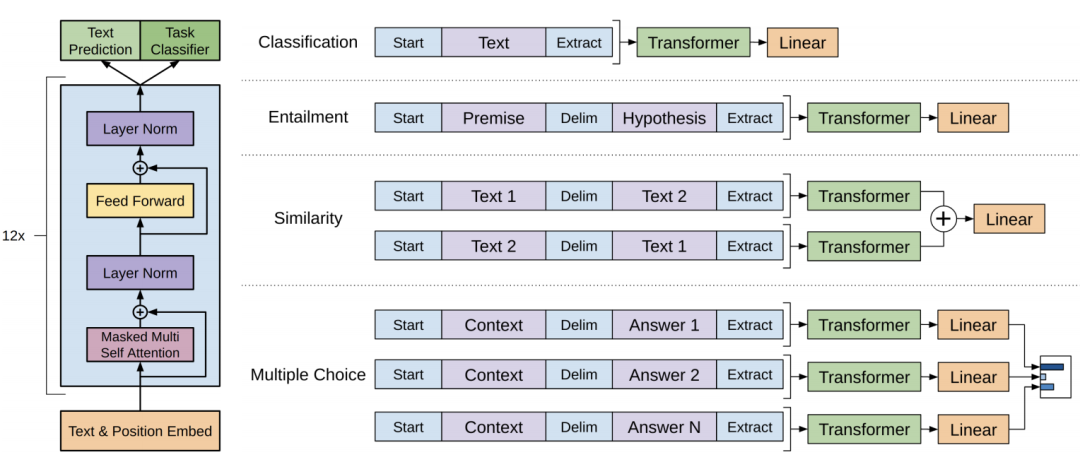
【深度学习遥感分割|论文解读4】UNetFormer:一种类UNet的Transformer,用于高效的遥感城市场景图像语义分割
【深度学习遥感分割|论文解读4】UNetFormer:一种类UNet的Transformer,用于高效的遥感城市场景图像语义分割
文章目录
- 【深度学习遥感分割|论文解读4】UNetFormer:一种类UNet的Transformer,用于高效的遥感城市场景图像语义分割
- 4. Experiments
- 4.1. Experimental settings
- 4.1.1. Datasets
- 4.1.2. Implementation details
- 4.1.3. Evaluation metrics
- 4.1.4. Models for comparison
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz
论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0924271622001654
4. Experiments
4.1. Experimental settings
4.1.1. Datasets
UAVid:UAVid数据集是一个高分辨率无人机语义分割数据集,聚焦于城市街景,具有两种空间分辨率(3840×2160 和 4096×2160),包含八个类别(Lyu et al., 2020)。由于图像的高空间分辨率、不均匀的空间变化、不清晰的类别界限及复杂的场景,使得UAVid的分割具有挑战性。具体而言,该数据集包含42个序列,共420张图像,其中200张用于训练,70张用于验证,150张用于官方测试。在实验中,每张图像被填充并裁剪成八个1024×1024像素的图块。

Vaihingen:Vaihingen数据集包含33幅高分辨率的TOP图像块,平均尺寸为2494×2064像素。每个TOP图像块具有三个多光谱波段(近红外、红、绿)以及数字表面模型(DSM)和归一化数字表面模型(NDSM),地面采样距离(GSD)为9 cm。数据集中包括五个前景类别(不透水表面、建筑物、低植被、树木、车辆)和一个背景类别(杂乱)。在实验中,仅使用TOP图像块,不包含DSM和NDSM。用于测试的图像为ID:2, 4, 6, 8, 10, 12, 14, 16, 20, 22, 24, 27, 29, 31, 33, 35, 38,验证集为ID:30,其余15张图像用于训练。图像块被裁剪为1024×1024像素的图块。

Potsdam:Potsdam数据集包含38幅超高分辨率的TOP图像块(GSD为5 cm),每幅图像尺寸为6000×6000像素,与Vaihingen数据集具有相同的类别信息。数据集提供了四个多光谱波段(红、绿、蓝、近红外)以及DSM和NDSM。用于测试的图像ID为:2_13, 2_14, 3_13, 3_14, 4_13, 4_14, 4_15, 5_13, 5_14, 5_15, 6_13, 6_14, 6_15, 7_13,验证集为ID:2_10,其余22张图像(不含存在标注错误的图像7_10)用于训练。实验中仅使用红、绿、蓝三个波段,并将原始图像块裁剪为1024×1024像素的图块。
LoveDA:LoveDA数据集包含5987张高分辨率的光学遥感图像(GSD为0.3 m),每张图像尺寸为1024×1024像素,涵盖7个地物类别:建筑物、道路、水体、荒地、森林、农业和背景(Wang et al., 2021a)。具体而言,2522张图像用于训练,1669张图像用于验证,1796张图像作为官方测试集。该数据集包含两类场景(城市和乡村),采集自中国的南京、常州和武汉三座城市。由于多尺度目标、复杂背景和类别分布不一致,数据集带来了显著的挑战。
4.1.2. Implementation details
所有实验中的模型均在单个NVIDIA GTX 3090 GPU上使用PyTorch框架实现。为了快速收敛,我们采用了AdamW优化器进行模型训练,基础学习率设置为6e-4,并使用余弦调度策略调整学习率。
对于UAVid数据集,在训练阶段,对输入图像(大小为1024×1024)进行了随机垂直翻转、随机水平翻转和随机亮度增强的数据扩增。训练周期设置为40,批量大小为8。在测试过程中,使用了测试时增强(TTA)策略,如垂直翻转和水平翻转。
对于Vaihingen、Potsdam和LoveDA数据集,图像随机裁剪为512×512像素的图块。在训练过程中,采用了随机缩放([0.5, 0.75, 1.0, 1.25, 1.5])、随机垂直翻转、随机水平翻转和随机旋转等增强技术,训练周期设置为100,批量大小为16。在测试阶段,使用了多尺度和随机翻转的数据增强策略。
4.1.3. Evaluation metrics
我们实验中使用了两类评估指标。第一类用于评估网络精度,包括总体精度(OA)、平均F1分数(F1)和平均交并比(mIoU)。第二类用于评估网络规模,包括浮点运算次数(FLOPs)以衡量复杂度、帧率(FPS)以评估速度、内存占用(MB)和模型参数数量(M)以衡量内存需求。
4.1.4. Models for comparison
我们选择了一组全面的基准方法进行量化对比,包括:
(i) 基于CNN的轻量级网络,用于高效语义分割:上下文聚合网络(CANet)(Yang等, 2021a)、双向分割网络(BiSeNet)(Yu等, 2018)、ShelfNet (Zhuang等, 2019)、SwiftNet (Oršić和Šegvić, 2021)、Fast-SCNN (Poudel等, 2019)、DABNet (Li等, 2019)、ERFNet (Romera等, 2017)和ABCNet (Li等, 2021c)。
(ii) 基于CNN的注意力网络:双重注意力网络(DANet)(Fu等, 2019)、快速注意力网络(FANet)(Hu等, 2020)、局部注意力网络(LANet)(Ding等, 2021)、交叉网络(CCNet)(Huang等, 2020)、多阶段注意残差UNet(MAResU-Net)(Li等, 2021a)和多注意力网络(MANet)(Li等, 2021b)。
(iii) 基于CNN的遥感影像语义分割网络:DST_5 (Sherrah, 2016)、V-FuseNet (Audebert等, 2018)、CASIA2 (Liu等, 2018)、DLR_9 (Marmanis等, 2018)、RoteEqNet (Marcos等, 2018)、UFMG_4 (Nogueira等, 2019)、HUSTW5 (Sun等, 2019)、TreeUNet (Yue等, 2019)、ResUNet-a (Diakogiannis等, 2020)、S-RA-FCN (Mou等, 2020)、DDCM-Net (Liu等, 2020)、EaNet (Zheng等, 2020a)、HMANet (Niu等, 2021)和AFNet (Yang等, 2021b)。
(iv) 混合Transformer网络,包含Transformer编码器和CNN解码器:TransUNet (Chen等, 2021b)、SwinUperNet (Liu等, 2021)、DC-Swin (Wang等, 2022)、STranFuse (Gao等, 2021)、SwinB-CNN + BD (Zhang等, 2022)、SwinTF-FPN (Panboonyuen等, 2021)、BANet (Wang等, 2021b)、CoaT (Xu等, 2021)、BoTNet (Srinivas等, 2021)和ResT (Zhang和Yang, 2021)。
(v) 完全基于Transformer的网络,包含Transformer编码器和Transformer解码器:SwinUNet (Cao等, 2021)、SegFormer (Xie等, 2021)和Segmenter (Strudel等, 2021)。
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz




![[含文档+PPT+源码等]精品基于PHP实现的会员综合管理平台的设计与实现](https://img-blog.csdnimg.cn/img_convert/a687a2a02044ab8f3cdf26a968d823de.png)