🏆 作者简介:席万里
⚡ 个人网站:https://dahua.bloggo.chat/
✍️ 一名后端开发小趴菜,同时略懂Vue与React前端技术,也了解一点微信小程序开发。
🍻 对计算机充满兴趣,愿意并且希望学习更多的技术,接触更多的大神,提高自己的编程思维和解决问题的能力。
如果本篇文章对友友你有所帮助,那还请点个小赞赞~
文章目录
- 谁为影狂-豆瓣数据【数据获取与预处理课设】
- 1.数据获取可行性及需求分析
- 1.1 课题背景
- 1.2 目的和意义
- 1.3 主要研究内容
- 1.4 课程设计创新点概述
- 2.核心算法
- 2.1 算法描述
- 2.2 问题总结
- 4.详细设计
- 4.1 流程图
- 4.2 代码
- 4.3 效果展示
- 5. 总结
谁为影狂-豆瓣数据【数据获取与预处理课设】
1.数据获取可行性及需求分析
1.1 课题背景
《数据获取与预处理》是一门实践性较强的软件基础课程,为了学好这门课程,必须在掌握理论知识的同时,加强上机实践,也要加强同其他学科的关联。本课程设计的目的就是要达到理论与实际应用相结合,使同学们能够根据特定的案列,学会分析爬取页面的方法,学会数据组织的方法,能把现实世界中的实际问题在计算机内部表示出来,能够运用数据获取与预处理的原理和方法解决简单的实际问题,逐步培养学生良好的程序设计能力。
1.2 目的和意义
(1)目的:从豆瓣top250上面获取的电影名称、导演和演员、评分、排名、图片等信息并保存下来
(2)意义:通过对电影数据的分析得出自己想要的信息。
1.3 主要研究内容
本文的主要研究内容包括下面两个部分。
(1)分析网页
对网页进行分析,寻找规律,获得想要的数据链接
(2)数据的提取与保存
对从网站中获取的信息进行分析,提取所需要的信息并把这些信息保存下来,并将部分信息做成折线图。
1.4 课程设计创新点概述
在实现时学到不同的方法读取和存储数据,实现按两种不同的xpath方法分别存电影封面图片和电影名称、导演和演员、评分、排名、简介等信息,对网页的分析更加详细。并对爬取的信息进行了处理,获取的数据信息更加简洁,看起来更轻松
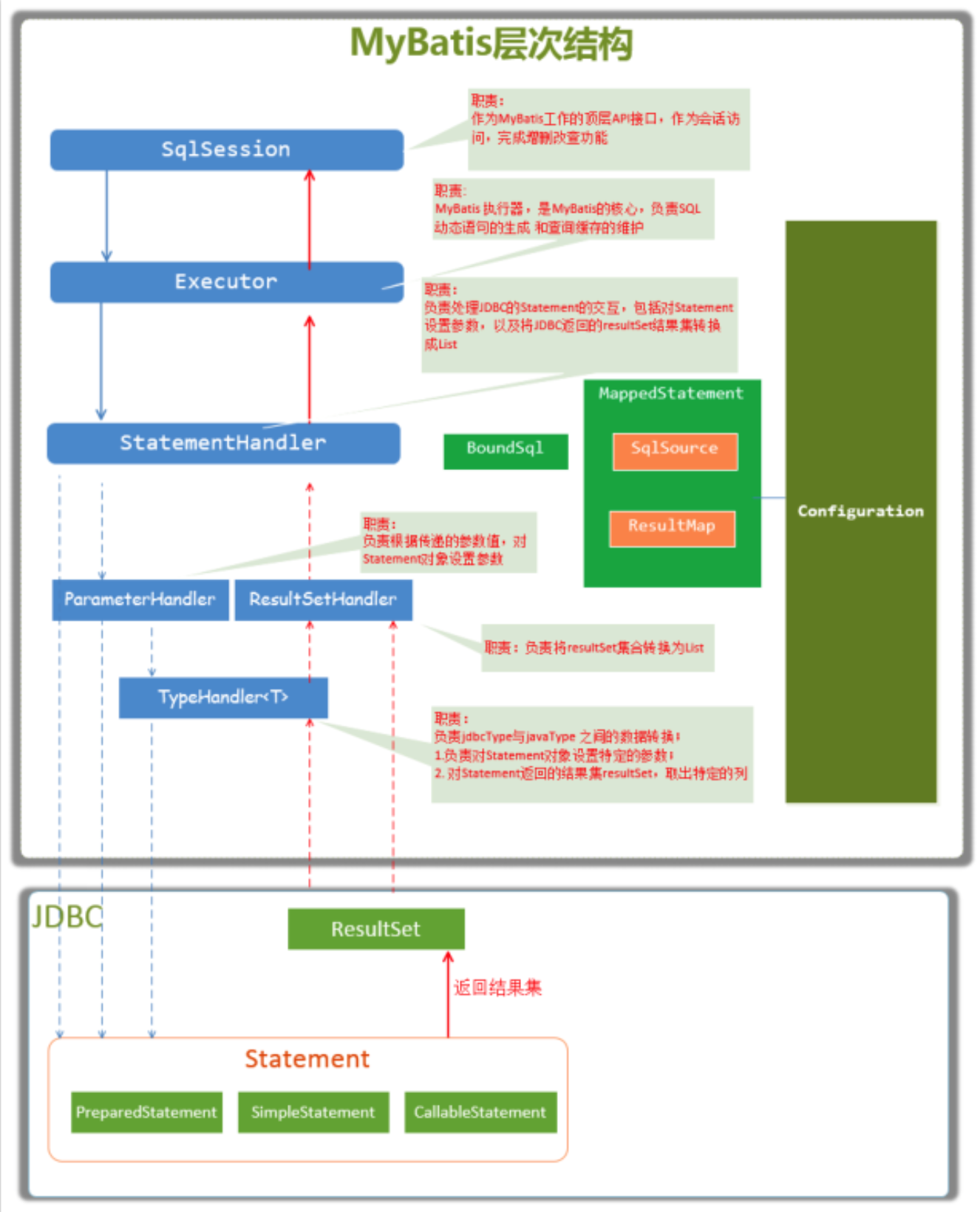
2.核心算法
2.1 算法描述
for start_num in range(0, 250, 25)
进行10次循环,每次读取25个电影的图片,信息,分步实现,可以方便查出程序问题,requests.get向网页发出请求。
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
后面用网页上分析复制下来的xpath获取对应数据
lis = html.xpath('//*[@id="content"]/div/div[1]/ol/li')
存放到文件和列表中,按列表前十绘制折线图
2.2 问题总结
代码量大,代码有部分太过于繁琐,对于折线图的绘制函数调用不是很合理,绘制图是在程序运行中实现,导致不关掉折线图就无法继续爬取数据。网络爬虫如果不严格控制网络采集的速度,会对被采集网站服务器造成很重的负担。恶意消耗别人网站的服务器资源,甚至是拖垮别人网站是一件不道德的事情。
本人承诺本次课题中爬取的数据都是公开数据,取得数据的手段合法,项目中爬取取得的所有数据仅供学习使用非商用,且没有对网站造成伤害
4.详细设计
首先根据url访问到电影网站页面,通过request请求访问到电影信息,调用读取电影封面函数读取电影封面和链接将网络上的内容下载到本地,保存在c盘的douban文件中,再调用获取电影信息函数读取电影名、导演和演员、评分、排名、简介等信息以及信息并把它们分别保存在豆瓣top250.csv文件中,以及把排行前10的电影评分和评价人数做成折线图。
4.1 流程图

4.2 代码
打开豆瓣网站右键鼠标选择检查,点击网络,在里面获得user-agent,再获取网页规律得出url,通过requests.get()函数赋值给response
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57"}
i = 0
for start_num in range(0, 250, 25):# 发起get请求:get方法会返回请求成功的响应对象response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers) # urltime.sleep(random.uniform(0.5, 1))img(response.text, start_num)massage(response, i)i = 1
存储图片函数,先对网页分析,再用etree.HTML()函数将字符串网页转换成_Element对象,再用列表存储电影信息,然后分别用title存放电影标题,img_url存放电影封面地址,再用urllib.request.urlretrieve方法将网上内容下载本地文件夹
element = html.etree.HTML(response)# 用response.text获取字符串格式的网页,用etree.HTML()可以将字符串格式的网页转换成_Element对象lis = element.xpath('//ol[@class="grid_view"]')[0]i = 1for li in lis:title = li.xpath('.//span[@class="title"]/text()')[0] # 获取影片标题img_url = li.xpath('.//img/@src')[0] # 获取封面地址#封面地址在img这个标签下的src属性中file_name = 'C:/douban/' + str(start_num + i) + '.' + title + '.jpg' # 点号能防止和名字粘在一起urllib.request.urlretrieve(img_url, filename=file_name) # 将网络上的文件下载到本地。该函数有两个必须的参数:第一个是文件的 URL 地址,第二个是本地文件的路径i += 1
绘制折线图函数,将列表中前10个电影名称,评分,评价人数按xy轴画折线图
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体,SimHei为黑体movies = movies[:10] # 取排名前十eval_num = eval_num[:10]rating = rating[:10]movies = movies[::-1]#切片eval_num = eval_num[::-1]rating = rating[::-1]fig, ax1 = plt.subplots() #返回一个包含一个 Axes 对象的 tuple,Axes 对象被赋值给了变量 ax1fig.set_size_inches(10, 7) # 设置画布的尺寸ax2 = ax1.twinx() ax1.plot(movies, eval_num, color='blue', label='评价数', marker='o')ax1.set_xlabel('电影名称', fontsize=16) # 设置x轴标签的文本内容#字体高度ax1.set_ylabel('评价数', color='blue', fontsize=16) # 设置y轴标签的文本内容ax1.tick_params(axis='y', labelcolor='blue') # axis='y' 表示设置y轴的刻度线和刻度标签ax1.legend(loc='upper left') # 将标签的位置设置在画布顶部中央ax2.plot(movies, rating, color='red', label='评分', marker='^')ax2.set_ylabel('评分', color='red', fontsize=16) # 设置y轴标签的文本内容ax2.tick_params(axis='y', labelcolor='red')ax2.spines['right'].set_position(('axes', 1))ax2.legend(loc='upper center')plt.title('电影评价数及评分折线图', fontsize=18) # 设置标题plt.show()
调用存储电影信息文件,在网页选择整个电影,获取html.xpath,再用相同的方法,获取电影名、导演和演员、评分、排名、简介等信息的xpath,在程序中处理得到我们想要的数据并打印,然后存入豆瓣top250.csv文件,下方调用函数绘制折线图。
html = etree.HTML(res.text)lis = html.xpath('//*[@id="content"]/div/div[1]/ol/li') # 整个电影的信息movies = [] # 电影名称列表eval_num = [] # 评价数列表rating = [] # 评分列表for li in lis:title = li.xpath(' ./ div / div[2] / div[1] / a / span[1]/text()')[0]link = li.xpath('./div/div[2]/div[1]/a/@href')[0] # href超链接director = li.xpath('./div/div[2]/div[2]/p[1]/text()')[0].strip() score = li.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0] peonum = li.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]intd = getintd(li) # 有些电影没有简介返回空列表报错:list index out of rangeprint(title, link)print(director)print('评分:', score)print('评价人数:', ''.join(filter(str.isdigit, peonum))) # 只保留数字print('简介:', intd)movies.append(title)eval_num.append(''.join(filter(str.isdigit, peonum)))rating.append(score)with open("./豆瓣top250.csv.", 'a', newline="", encoding='utf-8-sig') as fp: writer = csv.writer(fp)writer.writerow((title, link, director, score, peonum, intd))if i == 0:movie_visual(movies, eval_num, rating)
4.3 效果展示



5. 总结
在这次数据获取与预处理实训中,我学到了对request库的运用,以及Python中调用各种库的便利,同时也加强了我通过使用lxml中etree对爬取到的数据进行Xpath解析的运用。也学会了分析爬取页面的方法以及数据提取的方法。对于爬虫这项技术我表现出很大的热情,我觉得这项技术非常实在有用,当然我们也不能违背法律,要合理运营爬虫。
注:本人承诺本次课题中爬取的数据都是公开数据,取得数据的手段合法,项目中爬取取得的所有数据仅供学习使用非商用,且没有对网站造成伤害 。