TensorFlow Profiler in practice: Optimizing TensorFlow models on AMD GPUs — ROCm Blogs

简介
TensorFlow Profiler 是一组旨在衡量 TensorFlow 模型执行期间资源利用率和性能的工具。它提供了关于模型如何与硬件资源交互的深入见解,包括执行时间和内存使用情况。TensorFlow Profiler 有助于定位性能瓶颈,使我们能够微调模型的执行,以提高效率并加快结果,这在需要接近实时预测的场景中尤为重要。
机器学习算法,特别是深度神经网络,具有很高的计算需求。评估机器学习应用程序的性能,以确保执行的是经过最优化的模型版本,这一点至关重要。这篇博客演示了如何在 AMD 硬件上使用 TensorFlow Profiler 工具,通过训练自编码器模型、收集设备跟踪数据、并根据分析结果修改自编码器的结构来优化模型性能。有关 TensorFlow Profiler 的更多信息,请参见 使用 Profiler 优化 TensorFlow。
在 GitHub 文件夹 中可以找到与本篇博客相关的资源。
前提条件
以下是跟随本博客所需的要求和说明:
操作系统和硬件
以下描述了支持的操作系统和硬件环境,推荐用于运行本博客文章中的示例。
-
AMD 加速器或 GPU:请参阅 ROCm 文档中有关支持的操作系统和硬件的列表,网址为 系统要求(Linux)。
-
ROCm 6.0: 请参阅 ROCm 安装说明。
-
Docker: 使用 适用于 Ubuntu 的 Docker 引擎。
-
TensorFlow 和 TensorBoard:使用官方的 ROCm Docker 镜像 rocm/tensorflow:rocm6.0-tf2.12-runtime,支持 TensorFlow 2.12。
运行此博客
使用 Docker 是搭建所需环境的最简单和最可靠的方法。
-
确保已安装 Docker。如果没有,请参阅 安装说明。
-
确保在主机上已安装
amdgpu-dkms(随 ROCm 一起提供),以便从 Docker 内部访问 GPU。有关详细信息,请参阅 ROCm Docker 说明。 -
克隆库,并进入博客目录:
git clone https://github.com/ROCm/rocm-blogs.git cd rocm-blogs/blogs/software-tools-optimization/tf_profiler
-
构建并启动容器。有关构建过程的详细信息,请参阅
dockerfile。这将启动一个 Jupyter Lab 服务器。cd docker docker compose build docker compose up
-
在浏览器中导航到 http://localhost:8888/lab/tree/src/tf_profiler_ae_example.ipynb 并打开
tf_profiler_ae_example.ipynb笔记本。
现在,请使用 Jupyter 笔记本来跟随此博客进行学习。
使用 TensorFlow Profiler 记录分析数据
在接下来的部分中,我们将设计并训练一个在 MNIST 数据集上的简单自编码器模型,同时使用 TensorFlow Profiler 收集分析数据。通过在 TensorBoard 中分析这些分析数据,我们将识别性能瓶颈,并做出明智的决策,以优化模型在 AMD 加速器上的性能。
设计一个简单的自动编码器
自动编码器是一种用于无监督学习的神经网络,旨在学习输入数据的高效表示。自动编码器通常用于降维或特征学习等任务。它们包括两个主要部分:*编码器*,将输入压缩为潜在空间表示;*解码器*,从潜在表示中重构输入数据。目标是最小化原始输入与其重建之间的差异,从而使模型能够在没有监督的情况下学习数据的显着特征。
我们将使用 MNIST 数据集来训练这个自动编码器。`MNIST` 数据集是一个大量的手写数字数据集,常用于训练各种图像处理系统。`MNIST` 是 tensorflow_datasets 模块的一部分,并随 TensorFlow 一起安装。对于自动编码器,其目标是让它学习 MNIST 数据集中手写数字的紧凑表示。
为了展示 TensorFlow Profiler 的优势,让我们设计如下的自动编码器神经网络:
首先导入以下模块:
import os import tensorflow as tf import tensorflow_datasets as tfds from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D from tensorflow.keras.models import Model from tensorflow.keras.callbacks import TensorBoardfrom datetime import datetime
接下来,加载数据集并进行预处理操作:将每个图像规范化到 [0,1] 范围。
# 加载数据集def preprocess_image(features):image = tf.cast(features['image'], tf.float32) / 255.0image = tf.image.resize(image, [28,28])image = tf.expand_dims(image[:, :, 0], -1)return image, image # Returns input and output the same for the autoencoder# 创建 mnist 训练和测试拆分
ds_train = tfds.load('mnist', split='train', as_supervised=False)
ds_train = ds_train.map(preprocess_image, num_parallel_calls = tf.data.AUTOTUNE).batch(64)ds_test = tfds.load('mnist', split='test', as_supervised=False)
ds_test = ds_test.map(preprocess_image, num_parallel_calls = tf.data.AUTOTUNE).batch(64)
让我们定义以下自动编码器架构:
# 定义架构 input_img = Input(shape = (28,28,1))# 编码器部分 x = Conv2D(512,(3,3), activation = 'relu', padding = 'same')(input_img) x = MaxPooling2D((2,2), padding = 'same')(x) x = Conv2D(128, (3,3), activation = 'relu', padding = 'same')(x) encoded = MaxPooling2D((2,2), padding='same')(x)# 解码器部分 x = Conv2D(128,(3,3), activation = 'relu', padding = 'same')(encoded) x = UpSampling2D((2,2))(x) x = Conv2D(512,(3,3), activation = 'relu', padding = 'same')(x) x = UpSampling2D((2,2))(x) decoded = Conv2D(1,(3,3), activation='sigmoid', padding='same')(x)autoencoder = Model(input_img, decoded)
最后,设置 profiling 回调函数以在模型训练时收集 profiling 数据。
# 定义优化器和损失函数
autoencoder.compile(optimizer = 'adam', loss = 'binary_crossentropy')# 设置 profiling。将 profiling 日志存储在相应的文件夹中
tensorboard_callback = TensorBoard(log_dir = './logs/' + datetime.now().strftime("%Y%m%d-%H%M%S"),histogram_freq=1, profile_batch='500,520')# 训练模型10轮
autoencoder.fit(ds_train,epochs = 10,validation_data = ds_test,callbacks = [tensorboard_callback], # callback needed for use of tensorboard tools)# 复制文件 "events.out.tfevents.1583461681.localhost.profile-empty" 到每个记录的日志中以显示数据
source_path = "./events.out.tfevents.1583461681.localhost.profile-empty"
destination_path = log_dir
shutil.copy(source_path, destination_path)
注意:
在上面的代码中,shutil.copy被用来将文件events.out.tfevents.1583461681.localhost.profile-empty复制到对应训练运行的 logs 文件夹中。这是 TensorBoard 的一个限制;它需要手动放置此文件才能正确显示 profiling 数据,并使PROFILE菜单可用。
为了探索 TensorFlow Profiler 的使用和功能,我们特意将自动编码器的训练限制为 10 轮。让我们运行以下代码来可视化自动编码器的输出。
# 显示图像import matplotlib.pyplot as plt
import numpy as np
import tensorflow_datasets as tfds# 提取一个测试图像
for test_images, _ in ds_test.take(30): # get image with index 30test_image = test_images[0:1]reconstructed_image = autoencoder.predict(test_image)# 绘制原始图像
fig, axes = plt.subplots(1,2)
axes[0].imshow(test_image[0,:,:,0], cmap='gray')
axes[0].set_title('Original Image')
axes[0].axis('off')# 绘制重建图像
axes[1].imshow(reconstructed_image[0,:,:,0], cmap='gray')
axes[1].set_title('Reconstructed Image')
axes[1].axis('off')plt.show()
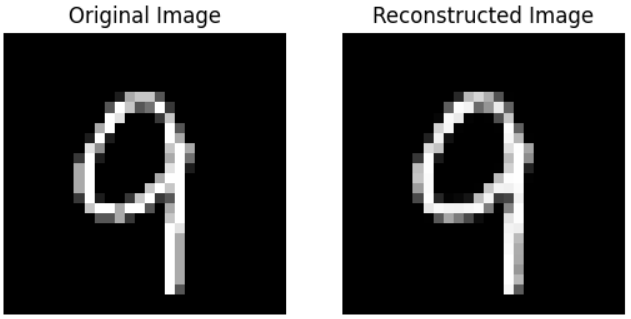
我们可以比较自动编码器的输入(原始图像)和它的输出(重建图像):
探索使用 TensorBoard 的 TensorFlow Profiler 数据
我们将使用 TensorBoard 来探索收集到的性能分析数据。TensorBoard 是一个用于机器学习实验的可视化工具。它可以帮助可视化训练指标和模型权重,使我们可以更深入地了解模型的训练过程。
TensorBoard 的一个有用特性是 TensorBoard 回调 API。这个功能可以集成到模型的训练循环中,自动记录诸如训练和验证指标之类的数据。TensorBoard 包括一个 Profile 选项,可以用于分析 TensorFlow 操作的时间和内存性能。这对于识别训练或推理过程中的瓶颈情况非常有用。启用性能分析设置 profile_batch 在 TensorBoard 回调中。
在我们的案例中,我们创建了一个 TensorBoard 回调实例 (tensorboard_callback = TensorBoard()) 并配置了以下参数:
-
log_dir: 对应于日志数据存储的位置。在这种情况下,文件夹还附加了当前时间戳:'./logs/' + datetime.now().strftime("%Y%m%d-%H%M%S") -
histogram_freq: 对应于记录日志的频率(以周期数表示)。值histogram_freq=1表示每个周期都记录数据。 -
profile_batch: 配置需要分析的批次。在这种情况下,我们定义`profile_batch='500,520'`。这将在批次 500 到批次 520 内分析操作。由于我们使用的批次大小为 64(`batch(64)`),并且训练集的大小为 60,000,
我们有60000 / 64 = 938批次,因此profile_batch='500,520'的范围在我们可分析的批次范围内。
让我们通过在 TensorBoard 上可视化分析结果来探索我们的 profiler 结果。
首先加载 Jupyter notebook 上的 TensorBoard 扩展:
%load_ext tensorboard
接下来,在 notebook 内启动 TensorBoard(可能需要几秒钟才能显示出来):
%tensorboard --logdir='./logs' --bind_all --port 6006
显示如下屏幕:
要可视化分析数据,请转到`PROFILE` 标签。在这里,我们会看到以下选项:
-
当前的
Run,对应选中的日志文件夹。 -
Tools部分,选择overview_page。 -
Hosts列表,显示当前执行 TensorFlow 代码时的 CPU 或主机。
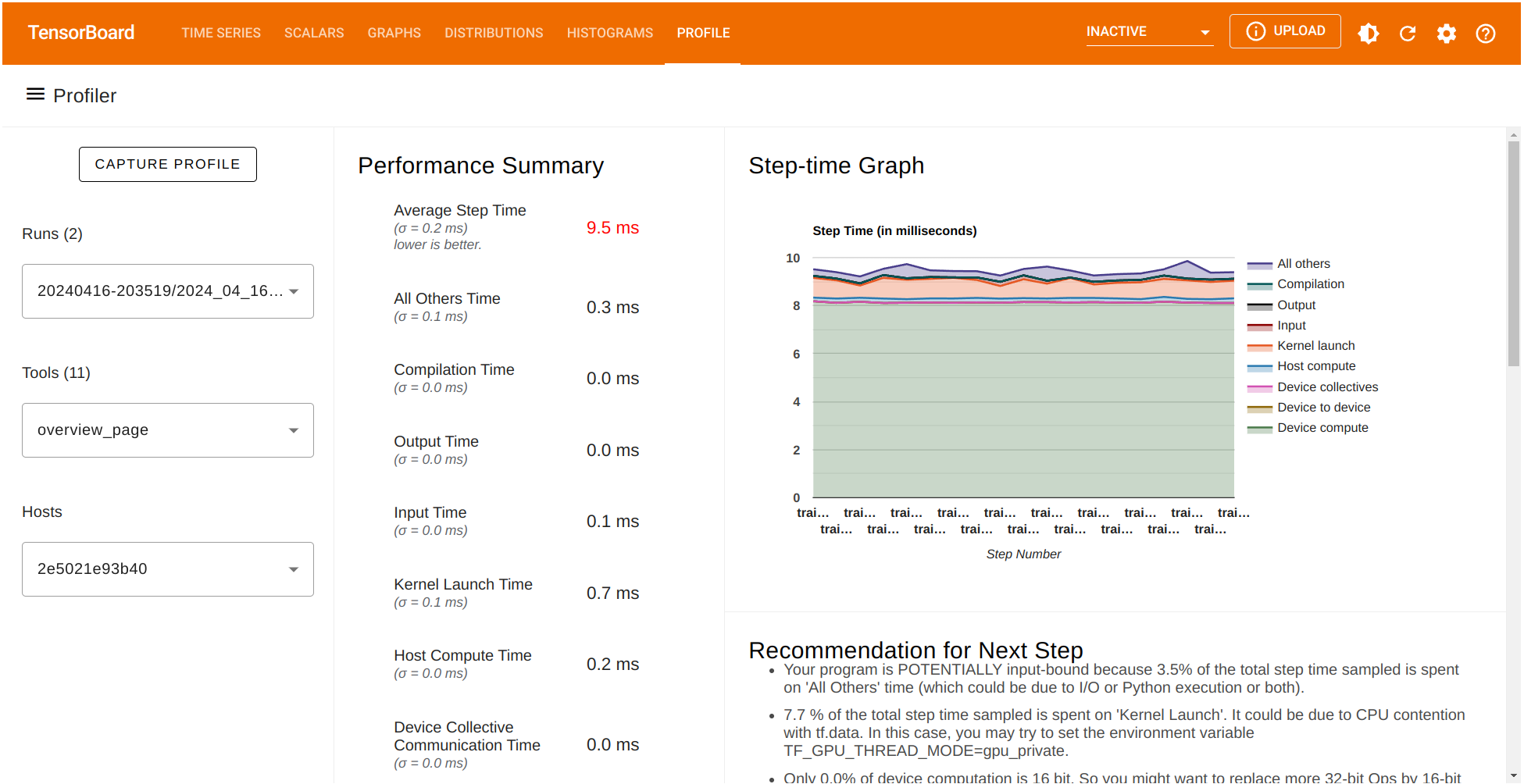
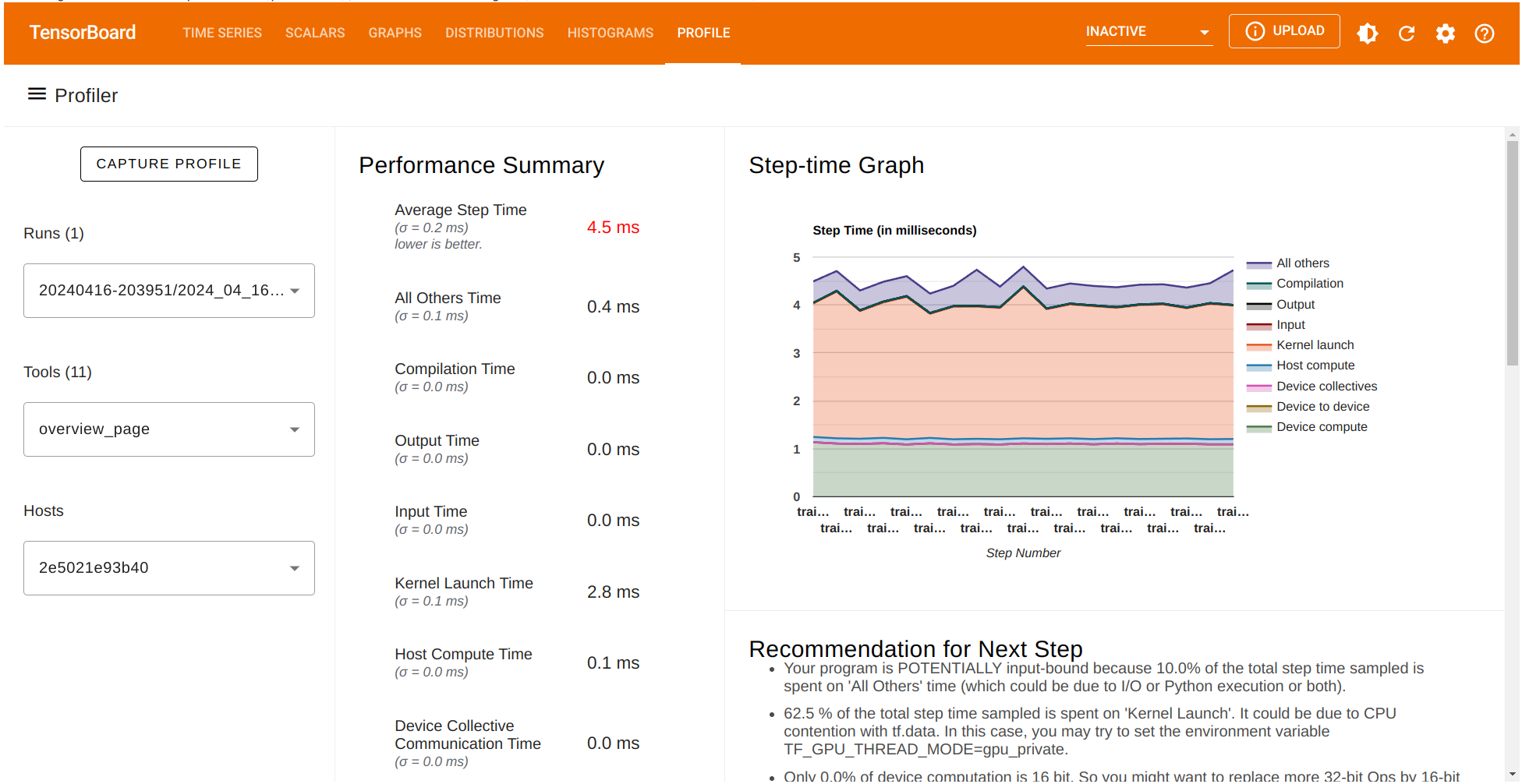
性能摘要包含若干性能指标。它还显示了一个 Step-time 图表,其中 x 轴对应于之前选择的批次(`profile_batch='500,520'`)。另外,TensorFlow Profiler 给了我们一些可以为更好性能实施的潜在建议。
TensorBoard 提供了几种工具来更好地理解我们的 TensorFlow 代码的执行。让我们专注于在同一次训练运行中收集的跟踪数据。在 Tools 菜单下选择 trace_viewer:
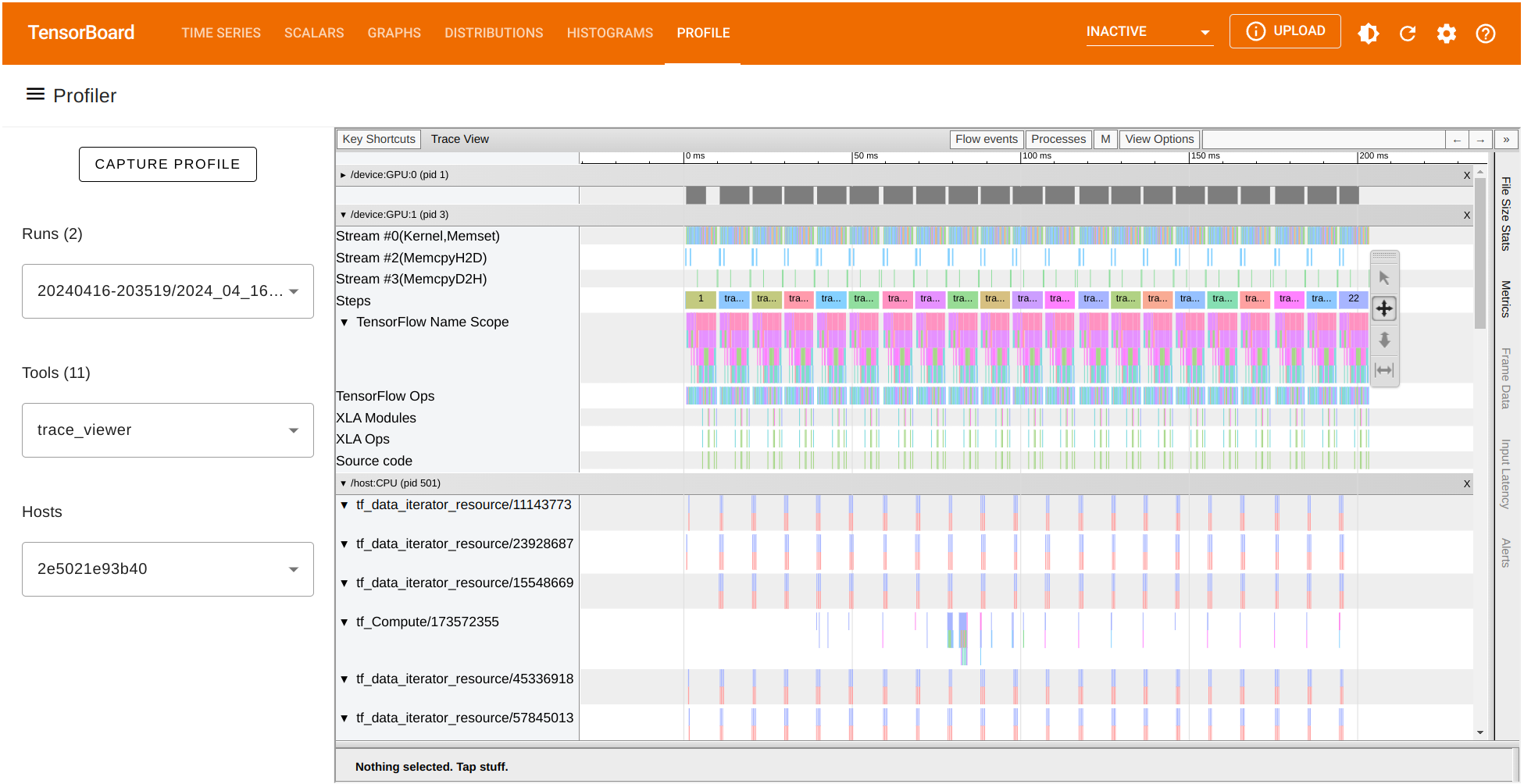
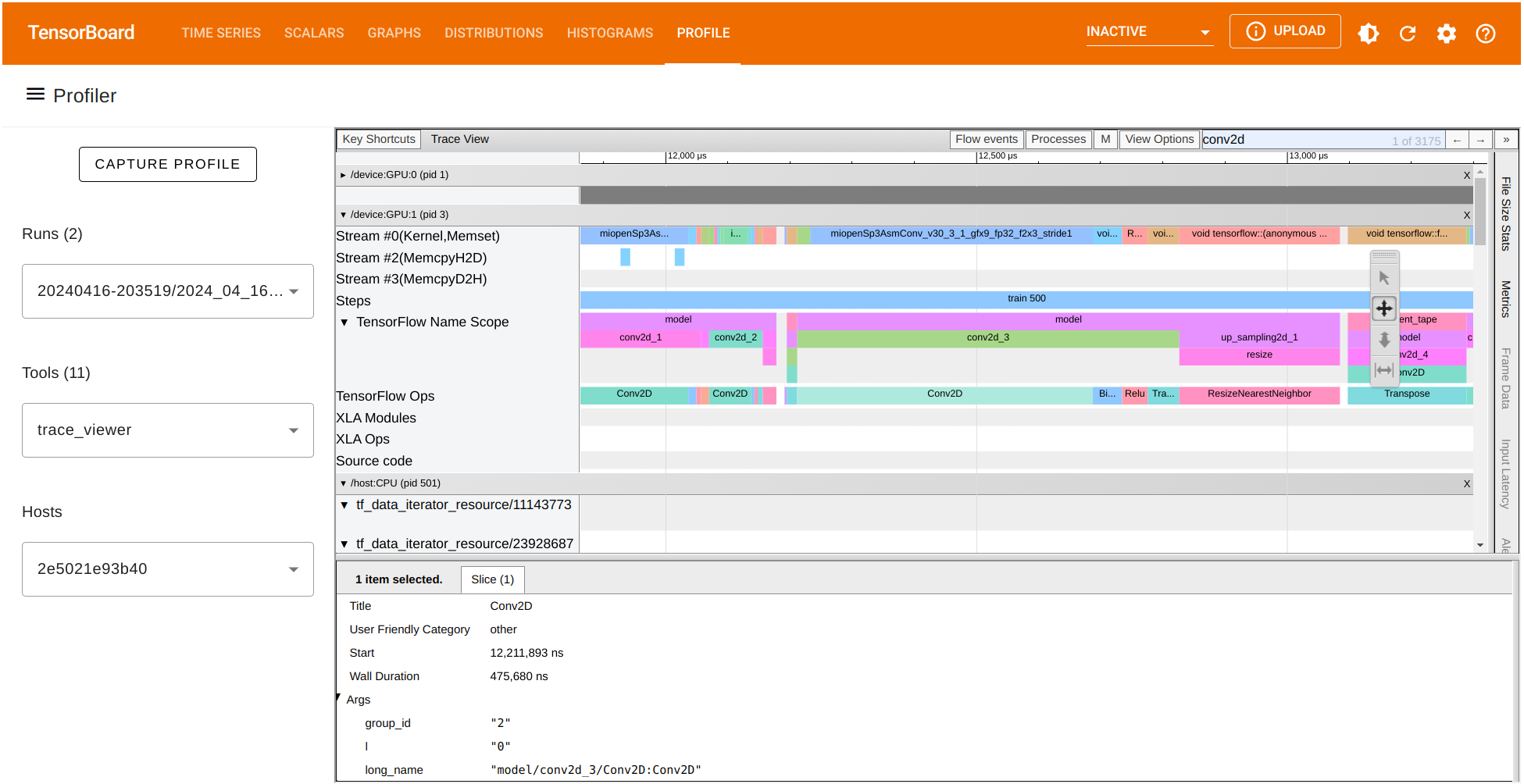
trace_viewer 选项允许我们观察每批次(`profile_batch='500,520'`)收集的跟踪数据。在跟踪视图内,x 轴表示时间,y 轴列出在可用设备上收集的每个跟踪。使用 A D W 和 S 键分别向左移动,向右移动,放大和缩小。
我们还可以查看任何 TensorFlow 操作的运行时间并可视化其跟踪。让我们重点关注批次 500。就我们的情况,我们观察到 GPU:1 上的 Conv2D 操作的持续时间约为 475,680 纳秒(ns)。根据这张图表,这个操作消耗了大部分处理时间。我们还可以观察其他 GPU 操作的运行时间以及在 CPU 上记录的跟踪。
比较不同 Profiler 运行的数据
到目前为止,我们已经展示了如何在 TensorFlow 中分析和可视化自动编码器实现的跟踪数据。我们还展示了 TensorFlow Profiler 如何创建训练过程中计算操作的性能摘要,甚至为我们提供潜在的改进性能的建议。让我们看看在按照 TensorFlow Profiler 提供的建议对代码进行一些更改后,性能摘要如何变化。
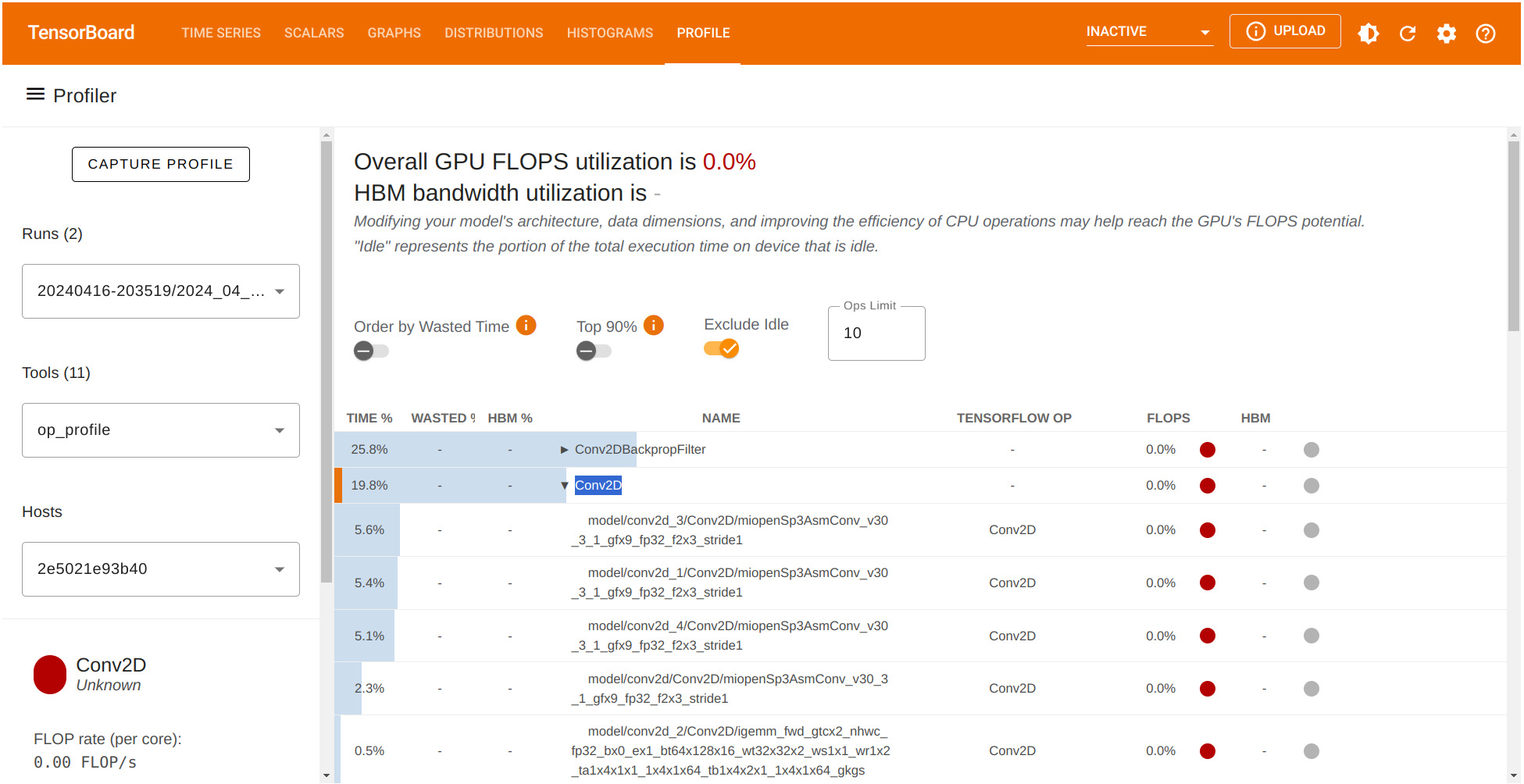
首先,通过左侧的 Tools 菜单探索 op_profile 选项。这次我们观察到 Conv2DBackpropFilter 和 Conv2D 在训练阶段占用了大部分处理时间。如果我们考虑在 Conv2D 操作中减少滤波器的数量来减少计算时间,同时在自动编码器的输出(重构)的质量之间进行权衡会怎么样呢?
让我们在对应的部分修改编码器和解码器中的滤波器数量如下:
# Encoder x = Conv2D(16,(3,3), activation = 'relu', padding = 'same')(input_img) x = MaxPooling2D((2,2), padding = 'same')(x) x = Conv2D(8, (3,3), activation = 'relu', padding = 'same')(x)
同样地,对于解码器:
# Decoder x = Conv2D(8,(3,3), activation = 'relu', padding = 'same')(encoded) x = UpSampling2D((2,2))(x) x = Conv2D(16,(3,3), activation = 'relu', padding = 'same')(x)
我们已经将编码器中的滤波器数量从原来的 512 修改为 16 ,并且在相应的 Conv2D 卷积层中从 128 修改为 8 。由于解码器的架构与编码器的架构是镜像对称的,因此在解码器部分也做了相应的修改。让我们比较输入、我们之前的自动编码器的输出和新更新后的自动编码器的输出:

在未优化和优化的重构中,我们没有看到两个自动编码器的重构之间有很大的视觉差异。
检查此更新运行记录的 TensorFlow Profiler 数据。
让我们也检查一下 Conv2D 计算中所占用的时间百分比。
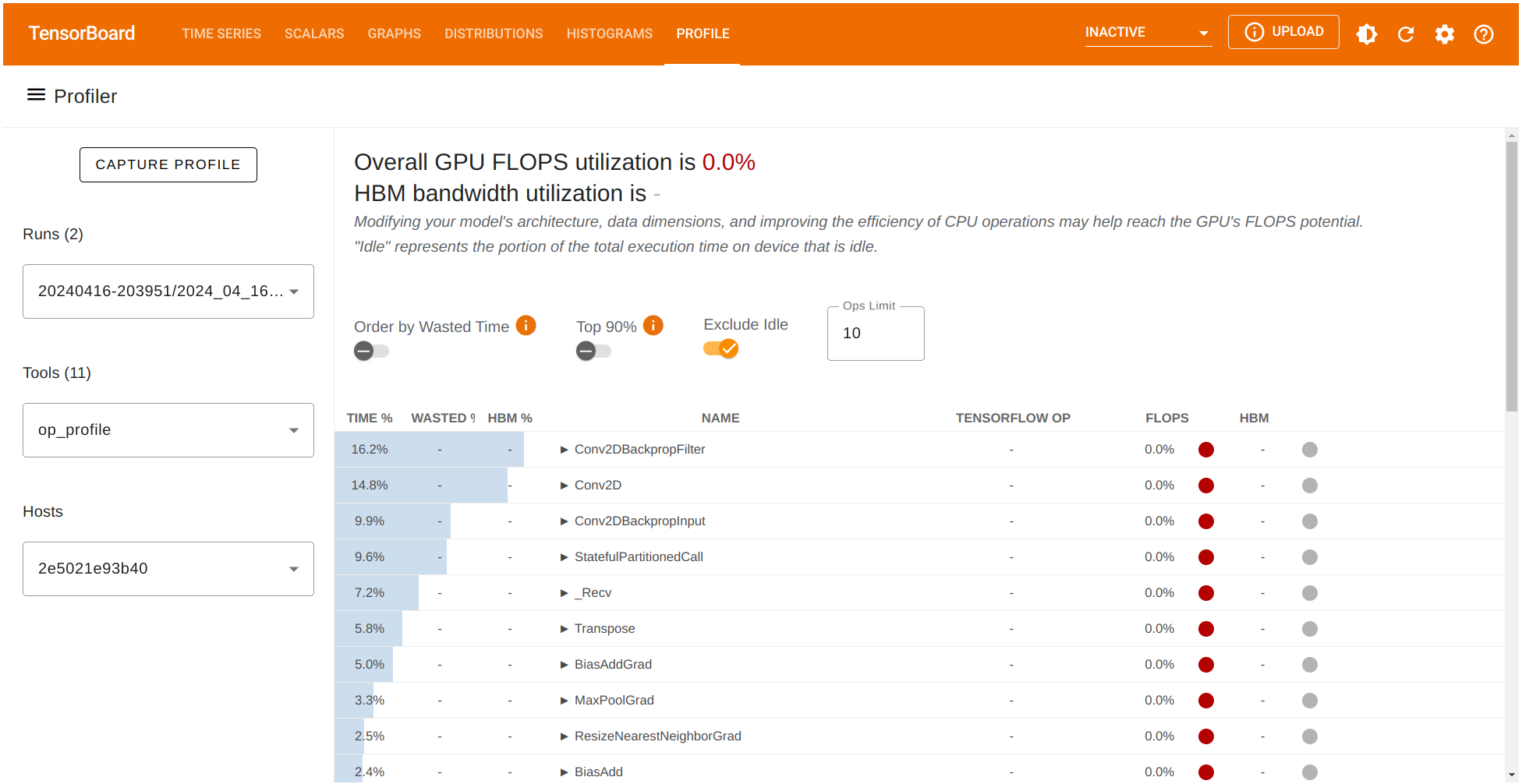
太好了!Profiler 工具帮助我们识别了模型中的潜在瓶颈,源于 Conv2D 操作。如果我们考虑在输出质量有所损失与减少计算时间之间进行一些权衡,我们可以在训练流程中实现更好的性能。
总结
TensorFlow Profiler 是一个优化深度神经网络计算的关键工具。它提供了详细的洞察力以优化 TensorFlow 模型,特别是展示了利用 AMD GPU 功能的显著优势。此设置确保了更快的机器学习计算,使得 AMD GPU 成为高级 TensorFlow 应用程序的绝佳选择。