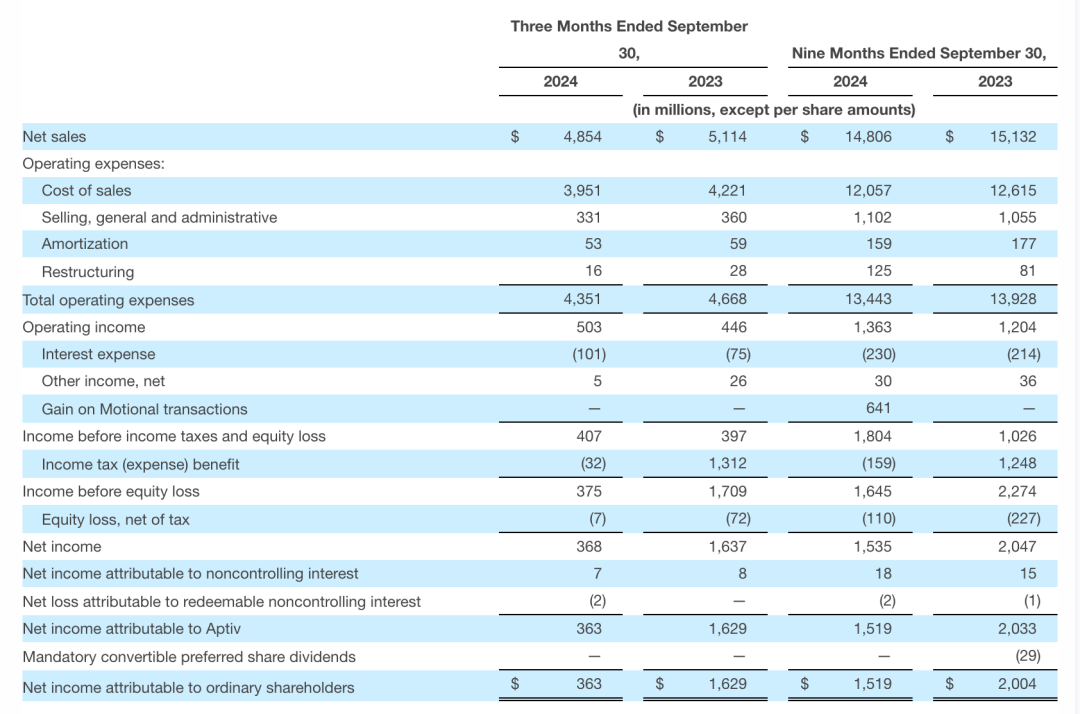
目录
一、样本及样本划分
1.1 划分样本的方法
1.1.1 train_test_split()函数
1.1.2 时间序列划分
1.1.3 交叉验证
二、导入或创建数据集
2.1 导入Sklearn自带的样本数据集
2.2 利用Sklearn生成随机的数据集
2.3 读入自己创建的数据集
2.3.1 用Python直接读取文本文件
2.3.2 用pandas库读取Excel或文本文件
三、数据预处理
3.1 归一化函数 MinMaxScaler()
3.2 z-score 标准化函数
3.2.1 sklearn.preprocessing.scale()函数
3.2.2 sklearn.preprocessing.StandardScaler()对象
3.3 二值化函数 Binarizer()
3.4 正则化函数 Normalizer()
3.5 独热编码函数
四、数据降维
一、样本及样本划分
在机器学习中,样本是指用于训练和评估模型的各种数据。样本可以是具体的数据点,也可以是一组数据点的集合。
样本划分是将样本集划分为训练集和测试集的过程。训练集用于模型的训练和参数的调整,而测试集用于评估模型在未见过的数据上的表现。
在样本划分时,通常会将样本集按照一定的比例划分为训练集和测试集。常见的划分比例是将样本集的70%用作训练集,30%用作测试集。划分比例的选择可以根据具体的问题和数据情况来决定。
在一些情况下,还可以将样本集划分为训练集、验证集和测试集。训练集用于模型的训练,验证集用于调整模型的超参数,而测试集用于最终评估模型的性能。这种划分方式可以帮助防止模型在训练集上过拟合,并且能够更好地衡量模型的泛化能力。
样本划分的目的是为了评估模型在未见过的数据上的表现,并且能够判断出模型是否存在过拟合或欠拟合的问题。样本划分要保证训练集和测试集是相互独立的,并且能够代表整个样本集的特征。
1.1 划分样本的方法
划分样本的方法可以根据具体的任务和数据情况选择。
1.1.1 train_test_split()函数
train_test_split()函数是sklearn库中提供的用于划分样本的函数。它可以将样本数据集划分为训练集和测试集,并可以指定划分的比例、随机种子、是否进行洗牌等参数。
函数的基本使用方式如下:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
参数说明:
X为特征数据,y为目标变量或标签。test_size参数指定了测试集所占的比例,可以是0到1之间的浮点数或整数。random_state参数用于指定随机种子,确保每次划分的结果一致。
默认情况下,train_test_split()函数会进行洗牌(shuffle),即将样本随机打乱后再划分,以避免数据的有序性对划分结果产生影响。
train_test_split()函数返回划分后的训练集和测试集的特征数据(X_train, X_test)以及对应的目标变量或标签(y_train, y_test)。
除了基本的划分特征和标签数据外,train_test_split()函数还可以同时划分多个数据集,如划分特征数据、目标变量和样本权重等。
1.1.2 时间序列划分
在时间序列问题中,样本的划分需要考虑时间的顺序性,以确保模型在未来的预测中能够正确地使用过去的信息。以下是两种常用的时间序列划分方法:
-
时间窗口划分(Time window splitting):在时间窗口划分中,数据集按时间顺序被分成固定大小的连续时间窗口。每个时间窗口通常包含连续的时间段,比如一天、一周或一个月。划分时可以设置窗口的大小和重叠度。训练集通常包含前面的时间窗口,而测试集包含后面的时间窗口。这种划分方法适用于以时间为主要维度的数据集,如股票价格、气象数据等。
-
时间点划分(Time point splitting):在时间点划分中,数据集按照特定的时间点进行划分。通常,将数据集分为训练集、验证集和测试集。训练集用于模型的训练,验证集用于调整模型的超参数和进行模型选择,而测试集用于最终评估模型的性能。时间点划分可以根据实际需求灵活选择时间点,如按照日期、季度或年份等进行划分。
在python中,可以使用train_test_split()函数或手动进行时间序列的划分。如果数据量较大且时间序列较长,建议使用train_test_split()函数,设置相应的参数进行时间窗口划分。如果数据量较小或时间序列较短,可以选择手动划分时间点。
以下是使用train_test_split()函数进行时间窗口划分的示例代码:
from sklearn.model_selection import train_test_split# 假设data为时间序列数据,target为对应的目标值
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, shuffle=False)# 可以根据实际需求设置窗口的大小
window_size = 7
# 根据窗口大小进行时间窗口划分
X_train = [data[i-window_size:i] for i in range(window_size, len(X_train))]
X_test = [data[i-window_size:i] for i in range(window_size, len(X_test))]
y_train = y_train[window_size:]
y_test = y_test[window_size:]
在上述代码中,data为时间序列数据,target为对应的目标值。test_size参数设置测试集的比例,这里为0.2,即占总体数据的20%。shuffle参数设置为False,确保按照时间顺序进行划分。
1.1.3 交叉验证
交叉验证是一种常用的样本划分方法,用于评估和选择机器学习模型的性能。它将数据集划分为多个互不重叠的子集,然后对模型进行多次训练和评估。以下是两种常见的交叉验证方法:
-
K折交叉验证(K-fold Cross Validation):在K折交叉验证中,数据集被划分为K个互不重叠的子集,称为折。每次训练时,选择K-1个折作为训练集,剩下的一个折作为验证集。重复K次,每次选择不同的验证集,最后将K次的评估结果取平均值作为最终模型的性能指标。K折交叉验证可以更充分地利用数据集,减少因单次划分带来的偶然性。

-
留一交叉验证(Leave-One-Out Cross Validation):在留一交叉验证中,每次训练时,将一条样本作为验证集,剩下的样本作为训练集。重复N次,N为样本的数量。留一交叉验证适用于样本量较小的情况,它基本上遍历了所有可能的训练集和测试集组合,但计算开销较大。
在Python中,可以使用scikit-learn中的cross_val_score()函数来进行交叉验证。
以下是使用K折交叉验证进行模型评估的示例代码:
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression# 假设X为特征数据,y为目标变量
kfold = KFold(n_splits=5, shuffle=True, random_state=42) # 设置折数、是否打乱数据和随机状态
model = LogisticRegression() # 假设使用逻辑回归模型scores = cross_val_score(model, X, y, cv=kfold) # 进行交叉验证评估
print("交叉验证准确率: %0.2f" % scores.mean()) # 打印平均准确率
在上述代码中:
n_splits参数表示划分为5折交叉验证,即将数据集分为5个子集。shuffle参数设置为True,表示在划分前是否打乱数据集。random_state参数用于设置随机状态,以便重现结果。model为机器学习模型,这里使用逻辑回归模型作为示例。cross_val_score()函数对模型进行交叉验证评估,并返回每次验证的性能指标,最后通过取平均值得到最终的评估结果。
交叉验证是一种常用的模型评估方法,可以更准确地评估模型的性能,并帮助选择最优的模型参数。在实际应用中,可以根据数据集的大小和问题的需求选择合适的交叉验证方法。
二、导入或创建数据集
2.1 导入Sklearn自带的样本数据集
使用sklearn.datasets模块中的函数来导入Sklearn自带的样本数据集。这个模块提供了一些常见的数据集,可以用于机器学习和数据分析的实验和练习。

以下是导入Sklearn自带样本数据集的示例代码:
from sklearn import datasets# 导入Iris数据集
iris = datasets.load_iris()
X_iris = iris.data # 特征数据
y_iris = iris.target # 目标变量# 导入波士顿房价数据集
boston = datasets.load_boston()
X_boston = boston.data # 特征数据
y_boston = boston.target # 目标变量# 导入手写数字数据集(MNIST)
digits = datasets.load_digits()
X_digits = digits.data # 特征数据
y_digits = digits.target # 目标变量
在上述代码中,datasets.load_iris()函数导入了Iris(鸢尾花)数据集。这个数据集包含了150个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),还有一个目标变量(花的种类)。
类似地,通过datasets.load_boston()函数可以导入波士顿房价数据集,该数据集包含了506个样本和13个特征,目标变量是房价。最后,datasets.load_digits()函数导入了手写数字数据集(MNIST),它包含了1797个样本和64个特征(8x8像素图像表示的手写数字),目标变量是0到9之间的整数。
2.2 利用Sklearn生成随机的数据集
要生成随机的数据集,可以使用Sklearn中的datasets模块。Sklearn提供了几种常用的数据集生成器,包括回归数据、分类数据和聚类数据等。
-
make_regression():生成回归问题的合成数据集。可以控制数据集的样本数量、特征数量、噪声等参数。
-
make_classification():生成分类问题的合成数据集。多类单标签数据集,为每个类分配一个或多个正态分布(球形)的点集。提供了为数据添加噪声的方式,可以控制数据集的样本数量、特征数量、类别数量、噪声等参数。
-
make_blobs():生成聚类问题的合成数据集。多类单标签数据集,为每个类分配一个或多个正态分布(球形)的点集,可以控制数据集的样本数量、聚类数量、特征数量、噪声等参数。
-
make_circles():生成环形分类问题的合成数据集。产生二维二元分类数据集,也可以为数据集添加噪声,可以为二元分类器产生一些环形判决界面的数据。
-
make_moons():生成半月形分类问题的合成数据集。其他特征同 make_circles()。
-
make_gaussian_quantiles():将一个单高斯分布的点集划分为两个数量均等的点集,作为两类。
-
make_hastie-10-2():产生一个,相似的二元分类数据集,有10个维度。
这些函数返回的数据集都是一个二维数组,其中每一行表示一个样本,每一列表示一个特征。同时,还可以通过调整参数来控制数据集的相关性、噪声等属性。
利用Sklearn生成环形、月亮形和环形数据集
示例代码:
from sklearn.datasets import make_circles
from sklearn.datasets import make_moons
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(12,4))plt.subplot (131)
x1,y1 = make_circles(n_samples= 1000, factor=0.5, noise=0.1)
# factor表示里圈和外圈的距离之比 每圈有n_samples/2个点
plt.scatter(x1[:,0],x1[:,1], marker='o',c=y1)plt.subplot (132)
x1,y1 = make_moons (n_samples= 1000, noise=0.1)
plt.scatter(x1[:,0],x1[:,1], marker='o',c=y1)plt.subplot (133)
x1,y1 = make_blobs(n_samples=100,n_features= 2,centers=3)
plt.scatter(x1[:,0],x1[:,1],c=y1);
plt.show()输出结果:

2.3 读入自己创建的数据集
2.3.1 用Python直接读取文本文件
Python内置了文件操作函数,先用 loadDataSet()函数先打开文件,然后依次读取文本文件中的每一行,再利用 split()方法分割一行中的每个数据,最后将这些数据依次添加到数组中,这样程序就和数据独立了,代码如下。
def loadDataSet():dataMat=[] # 保存特征属性labelMat=[] # 保存标签属性fr=open('G:\\1r2.txt') # 打开文本文件 1r2.txt (自己的文件路径)for line in fr.readlines(): # 依次读取文本文件中的一行lineArr=line.strip().split() # 根据空格分割一行中的每列dataMat.append([float (lineArr[0]),float(lineArr[1])])labelMat.append(int(lineArr[2]))
return dataMat,labelMat2.3.2 用pandas库读取Excel或文本文件
可以使用pandas库的read_excel()方法来读取Excel文件,使用read_csv()方法来读取文本文件。
下面是一个使用pandas读取Excel和文本文件的示例:
import pandas as pd# 读取Excel文件
df_excel = pd.read_excel('data.xlsx')# 读取文本文件
df_csv = pd.read_csv('data.csv')# 打印Excel文件的前几行数据
print(df_excel.head())# 打印文本文件的前几行数据
print(df_csv.head())
在上述示例中,read_excel()方法和read_csv()方法分别读取了名为data.xlsx和data.csv的文件,并将结果存储在DataFrame对象中。然后,使用head()方法打印了前几行数据。
三、数据预处理
数据预处理在数据分析和机器学习领域中扮演着至关重要的角色。原始数据中常常存在着各种问题,如缺失值、重复值、异常值、不一致的格式等,这些问题可能导致模型的性能下降或产生错误的结论。因此,需要进行数据预处理来清洗和转换数据,以提高数据的质量和可用性。
3.1 归一化函数 MinMaxScaler()
在Python的机器学习库scikit-learn中,可以使用MinMaxScaler()函数实现归一化。该函数将数据中的每个特征转换为指定的范围内。
公式如下:
X_scaled = (X - X_min) / (X_max - X_min)参数说明:
- X表示原始数据集;
- X_scaled表示归一化后的数据集;
- X_min表示每个特征的最小值;
- X_max表示每个特征的最大值。
下面是一个使用MinMaxScaler()函数进行数据归一化的示例:
from sklearn.preprocessing import MinMaxScaler
import pandas as pd# 创建数据集
data = {'A': [10, 20, 30, 40, 50],'B': [1, 2, 3, 4, 5],'C': [100, 200, 300, 400, 500]}
df = pd.DataFrame(data)# 创建MinMaxScaler对象
scaler = MinMaxScaler()# 对数据进行归一化
df_scaled = scaler.fit_transform(df)# 将归一化后的数据集转换为DataFrame
df_normalized = pd.DataFrame(df_scaled, columns=df.columns)print(df_normalized)
注意:
- MinMaxScaler()函数默认将数据进行按列归一化,即每列的最小值和最大值用于计算归一化的范围。如果需要按行归一化,可以指定参数axis=1。
MinMaxScaler()函数还提供了inverse_transform()函数,用于将归一化后的数据还原为原始数据。
3.2 z-score 标准化函数
标准化有两种实现方式:一是调用 sklearn.preprocessing.scale()函数;二是实例化一个sklearn.preprocessing.StandardScaler()对象,后者的好处是可以保存训练得到的参数(均值、方差),直接使用其对象对测试数据进行转换。
3.2.1 sklearn.preprocessing.scale()函数
sklearn库中的preprocessing模块提供了scale()函数来实现z-score标准化(也称为标准化)。
下面是使用scale()函数进行标准化的示例代码:
from sklearn.preprocessing import scale# 原始数据
data = [1, 2, 3, 4, 5]# 标准化后的数据
scaled_data = scale(data)print(scaled_data)
输出结果:
[-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
# 原始数据经过scale()函数处理后,得到了标准化的数据。
# 每个数据点的值都被减去了原始数据的均值,然后除以了原始数据的标准差,得到了具有均值为0,标准差为1的数据如果需要对二维或多维数据进行标准化,可以将数据传递给scale()函数的第一个参数。例如:
from sklearn.preprocessing import scale# 原始数据
data = [[1, 2, 3],[4, 5, 6],[7, 8, 9]]# 标准化后的数据
scaled_data = scale(data)print(scaled_data)
输出结果:
[[-1.22474487 -1.22474487 -1.22474487][ 0. 0. 0. ][ 1.22474487 1.22474487 1.22474487]]
# 二维数据每个特征维度都进行了标准化处理3.2.2 sklearn.preprocessing.StandardScaler()对象
sklearn中的preprocessing模块还提供了StandardScaler类来实现标准化。
下面是使用StandardScaler类进行标准化的示例代码:
from sklearn.preprocessing import StandardScaler# 创建StandardScaler对象
scaler = StandardScaler()# 原始数据
data = [[1, 2, 3],[4, 5, 6],[7, 8, 9]]# 调用fit_transform()方法来计算数据的均值和标准差,并进行标准化处理
scaled_data = scaler.fit_transform(data)print(scaled_data)
输出结果:
[[-1.22474487 -1.22474487 -1.22474487][ 0. 0. 0. ][ 1.22474487 1.22474487 1.22474487]]
注意:
- 由于fit_transform()方法返回的是一个新的数组,因此需要将结果赋值给一个新的变量(在上述示例中,将结果赋值给scaled_data)。
与scale()函数不同,StandardScaler类还提供了一些其他方法和属性,例如:
- scaler.mean_:返回数据的均值。
- scaler.var_:返回数据的方差。
- scaler.transform():对新的数据进行标准化,使用之前计算得到的均值和标准差。
通过使用StandardScaler类,可以更灵活地对数据进行标准化处理,并且可以保存标准化的参数以便后续使用。
3.3 二值化函数 Binarizer()
在sklearn.preprocessing模块中,Binarizer()函数不是用于二值化特征的,而是用于二值化样本的。 具体来说,Binarizer()函数将连续型的特征值根据一个阈值进行二值化处理。
函数的语法如下:
sklearn.preprocessing.Binarizer(threshold=0.0, copy=True)
参数说明:
- threshold:阈值,默认为0.0。
- copy:是否复制,默认为True。
使用Binarizer()函数的示例如下:
from sklearn.preprocessing import BinarizerX = [[1, -1, 2],[2, 0, 0],[0, 1, -1]]# 创建Binarizer对象,并指定阈值为1.5
binarizer = Binarizer(threshold=1.5)# 将样本进行二值化
X_binarized = binarizer.transform(X)print(X_binarized)
运行结果为:
[[0 0 1][1 0 0][0 0 0]]
# 样本中的特征值大于1.5的被转化为1,小于等于1.5的被转化为03.4 正则化函数 Normalizer()
在sklearn.preprocessing模块中,Normalizer()函数用于对特征矩阵进行正则化处理,即将每个样本的特征向量缩放到单位范数(即每个特征向量的L2范数等于1)。
函数的语法如下:
sklearn.preprocessing.Normalizer(norm='l2', copy=True)
参数说明:
- norm:正则化方式,默认为'l2',表示按L2范数进行正则化。还可以选择'l1'表示按L1范数进行正则化。
- copy:是否复制,默认为True。
使用Normalizer()函数的示例如下:
from sklearn.preprocessing import Normalizer
import numpy as npX = np.array([[1, 2],[2, 3],[3, 4]])# 创建Normalizer对象,默认按L2范数正则化
normalizer = Normalizer()# 对特征矩阵进行正则化
X_normalized = normalizer.transform(X)print(X_normalized)
运行结果为:
[[0.4472136 0.89442719][0.5547002 0.83205029][0.6 0.8 ]]
# 每个样本的特征向量被缩放到了单位范数3.5 独热编码函数
独热编码(One-Hot Encoding)是一种常用的特征编码方法,可以将离散特征的取值转换为一个特征向量,以便机器学习算法能够更好地理解和利用这些特征。 但需要注意的是,独热编码会增加特征维度,可能导致特征空间的维度爆炸。因此,在使用独热编码之前,可以考虑对离散特征进行特征选择或者降维,以减少特征维度。
在sklearn.preprocessing模块中,可以使用OneHotEncoder()函数进行独热编码。
函数的语法如下:
sklearn.preprocessing.OneHotEncoder(categories='auto', drop=None, sparse=True, dtype=<class 'numpy.float64'>, handle_unknown='error')
参数说明:
- categories:指定要编码的特征的取值范围,默认为'auto',表示根据输入数据自动推断。
- drop:指定是否删除其中一列,默认为None,表示不删除。可以选择'first'或'if_binary',表示删除第一列或者删除所有二进制特征。
- sparse:指定是否返回稀疏矩阵,默认为True,表示返回稀疏矩阵。可以选择False表示返回密集矩阵。
- dtype:指定编码后矩阵的数据类型,默认为numpy.float64。
- handle_unknown:指定处理未知取值的方式,默认为'error',表示遇到未知取值时抛出错误。可以选择'ignore'表示忽略未知取值。
使用OneHotEncoder()函数的示例如下:
from sklearn.preprocessing import OneHotEncoder
import numpy as npX = np.array([[1, 'A'],[2, 'B'],[3, 'A'],[1, 'B']])# 创建OneHotEncoder对象
encoder = OneHotEncoder()# 对特征矩阵进行独热编码
X_encoded = encoder.fit_transform(X)print(X_encoded.toarray())
运行结果为:
[[1. 0. 1. 0. 0.][0. 1. 0. 1. 0.][0. 0. 1. 0. 0.][1. 0. 0. 1. 0.]]
# 每个离散特征的取值都被转换为了一个特征向量,其中每个特征向量中只有一个元素为1,表示该样本的特征取值四、数据降维
数据降维是指通过某种特定的方法或算法将高维数据转换为低维数据的过程。在机器学习和数据分析中,数据降维可以用于减少数据的维度,提取数据中的主要特征,去除冗余信息,以便更好地进行可视化、建模和分析。
常用的数据降维方法包括主成分分析(Principal Component Analysis, PCA)、线性判别分析(Linear Discriminant Analysis, LDA)等。
-
主成分分析(PCA)是一种无监督的降维方法,它通过线性变换将原始特征映射到新的特征空间,使得新的特征具有最大的方差。PCA可以用于去除数据中的冗余信息,提取出最主要的特征。
-
线性判别分析(LDA)是一种有监督的降维方法,它通过线性变换将原始特征映射到新的特征空间,以使得同类样本之间的距离尽可能小,异类样本之间的距离尽可能大。LDA可以用于提取最具判别性的特征。
在sklearn.decomposition模块中,可以使用PCA()函数进行主成分分析降维。
函数的语法如下:
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)
参数说明:
- n_components:指定降维后的维度,默认为None,表示保留所有主成分。
- copy:指定是否复制输入数据,默认为True,表示复制。
- whiten:指定是否使用白化,默认为False,表示不使用。
- svd_solver:指定使用的SVD算法,默认为'auto',表示根据数据的大小和维度自动选择算法。
- tol:指定SVD算法的收敛阈值,默认为0.0。
- iterated_power:指定幂迭代的次数,默认为'auto',表示根据数据的维度自动选择次数。
- random_state:指定随机数生成器的种子,默认为None,表示使用当前系统时间作为种子。
使用PCA()函数的示例如下:
from sklearn.decomposition import PCA
import numpy as npX = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])# 创建PCA对象
pca = PCA(n_components=2)# 对数据进行降维
X_reduced = pca.fit_transform(X)print(X_reduced)
运行结果为:
[[-1.73205081 0. ][ 0. 0. ][ 1.73205081 0. ]]
# 原始数据被降维为一个二维的特征向量注意:
- 在进行数据降维之前,可以先对数据进行标准化或归一化,以保证不同特征之间的尺度一致,避免因为尺度不一致而对降维结果产生影响。