本推文详细介绍了一篇上海交通大学乐心怡老师课题组被人工智能顶级会议AAAI 2025录用的的最新论文《SAIL: Sample-Centric In-Context Learning for Document Information Extraction》。论文的第一作者为张金钰。该论文提出了一种无需训练的、以样本为中心的、基于上下文学习的文档信息抽取方法 (SAmple-Centric In-Context Learning for Document Information Extraction,简称SAIL)。该方法为每个测试样本定制个性化提示词,同时引入布局相似性和实体级文本相似性来增加搜索多样化。SAIL的性能优于之前的无训练方法,并且性能接近全监督学习的方法。更为重要的是,SAIL具有良好的泛化性。
本推文由张金钰撰写,审核为乐心怡老师。
原文链接:https://arxiv.org/abs/2412.17092
代码链接:https://github.com/sky-goldfish/SAIL
1. 会议介绍

第39届AAAI (Annual AAAI Conference on Artificial Intelligence)将于2025年2月25日至3月4日在美国费城隆重举行。AAAI会议起始于 1980 年,是人工智能领域久负盛名且极具影响力的国际顶级学术会议之一,由美国人工智能协会主办。该会议全面覆盖机器学习、自然语言处理、计算机视觉、机器人技术、多智能体系统、知识表示与推理等多项人工智能核心研究领域。AAAI是人工智能领域的顶级会议之一,也是中国计算机学会(CCF)A类会议。
原文链接:https://arxiv.org/abs/2412.17092
代码链接:https://github.com/sky-goldfish/SAIL
2. 研究背景及主要贡献
(1)什么是文档信息抽取?
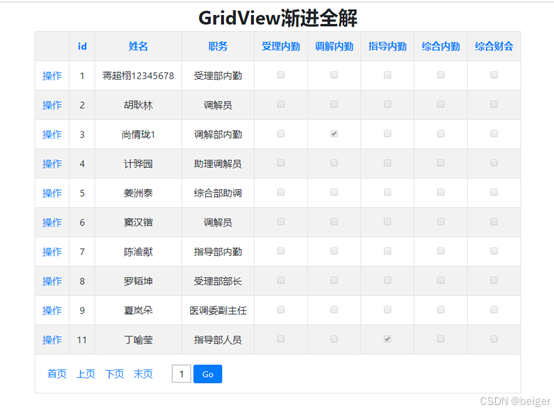
文档信息抽取旨在从文档中(如收据、表格、发票等)中提取结构化信息。如图1,对一个小票文档,通常需要识别出小票号、各类商品单价、各类商品数量、各类商品价格、总价等信息。

图1 文档信息抽取任务
解决文档信息抽取的传统方法往往基于全训练学习(如 LayoutLMv3 等)。这些方法在训练数据上表现良好,但在处理未见过的数据时泛化能力有限。因此,研发无需训练的文档信息抽取方法,且使其具备良好的泛化能力,这非常关键。一种可行的思路是利用强大的预训练模型(如大语言模型 LLMs),仅需少量示例即可泛化到不同类型的文档。
(2)挑战与困难
无训练的文档信息抽取方法主要面临两个挑战:
(1)文档内容十分复杂,需要很好地理解文本与布局之间的关系。但是,仅通过少量的示例建立文本与布局之间的关系并提取隐含布局信息非常困难。
(2)预训练模型需要合适的提示词才能发挥最佳性能。之前工作的提示词是针对特定预训练模型特殊设计的,导致在不同模型间转换时性能会显著下降。
(3)本文的解决办法
本文提出了一种以样本为中心的基于上下文学习的文档信息抽取方法SAIL。其贡献可以概括为:
(1)提出了一种以样本为中心的提示词方法,针对每一个测试样本,都会搜索最合适的示例作为上下文学习的提示词。
(2)在搜索最合适的示例时,引入布局相似性(下图中的layout similarity)和实体级文本相似性(下图中的entity-level text similarity),从不同角度对视觉丰富的文档进行全面深入分析,有助于提升大语言模型对文档的理解能力。
(3)构造了规范统一的提示词模板,可以在不同的大语言模型之间实现较好的迁移。

图2 SAIL中使用的三种示例及和GPT-4o结果的对比
3. 方法

图3 SAIL的整体架构
SAIL的整体架构如图3所示。主要包括五个步骤:
(1)通过光学字符识别处理测试文档和训练文档,提取文本和边框(box)信息。
(2)将文本转换为不同类型的嵌入表示,用于选择文档级文本相似性示例、实体级文本相似示例和布局相似示例。
(3)选择示例。
(4)将示例代入提示词模板。
(5)大语言模型根据提示词进行推理,生成预测标签。
其中,选择示例的三种方法如下:
(1)文档级文本相似示例:通过文本语义搜索,使用Sentence - BERT编码文档文本,计算余弦相似度来选择与测试样本最相似的训练文档示例。
(2)实体级文本相似示例:过滤掉仅含数字的文本后,用Sentence - BERT编码实体文本,计算余弦相似度,为每个测试实体选择最相似的实体示例。
(3)布局相似示例:将边框信息绘制在空白图像上,裁剪并调整布局图像大小,通过计算均方误差(MSE)损失来选择布局相似的文档,如图4所示。

图4 布局相似性评估方法
4. 实验
(1)实施细节
论文使用开源ChatGLM3(ChatGLM3-6b-32k),闭源GPT-3.5(GPT-3.5-turbo)和GPT-4(GPT-4o)三个大语言模型在FUNSD、CORD、SROIE数据集上评估。采用实体级F1分数、精确率和召回率作为评估指标。
(2)实验结果
实验的结果如表1所示。与Baseline的对比,SAIL体现出了更好的性能,具体体现在:
1)首先,SAIL在所有数据集上使用不同大语言模型的表现都稳定优于其他training-free的方法。
2)其次,得益于本文构造的规范统一的提示词模板,SAIL对各种大语言模型具有更好的鲁棒性和适应性。
3)最后,作为training-free的方法,SAIL甚至超越了很多全监督学习的方法。
表1 SAIL与Baseline的对比

在与多模态大语言模型对比方面,本文将SAIL与LLaVA-1.5和GPT-4o进行了对比,实验结果见表2。可以发现,开源的LLaVA的文档信息抽取能力比较有限。其次,闭源的GPT-4o明显优于LLaVA,但与SAIL相比仍然存在很大的不足。
表2 SAIL与多模态LLM的对比

(3)消融实验
表3对比了对所有测试样例都采用固定的examples(Fixed)、对不同的测试样例采用不同的examples(Adaptive)。结果表明,以样本为中心的examples显著超越了固定的examples。
表3 以样本为中心的Adaptive examples显著超越了Fixed examples

表4证明了我们在选择示例时,所采用的三种相似度(结构相似度、文档级别文本相似度、实体级别文本相似度)的有效性。
表4 不同相似度的examples的有效性

5. 总结与展望
论文提出了一种以样本为中心的基于上下文学习的文档信息抽取方法SAIL,用于training-free文档信息抽取任务。SAIL 利用布局相似性和实体级文本相似性与统一的提示词模板相结合,为每个测试样本构建定制化的提示词,使用不同LLM在三个数据集上均展现了优于基线的表现。
6. 更多信息
乐心怡老师本科就读于清华大学,博士毕业于香港中文大学,目前为上海交通大学自动化系副教授,主要研究基于大模型的工业感知方法及系统,个人主页为:https://automation.sjtu.edu.cn/LXY。
乐老师课题组计算资源充足,研究方向前沿。目前课题组紧急招收大模型和智能体方向科研实习生。前期工作已中稿NeurIPS 2024,希望进一步深化投稿期刊T-PAMI或IJCV。具体工作包括协助实现LLM Agent针对复杂任务的评测,包括LLM Agent应用需求调研、数据合成方法设计和主流LLM、VLM、Agent框架评测等。
对于具备如下条件的本科生,也非常欢迎加入:
1.计算机、AI、自动化、软件工程、信息工程等理工科背景本科生;
2.学有余力,能够投入较多时间(请在邮件中注明一周可以投入的时间);
3.熟练掌握python, pytorch等编程语言和编程框架,熟悉基本的软件工程编程规范,能阅读英文论文。
联系方式及方法:
请发送邮件至lene90525@gmail.com或lexinyi@sjtu.edu.cn,主题:科研实习_学校+年级+姓名,附上个人简历(学业情况、项目经历、科研经历等)