文章目录
- 前言
- 一、初识OCR技术
- 1.文字识别技术的概念
- 1.1 文字识别(OCR)介绍
- 1.2 文字识别(OCR)应用场景
- 2.文字识别技术的发展历程
- 2.1 OCR识别领域发展历程
- 2.1.1 西文OCR
- 2.1.1 Tesseract
- 2.1.3 LeNet
- 2.1.4 深度学习OCR
- 2.2 OCR识别流程历程
- 3.简要介绍文字定位与文字识别技术
- 3.1 文字定位
- 3.1 基于传统方法
- 3.2 基于深度学习
- 3.2.1 基于侯选框
- 3.2.2 基于分割
- 3.2.3 直接回归
- 二、华为云OCR服务介绍
- 1.简要介绍华为云OCR服务
- 1.1 通用类
- 1.2 证件类
- 1.3 票据类
- 1.4 行业类
- 1.5 定制类
- 2.华为云OCR服务的应用场景
- 2.1 身份验证场景
- 2.2 物流快递场景
- 2.2.1 快递员取件填写运单
- 2.2.2 提取运单信息存入系统
- 2.3 医疗保险理赔场景
- 2.4 汽车金融场景
- 2.5 互联网网络截图场景
- 2.5.1 电商图片
- 2.5.2 聊天截图
- 2.6 政法法院场景
- 2.7 财务报销场景
- 2.8 医疗化验单/检验单OCR识别场景
- 2.9 定制专属OCR服务接口:缅甸身份证OCR识别
- 3.华为云OCR服务定价
- 3.1 按需付费、阶梯收费
- 3.2 专属定制
- 三、华为云OCR使用指南
- 1.华为云OCR SDK开发指南
- 2.华为云OCR .NET SDK的使用
- 2.1 前提准备
- 2.2 安装对应语言的SDK
- 2.3 开始使用
- 2.3.1 导入依赖模块
- 2.3.2 配置客户端连接参数
- 2.3.2.1 默认配置
- 2.3.2.2 网络代理(可选)
- 2.3.2.3 超时配置(可选)
- 2.3.2.41 SSL配置(可选)
- 2.3.3 配置客户端连接参数
- 2.3.4 初始化客户端
- 2.3.4.1 指定云服务region方式(推荐)
- 2.3.4.2 指定云服务endpoint方式
- 2.3.5 发送请求并查看响应
- 2.3.6 异常处理
- 2.3.7 运行程序
- 2.3.7.1 华为云在线调用
- 2.3.7.1 代码调用
- 3.华为云OCR SDK的相关参考
- 2.华为云文字识别OCR服务操作指南
- 2.1 选择华为云文字识别OCR服务的理由
- 2.2 华为云文字识别Console介绍
- 2.2.1 进入Console页面
- 2.2.1.1 申请服务
- 2.2.1.2 服务支持场景及API调用计费标准
- 总结
前言
随着我国信息化建设的全面开展,OCR文字识别技术诞生20余年来,经历从实验室技术到产品的转变,已经进入行业应用开发的成熟阶段。相比发达国家的广泛应用情况,OCR文字识别技术在国内各行各业的应用还有着广阔的空间。随着国家信息化建设进入内容建设阶段,为OCR文字识别技术开创了一个全新的行业应用局面。
一、初识OCR技术
1.文字识别技术的概念
1.1 文字识别(OCR)介绍
文字识别:光学字符识别(Optical Character Recognition,OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
OCR以开放API(Application Programming Interface,应用程序编程接口)的方式提供给用户,用户使用Python、Java等编程语言调用OCR服务API将图片识别成文字,帮助用户自动采集关键数据,打造智能化业务系统,提升业务效率。
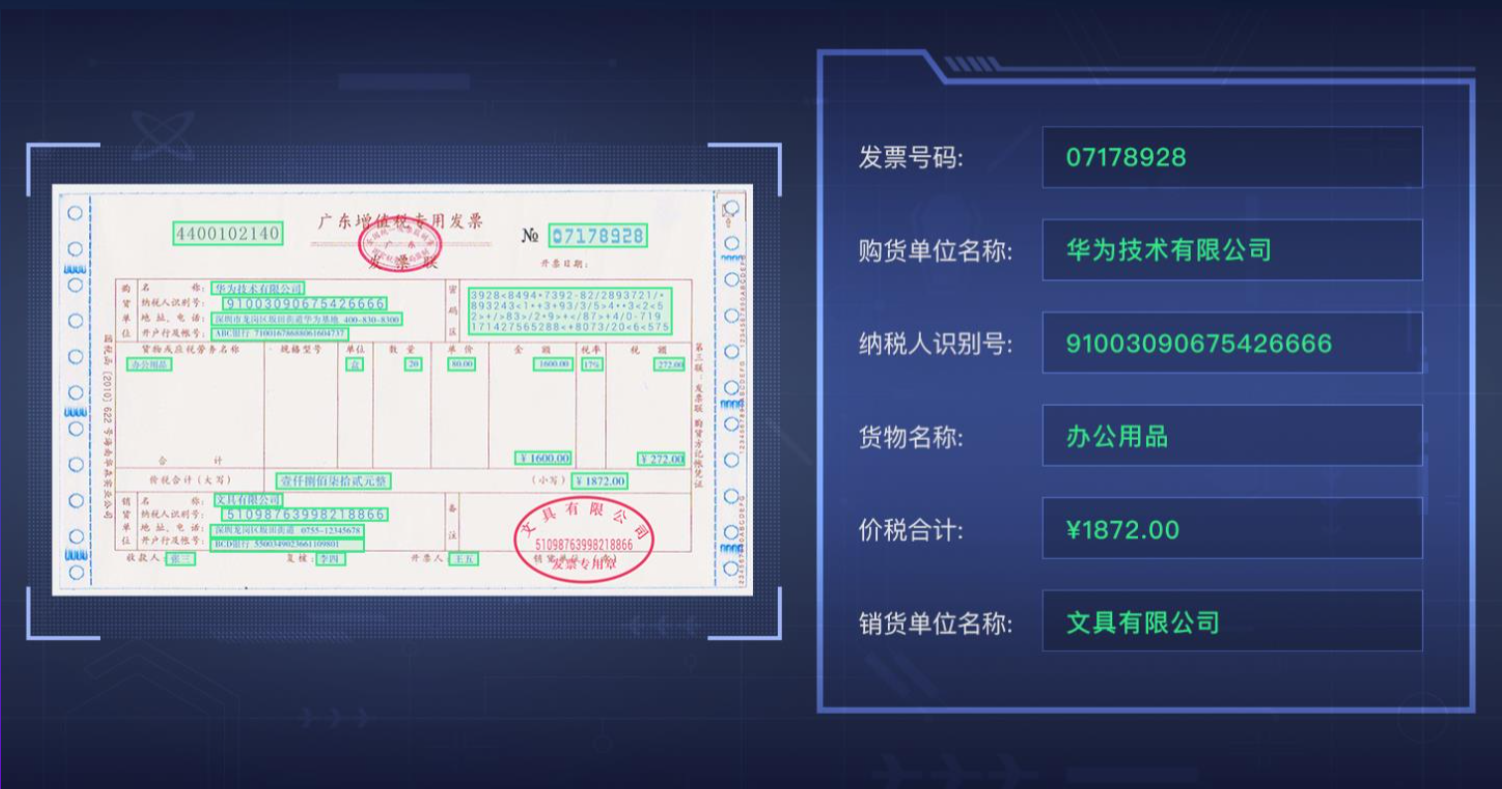
1.2 文字识别(OCR)应用场景
华为云OCR使用要求用户需要具备编程能力,熟悉Java/Python/iOS/Android/Node.js编程语言。服务需要用户通过调用API接口,实现将图片或扫描件中的文字识别成可编辑的文本。文字提取之后返回的结果是JSON格式,用户需要通过编码将识别结果对接到业务系统或保存为TXT、Excel等格式。
文字识别(OCR)应用场景主要有以下三个方面:
| 类型 | 说明 |
|---|---|
| 通用类OCR(General OCR) | 支持表格识别、文档识别、网络图片识别、手写文字识别、智能分类识别、健康码识别、核酸检测记录识别等任意格式图片上文字信息的自动化识别,自适应分析各种版面和表格,快速实现各种文档电子化。 |
| 票据类OCR(Receipt OCR) | 支持增值税发票识别、机动车销售发票识别、出租车发票识别、火车票识别、定额发票识别、车辆通行费发票识别、飞机行程单识别以及发票验真;支持图片及PDF、OFD文档上有效信息的自动识别和结构化提取。 |
| 证件类OCR(Card OCR) | 支持身份证识别、行驶证识别、驾驶证识别、护照识别、营业执照识别、银行卡识别、道路运输证识别、车牌识别、名片识别、VIN码识别、道路运输从业资格证识别等卡证图片上有效信息的自动识别和关键字段结构化提取。 |

2.文字识别技术的发展历程
2.1 OCR识别领域发展历程
OCR识别领域发展历程主要经历以下几个历程:西文OCR=》Tesseract=》LeNet=》深度学习OCR

2.1.1 西文OCR
在OCR技术中,印刷体文字识别是开展最早,技术上最为成熟的一个。欧美国家为了将浩如烟海、与日俱增的大量报刊杂志、文件资料和单据报表等文字材料输入计算机进行信息处理,从上世纪50年代就开始了西文OCR技术的研究,以便代替人工键盘输入。经过40多年的不断发展和完善,并随着计算机技术的飞速发展,西文OCR技术现已广泛应用于各个领域,使得大量的文字资料能够快速、方便、省时省力和及时地输入到计算机中,实现了信息处理的“电子化”。
2.1.1 Tesseract
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生。2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
Tesseract目前已作为开源项目发布在Google Project,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具。
2.1.3 LeNet
LeNet是经典CNN(Convolutional Neural Network)神经网络构造之一,第一次是在1995年由Yann LeCun,Leon Bottou,Yoshua Bengio,和Patrick Haffner提出的,这种神经网络结构在MINIST手写数字数据集上取得了优异的结果。
下面是使用LeNet进行识别的过程:
- 安排数据
- 确定超参数
- 建立网络结构,写上损失函数和优化器
- 安排训练过程
- 安排测试过程
- 保存模型
# coding=utf-8 (在源码开头声明编码方式,这样注释和代码中有中文不会报错)
import torch # 导入pytorch库
import torch.nn as nn # torch.nn库
import torch.nn.functional as F
import torch.optim as optim#torch.optim包主要包含了用来更新参数的优化算法,比如SGD、AdaGrad,RMSProp、 Adam等from torchvision import datasets, transforms#torchvision包含关于图像操作的方便工具库。# vision.datasets:几个常用的数据库,可以下载和加载;#vision.models:流行的模型,比如AlexNet,VGG,ResNet等#vision.transforms:常用的图像操作,例如:随机切割,旋转,数据类型转换,图像转到tensor,tensor到图像等。#vision.utils: 用于把形似 (3 x H x W) 的张量保存到硬盘中,给一个mini-batch的图像可以产生一个图像格网。from torch.autograd import Variable#torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现from torch.utils.data import DataLoader#PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入# 下载训练集。在pytorch下可以直接调用torchvision.datasets里面的MNIST数据集(这是官方写好的数据集类),这是方法一。还可以自己定义和加载。加载之后的train_dataset等于train_dataset = datasets.MNIST(root='./num/',train=True,transform=transforms.ToTensor(),download=True)#root(string): 数据集的根目录root directory。'./num/'意思就是建立在根目录下建立一个num文件夹,把num下的MNIST数据集加载进来。#train是可选填的,表示从train.pt创建数据集,就是进入训练数据集开启训练模式。#transform是选填的,接收PIL图像并且返回已转换版本。#download也是选填的,如果true就从网上下载数据集并放在根目录/num下,如果已经下载好了就不会再次下载。
# 下载测试集
test_dataset = datasets.MNIST(root='./num/',train=False,transform=transforms.ToTensor(),download=True)
# dataset 参数用于指定我们载入的数据集名称
# 在装载的过程会将数据随机打乱顺序并进打包
batch_size = 64# batch_size参数设置了每个包中的图片数据个数# 装载训练集
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)#建立一个数据迭代器,在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化。#dataset——给出需要加载的数据来源,train_dataset的类型是torchvision.datasets.mnist.MNIST#batchsize——选填,一次加载多少个数据样本,默认是1个#shuffle——选填,true就是每个epoch都会洗一下牌,默认是不洗牌# 装载测试集
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=True)#建立网络结构
# 卷积层使用 torch.nn.Conv2d
# 激活层使用 torch.nn.ReLU
# 池化层使用 torch.nn.MaxPool2d
# 全连接层使用 torch.nn.Linearclass LeNet(nn.Module):#LeNet类是从torch.nn.Module这个父类继承下来的,在__init__构造函数中申明各个层的定义,然后再写上forward函数,在forward里定义层与层之间的连接关系,这样就完成了前向传播的过程。def __init__(self):super(LeNet, self).__init__()#super(LeNet,self)__init__():在单继承中 super 主要是用来调用父类的方法的,而且在python3中可以 用super().xxx 代替 super(Class, self).xxxself.conv1 = nn.Sequential(nn.Conv2d(1, 6, 3, 1, 2), nn.ReLU(),nn.MaxPool2d(2, 2))#nn.Sequential是一个顺序容器,将神经网络模块按照传入顺序依次被添加到计算图中执行。
#Conv2D的结构是:nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True))self.conv2 = nn.Sequential(nn.Conv2d(6, 16, 5), nn.ReLU(),nn.MaxPool2d(2, 2))self.fc1 = nn.Sequential(nn.Linear(16 * 5 * 5, 120),nn.BatchNorm1d(120), nn.ReLU())self.fc2 = nn.Sequential(nn.Linear(120, 84),nn.BatchNorm1d(84),nn.ReLU(),nn.Linear(84, 10))# 最后的结果一定要变为 10,因为数字的选项是 0 ~ 9def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = x.view(x.size()[0], -1)#x.view(x.size(0), -1)这句话是说将第二次卷积的输出拉伸为一行,接下来就是全连接层x = self.fc1(x)x = self.fc2(x)return x#指定设备。“cuda:0”代表起始的device_id为0,如果直接是“cuda”,同样默认是从0开始。可以根据实际需要修改起始位置,如“cuda:1”。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
LR = 0.001
#LR是学习率,这是一个超参数
#实例化LeNet。to(device)代表将模型加载到指定设备上。
net = LeNet().to(device)
# 损失函数使用交叉熵
criterion = nn.CrossEntropyLoss()
# 优化函数使用 Adam 自适应优化算法
optimizer = optim.Adam(net.parameters(),lr=LR,
)epoch = 1
if __name__ == '__main__':#如果这个脚本是主函数,那么就运行如下代码。“__name__”是Python的内置变量,用于指代当前模块。for epoch in range(epoch):sum_loss = 0.0for i, data in enumerate(train_loader):#enumerate()用于可迭代\可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标。data里面包含图像数据(inputs)(tensor类型的)和标签(labels)(tensor类型)inputs, labels = datainputs, labels = Variable(inputs).cuda(), Variable(labels).cuda()#注意使用多gpu时训练或测试 inputs和labels需加载到gpu中。模型和相应的数据进行.cuda()处理。就可以将内存中的数据复制到GPU的显存中去optimizer.zero_grad() #每个batch开始时都需要将梯度归零outputs = net(inputs) #将数据传入网络进行前向运算loss = criterion(outputs, labels) #得到损失函数loss.backward() #反向传播optimizer.step() #通过梯度做一步参数更新# print(loss)sum_loss += loss.item()#pytorch中,.item()方法 是得到一个元素张量里面的元素值
#具体就是 用于将一个零维张量转换成浮点数,比如计算loss,accuracy的值if i % 100 == 99:print('[%d,%d] loss:%.03f' %(epoch + 1, i + 1, sum_loss / 100))sum_loss = 0.0net.eval() #将模型变换为测试模式
#在PyTorch中进行validation时,会使用model.eval()切换到测试模式,在该模式下,主要用于通知dropout层和batchnorm层在train和val模式间切换。#在train模式下,dropout网络层会按照设定的参数p设置保留激活单元的概率(保留概率=p); batchnorm层会继续计算数据的mean和var等参数并更新。
#在val模式下,dropout层会让所有的激活单元都通过,而batchnorm层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值。该模式不会影响各层的gradient计算行为,即gradient计算和存储与training模式一样,只是不进行backprobagation。
correct = 0
total = 0
for data_test in test_loader:images, labels = data_testimages, labels = Variable(images).cuda(), Variable(labels).cuda()output_test = net(images)_, predicted = torch.max(output_test, 1)#其中这个 1代表行,0的话代表列。
#不加_,返回的是一行中最大的数。
#加_,则返回一行中最大数的位置。total += labels.size(0)correct += (predicted == labels).sum()print("correct1: ", correct)print("Test acc: {0}".format(correct.item() / len(test_dataset)))
2.1.4 深度学习OCR
随着深度学习OCR发展,MINST数据集的建立开始使用各种深度学习算法,OCR也广泛进入了商业化领域。进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。其中以OCR为科技核心的云脉技术不断创新进取,研发了一系列OCR软件产品,并且运用在医院,学校,企业等各大市场。
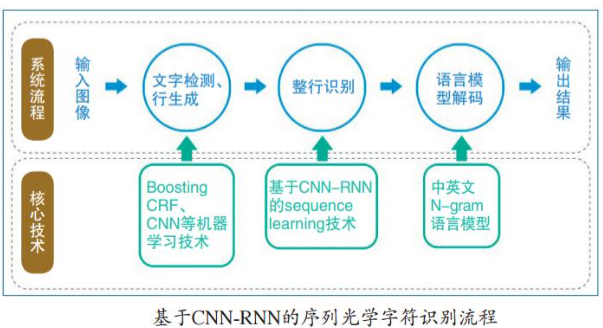
2.2 OCR识别流程历程
下面是经典的光学字符识别系统流程和技术框架图解:
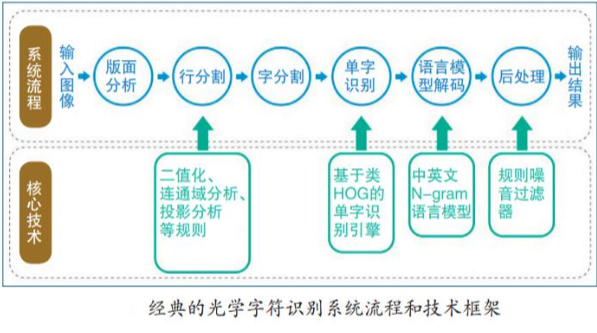
下面是基于CNN-RNN的序列光学字符识别流程图解:
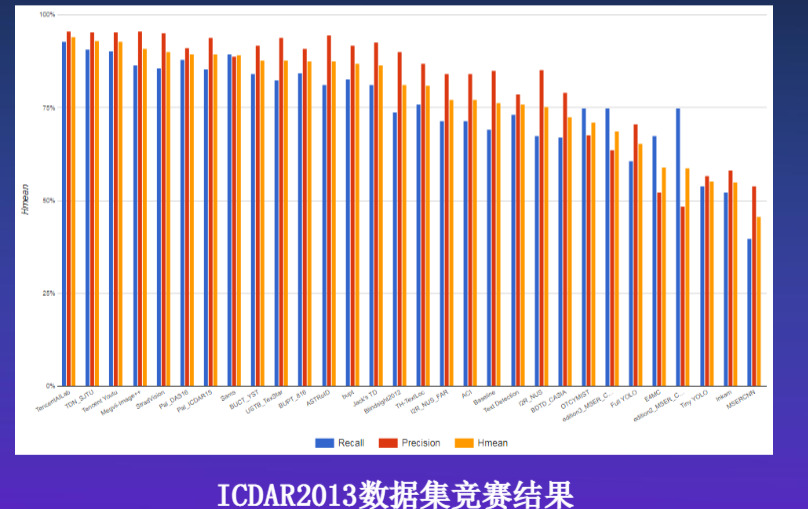
目前,在OCR文字定位与识别领域,主流方法都是基于深度学习方法。如
在ICDAR2013自然场景上前20名已经见不到传统方法的影子了。
3.简要介绍文字定位与文字识别技术
目前OCR技术主要分为文字定位和文字识别两个流程。
3.1 文字定位
文字定位是文字识别的前提条件,要解决的问题是如何在杂乱无序、千奇百怪的不同场景中准确地定位出文字的位置。由于不同场景背景的复杂性、光照的多变性以及字体的不可预测性等原因,文字定位面临着极大的挑战。
 文字定位主要有传统方法和深度学习两种:基于传统方法、基于深度学习。
文字定位主要有传统方法和深度学习两种:基于传统方法、基于深度学习。
3.1 基于传统方法
传统方法:人工设计特征描述,基于模板匹配方式识别文字,需要准确的特征描述,难以满足复杂场景识别任务。
- 基于连通区域(MSER,SWT…)
- 基于滑动窗
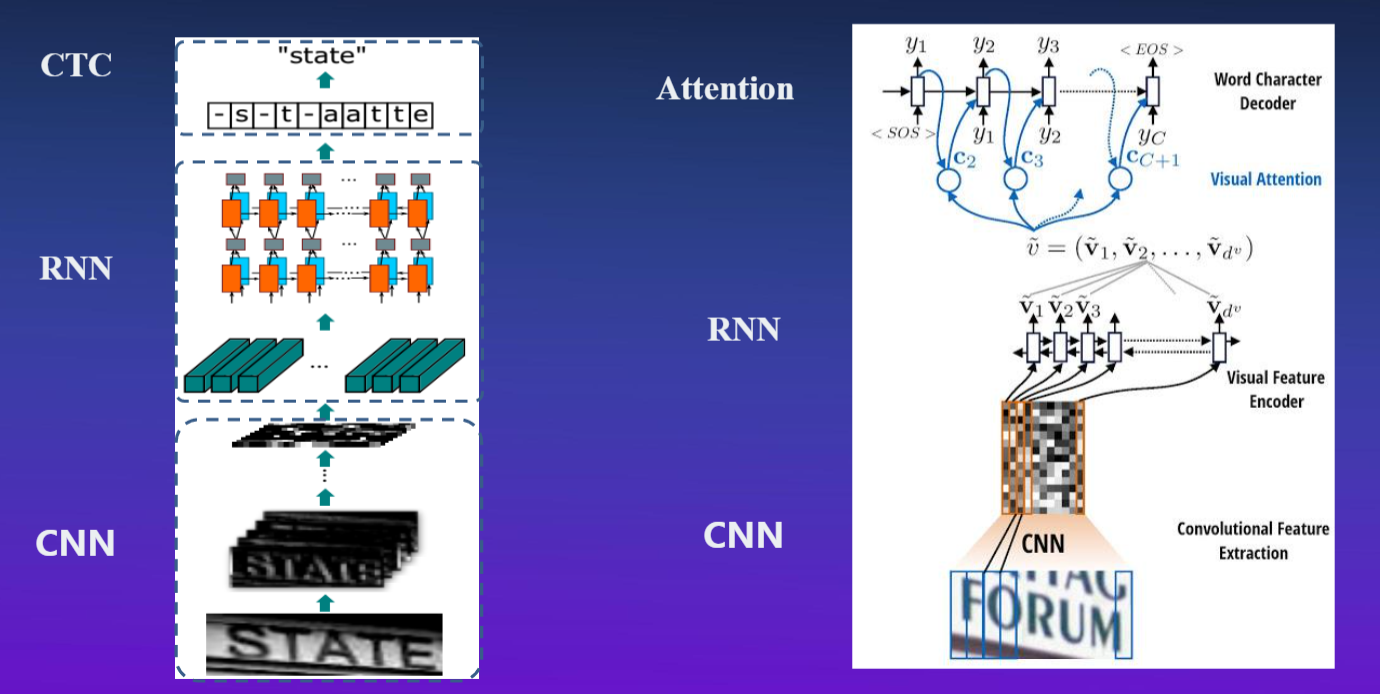
3.2 基于深度学习
深度学习方法:海量标注数据自动学习文字特征,主流方法是基于CNN+RNN的深度学习网络。
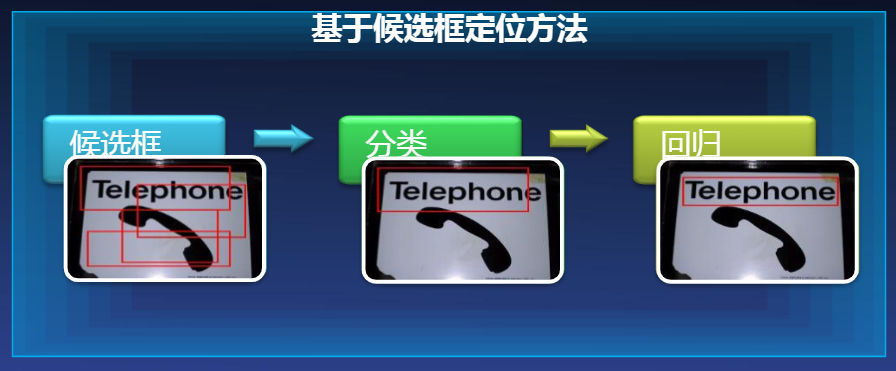
3.2.1 基于侯选框
- TextBoxes:A fast text detector with a single deep neural network
- Detecting Oriented Text in Natural Images by Linking Segments
3.2.2 基于分割
- Multi-oriented text detection with fully convolutional networks
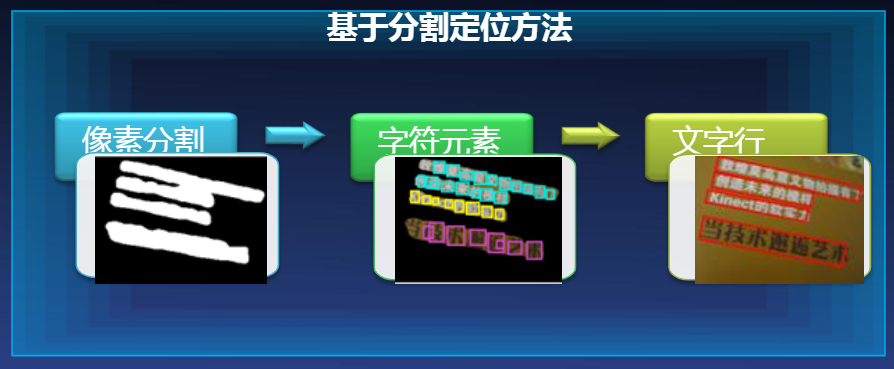
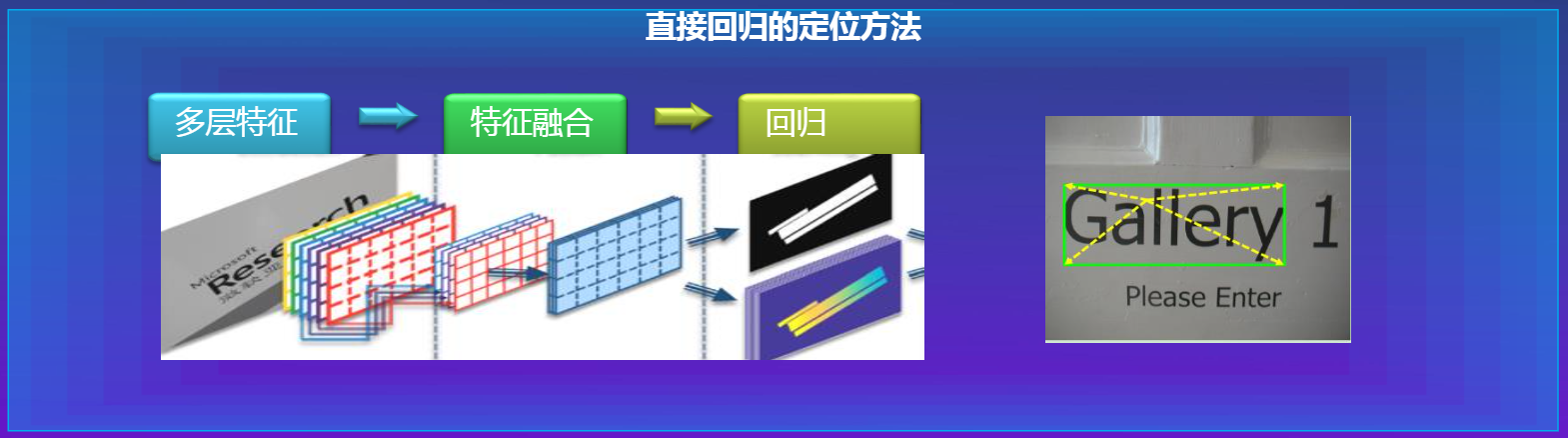
3.2.3 直接回归
- Deep Direct Regression for Multi-Oriented Scene Text Detection
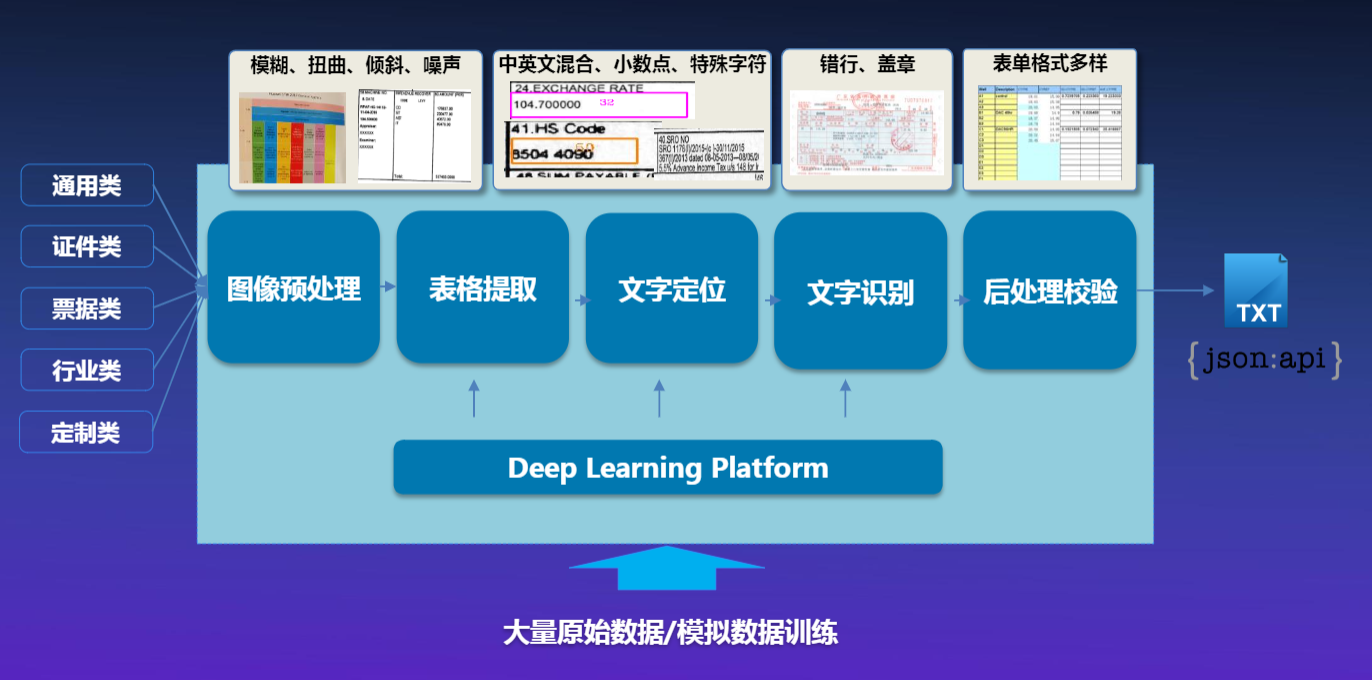
二、华为云OCR服务介绍
1.简要介绍华为云OCR服务
华为云文字识别主要分为:通用类、证件类、票据类、行业类、定制类。
1.1 通用类
OCR服务接口
- 通用表格识别
- 通用文字识别
- 网络截图识别
- 签名盖章检测
- 手写数字字母识别
OCR优势
- 识别精度高,支持不同版面自适应分析
- 自动化匹配信息,提升审核准确度
- 提高效率,节约人工成本

1.2 证件类
OCR服务接口
- 身份证识别
- 行驶证识别
- 驾驶证识别
- 护照检测
- 缅甸身份证识别
OCR优势
- 识别精度高,支持任意角度倾斜、缺角、反光、复杂背景等场景的卡证识别
- 支持外语证件的订制OCR识别
- 通过卡证识别,快速完成快递录单、手机开户等场景信息录入,实名认证

1.3 票据类
OCR服务接口
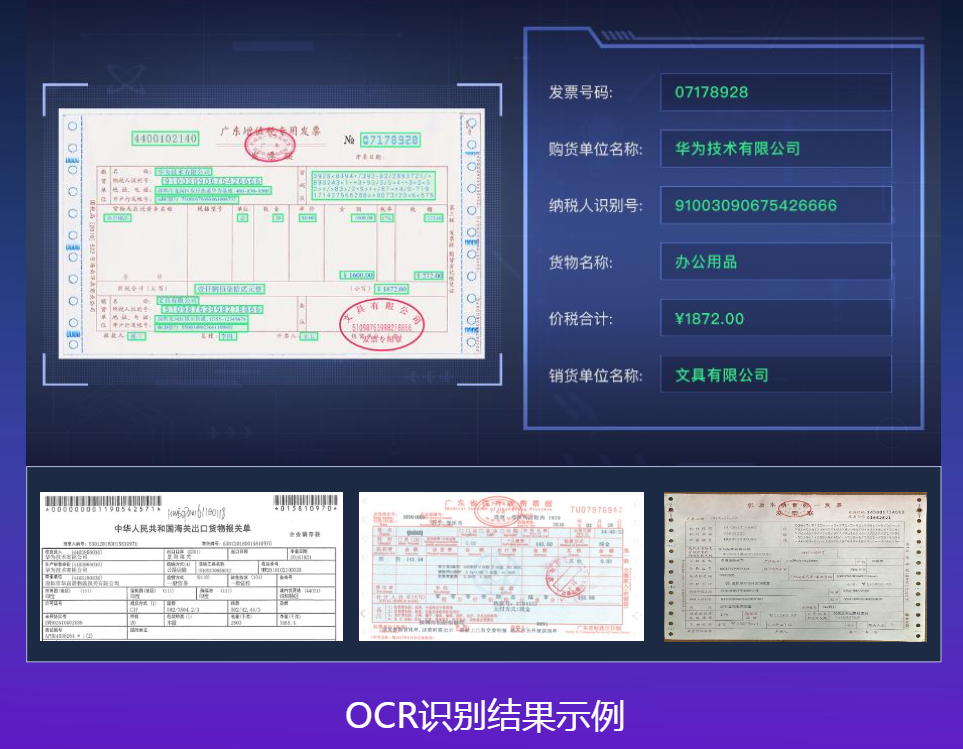
- 增值税发票识别
- 医疗发票识别
- 机动车销售发票识别
- 海关清关单据识别
OCR优势
- 支持多种票据自动识别,结构化提取多项关键信息
- 支持图像翻转、文字错行、盖章干扰等复杂场景,数字、符号等文本识别精度高
1.4 行业类
OCR服务接口
- 物流电子面单识别
- 物流纸质面单识别
- 医疗化验单据识别
OCR优势
- 行业解决方案成熟
- 支持姓名、地址、电话等关键字段自动提取
- 支持复杂背景、扭曲等情况
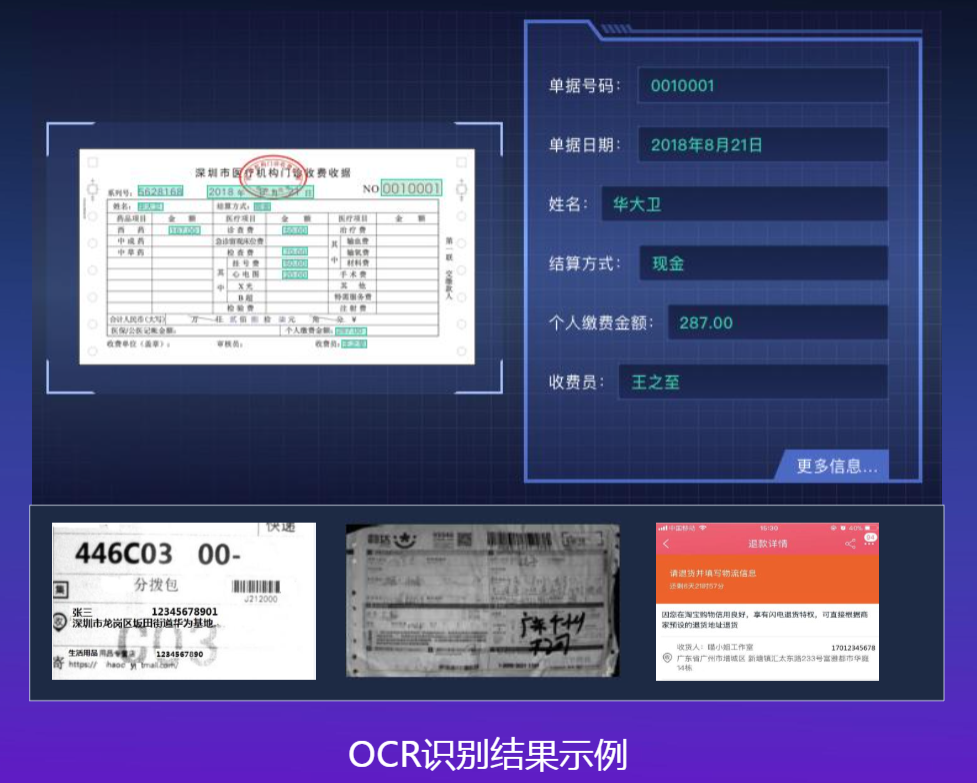
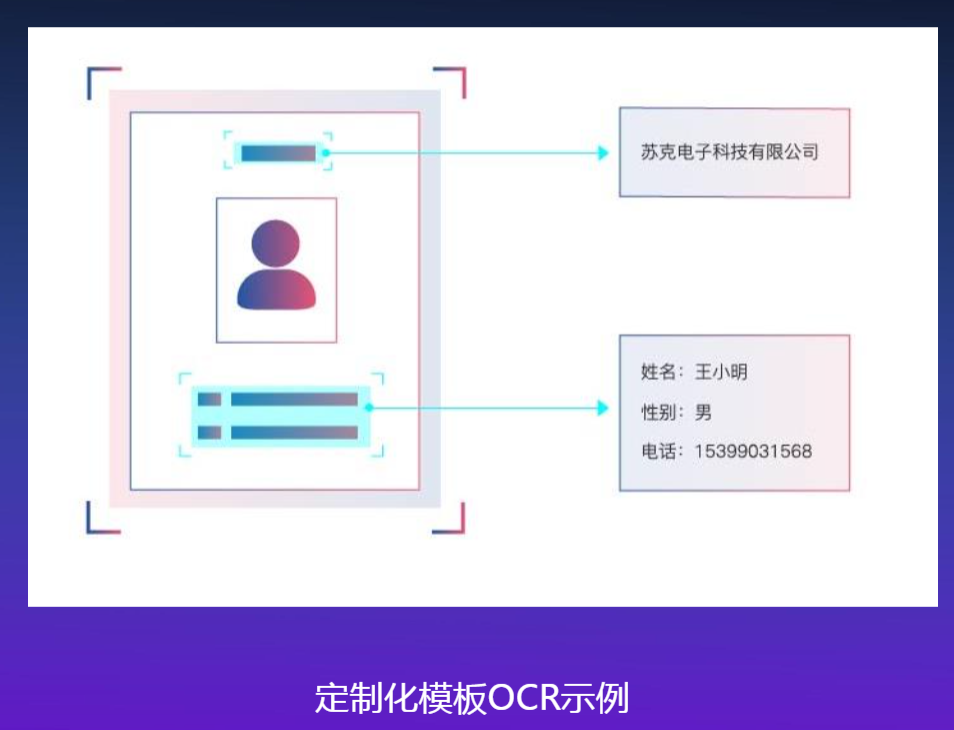
1.5 定制类
服务功能
- 用户自定义模板,识别各类证件、票据
- 专属API定制开发,满足高精度特殊场景
OCR优势
- 可视化界面操作,用户轻松指定识别区域,完成模板设计并调用服务接口
- 对各类证件、票据定制独立模板,适应不同格式图片的自动识别及结构化提取
2.华为云OCR服务的应用场景
华为云OCR服务的应用场景主要有:
- 身份验证场景
- 物流快递场景
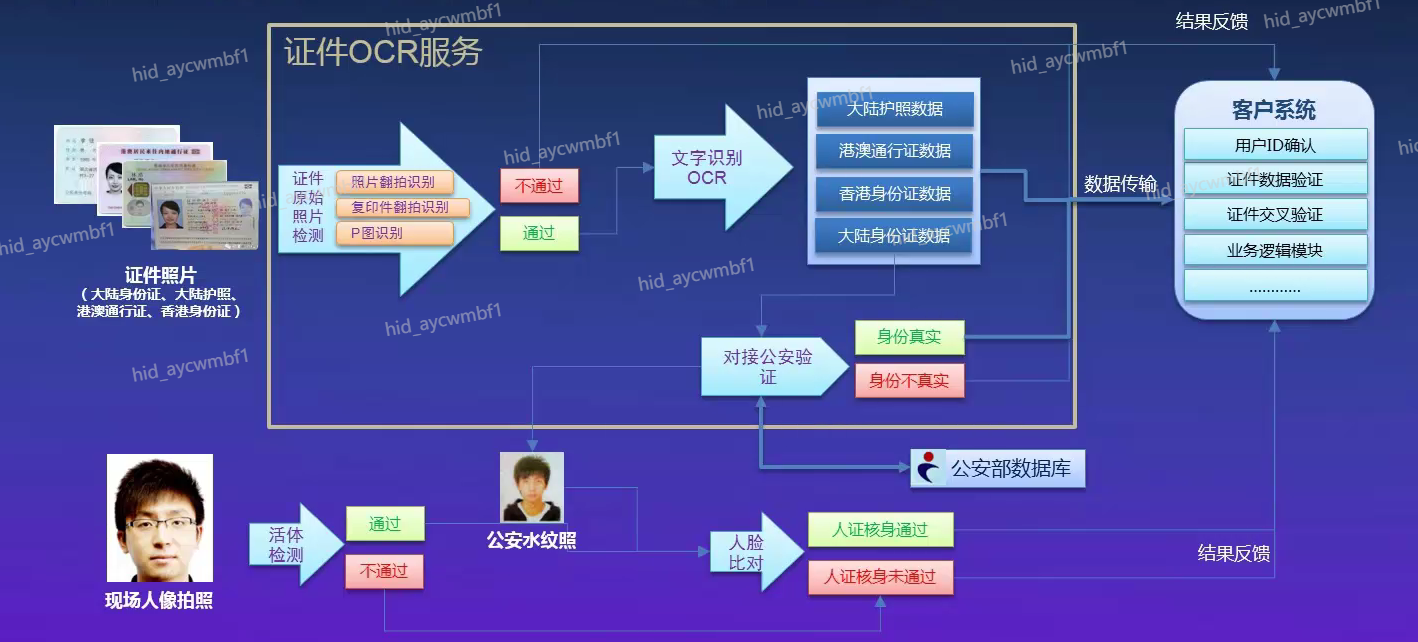
2.1 身份验证场景
在金融、证券、保险、政务、安防等众多领域中,大量场景需要对客户进行身份验证。
本服务可审核证件是否为原件,有效防止照片翻拍、复印件翻拍、P图等欺骗行为,识别证件中的文字内容,并对接公安系统验证身份是否真实有效。
2.2 物流快递场景
物流快递场景用到OCR服务主要有两个方面:快递员取件填写运单、提取运单信息存入系统。
物流快递场景主要流程如下:

2.2.1 快递员取件填写运单
1、身份证OCR:实名认证
- 取件时,移动端APP:身份证拍照、识别、校验
- 速度快:<1秒;精度高:>98%
2、网络截图OCR
- 电商收到买家地址截图、聊天截图OCR识别、自动提取信息(姓名、地址、电话等)
快递员取件填写运单:华为云OCR能够准确识别不同角度、复杂背景图片,简化录入过程,提高服务效率。
2.2.2 提取运单信息存入系统
1、电子面单OCR
- 自动提取:编号信息,收/寄件人姓名、电话、地址
- 平均字符精度:99%
2、纸质面单OCR
- 文字检测:特定内容是否填写
- 盖章检测:是否盖章(检视章),合规性检测等
提取运单信息存入系统:华为云OCR能够智能处理各种复杂背景,提取结构化信息大幅节省人力,提升流程自动化程度。
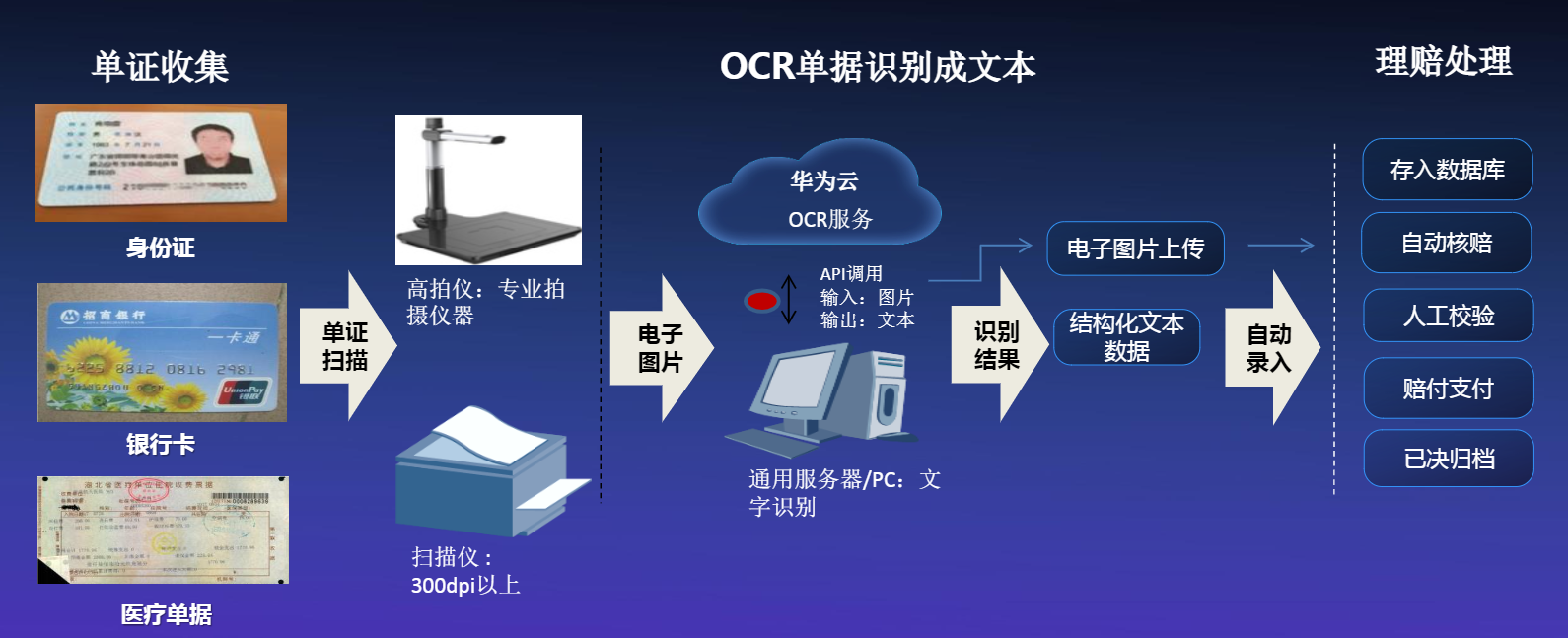
2.3 医疗保险理赔场景
华为云OCR在医疗保险理赔场景中的优势主要有:
- 加快理赔处理速度,明显提高用户体验,同时降低人保人工成本
- 有效解决医疗单据中错行、文字相互覆盖、盖章干扰等复杂场景的文字识别;解决维吾尔文干扰的身份证文字识别
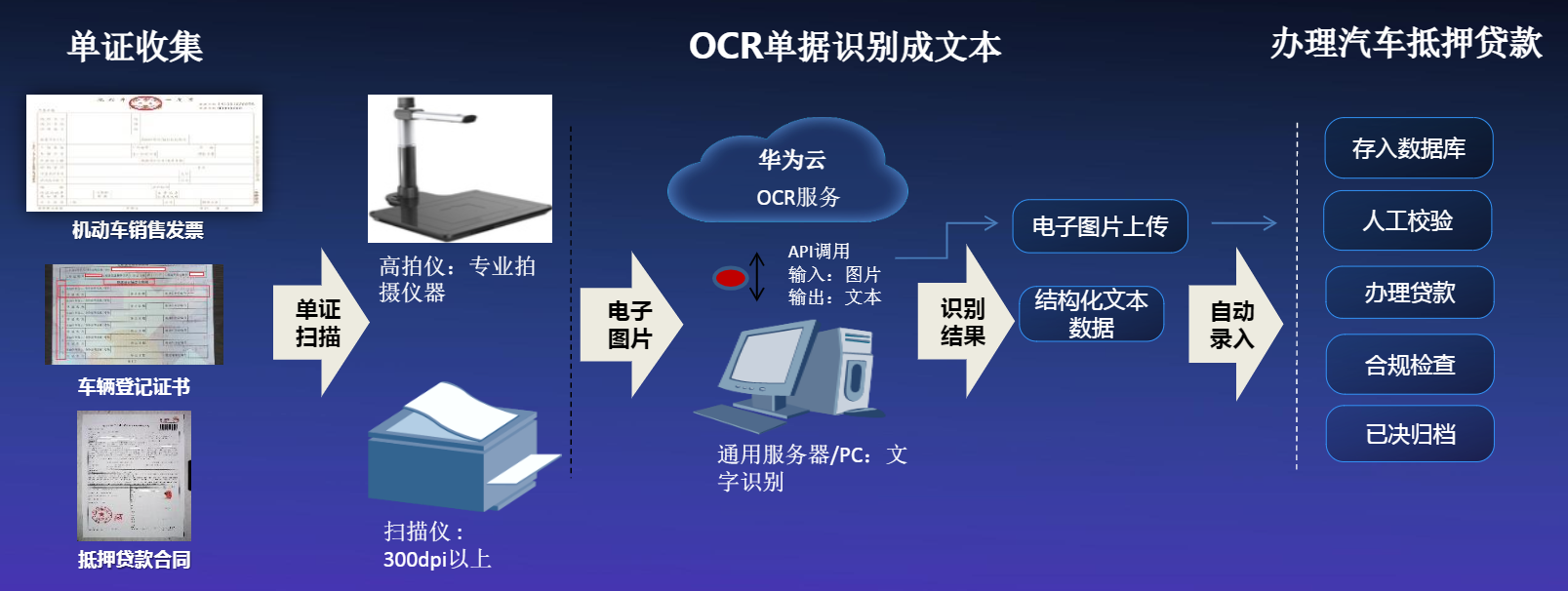
2.4 汽车金融场景
华为云OCR在汽车金融场景中的优势主要有:
- 大幅提高数据录入核对效率,改善用户体验,同时降低人工成本
- 提取购车发票等图片的结构化信息,有效解决旋转、错行、模糊变形等复杂场景,准确率高>98%
- 自动进行合同签名检测,保证合规
2.5 互联网网络截图场景
互联网网络截图场景主要分为:电商图片、聊天截图。
2.5.1 电商图片
电商图片提取的主要信息主要有:
- 店铺、商品主图,详情图
- 用户评价图、打分
- 订单编号、金额
- 识别关注、收藏、心愿单截图
华为云OCR在电商图片场景中的优势主要有:
- 批量提取商品信息:价格、销量、评价等
- 用户评价审核
- 判断是否关注、收藏(淘宝返利)
2.5.2 聊天截图
电商图片提取的主要信息主要有:
1、聊天截图
- 聊天软件、社交网络截图
- 聊天内容自动识别提取
2、用户自生成(UGC)图片
- 各种手机截图、网页截图
- 用户拍照图片、合成图片
华为云OCR在聊天截图场景中的优势主要有:
- 快捷提取聊天信息:地址、电话等
- 图像内容审查:敏感词检测
- 信息统计、数据挖掘
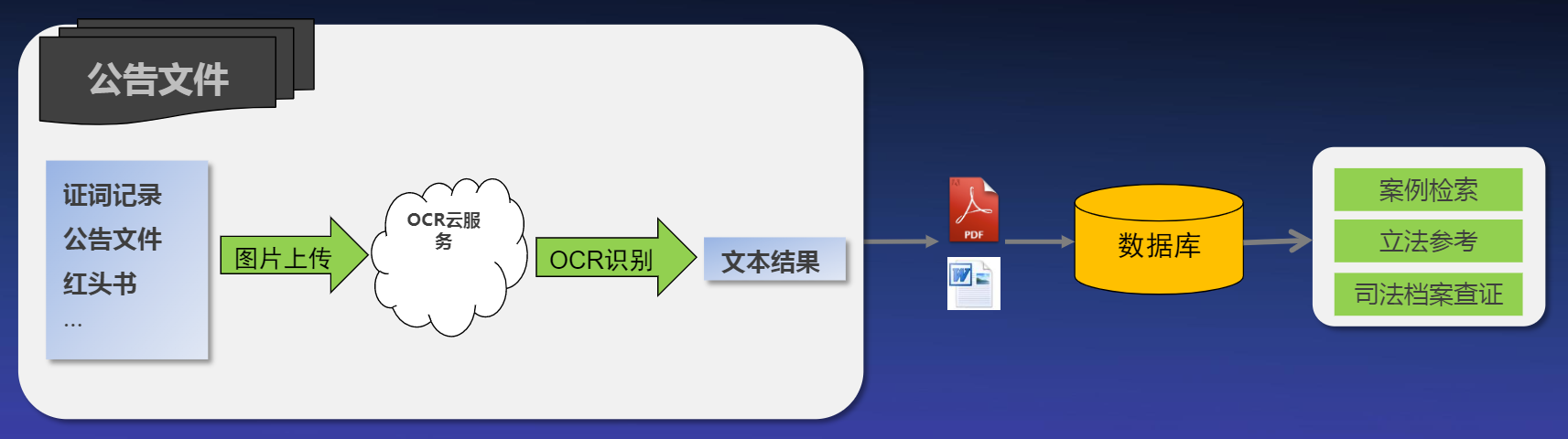
2.6 政法法院场景
华为云OCR在政法法院场景中的优势主要有:
- 支持各种格式文档、表格等图片识别,返回结构化文档
- 大幅效率提升,准确率高,建立数据资产
2.7 财务报销场景
华为云OCR在财务报销场景中的优势主要有:
- 支持方向检测,票据倾斜和扭曲矫正
- 去除盖章影响
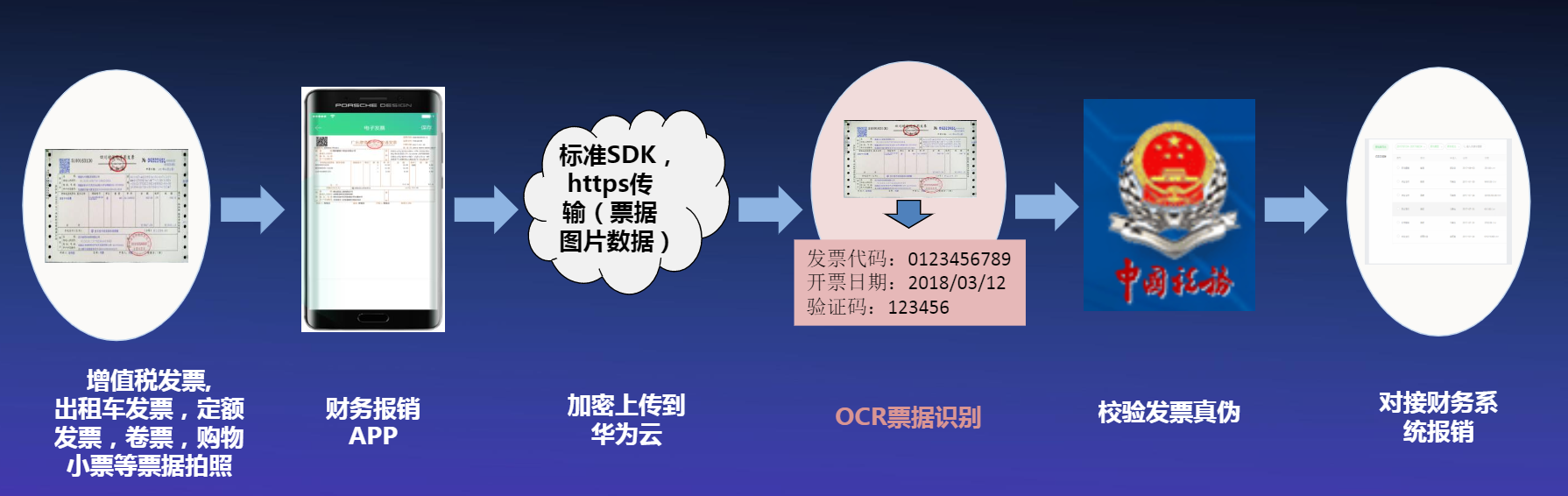
2.8 医疗化验单/检验单OCR识别场景
华为云OCR在医疗化验单/检验单OCR识别场中的优势主要有:
- 自适应识别不同医院不同版式化验单
- 自动提取姓名、年龄、住院号等关键信息
- 支持扭曲变形、倾斜遮挡等复杂场景

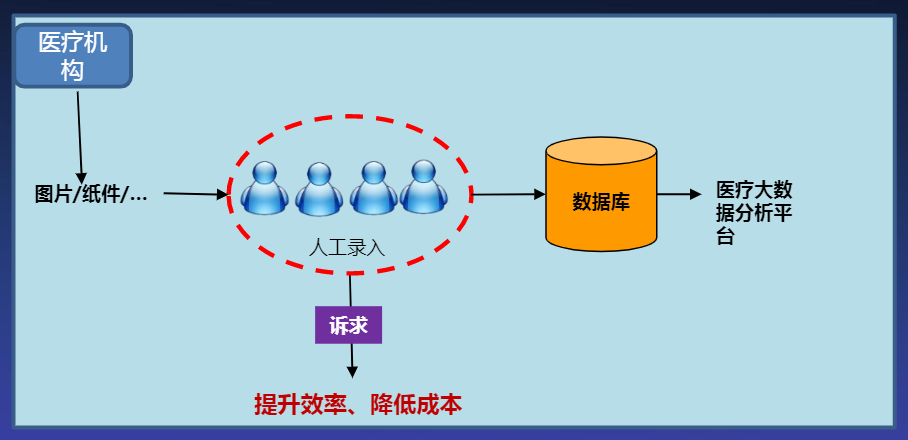
2.9 定制专属OCR服务接口:缅甸身份证OCR识别
缅甸身份证OCR服务:
- 支持缅甸文OCR识别
- 适应任意角度倾斜、缺角、反光、复杂背景等场景,识别精度高
定制专属OCR服务:
- 满足不同版式个性化需求
- 支持外语OCR识别
- 专业团队快速定制开发
- 在华为云上提供专属API接口

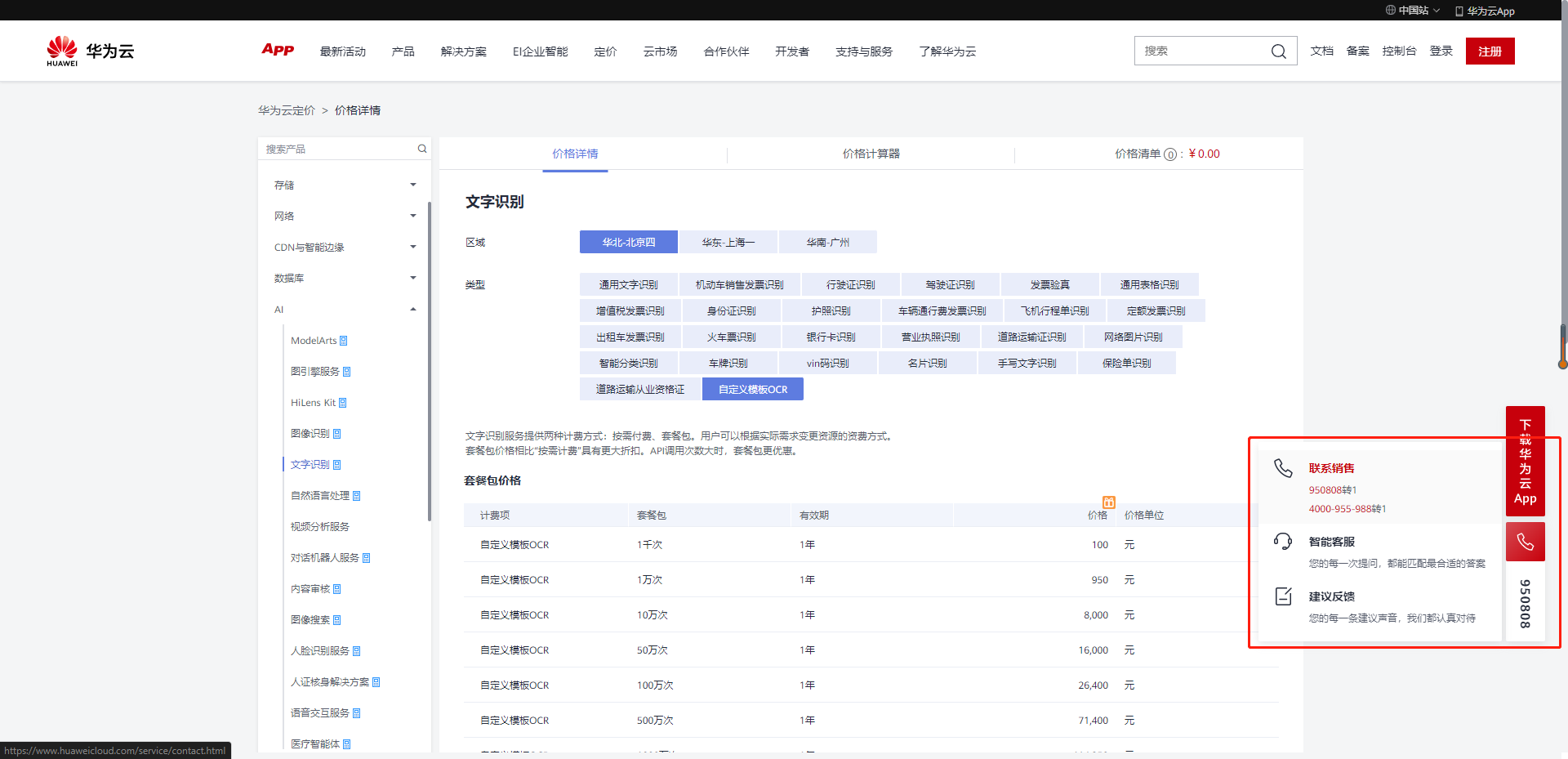
3.华为云OCR服务定价
3.1 按需付费、阶梯收费
文字识别服务提供两种计费方式:按需付费、套餐包。用户可以根据实际需求变更资源的资费方式。
套餐包价格相比“按需计费”具有更大折扣。API调用次数大时,套餐包更优惠。
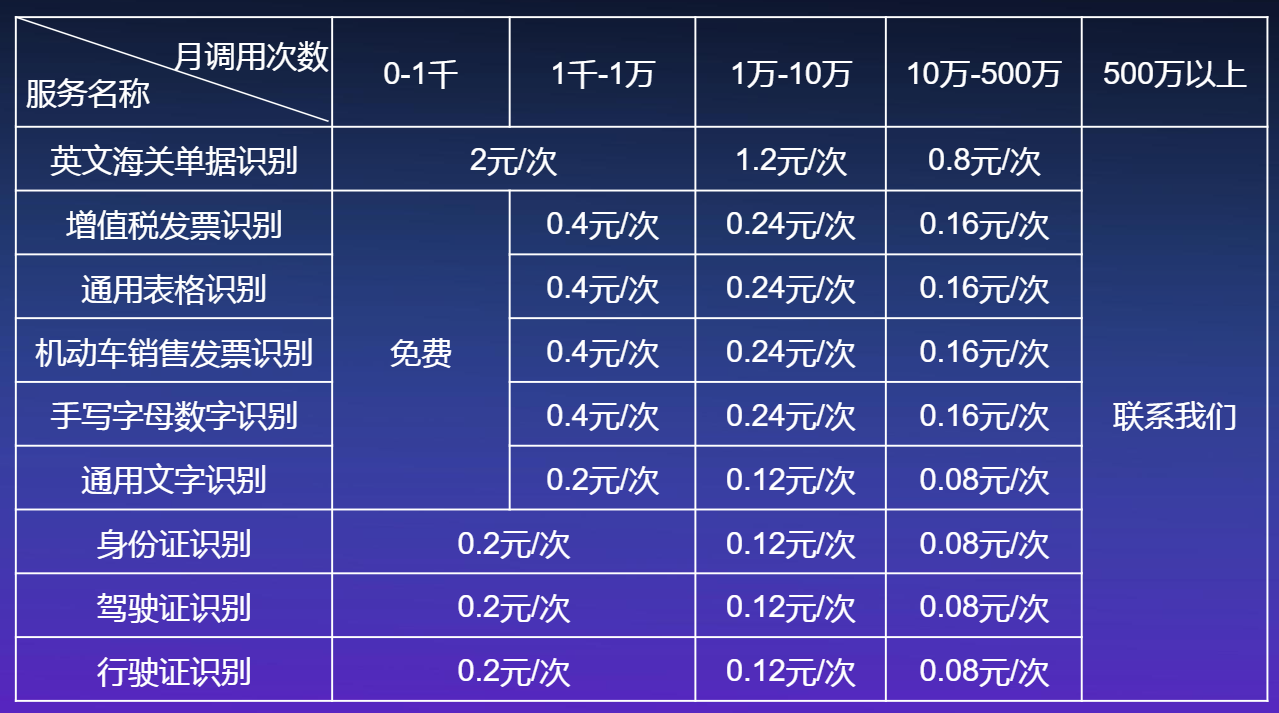
具体以官网实际价格为准:https://www.huaweicloud.com/pricing.html?tab=detail#/ocr
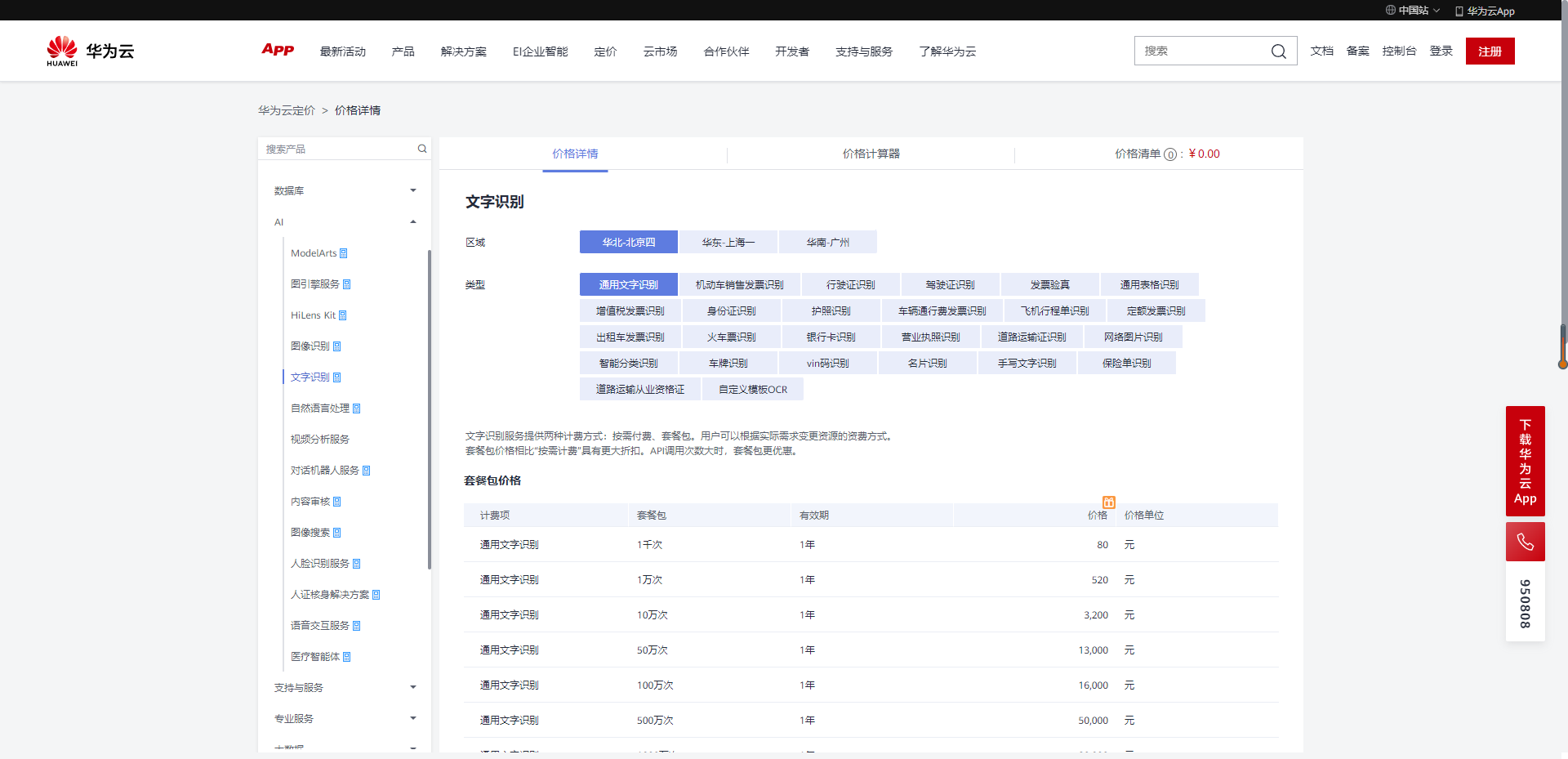
3.2 专属定制
如果需要专属定制OCR可以联系华为云客服进行咨询。
官网:https://www.huaweicloud.com/pricing.html?tab=detail#/ocr
三、华为云OCR使用指南
1.华为云OCR SDK开发指南
华为云SDK官网:https://developer.huaweicloud.com/intl/zh-cn/sdk?all
2.华为云OCR .NET SDK的使用
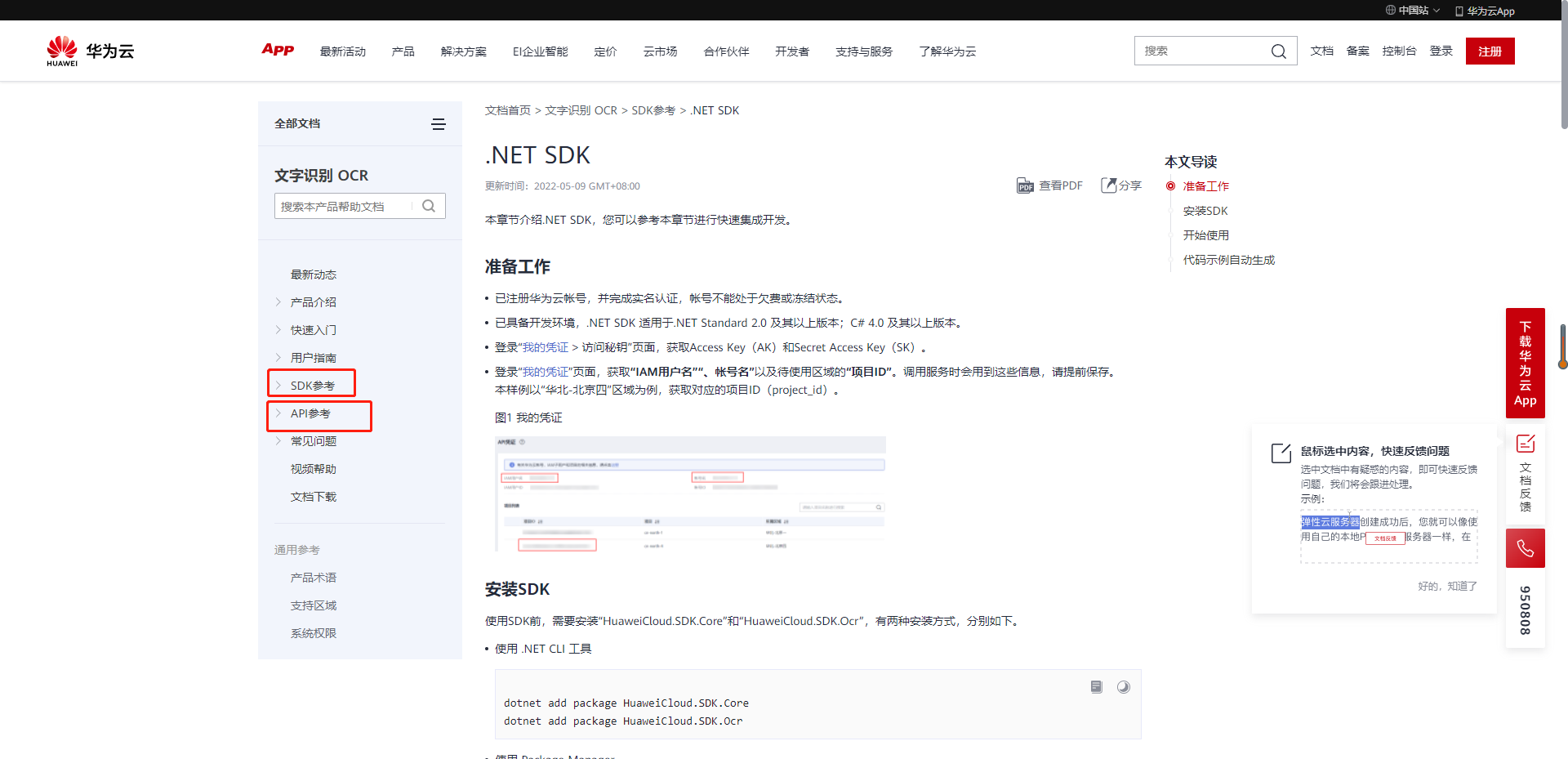
2.1 前提准备
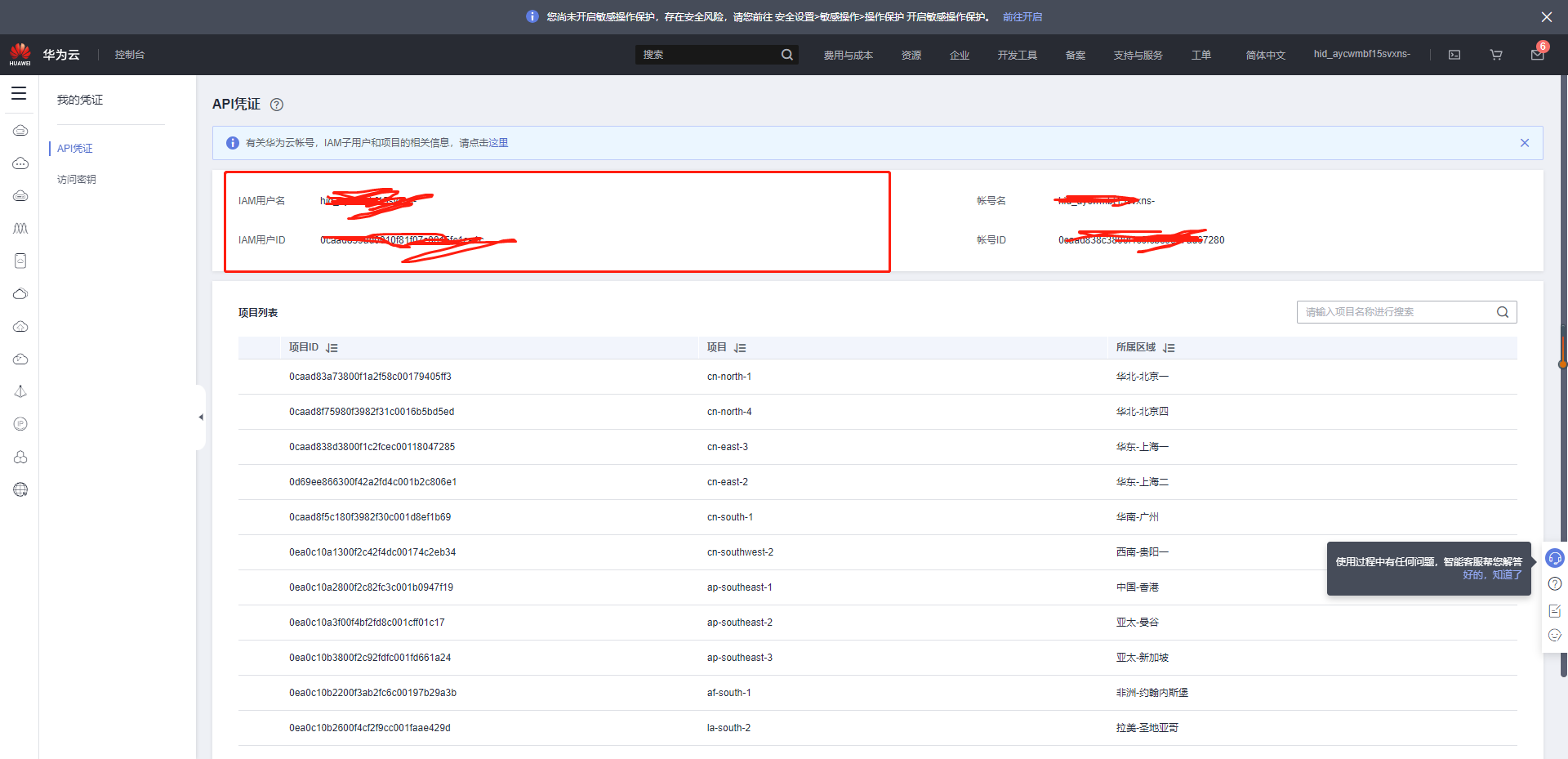
进入密钥管理界面:https://console.huaweicloud.com/iam/?region=cn-north-4#/mine/apiCredential
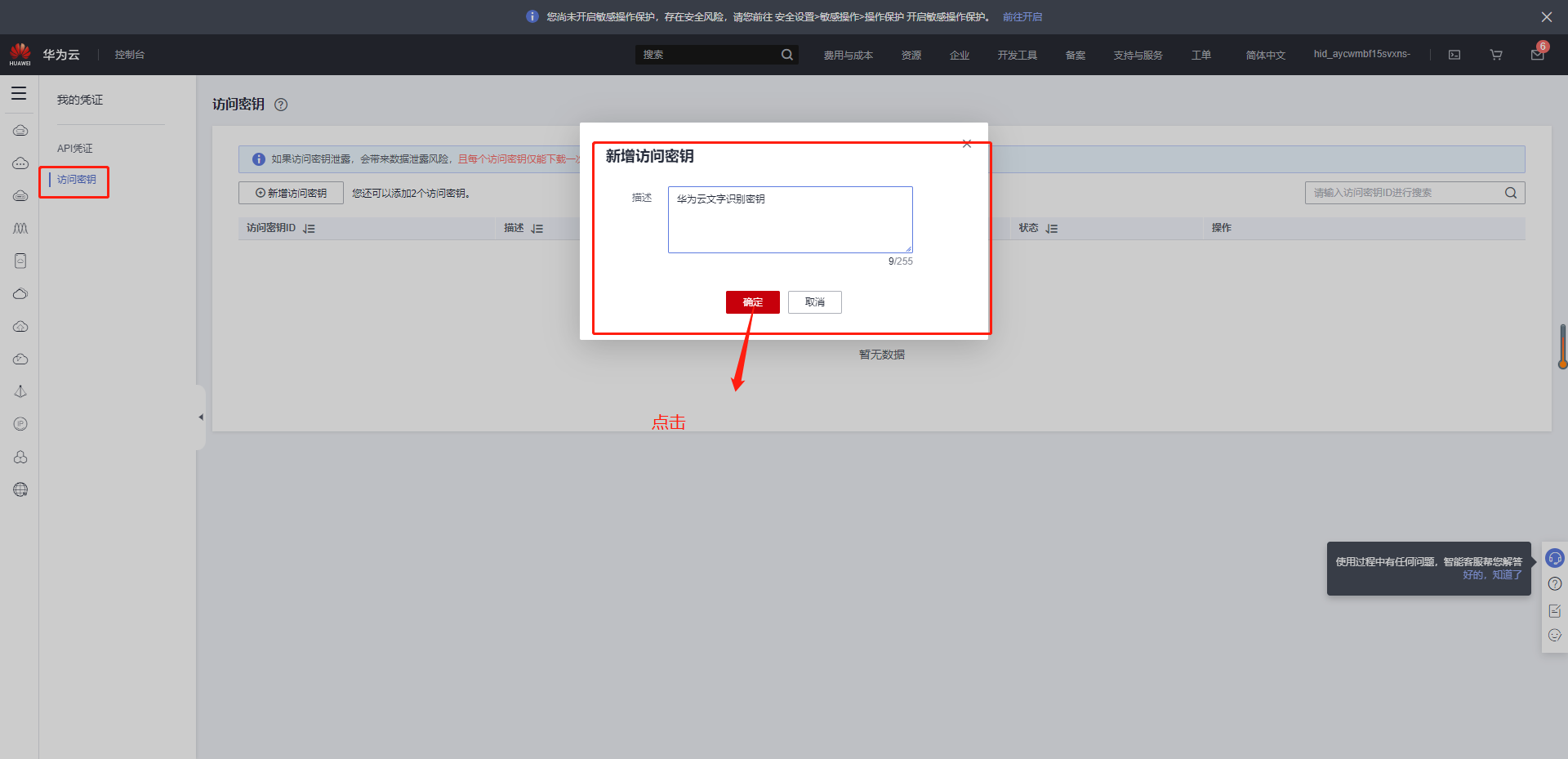
点击确定后选择立即下载就可以获取Access Key(AK)和Secret Access Key(SK)。
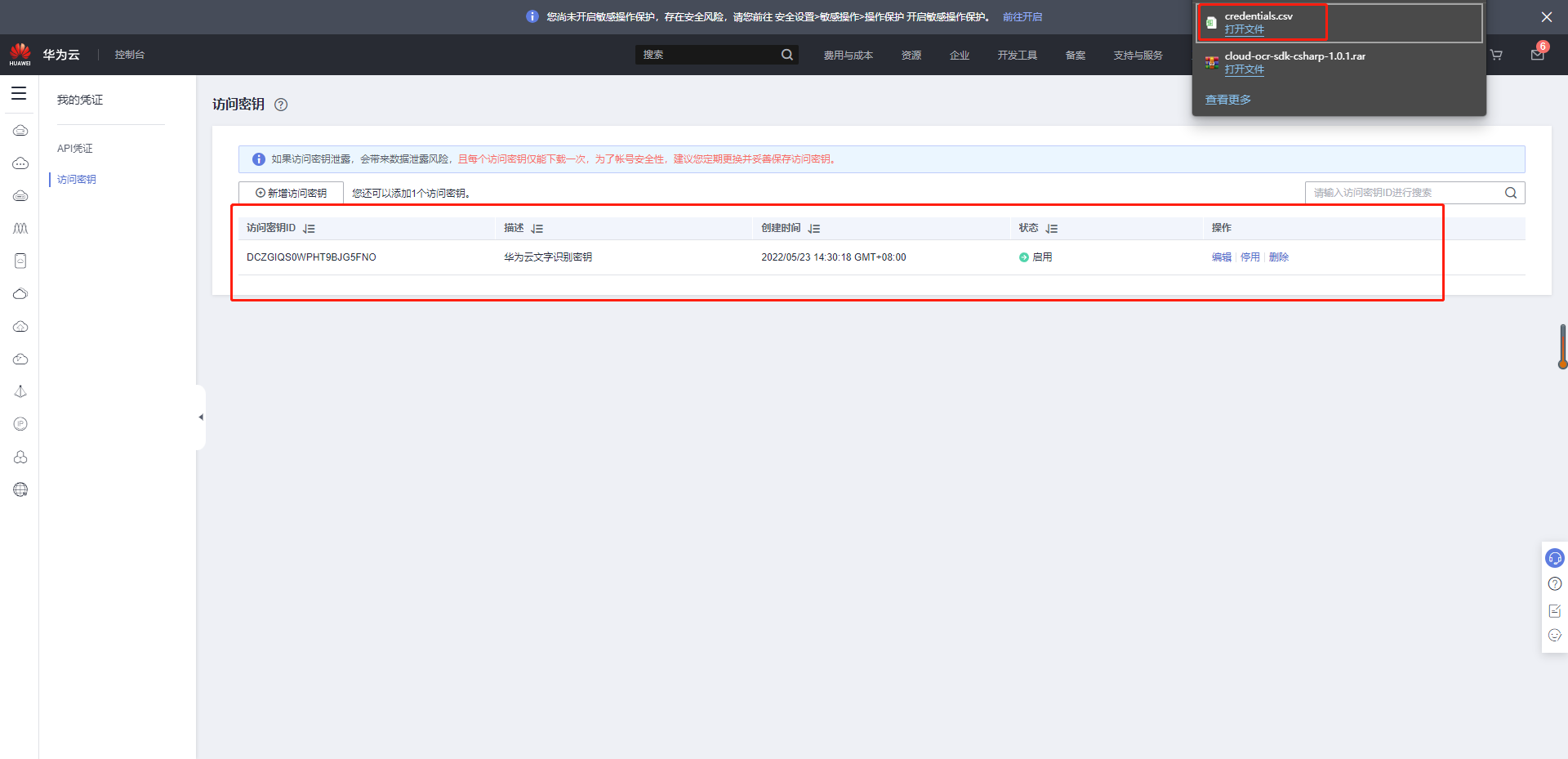
切换到API凭证,获取“IAM用户名”“、帐号名”以及待使用区域的“项目ID”。调用服务时会用到这些信息,请提前保存。
2.2 安装对应语言的SDK
使用SDK前,需要安装“HuaweiCloud.SDK.Core”和“HuaweiCloud.SDK.Ocr”,有两种安装方式,分别如下。
使用 .NET CLI 工具
dotnet add package HuaweiCloud.SDK.Core
dotnet add package HuaweiCloud.SDK.Ocr
使用 Package Manager
Install-Package HuaweiCloud.SDK.Core
Install-Package HuaweiCloud.SDK.Ocr
2.3 开始使用
2.3.1 导入依赖模块
using HuaweiCloud.SDK.Core;
using HuaweiCloud.SDK.Core.Auth;
using HuaweiCloud.SDK.Ocr.V1;
using HuaweiCloud.SDK.Ocr.V1.Model;
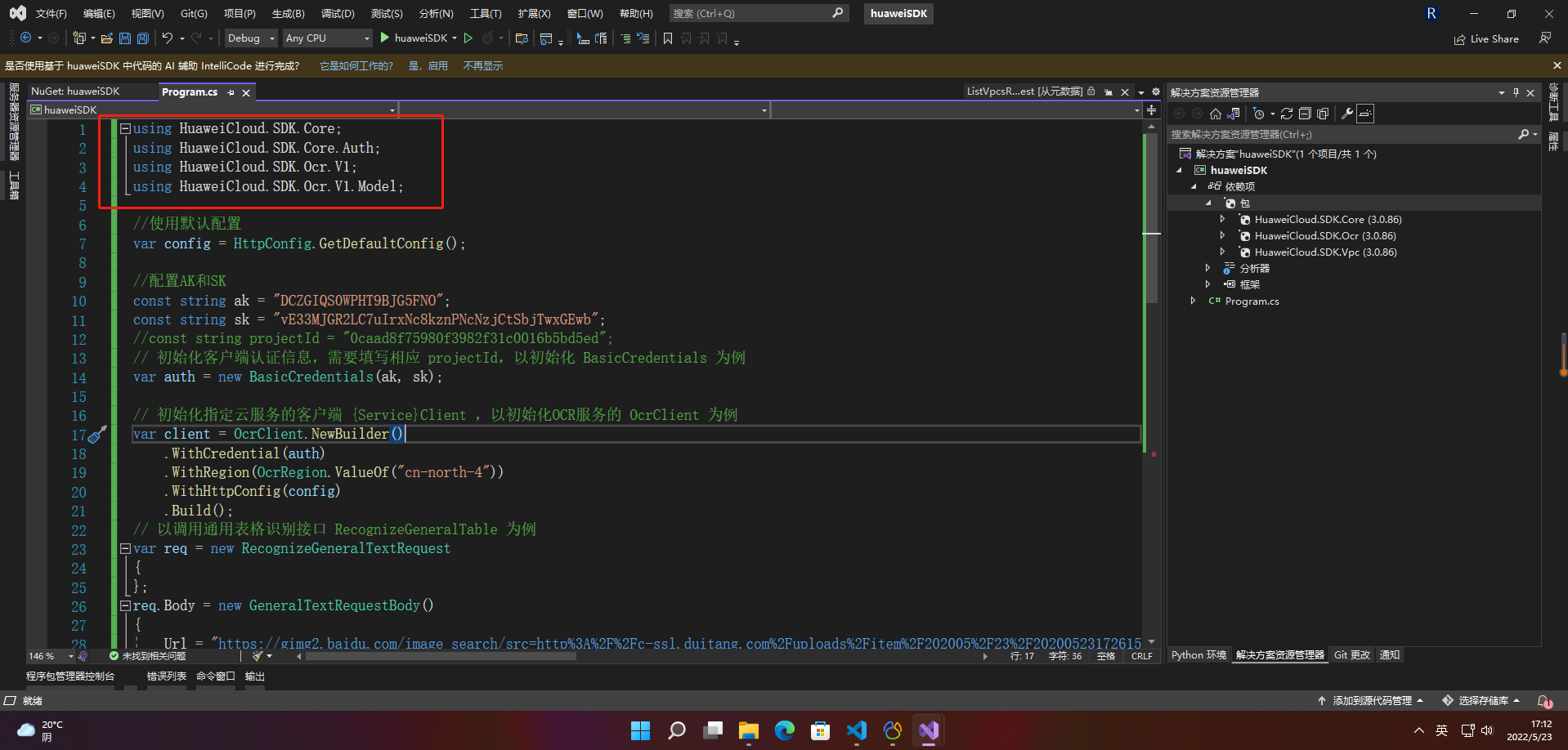
2.3.2 配置客户端连接参数
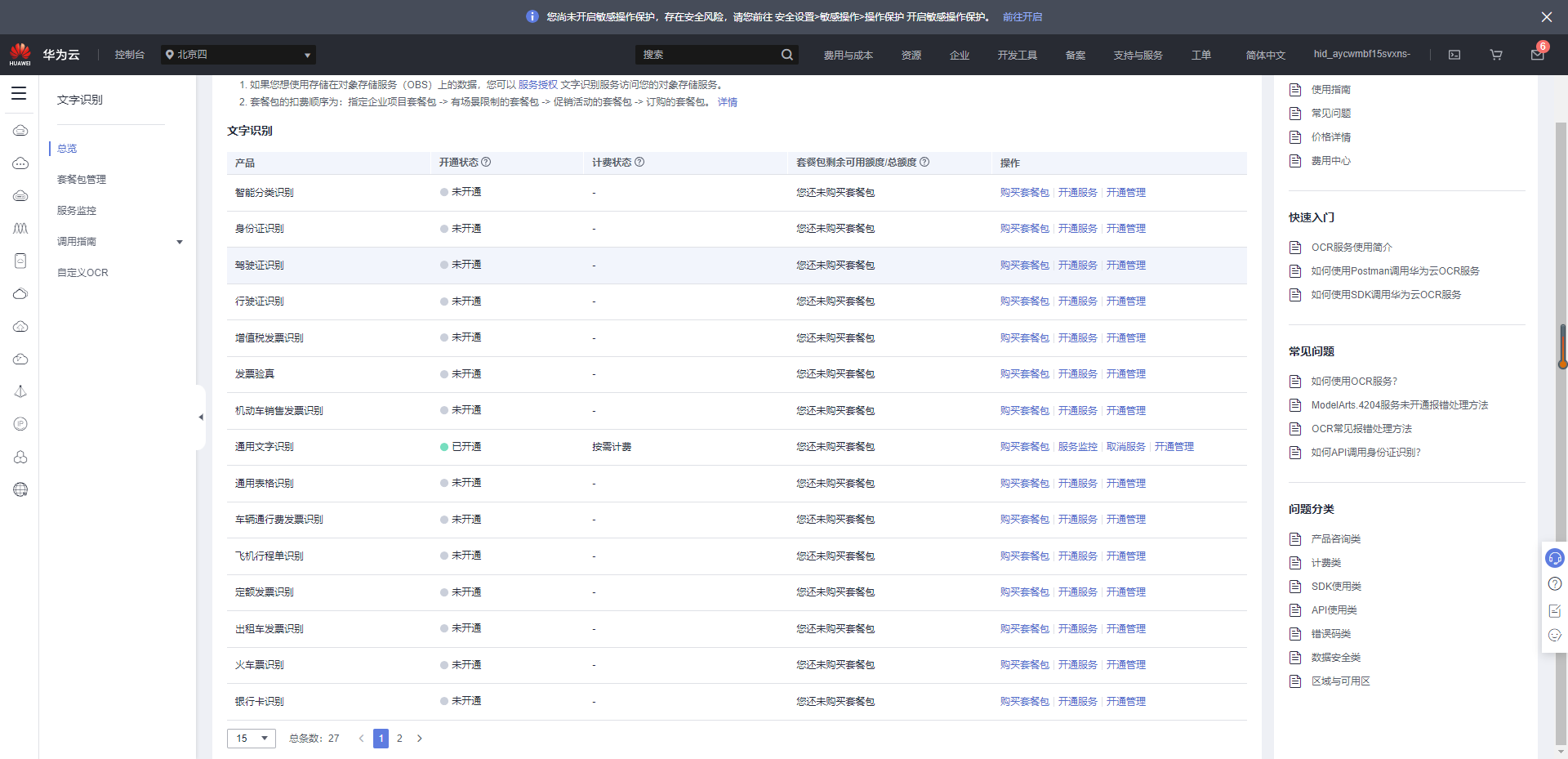
首先开通文字识别服务网址:https://console.huaweicloud.com/ocr/?region=cn-north-4#/ocr/overview
2.3.2.1 默认配置
// 使用默认配置
var config = HttpConfig.GetDefaultConfig();
2.3.2.2 网络代理(可选)
// 根据需要配置网络代理
config.ProxyHost = "proxy.huaweicloud.com";
config.ProxyPort = 8080;
config.ProxyUsername = "test";
config.ProxyPassword = "test";
2.3.2.3 超时配置(可选)
// 默认超时时间为120秒,可根据需要调整
config.Timeout = 120;
2.3.2.41 SSL配置(可选)
// 根据需要配置是否跳过SSL证书验证
config.IgnoreSslVerification = true;
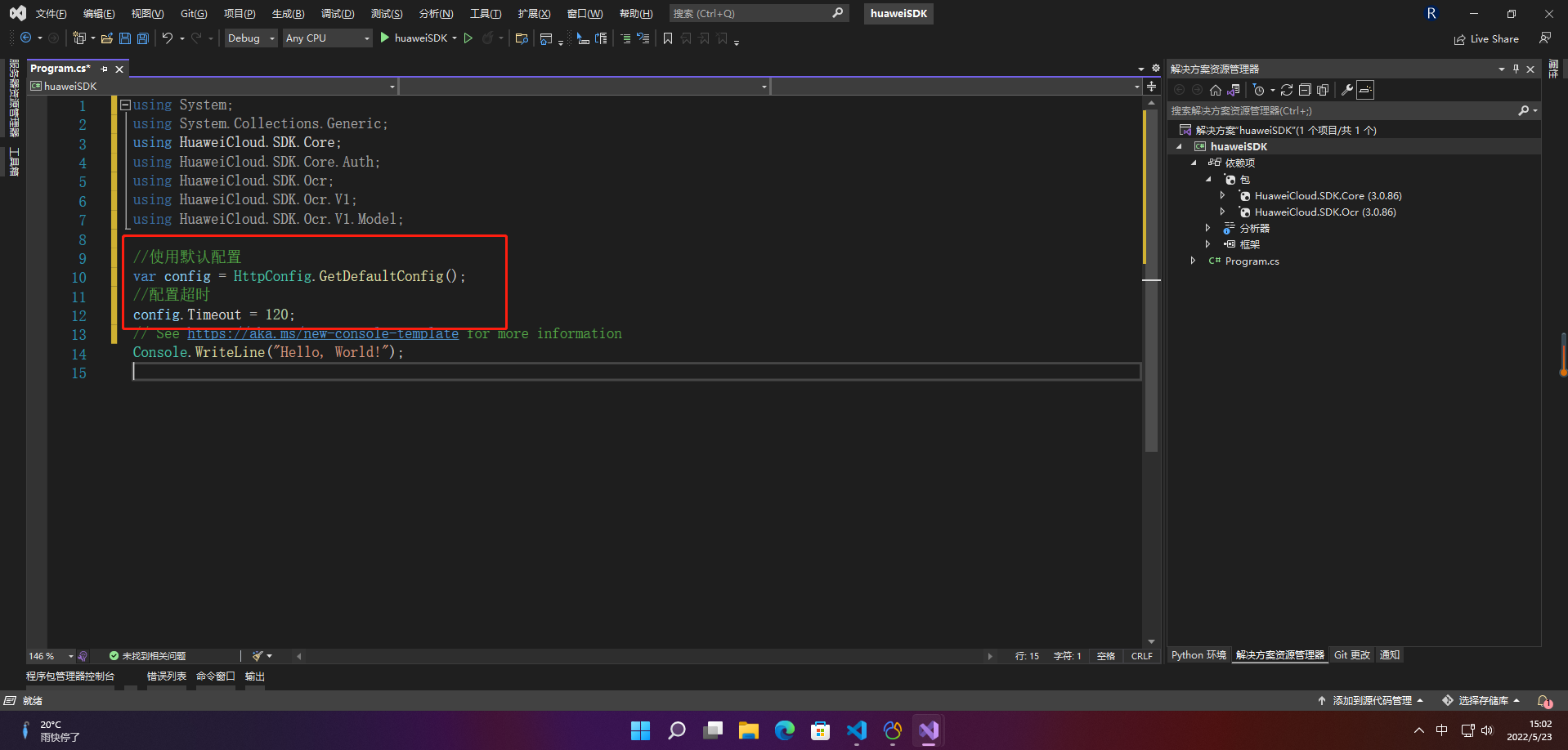
2.3.3 配置客户端连接参数
配置AK、SK信息。华为云通过AK识别用户的身份,通过SK对请求数据进行签名验证,用于确保请求的机密性、完整性和请求者身份的正确性。
//配置AK和SK
const string ak = "";
const string sk = "";
var auth = new BasicCredentials(ak,sk);
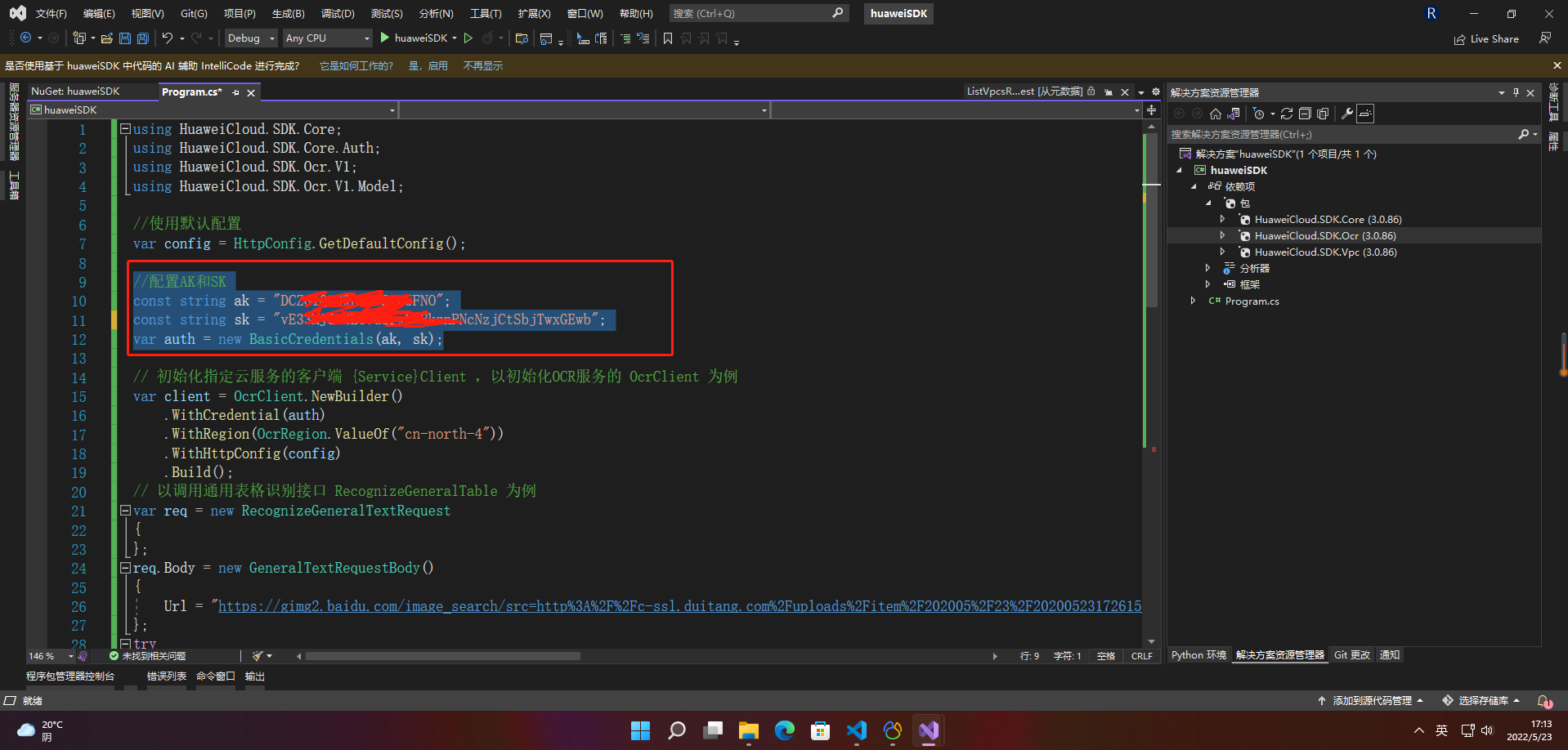
2.3.4 初始化客户端
2.3.4.1 指定云服务region方式(推荐)
// 初始化指定云服务的客户端 {Service}Client ,以初始化OCR服务的 OcrClient 为例
var client = OcrClient.NewBuilder().WithCredential(auth).WithRegion(OcrRegion.ValueOf("cn-north-4")).WithHttpConfig(config).Build();
2.3.4.2 指定云服务endpoint方式
// 指定终端节点,以OCR服务北京四的 endpoint 为例
String endpoint = "https://ocr.cn-north-4.myhuaweicloud.com";
// 初始化客户端认证信息,需要填写相应 projectId,以初始化 BasicCredentials 为例
var auth = new BasicCredentials(ak, sk, projectId);// 初始化指定云服务的客户端 {Service}Client,以初始化OCR服务的 OcrClient 为例
var client = OcrClient.NewBuilder().WithCredential(auth).WithEndPoint(endpoint).WithHttpConfig(config).Build();
endpoint是华为云各服务应用区域和各服务的终端节点.
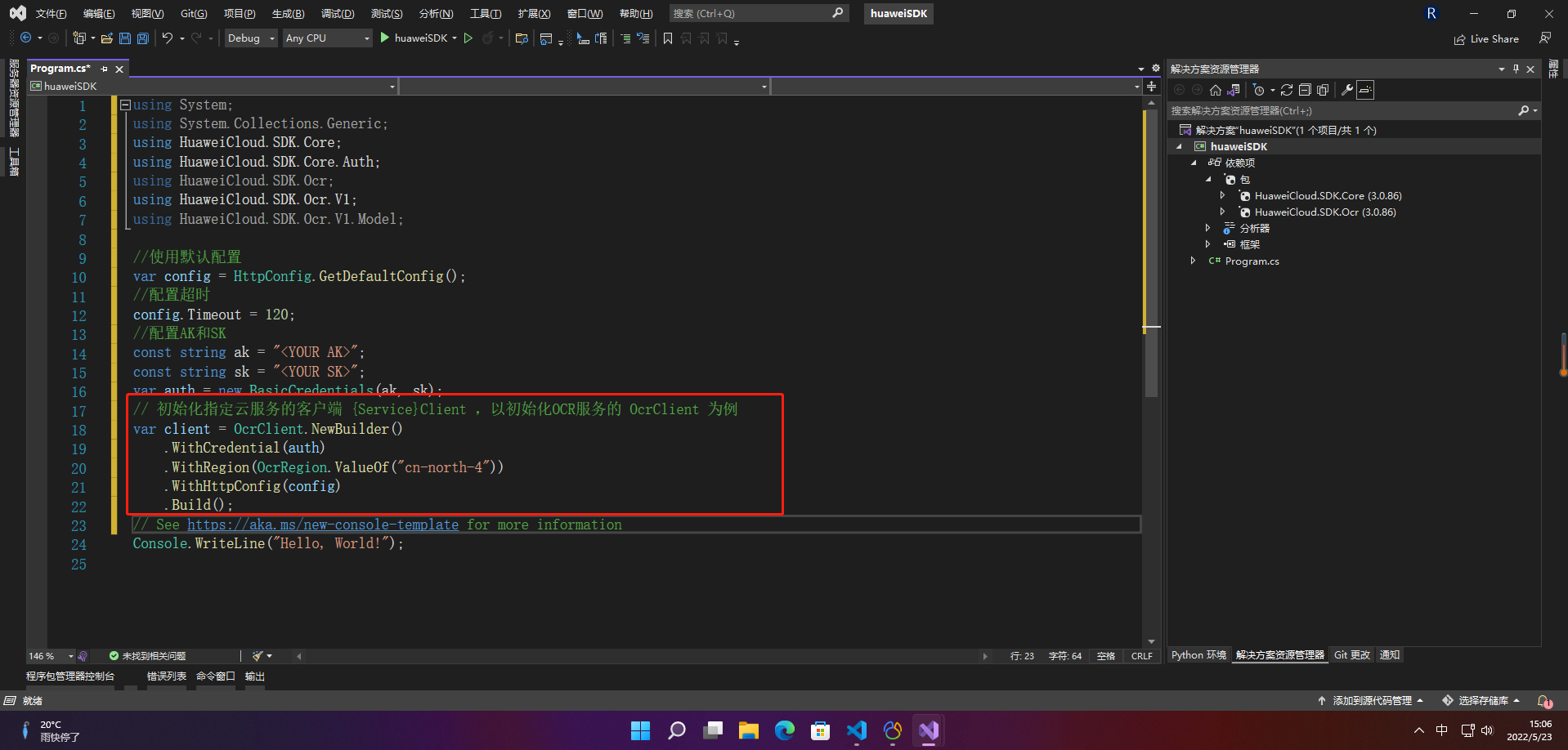
2.3.5 发送请求并查看响应
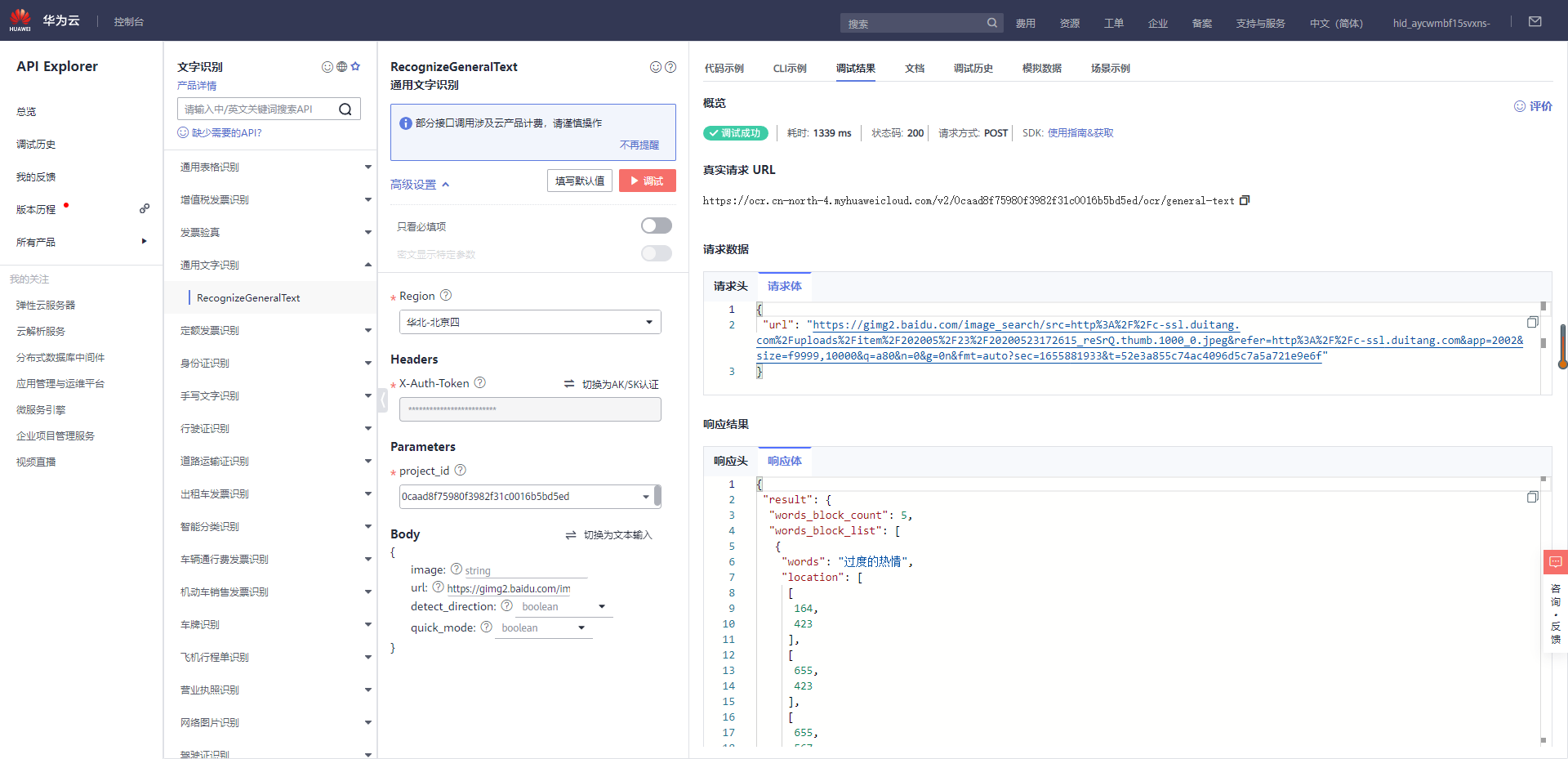
// 以调用通用表格识别接口 RecognizeGeneralTable 为例
var req = new RecognizeGeneralTextRequest
{
};
req.Body = new GeneralTextRequestBody()
{Url = "https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fc-ssl.duitang.com%2Fuploads%2Fitem%2F202005%2F23%2F20200523172615_reSrQ.thumb.1000_0.jpeg&refer=http%3A%2F%2Fc-ssl.duitang.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1655881933&t=52e3a855c74ac4096d5c7a5a721e9e6f"
};
try
{var resp = client.RecognizeGeneralText(req);var respStatusCode = resp.HttpStatusCode;Console.WriteLine(respStatusCode);
}
catch (Exception e)
{Console.WriteLine(e);
}
2.3.6 异常处理
| 一级分类 | 一级分类说明 | 二级分类 | 二级分类说明 |
|---|---|---|---|
| ConnectionException | 连接类异常 | HostUnreachableException | 网络不可达、被拒绝。 |
| ConnectionException | 连接类异常 | SslHandShakeException | SSL认证异常。 |
| RequestTimeoutException | 响应超时异常 | CallTimeoutException | 单次请求,服务器处理超时未返回。 |
| RequestTimeoutException | 响应超时异常 | RetryOutageException | 在重试策略消耗完成后,仍无有效的响应。 |
| ServiceResponseException | 服务器响应异常 | ServerResponseException | 服务端内部错误,Http响应码:[500,]。 |
| ServiceResponseException | 服务器响应异常 | ClientRequestException | 请求参数不合法,Http响应码:[400,500) |
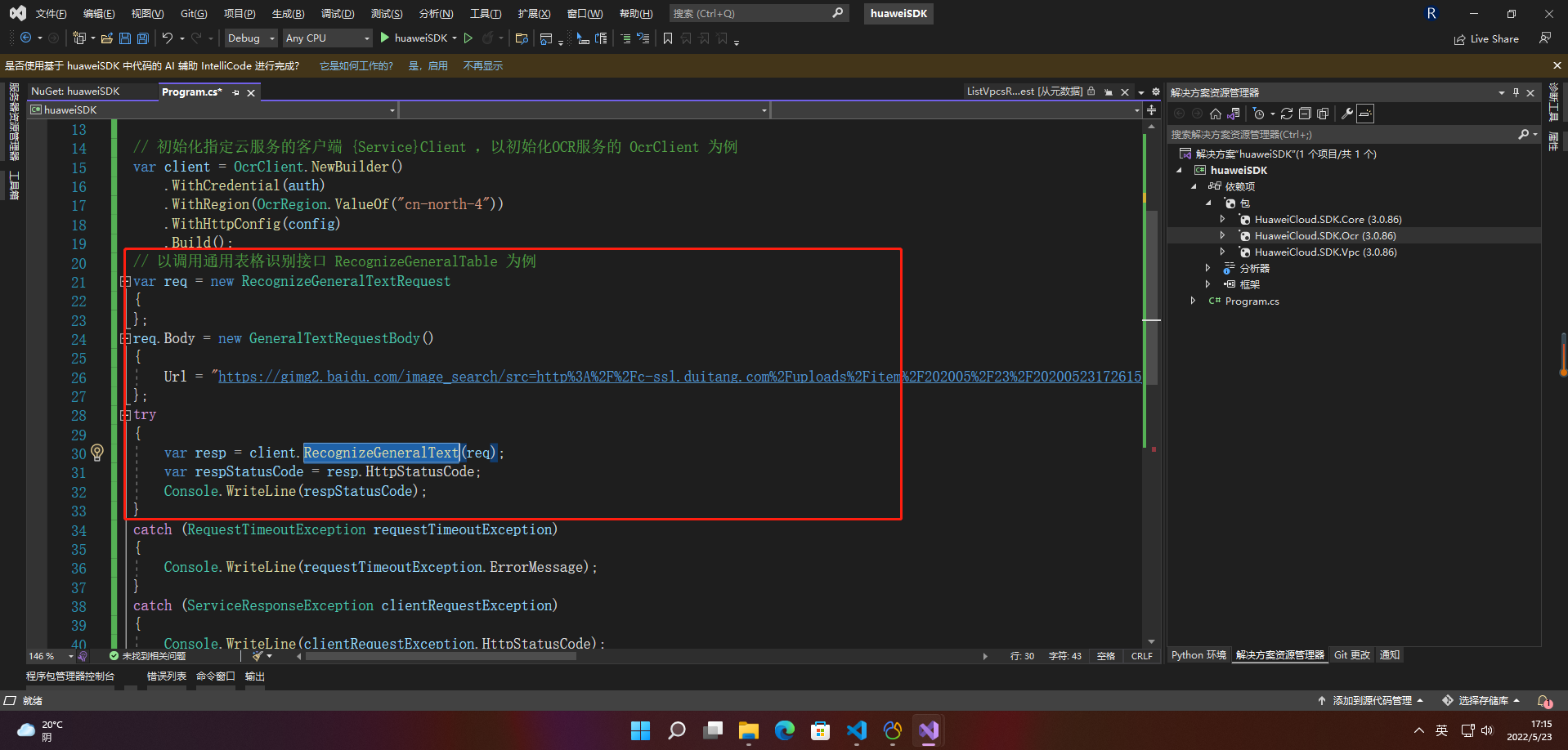
try
{var resp = client.RecognizeGeneralText(req);var respStatusCode = resp.HttpStatusCode;Console.WriteLine(respStatusCode);
}
catch (RequestTimeoutException requestTimeoutException)
{Console.WriteLine(requestTimeoutException.ErrorMessage);
}
catch (ServiceResponseException clientRequestException)
{Console.WriteLine(clientRequestException.HttpStatusCode);Console.WriteLine(clientRequestException.ErrorCode);Console.WriteLine(clientRequestException.ErrorMsg);
}
catch (ConnectionException connectionException)
{Console.WriteLine(connectionException.ErrorMessage);
}
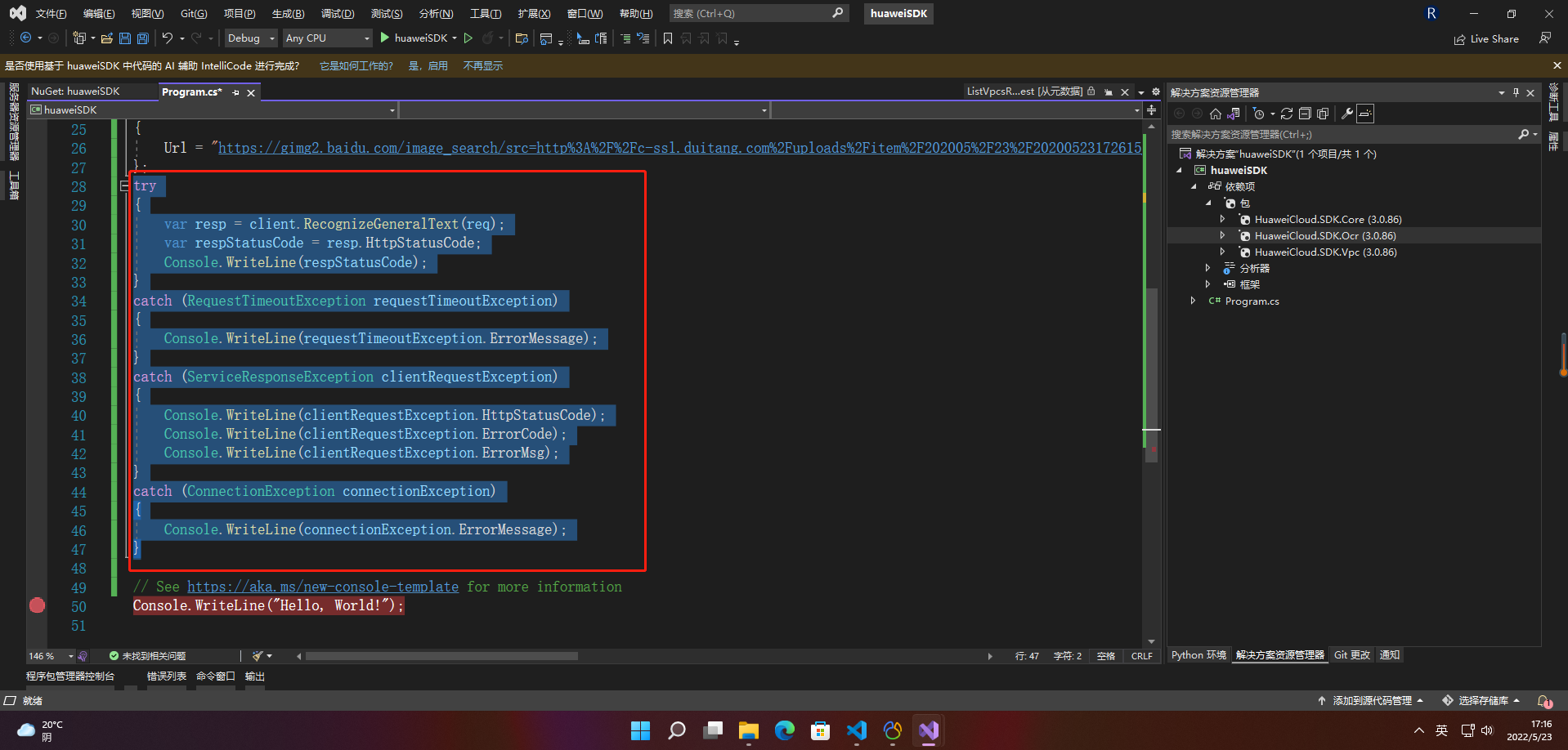
2.3.7 运行程序
2.3.7.1 华为云在线调用
2.3.7.1 代码调用
github源码仓库地址:https://sdkcenter.developer.huaweicloud.com/?product=OCR
using HuaweiCloud.SDK.Core;
using HuaweiCloud.SDK.Core.Auth;
using HuaweiCloud.SDK.Ocr.V1;
using HuaweiCloud.SDK.Ocr.V1.Model;//使用默认配置
var config = HttpConfig.GetDefaultConfig();//配置AK和SK
const string ak = "DCZGIQS0WPHT9BJG5FNO";
const string sk = "vE33MJGR2LC7uIrxNc8kznPNcNzjCtSbjTwxGEwb";
//const string projectId = "0caad8f75980f3982f31c0016b5bd5ed";
// 初始化客户端认证信息,需要填写相应 projectId,以初始化 BasicCredentials 为例
var auth = new BasicCredentials(ak, sk);// 初始化指定云服务的客户端 {Service}Client ,以初始化OCR服务的 OcrClient 为例
var client = OcrClient.NewBuilder().WithCredential(auth).WithRegion(OcrRegion.ValueOf("cn-north-4")).WithHttpConfig(config).Build();
// 以调用通用表格识别接口 RecognizeGeneralTable 为例
var req = new RecognizeGeneralTextRequest
{
};
req.Body = new GeneralTextRequestBody()
{Url = "https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fc-ssl.duitang.com%2Fuploads%2Fitem%2F202005%2F23%2F20200523172615_reSrQ.thumb.1000_0.jpeg&refer=http%3A%2F%2Fc-ssl.duitang.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1655881933&t=52e3a855c74ac4096d5c7a5a721e9e6f"
};
try
{var resp = client.RecognizeGeneralText(req);var respStatusCode = resp.HttpStatusCode;Console.WriteLine(respStatusCode);
}
catch (RequestTimeoutException requestTimeoutException)
{Console.WriteLine(requestTimeoutException.ErrorMessage);
}
catch (ServiceResponseException clientRequestException)
{Console.WriteLine(clientRequestException.HttpStatusCode);Console.WriteLine(clientRequestException.ErrorCode);Console.WriteLine(clientRequestException.ErrorMsg);
}
catch (ConnectionException connectionException)
{Console.WriteLine(connectionException.ErrorMessage);
}// See https://aka.ms/new-console-template for more information
Console.WriteLine("Hello, World!");
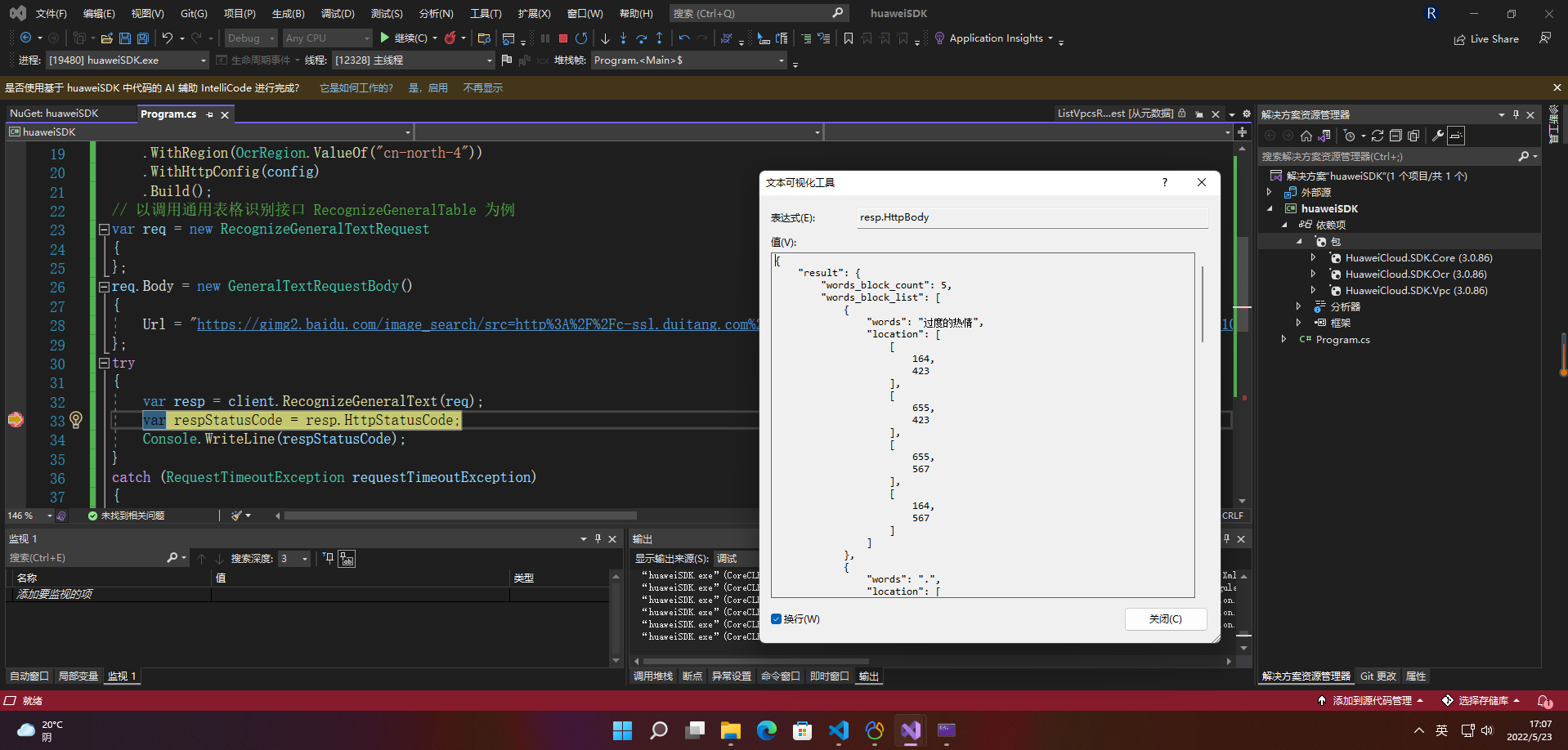
3.华为云OCR SDK的相关参考
华为云OCR SDK参考文档:https://support.huaweicloud.com/sdkreference-ocr/ocr_04_0012.html
华为云OCR API参考文档:https://support.huaweicloud.com/api-ocr/ocr_03_0031.html
2.华为云文字识别OCR服务操作指南
2.1 选择华为云文字识别OCR服务的理由
华为云文字识别OCR服务主要优势有以下几点:
- 优势1:识别精度高采用先进的深度学习算法,针对各种业务场景优化,文字识别精度高
- 优势2:稳定服务成功应用于各类场景,基于华为等企业客户的长期实践,经受过复杂场景考验
- 优势3:支持复杂场景证件支持复杂背景、扭曲、倾斜;表单支持盖章、错行等场景
- 优势4:简单易用提供符合RESTful规范的API访问接口,兼容性强,使用方便
2.2 华为云文字识别Console介绍
华为云OCR服务官网:https://www.huaweicloud.com/product/ocr.html

2.2.1 进入Console页面
2.2.1.1 申请服务
在“文字识别”控制台的“商用服务”页签中可以申请服务,确保申请服务成功的前提是账号已经通过实名验证。
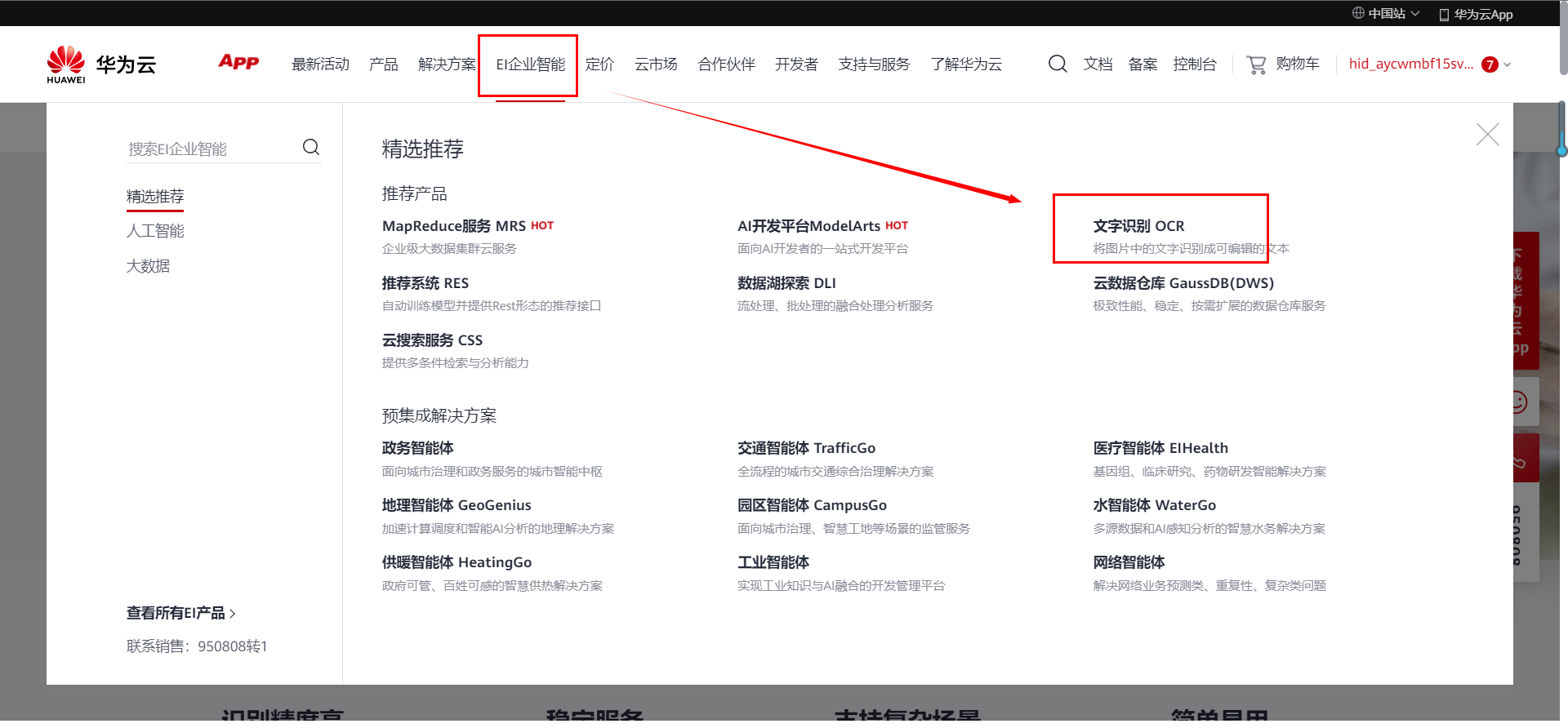
找到文字识别OCR进入页面
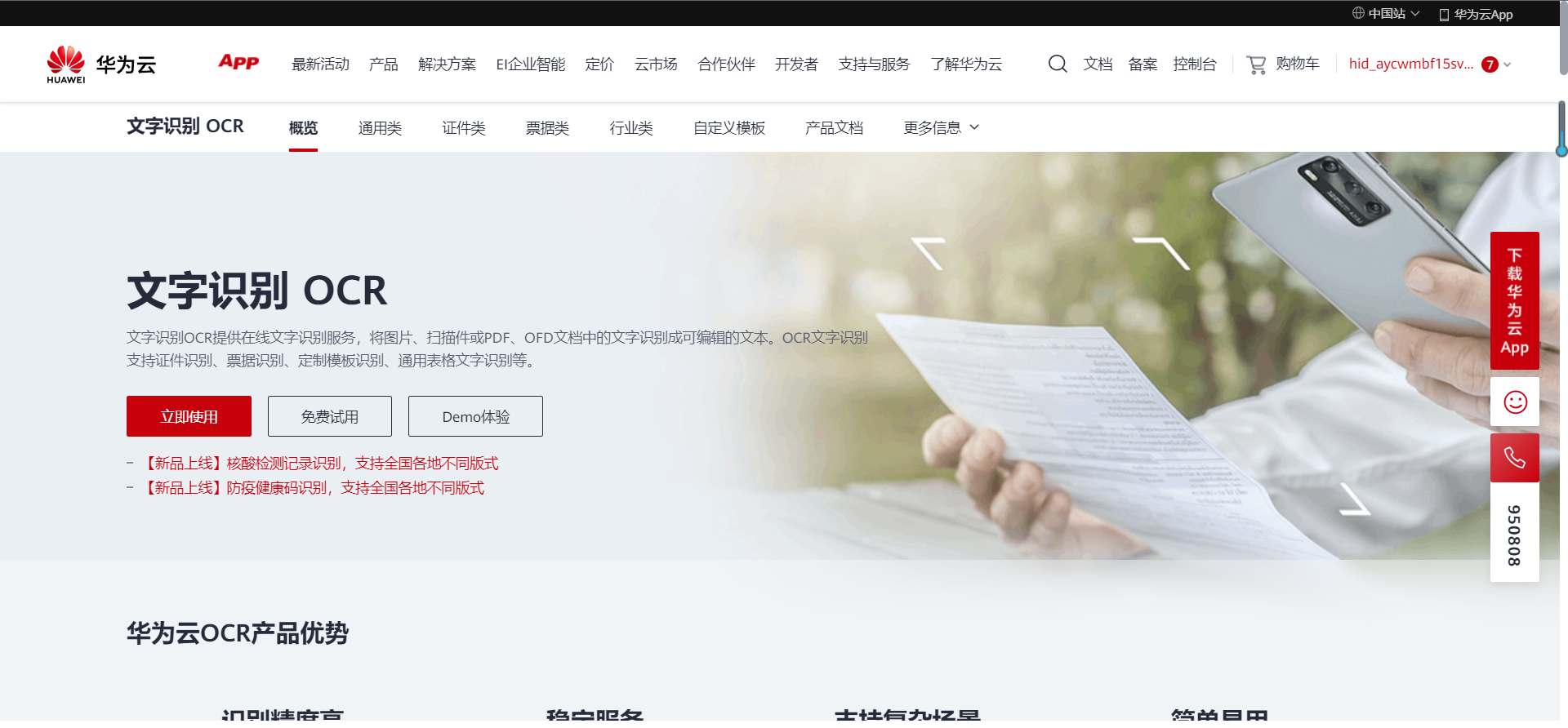
点击立即使用进入控制台
在当前的服务申请页面中可以通过“了解更多”了解该服务支持的场景表,同时建议申请服务前通过“了解计费详情”了解每个服务的计费标准,目前OCR服务计费项是根据每个服务API成功调用的次数进行阶梯计费(调用量越大单次调用的费用越低),调用API的方式有两种:
- Token
- AK/SK
Token及AK/SK获取方式请参考以下链接:http://forum.huaweicloud.com/forum.php?mod=viewthread&tid=5028&page=1&extra=#pid6043
2.2.1.2 服务支持场景及API调用计费标准
| 场景 | 说明 |
|---|---|
| 身份证识别 | 自动识别身份证上的全部信息,支持身份证正反面识别,一次扫描即可识别身份证号码、姓名、地址等全部信息,在暗光、倾斜、过曝光、阴影等异常条件下均可准确识别身份证信息 |
| 驾驶证识别 | 自动识别驾驶证正页上的全部信息,自动提取出姓名、性别、领证日期、准驾车型、有效期限等结构化信息,在暗光、倾斜、过曝光、防伪标志干扰、阴影等异常条件下均可准确识别驾驶证信息 |
| 行驶证识别 | 自动识别行驶证正页上的全部信息,自动提取出号牌号码、车辆类型、所有人、使用性质、品牌型号、车辆识别代号、发动机号码、注册日期等结构化信息,在暗光、倾斜、过曝光、防伪标志干扰、阴影等异常条件下均可准确识别行驶证信 |
| 增值税发票识别 | 通过对增值税发票图片预处理、表格提取、文字提取、文字识别、结构化信息输出等一系列技术化手段,快速将增值税发票上的文字信息识别出来,用于后续的进一步处理,节省大量的人工录入成本 |
| 英文海关单据识别 | 可识别出英文海关单据图片上的文字内容和数字,智能提取为可编辑的文本。英文海关单据识别采用了自动定位分割算法、分布式计算框架、集成深度学习进行纠错,经过大规模图像文字训练,达到高精度的识别要 |
| 通用表格识别 | 提取表格内的文字和所在行列位置信息,适应不同格式的表格。同时也识别表格外部的文字区域。用于各种单据和报表的电子化,恢复结构化信息 |
| 通用文字识别 | 提取图片内的文字及其对应位置信息,并能够根据文字在图片中的位置进行结构化整理工作 |
| 手写字母数字识别 | 提取表格内的手写字母、数字和所在行列位置信息,适应不同格式的表格。同时也支持表格外部文字区域的手写字母数字识别 |
| 机动车销售发票识别 | 自动识别机动车销售发票图片内的文本内容,并返回结构化字段信息,用于后续的进一步处理,节省大量的人工录入成本 |
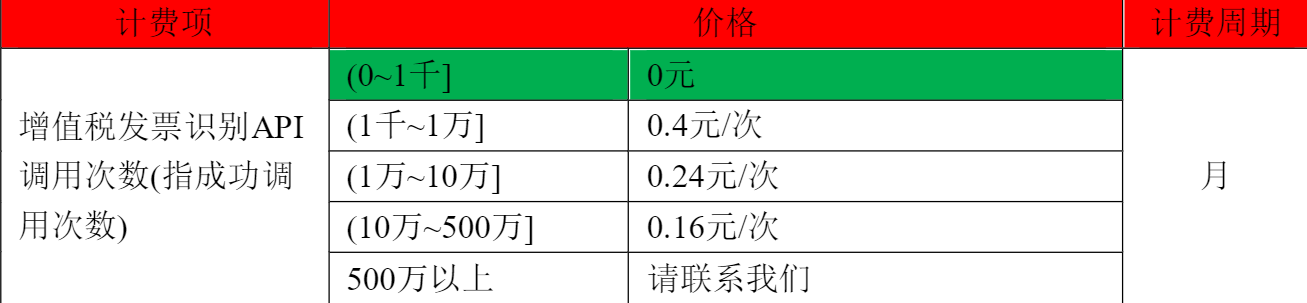
更多价格详情:https://support.huaweicloud.com/pro_price/#ocr_detail
总结
文字识别应用的场景非常的广,基本上所有用到文字的领域都需要文字识别。比如说是物流与制造业,金融保险,医疗教育,政务政法,互联网等,我们的产品基本上在这几个方面都有应用。
华为云文字识别服务有如下的特点,首先的识别精度高,证件和票据类的识别率在很多场景都能达到99%以上,数据安全和端云协同前面已经提过了。我们还有高适应性,比如说支持错行、盖章、倾斜、文字叠加、反光、任意角度等复杂场景,同时多种易用的SDK。很多时候你的产品再好,不好用,消费者也是不认可的。最后就是高可用,基本上可以支持每月十亿级或者更高的调用量。
本文主要介绍了华为云文字识别服务的相关概念和使用实操,想使用华为云OCR服务的小伙伴可以执行实操流程步骤来实现自己业务场景。
本文整理自华为云社区【内容共创】活动第16期。
查看活动详情:https://bbs.huaweicloud.com/blogs/352652
相关任务详情:任务24.华为云文字识别服务