目录
一、WordCloud库
例子:
结果:
二、Jieba库
两个基本方法
jieba.cut()
jieba.cut_for_serch()
关键字提取:
jieba.analyse包
一、WordCloud库
词云图,以视觉效果提现关键词,可以过滤文本信息,掌握关键信息,通过一个例子理解它的大概用法
例子:
pip install wordcloud由于一开始一直报字体文件格式错误(明明是 .ttf 没什么问题),因此在晚上查到需要把pillow库更新一下, 解决了
conda update pillow代码:
from wordcloud import WordCloud
with open(r"C:\Users\zxd\Desktop\a_new_hope.txt",mode='r',encoding="utf-8") as file:# 数据文件txt = file.read()# 如果数据文件中包含的有中文的话,font_path必须指定字体,否则中文会乱码# collocations:是否包括两个词的搭配,默认为True,如果为true的时候会有重复的数据,这里我不需要重复数据,所以设置为False# generate 读取文本文件mycloud = WordCloud(font_path=r"C:\Windows\Fonts\msyh.ttc",collocations=False,max_words=50).generate(txt)# 生成image = mycloud.to_image()# 展示image.show()# 写入文件
# mycloud.to_file("tag.jpg")WordCloud实例化参数:
- font_path:字体路径,若为英文可以不指定,若文本含中文需指定字体否则会乱码(windows绝对路径为:"C:/Windows/Fonts/xxx",也可以将文件放到项目的相对路径下面),注意仅支持使用 .ttf 格式的字体
- collocation:是否包含两个词的搭配
- max_words:显示词的最大个数
- width/height/background_color:其他图形设置
实例化后的几个方法:
- WordCloud().generate(txt文件):传递文本数据
- mycloud.to_image():将词云图生成
- image.show():展示图片
- mycloud.to_file():写入到文件
结果:
txt 的赋值可以自己随便敲单词,文本即可


二、Jieba库
在使用 wordcloud 时,处理中文文本有可能会出现以下问题:

我用了一个较短文本,可以看出通过 wordcloud 方法划分后的并不是词,而是句子,这是由于英文分词可以通过空格拆分,中文会不准确,因此我们需要针对性地做分词,分词后,再传递给 wordcloud
两个基本方法
jieba.cut()
- 字符串
- cut_all:默认 False精确模式,否则为全模式
- 是否使用HMM模型
jieba.cut_for_serch()
- 字符串
- 是否使用HMM模型
返回迭代器,每个元素是拆分后的一个词
 直接上例子看区别,根据个人需求选择
直接上例子看区别,根据个人需求选择
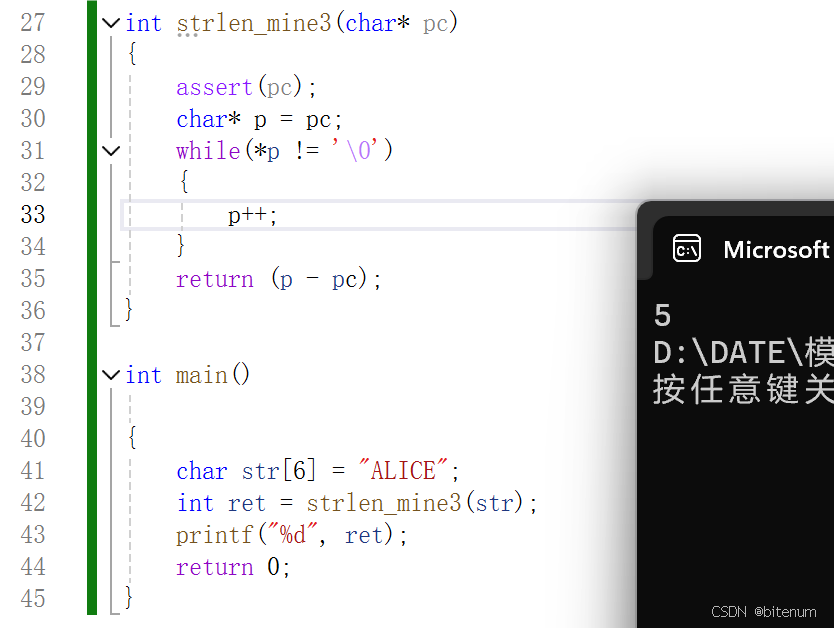
import jiebaprint(' '.join(jieba.cut('林妹妹毕业于中国科学院计算机研究所,后前往日本东京大学深造',cut_all=True)))
print(' '.join(jieba.cut('林妹妹毕业于中国科学院计算机研究所,后前往日本东京大学深造',cut_all=False)))
print(' '.join(jieba.cut_for_search('林妹妹毕业于中国科学院计算机研究所,后前往日本东京大学深造')))林妹妹 妹妹 毕业 于 中国 中国科学院 科学 科学院 学院 计算 计算机 算机 研究 研究所 , 后 前往 往日 日本 日本东京大学 东京 东京大学 大学 深造林妹妹 毕业 于 中国科学院 计算机 研究所 , 后 前往 日本东京大学 深造妹妹 林妹妹 毕业 于 中国 科学 学院 科学院 中国科学院 计算 算机 计算机 研究 研究所 , 后 前往 日本 东京 大学 日本东京大学 深造关键字提取:
from wordcloud import WordCloud
with open(r"C:\Users\zxd\Desktop\新蝙蝠侠评论.txt",mode='r',encoding="utf-8") as file:# 读取数据文件txt = file.read()# 如果数据文件中包含的有中文的话,font_path必须指定字体,否则中文会乱码# collocations:是否包括两个词的搭配,默认为True,如果为true的时候会有重复的数据,这里我不需要重复数据,所以设置为False# generate 读取文本文件mycloud = WordCloud(font_path=r"C:\Windows\Fonts\msyh.ttc",collocations=False,max_words=50).generate(jb_txt)# 生成image = mycloud.to_image()# 展示image.show()# 写入文件
# mycloud.to_file("tag.jpg")在使用上述代码分析中文文本过程中,我们又遇到新问题:

有许多如“我”、“是”、“的”等无效信息,因此需要进一步处理
jieba.analyse包
里面有一个 extract_tags() 方法,可以用于提取关键字,返回一个可以迭代的列表,方法的具体介绍可以再看看这个文章
3、Python 中文分词组件Jieba_jieba.analyse-CSDN博客
extract_tags()方法:
重要参数:
- text,写入的文本
- topK:返回关键词的数量,重要性从高到底排序
- withWeight:是否同时返回每个关键字的权重
- allowPOS=():词性过滤,n、v、a 等,可传入元组
from wordcloud import WordCloud
import jieba.analysewith open(r"C:\Users\zxd\Desktop\新蝙蝠侠评论.txt",mode='r',encoding="utf-8") as file:# 读取数据文件txt = file.read()#获取关键字标签txt_tag_list=jieba.analyse.extract_tags(txt,allowPOS=('n'))print(analysed_txt_list)print(type(analysed_txt_list))['蝙蝠侠', '电影', '谜语', '剧情', '猫女', '小时', '黑色', '蝙蝠', '镜头', '正义', '氛围', '故事', '漫画', '全片', '观众', '人物', '感觉', '角色', '骑士', '文艺']
<class 'list'>使用 extract_tags() 做词云图
from wordcloud import WordCloud
import jieba.analysewith open(r"C:\Users\zxd\Desktop\新蝙蝠侠评论.txt",mode='r',encoding="utf-8") as file:# 读取数据文件txt = file.read()txt_tag_list=jieba.analyse.extract_tags(txt,allowPOS=('n'))print(analysed_txt_list)print(type(analysed_txt_list))analysed_txt_tag=' '.join(txt_tag_list)# 如果数据文件中包含的有中文的话,font_path必须指定字体,否则中文会乱码# generate 读取文本文件mycloud = WordCloud(font_path=r"C:\Windows\Fonts\msyh.ttc",collocations=False,max_words=20).generate(analysed_txt_tag)# 生成image = mycloud.to_image()# 展示image.show()