文章目录
- 第5章 分析器
- 5.1 分析器的组成
- 5.1.1 字符过滤器
- 1)HTMLStripCharFilter
- 2)PatternReplaceCharFilter
- 3)MappingCharFilter
- 4)Luke使用字符过滤器
- 5.1.2 分词器
- 1)StandardTokenzier
- 2)keywordTokenizer
- 3)WhitespaceTokenizer
- 5.1.3 token过滤器
- 1)LowerCaseFilter
- 2)UpperCaseFilter
- 5.2 分析器进行分词
- 5.2.1 分析器的执行流程
- 5.2.2 自定义分析器
- 1)分析器的继承体系
- 2)CustomAnalyzer
- 3)自定义分析器
- 5.2.3 同义词查询
- 1)手写实现同义词功能
- 2)使用Lucene内置过滤器
- 5.3 Lucene原生分析器
- 5.3.1 StandardAnalyzer
- 5.3.2 SimpleAnalyzer
- 5.3.3 WhitespaceAnalyzer
- 5.3.4 CJKAnalyzer
- 5.3.5 SmartChineseAnalyzer
- 5.4 第三方中文分析器
- 5.4.1 IKAnalyzer
- 5.4.2 ANSJ
- 5.4.3 MMSeg4J
- 5.4.4 ICTCLAS
第5章 分析器
5.1 分析器的组成
分析器,是将用户输入的一段文本,分析成符合逻辑的一种工具。分析器中包含字符过滤器(Char Filters)、**分词器(Tokenizer)和Token过滤器(Token Filters)**两个组件;其中分词器是分析器中最为核心的组件。
- 字符过滤器(Char Filters):字符过滤器是针对文本在分词器前的一些字符转换,如解析html代码、正则表达式等
- 分词器(Tokenizer):将用户输入的文本根据指定条件进行词语拆分,如I am Chinese拆分成:I、am、Chinese
- Token过滤器(Token Filters):Token过滤器是堆文本在分词后的词语进行过滤,如大小写转换、停用词处理、字符过滤等;
到目前为止呢,分词器没有办法做到完全的符合人们的要求。和我们有关的分析器有英文的和中文的;
【英文分析器】
英文的分析器过程:输入文本-关键词切分-去停用词-形态还原-转为小写。
我们知道英文本身是以单词为单位,单词与单词之间,句子之间通常是空格、逗号、句号分隔。因此对于英文,可以简单的以空格来判断某个字符串是否是一个词,比如:I am Chinese,Chinese很容易被程序处理。
【中文分析器】
中文是以字为单位的,字与字再组成词,词再组成句子。中文:我是中国人,电脑不知道“是中”是一个词,还是“中国”是一个词?所以我们需要一定的规则来告诉电脑应该怎么切分,这就是中文分词器所要解决的问题。
分别分析主要包含两个过程:分词和过滤:

- 字符过滤器:解析一些特殊字符,如html代码、正则表达式、自定义字符解析规则等
- 分词器:将Document中Field域的值切分成一个一个的单词。具体的切分方法(算法)根据使用的分词器而不同。
- Token过滤器:去除标点符号,去除停用词(嗯、的、啊、是、is、am、a、and等),词的大写转换小写。
【分词举例】
原始文档:I am Chinese and I love China
分析后:chinese ,love ,china
5.1.1 字符过滤器
在一段文本进行分词之前,先进行字符过滤,如HTML过滤、字符串替换过滤、正则表达式过滤等;
1)HTMLStripCharFilter
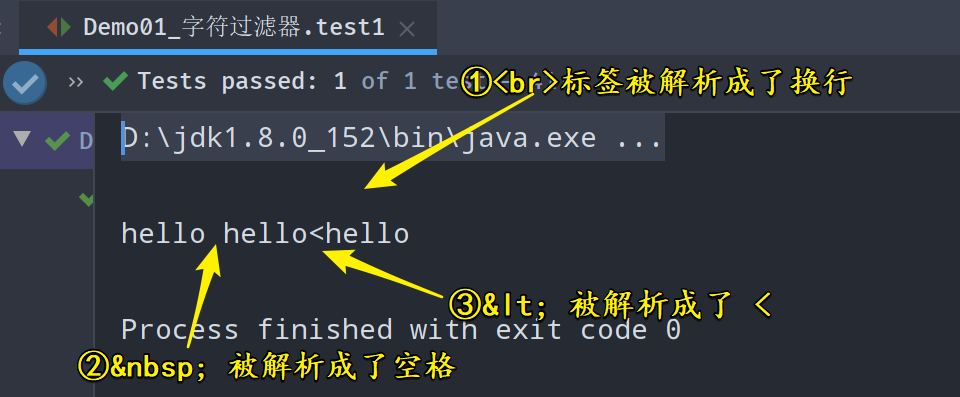
HTMLStripCharFilter过滤器可以解析html标签、特殊字符等;
【示例代码】
package com.dfbz.demo04_分析器的组成;import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.charfilter.HTMLStripCharFilter;
import org.apache.lucene.analysis.charfilter.MappingCharFilter;
import org.apache.lucene.analysis.charfilter.NormalizeCharMap;
import org.apache.lucene.analysis.pattern.PatternReplaceCharFilter;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;import java.io.StringReader;
import java.util.regex.Pattern;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01_字符过滤器 {@Testpublic void test1() throws Exception {HTMLStripCharFilter filter = new HTMLStripCharFilter(new StringReader("<br>hello hello<hello"));char[] chars = new char[1024];int len = filter.read(chars);System.out.println(new String(chars, 0, len));}
}
2)PatternReplaceCharFilter
PatternReplaceCharFilter是基于正则表达式的字符过滤器,运行用户通过正则表达式来过滤字符
@Test
public void test2() throws Exception {// 定义正则表达式Pattern pattern = Pattern.compile("\\d"); // 匹配数字的正则表达式// 创建基于正则表达式的字符过滤器 将正则表达式匹配到的数据转为: + PatternReplaceCharFilter filter = new PatternReplaceCharFilter(pattern, "+", new StringReader("7k7k"));char[] chars = new char[1024];int len = filter.read(chars, 0, 1024);System.out.println(new String(chars, 0, len));
}

3)MappingCharFilter
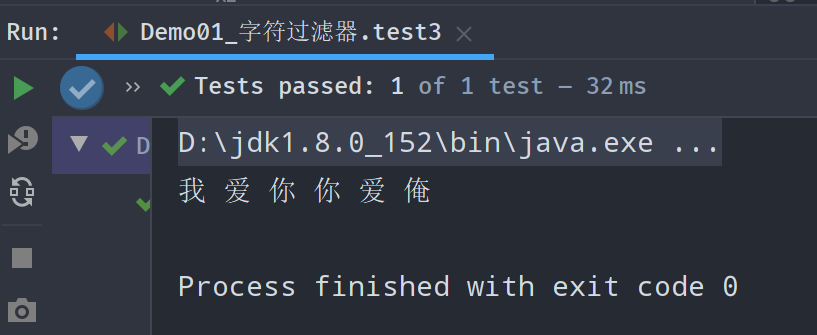
MappingCharFilter允许用户自定义字符替换成自己自定义的字符;
@Test
public void test3() throws Exception {// 创建字符映射NormalizeCharMap.Builder builder = new NormalizeCharMap.Builder();builder.add("love", "爱");builder.add("You", "你");builder.add("I", "我"); // 注意是区分大小写的builder.add("me", "俺");NormalizeCharMap charMap = builder.build();// 根据字符映射来创建字符过滤器MappingCharFilter filter = new MappingCharFilter(charMap, new StringReader("I love You You love me"));char[] chars = new char[1024];int len = filter.read(chars, 0, 1024);System.out.println(new String(chars, 0, len));
}
4)Luke使用字符过滤器
打开luke工具,查看Lucene内置的字符过滤器;
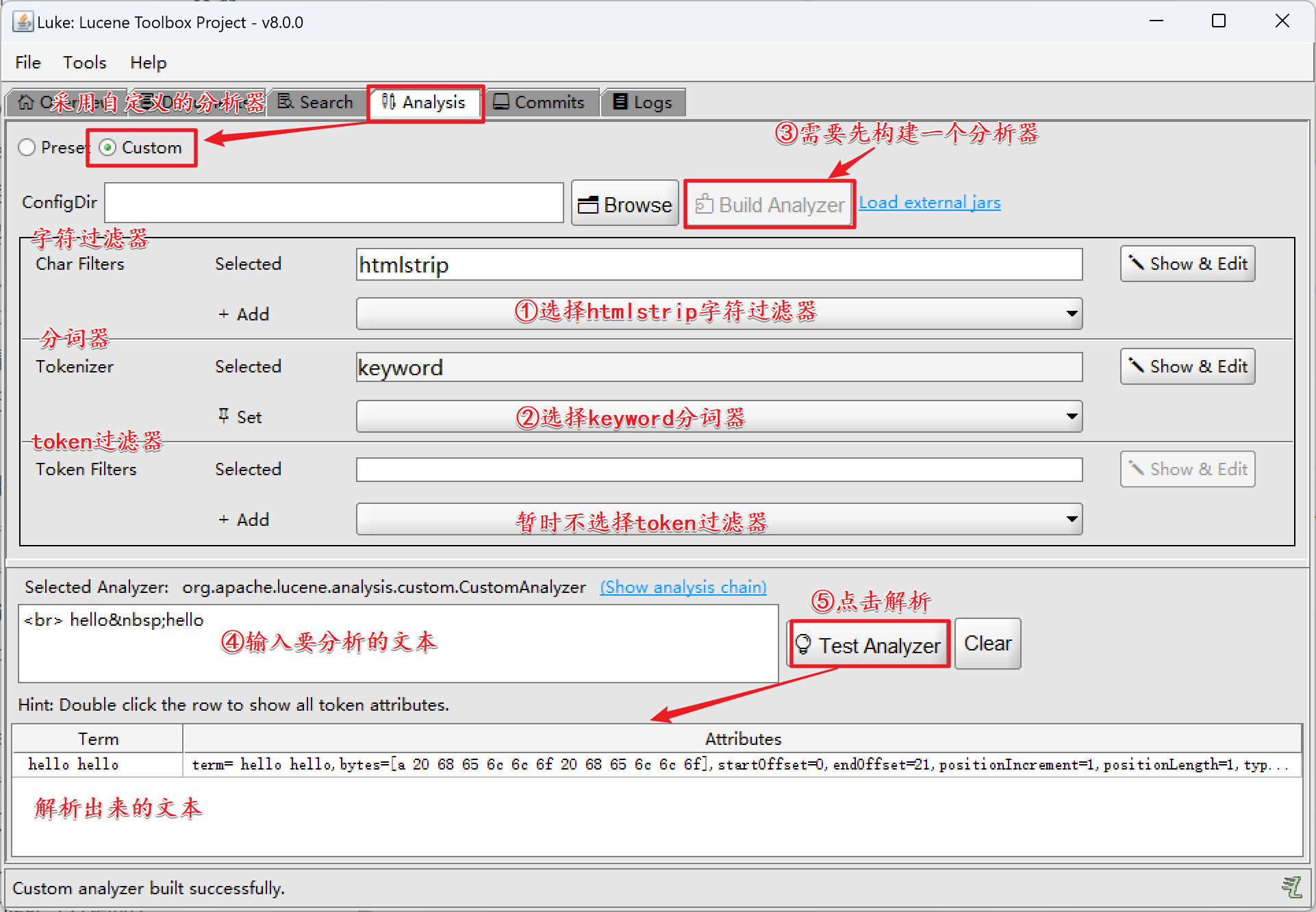
【分析如下文本】
<hr> hello hello
5.1.2 分词器
Lucene内置有很多分词器,我们可以打开Luke工具查看;
1)StandardTokenzier
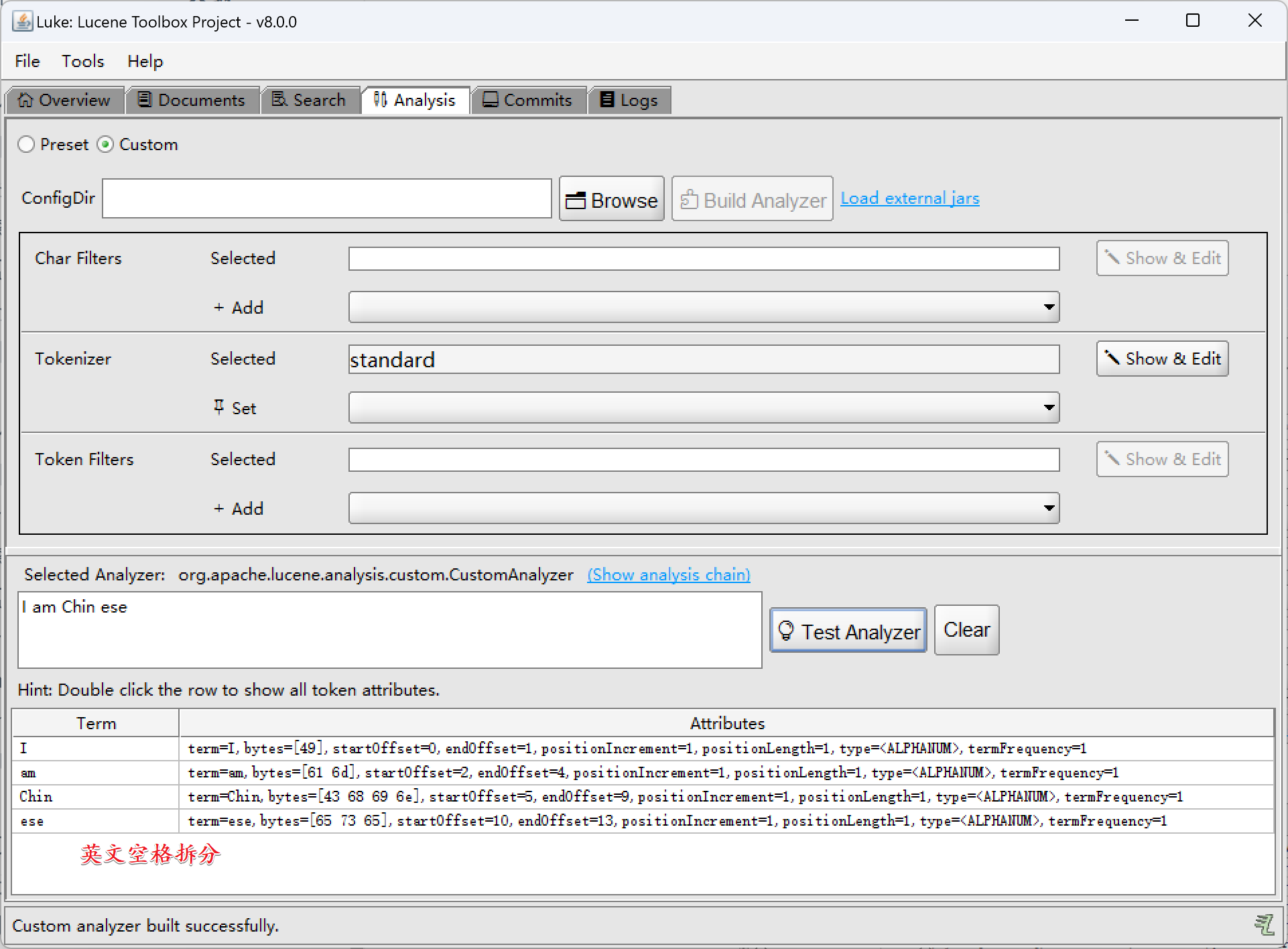
- StandardTokenzier:中文单字拆分、英文空格拆分
我是中国人I am Chinses
中文单字拆分:

英文空格拆分:
2)keywordTokenizer
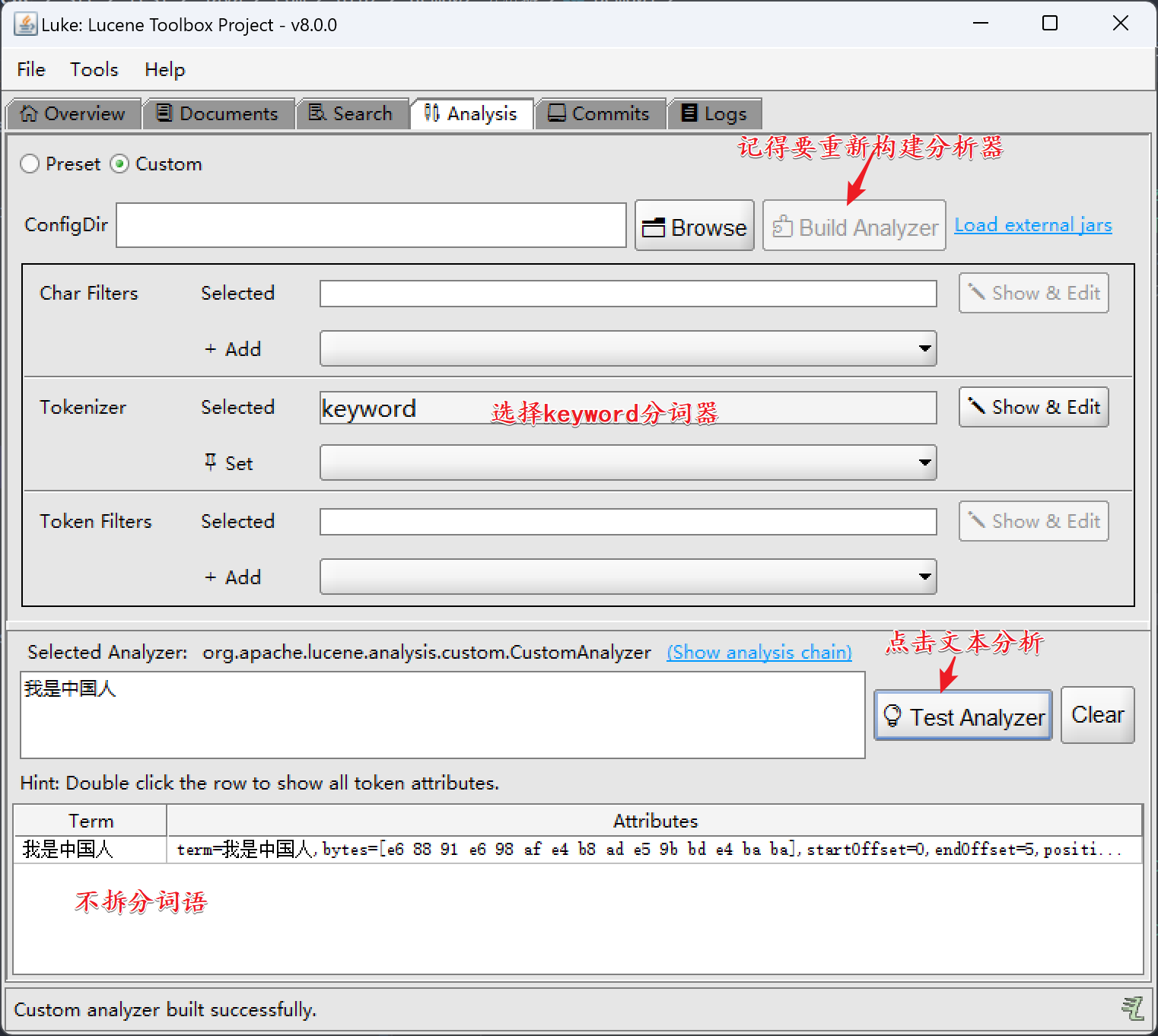
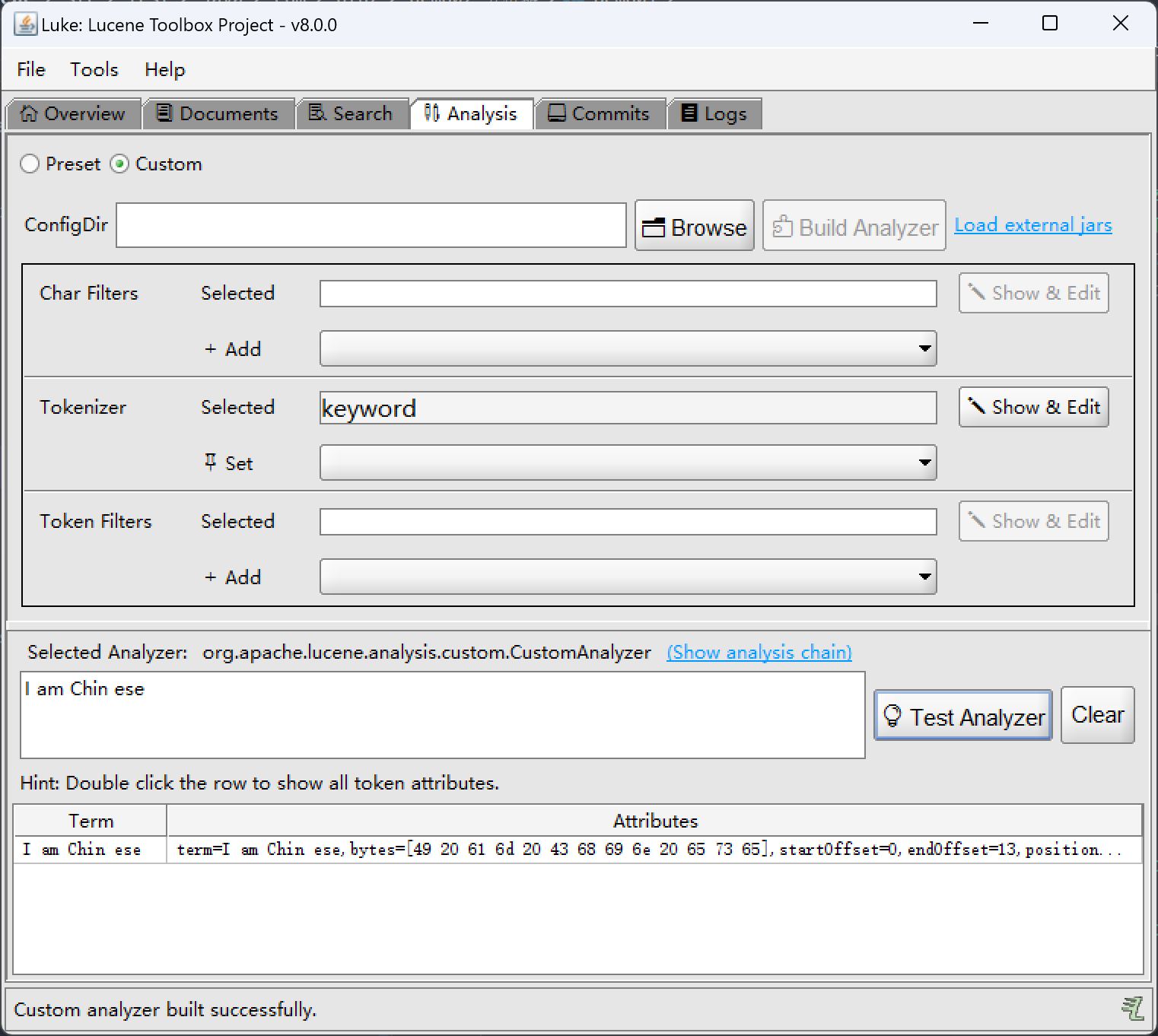
- keywordTokenizer:不对词语进行任何的拆分
我是中国人I am Chinses
中文:
英文:
3)WhitespaceTokenizer
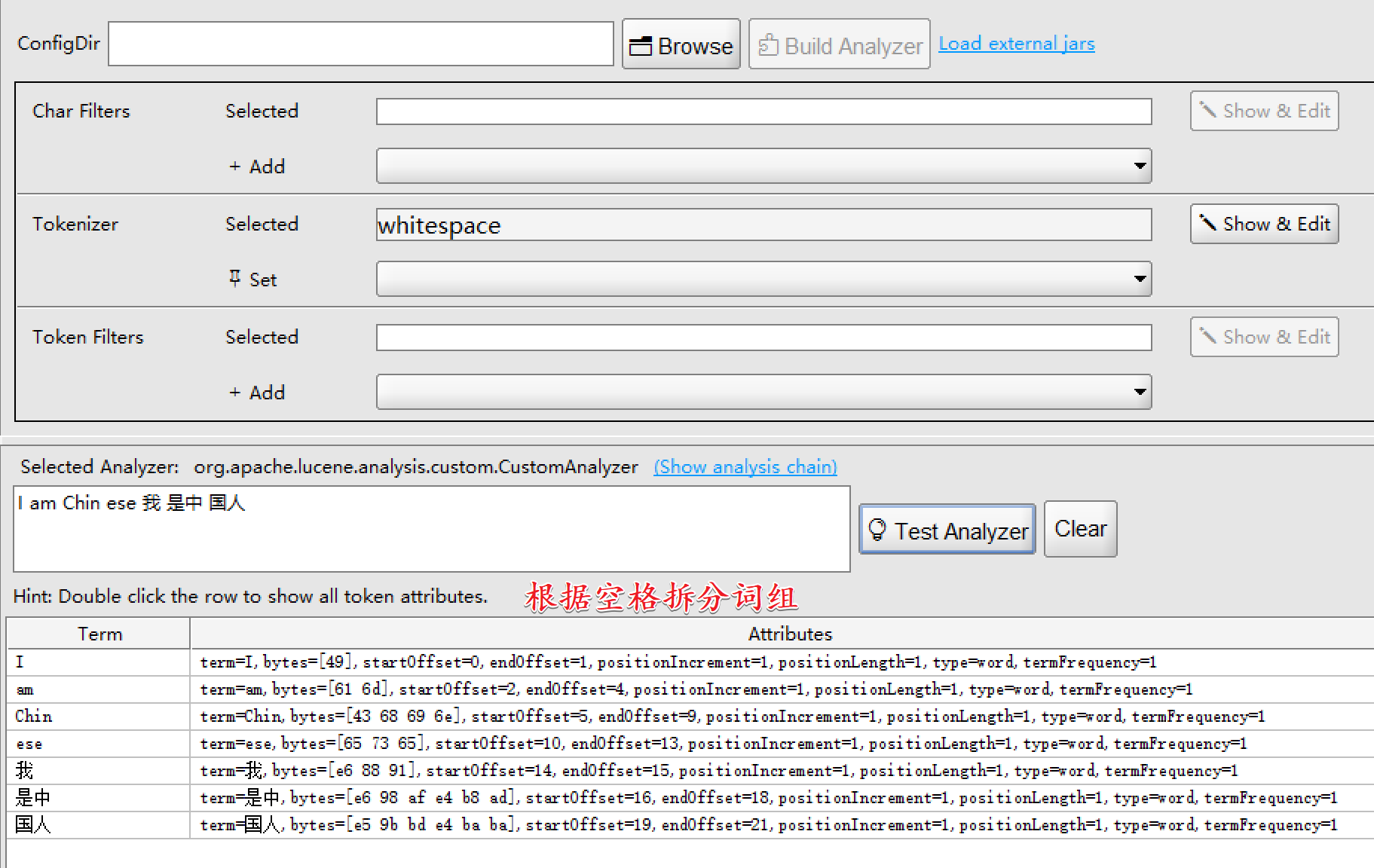
- WhitespaceTokenizer:不管中英文都是按照空格进行拆分
5.1.3 token过滤器
1)LowerCaseFilter
LowerCaseFilter:将分词后的词汇都转成小写
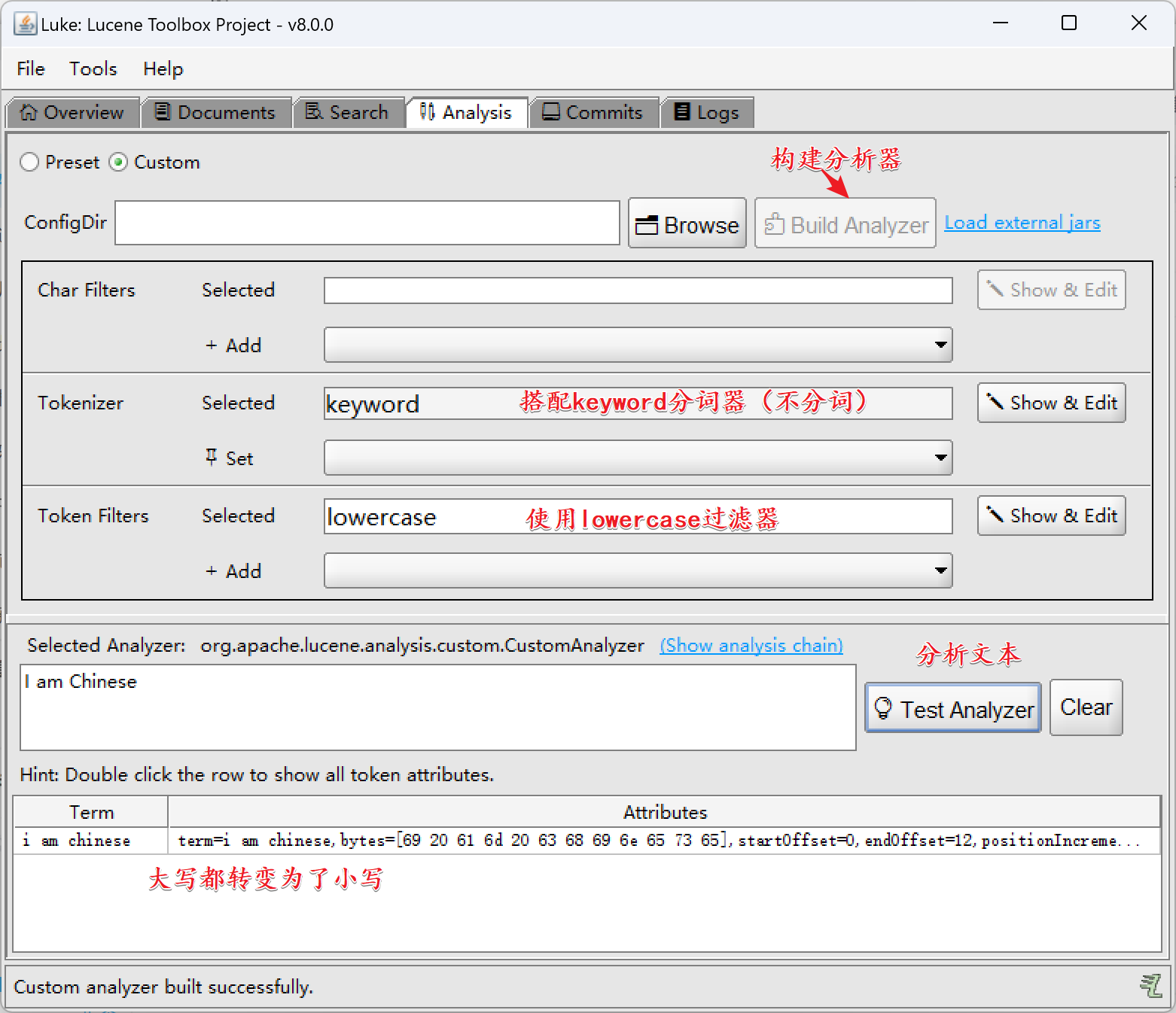
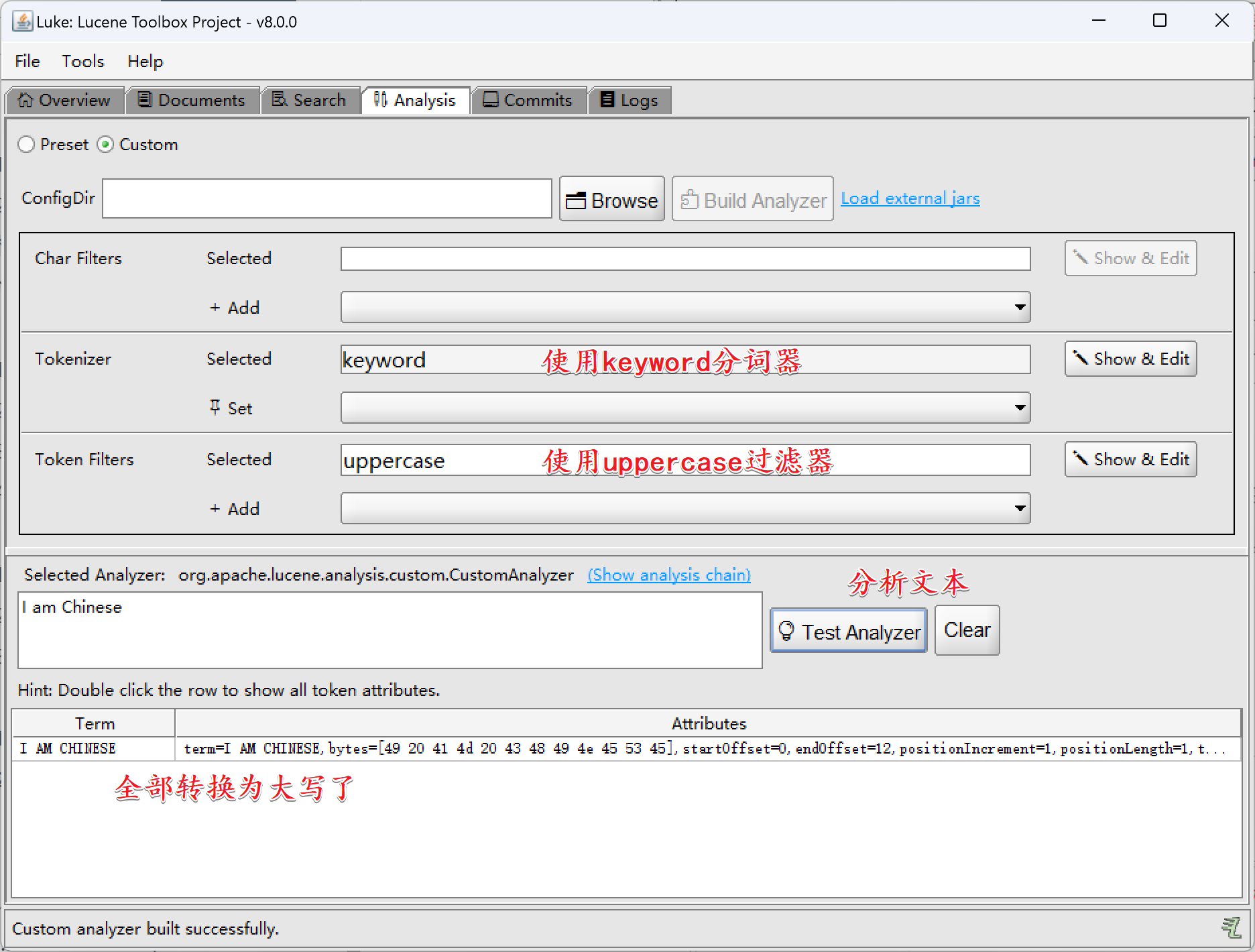
2)UpperCaseFilter
UpperCaseFilter:将分词后的词汇都转成大写
5.2 分析器进行分词
5.2.1 分析器的执行流程
在Lucene中,首先需要将文本转换为输入流传递给分析器,分析器经过内部一系列过滤、分词、再过滤,之后会生成TokenStream对象,该对象保存了分析器分析之后的所有数据;

分析对文本分析好了之后,内部会有词组之间偏移量、文字排列的序号、词组信息、词组类型等数据;通过以下类进行封装:
- PositionIncrementAttribute:用于获取词组之间的偏移量
- OffsetAttribute:文字排列的序号偏移量
- CharTermAttribute:词组信息,通过该类可以获取到具体的分词
- TypeAttribute:词组的类型
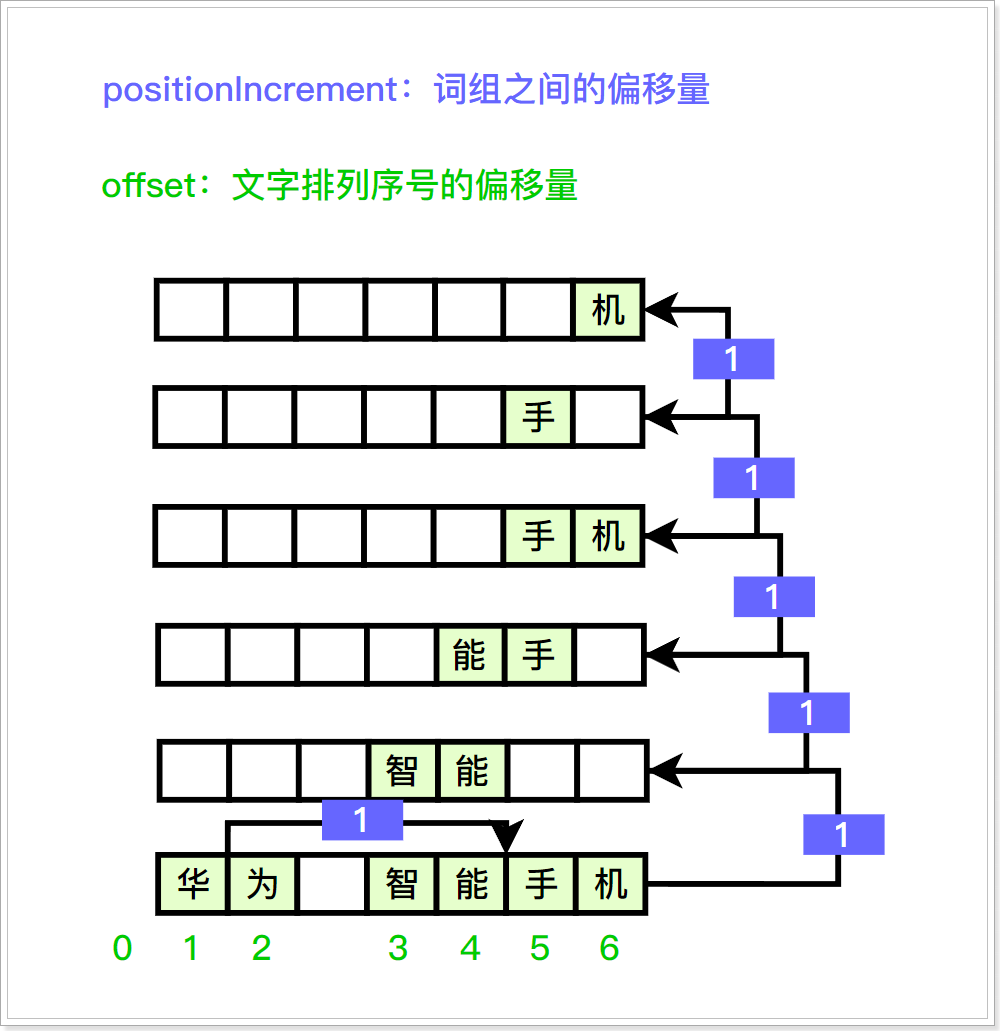
positionIncrement:如上图:"华为"这个词组到"智能手机"这个词组往下走了一个偏移量(positionIncrement);同理,"智能手机"词组到"智能"词组也往下走了一个偏移量(positionIncrement),以此类推…;offerset:词组中,文字的偏移量;例如华为(0~2),智能手机(2~6)、智能(2~4)、能手(3~5);以此类推…
【示例代码】
package com.dfbz.demo05_分析器的使用;import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;import java.io.StringReader;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01_分析器的使用 {@Testpublic void test1() throws Exception {Analyzer analyzer = new IKAnalyzer();/*对内容进行分词参数1: 分词的域(可以不写)参数2: 分词的文本*/TokenStream tokenStream = analyzer.tokenStream("xxx", new StringReader("华为智能手机"));// 需要重置一下stream,让内部指针回到头部tokenStream.reset();// 使用CharTermAttribute保存分词后的每一个词组CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);PositionIncrementAttribute positionIncrementAttribute = tokenStream.addAttribute(PositionIncrementAttribute.class);TypeAttribute typeAttribute = tokenStream.addAttribute(TypeAttribute.class);// 遍历词组,如果还有下一个词组就进入循环while (tokenStream.incrementToken()) {System.out.println(charTermAttribute);System.out.println("【" + offsetAttribute.startOffset() + "-" + offsetAttribute.endOffset() + "】");System.out.println(positionIncrementAttribute.getPositionIncrement());System.out.println(typeAttribute.type());System.out.println("-----------------------------");}}
}
执行结果如下:
华为
【0-2】
1
CN_WORD
-----------------------------
智能手机
【2-6】
1
CN_WORD
-----------------------------
智能
【2-4】
1
CN_WORD
-----------------------------
能手
【3-5】
1
CN_WORD
-----------------------------
手机
【4-6】
1
CN_WORD
-----------------------------
手
【4-5】
1
CN_WORD
-----------------------------
机
【5-6】
1
CN_CHAR
-----------------------------
5.2.2 自定义分析器
1)分析器的继承体系
我们知道分析器由CharFilter、Tokenizer、TokenFilter三个部件组成,因此自定义分析器只要准备好对应的三大组件即可;
注意:从Lucene5.0.0版本后不再推荐将字符过滤器集成在分析器中,如需进行字符过滤那就让用户自行指定合适的字符过滤器进行过滤,然后将过滤好的文本交由分析器进行下一步处理;
- 三大组件的继承关系:

CharFilter本质上是一个输入流(Reader),Tokenizer和TokenFilter本质上是一个TokenStream;
2)CustomAnalyzer
CustomAnalyzer是Lucene提供的一个用于自定义分析器的一个分析器,通过CustomAnalyzer可以搭配任意的字符过滤器、分词器、token过滤器来完成指定功能。
【示例代码】
package com.dfbz.demo05_分析器的使用;import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.charfilter.MappingCharFilter;
import org.apache.lucene.analysis.charfilter.NormalizeCharMap;
import org.apache.lucene.analysis.core.LowerCaseFilterFactory;
import org.apache.lucene.analysis.custom.CustomAnalyzer;
import org.apache.lucene.analysis.standard.StandardTokenizerFactory;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;import java.io.StringReader;/*** @author lscl* @version 1.0* @intro:*/
public class Demo02_CustomAnalyzer {@Testpublic void test1() throws Exception {String txt = "I love You You love me";// 1. 字符过滤器// 创建字符映射NormalizeCharMap.Builder builder = new NormalizeCharMap.Builder();builder.add("I", "我"); // 注意是区分大小写的(先经过charFilter再经过tokenFilter)NormalizeCharMap charMap = builder.build();// 根据字符映射来创建字符过滤器MappingCharFilter filter = new MappingCharFilter(charMap, new StringReader(txt));char[] chars = new char[1024];int len = filter.read(chars);txt = new String(chars, 0, len);// 自定义分析器CustomAnalyzer analyzer = CustomAnalyzer.builder().withTokenizer(StandardTokenizerFactory.class) // 2. 分词器.addTokenFilter(LowerCaseFilterFactory.class) // 3. 分析器.build();TokenStream tokenStream = analyzer.tokenStream("xx", new StringReader(txt));tokenStream.reset();CharTermAttribute termAttribute = tokenStream.addAttribute(CharTermAttribute.class);while (tokenStream.incrementToken()) {System.out.println(termAttribute);}tokenStream.close();}
}
3)自定义分析器
- 定义分析器:
package com.dfbz.analyzer;import org.apache.lucene.analysis.*;
import org.apache.lucene.analysis.standard.StandardTokenizer;/*** @author lscl* @version 1.0* @intro:*/
public class MyAnalyzer extends Analyzer {@Overrideprotected TokenStreamComponents createComponents(String fieldName) {// 分词器Tokenizer tokenizer = new StandardTokenizer();// token过滤器-1(转小写)LowerCaseFilter lowerCaseFilter = new LowerCaseFilter(tokenizer);// token过滤器-2(停用词)CharArraySet stopWords = StopFilter.makeStopSet("am", "is", "are");StopFilter stopFilter = new StopFilter(lowerCaseFilter, stopWords);return new TokenStreamComponents(tokenizer, stopFilter);}
}
- 测试代码:
package com.dfbz.demo05_分析器的使用;import com.dfbz.analyzer.MyAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.charfilter.MappingCharFilter;
import org.apache.lucene.analysis.charfilter.NormalizeCharMap;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;import java.io.StringReader;/*** @author lscl* @version 1.0* @intro:*/
public class Demo03_自定义分析器 {@Testpublic void test1() throws Exception {// 原始文本String txt = "I am Chinese How are you";// 创建字符映射NormalizeCharMap.Builder builder = new NormalizeCharMap.Builder();builder.add("I", "我");builder.add("you", "你");NormalizeCharMap charMap = builder.build();// 根据字符映射来创建字符过滤器MappingCharFilter filter = new MappingCharFilter(charMap, new StringReader(txt));char[] chars = new char[1024];int len = filter.read(chars, 0, 1024);txt = new String(chars, 0, len);Analyzer analyzer = new MyAnalyzer();TokenStream tokenStream = analyzer.tokenStream("xxx", new StringReader(txt));tokenStream.reset();CharTermAttribute attribute = tokenStream.addAttribute(CharTermAttribute.class);while (tokenStream.incrementToken()) {System.out.println(attribute);}}
}

5.2.3 同义词查询
1)手写实现同义词功能
- 1)自定义Token过滤器:
package com.dfbz.analyzer;import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/*** @author lscl* @version 1.0* @intro: 自定义同义词token过滤器*/
public class MySynonymTokeFilter extends TokenFilter {private CharTermAttribute termAttribute;protected MySynonymTokeFilter(TokenStream input) {super(input);// 添加一个CharTermAttribute接收分词器分词好的词组termAttribute = input.addAttribute(CharTermAttribute.class);}/*** 当TokenStream调用incrementToken方法时会执行该方法** @return* @throws IOException*/@Overridepublic final boolean incrementToken() throws IOException {// 如果没有下一次词组了,则结束if (!input.incrementToken()) return false;String[] synonymWords = getSynonymWords(termAttribute.toString());if (synonymWords != null) {// 代表有同义词// 清空原来的词组
// termAttribute.setEmpty();for (String word : synonymWords) {termAttribute.append("、" + word);}}return true;}/*** 存储同义词** @param name* @return*/public String[] getSynonymWords(String name) {Map<String, String[]> synonymMap = new HashMap<>();synonymMap.put("中国", new String[]{"天朝", "大陆", "华夏"});synonymMap.put("我", new String[]{"咱", "俺", "洒家"});return synonymMap.get(name);}
}
- 2)自定义分析器:
package com.dfbz.analyzer;import org.apache.lucene.analysis.Analyzer;
import org.wltea.analyzer.lucene.IKTokenizer;/*** @author lscl* @version 1.0* @intro: 自定义同义词分析器*/
public class MySynonymAnalyzer extends Analyzer {@Overrideprotected TokenStreamComponents createComponents(String fieldName) {// 1. 分词器IKTokenizer tokenizer = new IKTokenizer();// 2. token过滤器MySynonymTokeFilter tokenFilter = new MySynonymTokeFilter(tokenizer);return new TokenStreamComponents(tokenizer, tokenFilter);}
}- 3)测试代码:
package com.dfbz.demo05_分析器的使用;import com.dfbz.analyzer.MySynonymAnalyzer;
import com.dfbz.analyzer.MySynonymAnalyzer2;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;import java.io.StringReader;/*** @author lscl* @version 1.0* @intro:*/
public class Demo04_同义词查询 {@Testpublic void test1() throws Exception {Analyzer ikAnalyzer = new IKAnalyzer();Analyzer synonymAnalyzer = new MySynonymAnalyzer();String txt = "我来自中国";System.out.println("IKAnalyzer: ");showAnalyzerInfo(ikAnalyzer, txt);System.out.println("SynonymAnalyzer: ");showAnalyzerInfo(synonymAnalyzer, txt);}public void showAnalyzerInfo(Analyzer analyzer, String txt) throws Exception {/*对内容进行分词参数1: 分词的域(可以不写)参数2: 分词的文本*/TokenStream tokenStream = analyzer.tokenStream("xxx", new StringReader(txt));// 需要重置一下stream,让内部指针回到头部tokenStream.reset();// 使用CharTermAttribute保存分词后的每一个词组CharTermAttribute termAttribute = tokenStream.addAttribute(CharTermAttribute.class);// 遍历词组,如果还有下一个词组就进入循环while (tokenStream.incrementToken()) {System.out.println(termAttribute.toString());}System.out.println("----------------------");}
}
对"我来自中国"文本进行分词:
IKAnalyzer:
我来
我
来自
中国
----------------------
SynonymAnalyzer:
我来
我、咱、俺、洒家
来自
中国、天朝、大陆、华夏
----------------------
2)使用Lucene内置过滤器
【自定义分析器集成SynonymGraphFilter】
package com.dfbz.analyzer;import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.synonym.SynonymGraphFilter;
import org.apache.lucene.analysis.synonym.SynonymMap;
import org.apache.lucene.util.CharsRef;
import org.wltea.analyzer.lucene.IKTokenizer;import java.io.IOException;/*** @author lscl* @version 1.0* @intro: 自定义同义词分析器*/
public class MySynonymAnalyzer2 extends Analyzer {@Overrideprotected TokenStreamComponents createComponents(String fieldName) {try {// 1. 分词器IKTokenizer tokenizer = new IKTokenizer();// 2. token过滤器// 添加同义词SynonymMap.Builder synonymMapBuilder = new SynonymMap.Builder();synonymMapBuilder.add(new CharsRef("中国"), new CharsRef("天朝"), true);synonymMapBuilder.add(new CharsRef("中国"), new CharsRef("大陆"), true);synonymMapBuilder.add(new CharsRef("中国"), new CharsRef("华夏"), true);synonymMapBuilder.add(new CharsRef("我"), new CharsRef("咱"), true);synonymMapBuilder.add(new CharsRef("我"), new CharsRef("俺"), true);synonymMapBuilder.add(new CharsRef("我"), new CharsRef("洒家"), true);SynonymMap synonymMap = synonymMapBuilder.build();SynonymGraphFilter tokenFilter = new SynonymGraphFilter(tokenizer, synonymMap, true);return new TokenStreamComponents(tokenizer, tokenFilter);} catch (IOException exception) {exception.printStackTrace();}return null;}
}
【测试代码】
@Test
public void test2() throws Exception {Analyzer ikAnalyzer = new IKAnalyzer();Analyzer synonymAnalyzer = new MySynonymAnalyzer2();String txt = "我来自中国";System.out.println("IKAnalyzer: ");showAnalyzerInfo(ikAnalyzer, txt);System.out.println("SynonymAnalyzer: ");showAnalyzerInfo(synonymAnalyzer, txt);}
对"我来自中国"文本进行分词:
IKAnalyzer:
我来
我
来自
中国
----------------------
SynonymAnalyzer:
我来
咱
俺
洒家
我
来自
天朝
大陆
华夏
中国
----------------------
5.3 Lucene原生分析器
5.3.1 StandardAnalyzer
- StandardAnalyzer分析器的拆分规则:
- 1)中文按照单字拆分,英文按照空格拆分
- 2)英文全部转换为小写
- 3)特殊字符会被过滤
【测试代码】
@Test
public void test2() throws Exception {Analyzer analyzer = new StandardAnalyzer();/*对内容进行分词参数1: 分词的域(可以不写)参数2: 分词的文本*/TokenStream tokenStream = analyzer.tokenStream("xxx", new StringReader("I am Chin ese 中国 人 * _ & "));// 需要重置一下stream,让内部指针回到头部tokenStream.reset();// 使用CharTermAttribute保存分词后的每一个词组CharTermAttribute attribute = tokenStream.addAttribute(CharTermAttribute.class);// 遍历词组,如果还有下一个词组就进入循环while (tokenStream.incrementToken()) {System.out.println(attribute.toString());}System.out.println("----------------------");
}
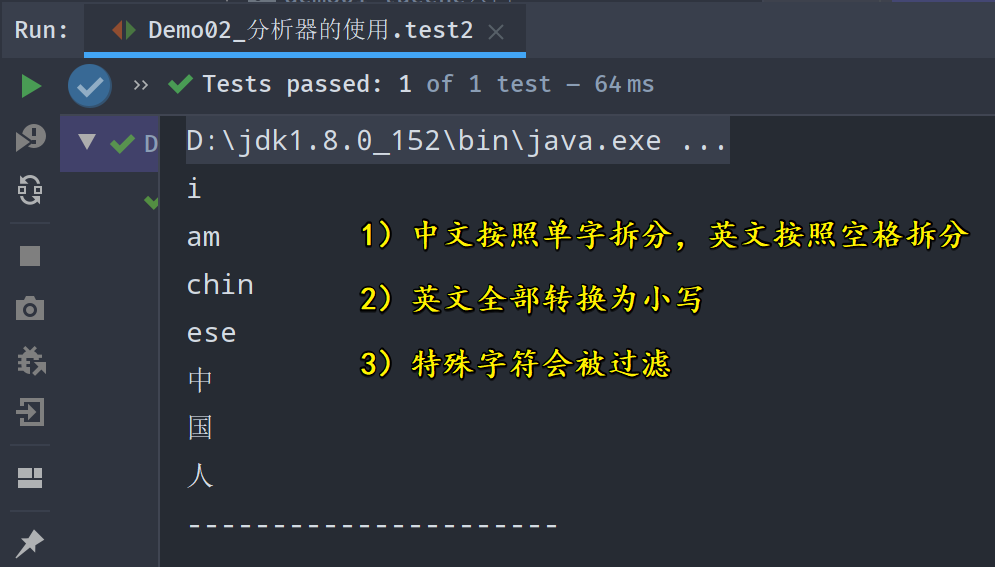
使用Luke查看分词情况:

使用Luke工具来分析文本:

5.3.2 SimpleAnalyzer
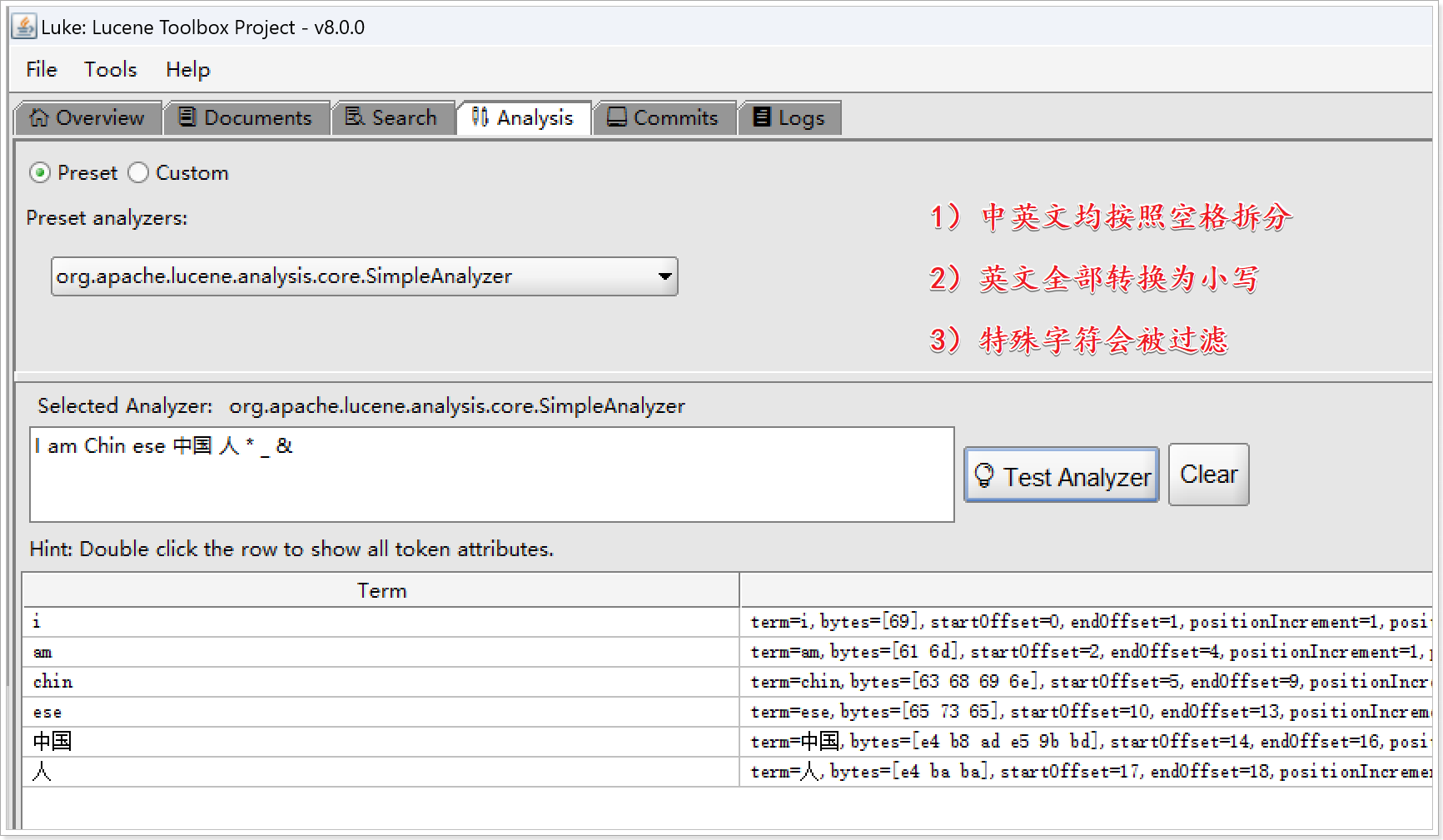
- SimpleAnalyzer分析器的拆分规则:
- 1)中英文均按照空格拆分
- 2)英文全部转换为小写
- 3)特殊字符会被过滤
分析文本:
I am Chin ese 中国 人 * _ &
5.3.3 WhitespaceAnalyzer
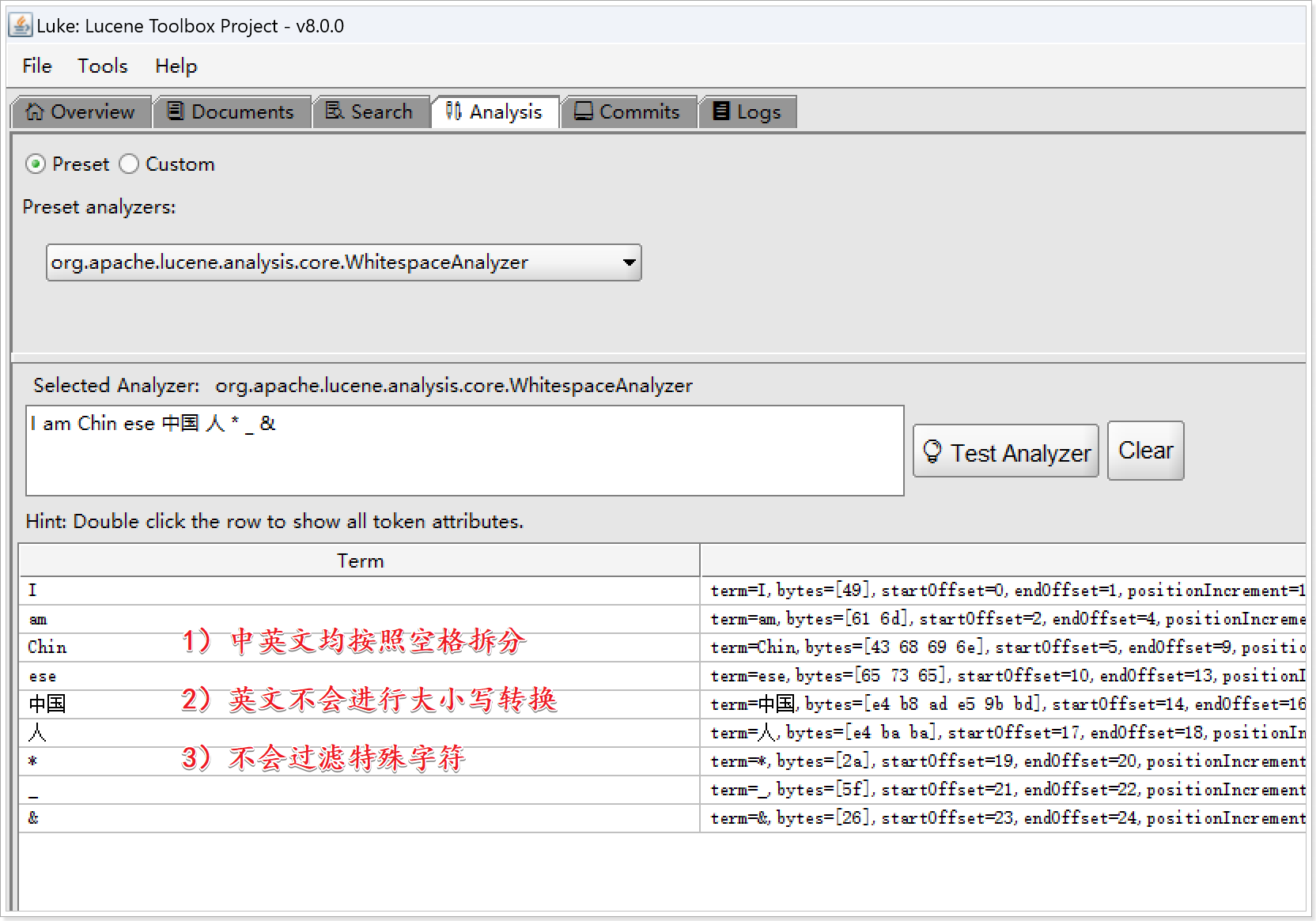
- WhitespaceAnalyzer分析器的拆分规则:
- 1)中英文均按照空格拆分
- 2)英文不会进行大小写转换
- 3)不会过滤特殊字符
【测试文本】
I am Chin ese 中国 人 * _ &
5.3.4 CJKAnalyzer
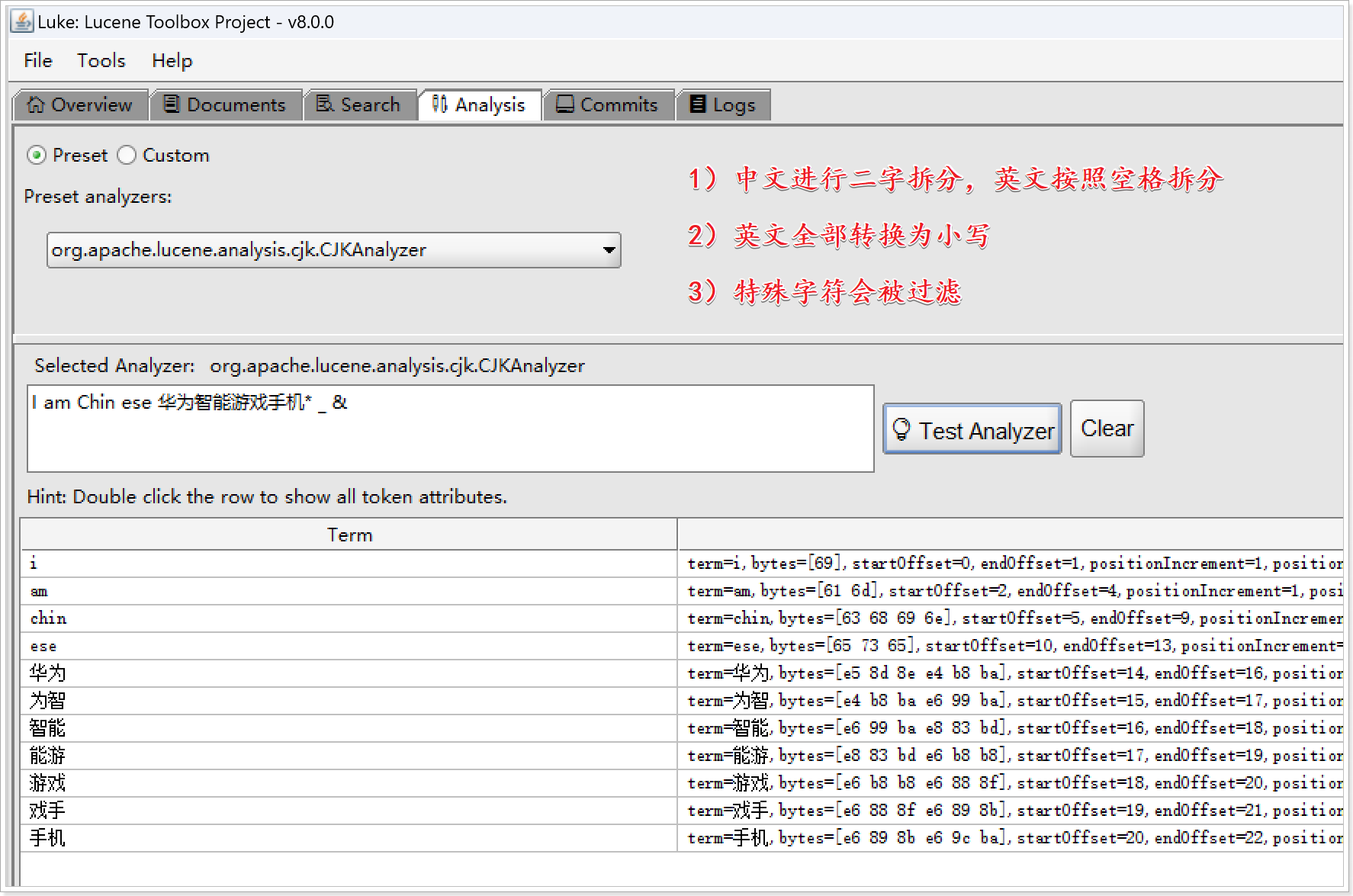
- CJKAnalyzer分析器的拆分规则:
- 1)中文进行二字拆分,英文按照空格拆分
- 2)英文全部转换为小写
- 3)特殊字符会被过滤
【测试文本】
I am Chin ese 华为智能游戏手机* _ &
5.3.5 SmartChineseAnalyzer
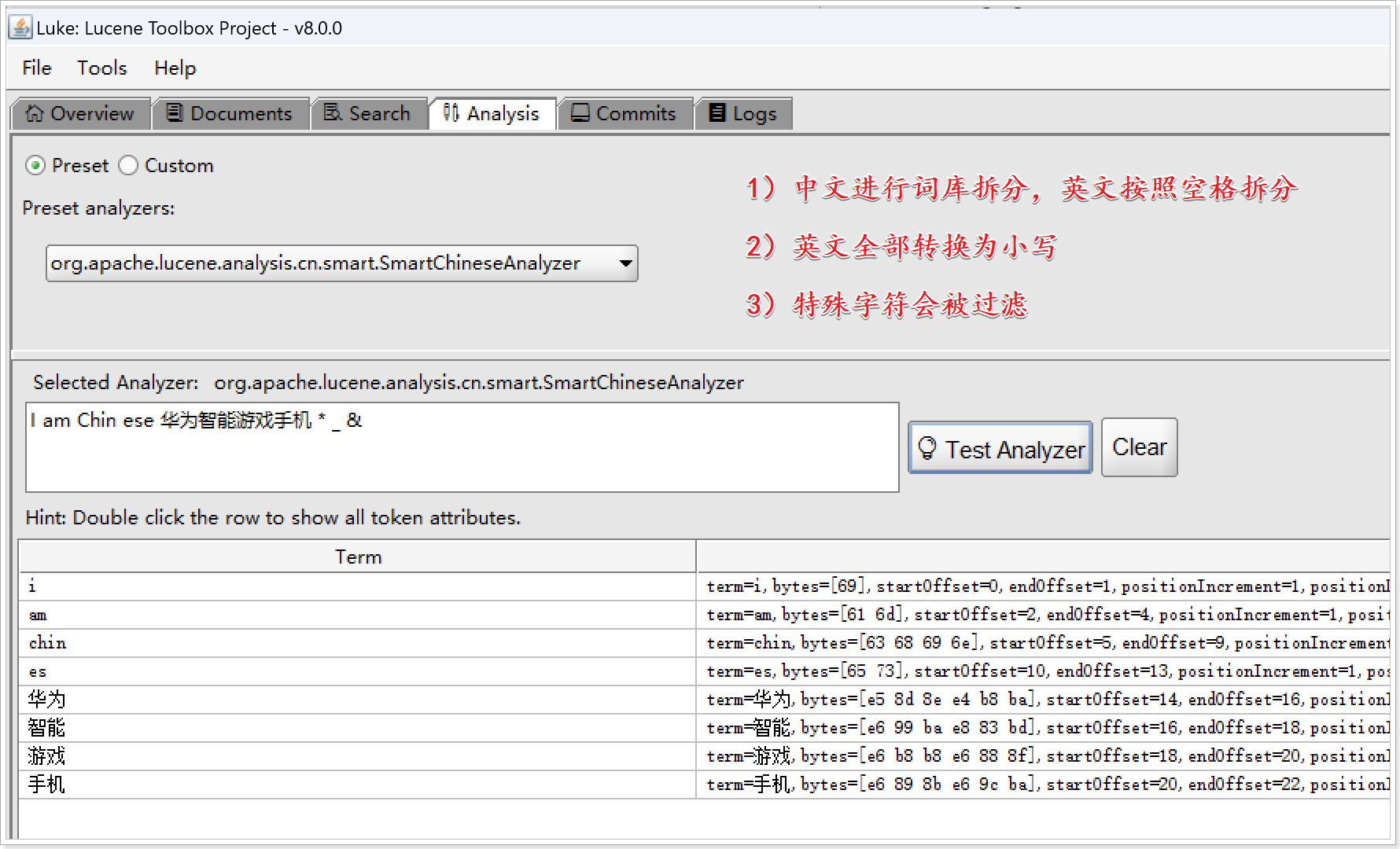
SmartChineseAnalyzer分析器的拆分规则:
- 1)中文进行词库拆分,英文按照空格拆分
- 2)英文全部转换为小写
- 3)特殊字符会被过滤
【测试文本】
I am Chin ese 华为智能游戏手机 * _ &
5.4 第三方中文分析器
我们都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。所以对于英文,我们可以简单以空格判断某个字符串是否为一个单词,比如I love China,love 和 China很容易被程序区分开来。
中文是以字为单位的,字与字再组成词,词再组成句子。中文:我是中国人,电脑不知道“是中”是一个词,还是“中国”是一个词?所以我们需要一定的规则来告诉电脑应该怎么切分,这就是中文分词器所要解决的问题。
5.4.1 IKAnalyzer
- IKAnalyzer:IK Analyzer是一个基于java语言开发的轻量级中文分词器包。采用词典分词的原理,允许使用者扩展词库。
最新版在 https://code.google.com/p/ik-analyzer/上,支持 Lucene 4.10 从 2006 年 12 月推出1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目 Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开 始,IK 发展为面向 Java 的公用分词组件,独立 于 Lucene 项目,同时提供了对 Lucene 的默认优化实现。适合在项目中应用。
IK Analyzer 2012 特性:
- 采用了特有的 “正向迭代最细粒度切分算法 “,支持细粒度和智能分词两种切分模式;
- 在系统环境:Core2 i7 3.4G 双核,4G 内存,window 7 64 位, Sun JDK 1.6_29 64 位 普通 pc 环境测试,IK2012 具有 160 万字 / 秒(3000KB/S)的高速处理能力。
- 2012 版本的智能分词模式支持简单的分词排歧义处理和数量词合并输出。
- 采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符
- 优化的词典存储,更小的内存占用。支持用户词典扩展定义。特别的,在 2012 版本,词典支持中文,英文,数字混合词语。
<dependency><groupId>com.github.magese</groupId><artifactId>ik-analyzer</artifactId><version>8.0.0</version></dependency>IK分词器提供有灵活拆分、最细粒度拆分两种拆分方法;其中灵活拆分更加能够贴近搜索的含义,最细粒度拆分则能够分出更多的词组;
【示例代码】
package com.dfbz.demo05_中文分析器;import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import org.wltea.analyzer.lucene.IKAnalyzer;import java.io.StringReader;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01_IKAnalyzer {@Testpublic void test1() throws Exception {/*** 是否灵活拆分* true: 灵活拆分* false: 最细粒度拆分(默认值)*/Analyzer analyzer = new IKAnalyzer(true);TokenStream tokenStream = analyzer.tokenStream("xx", new StringReader("华为5G游戏手机"));CharTermAttribute attribute = tokenStream.addAttribute(CharTermAttribute.class);tokenStream.reset();while (tokenStream.incrementToken()){System.out.println(attribute);}tokenStream.close();}
}
- 灵活拆分:
华为、5g、游戏手机
- 最细粒度拆分:
华为、5g、5、g、游戏手机、游戏手、游戏、手机、手、机
另外,IK分析器还提供另一种自己独特的分词API:
@Test
public void test2() throws Exception {/*** 是否灵活拆分* true: 灵活拆分* false: 最细粒度拆分(默认值)*/IKSegmenter segmenter = new IKSegmenter(new StringReader("小米5G智能游戏手机"), true);// 保存每一个词组Lexeme lexeme;while ((lexeme = segmenter.next()) != null) {String word = lexeme.getLexemeText();System.out.println(word);}
}
- 拆分情况:
小米、5g、智能、游戏手机
5.4.2 ANSJ
- Ansj:Ansj 是一个开源的 Java 中文分词工具,基于中科院的 ictclas 中文分词算法,比其他常用的开源分词工具(如mmseg4j)的分词准确率更高。Ansj中文分词是一款纯Java的、主要应用于自然语言处理的、高精度的中文分词工具,目标是“准确、高效、自由地进行中文分词”,可用于人名识别、地名识别、组织机构名识别、多级词性标注、关键词提取、指纹提取等领域,支持行业词典、用户自定义词典。
<!--ansj核心包-->
<dependency><groupId>org.ansj</groupId><artifactId>ansj_seg</artifactId><version>5.1.6</version></dependency>【示例代码】
package com.dfbz.demo05_中文分析器;import org.ansj.domain.Result;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.BaseAnalysis;
import org.junit.Test;import java.util.List;/*** @author lscl* @version 1.0* @intro:*/
public class Demo02_ANSJ {@Testpublic void test1() throws Exception {Result result = BaseAnalysis.parse("华为5G游戏手机");// 获取所有词组List<Term> terms = result.getTerms();for (Term term : terms) {System.out.println(term.getName());}}
}
- 拆分情况:
华为、5、g、游戏、手机
5.4.3 MMSeg4J
- MMSeg4J:mmseg4j用Chih-Hao Tsai 的MMSeg算法实现的中文分词工具包,并实现lucene的analyzer和solr的r中使用。 MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex加了四个规则。官方说:词语的正确识别率达到了 98.41%。mmseg4j已经实现了这两种分词算法。
<dependency><groupId>com.chenlb.mmseg4j</groupId><artifactId>mmseg4j-core</artifactId><version>1.10.0</version></dependency>5.4.4 ICTCLAS
- ICTCLAS:ICTCLAS分词器是中国科学院计算技术研究所在多年研究工作积累的基础上,研制出了汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),基于完全C/C++编写,主要功能包括中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。先后精心打造五年,内核升级6次,目前已经升级到了ICTCLAS3.0。ICTCLAS3.0分词速度单机996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M,是当前世界上最好的汉语词法分析器,商业收费。
<dependency><groupId>com.github.yujiaao.ictclas4j</groupId><artifactId>ictclas4j</artifactId><version>1.1.1</version></dependency>


















