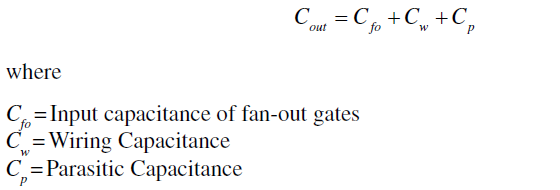主页:Getting Started—>Release Notes
NVIDIA TensorRT 是一个 C++ 库,可促进 NVIDIA GPU 上的高性能推理。它旨在与常用于训练的深度学习框架配合使用。TensorRT 专注于在 GPU 上快速高效地运行已经训练过的网络以生成结果;也称为推理。这些发行说明描述了 TensorRT 10.6.0 产品包的主要功能、软件增强和改进以及已知问题。
发行说明
NVIDIA TensorRT 是一个 C++ 库,可促进 NVIDIA GPU 上的高性能推理。它旨在与常用于训练的深度学习框架配合使用。TensorRT 专注于在 GPU 上快速高效地运行已训练的网络以生成结果;也称为推理。这些发行说明描述了 TensorRT 10.6.0 产品包的主要功能、软件增强和改进以及已知问题。
有关以前发布的 TensorRT 文档,请参阅 TensorRT 档案。
1. TensorRT Release 10.x.x
1.1. TensorRT Release 10.6.0
1.2. TensorRT Release 10.5.0
1.3. TensorRT Release 10.4.0
1.4. TensorRT Release 10.3.0
这些是 TensorRT 10.3.0 发行说明,适用于 x86 Linux 和 Windows 用户、Linux 上的基于 Arm® 的 CPU 核心(适用于服务器基础系统架构 (SBSA) 用户)和 JetPack 用户。此版本包括来自以前 TensorRT 版本的几个修复和其他更改。
有关以前发布的 TensorRT 文档,请参阅 NVIDIA TensorRT 存档文档。
主要功能和增强功能
此 TensorRT 版本包括以下主要功能和增强功能
-
在 IBuilderConfig 中添加了新的 setRuntimePlatform API,以增强 TensorRT 引擎的跨平台兼容性。此 API 在与构建 TensorRT 引擎不同的运行时平台上执行 TensorRT 引擎。目前,TensorRT 支持在 Linux x86_64 平台上构建引擎并在 Windows x86_64 平台上运行引擎。此功能是实验性的,但预计将在下一个 TensorRT 版本中投入生产。
-
当 GEMM 具有较大的权重常数时,改进了引擎构建时间。
-
为 NVIDIA Ada Lovelace GPU (SM 89) 添加了 FP8 卷积,其限制与 NVIDIA Hopper 对 FP8 卷积的限制相同。
-
改进了 Normalization 和 FP8 量化融合的性能。
-
添加了为实现 IPluginV3 的 TensorRT 插件的输入输出对添加别名的功能。要使用此功能,插件必须实现 IPluginV3OneBuildV2 构建功能接口,并且必须启用 PreviewFeature::kALIASED_PLUGIN_IO_10_03。
Compatibility
-
TensorRT 10.3.0 has been tested with the following:
TensorFlow 2.13.1
PyTorch >= 2.0 (refer to the requirements.txt file for each sample)
ONNX 1.16.0 -
This TensorRT release supports CUDA®:
12.5 update 1
12.4 update 1
12.3 update 2
12.2 update 2
12.1 update 1
12.0 update 1
11.8
11.7 update 1
11.6 update 2
11.5 update 2
11.4 update 4
11.3 update 1
11.2 update 2
11.1 update 1
11.0 update 3 -
此 TensorRT 版本至少需要 Linux 上的 NVIDIA 驱动程序 r450 或 Windows 上的 r452,这是 CUDA 11.0 所要求的,这是此 TensorRT 版本支持的最低 CUDA 版本。
限制
1.对于组卷积和深度卷积,没有优化的 FP8 卷积。因此,对于包含这些卷积操作的 ConvNets,仍然建议使用 INT8。
2. FP8 卷积仅支持输入/输出通道,它们是 16 的倍数。否则,TensorRT 将回退到非 FP8 卷积
3. FP8 MHA 中批量 GEMMS 的累积 dtype 必须是 FP32。
-
这可以通过在批量 GEMM 之前添加 Cast(到 FP32)操作并在批量 GEMM 之后添加 Cast(到 FP16)来实现。
-
或者,您可以使用 TensorRT 模型优化器转换您的 ONNX 模型,它会自动添加 Cast 操作。
- 在 FP8 MHA 中,第一个批量 GEMM 和 softmax 之间不能有任何逐点操作,例如使用注意力掩码。这将在未来的 TensorRT 版本中得到改进。
- FP8 MHA 融合仅支持头部大小为 16 的倍数。如果 MHA 的头部大小不是 16 的倍数,请勿在 MHA 中添加 Q/DQ 操作以回退到 FP16 MHA 以获得更好的性能
- 在 QNX 上,分割成大量 DLA 可加载项的网络可能会在推理期间失败。
- DLA 编译器可以删除身份转置,但不能将多个相邻的转置层融合为单个转置层(重塑也是如此)。例如,给定一个由两个非平凡转置和中间的身份重塑组成的 TensorRT IShuffleLayer,除非用户提前在模型定义中手动合并转置,否则 shuffle 层将转换为两个连续的 DLA 转置层。
- 隐式批处理模式不支持 IUnaryLayer 的 nvinfer1::UnaryOperation::kROUND 或 nvinfer1::UnaryOperation::kSIGN 操作。
- 对于包含规范化层的网络,特别是如果以混合精度部署,则以包含相应函数操作的最新 ONNX 操作集为目标,例如 LayerNormalization 的
opset 17 或 GroupNormalization 的 opset 18。使用函数操作的数值精度优于使用原始操作的相应规范化层实现。 - 权重流目前主要支持基于 GEMM 的网络,例如 Transformers。基于卷积的网络可能只有少数权重可以流式传输。
- 弃用 INT8 隐式量化和校准器 API,包括 dynamicRangeIsSet、CalibrationAlgoType、IInt8Calibrator、IInt8EntropyCalibrator、IInt8EntropyCalibrator2、IInt8MinMaxCalibrator、IInt8Calibrator、setInt8Calibrator、getInt8Calibrator、setCalibrationProfile、getCalibrationProfile、setDynamicRange、getDynamicRangeMin、getDynamicRangeMax 和 getTensorsWithDynamicRange。它们可能无法提供最佳性能和准确性。作为解决方法,请改用
INT8 显式量化。 - 当两个具有 INT8-QDQ 和残差相加的卷积共享相同权重时,不会发生恒定权重融合。复制共享权重以获得更好的性能。
弃用 API 的生命周期
TensorRT 10.3 中弃用的 API 将保留到 2025 年 8 月。
TensorRT 10.2 中弃用的 API 将保留到 2025 年 7 月。
TensorRT 10.1 中弃用的 API 将保留到 2025 年 5 月。
TensorRT 10.0 中弃用的 API 将保留到 2025 年 3 月。
TensorRT 9.3 中弃用的 API 将保留到 2025 年 1 月。
TensorRT 9.2 中弃用的 API 将保留到 2024 年 11 月。
TensorRT 9.1 中弃用的 API 将保留到 2024 年 10 月。
TensorRT 9.0 中弃用的 API 将保留到 2024 年 8 月。
请参阅 API 文档(C++、Python)以获取有关更新代码以删除已弃用功能的说明。
已弃用和删除的功能
以下功能已在 TensorRT 10.3.0 中弃用或删除。
从 TensorRT 10.0 开始,弃用 NVIDIA Volta 支持(具有计算能力 7.0 的 GPU)。Volta 支持可能会在 2024 年 9 月之后被删除。
弃用 ScatterElements 插件的第 1 版。它被实现 IPluginV3 接口的第 2 版取代。
已修复问题
修复了在 Hopper GPU 上并行运行多个执行上下文时出现的间歇性挂起问题。
使用 FP8 卷积运行 ResNet18/ResNet50 时存在已知准确性问题。此问题已修复。
当 K 等于 0 且缩减维度很大时,TopK 可能出现除以零的错误。
已知问题是 Diffusion 网络的引擎构建可能会失败。解决方法是启用 -stronglyTyped 选项。
与 TensorRT 9.3 相比,NVIDIA Orin 上的 ConvNext 性能下降高达 10%。
与 TensorRT 9.2 相比,包含 GridSample 操作的网络性能下降高达 4 倍。
libnvinfer_lean.so 库的大小增加了 10 MB。此问题已修复。
已为包括detectron2、efficientdet、efficientnet、engine_refit_onnx_bidaf、introductory_parser_samples、network_api_pytorch_mnist、onnx_custom_plugin、onnx_packnet、sample_weight_stripping、simple_progress_monitor、tensorflow_object_detection_api和yolo_v3_onnx在内的示例启用了Python 3.12支持。
在使用静态链接编译示例时,如果显示错误消息/usr/bin/ld:无法转换GOTPCREL重定位;使用–no-relax重新链接,则解决方法是在samples/Makefile.config中的链接步骤中添加-Wl,--no-relax。此问题已修复。
如果切片输入是常量张量,则具有模式 nvinfer1::SampleMode::kCLAMP 或 nvinfer1::SampleMode::kFILL(ONNX 等效于具有常量或边缘模式的 Pad 操作)的 nvinfer1::ISliceLayer 可能会在引擎编译期间中断。此问题已修复,因此切片可以处理常量输入。
已知问题
功能性
如果在输入/输出通道不是 16 的倍数的卷积操作之前添加 FP8-Q/DQ 操作,则已知引擎构建失败。删除这些卷积的 FP8-Q/DQ 操作以解决此问题。
Python 示例 non_zero_plugin 和 python_plugin 不支持 Python 3.12。将在 10.4 中添加支持。此问题已在 OSS 10.3 版本中修复。
如果使用 Python 包索引 (PyPI) 安装了 TensorRT 8.6 或 9.x,则无法使用 PyPI 将 TensorRT 升级到 10.x。您必须先使用 pip uninstall tensorrt tensorrt-libs tensorrt-bindings 卸载 TensorRT,然后使用“pip install tensorrt”重新安装 TensorRT。这将删除以前的 TensorRT 版本并安装最新的 TensorRT 10.x。此步骤是必需的,因为 Python 包名称中添加了后缀 -cuXX,这会导致升级无法正常工作。
CUDA 计算清理器可能会报告某些旧内核的竞争检查危害。但是,相关内核在运行时没有功能问题。
在 NVIDIA Hopper GPU 上运行 TensorRT 应用程序时,计算清理器 initcheck 工具可能会标记误报未初始化的 global 内存读取错误。这些错误可以安全地忽略,并将在即将发布的 CUDA 版本中修复。
如果头部数量较少,多头注意力融合可能不会发生并影响性能。
CUDA 12.1 中已修复 NVRTC 中出现的使用后释放问题。当将 CUDA 12.0 中的 NVRTC 与 TensorRT 静态库一起使用时,您可能会在某些情况下遇到崩溃。链接 CUDA 12.1 或更新版本中的 NVRTC 和 PTXJIT 编译器将解决此问题。
Valgrind 内存泄漏检查工具在检测 TensorRT 应用程序的潜在内存泄漏时会报告一些已知问题。为抑制这些问题,建议在运行 Valgrind 内存泄漏检查工具时提供包含以下内容的 Valgrind 抑制文件。将选项 --keep-debuginfo=yes 添加到 Valgrind 命令行以抑制这些错误。
{Memory leak errors with dlopen.Memcheck:Leakmatch-leak-kinds: definite...fun:*dlopen*...
}
{Memory leak errors with nvrtcMemcheck:Leakmatch-leak-kinds: definitefun:mallocobj:*libnvrtc.so*...
}SM 7.5 及更早版本的设备可能没有为所有具有 Q/DQ 节点的层提供 INT8 实现。在这种情况下,您在构建引擎时会遇到无法找到任何实现的错误。要解决此问题,请删除量化失败层的 Q/DQ 节点。
安装 cuda-compat-11-4 包可能会干扰 CUDA 增强兼容性,并导致 TensorRT 失败,即使驱动程序是 r465。解决方法是删除 cuda-compat-11-4 包或将驱动程序升级到 r470。(不适用于 Jetson 平台)
对于某些网络,使用 4096 的批处理大小可能会导致 DLA 的准确性下降。
对于在启用 GPU 回退的 DLA 上运行的广播元素层,使用一个 NxCxHxW 输入和一个 Nx1x1x1 输入,如果至少一个输入以 kDLA_LINEAR 格式使用,则存在已知的准确性问题。建议将此类元素层的输入格式明确设置为不同的张量格式。
不支持使用 kAVERAGE 池化的独占填充。
由于已知的驱动程序问题,Valgrind 工具在 L4T 上使用 CUDA 12.4 时发现内存泄漏。预计此问题将在 CUDA 12.6 中修复。
由于 Windows 10 中的错误,用户定义的 processDebugTensor 函数不支持调试张量功能的异步 CUDA 调用。
当网络包含两个连续的 GEMV 操作(MatrixMultiply 与 gemmM 或 gemmN == 1)时,存在已知的准确性问题。要解决此问题,请尝试填充 MatrixMultiply 输入以使其维度大于 1。
将 INT4 张量绑定为网络输出时存在已知的准确性问题。要解决此问题,请在输出前添加 IDequantizeLayer。
在 Windows 上使用 CUDA 12.5 时,fcPlugin (CustomFCPluginDynamic) 可能会导致某些 GPU 上出现 CUDA 错误。
AArch64 tar 包(包括 SBSA 和 JetPack 版本)中包含的 libnvonnxparser_static.a 静态库构造不正确,包含 x86_64 和 AArch64 对象文件的混合。这导致 ONNX 解析器静态库无法在非 x86 平台上使用。此问题将在下一版本中修复。
与非 refit 引擎相比,kREFIT 和 kREFIT_IDENTICAL 的性能有所下降,其中卷积层存在于分支或循环内,精度为 FP16/INT8。此问题将在未来的版本中得到解决。
网络模式 fc-xelu-bias 和 conv-xelu-bias 中存在已知的准确性问题(当偏差操作在 xelu 之后时)。
对于同一网络,编译缓存的大小可能会略有增加或减少。
使用 PyPI 上托管的 Python wheel 安装 TensorRT 时,加载程序在反序列化版本兼容的引擎时找不到 lean 库。您可以通过手动将 wheel 安装目录添加到加载程序路径来解决此问题。例如,在 Linux 上,您可以运行以下命令:
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib/python3.10/dist-packages/tensorrt_lean_libs/
性能
BERT 演示不支持 Python 3.11 环境。此问题将在 TensorRT 10.5 版本中修复。
与 TensorRT 10.2 相比,在 NVIDIA Ada Lovelace GPU 上,FP16 精度和 OOTB 模式下 mamba_370m 的构建时间回归高达 45%。
与 TensorRT 10.2 相比,在 NVIDIA Ada Lovelace GPU 上,FP16 精度和 OOTB 模式下 mbart-cnn/mamba-370m 的 CPU 内存使用率回归高达 15%。
与 Ampere 和 Hopper GPU 上的 TensorRT 10.2 相比,使用 INT8 QDQ 的 BERT/Megatron 网络的性能回归高达 6%。
与 H100 GPU 上的 BS1 和 Seq128 的 TensorRT 10.2 相比,FP16 精度的 BERT/Megatron 网络的性能回归高达 6%。
与 TensorRT 10.2 相比,H100 GPU 上 FP16 精度的双向 LSTM 性能下降高达 6%。
与 TensorRT 10.2 相比,Orin 和 H100 GPU 上 PilotNet 网络的 FP16 精度性能下降高达 8%,TF32/FP32 精度性能下降高达 560%。
与 TensorRT 8.2 相比,包含 RandomUniform 操作的网络性能下降高达 300%。
与 TensorRT 10.2 相比,H100 GPU 上 TF32 精度的深度推荐网络性能下降高达 12%。
在没有注意插件的情况下运行 TensorRT-LLM 时,性能下降高达 25%。目前的建议是使用 TensorRT-LLM 时始终启用注意插件。
已知启用 REFIT 构建的引擎与禁用 REFIT 构建的引擎之间存在性能差距。
由于策略选择不稳定,Orin 上的 BERT-Large INT8-QDQ 模型的引擎大小波动高达 60 MB。
与 TensorRT 9.3 相比,BasicUNet、DynUNet 和 HighResNet 在 INT8 精度方面的性能下降高达 16%。
在 NVIDIA Hopper GPU 上,BART 网络的引擎构建时间最多可增加 40 秒。
在 NVIDIA Ampere GPU 上,某些大型语言模型 (LLM) 的引擎构建时间最多可增加 20 秒。
由于有更多可用于评估的策略,某些类似 Bert 的模型的构建时间最多可增加 2.5 倍。
与 TensorRT 8.5 相比,NVIDIA Ampere GPU 上的 CortanaASR 模型的性能下降高达 13%。
与 TensorRT 8.5.1 相比,A30/A40 上的 ShuffleNet 模型的性能下降高达 18%。
在具有隐式数据相关形状的张量上进行卷积可能比在相同大小的其他张量上运行慢得多。有关隐式数据相关形状的定义,请参阅词汇表。
对于某些 Transformer 模型,包括 ViT、Swin-Transformer 和 DETR,与 FP16 精度相比,INT8 精度(包括显式和隐式量化)的性能有所下降。
对于使用稀疏性的网络,FP16 精度的性能下降高达 5%。
与 NVIDIA A10 GPU 上 OpenRoadNet 上的 TensorRT 8.5 相比,FP16 精度的性能下降高达 6%。
与 L4 GPU 上禁用 FP16 的情况下 BERT 网络上的 TensorRT 8.6 相比,INT8 精度的性能下降高达 70%。在构建器配置中启用 FP16 并禁用 INT8 来解决此问题。
在显式量化网络中,之前有 Q/DQ 对但之后没有 Q/DQ 对的组卷积预计会以 INT8-IN-FP32-OUT 混合精度运行。但是,如果输入通道数较少,NVIDIA Hopper 可能会回退到 FP32-IN-FP32-OUT。
1.5. TensorRT Release 10.2.0
1.6. TensorRT Release 10.1.0
1.7. TensorRT Release 10.0.1
1.8. TensorRT Release 10.0.0 Early Access
2. TensorRT Release 9.x.x
2.1. TensorRT Release 9.3.0
2.2. TensorRT Release 9.2.0
2.3. TensorRT Release 9.1.0
2.4. TensorRT Release 9.0.1
3. TensorRT Release 8.x.x
3.1. TensorRT Release 8.6.1
3.2. TensorRT Release 8.5.3
这些是 TensorRT 8.5.3 发行说明,适用于 x86 Linux、Windows 和 JetPack 用户。此版本仅针对 Linux 上的服务器基础系统架构 (SBSA) 用户整合了基于 Arm® 的 CPU 核心。此版本包含来自之前 TensorRT 版本的几个修复以及以下其他更改。
这些发行说明适用于工作站、服务器和 NVIDIA JetPack™ 用户,除非特别附加(不适用于 Jetson 平台)。
有关之前发布的 TensorRT 文档,请参阅 NVIDIA TensorRT 存档文档。
弃用 API 的生命周期
TensorRT 8.0 之前弃用的 API 将在 TensorRT 9.0 中被移除。
TensorRT 8.0 中弃用的 API 将至少保留到 2022 年 8 月。
TensorRT 8.2 中弃用的 API 将至少保留到 2022 年 11 月。
TensorRT 8.4 中弃用的 API 将至少保留到 2023 年 2 月。
TensorRT 8.5 中弃用的 API 将至少保留到 2023 年 9 月。
有关如何更新代码以删除已弃用功能的使用,请参阅 API 文档(C++、Python)。
Compatibility
TensorRT 8.5.3 has been tested with the following:
cuDNN 8.6.0
TensorFlow 1.15.5
PyTorch 1.11.0
ONNX 1.12.0
This TensorRT release supports CUDA®:
11.8
11.7 update 1
11.6 update 2
11.5 update 2
11.4 update 4
11.3 update 1
11.2 update 2
11.1 update 1
11.0 update 1
10.2
建议您将 TensorRT 与经过测试的软件堆栈一起使用;包括平台和软件功能部分中记录的 cuDNN 和 cuBLAS 版本。可以使用其他语义兼容的 cuDNN 和 cuBLAS 版本;但是,其他版本可能会有性能改进和回归。在极少数情况下,还可能会观察到功能回归。
限制
-
DLA softmax 有两种模式,模式根据输入张量的形状自动选择,其中:
-
当所有非批量、非轴维度为 1 时,触发第一种模式,
-
如果有效,则在其他情况下触发第二种模式。
-
-
仅 DLA 3.9.0 及更高版本支持这两种模式中的第二种。它涉及可能导致轻微错误的近似值。此外,仅 DLA 3.9.0
及更高版本支持大于 1 的批量大小。有关更多信息,请参阅 DLA 支持的层。 -
在 QNX 上,分割成大量 DLA 可加载项的网络可能会在推理过程中失败。
-
如果在 Windows 上使用 Python 3.9.10,您可能会遇到错误,例如“无法加载库:nvinfer_builder_resource.dll”。您可以通过降级到早期版本的 Python 3.9 来解决此问题。
-
在某些情况下,RNNv2Layer 在 TensorRT 8.0 中可能需要比 TensorRT 7.2
更大的工作区大小才能运行所有支持的策略。请考虑增加工作区大小以解决此问题。 -
CUDA 图形捕获仅在使用 11.x 和 >= 11.1 驱动程序(455 或更高版本)的版本时才会捕获 inputConsumed 和
profiler 事件。 -
DLA编译器能够删除身份转置,但不能将多个相邻的转置层融合为单个转置层(重塑也是如此)。例如,给定一个由两个非平凡转置和中间的身份重塑组成的
TensorRT IShuffleLayer。除非您提前在模型定义中手动将转置合并在一起,否则 shuffle 层将转换为两个连续的
DLA 转置层。 -
在 QAT 网络中,对于之前有 Q/DQ 对但之后没有 Q/DQ 对的组卷积,我们可以在 INT8-IN-FP32-OUT
混合精度之前运行。但是,如果输入通道较小,则 NVIDIA Hopper™ 架构 GPU 中可能会丢失 GPU 内核并回退到
FP32-IN-FP32-OUT。此问题将在未来的版本中修复。 -
在 PowerPC 平台上,由于缺少 Python 模块依赖项,依赖于 TensorFlow、ONNX Runtime 和 PyTorch
的示例无法运行。这些框架尚未为 PowerPC 构建和/或发布到标准存储库。
已弃用和已删除的功能
TensorRT 8.5.3 中已弃用以下功能:
- TensorRT 8.5.3 将是支持 NVIDIA Kepler (SM 3.x) 和 NVIDIA Maxwell (SM 5.x)
设备的最后一个版本。TensorRT 8.6 将不再支持这些设备。NVIDIA Pascal (SM 6.x) 设备将在 TensorRT
8.6 中弃用。 - 在下一个 TensorRT 版本中,将不再支持 CUDA Toolkit 10.2。
已修复的问题
- 对于 INT8 融合 MHA 插件,已添加对序列长度 64 和 96 的支持。
- PyTorch 容器中存在一个问题,即某些 ONNX 模型会失败并显示错误消息 SSA 验证失败。此问题现已修复。
- 使用 IExecutionContext::enqueueV3 时,必须使用 IExecutionContext::setInputTensorAddress 或 IExecutionContext::setTensorAddress 为每个输入张量设置一个非空地址,即使没有从输入张量计算任何内容。
- 当其中一个步幅为 0 时,带有 SampleMode::kWRAP 的 ISliceLayer 有时会导致引擎构建失败。此问题已修复。
- 当网络使用隐式批处理并使用 cudaGraph 捕获时,会出现问题。此问题现已修复。
- 当使用 PreviewFeature kDISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805 时,一些使用 cuBLAS 的插件会报告 CUBLAS_STATUS_NOT_INITIALIZED 错误(使用 CUDA 版本 11.8)。此问题现已修复。
- 对于一些基于编码器的转换器网络,如果某些层上有强制精度,TensorRT 会在编译期间报告错误(张量类型不匹配)。此问题现已修复。
- 对于一些有分支的网络,如果一侧的某些层上有强制精度,TensorRT 会在编译期间报告错误张量类型不匹配。此问题现已修复。
- 当使用多个配置文件时触发断言,并且配置文件最终导致发生不同的优化,从而导致插槽数量不足的错误。此问题已修复,以正确初始化内部使用的插槽。
- 当矩阵乘法水平融合过程融合具有偏差的两层时,偏差融合无法正确处理,从而导致准确性问题。此问题现已修复。
- 当网络包含 Exp 运算符并且 Exp 运算符具有常量输入时,会出现准确性问题。此问题现已修复。
- 与 Pascal GPU 上的 TensorRT 8.4 相比,LSTM 网络在 FP32 精度方面的性能下降高达
16%。此问题现已修复。 - 当 GEMM/Conv/MatMul 操作后跟 Reshape 操作时,TensorRT 可能会输出错误的结果。此问题现已修复。
公告
- 在下一个 TensorRT 版本中,cuDNN、cuBLAS 和 cuBLASLt 策略源将在构建器分析中默认关闭。TensorRT计划在未来版本中删除 cuDNN、cuBLAS 和 cuBLASLt 依赖项。使用 PreviewFeature 标志 kDISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805 评估禁用 cuBLAS 和 cuDNN对功能和性能的影响,并在您的用例中出现严重回归时向 TensorRT 报告。
- TensorRT 8.5 之前的 TensorRT Python wheel 文件(例如 TensorRT 8.4)已发布到 NGC PyPI repo。从 TensorRT 8.5 开始,Python wheel 将发布到上游 PyPI。这将使安装 TensorRT变得更容易,因为它不需要任何先决条件步骤。此外,用于安装的 Python 包的名称已从 nvidia-tensorrt 更改为 tensorrt。
- 以前版本中的 C++ 和 Python API 文档包含在 tar 文件包中。此版本不再将文档捆绑在 tar 文件中,因为在线文档可以在发布后更新,并避免遇到包内陈旧文档中发现的错误。
已知问题
功能性
- 当 GEMM 操作后跟 gelu_erf 操作时,为 CUDA 11.4 编译的 TensorRT 可能无法编译图表。
- 已知问题在于,即使可以运行更大的输入形状,大型图表也会导致特定输入形状出现内存不足错误。
- Valgrind 内存泄漏检查工具在检测 TensorRT 应用程序的潜在内存泄漏时报告了已知问题。建议在运行 Valgrind
内存泄漏检查工具时提供包含以下内容的 Valgrind 抑制文件来抑制这些问题。将选项 --keep-debuginfo=yes 添加到
Valgrind 命令行以抑制这些错误。
{Memory leak errors with dlopen.Memcheck:Leakmatch-leak-kinds: definite...fun:*dlopen*...
}
{Memory leak errors with nvrtcMemcheck:Leakmatch-leak-kinds: definitefun:mallocobj:*libnvrtc.so*...
}
- 使用 Python 3.10 安装要求时,Python 示例 yolov3_onnx 存在已知问题。建议在运行示例时使用 Python
版本 < 3.10。 - 自动调谐器假设 INonZeroLayer 返回的索引数量是输入元素数量的一半。因此,依赖于更严格假设的网络可能无法构建。
- SM 7.5 及更早版本的设备可能没有所有具有 Q/DQ 节点的层的 INT8
实现。在这种情况下,您将在构建引擎时遇到无法找到任何实现的错误。要解决此问题,请删除量化失败层的 Q/DQ 节点。 - 来自 cuDNN 的反卷积算法之一表现出非确定性执行。禁用 cuDNN 策略将阻止选择此算法(请参阅
IBuilderConfig::setTacticSources)。 - 当仅设置输出类型而非层精度时,FP16 模式下的 TensorRT 无法正确执行转换操作。
- TensorRT 不会为从 FP16 模式下的 ONNX 模型导入的操作保留精度。
- 在 WSL 平台上使用 ILoop 层的网络存在已知功能问题(编译期间出现 CUDA 错误)。
- 在 SM 3.x 设备上无法为 CUDA 10.x 选择策略源 cuBLASLt。如果选择,它将回退到使用 cuBLAS。(不适用于 Jetson 平台)
- 安装 cuda-compat-11-4 包可能会干扰 CUDA 增强兼容性并导致 TensorRT 失败,即使驱动程序是 r465。解决方法是删除 cuda-compat-11-4 包或将驱动程序升级到 r470。(不适用于 Jetson 平台)
- TensorFlow 1.x 不支持 Python 3.9 或更新版本。任何依赖于 TensorFlow 1.x 的 Python 示例都无法使用 Python 3.9 或更新版本运行。 对于某些网络,使用 4096 的批处理大小可能会导致 DLA 的准确度下降。
- 使用 DLA 时,元素级、一元级或激活层紧接着缩放层可能会导致 INT8模式下的准确度下降。请注意,这是一个在以前的版本中也发现的预先存在的问题,而不是回归问题。
- 使用 DLA 时,INT8 卷积后跟 FP16 层可能会导致准确度下降。在这种情况下,请将卷积更改为 FP16 或将后续层更改为 INT8。 使用算法选择器 API 时,HWC1 和 HWC4 DLA 格式均报告为 TensorFormat::kDLA_HWC4。
- 对于基于 Transformer 解码器的模型(例如 GPT2),序列长度为动态,与以前的版本相比,TensorRT 8.5 需要额外的工作空间(最多 2 倍)。
- 对于某些 QAT 模型,如果卷积和逐点融合导致多输出层中的一些输出张量量化,而其他输出张量未量化,则引擎构建可能会失败,并显示以下错误消息
[E] Error[2]: [optimizer.cpp::filterQDQFormats::4422] Error Code 2: Internal Error (Assertion !n->candidateRequirements.empty() failed. All of the candidates were removed, which points to the node being incorrectly marked as an int8 node.
一种解决方法是禁用 kJIT_CONVOLUTIONS 策略源。
- 对于某些 QAT 模型,当启用 FP16 并创建外部节点时,如果张量是外部节点的输出,并且同时作为外部节点子图内另一个节点的输入,则
TensorRT 可能会针对该节点报告以下消息的错误:
[W] [TRT] Skipping tactic 0x0000000000000000 due to Myelin error: Concat operation "XXX" has different types of operands.一种解决方法是在张量和外部节点内的节点之间插入一个转换节点。
性能
1.在 Windows 系统上,对于 BERT 网络,NVIDIA Ampere 架构 GPU 的性能下降了约 12%。
2.在 Arm 服务器基础系统架构 (SBSA) 上运行实例规范化层时存在已知的性能问题。
在使用 CUDA 10.2 的 NVIDIA Volta 或 NVIDIA Turing GPU 上以 FP32 精度运行时,Jasper 网络的性能与 TensorRT 8.2 相比下降了高达 22%。如果改用 CUDA 11.x,则可以避免这种性能下降。
在使用 CUDA 10.2 的 NVIDIA Volta GPU 上以 FP32 精度运行时,InceptionV4 网络的性能与 TensorRT 8.2 相比下降了高达 5%。如果改用 CUDA 11.x,则可以避免这种性能下降。
在 T4 上启用 FP16 和 INT8 精度运行时,BART 的性能与 TensorRT 8.2 相比下降了高达 27%。可以通过禁用 INT8 精度标志来修复此性能下降。
由于 InstanceNormalization 插件中的 cuDNN 回归,在 NVIDIA Ampere 架构 GPU 上以 FP16 精度运行时,与 TensorRT 8.2 相比,SegResNet 网络的性能下降高达 10%。这将在未来的 TensorRT 版本中得到修复。您可以通过将 cuDNN 版本恢复为 cuDNN 8.2.1 来解决回归问题。
与在 GPU 上运行该层相比,在 NVIDIA Orin 上将 SoftMax 层卸载到 DLA 时性能会下降,并且批量大小越大,性能下降幅度越大。例如,与最后一个 SoftMax 层在 GPU 上运行时相比,当网络在 DLA 上运行时,批量大小为 16 的 FP16 AlexNet 下降了 32%。
对于某些 LSTM 网络,由于策略选择不稳定,从同一网络构建的不同引擎之间的性能差异高达 20%。
由于 NVIDIA Orin 和 Xavier 之间的 DLA 硬件规格差异,与在 Xavier 上运行相比,在 NVIDIA Orin 上运行涉及卷积(包括反卷积、全连接和连接)的 DLA FP16 操作时,预计延迟会相对增加。在相同的 DLA 时钟和内存带宽下,NVIDIA Orin 上的 INT8 卷积操作预计比 Xavier 快 4 倍左右,而 NVIDIA Orin 上的 FP16 卷积操作预计比 Xavier 慢 40% 左右。
DLA 时钟存在一个已知问题,要求用户在更改 nvpmodel 电源模式后重新启动系统,否则会遇到性能下降。有关详细信息,请参阅 L4T 板支持包发行说明。
对于基于变压器的网络(例如 BERT 和 GPT),TensorRT 在编译期间最多可以消耗模型大小 10 倍的 CPU 内存。
在 NVIDIA Turing GPU 上,BS=1 时的 DeepASR 网络性能下降幅度高达 17%。
与 NVIDIA Jetson AGX Xavier™ 上的 TensorRT 8.0.1.6 相比,FP16 模式下 ResNeXt 网络的性能下降幅度高达 7.5%。
与 TensorRT 7.2.3 相比,Xavier 上 FP16 中批处理大小为 2 的 ResNet-152 的性能下降幅度高达 10-11%。
与 TensorRT 7.2.3 相比,P100 和 V100 上带有 CUDA 11.3 的 DenseNet 的性能下降幅度高达 40%。CUDA 11.0 不存在这种下降。(不适用于 Jetson 平台)
在 Xavier 上,DLA 会自动将 INT8 LeakyRelu 层升级到 FP16 以保持准确性。因此,与使用不同激活(如 ReLU)的等效网络相比,延迟可能会更差。为了缓解这种情况,您可以禁用 LeakyReLU 层在 DLA 上运行。
与仅在 DLA 上运行相比,在 Xavier 平台上与其他 DLA 和 iGPU 并行运行某些 ConvNets 时,性能下降高达 126%。
对于使用稀疏性的 FP16 精度网络,性能下降高达 5%。
在 Volta GPU 上,在 CUDA 11.8 和 CUDA 10.2 之间,批量大小 = 1 时,Megatron 网络在 FP32 精度下的性能下降高达 5%。这种性能下降不会发生在 Turing 或更高版本的 GPU 上。
对于 TF32 精度的一些 ConvNets 的 H100 性能尚未完全优化。这将在未来的 TensorRT 版本中得到改进。
与 NVIDIA Volta GPU 上的 TensorRT 8.4 相比,在批次大小 = 1 的情况下,ResNeXt-50 QAT 网络在 INT8、FP16 和 FP32 精度下的性能下降高达 6%。
一些 Transformer 在 FP16 精度下的 H100 性能尚未完全优化。这将在未来的 TensorRT 版本中得到改进。
一些包含深度卷积的 ConvNets(如 QuartzNets 和 EfficientDet-D0)在 INT8 精度下的 H100 性能尚未完全优化。这将在未来的 TensorRT 版本中得到改进。
一些 LSTM 在 FP16 精度下的 H100 性能尚未完全优化。这将在未来的 TensorRT 版本中得到改进。
一些 3DUnets 的 H100 性能尚未完全优化。这将在未来的 TensorRT 版本中得到改进。
与 NVIDIA Ampere 架构 GPU 上的 TensorRT 8.4 相比,OpenRoadNet 网络在 TF32 精度下的性能下降幅度高达 6%。
T5 网络在 FP32 精度下的性能下降幅度高达 6%