从输入 URL 到页面展示到底发生了什么?(非常重要)
类似的问题:打开一个网页,整个过程会使用哪些协议?
先来看一张图(来源于《图解 HTTP》):
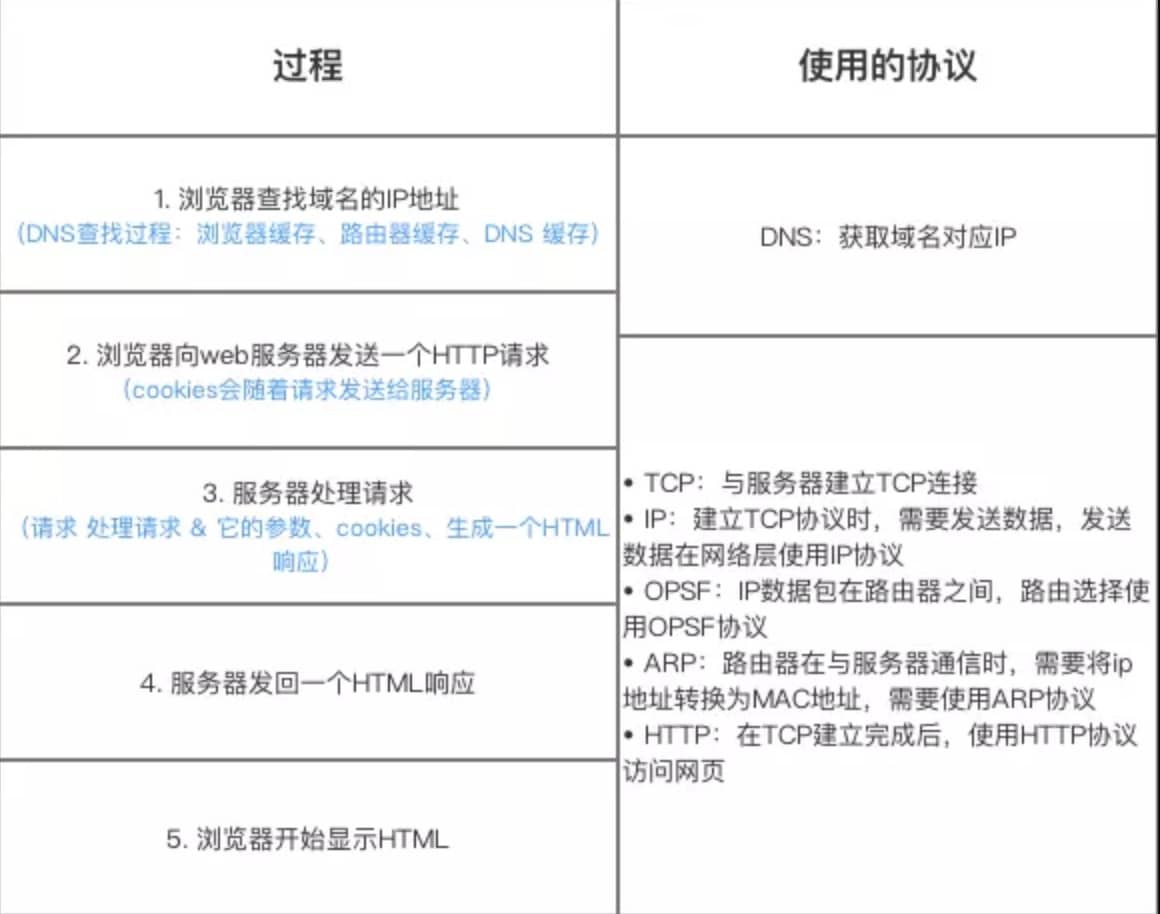
上图有一个错误需要注意:是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
总体来说分为以下几个步骤:
- 在浏览器中输入指定网页的 URL。
- 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
- 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
- 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
- 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
- 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
- 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
详细介绍可以查看这篇文章:访问网页的全过程(知识串联)(强烈推荐)。
HTTP 状态码有哪些?
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
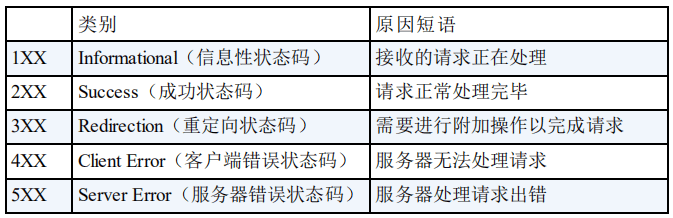
常见 HTTP 状态码
关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:HTTP 常见状态码总结(应用层)。
HTTP 状态码有哪些?
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
HTTP 和 HTTPS 有什么区别?(重要)

HTTP 和 HTTPS 对比
- 端口号:HTTP 默认是 80,HTTPS 默认是 443。
- URL 前缀:HTTP 的 URL 前缀是
http://,HTTPS 的 URL 前缀是https://。 - 安全性和资源消耗:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
- SEO(搜索引擎优化):搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
-
HTTP/1.1 和 HTTP/2.0 有什么区别?
HTTP/1.0 和 HTTP/1.1 对比
- 多路复用(Multiplexing):HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
- 二进制帧(Binary Frames):HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
- 头部压缩(Header Compression):HTTP/1.1 支持
Body压缩,Header不支持压缩。HTTP/2.0 支持对Header压缩,使用了专门为Header压缩而设计的 HPACK 算法,减少了网络开销。 - 服务器推送(Server Push):HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
HTTP 是不保存状态的协议, 如何保存用户状态?
HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们如何保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库 redis 保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
Cookie 被禁用怎么办?
最常用的就是利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
URI 和 URL 的区别是什么?
- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
- URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
GET 和 POST 的区别
GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
- 语义(主要区别):GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
- 幂等:GET 请求是幂等的,即多次重复执行不会改变资源的状态,而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
- 格式:GET 请求的参数通常放在 URL 中,形成查询字符串(querystring),而 POST 请求的参数通常放在请求体(body)中,可以有多种编码格式,如 application/x-www-form-urlencoded、multipart/form-data、application/json 等。GET 请求的 URL 长度受到浏览器和服务器的限制,而 POST 请求的 body 大小则没有明确的限制。不过,实际上 GET 请求也可以用 body 传输数据,只是并不推荐这样做,因为这样可能会导致一些兼容性或者语义上的问题。
- 缓存:由于 GET 请求是幂等的,它可以被浏览器或其他中间节点(如代理、网关)缓存起来,以提高性能和效率。而 POST 请求则不适合被缓存,因为它可能有副作用,每次执行可能需要实时的响应。
- 安全性:GET 请求和 POST 请求如果使用 HTTP 协议的话,那都不安全,因为 HTTP 协议本身是明文传输的,必须使用 HTTPS 协议来加密传输数据。另外,GET 请求相比 POST 请求更容易泄露敏感数据,因为 GET 请求的参数通常放在 URL 中。
再次提示,重点搞清两者在语义上的区别即可,实际使用过程中,也是通过语义来区分使用 GET 还是 POST。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。


![YOLOv11融合[ECCV2024]自调制特征聚合SMFA模块及相关改进思路|YOLO改进最简教程](https://i-blog.csdnimg.cn/direct/7ef3a055670844588e06284729373cf5.png)