我们每天都会接触到大量的网页内容。然而,如何从这些内容中快速提取关键信息,并有效地进行整理和分享,一直是困扰我们的问题。本文将介绍一款我近期完成的基于AI技术的智能网页内容截图工具,它能够自动分析网页内容,截取重要区域,为用户提供便捷的内容提取与可视化服务。
一、项目背景与价值
在撰写文章或进行学术研究时,我们常常需要从网页中提取关键信息。然而,许多网页内容丰富,需要截图的内容较多,手动截图不仅费时费力,还容易遗漏重要信息。为了解决这一问题,我们开发了一款智能网页内容截图工具,通过AI技术自动分析网页内容,并截取重要区域,提高内容提取的效率和准确性。

二、技术实现
-
技术选型
本项目采用Python编程语言,结合Streamlit、Playwright、Pillow等库实现。Streamlit用于构建交互式Web应用,Playwright用于网页自动化操作,Pillow用于图像处理。
-
核心逻辑
(1)数据预处理:从用户输入的URL获取网页内容,并进行初步处理,如去除HTML标签、提取文本等。
(2)核心业务逻辑:使用AI技术分析网页内容,识别关键区域,并生成JSON格式的区域列表。
(3)结果处理:根据区域列表,使用Playwright截取对应区域的截图,并展示给用户。
-
关键设计决策
(1)使用Playwright进行网页自动化操作,实现快速、稳定的内容提取。
(2)结合Pillow库进行图像处理,确保截图质量。
(3)采用Streamlit构建交互式Web应用,提高用户体验。
三、核心逻辑说明:
class AnalyzeWebPage(Action):
"""分析网页内容的动作"""
PROMPT_TEMPLATE: ClassVar[str] = """分析以下HTML内容,识别包含关键商业和产品信息的区域。将较长的内容区域分成多个独立的小区块。
重点关注以下内容(每个区域建议不超过一屏幕高度):
1. 产品标题区域:
- 产品名称和简短标语
- 一句话价值主张
2. 核心特性区域:
- 识别所有产品功能或特点
- 每个技术优势说明
- 所有应用场景
3. 产品亮点:
- 所有产品优势点
- 所有核心功能说明
- 所有用户价值点
请严格按照以下JSON格式返回结果,不要包含任何其他说明文字:
[
{{
"description": "产品名称和简短标语",
"selector": "h1.product-title"
}},
{{
"description": "AI自动操作特性介绍",
"selector": "div.feature-block:nth-child(1)"
}}
]
注意:
- 必须返回JSON数组格式
- 每个区域必须包含 description 和 selector 两个字段
- 不要返回任何其他格式的内容
- 不要包含任何解释或说明文字
HTML内容:
{html_content}
"""
REVIEW_PROMPT: ClassVar[str] = """作为网页内容分析专家,请仔细审查以下已识别的内容区域,并检查是否有遗漏或不准确的地方。
当前已识别的区域:
{areas}
原始HTML内容:
{html_content}
请重点检查:
1. 产品核心信息是否完整(标题、简介、价格等)
2. 产品特性和功能说明是否完整
3. 技术规格和参数是否完整
4. 使用场景和用户价值是否完整
5. 产品优势和亮点是否完整
如果发现遗漏,请严格按照以下JSON格式返回完整的区域列表:
[
{{
"description": "区域描述",
"selector": "CSS选择器"
}}
]
如果当前区域划分已经完整,直接返回"PASS"。
注意:
- 必须返回JSON数组或"PASS"
- 不要返回任何其他格式的内容
- 不要包含任何解释或说明文字
"""
name: str = "AnalyzeWebPage"
async def run(self, html_content: str) -> list:
"""实现网页分析逻辑"""
try:
# 使用模板分析页面内容
prompt = self.PROMPT_TEMPLATE.format(html_content=html_content)
logger.debug(f"发送给AI的提示: {prompt[:200]}...")
try:
# 添加明确的格式要求
response = await self._aask(prompt + "\n请严格按照JSON数组格式返回结果,不要包含任何其他内容。")
logger.debug(f"AI的原始响应: {response}")
except Exception as e:
logger.error(f"调用AI接口失败: {str(e)}")
return self.get_default_areas()
# 尝试从响应中提取JSON部分
areas = None
try:
# 尝试直接解析
if response and response.strip().startswith("["):
areas = json.loads(response.strip())
# 尝试从代码块中提取
elif response and "```" in response:
code_blocks = response.split("```")
for block in code_blocks:
block = block.strip()
if block.startswith("json"):
block = block[4:].strip()
try:
parsed = json.loads(block)
if isinstance(parsed, list):
areas = parsed
break
except:
continue
if not areas:
logger.warning("无法从响应中提取有效的JSON,使用默认区域")
return self.get_default_areas()
except json.JSONDecodeError as e:
logger.error(f"JSON解析错误: {str(e)}")
logger.error(f"尝试解析的文本: {response}")
return self.get_default_areas()
except Exception as e:
logger.error(f"解析过程中的其他错误: {str(e)}")
logger.error(f"错误类型: {type(e)}")
logger.error(f"出错时的响应内容: {response}")
return self.get_default_areas()
# 确保areas不为None后再进行审查
try:
logger.info("开始审查区域完整性...")
reviewed_areas = await self.review_areas(html_content, areas)
logger.info(f"审查完成,最终区域数量: {len(reviewed_areas)}")
return reviewed_areas
except Exception as e:
logger.error(f"区域审查失败: {str(e)}")
return areas # 如果审查失败,返回原始区域
except Exception as e:
logger.exception(f"分析页面失败: {str(e)}")
# 如果前面的步骤都失败了,返回默认区域
logger.warning("使用默认区域")
return self.get_default_areas()
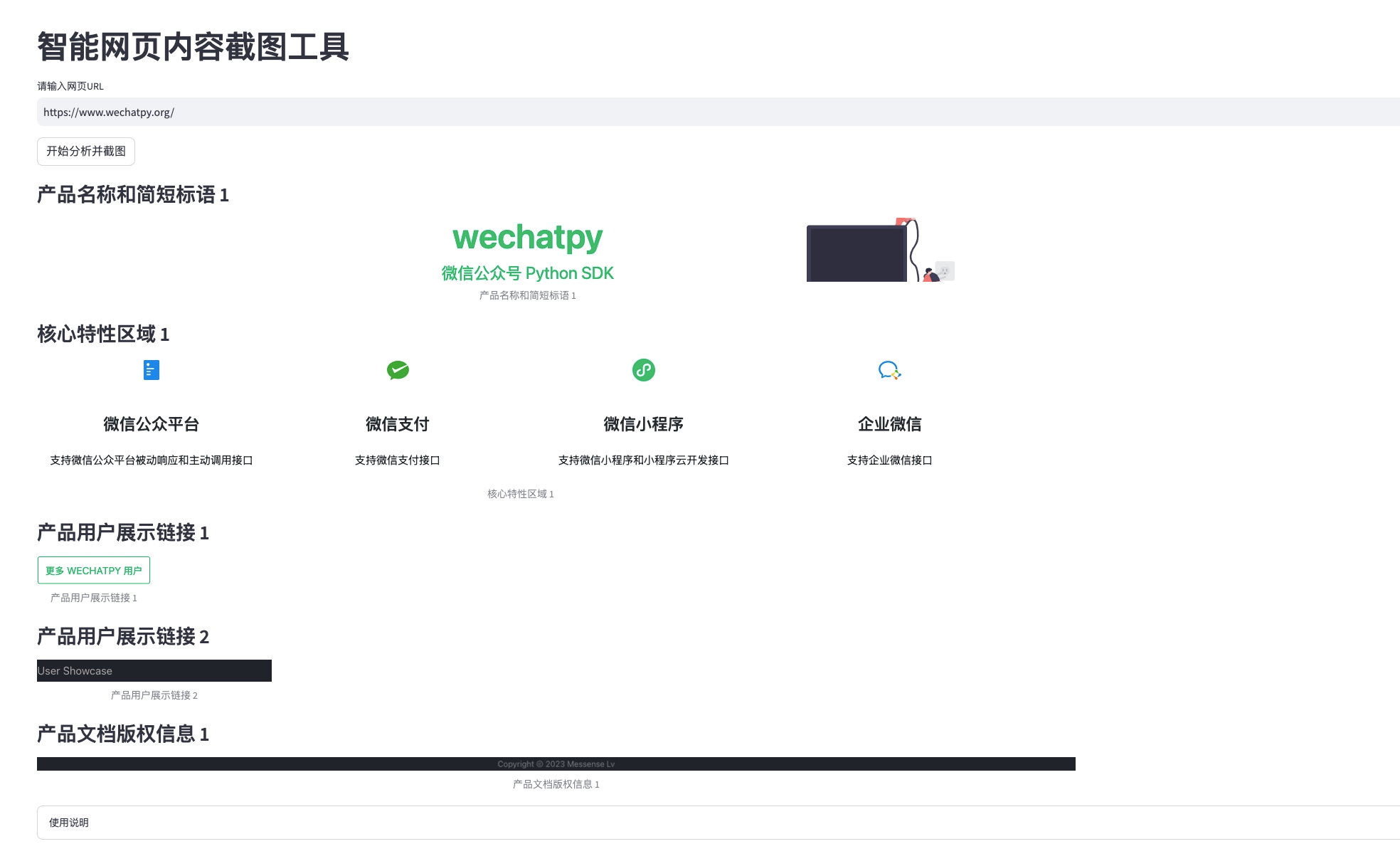
这是最主要的代码部分,用来分析网页内容,该智能体会根据playwright抓取到的网页源码,分析其中的内容部分,做一遍阅读理解,找到内容的重点,然后,选出内容重点所在页面元素的所在父级元素,调用相应的类库,把它渲染成图片,并保存下来。
我还加了一个“审阅选取的区域是否合理完整”的智能体,以及用来截图的工具类。
最后,通过streamlit把结果展示出来,这样,我可以通过预览来决定,那些截图是我想要,我直接用就可以了。
这款工具不仅能够提高内容提取的效率和准确性,还能为用户提供便捷的内容可视化服务。奇奇怪怪的小工具又增加了!但话不多说,你说它是不是也挺使用的啊?
本文由 mdnice 多平台发布