目录
- 问题 1:Spark 作业超时
- 问题描述
- 解决方案
- Python 实现
- 问题 2:内存溢出
- 问题描述
- 解决方案
- Python 实现
- 问题 3:Shuffle 性能问题
- 问题描述
- 解决方案
- Python 实现
- 问题 4:Spark 作业调度不均
- 问题描述
- 解决方案
- Python 实现
- 问题 5:任务失败
- 问题描述
- 解决方案
- Python 实现
- 问题 6:GC 频繁
- 问题描述
- 解决方案
- Python 实现
- 问题 7:数据倾斜
- 问题描述
- 解决方案
- Python 实现
- 问题 8:Executor 失败
- 问题描述
- 解决方案
- Python 实现
- 问题 9:JVM 参数配置不当
- 问题描述
- 解决方案
- Python 实现
- 问题 10:资源不足导致调度延迟
- 问题描述
- 解决方案
- Python 实现
- 问题 11:SQL 查询性能差
- 问题描述
- 解决方案
- Python 实现
- 问题 12:无法读取数据源
- 问题描述
- 解决方案
- Python 实现
- 问题 13:Zookeeper 配置问题
- 问题描述
- 解决方案
- Python 实现
- 问题 14:HDFS 数据读取失败
- 问题描述
- 解决方案
- Python 实现
- 问题 15:Spark 集群失去联系
- 问题描述
- 解决方案
- Python 实现
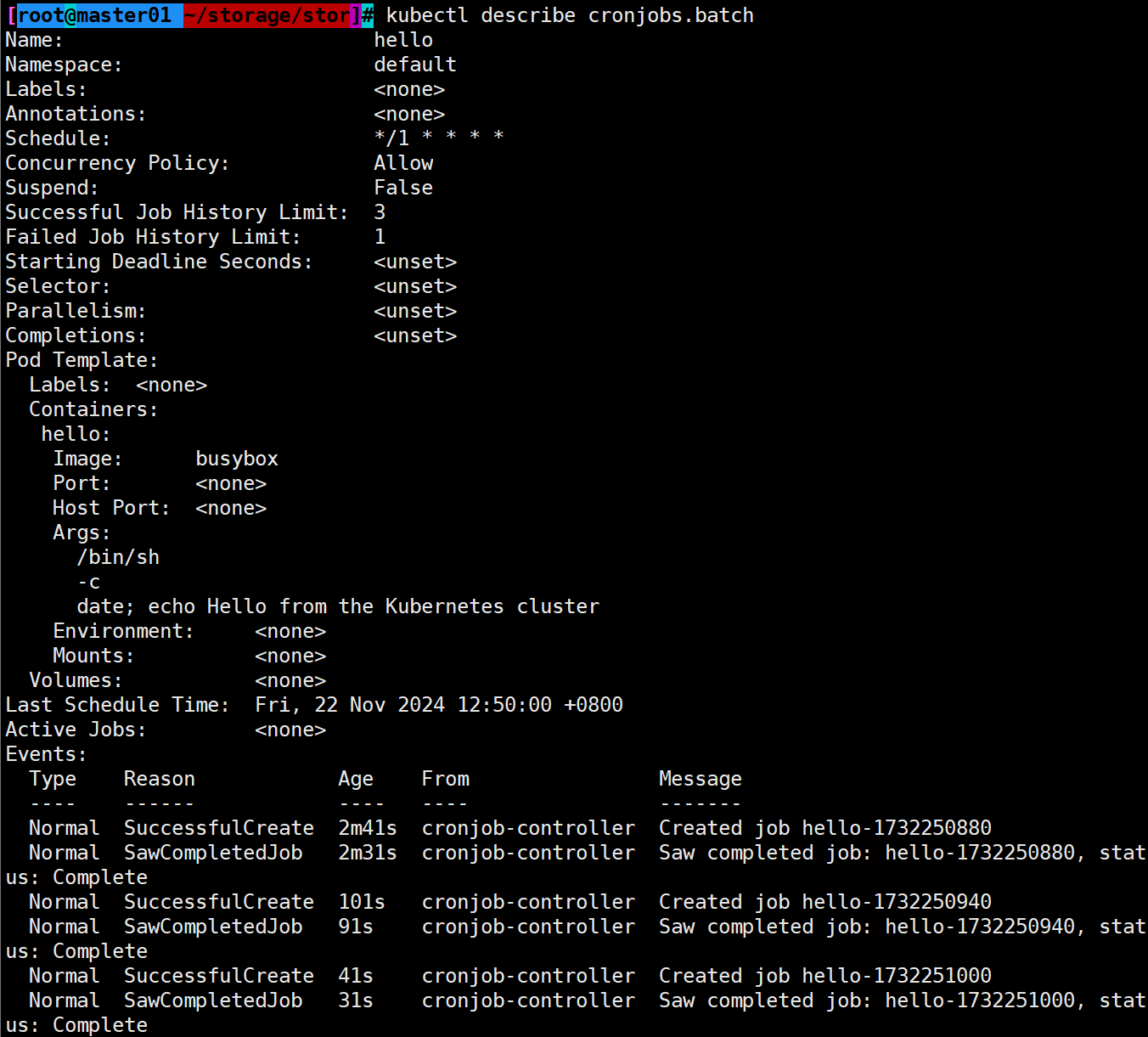
以下是关于 Spark 使用过程中的 15 个常见问题、详细解决方案及 Python 面向对象代码实现的总结。对于每个问题,给出了实际代码示例和解决方案。
问题 1:Spark 作业超时
问题描述
Spark 作业可能会因为资源不足或任务调度不当而超时。
解决方案
- 增加 Spark 的超时时间。
- 调整 Spark 的资源分配,确保每个作业都能获得足够的 CPU 和内存。
Python 实现
from pyspark.sql import SparkSessionclass SparkJobTimeoutConfig:def __init__(self, spark):self.spark = sparkdef update_timeout(self, spark_conf, timeout_ms):print(f"设置 Spark 作业超时为 {timeout_ms} 毫秒。")self.spark.conf.set(spark_conf, timeout_ms)# 示例
spark = SparkSession.builder.appName("TimeoutExample").getOrCreate()
configurer = SparkJobTimeoutConfig(spark)
configurer.update_timeout("spark.network.timeout", 120000) # 设置超时为120秒
问题 2:内存溢出
问题描述
Spark 作业可能由于内存配置不足而导致内存溢出。
解决方案
- 增加 executor 的内存,使用
spark.executor.memory配置。 - 增加分区数,减少单个任务的内存占用。
Python 实现
class SparkMemoryConfig:def __init__(self, spark):self.spark = sparkdef configure_memory(self, memory_size):print(f"配置每个 Executor 的内存为 {memory_size}。")self.spark.conf.set("spark.executor.memory", memory_size)# 示例
spark = SparkSession.builder.appName("MemoryConfigExample").getOrCreate()
memory_configurer = SparkMemoryConfig(spark)
memory_configurer.configure_memory("4g")
问题 3:Shuffle 性能问题
问题描述
Spark 在进行 shuffle 操作时,性能可能会显著下降,尤其是在大规模数据集下。
解决方案
- 增加 shuffle 文件的压缩。
- 调整 shuffle 的分区数,避免过多或过少的分区。
Python 实现
class ShuffleOptimizer:def __init__(self, spark):self.spark = sparkdef optimize_shuffle(self, shuffle_partitions=200, shuffle_compression="snappy"):print(f"设置 shuffle 分区数为 {shuffle_partitions} 和压缩格式为 {shuffle_compression}。")self.spark.conf.set("spark.sql.shuffle.partitions", shuffle_partitions)self.spark.conf.set("spark.shuffle.compress", "true")self.spark.conf.set("spark.shuffle.spill.compress", "true")self.spark.conf.set("spark.io.compression.codec", shuffle_compression)# 示例
spark = SparkSession.builder.appName("ShuffleOptimization").getOrCreate()
shuffle_optimizer = ShuffleOptimizer(spark)
shuffle_optimizer.optimize_shuffle(shuffle_partitions=300, shuffle_compression="lz4")
问题 4:Spark 作业调度不均
问题描述
Spark 作业调度不均可能导致一些节点被过度利用,而其他节点处于空闲状态。
解决方案
- 使用 Fair Scheduler 或 Capacity Scheduler 进行作业调度。
- 调整
spark.scheduler.mode参数,选择公平调度或容量调度模式。
Python 实现
class SchedulerConfig:def __init__(self, spark):self.spark = sparkdef configure_scheduler(self, scheduler_mode="FAIR"):print(f"设置 Spark 调度模式为 {scheduler_mode}。")self.spark.conf.set("spark.scheduler.mode", scheduler_mode)# 示例
spark = SparkSession.builder.appName("SchedulerConfigExample").getOrCreate()
scheduler_config = SchedulerConfig(spark)
scheduler_config.configure_scheduler(scheduler_mode="FAIR")
问题 5:任务失败
问题描述
Spark 任务失败可能是由于资源不足、数据损坏或代码错误导致的。
解决方案
- 增加任务的重试次数,使用
spark.task.maxFailures配置。 - 调整
spark.speculation配置启用任务推测执行。
Python 实现
class TaskFailureHandler:def __init__(self, spark):self.spark = sparkdef set_retry_policy(self, max_failures=4, enable_speculation=True):print(f"设置任务最大重试次数为 {max_failures},启用推测执行: {enable_speculation}")self.spark.conf.set("spark.task.maxFailures", max_failures)self.spark.conf.set("spark.speculation", enable_speculation)# 示例
spark = SparkSession.builder.appName("TaskFailureHandler").getOrCreate()
failure_handler = TaskFailureHandler(spark)
failure_handler.set_retry_policy(max_failures=6, enable_speculation=True)
问题 6:GC 频繁
问题描述
频繁的垃圾回收 (GC) 会影响 Spark 作业的性能。
解决方案
- 调整 Spark 的内存设置,确保每个任务使用的内存合理。
- 增加 executor 的数量,减少每个 executor 的内存压力。
Python 实现
class GCOptimizer:def __init__(self, spark):self.spark = sparkdef adjust_gc_settings(self, executor_cores=2, executor_memory="2g"):print(f"调整 GC 设置,executor 核心数为 {executor_cores},内存为 {executor_memory}。")self.spark.conf.set("spark.executor.cores", executor_cores)self.spark.conf.set("spark.executor.memory", executor_memory)# 示例
spark = SparkSession.builder.appName("GCOptimization").getOrCreate()
gc_optimizer = GCOptimizer(spark)
gc_optimizer.adjust_gc_settings(executor_cores=4, executor_memory="4g")
问题 7:数据倾斜
问题描述
Spark 中的某些操作(如 join、groupBy)可能导致数据倾斜,导致部分任务处理数据过多而其他任务几乎没有数据。
解决方案
- 对数据进行分区,使用
salting技术进行均衡。 - 使用
broadcast变量进行广播小表以避免数据倾斜。
Python 实现
class DataSkewHandler:def __init__(self, spark):self.spark = sparkdef handle_skew(self, df):print("处理数据倾斜,使用广播变量优化 join 操作。")# 假设 `small_df` 是一个小表small_df = self.spark.read.parquet("/path/to/small_df")broadcasted_df = self.spark.broadcast(small_df)result_df = df.join(broadcasted_df, on="key", how="left")return result_df# 示例
spark = SparkSession.builder.appName("DataSkewExample").getOrCreate()
df = spark.read.parquet("/path/to/large_df")
skew_handler = DataSkewHandler(spark)
result = skew_handler.handle_skew(df)
问题 8:Executor 失败
问题描述
Executor 失败可能由于内存溢出、硬件故障或长时间运行的任务。
解决方案
- 增加 executor 的内存配置,使用
spark.executor.memory配置。 - 设置合适的任务分配,避免 executor 资源过载。
Python 实现
class ExecutorFailureHandler:def __init__(self, spark):self.spark = sparkdef configure_executor(self, memory_size="4g", cores=2):print(f"配置 executor 内存为 {memory_size},核心数为 {cores}。")self.spark.conf.set("spark.executor.memory", memory_size)self.spark.conf.set("spark.executor.cores", cores)# 示例
spark = SparkSession.builder.appName("ExecutorFailureExample").getOrCreate()
executor_handler = ExecutorFailureHandler(spark)
executor_handler.configure_executor(memory_size="6g", cores=4)
问题 9:JVM 参数配置不当
问题描述
Spark 的 JVM 参数配置不当,可能会影响性能或导致任务失败。
解决方案
通过 spark.driver.extraJavaOptions 和 spark.executor.extraJavaOptions 配置 JVM 参数。
Python 实现
class JVMConfig:def __init__(self, spark):self.spark = sparkdef configure_jvm(self, java_options="-Xmx4g"):print(f"配置 JVM 参数: {java_options}")self.spark.conf.set("spark.driver.extraJavaOptions", java_options)self.spark.conf.set("spark.executor.extraJavaOptions", java_options)# 示例
spark = SparkSession.builder.appName("JVMConfigExample").getOrCreate()
jvm_configurer = JVMConfig(spark)
jvm_configurer.configure_jvm(java_options="-Xmx8g")
问题 10:资源不足导致调度延迟
问题描述
Spark 作业可能因为资源不足,导致调度延迟,影响作业执行时间。
解决方案
- 增加集群的资源,确保足够的 executor 和内存。
- 使用动态资源分配 (
spark.dynamicAllocation.enabled) 来提高资源利用率。
Python 实现
class ResourceAllocation:def __init__(self, spark):self.spark = sparkdef enable_dynamic_allocation(self, min_executors=2, max_executors=10):print(f"启用动态资源分配,最小 Executors 为 {min_executors},最大 Executors 为 {max_executors}。")self.spark.conf.set("spark.dynamicAllocation.enabled", "true")self.spark.conf.set("spark.dynamicAllocation.minExecutors", min_executors)self.spark.conf.set("spark.dynamicAllocation.maxExecutors", max_executors)# 示例
spark = SparkSession.builder.appName("ResourceAllocationExample").getOrCreate()
resource_allocator = ResourceAllocation(spark)
resource_allocator.enable_dynamic_allocation(min_executors=3, max_executors=15)
问题 11:SQL 查询性能差
问题描述
SQL 查询执行时性能较差,尤其是在大数据量下。
解决方案
- 使用
cache()或persist()方法缓存数据。 - 调整 Spark SQL 配置,优化查询性能。
Python 实现
class SQLPerformanceOptimizer:def __init__(self, spark):self.spark = sparkdef optimize_sql(self, df):print("优化 SQL 查询,缓存数据。")df.cache()df.show()# 示例
spark = SparkSession.builder.appName("SQLPerformanceExample").getOrCreate()
df = spark.read.parquet("/path/to/data")
optimizer = SQLPerformanceOptimizer(spark)
optimizer.optimize_sql(df)
问题 12:无法读取数据源
问题描述
Spark 可能无法读取数据源,可能是因为数据路径错误、格式不支持等问题。
解决方案
- 确保数据路径正确,并且 Spark 支持该格式。
- 使用适当的读取方法(如
.csv(),.parquet())指定格式。
Python 实现
class DataSourceReader:def __init__(self, spark):self.spark = sparkdef read_data(self, file_path, format="parquet"):print(f"读取 {format} 格式的数据:{file_path}")if format == "parquet":return self.spark.read.parquet(file_path)elif format == "csv":return self.spark.read.csv(file_path, header=True, inferSchema=True)# 示例
spark = SparkSession.builder.appName("DataSourceExample").getOrCreate()
reader = DataSourceReader(spark)
df = reader.read_data("/path/to/data", format="csv")
问题 13:Zookeeper 配置问题
问题描述
Zookeeper 配置不当会影响 Spark 集群的协调和容错能力。
解决方案
- 配置正确的 Zookeeper 地址和端口。
- 调整
spark.zookeeper.url配置,确保节点间通信稳定。
Python 实现
class ZookeeperConfig:def __init__(self, spark):self.spark = sparkdef configure_zookeeper(self, zk_url="localhost:2181"):print(f"设置 Zookeeper 地址为 {zk_url}。")self.spark.conf.set("spark.zookeeper.url", zk_url)# 示例
spark = SparkSession.builder.appName("ZookeeperConfigExample").getOrCreate()
zk_configurer = ZookeeperConfig(spark)
zk_configurer.configure_zookeeper(zk_url="zookeeper1:2181")
问题 14:HDFS 数据读取失败
问题描述
Spark 读取 HDFS 数据时可能因权限或路径错误导致失败。
解决方案
- 检查文件路径,确保路径正确。
- 检查 HDFS 文件权限,确保 Spark 有读取权限。
Python 实现
class HDFSReader:def __init__(self, spark):self.spark = sparkdef read_hdfs_data(self, hdfs_path):print(f"读取 HDFS 数据:{hdfs_path}")return self.spark.read.parquet(hdfs_path)# 示例
spark = SparkSession.builder.appName("HDFSReadExample").getOrCreate()
hdfs_reader = HDFSReader(spark)
df = hdfs_reader.read_hdfs_data("hdfs://namenode/path/to/data")
问题 15:Spark 集群失去联系
问题描述
Spark 集群的节点可能因为网络故障或配置错误导致失去联系。
解决方案
- 检查 Spark 集群配置文件,确保所有节点的配置一致。
- 检查网络连接,确保节点间的通信通畅。
Python 实现
class ClusterHealthChecker:def __init__(self, spark):self.spark = sparkdef check_cluster_health(self):print("检查 Spark 集群健康状态。")status = self.spark.sparkContext.statusTracker()print(status)# 示例
spark = SparkSession.builder.appName("ClusterHealthCheck").getOrCreate()
health_checker = ClusterHealthChecker(spark)
health_checker.check_cluster_health()
这些是 Spark 中常见的 15 个问题、分析及解决方案。通过面向对象的设计,给出了解决问题的实现方式和代码示例,帮助开发者更加高效地配置、调优和排除故障。




![[第五空间 2021]pklovecloud 详细题解](https://i-blog.csdnimg.cn/direct/25a7ae7d2d604682807f05922b4ff3da.png)