随着流行的深度学习框架的出现,如 TensorFlow、Keras、PyTorch 以及其他类似库,学习神经网络对于新手来说变得更加便捷。虽然这些框架可以让你在几分钟内解决最复杂的计算任务,但它们并不要求你理解背后所有需求的核心概念和直觉。如果你知道特定函数如何工作,并且能在代码块中准确地使用它,就可以轻松地解决大多数问题。然而,要真正理解神经网络的概念以及完整的工作流程,从零开始学习人工神经网络的工作原理是至关重要的。这些神经网络是如何解决复杂问题的呢?
对于任何对人工智能和深度学习感兴趣的人,理解神经网络的原理以及构建过程都是一项有价值的探索。尽管我们暂时不使用深度学习框架如 TensorFlow、Keras 或 PyTorch,但我们将利用 NumPy 等库来进行数值矩阵计算。通过 NumPy 数组,我们可以进行模拟深度学习效果的复杂计算,并借此理解神经网络的编程流程。借助从头开始构建的这些神经网络,我们将实现一些简单的神经网络解决方案。
准备工作
为了跟进本文,你需要具备一些 Python 编程经验,并对深度学习有初步了解。我们假设所有读者都能访问足够强大的设备以运行提供的代码。
如果你还没有合适的 GPU,建议使用GPU云服务。因为这是最快、相对低成本获得 GPU,且可以简单灵活完成配置的方式。Digital Ocean 的 GPU Droplets 提供 H100 实例,近期限时优惠仅需 2.5刀/小时,点击这里了解 GPU Droplets 更多信息。
关于如何开始使用 Python 代码,我们建议你尝试这个初学者指南,以设置你的系统并准备运行初学者教程。
先了解一些概念
神经网络是深度学习和人工智能未来中最引人入胜的话题之一。虽然“人工神经网络”一词只是受到生物神经元概念的启发,但在构建这些网络时有一些明显的相似之处值得注意。就像人类神经元一样,使用人工神经网络的有趣的地方在于,我们通常可以确定它们在做什么,但很难确切知道它们是如何工作并实现目标的。尽管我们可以回答一些“xx是什么”的问题,但要完全理解模型的行为仍需进一步探索。这就是“黑盒”深度学习的来源,这个称呼适用于许多深度学习系统。不过,有许多神经网络是可解释的,使我们能够轻松地解释其目的和方法,这也取决于具体的用例。
人工智能是一个涉猎广泛的领域,而深度学习和神经网络只是其中的两个子域。在本文中,我们的主要目标是深入理解神经网络的概念,并展示如何在不使用一些知名和流行的深度学习框架的情况下从零开始构建一个架构。在深入学习如何从零实现神经网络之前,让我们直观地了解它们的工作原理。
理解神经元的概念
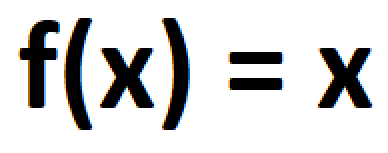
大多数数学运算可以通过函数连接。函数是神经网络学习几乎任何事物的最基本概念之一。无论函数具体实现什么,神经网络都可以被设计成近似该函数。这便是著名的普遍近似定理,它赋予神经网络处理各种不同挑战的能力,同时也带来了黑盒的特性。
许多现实世界的问题,如计算机视觉任务和自然语言处理任务,也可以表示为相互关联的函数。例如,通过函数,我们可以将几个输入单词映射到特定的输出单词,或将一组图像与各自的输出图像相连。数学和现实世界问题中的大多数概念都可以被重构为函数,从而框定问题并让神经网络找到适当的解决方案。
什么是人工神经网络?它是如何工作的?
人工神经网络通常被称为神经网络、神经网或 NNs。这些网络受到生物神经元的启发。需要再次强调的是,实际上,生物神经元与用于构建神经网络架构的“神经元”之间几乎没有直接关联。尽管两者的基本工作方式截然不同,但它们的共同点在于,结合在一起时,这些“神经元”可以相对容易地解决复杂任务。
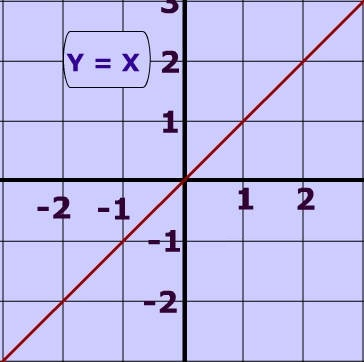
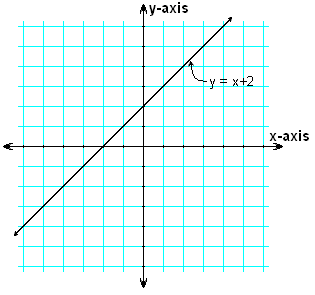
为了理解神经网络的基本工作原理,线性方程“y = mx + c”是帮助理解神经网络的关键数学概念之一。方程中的“y = mx”部分帮助操控线条,获得所需的形状和数值。而另一个值,截距“c”,则通过改变在 y 轴上的位置来调整线条的位置。请参见以下两张图,以更清楚地了解此基本概念。
在神经网络中,Y=WX+B可以用来表示这个方程,Y代表输出值,w代表需要调整的权重,x代表输入值,b代表值,通过使用这个简单的逻辑,神经网络可以使用已知的信息‘b’和‘w’来确定‘x’的值。
为了更好地理解权重和偏差这一特定概念,我们可以通过如下所示的简单代码片段和结果输出来进行探索。通过一些输入值、权重和偏差,我们可以使用输入值与权重转置值的点乘积来计算输出。在得到的结果值上,再添加相应的偏差来得到所需的值。下面的示例相对简单,但足以建立基本理解。不过,在下一节和即将发布的文章中,我们将介绍更复杂的概念。
import numpy as np
inputs = [1, 2, 3, 2.5]
weights = [[ 0.2, 0.8, - 0.5, 1 ],[ 0.5, - 0.91, 0.26, - 0.5 ],[ - 0.26, - 0.27, 0.17, 0.87 ]]
biases = [2, 3, 0.5]
outputs = np.dot(weights, inputs) + biasesOr Use this methodnp.dot(inputs, weights.T) + biasesprint (outputs)[4.8 1.21 2.385]当神经网络组合在一起时,它们能够在反向传播的帮助下通过训练过程进行学习。第一步是前向传播,即通过使用随机权重计算每一层直到输出单元所需的信息。然而,这些随机权重通常永远不会接近完美,需要调整权重才能获得更理想的结果。因此,神经网络中的反向传播是其功能中更重要的方面之一。反向传播是操纵和调整权重的地方,通常通过比较手头的输出和预期的输出。我们将在下一节和即将发表的文章中进一步探讨这些概念。
从零开始构建神经网络

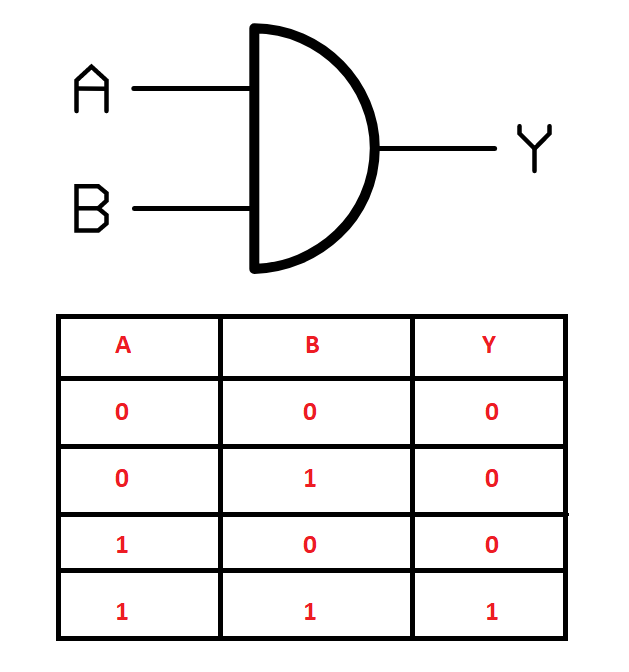
在本节中,我们将学习如何从零开始构建神经网络来解决一些任务。在开始构建神经网络之前,先了解我们要解决的问题类型。目标是构建能够理解和解决逻辑门功能的神经网络,例如 AND、OR、NOT、XOR 等逻辑门。对于这个特定示例,我们将研究如何通过从头构建神经网络来解决 XOR 门问题。
逻辑门是电子元件的基本构建块之一。选择这些逻辑门是因为每个门都基于特定的逻辑运行。例如,XOR 门仅在两个输入值不同时输出高电平;如果两个输入值相同,输出为低电平。这些逻辑通常通过真值表表示。上图展示了 XOR 门的符号和真值表表示。我们可以使用数组形式的输入和输出值来训练构建的神经网络,以获得理想结果。
首先,导入构建神经网络所需的库。在本节中,不使用任何深度学习框架,仅使用 NumPy 来简化复杂的张量和数学计算。即使没有 NumPy 库,你也可以选择手动构建神经网络,但这会耗费更多时间。本节唯一的其他库是 matplotlib,用于可视化损失并绘制模型在特定训练时期后的变化。
import numpy as np
import matplotlib.pyplot as plt让我们描述真值表的输入和 XOR 门的预期输出。读者可以选择使用不同的门并进行相应的实验(请注意,有时你可能无法获得所需的结果)。以下是 XOR 门的输入变量和预期结果的代码片段。
a = np.array([0, 0, 1, 1])
b = np.array([0, 1, 0, 1])# y_and = np.array([[0, 0, 0, 1]])
y_xor = np.array([[0,1,1,0]])让我们将输入组合成一个数组实体,这样我们就有了一个总输入数组和一个输出数组供神经网络学习。这个组合过程可以通过几种方式完成。在下面的代码块中,我们使用一个列表来组合两个数组,然后将最终列表转换回 numpy 数组格式。在下一节中,我还提到了另一种组合输入数据的方法。
total_input = []total_input = [a, b]total_input = np.array(total_input)得到的输入数组如下所示:
array([[0, 0, 1, 1],[0, 1, 0, 1]])对于大多数神经网络问题,数组的形状是最关键的概念。形状不匹配是解决此类任务时最有可能出现的错误。因此,让我们打印并分析输入数组的形状。
(2, 4)现在让我们定义一些从头开始构建神经网络所需的基本参数。节点的激活函数定义给定一个输入或一组输入时该节点的输出。我们将首先定义 S 型函数,这将是我们执行此任务的主要激活函数。然后,我们将继续定义一些基本参数,例如输入神经元、隐藏神经元、输出神经元的数量、总训练样本以及我们将训练神经网络的学习效率。
# Define the sigmoid activation function:
def sigmoid (x):return 1/(1 + np.exp(-x))# Define the number of neurons
input_neurons, hidden_neurons, output_neurons = 2, 2, 1# Total training examples
samples = total_input.shape[1]# Learning rate
lr = 0.1# Define random seed to replicate the outputs
np.random.seed(42)下一步,我们将初始化将通过隐藏层和输出层的权重,如下面的代码片段所示。随机化权重而不是为其分配零值通常是一个好主意,因为神经网络有时可能无法学习所需的结果。
# Initializing the weights for hidden and output layersw1 = np.random.rand(hidden_neurons, input_neurons)
w2 = np.random.rand(output_neurons, hidden_neurons)在下一个代码块中,我们将定义神经网络模型的工作结构。首先,我们将使函数通过神经网络结构执行前向传播。我们将首先计算隐藏层中的权重和输入值,然后将它们传递给我们的 S 型激活函数。然后,我们也将对输出层执行类似的传播,其中我们将利用我们之前定义的第二个权重。随机生成的权重显然无法达到预期的结果,需要进行微调。因此,我们还将实现反向传播机制,以帮助我们的模型更有效地训练。此操作的执行方式与我们在上一节中讨论的方式类似。
# Forward propagation
def forward_prop(w1, w2, x):z1 = np.dot(w1, x)a1 = sigmoid(z1)z2 = np.dot(w2, a1)a2 = sigmoid(z2)return z1, a1, z2, a2# Backward propagation
def back_prop(m, w1, w2, z1, a1, z2, a2, y):dz2 = a2-ydw2 = np.dot(dz2, a1.T)/mdz1 = np.dot(w2.T, dz2) * a1*(1-a1)dw1 = np.dot(dz1, total_input.T)/mdw1 = np.reshape(dw1, w1.shape)dw2 = np.reshape(dw2,w2.shape)return dz2,dw2,dz1,dw1现在我们已经定义了前向传播和后向传播机制,可以开始训练神经网络了。让我们进行一个训练循环,运行预定义的迭代次数。首先,我们利用前向传播来获取输出值,然后将其与预期输出进行比较,开始计算相应的损失。开始执行神经网络的反向传播后,我们就可以微调权重,以接近预期的最终结果。以下是训练过程的代码块,我们还确保损失不断减少,表明神经网络正在学习如何预测所需结果,并附带相应图表。
losses = []
iterations = 10000for i in range(iterations):z1, a1, z2, a2 = forward_prop(w1, w2, total_input)loss = -(1/samples)*np.sum(y_xor*np.log(a2)+(1-y_xor)*np.log(1-a2))losses.append(loss)da2, dw2, dz1, dw1 = back_prop(samples, w1, w2, z1, a1, z2, a2, y_xor)w2 = w2-lr*dw2w1 = w1-lr*dw1# We plot losses to see how our network is doing
plt.plot(losses)
plt.xlabel("EPOCHS")
plt.ylabel("Loss value")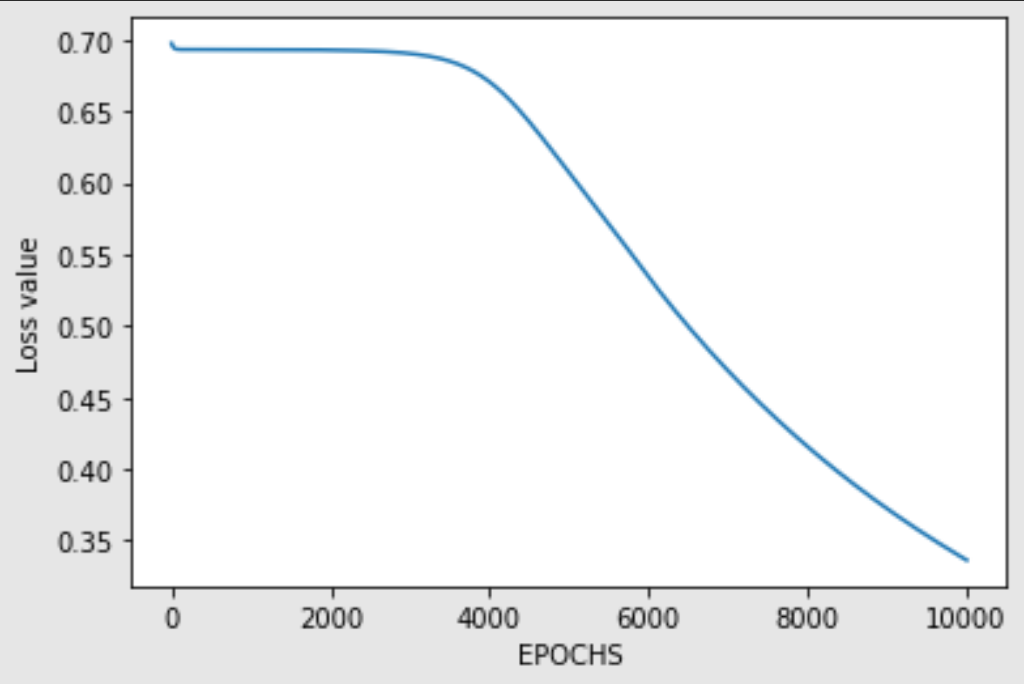
让我们定义预测函数,通过该函数我们可以利用经过训练的神经网络来计算一些预测。我们将执行前向传播并压缩获得的结果。由于我们在训练过程中对权重进行了微调,因此我们应该能够以 0.5 的阈值实现所需的结果。
# Creating the predict functiondef predict(w1,w2,input):z1, a1, z2, a2 = forward_prop(w1,w2,test)a2 = np.squeeze(a2)if a2>=0.5:print("For input", [i[0] for i in input], "output is 1")else:print("For input", [i[0] for i in input], "output is 0")现在我们已经完成了预测函数的定义,我们可以测试你构建的神经网络所做的预测,并在对模型进行约 10000 次迭代训练后查看其性能。我们将测试四种可能情况中的每一种预测结果,并将它们与 XOR 门的预期结果进行比较。
test = np.array([[0],[0]])
predict(w1,w2,test)
test = np.array([[0],[1]])
predict(w1,w2,test)
test = np.array([[1],[0]])
predict(w1,w2,test)
test = np.array([[1],[1]])
predict(w1,w2,test)For input [0, 0] output is 0
For input [0, 1] output is 1
For input [1, 0] output is 1
For input [1, 1] output is 0我们可以注意到,神经网络的预测结果与预期结果相似。因此可以得出结论,从零构建的神经网络成功地准确预测了 XOR 门任务。本节中的大部分代码参考了以下 GitHub 资源。如果你想要另一个学习资源,建议查看它。同时,鼓励读者通过从头构建神经网络来尝试解决不同类型的逻辑门,以探索它们的其他变体。
使用深度学习框架的构建进行比较
深度学习和人工神经网络的领域非常广阔。虽然可以从头开始构建神经网络来解决复杂的问题,但由于需要大量的时间以及需要构建的网络的固有复杂性,这通常是不可行的。因此,我们使用深度学习框架(如 TensorFlow、PyTorch、MXNet、Caffe 和其他类似的库(或工具))来设计、训练和验证神经网络模型。
这些深度学习框架允许开发人员和研究人员快速构建他们想要的模型来解决特定任务,而无需在复杂和不必要的细节的底层工作上投入太多。在众多可用的深度学习框架中,目前最流行的两种构建神经网络的工具是 TensorFlow 和 PyTorch。在本节中,我们将借助深度学习框架重建我们在前面几节中构建的项目。
对于这个重建项目,我将使用 TensorFlow 和 Keras 库。以下是我们用于构建神经网络以解决与门和异或门的导入列表。
import tensorflow as tf
from tensorflow import keras
import numpy as np导入必要的库后,我们可以定义一些必需的参数,我们将利用这些参数构建神经网络来学习与门的输出。与与门类似,我们也将像上一节中那样构建异或门。首先,让我们看看与门的构造。下面是与门的输入和预期结果。与门的逻辑是,只有当两个(或所有)输入都为高时,输出才为高。否则,当任一输入为低时,输出也为低。
a = np.array([0, 0, 1, 1])
b = np.array([0, 1, 0, 1])y_and = np.array([0, 0, 0, 1])我们声明了输入和预期输出,就该将两个输入数组组合成一个实体了。我们可以通过几种方法来实现这一点,如上一节所述。对于此代码片段,我们将它们附加到一个包含四个单独元素的列表中,每个列表都有两个元素。组合输入元素后获得的最终数组将存储在一个新数组中。
total_input = []for i, j in zip(a, b):input1 = []input1.append(i)input1.append(j)total_input.append(input1)
total_input = np.array(total_input)两个初始输入列表组合后得到的输入数组如下所示。
array([[0, 0],[0, 1],[1, 0],[1, 1]])这个最终输入数组的形状如下。
(4, 2)下一步,我们将创建训练数据及其各自的输出标签。首先,我们将创建列表来存储输入和输出的训练数据。我们完成这些元素的循环后,我们就可以将这些列表保存为数组,并使用它们进行进一步的计算和神经网络训练。
x_train = []
y_train = []for i, j in zip(total_input, y_and):x_train.append(i)y_train.append(j)
x_train = np.array(x_train)
y_train = np.array(y_train)此类任务的训练过程非常简单。我们可以定义所需的库,即输入层、隐藏层和输出节点的密集层,最后是顺序模型,以便我们可以构建顺序类型模型来解决所需的 AND 门任务。首先,我们将定义模型的类型,然后继续添加输入层,它将按照我们之前的定义接受输入。我们有两个隐藏层,每个隐藏层有十个节点,并带有 ReLU 激活函数。最终的输出层包含一个节点的 Sigmoid 激活函数,为我们提供所需的结果。根据提供的输入,最终输出为零或一。
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(Input(shape = x_train[0].shape))
model.add(Dense(10, activation = "relu"))
model.add(Dense(10, activation = "relu"))
model.add(Dense(1, activation = "sigmoid"))
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 30
_________________________________________________________________
dense_1 (Dense) (None, 10) 110
_________________________________________________________________
dense_2 (Dense) (None, 1) 11
=================================================================
Total params: 151
Trainable params: 151
Non-trainable params: 0
_________________________________________________________________上表显示了包含隐藏层和输出节点及其各自参数的顺序类型网络的摘要。现在我们已经构建了模型架构来解决所需的 AND 门任务,我们可以继续编译模型并对其进行相应的训练。我们将利用 Adam 优化器、二元交叉熵损失函数,并计算二元准确度来验证我们的模型有多准确。
model.compile(optimizer = "adam", loss = "binary_crossentropy", metrics = "binary_accuracy")模型编译完成,让我们开始训练过程,看看模型是否能够达到预期的结果。请注意,从头开始的神经网络的损失函数和优化器等内容尚未涵盖。我们将在未来的文章中介绍这些概念。下面是训练所需模型的代码片段。
model.fit(x_train, y_train, epochs = 500)我们将对模型进行大约 500 个时期的训练,以确保它能够按预期学习要求。由于这些门控任务的数据较少,因此模型将需要更多的训练来学习并相应地优化结果。训练完成后(大约需要几分钟),我们可以继续使用预测函数来验证获得的结果。让我们对数据集执行预测,如下面的代码片段所示。
model.predict(x_train)array([[0.00790971],[0.02351646],[0.00969902],[0.93897456]], dtype=float32)我们可以注意到,AND 门的结果与预期的差不多。对于必须为零的输出值,预测得到的结果能够预测接近零的值,而对于必须为 1 的输出值,我们得到的结果接近 1。我们还可以对这些值进行四舍五入以获得所需的结果。除了我们刚刚完成的 AND 门之外,让我们探索另一个门。
同样,对于 XOR 门,我们也可以继续遵循与 AND 门类似的工作流程。首先,我们将定义 XOR 门所需的输入。它再次是一个 2 通道输入,利用变量 a 和 b 存储输入值。y 变量将把预期的结果值存储在 NumPy 数组中。我们将以类似于本节中使用的方法组合这两个输入数组。输入组合起来,我们得到了所需的组合,我们将数据分为训练输入信息及其结果标签输出。
a = np.array([0, 0, 1, 1])
b = np.array([0, 1, 0, 1])y_xor = np.array([0, 1, 1, 0])total_input = []for i, j in zip(a, b):input1 = []input1.append(i)input1.append(j)total_input.append(input1)total_input = np.array(total_input)x_train = []
y_train = []for i, j in zip(total_input, y_xor):x_train.append(i)y_train.append(j)x_train = np.array(x_train)
y_train = np.array(y_train)我们将使用与本文本节前面类似的顺序类型架构。代码片段和模型的最终摘要如下所示:
model1 = Sequential()
model1.add(Input(shape = x_train[0].shape))
model1.add(Dense(10, activation = "relu"))
model1.add(Dense(10, activation = "relu"))
model1.add(Dense(1, activation = "sigmoid"))model1.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 10) 30
_________________________________________________________________
dense_4 (Dense) (None, 10) 110
_________________________________________________________________
dense_5 (Dense) (None, 1) 11
=================================================================
Total params: 151
Trainable params: 151
Non-trainable params: 0
_________________________________________________________________我们将定义优化器和损失函数等参数来编译模型,然后拟合模型。对于训练过程,我们将使用第二个模型和新的训练数据输入和输出进行训练。我们将对我们的模型进行一千次训练,然后获得最佳预测。由于要训练的数据样本相对较少,因此训练只需几分钟。
model1.compile(optimizer = "adam", loss = "binary_crossentropy", metrics = "binary_accuracy")model1.fit(x_train, y_train, epochs = 1000)让我们对训练输入数据进行预测,并查看训练过程完成后模型能够预测的输出。
model1.predict(x_train)array([[0.01542357],[0.995468 ],[0.99343044],[0.00554709]], dtype=float32)我们可以注意到,输出值与相应的预期结果非常准确。当预期结果为零时,值更接近零,当预期结果为一时,值更接近一。最后,让我们分别对 AND 门和 XOR 门模型的两个预测值进行四舍五入。执行此步骤将帮助我们获得预期输出所需的单个整数值。
model.predict(x_train).round()
model1.predict(x_train).round()array([[0.],[0.],[0.],[1.]], dtype=float32)array([[0.],[1.],[1.],[0.]], dtype=float32)我们可以注意到,经过训练的两个模型都能够利用提供的输入生成理想的输出。即使我们的数据量较少,经过长时间的训练,该模型也能够在减少损失的情况下实现预期结果。从头开始学习神经网络所有基本知识的工作原理是相当漫长的。优化器、损失函数、各种损失函数和其他类似主题等复杂概念将在未来的关于从头构建神经网络的文章中介绍。
结论
在本文中,我们展示了从头构建神经网络的大部分基本概念。在简要介绍之后,我们探讨了理解人工神经网络工作原理所需的一些关键要素。掌握了基本概念后,我们开始使用 NumPy 从头构建神经网络,并尝试了一个可以解决 XOR 门问题的 ANN。最后,我们还学习了如何使用深度学习框架(如 TensorFlow 和 Keras)构建 AND 和 XOR 等逻辑门的解决方案。
人工神经网络 (ANN) 和深度学习带来了一场革命,使机器能够完成一些曾经被认为不可能的复杂任务。成功的人工智能和神经网络之旅从简单的感知器模型开始,逐步迈向带有 n 个隐藏层的复杂架构。随着 GPU 的普及和经济实惠的计算资源的普及,任何有兴趣学习如何创建此类模型和框架的人都可以更容易地开始。神经网络的复杂性和概念繁多,尤其是当我们尝试从零开始构建这些网络时,就像我们在本文中所做的那样。在未来的部分中,我们将进一步探索从头构建神经网络的更多基础。
当然如果你还没找到合适的 GPU,但是有希望训练大模型,欢迎尝试 Digitalocean 的
在接下来的文章中,我们将研究更多生成对抗网络的变体,例如 pix-2-pix GAN、BERT Transformer,当然还有从头构建神经网络的第二部分。在此之前,继续探索和学习新知识吧!