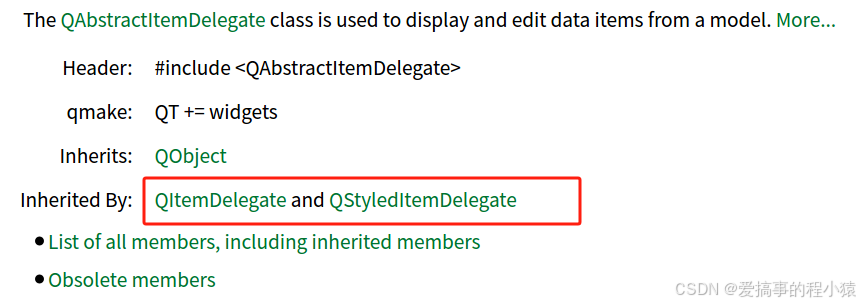
文章目录
- 前言
- 一、Zookeeper完全分布式部署(手动部署)
- 1. 下载Zookeeper
- 2. 上传安装包
- 2. 解压zookeeper安装包
- 3. 配置zookeeper配置文件
- 3.1 创建 zoo.cfg 配置文件
- 3.2 修改 zoo.cfg 配置文件
- 3.3 创建数据持久化目录并创建myid文件
- 4. 虚拟机hadoop2安装并配置Zookeeper
- 5. 虚拟机hadoop3安装并配置Zookeeper
- 6. 配置Zookeeper系统环境变量
- 4.1 配置虚拟机hadoop1的Zookeeper环境变量
- 4.2 配置虚拟机hadoop2的Zookeeper环境变量
- 4.3 配置虚拟机hadoop3的Zookeeper环境变量
- 5. 启动Zookeeper集群
- 6. 查看Zookeeper集群状态
- 二、使用shell脚本自动部署Zookeeper完全分布式(选看)
- 1. 下载Zookeeper
- 2. 上传安装包
- 3. 使用shell脚本自动部署Zookeeper完全分布式
- 3.1 创建 hadoop1_zookeeper_install_config.sh 脚本文件并添加脚本内容
- 3.2 添加可执行权限
- 3.3 执行脚本
- 4. 加载环境变量
- 5. 启动Zookeeper集群
- 6. 查看Zookeeper集群状态
前言
- 介绍在虚拟机hadoop1、hadoop2和hadoop3部署完全分布式Zookeeper
- 配置zookeeper配置文件
- 配置zookeeper环境变量
- 启动zookeeper及查看zookeeper集群状态
- 提供shell脚本自动化安装zookeeper完全分布式
一、Zookeeper完全分布式部署(手动部署)
1. 下载Zookeeper
点击下载zookeeper3.7.0安装包:https://archive.apache.org/dist/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
2. 上传安装包
通过拖移的方式将下载的zookeeper安装包apache-zookeeper-3.7.0-bin.tar.gz上传至虚拟机hadoop1的/export/software目录。

2. 解压zookeeper安装包
在虚拟机hadoop1上传完成后将zookeeper安装包通过解压方式安装至/export/servers目录。
tar -zxvf /export/software/apache-zookeeper-3.7.0-bin.tar.gz -C /export/servers/

重命名
在虚拟机hadoop1把解压后的安装目录apache-zookeeper-3.7.0-bin重命名为zookeeper-3.7.0,重命名是为了简化路径,其次是为了标准化命名。
mv /export/servers/apache-zookeeper-3.7.0-bin /export/servers/zookeeper-3.7.0

3. 配置zookeeper配置文件
3.1 创建 zoo.cfg 配置文件
在虚拟机hadoop1通过复制Zookeeper的模板配置文件zoo_sample.cfg创建配置文件zoo.cfg。
cp /export/servers/zookeeper-3.7.0/conf/zoo_sample.cfg /export/servers/zookeeper-3.7.0/conf/zoo.cfg

3.2 修改 zoo.cfg 配置文件
在虚拟机hadoop1修改 zoo.cfg 配置文件,执行如下命令修改和添加配置文件内容。
cat >/export/servers/zookeeper-3.7.0/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/export/data/zookeeper/zkdata
clientPort=2181server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
EOF

3.3 创建数据持久化目录并创建myid文件
在虚拟机hadoop1创建数据持久化目录并创建myid文件。
mkdir -p /export/data/zookeeper/zkdata
echo 1 > /export/data/zookeeper/zkdata/myid

在虚拟机hadoop2创建数据持久化目录并创建myid文件。
mkdir -p /export/data/zookeeper/zkdata
echo 2 > /export/data/zookeeper/zkdata/myid

在虚拟机hadoop3创建数据持久化目录并创建myid文件。
mkdir -p /export/data/zookeeper/zkdata
echo 3 > /export/data/zookeeper/zkdata/myid

4. 虚拟机hadoop2安装并配置Zookeeper
在虚拟机hadoop1使用scp命令把虚拟机hadoop1的zookeeper的安装目录复制到虚拟机hadoop2的相同目录下,就相当于在hadoop2安装并配置了zookeeper。
scp -r /export/servers/zookeeper-3.7.0/ hadoop2:/export/servers/

5. 虚拟机hadoop3安装并配置Zookeeper
在虚拟机hadoop1使用scp命令把虚拟机hadoop1的zookeeper的安装目录复制到虚拟机hadoop3的相同目录下,就相当于在hadoop3安装并配置了zookeeper。
scp -r /export/servers/zookeeper-3.7.0/ hadoop3:/export/servers/

6. 配置Zookeeper系统环境变量
4.1 配置虚拟机hadoop1的Zookeeper环境变量
在虚拟机hadoop1使用echo命令向环境变量配置文件/etc/profile追加环境变量内容。
echo >> /etc/profile
echo 'export ZK_HOME=/export/servers/zookeeper-3.7.0' >> /etc/profile
echo 'export PATH=$PATH:$ZK_HOME/bin' >> /etc/profile
配置环境变量后,需要使用如下命令加载环境变量配置文件/etc/profile,使用Zookeeper的环境变量生效。
source /etc/profile

4.2 配置虚拟机hadoop2的Zookeeper环境变量
在虚拟机hadoop2使用echo命令向环境变量配置文件/etc/profile追加环境变量内容。
echo >> /etc/profile
echo 'export ZK_HOME=/export/servers/zookeeper-3.7.0' >> /etc/profile
echo 'export PATH=$PATH:$ZK_HOME/bin' >> /etc/profile
配置环境变量后,需要使用如下命令加载环境变量配置文件/etc/profile,使用Zookeeper的环境变量生效。
source /etc/profile

4.3 配置虚拟机hadoop3的Zookeeper环境变量
在虚拟机hadoop3使用echo命令向环境变量配置文件/etc/profile追加环境变量内容。
echo >> /etc/profile
echo 'export ZK_HOME=/export/servers/zookeeper-3.7.0' >> /etc/profile
echo 'export PATH=$PATH:$ZK_HOME/bin' >> /etc/profile
配置环境变量后,需要使用如下命令加载环境变量配置文件/etc/profile,使用Zookeeper的环境变量生效。
source /etc/profile

5. 启动Zookeeper集群
在虚拟机hadoop1执行如下命令启动zookeeper。
zkServer.sh start

在虚拟机hadoop2执行如下命令启动zookeeper。
zkServer.sh start

在虚拟机hadoop3执行如下命令启动zookeeper。
zkServer.sh start

6. 查看Zookeeper集群状态
在虚拟机hadoop1执行如下命令查看Zookeeper集群状态是否正常。
zkServer.sh status

在虚拟机hadoop2执行如下命令查看Zookeeper集群状态是否正常。
zkServer.sh status

在虚拟机hadoop3执行如下命令查看Zookeeper集群状态是否正常。
zkServer.sh status

如果集群启动正常如上图所示,会有一个领导者leader,两个跟随者follower。
若要停止Zookeeper集群运行,依次在虚拟机hadoop1、hadoop2和hadoop3执行如下命令停止Zookeeper服务。
zkServer.sh stop
二、使用shell脚本自动部署Zookeeper完全分布式(选看)
1. 下载Zookeeper
点击下载zookeeper3.7.0安装包:https://archive.apache.org/dist/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
2. 上传安装包
通过拖移的方式将下载的zookeeper安装包apache-zookeeper-3.7.0-bin.tar.gz上传至虚拟机hadoop1的/export/software目录。
3. 使用shell脚本自动部署Zookeeper完全分布式
3.1 创建 hadoop1_zookeeper_install_config.sh 脚本文件并添加脚本内容
在虚拟机hadoop1上创建hadoop1_zookeeper_install_config脚本文件
touch /export/shell/hadoop1_zookeeper_install_config.sh
添加如下内容:
#!/bin/bash# 定义常量
ZK_VER="3.7.0"
ZK_BIN_TAR="apache-zookeeper-${ZK_VER}-bin.tar.gz"
ZK_DATA_DIR="/export/data/zookeeper/zkdata"
DATA_DIR="/export/data"
SOFTWARE_DIR="/export/software"
SERVERS_DIR="/export/servers"# 如果数据持久化目录存在则删除
if [ -d "${ZK_DATA_DIR}" ]; thenecho "删除 Hadoop1 的数据持久化目录 ${ZK_DATA_DIR}..."rm -rf ${ZK_DATA_DIR}
fissh root@hadoop2 \
"
if [ -d \"${ZK_DATA_DIR}\" ]; thenecho \"删除 Hadoop2 的数据持久化目录 ${ZK_DATA_DIR}...\"rm -rf ${ZK_DATA_DIR}
fi
exit
"ssh root@hadoop3 \
"
if [ -d \"${ZK_DATA_DIR}\" ]; thenecho \"删除 Hadoop3 的数据持久化目录 ${ZK_DATA_DIR}...\"rm -rf ${ZK_DATA_DIR}
fi
exit
"# 检查zookeeper是否已解压
if [ -d "${SERVERS_DIR}/apache-zookeeper-${ZK_VER}-bin" ]; thenecho "zookeeper安装程序已存在,正在删除原安装程序目录..."rm -rf "${SERVERS_DIR}/apache-zookeeper-${ZK_VER}-bin"
fi
if [ -d "${SERVERS_DIR}/zookeeper-${ZK_VER}" ]; thenecho "zookeeper安装程序已存在,正在删除原安装程序目录..."rm -rf "${SERVERS_DIR}/zookeeper-${ZK_VER}"
fi# 检查zookeeper安装包是否存在
if [ -f ${SOFTWARE_DIR}/${ZK_BIN_TAR} ]; thenecho "zookeeper安装包存在,正在解压安装包..."# 解压zookeeper安装包tar -zxvf ${SOFTWARE_DIR}/${ZK_BIN_TAR} -C ${SERVERS_DIR}echo "解压 ${SOFTWARE_DIR}/${ZK_BIN_TAR} 到 ${SERVERS_DIR} 目录成功"
elseecho "zookeeper安装包不存在,请先上传安装包到 ${SOFTWARE_DIR} 目录"exit 1
fi# 重命名
mv ${SERVERS_DIR}/apache-zookeeper-${ZK_VER}-bin ${SERVERS_DIR}/zookeeper-${ZK_VER}
if [ $? -eq 0 ]; thenecho "${SERVERS_DIR}/apache-zookeeper-${ZK_VER}-bin 重命名为 ${SERVERS_DIR}/zookeeper-${ZK_VER} 成功"
elseecho "${SERVERS_DIR}/apache-zookeeper-${ZK_VER}-bin 重命名为 ${SERVERS_DIR}/zookeeper-${ZK_VER}失败,请检查"exit 1
fi# 创建zoo.cfg配置文件
cp ${SERVERS_DIR}/zookeeper-${ZK_VER}/conf/zoo_sample.cfg ${SERVERS_DIR}/zookeeper-${ZK_VER}/conf/zoo.cfg
if [ $? -eq 0 ]; thenecho "ZooKeeper 配置文件 zoo.cfg 创建成功"
elseecho "ZooKeeper 配置文件 zoo.cfg 创建失败,请检查"exit 1
fi# 修改zoo.cfg配置文件内容
cat >${SERVERS_DIR}/zookeeper-${ZK_VER}/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/export/data/zookeeper/zkdata
clientPort=2181server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
EOF
echo "${SERVERS_DIR}/zookeeper-${ZK_VER}/conf/zoo.cfg 配置文件修改成功"# 创建数据持久化目录并创建myid文件
mkdir -p /export/data/zookeeper/zkdata
echo 1 > /export/data/zookeeper/zkdata/myid
if [ $? -eq 0 ]; thenecho 'Hadoop1 创建数据持久化目录并创建 myid 文件成功'
elseecho 'Hadoop1 创建数据持久化目录并创建 myid 文件失败,请检查'exit 1
fissh root@hadoop2 \
"
mkdir -p /export/data/zookeeper/zkdata
echo 2 > /export/data/zookeeper/zkdata/myid
if [ $? -eq 0 ]; thenecho 'Hadoop2 创建数据持久化目录并创建 myid 文件成功'
elseecho 'Hadoop2 创建数据持久化目录并创建 myid 文件失败,请检查'
fi
exit
"ssh root@hadoop3 \
"
mkdir -p /export/data/zookeeper/zkdata
echo 3 > /export/data/zookeeper/zkdata/myid
if [ $? -eq 0 ]; thenecho 'Hadoop3 创建数据持久化目录并创建 myid 文件成功'
elseecho 'Hadoop3 创建数据持久化目录并创建 myid 文件失败,请检查'
fi
exit
"# 配置ZooKeeper系统环境变量
if [ -n "$ZK_HOME" ]; thenecho "Hadoop1 ZooKeeper 环境变量已配置:$ZK_HOME"
elseecho >> /etc/profileecho 'export ZK_HOME=/export/servers/zookeeper-3.7.0' >> /etc/profileecho 'export PATH=$PATH:$ZK_HOME/bin' >> /etc/profileecho "Hadoop1 ZooKeeper 环境变量配置成功"
fi# 分发环境变量配置文件到hadoop2
scp /etc/profile root@hadoop2:/etc/
if [ $? -eq 0 ]; thenecho "分发 /etc/profile 到 hadoop2 的 /etc 目录成功"
elseecho "分发 /etc/profile 到 hadoop2 的 /etc 目录失败,请检查"exit 1
fi# 分发环境变量配置文件到hadoop3
scp /etc/profile root@hadoop3:/etc/
if [ $? -eq 0 ]; thenecho "分发 /etc/profile 到 hadoop3 的 /etc 目录成功"
elseecho "分发 /etc/profile 到 hadoop3 的 /etc 目录失败,请检查"exit 1
fi# 分发安装程序到hadoop2
scp -r ${SERVERS_DIR}/zookeeper-${ZK_VER} root@hadoop2:${SERVERS_DIR}/
if [ $? -eq 0 ]; thenecho "分发 ${SERVERS_DIR}/zookeeper-${ZK_VER} 到 hadoop2 的 ${SERVERS_DIR} 目录成功"
elseecho "分发 ${SERVERS_DIR}/zookeeper-${ZK_VER} 到 hadoop2 的 ${SERVERS_DIR} 目录失败,请检查"exit 1
fi# 分发安装程序到hadoop3
scp -r ${SERVERS_DIR}/zookeeper-${ZK_VER} root@hadoop3:${SERVERS_DIR}/
if [ $? -eq 0 ]; thenecho "分发 ${SERVERS_DIR}/zookeeper-${ZK_VER} 到 hadoop3 的 ${SERVERS_DIR} 目录成功"
elseecho "分发 ${SERVERS_DIR}/zookeeper-${ZK_VER} 到 hadoop3 的 ${SERVERS_DIR} 目录失败,请检查"exit 1
fiecho -e "\n-----zookeeper 完全分布式安装配置完成-----\n"
echo -e "1. 依次在虚拟机Hadoop1、Hadoop2和Hadoop3执行命令 \e[31msource /etc/profile\e[0m 加载环境变量\n"
echo -e "2. 依次在虚拟机Hadoop1、Hadoop2和Hadoop3启动ZooKeeper服务:\e[31mzkServer.sh start\e[0m\n"
echo -e "3. 依次在虚拟机Hadoop1、Hadoop2和Hadoop3查看ZooKeeper服务状态:\e[31mzkServer.sh status\e[0m\n"
echo -e "若要停止ZooKeeper集群运行,依次在虚拟机Hadoop1、Hadoop2和Hadoop3停止ZooKeeper服务: \e[31mzkServer.sh stop\e[0m"exit 0

3.2 添加可执行权限
在虚拟机hadoop1上给脚本文件/export/shell/hadoop1_hadoop_install_config.sh添加可执行权限。
chmod +x /export/shell/hadoop1_zookeeper_install_config.sh

3.3 执行脚本
在虚拟机hadoop1上执行脚本文件自动化安装配置zookeeper完全分布式。
/export/shell/hadoop1_zookeeper_install_config.sh
执行完成如下图所示。

4. 加载环境变量
根据使用shell脚本自动安装完成后的提示依次在虚拟机hadoop1、hadoop2和hadoop3执行如下命令加载环境变量。
source /etc/profile

5. 启动Zookeeper集群
在虚拟机hadoop1执行如下命令启动zookeeper。
zkServer.sh start
在虚拟机hadoop2执行如下命令启动zookeeper。
zkServer.sh start
在虚拟机hadoop3执行如下命令启动zookeeper。
zkServer.sh start
6. 查看Zookeeper集群状态
在虚拟机hadoop1执行如下命令查看Zookeeper集群状态是否正常。
zkServer.sh status
在虚拟机hadoop2执行如下命令查看Zookeeper集群状态是否正常。
zkServer.sh status
在虚拟机hadoop3执行如下命令查看Zookeeper集群状态是否正常。
zkServer.sh status
如果集群启动正常如上图所示,会有一个领导者leader,两个跟随者follower。
若要停止Zookeeper集群运行,依次在虚拟机hadoop1、hadoop2和hadoop3执行如下命令停止Zookeeper服务。
zkServer.sh stop