作者:品曲,宗雁,佀畅,侠雕,伟林
导读
一直以来,大模型在模型效果上被证明具有显著优势。而ChatGPT的出现,证明了其在工业生产工具方面具有巨大潜力。毫无疑问,大模型的训练需要巨大的算力,这对分布式并行框架是一项考验。现如今,业界越来越多的团队纷纷转向分布式框架的研究与开发之中,既有针对特定场景特定模型的极致手工优化,也包括面向通用模型通用场景的自动分布式工作。然而,它们在实际生产场景仍然有一些挑战。一方面,对于手工优化的框架,虽然其特定情况下的性能较为极致,但通用性存在限制。另一方面,现有的自动分布式框架可能在通用性和性能方面表现较好,但通常需要忍受较长的策略搜索时间,进而对业务落地产生一定的影响。为了应对以上问题,PAI 团队推出并开源了TePDist(Tensor Program Distributed System),它通过在HLO上做分布式策略搜索,实现与用户模型语言解耦。并且在保持通用性的同时,在可接受的策略搜索时间内,追求高性能分布式策略。
TePDist背后的技术框架如何设计?未来有哪些规划?今天一起来深入了解。
TePDist是什么?
TePDist是阿里云PAI团队自研的基于HLO IR层的全自动分布式深度学习系统,它不仅仅是一个分布式Compiler,还拥有自己的分布式Runtime,有效地解决了深度学习模型并行策略的自动搜索与分布式策略实施问题。
在架构方面,TePDist采用Client/Server模式,实现分布式策略与模型描述的解耦。Server端是TePDist最重要部分,它以HLO IR作为输入,自动探索并实施分布式并行策略;Client端以用户描述的模型为输入,将其转换成HLO IR。因此,任何具有转换HLO IR能力的Client,都可经过适配后接入Server端。
在功能方面,TePDist分为两个部分。一是在HLO IR上进行SPMD(Data Parallel和Sharding)和Pipeline并行的策略搜索。并以此构建编译基于Task Graph的执行计划。二是高效运行执行计划的分布式执行引擎。
在使用方面,TePDist提供了不同优化级别,高优化级别更加追求分布式策略质量,低优化级别会额外采取一些Heuristic,以较为微小策略质量牺牲,换取更快地搜索时间,以此满足落地需求。
项目开源地址:https://github.com/alibaba/TePDist
TePDist的主要特性如下:
- 一套完整的系统:采用Client/Server模式。Client可以是任何能够生成XLA HLO的前端。Server负责进行分布式策略规划,以及自动分布式任务拉起。Client与Server解耦的动机是期望将来更方便地对接不同的前端框架。
- 以HLO IR作为Server端输入:HLO的粒度刚刚好,目前看到的超大模型基本上有上万条HLO指令。在HLO这个层级做分布式策略规划,可以避免依赖灵活多变的模型高层次抽象,以不变应万变。
- 全自动探索分布式策略:TePDist支持在没有任何annotation的情况下做策略搜索。当然,用户也可以选择通过annotation进行一定程度的干预。
- 定义不同优化级别:用户可以选择使用O2和O3两个优化级别,用以控制策略搜索时间。它们均为Cost based策略搜索方法。其中O2级别采用了一定的Heuristic,会以牺牲轻微的并行策略质量为代价,换取更快地搜索时间,这对超大规模模型非常有用。O3级别对策略的质量有一定的保证。
- 合理拆解策略搜索问题:TePDist采用了多种手段,把策略探索问题拆解成优化子问题,运用多种算法,分别对子问题进行求解,有效管理了问题的复杂性。
- 具有特色的流水线并行规划:无需把DAG排成拓扑线性序,我们把stage划分建模成整数线性规划问题(ILP),使用ILP Solver自动寻找通讯量最小的切分方案。
TePDist架构
TePDist采用Client/Server分离的架构,将前端模型构建与后端策略搜索实施解耦。Server端分为两个过程:
- 编译(Build Execution Plan):在这个过程中会构建执行计划,包括:自动分布式策略的搜索,device mesh的分配,TepDist执行引擎的构建——Task Graph的构建以及为Task Graph确定静态调度顺序。架构和流程列于下图左图中;
- 运行(Execute Plan):编译阶段完成后,Client下达Input data供给指令,即可触发运行该Execution Plan的运行。为了追求高性能和高可控性,我们完全自研了TePDist的运行时,具体包含无损分布式初始化,分布式checkpoint,NCCL复杂通信域的管理,多worker协同管理,以及Task Graph级别的Memory reuse等。架构和流程列于下图右图中;

自动分布式策略搜索
自动分布式是TePDist核心功能之一,我们对SPMD策略的搜索空间做了合理的分层拆解,在不同的层级使用不同的算法。同时对用户提供不同优化级别,用以控制策略搜索的时间。对Pipeline stage划分则无需对DAG按照线性排序,然后使用ILP对其stage的划分进行建模,同时也为用户提供了用于控制搜索时间的剪枝参数。以下对这部分内容做简单的描述,技术的具体细节请参考我们的论文:(TODO)
SPMD Strategy
由于HLO指令数较多,直接使用ILP建模求解可能会因问题规模过大,导致搜索时间过长。显然,通过缩图可以减小问题求解的规模。为此,TePDist将DAG划分为了三个层级,并对每层使用不同的优化方法进行求解。

- Cone结构
HLO DAG中存在大量的Cone结构,它对我们的Formulation非常重要。什么是Cone结构?它是包含两种节点的子图:Root节点和非Root节点。其中,Root节点为具有多个输入或特征为计算密集型的节点;非Root节点为其他节点。我们可以在HLO的DAG中识别所有的Cone结构。大多数Cone结构都呈现出“倒三角”的形态,如上图中灰色三角区域标出的部分。显然,Cone代表更粗粒度的节点,我们的算法需要为每个Cone确定切分策略。每个Cone应该有多少种可能得切分策略?答案是取决于其Cone Root有多少种切分策略。具体做法:在Cone内,通过对Cone Root节点枚举的每种切分策略,我们都可以以通信代价最小为目标,通过贪心或动态规划方法求解Cone内剩余节点的切分策略。由此,我们可以得到该Cone的多种不同切分策略,这些策略都是每个Cone的候选策略。
- Segment
虽然Cone结构的粒度更粗,在一定程度上缩减了问题规模。但对大模型来说,Cone的数量依然巨大,可能需要进一步处理。事实上,大模型在结构方面具有重复堆叠的特征。这意味着每个模型可能可以划分为多个类似“layer”的结构,从而将大模型分而治之。为此,我们分析了PAI平台上运行的Workload,并总结了一种通用的分图处理方法。通过图分析识别图中所有的关键节点(Critical nodes),并以它们为分图间隔点,将整体模型划分为近似线性的多个Segment,如上图中标出的三个Segment,每个Segment都包含若干Cone结构。这里同样存在一个问题:每个Segment需要保留多少种候选策略?答案是取决于其包含的所有Critical nodes的切分策略数量组合。在做法上,通过对每个Critical node枚举切分策略,以其内部的Cone为基本单元,以最小通信代价为目标,使用整数线性规划(ILP)确定该segment的整体切分策略。
关于critical nodes的识别,可以参考我们论文中的描述。
- 整体Graph
Segment之间的近线性拓扑,天然适合动态规划求解。上述为每个Segment确定候选切分策略后,TePDist以最小通信代价为目标,使用动态规划(DP)对整体DAG完成确定唯一策略。
Pipeline Strategy
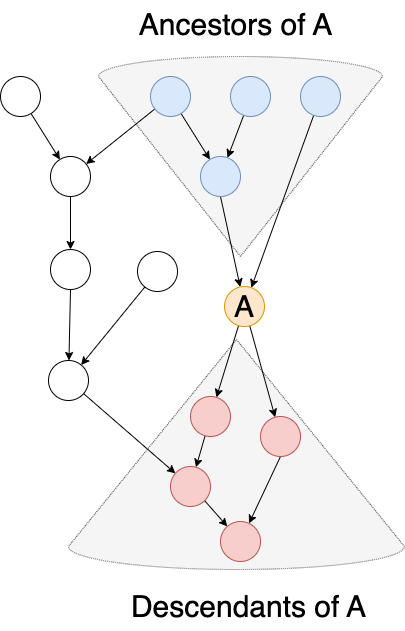
TePDist在划分Pipeline stage时的一大特点是不需要将DAG排成线性序列。并且,TePDist将Stage划分建模成整数线性规划(ILP)问题求解。划分的基本原则是尽量保证各个stage计算量均匀的情况下,追求最小的通信切面。因为,DAG中的每个节点都可以找到它的祖先节点和后继节点,这种前驱后继的依赖关系可以被描述成ILP问题的线性约束,如下图中蓝色和红色所示。在策略搜索时间的压缩方面,TePDist向用户提供了用于控制stage计算均匀性比率的控制接口。Pipeline建模的具体formulation可以参考我们的论文。
分布式执行引擎
TePDist自己定制了执行引擎,通过将HLO computation实例化并组织成Task Graph,且采用静态调度执行。
Task Graph
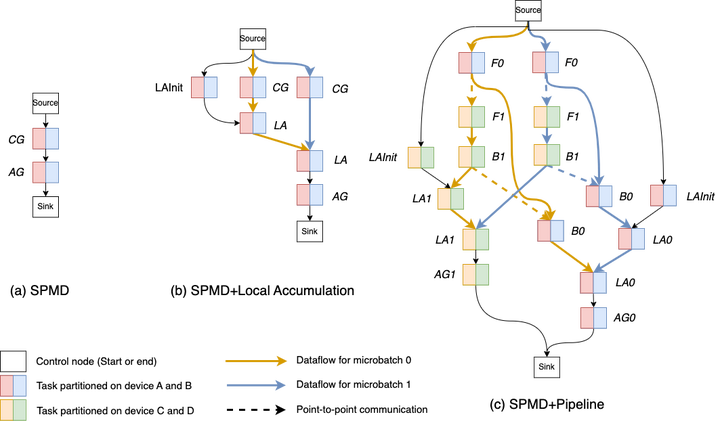
为了能够组合各种各样的并行模式,我们抽象了Task Graph。当将并行策略应用到HLO上时,被拆分或切分的多个HLO computation需要组合成完整的执行逻辑,为此我们抽象出了Task Graph,它由一系列具有连接关系的Task Node组成。在Task Graph中,我们约定Source和Sink为起始和终止节点,其他Task Node均为各种HLO computation的实例。举例说明,对含有Gradient Accumulation的训练任务,原始的HLO computation被切分为Compute Gradients、Gradient Accumulation和Apply Gradients三个部分。那么由此创建三种不同的Task Node,然后组合成完整的执行逻辑。下图展现了三种切分策略时,Task Graph的具体形态。
静态调度计划
在构建执行计划期间,TePDist在Task Graph上制定静态调度计划。相比于执行期通过动态调度执行Task Graph来说,静态调度具有更好的性能。一方面,静态调度在编译期间事先把调度顺序确定好,而动态调度十分依赖执行期的管控节点,从而可能因存在中心管理节点而成为性能瓶颈。但静态调度一经确定,每个worker就可以按部就班执行,对中心管控没有依赖。另一方面,静态调度会让显存使用呈现稳定状态。当执行Pipeline并行策略时,1F1B的调度策略能够使显存及时释放,从而降低峰值显存用量。而动态调度就不能保证完全呈现1F1B的调度顺序。
其他
在执行引擎方面,我们还做了如下工作:
- 分布式初始化
TePDist直接对Sharding Tensor的各个分片做初始化。为了保证切分后的初始化结果与切分前完全一致,应该给予不同分片于相同的初始化种子,但不同的随机数起始生成状态。在TePDist中,拥有C++层实现的Sharding Initializer,它可以在不同Tensor分片上,令随机数生成器Skip到正确的起始状态进行初始化,并且通过多线程为初始化过程并行加速,这对超大模型十分有用。
- 通过NcclContext管理复杂的通信域
复杂的分布式策略可能包含集合通信和点对点通信,而每次通信涉及到Device可能完全不同,这使得通信域的管理变得复杂。TePDist在首次运行开始前会对所有的通信指令和节点做一次收集,然后依次建立对应的通信域,并存入Cache中,以在适当的时机复用。
- Task Graph的执行
因为Task Graph是我们提出的新抽象,因此需要对Task Graph运行时做全面的管理,包括:
- Task Node的多线程异步Launch
- Input output alias
- Task Graph级别的垃圾回收机制
- 协调多机共同执行Task Graph
性能实验
我们在以下两个商用平台上对TePDist做了性能实验,所有实验均采用FP32进行。
- M8平台:8 * V100-SMX2-32GB GPU w/NVLink2, 2 * Xeon (Skylake) CPU 48C 2.5GHz, 768GB DDR4-2666, 1 * 100G RoCE interconnect.
- S1平台:1 * V100S-PCIE-32GB GPU, 2 * Xeon (Cascade Lake) 52C 2.5GHz, 512GB
DDR4-2666, 1 * 100G RoCE interconnect.
模型扩展实验
(表格格式根据平台需要修改,也可直接用图片)
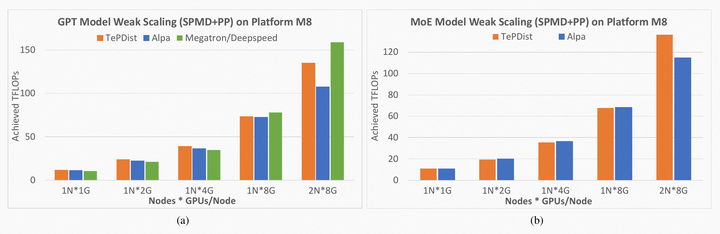
我们在GPT和MoE模型上做了SPMD+Pipeline混合策略的模型扩展性实验,并与Alpa和Megatron/DeepSpeed进行了对比。
下面两个表格列出了GPT和MoE的不同版本配置,参数量均逐行递增。
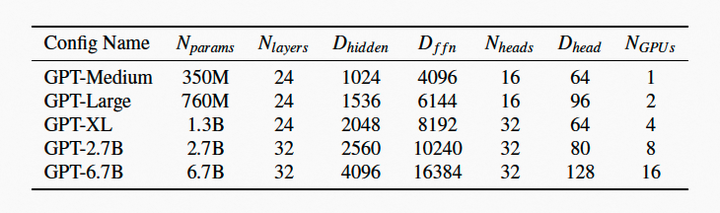
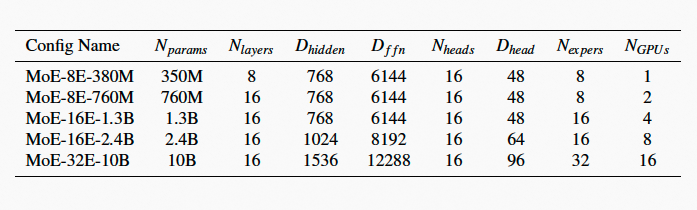
将统计的计算量(TFLOPS)作为扩展性衡量指标。在单机单卡到两机16卡的算力资源上逐步扩展模型,从实验表现看,GPT和MoE在扩展性上表现较好。单精度计算能力方面,V100的理想计算峰值为15.6TFLOPS。TePDist能够使GPT和MoE分别达到峰值能力的62%和58%,和自动分布式的框架Alpa相比,TePDist能够提供基本相当的性能,在某些情况下还会有性能提升。
通用性实验
我们还提供了其他模型的benchmark,来证明TePDist在自动化方面的通用表现。对VGG-19,DNABert和UNet模型做数据弱扩展实验。其中,将VGG-19的分类器扩展到百万分类级别,实验配置如下。

对Wide-ResNet模型做模型弱扩展实验,实验配置如下。
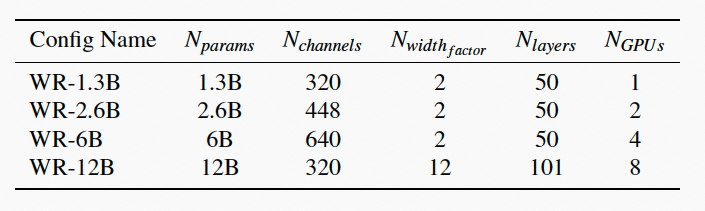
在M8平台上,TePDist均表现出接近理想线性加速比的性能。在VGG-19模型实验中,TePDist找到了将最后一层大规模分类器做模型并行的策略。

不同优化级别
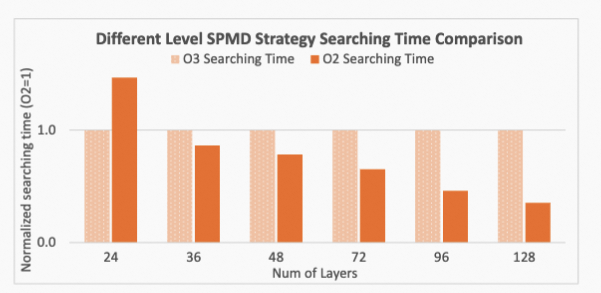
针对GPT-3模型,我们对比了SPMD两种优化级别下的策略搜索完成时间。O2级别表示带有Heuristic的三层搜索算法,O3表示不分层的搜索算法。实验表明,在小模型上,O2级别的优化由于三层的划分以及对每个层级多次使用ILP求解,在搜索效率上并不占优势。但随着模型的增大,其搜索效率显著提高。在超大模型上,O2级别的搜索表现出很大的优势。
RoadMap
后续我们计划定期优化TePDist系统,并不断完成产品化工作。
- 继续优化现有的执行引擎
- 支持更多样的并行策略
- 提供更丰富的前端支持
- 自动化显存优化技术
开源地址:https://github.com/alibaba/TePDist
希望各位感兴趣的开发者们加入我们,一起打造更快更好的自动分布式系统!
TePdist开源项目钉群