目录
一、需求分析
二、方案设计(概要/详细)
三、技术选型
四、OCR 测试 Demo
五、批量文件识别完整代码实现
六、总结
一、需求分析
市场部同事进行采购或给客户报价时,往往基于过往采购合同数据,给出现在采购或报价的金额区间,现需要整合过往已有合同数据进行录入,以Excel 表格形式,方便市场部同事查找和计算。
二、方案设计(概要/详细)
由于合同文件数据类型多样,格式复杂(样式不固定,且不是单纯的文本文字)于是在数据录入过程中需要进行如下几步操作:
- 数据分类
如果一个PDF包含图像,通常是由扫描仪或者拍照设备生成的PDF。遍历所有的文件判断每一页是否含有图像。把所有文件分成两类,有图(扫描或拍照生成的PDF)或无图(Word转PDF)
- 数据清洗刷选,校准
a.对于格式相对固定的Word转PDF文件,将数据可以全部获取,使用模板匹配提取关键字段(如采购名称、数量、价格、日期等)。在按照关键词(金额,时间等)匹配,并写道Excel A中,并对得到的数据内容进行验证校准。
b.扫描或拍照生成的PDF,使用OCR光学识别,将PDF页面转化成图片,然后再识别图片内容,进行关键词匹配并写道Excel B中,并对得到的数据内容进行验证校准。
- 数据整合
设计好最终需要的Excel要有哪些字段,然后将Excel A 和 Excel B 按照时间排序归并到最终的Excel中 (所有的数据按照时间都存到一个sheet中,方便后期直接查询)
三、技术选型
由于要用到一些数据处理上的方法,使用 Python 会简单一点 ,同时这只是一个简单的需求,不算是一个正规的项目,应该越快越简单越好 Python 作为脚本语言是很好的选择 ,于是采用的技术栈就是 Python + OCR
四、OCR 测试 Demo
import pytesseract
import codecs
from PIL import Imageif __name__ == '__main__':# 指定 Tesseract 安装路径pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'im = Image.open('./test.png')result = pytesseract.image_to_string(im, lang='chi_sim')print(result)# 首先导入codecs库,用codecs.open()方法创建并打开一个名为output.txt的文件,以utf-8编码模式写入resultwith codecs.open('output.txt', 'w', encoding='utf-8') as f:f.write(result)这种方式只能识别简单的图片文本内容,但是对于拍照,扫描版,以及图片中含有表格的形式,都无法识别。

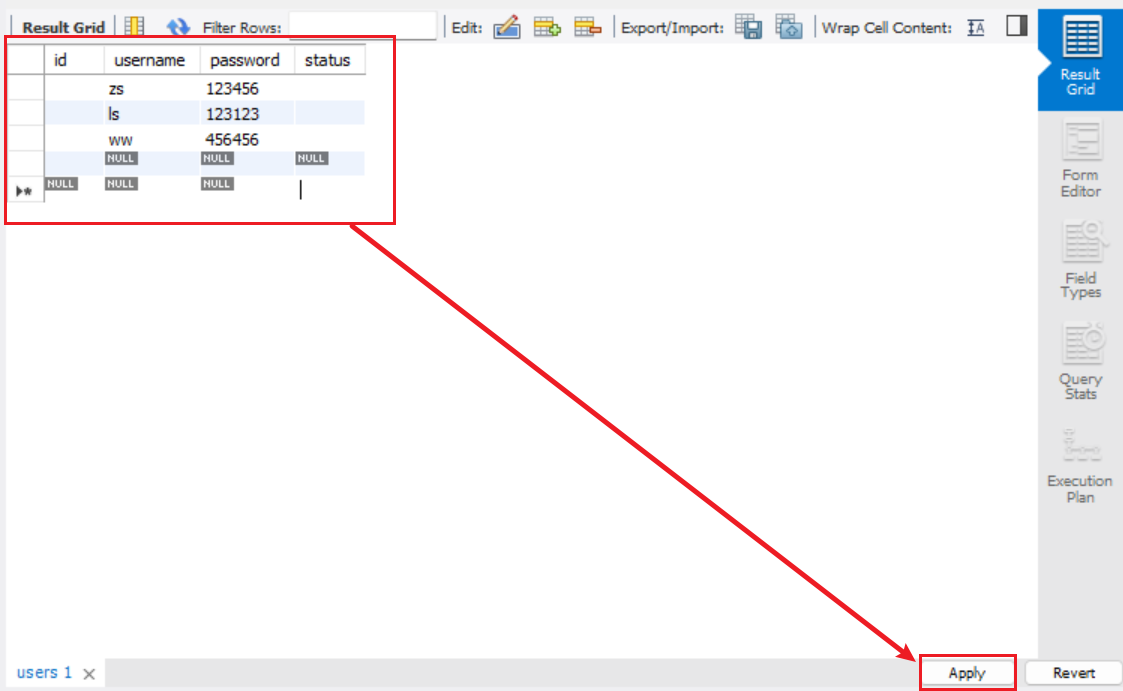
识别结果

于是更换思路,自己实现OCR难度较大且识别效果不好,经过调研之后,发现GitHub 上有一个开源的OCR 识别工具,可以直接调用里面的API接口,不用自己写OCR 识别方法了。
Umi-OCR总结有几大特点:免费、方便、高效、灵活 支持繁中、英语、日语等语言,使用不同的识别引擎就能识别不同种类的文字,并且给开发者提供Http服务,使用api的方式,让不同的编程语言都调用接口。
Release Umi-OCR v2.1.4 · hiroi-sora/Umi-OCR
下面给出安装包的下载地址
Release Umi-OCR v2.1.4 · hiroi-sora/Umi-OCR
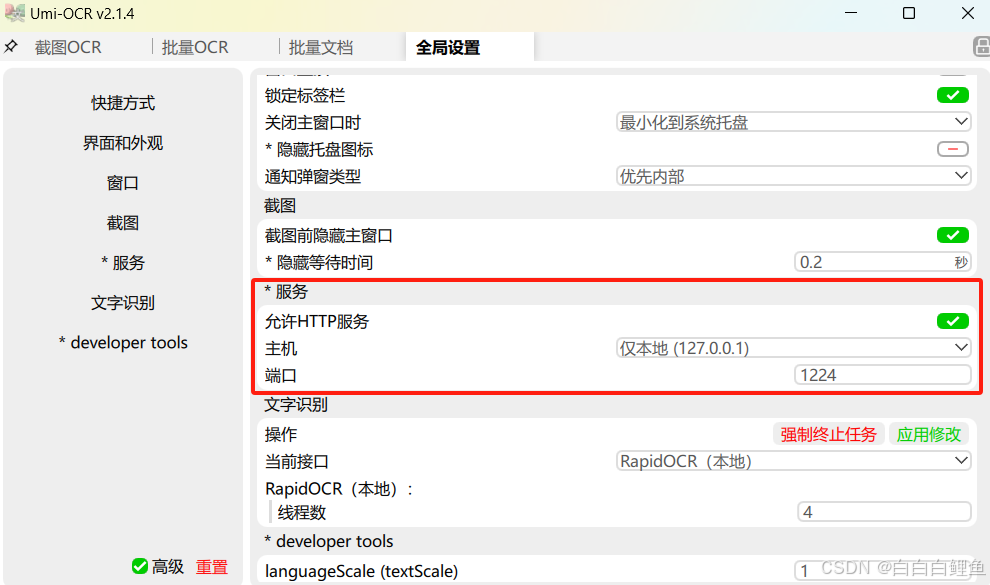
测试结果:
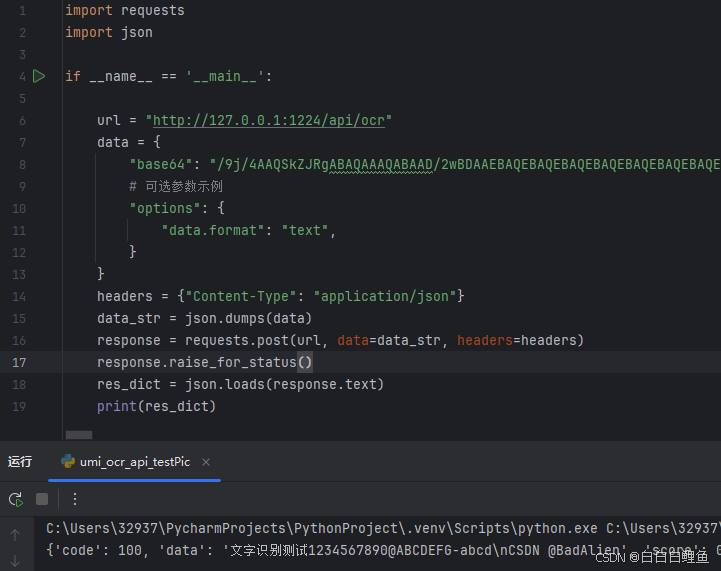
说明:在测试的时候,OCR工具记得打开,否则连接不上

五、批量文件识别完整代码实现
import requests
import json
import openpyxl
import os
import base64
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from PIL import Image
from io import BytesIO
from openpyxl import Workbook
from openpyxl.drawing.image import Image as ExcelImage
import fitz # PyMuPDF# compress_image 功能:压缩图片,确保其文件大小不超过指定的最大值。 参数:image_path (str): 图片文件的路径。 max_size_kb (int, 默认值 1024): 图片的最大文件大小(单位:KB)。
# 逻辑:
# 打开图片并获取其 EXIF 信息。
# 获取原始图片的尺寸。
# 使用循环尝试不同的质量参数,直到文件大小小于或等于 max_size_kb 或质量参数降到 10 以下。
# 保存压缩后的图片,确保其尺寸与原始图片一致。
# 返回压缩后的图片对象。def compress_image(image_path, max_size_kb=1024):print("进入压缩方法")# 打开图片img = Image.open(image_path)# 保留图片的 EXIF 信息exif_data = img.info.get('exif', None)# 获取原始图片的尺寸original_size = img.size# 尝试不同的质量参数,直到文件大小小于或等于 max_size_kbquality = 95while True:# 保存压缩后的图片,保留 EXIF 信息img.save(image_path, format=img.format, optimize=True, quality=quality, exif=exif_data)# 检查文件大小file_size_kb = os.path.getsize(image_path) / 1024if file_size_kb <= max_size_kb or quality <= 10:break# 降低质量参数quality -= 5# 确保压缩后的图片尺寸与原始图片一致img = Image.open(image_path)if img.size != original_size:img = img.resize(original_size)img.save(image_path, format=img.format, optimize=True, quality=quality, exif=exif_data)print(f"图片压缩完成,文件大小: {file_size_kb:.2f} KB")return img # 返回压缩后的图片对象# post_url 功能:发送 POST 请求到 OCR API,并将结果写入 Excel 文件。 参数: base64_strings (list): 图片的 Base64 编码字符串列表。excel_file_path (str): Excel 文件的路径。file_name (str): 文件名。imgs (list): 图片对象列表。
# 逻辑:
# 构建请求数据,包括 Base64 编码的图片字符串和选项。
# 设置请求头和重试策略。
# 发送 POST 请求到指定 URL。
# 解析响应数据并将其写入 Excel 文件的相应单元格。
# 调用 insert_images_into_excel 方法将图片插入到 Excel 文件中。
# 保存 Excel 文件。
# 处理请求异常并打印错误信息。def post_url(base64_strings, excel_file_path, file_name, imgs):url = "http://127.0.0.1:1224/api/ocr"data = {"base64": base64_strings[0],"options": {"data.format": "text",}}headers = {"Content-Type": "application/json"}data_str = json.dumps(data)session = requests.Session()retries = Retry(total=4, backoff_factor=2, status_forcelist=[502, 503, 504])session.mount('http://', HTTPAdapter(max_retries=retries))try:response = session.post(url, data=data_str, headers=headers, timeout=100)response.raise_for_status()res_dict = json.loads(response.text)# 写入 Excelworkbook = openpyxl.load_workbook(excel_file_path)sheet = workbook['Sheet']row = sheet.max_row + 1base_name = os.path.splitext(file_name)[0] # 去掉文件后缀sheet[f'A{row}'] = base_name # 文件名放在第一列sheet[f'B{row}'] = res_dict.get('data', '') # 文件内容放在第二列# 插入图片insert_images_into_excel(sheet, row, imgs)# 保存工作簿workbook.save(excel_file_path)except requests.exceptions.RequestException as e:print(f"请求失败: {e}")print(f'post_url 方法调用完成!文件: {file_name}')# insert_images_into_excel 功能:将图片插入到 Excel 工作表中。 参数: sheet (openpyxl.worksheet.worksheet.Worksheet): Excel 工作表对象。 row (int): 插入图片的行号。 imgs (list): 图片对象列表。
# 逻辑:
# 初始化列索引为 3(即 C 列)。
# 遍历图片对象列表,生成正确的列名。
# 将图片对象插入到指定的单元格。
# 更新列索引以插入下一张图片。def insert_images_into_excel(sheet, row, imgs):col = 3 # 从 C 列开始for img in imgs:# 生成正确的列名col_letter = openpyxl.utils.get_column_letter(col)img_path = f"{col_letter}{row}"img_obj = ExcelImage(img)sheet.add_image(img_obj, img_path)col += 1# fix_pic_file 功能:处理图片文件,包括压缩和 Base64 编码。 参数:image_path (str): 图片文件的路径。
# 逻辑:
# 判断文件大小,如果超过 1MB,则调用 compress_image 方法进行压缩。
# 打开图片文件并读取其内容,进行 Base64 编码。
# 去掉 Base64 编码头部(如果存在)。
# 返回 Base64 编码字符串和图片对象。def fix_pic_file(image_path):# 判断文件大小file_size_kb = os.path.getsize(image_path) / 1024if file_size_kb > 1024: # 1MB# 压缩图片img = compress_image(image_path)else:img = Image.open(image_path)with open(image_path, "rb") as image_file:encoded_string = base64.b64encode(image_file.read()).decode('utf-8')# 去掉 base64 编码头部if encoded_string.startswith('data:image/png;base64,'):encoded_string = encoded_string.replace('data:image/png;base64,', '')elif encoded_string.startswith('data:image/jpg;base64,'):encoded_string = encoded_string.replace('data:image/jpg;base64,', '')print(f'fix_pic_file 方法调用完成!文件: {os.path.basename(image_path)}')return encoded_string, img# 功能:将 PDF 文件转换为图片文件。 参数:pdf_path (str): PDF 文件的路径 ; output_folder (str): 输出图片文件的目录。
# 逻辑:
# 打开 PDF 文件。
# 遍历每一页,将其转换为图片并保存到指定目录。
# 返回图片文件路径列表和 PDF 文件的基本名称。def convert_pdf_to_image(pdf_path, output_folder):# 打开 PDF 文件pdf_document = fitz.open(pdf_path)base_name = os.path.splitext(os.path.basename(pdf_path))[0]images = []for page_num in range(len(pdf_document)):page = pdf_document.load_page(page_num)pix = page.get_pixmap()img_path = os.path.join(output_folder, f"{base_name}_page_{page_num + 1}.png")pix.save(img_path)images.append(img_path)return images, base_name# 功能:批量处理指定文件夹中的图片和 PDF 文件。 参数:folder_path (str): 包含图片和 PDF 文件的文件夹路径 ; excel_file_path (str): Excel 文件的路径。# 逻辑:获取文件夹中所有符合条件的文件(PNG、JPG、JPEG、PDF)。
# 遍历每个文件:
# 如果是 PDF 文件,调用 convert_pdf_to_image 方法将其转换为图片。
# 对每张图片调用 fix_pic_file 方法进行处理,获取 Base64 编码字符串和图片对象。
# 调用 post_url 方法将处理结果写入 Excel 文件。
# 如果是图片文件,直接调用 fix_pic_file 和 post_url 方法进行处理。def batch_process(folder_path, excel_file_path):files = [f for f in os.listdir(folder_path) if f.endswith(('.png', '.jpg', '.jpeg', '.pdf'))]for file in files:file_path = os.path.join(folder_path, file)if file.endswith('.pdf'):# 转换 PDF 为图片images, base_name = convert_pdf_to_image(file_path, folder_path)base64_strings = []compressed_imgs = []for img_path in images:base64_string, img = fix_pic_file(img_path)base64_strings.append(base64_string)compressed_imgs.append(img)post_url(base64_strings, excel_file_path, base_name, compressed_imgs)else:base64_string, img = fix_pic_file(file_path)post_url([base64_string], excel_file_path, file, [img])# 批量处理指定文件夹中的 图片和 PDF 文件,通过 OCR API 获取文本内容,并将结果写入 Excel 文件中(同时,处理过程中会对图片进行压缩和 Base64 编码)# 1、指定文件夹路径和 Excel 文件路径。
# 2、如果 Excel 文件不存在,创建一个新的 Excel 文件。
# 3、调用 batch_process 方法批量处理文件夹中的图片和 PDF 文件。
# 4、打印处理结束信息。if __name__ == '__main__':# 指定文件夹路径和 Excel 文件路径folder_path = 'D:\\ssproject\\ssprice'excel_file_path = 'D:\\ssproject\\ssprice\\excel.xlsx'# 创建 Excel 文件(如果不存在)if not os.path.exists(excel_file_path):workbook = Workbook()workbook.save(excel_file_path)# 批量处理图片batch_process(folder_path, excel_file_path)print('处理结束!')六、总结
当然,以上只是根据实际情况简单实现了一下后端数据录入的工作,要实现数据闭环还需要匹配对应的文件上传功能以及前端页面展示,在此不给予展示实现过程。