spark-on-k8s 介绍
摘要
最近一段时间都在做与spark相关的项目,主要是与最近今年比较火的隐私计算相结合,主要是在机密计算领域使用spark做大数据分析、SQL等业务,从中也了解到了一些spark的知识,现在做一个简单的总结,主要关注spark on k8s模式。
需要先从大数据开始讲起,大数据应用是指运行在大数据处理框架之上,对大数据进行分布处理的应用,典型的框架如:Hadoop MapReduce、Spark、Flink、Hive等等,可以应用于日志挖掘、SQL查询、机器学习等等。
处理大数据需要借助MapReduce编程模型,典型的大数据框架也是基于该编程模型实现的,该模型可以将大型数据处理任务分解成很多单个的、可以在服务器集群中并行执行的任务,而这些任务的计算结果可以合并在一起来计算最终的结果。
MapReduce
主要包含两个基本的数据转换操作:map过程和reduce过程。
map:
map操作会将集合中的元素从一种形式转化成另一种形式,在这种情况下,输入的键值对会被转换成零到多个键值对输出。
reduce:
某个键的所有键值对都会被分发到同一个reduce操作中,确切的说,这个键和这个键所对应的所有值都会被传递给同一个Reducer。reduce过程的目的是将值的集合转换成一个值(例如求和或者求平均),或者转换成另一个集合。这个Reducer最终会产生一个键值对。
下面这张图很清晰的展示了MapReduce的过程:

举个例子,我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。简单来说,Map就是“分”而Reduce就是“合” 。
主要包含: (input) ->map-> ->combine-> ->reduce-> (output)
然后我们结合spark理解一下上面的过程,spark中有数据分区partition的概念,对应图中的输入。每个partition对应一个task,也就是图中的Mapper Task,执行Map操作。如果spark集群中的worker数量越多,每个worker分配的CPU核心数越多,则同一时间并发执行的Mapper Task越多,这样可以提升整体任务执行的效率。
Map操作结束后,需要将Map的结果按key相同进行合并,这就是spark中的shuffle阶段,在spark日志中我们可以明显的观察到这些阶段:
2024-10-22 01:46:33,399 INFO org.apache.spark.scheduler.TaskSetManager - Starting task 752.0 in stage 3.0 (TID 756) (10.244.2.48, executor 4, partition 752, PROCESS_LOCAL, 4930 bytes) taskResourceAssignments Map()
2024-10-22 01:46:33,399 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 744.0 in stage 3.0 (TID 748) in 3102 ms on 10.244.2.48 (executor 4) (744/755)
2024-10-22 01:46:33,635 INFO org.apache.spark.scheduler.TaskSetManager - Starting task 753.0 in stage 3.0 (TID 757) (10.244.2.47, executor 2, partition 753, PROCESS_LOCAL, 4930 bytes) taskResourceAssignments Map()
2024-10-22 01:46:33,636 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 743.0 in stage 3.0 (TID 747) in 3485 ms on 10.244.2.47 (executor 2) (745/755)
2024-10-22 01:46:34,033 INFO org.apache.spark.scheduler.TaskSetManager - Starting task 754.0 in stage 3.0 (TID 758) (10.244.1.18, executor 9, partition 754, PROCESS_LOCAL, 4930 bytes) taskResourceAssignments Map()
2024-10-22 01:46:34,033 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 745.0 in stage 3.0 (TID 749) in 3544 ms on 10.244.1.18 (executor 9) (746/755)
2024-10-22 01:46:34,358 INFO org.apache.spark.scheduler.TaskSetManager - Starting task 0.0 in stage 4.0 (TID 759) (10.244.3.180, executor 1, partition 0, PROCESS_LOCAL, 4944 bytes) taskResourceAssignments Map()
2024-10-22 01:46:34,358 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 746.0 in stage 3.0 (TID 750) in 3324 ms on 10.244.3.180 (executor 1) (747/755)
2024-10-22 01:46:34,383 INFO org.apache.spark.storage.BlockManagerInfo - Added broadcast_6_piece0 in memory on 10.244.3.180:41365 (size: 16.5 KiB, free: 2.1 GiB)
2024-10-22 01:46:35,749 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 747.0 in stage 3.0 (TID 751) in 3268 ms on 10.244.2.49 (executor 7) (748/755)
2024-10-22 01:46:35,828 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 748.0 in stage 3.0 (TID 752) in 3327 ms on 10.244.1.16 (executor 3) (749/755)
2024-10-22 01:46:36,035 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 749.0 in stage 3.0 (TID 753) in 3471 ms on 10.244.3.181 (executor 5) (750/755)
2024-10-22 01:46:36,480 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 750.0 in stage 3.0 (TID 754) in 3544 ms on 10.244.1.17 (executor 6) (751/755)
2024-10-22 01:46:36,800 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 0.0 in stage 4.0 (TID 759) in 2485 ms on 10.244.3.180 (executor 1) (1/1)
2024-10-22 01:46:36,843 INFO org.apache.spark.scheduler.TaskSchedulerImpl - Removed TaskSet 4.0, whose tasks have all completed, from pool
2024-10-22 01:46:36,834 INFO org.apache.spark.scheduler.DAGScheduler - ShuffleMapStage 4 (count at NativeMethodAccessorImpl.java:0) finished in 323.208 s
2024-10-22 01:46:36,825 INFO org.apache.spark.scheduler.DAGScheduler - looking for newly runnable stages
2024-10-22 01:46:36,803 INFO org.apache.spark.scheduler.DAGScheduler - running: Set(ShuffleMapStage 3)
2024-10-22 01:46:36,814 INFO org.apache.spark.scheduler.DAGScheduler - waiting: Set(ShuffleMapStage 5, ResultStage 6)
2024-10-22 01:46:36,837 INFO org.apache.spark.scheduler.DAGScheduler - failed: Set()
2024-10-22 01:46:36,903 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 751.0 in stage 3.0 (TID 755) in 3669 ms on 10.244.3.182 (executor 8) (752/755)
2024-10-22 01:46:37,186 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 752.0 in stage 3.0 (TID 756) in 3772 ms on 10.244.2.48 (executor 4) (753/755)
2024-10-22 01:46:37,249 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 753.0 in stage 3.0 (TID 757) in 3525 ms on 10.244.2.47 (executor 2) (754/755)
2024-10-22 01:46:37,332 INFO org.apache.spark.scheduler.TaskSetManager - Finished task 754.0 in stage 3.0 (TID 758) in 3276 ms on 10.244.1.18 (executor 9) (755/755)
2024-10-22 01:46:37,332 INFO org.apache.spark.scheduler.TaskSchedulerImpl - Removed TaskSet 3.0, whose tasks have all completed, from pool
2024-10-22 01:46:37,332 INFO org.apache.spark.scheduler.DAGScheduler - ShuffleMapStage 3 (count at NativeMethodAccessorImpl.java:0) finished in 323.799 s
2024-10-22 01:46:37,355 INFO org.apache.spark.scheduler.DAGScheduler - looking for newly runnable stages
2024-10-22 01:46:37,333 INFO org.apache.spark.scheduler.DAGScheduler - running: Set()
2024-10-22 01:46:37,333 INFO org.apache.spark.scheduler.DAGScheduler - waiting: Set(ShuffleMapStage 5, ResultStage 6)
2024-10-22 01:46:37,333 INFO org.apache.spark.scheduler.DAGScheduler - failed: Set()
2024-10-22 01:46:37,333 INFO org.apache.spark.scheduler.DAGScheduler - Submitting ShuffleMapStage 5 (MapPartitionsRDD[27] at count at NativeMethodAccessorImpl.java:0), which has no missing parents
2024-10-22 01:46:37,361 INFO org.apache.spark.storage.memory.MemoryStore - Block broadcast_7 stored as values in memory (estimated size 58.5 KiB, free 2.1 GiB)
2024-10-22 01:46:37,361 INFO org.apache.spark.storage.memory.MemoryStore - Block broadcast_7_piece0 stored as bytes in memory (estimated size 28.8 KiB, free 2.1 GiB)
2024-10-22 01:46:37,362 INFO org.apache.spark.storage.BlockManagerInfo - Added broadcast_7_piece0 in memory on spark-861c5b92b02212c6-driver-svc.dios-task.svc:7079 (size: 28.8 KiB, free: 2.1 GiB)
2024-10-22 01:46:37,362 INFO org.apache.spark.SparkContext - Created broadcast 7 from broadcast at DAGScheduler.scala:1433
2024-10-22 01:46:37,363 INFO org.apache.spark.scheduler.DAGScheduler - Submitting 120 missing tasks from ShuffleMapStage 5 (MapPartitionsRDD[27] at count at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14))
当然,在Spark中没有明显的区分Map和Reduce阶段,而是将其抽象成一个Job,这些Job会对Spark中抽象出的RDD(弹性分布式数据集)进行处理,不同的RDD之间有依赖关系,同时也可以在执行完一个Job后缓存该Job输出的RDD,用于其它Job使用。
Spark中还有Stage的概念,Stage就是由RDD之间的依赖关系划分而来,一个Stage中包含多个操作,下图的Stage,我们可以看出是有两个输入,通过parquet读入数据,并进行业务逻辑处理。

ShuffleMapStage这种类别的stage看起来是包含了MapReduce的全过程。而ResultStage是保存结果的阶段。

同时在ShuffleMapStagestage执行过程中,还包括Shuffle Writer & Shuffle Read:
-
Shuffle Writer:当ShuffleMapStage、文件落盘,也相当于map阶段。它保证了数据的安全性,同时避免所有的数据都放在内存中,占用大量内存。 -
Shuffle Read:map过程会将文件写入磁盘,并且把位置信息会告诉Driver;reduce task启动前会向Driver获取磁盘文件的位置信息,然后去拉取数据。
Spark Application程序运行时三个核心概念:Job、Stage、Task,说明如下:
Job:由多个Task 的并行计算部分,一般Spark 中的action 操作(如 save、collect,后面进一步说明),会生成一个Job。
Stage:Job 的组成单位,一个Job 会切分成多个Stage,Stage 彼此之间相互依赖顺序执行,而每个Stage 是多个Task 的集合,类似map 和reduce stage。
Task:被分配到各个Executor 的单位工作内容,它是Spark 中的最小执行单位,一般来说有多少个Paritition
(物理层面的概念,即分支可以理解为将数据划分成不同部分并行处理),就会有多少个Task,每个Task 只会处理单一分支上的数据。
大数据处理框架架构
大数据处理框架一般都是主从(Master-Worker)架构,Master是整个框架的大脑,负责接受、管理、调度任务(依据Worker中资源的使用情况,或者说任务数量进行调度),并负责管理Worker。而Worker相当于计算域,负责执行具体的任务单元,并时刻与Master保持心跳连接。Worker中同时执行的任务数量是由分配的CPU核心数决定的。在Spark中Master相当于driver,Worker相当于executor,每个具体的任务相当于Task,也就是说Job中的Task可以被调度到不同的executor计算。

Spark on k8s
Kubernetes(简称 K8s)是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。它最初是由 Google 内部的 Borg 系统启发并设计的,于 2014 年作为开源项目首次亮相。
k8s APIServer对外提供接口,但是外部请求需要经过k8s集群安全机制的验证,在spark on k8s中,也有相应的配置。
Spark的部署方式目前有,local本地模式、standalone模式、spark on yarn模式、spark on mesos模式。
-
本地模式
Spark单机运行,一般用于开发测试。 -
Standalone模式
构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。缺点:需要常驻Master和Worker服务,需要每个节点提供spark运行时环境。 -
Spark on Yarn模式
Spark客户端直接连接Yarn。不需要额外构建Spark集群。 -
Spark on Mesos模式
Spark客户端直接连接Mesos。不需要额外构建Spark集群。 -
k8s模式
无需常驻spark相关的服务,支持容器化运行任何作业;不需要依赖节点运行时环境;更贴近云原生生态。
目前我看到的,使用比较多的是Spark on Yarn和k8s模式。
Spark on k8s模式介绍
如何运行
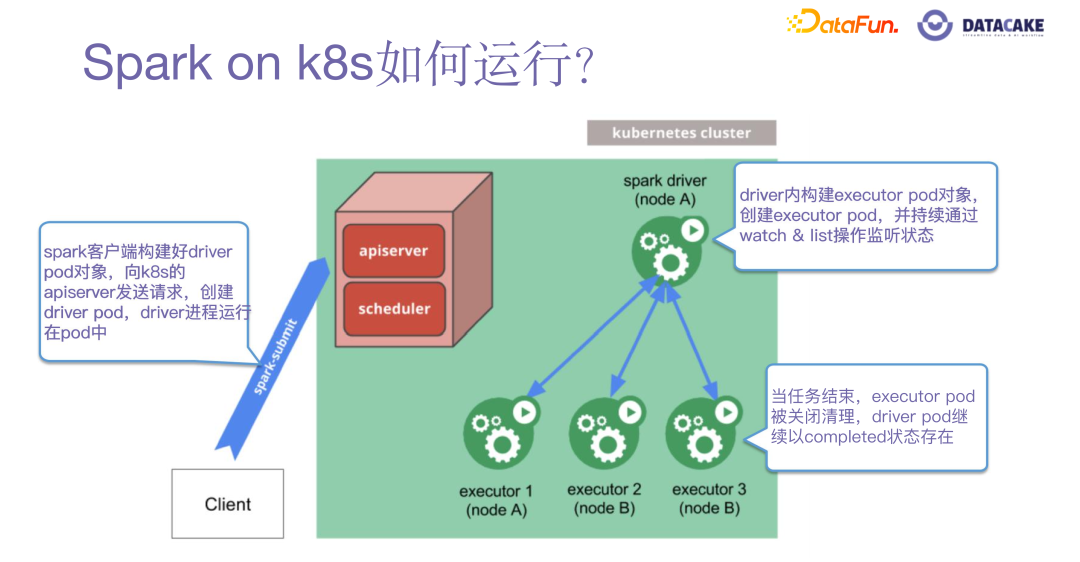
- spark客户端提交任务到apiserver,创建driver
- driver根据配置,创建指定数量的executor
- driver调度task到指定的executor计算
- 数据域和计算域都在executor
- 任务结束之后,driver销毁所有executor,同时自己也退出,也可以根据配置选择保留executor,状态是completed
模式
-
client mode
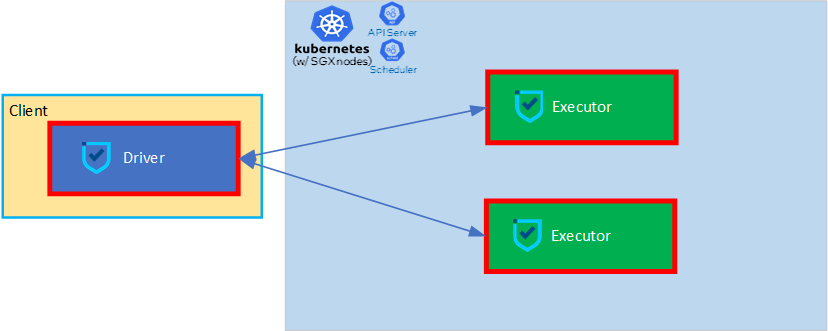
这种模式下,Driver进程相对于实际参与计算的executor而言,相当于一个第三方的client。在这里是k8s集群外的一个进程,在spark client容器里面cluster mode
-
cluster mode
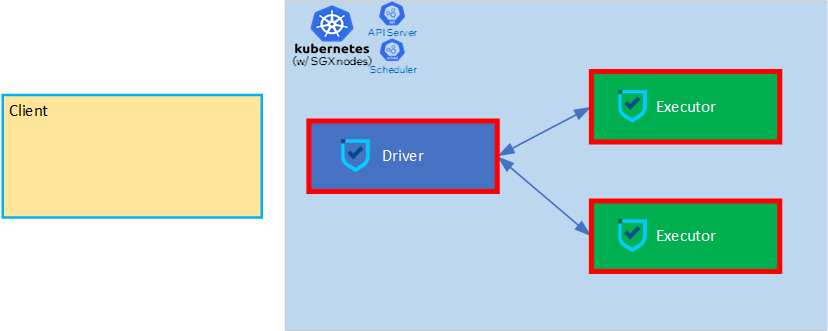
Driver进程是k8s集群内的一个进程。
常用的是Cluster模式。
安全性
-
Spark自身的安全性
-
认证:
spark内部连接的身份认证,借助k8s的secret资源实现
-
加密
使能基于AES的rpc加密,可以指定密钥长度和算法
-
本地存储加密
使能本地磁盘I/O读写加密,也就是落盘加密,可以指定密钥长度和算法
-
SSL加密
使能网络连接的SSL
具体展开,spark借助k8s的secret资源完成:
-
身份认证
--conf spark.authenticate=true \ --conf spark.authenticate.secret=$secure_password \ --conf spark.kubernetes.executor.secretKeyRef.SPARK_AUTHENTICATE_SECRET="spark-secret:secret" \ --conf spark.kubernetes.driver.secretKeyRef.SPARK_AUTHENTICATE_SECRET="spark-secret:secret" \ -
加密传输
--conf spark.ssl.enabled=true \--conf spark.ssl.port=8043 \--conf spark.ssl.keyPassword=$secure_password \--conf spark.ssl.keyStore=$KEY_STORE \--conf spark.ssl.keyStorePassword=$secure_password \--conf spark.ssl.keyStoreType=JKS \--conf spark.ssl.trustStore=$KEY_STORE \--conf spark.ssl.trustStorePassword=$secure_password \--conf spark.ssl.trustStoreType=JKS"
secure_password是创建keystore中密钥的密码短语,同时密钥短语创建为secret,以便spark集群内的driver,executor之间可以访问到,然后使用它完成身份认证。
keystore中存储了自签名的根证书,可以颁发二级证书,并建立双向认证的ssl加密链接。 -
-
Spark on k8s,k8s apiserver的访问授权(RBAC)参考:https://downloads.apache.org/spark/docs/3.1.3/running-on-kubernetes.html#rbac
-
k8s集群上创建专门为spark任务提供的serviceaccount
- 创建service account
- bind service account and user
- bind user and context
- bind context and cluster
- 切换到spark context下,导出config文件
-
将步骤1中的config文件拷贝到spark client中,用于提交任务时的鉴权
-
Spark image
简单说一下,spark image中包含:
- spark本身
- pyspark的依赖包,以及python
- 访问使用s3协议之类的jar包,如:
aws-java-sdk-bundle-1.11.375.jar、hadoop-aws-3.2.0.jar - 环境变量
-
/opt/entrypoint.sh
特别说一下/opt/entrypoint.sh,里面编写了一些启动逻辑,比如:如果启动driver,该执行哪个类,启动executor该执行哪个类。
并且,还可以通过修改这个脚本,修改一些java虚拟机的配置,比如:
- -Djdk.lang.Process.launchMechanism=fork
- -XX:MaxMetaspaceSize=$MAX_META_SPACE_SIZE
- -Xms$DRIVER_JVM_MEM_SIZE
- -Xmx$DRIVER_JVM_MEM_SIZE
- -Dlog4j.configuration=file:///opt/spark/logs-conf/log4j.properties
- -Duser.timezone=Asia/Shanghai
- -Dfile.encoding=UTF-8
等等.....
同时还可以通过环境变量结合该脚本实现一些URL和端口的绑定,总之,容器化真的太方便了,特别灵活。
Spark on k8s的配置
https://downloads.apache.org/spark/docs/3.1.3/running-on-kubernetes.html
具体的配置的介绍这里不再展开,大家可以自行参考官方文档,这里主要写一下我在实际使用中的一些经验。
spark客户端使用spark-submit提交任务到k8s集群,可以指定任务的配置,包括driver和executor的资源分配等等,如下是一个示例:
/app/spark313/bin/spark-submit \--master k8s://https://xxxxxx:6443 \--deploy-mode cluster \--name yeqc-pyspark \--conf spark.executor.instances=15 \--conf spark.rpc.netty.dispatcher.numThreads=4 \--conf spark.kubernetes.container.image=xxx \--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \--conf spark.kubernetes.authenticate.executor.serviceAccountName=spark \--conf spark.kubernetes.executor.deleteOnTermination=true \--conf spark.kubernetes.driver.podTemplateFile=./driver.yaml \--conf spark.kubernetes.executor.podTemplateFile=./executor.yaml \--conf spark.kubernetes.namespace=xxx-task \--conf spark.kubernetes.sgx.log.level=error \--conf spark.ssl.enabled=false \--conf spark.kubernetes.driverEnv.DRIVER_JVM_MEM_SIZE=4g \--conf spark.kubernetes.driverEnv.MAX_META_SPACE_SIZE=2g \--conf spark.executor.memory=4g \--conf spark.driver.memory=4g \--conf spark.extraListeners=xxx \--conf spark.kubernetes.file.upload.path=s3a://zlg-contract-lite/fileupload/ \--conf spark.hadoop.fs.s3a.access.key=xxx \--conf spark.hadoop.fs.s3a.endpoint=xxx \--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false \--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \--conf spark.hadoop.fs.s3a.fast.upload=true \--conf spark.hadoop.fs.s3a.secret.key=xxx \--conf spark.kubernetes.submission.connectionTimeout=500000 \--conf spark.kubernetes.submission.requestTimeout=500000 \--conf spark.kubernetes.driver.connectionTimeout=500000 \--conf spark.kubernetes.driver.requestTimeout=500000 \--conf spark.scheduler.maxRegisteredResourcesWaitingTime=120000 \--conf spark.executor.heartbeatInterval=100s \--conf spark.network.timeout=180s \kubernetes/tests/pi.py
在使用过程中发现:
—conf 的优先级大于 env 大于 yaml,可以通过--conf来做配置。
同时,spark的配置会依赖driver和executor容器中的环境变量,所以可以通过设定一些容器的环境变量,来实现传参,如下:
Environment:POD_NAME: gddp-offline-2k9w3xxz4-pn-mapping-v2-15757160322-gdios-cfdcf092b772789e-driver (v1:metadata.name)QUOTE_TYPE: gramineMALLOC_ARENA_MAX: 4SPARK_USER: gdiosSPARK_APPLICATION_ID: spark-236f30acd3d54cdabe786d6127f6ea2fMAX_META_SPACE_SIZE: 1gUSER_CODE_FILE_NAME: pn_xxx_v2_2K9W3XXZ4.pyDRIVER_JVM_MEM_SIZE: 4gHADOOP_USER_NAME: rootSPARK_DRIVER_BIND_ADDRESS: (v1:status.podIP)SPARK_AUTHENTICATE_SECRET: <set to the key 'secret' in secret 'spark-secret'> Optional: falseHADOOP_CONF_DIR: /opt/hadoop/confSPARK_LOCAL_DIRS: /var/data/spark-5747ce56-72e2-4e47-a95b-1e56773072edSPARK_CONF_DIR: /opt/spark/conf
可以通过参数:--conf spark.kubernetes.driverEnv.MAX_META_SPACE_SIZE=2g来设置driver的环境变量,比如这个设置了java进程的原空间,会在entrypoint.sh脚本中引用。
此外,spark会将spark-submit提交的参数,以k8s资源configmap挂载到容器内,然后容器内的程序去spark conf的默认路径读取该文件,来实现配置的传递。
如下被挂载到/opt/spark/conf,而该目录被设置成了环境变量SPARK_CONF_DIR:
Mounts:/app/log/ from app-log (rw)/opt/hadoop/conf from hadoop-properties (rw)/opt/spark/conf from spark-conf-volume-driver (rw)/opt/spark/pod-template from pod-template-volume (rw)/ppml/keys from secure-keys (rw)/root/.kube from kubeconfig (rw)/var/data/spark-5747ce56-72e2-4e47-a95b-1e56773072ed from spark-local-dir-1 (rw)/var/lib/kubelet/device-plugins from device-plugin (rw)/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-xmbdt (ro)...
hadoop-properties:Type: ConfigMap (a volume populated by a ConfigMap)Name: gddp-offline-2k9w3xxz4-pn-mapping-v2-15757160322-gdios-cfdcf092b772789e-hadoop-configOptional: falsepod-template-volume:Type: ConfigMap (a volume populated by a ConfigMap)Name: gddp-offline-2k9w3xxz4-pn-mapping-v2-15757160322-gdios-cfdcf092b772789e-driver-podspec-conf-mapOptional: falsespark-local-dir-1:Type: EmptyDir (a temporary directory that shares a pod's lifetime)Medium: SizeLimit: <unset>spark-conf-volume-driver:Type: ConfigMap (a volume populated by a ConfigMap)Name: spark-drv-17961592b772877b-conf-mapOptional: falsekube-api-access-xmbdt:Type: Projected (a volume that contains injected data from multiple sources)TokenExpirationSeconds: 3607ConfigMapName: kube-root-ca.crtConfigMapOptional: <nil>DownwardAPI: true
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300snode.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events: <none>
在项目中还遇到,本地的spark客户端提交spark任务到腾讯云的k8s集群失败的问题,那是因为公有云需要公网IP访问,而此IP没有注册到k8s集群的证书中。

还有超时时间太短的问题,报错:
Random KubernetesClientException: Operation: [create] for kind: [Pod] with name: [null] in namespace: [XXX] failed.
可以参考下面的配置增大任务提交的超时时间:

还有spark内部网络通信和driver与executor的心跳时间调整:


还有spark内部是默认有容错能力的,比如某个Task报错,driver会重新调度Task到其它executor执行,但是容错次数有限,默认是同一个Task连续失败4次,任务就终止了,可以适当增加重试次数,来提高成功率:

并发度的配置,根据集群资源设置合理的任务配置,根据任务配置设置合理的并发度配置,可以事半功倍,提升任务执行效率:

我们前面介绍过,每个partition对应一个Task,每个Task是最小的执行单元,所以如果CPU核心数很少,但是任务数量很多,这可能会降低任务的执行效率,一般的建议,Task数量是任务配置核心数的2到3倍。
其它配置可以参考spark官方文档,直接Google就可以。
Pyspark运行原理
主要还是围绕实际使用来介绍,可能不全或者有偏差。
如下图所示,pyspark任务是在driver和executor中,通过Fork/Vfork等系统调用创建的Python子进程,driver侧有一个python进程,executor侧有多个python进程,
取决于executor分配的CPU核心数,每个python进程是由一个独立的线程去维护,多核情况下,线程之间互斥的创建子进程。
同时,python进程会监听一个端口,java进程通过socket与python进程通信,也可以看到是借助Py4j实现的。
编写pyspark代码的时候,可以声明spark任务的配置:
# 初始化SparkSession
spark = SparkSession.builder.enableHiveSupport().config("spark.sql.shuffle.partitions", "400").config("spark.default.parallelism", "30").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").getOrCreate()

再贴两张图,可以更加清洗的展示具体的任务执行过程:
driver端:

executor端:

对了,上面的图片中提到了pyspark.daemon进程,它是负责创建python进程的管理器,可以配置参数,设置不启动它。
我目前的理解,pyspark与原生的spark应用(java或scala编写)的实现原理一致,只不过是换了一种语言来实现,比如说支持对RDD的map、join等操作,支持cache。
唯一的区别是pyspark需要额外创建python子进程,这对于大规模、超大数据的集群计算来说,会有比较高的资源消耗,同时进程间的通信也极大的影响任务执行效率,同时,对于一些特殊的业务,如隐私计算中的机密计算场景下,如果可信执行环境(TEE)对Fork、vFork等系统调用支持的不是很好,或者说需要很大的内存代价,则对spark任务有很大的影响,甚至在实际生产环境中完全不可用。
Spark开发——Pyspark & Scala demo
给出几个demo:
pyspark code
import time
from pyspark import SparkConf, SparkContext# 创建 SparkConf 对象
conf = SparkConf()# 打印配置信息
print("Spark Configuration:")
for key, value in conf.getAll():print(f"{key}: {value}")#time.sleep(300)
print('start rdd calculate')
conf = SparkConf().setAppName("rdd-test")
sc = SparkContext(conf=conf)
data = range(1024*1024)
rdd = sc.parallelize(data)
result = rdd.map(lambda x: x * 2).filter(lambda x: x > 5000)
print(result.collect())
scala code
import org.apache.spark.{SparkConf, SparkContext}object SimpleRDDMapExample {def main(args: Array[String]): Unit = {// 配置 Sparkval conf = new SparkConf().setAppName("SimpleRDDMapExample").setMaster("local[*]") // local模式val sc = new SparkContext(conf)// 创建一个 RDDval data = Seq(1, 2, 3, 4, 5)val rdd = sc.parallelize(data)// 使用 map 操作逐元素进行处理,假设我们对每个元素加 1val mappedRDD = rdd.map(x => x + 1)// 收集结果并打印val result = mappedRDD.collect()result.foreach(println)// 停止 SparkContextsc.stop()}
}submit demo
/root/dev_build/spark/bin/spark-submit \--master k8s://https://x.x.x.x:6443 \--deploy-mode cluster \--name zzy-pyspark \--conf spark.executor.instances=1 \--conf spark.rpc.netty.dispatcher.numThreads=4 \--conf spark.kubernetes.container.image=xxx \--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \--conf spark.kubernetes.authenticate.executor.serviceAccountName=spark \--conf spark.kubernetes.executor.deleteOnTermination=false \--conf spark.kubernetes.driver.podTemplateFile=./driver-8.yaml \--conf spark.kubernetes.executor.podTemplateFile=./executor-8.yaml \--conf spark.kubernetes.namespace=spark \--conf spark.kubernetes.sgx.log.level=error \--conf spark.ssl.enabled=false \--conf spark.executor.memory=8g \--conf spark.driver.memory=8g \--conf spark.kubernetes.driverEnv.SGX_DRIVER_JVM_MEM_SIZE=2g \--conf spark.kubernetes.file.upload.path=s3a://zlg-contract-lite/fileupload/ \--conf spark.hadoop.fs.s3a.access.key=xxx\--conf spark.hadoop.fs.s3a.endpoint=http://x.x.x.x:30099 \--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false \--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \--conf spark.hadoop.fs.s3a.fast.upload=true \--conf spark.hadoop.fs.s3a.secret.key=xxx\--conf spark.kubernetes.submission.connectionTimeout=50000 \--conf spark.kubernetes.submission.requestTimeout=50000 \--conf spark.kubernetes.driver.connectionTimeout=50000 \--conf spark.kubernetes.driver.requestTimeout=50000 \--conf spark.network.timeout=10000000 \--conf spark.executor.heartbeatInterval=10000000 \--verbose \kubernetes/tests/rdd_test.py
总结
总的来说spark对于大数据处理有其独特的优势,特别是结合k8s之后,大规模的集群计算变得更加轻便,可以完成绝大部分的统计计算任务。
但是spark这类复杂的应用在结合可信执行环境技术(TEE)的时候存在很多问题,TEE是由硬件确保内存中计算的安全性,相较普通操作系统、硬件而言,具有很高的使用难度,特别是提供进程级别安全隔离的TEE技术路线,实现难度极大,但是这些进程级别的TEE也提供一些库操作系统来实现Linux的系统调用,不过这些库操作系统对于应用的兼容性存在一定的问题,同时他们本身也存在一些问题,就会导致与复杂应用结合难度极大,或者说即便能运行,但是也存在各种各样的弊端。
算是入门spark的开头吧,后续会继续更新spark更加进阶的内容,如:spark逻辑处理流程、spark应用、shuffle、RDD、transformation操作、action操作等等。
参考
- spark on k8s 官方配置详解