶段,我们使用前景点的常规网格提示SAM,平均每张图像生成约100个高质量掩码。
介绍一下SAM模型?
SAM的创新性在哪里?
详细介绍一下SAM的网络结构
SAM的加速和量化你有了解吗?
SAM的应用场景
YOLO系列问题
前处理和后处理具体包括什么?
前处理你是如何加速的?
YOLOv8的改进点有哪些?
Yolov8换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。
Yolov8使用C2f模块代替C3模块。具体改进如下:
第一个卷积层的Kernel size从6×6改为3x3。
所有的C3模块改为C2f模块,如下图所示,多了更多的跳层连接和额外Split操作。
Block数由C3模块3-6-9-3改为C2f模块的3-6-6-3。