强烈推荐一个大神的人工智能的教程:http://www.captainai.net/zhanghan
前言
- 近几个月ChatGPT爆火出圈,一路狂飙;它功能十分强大,不仅能回答各种各样的问题,还可以信写作,给程序找bug…
- 我经过一段时间的深度使用后,十分汗颜,"智障对话"体验相比,它是如此的丝滑流畅
- 作为一名技术人,情不自禁的对它的原理产生了十分浓厚的兴趣;于是花费了一些时间去研究其实现技术原理,在此与大家分享
ChatGPT基本信息&原理
ChatGPT基本信息
-
研发公司:OpenAI
-
创立年份:2015年
-
创立人:马斯克、Sam Altman及其他投资者
-
目标:造福全人类的AI技术
-
GPT(Generative Pre-trained Transformer):生成式预训练语言模型
-
GPT作用:问答,生成文章等
-
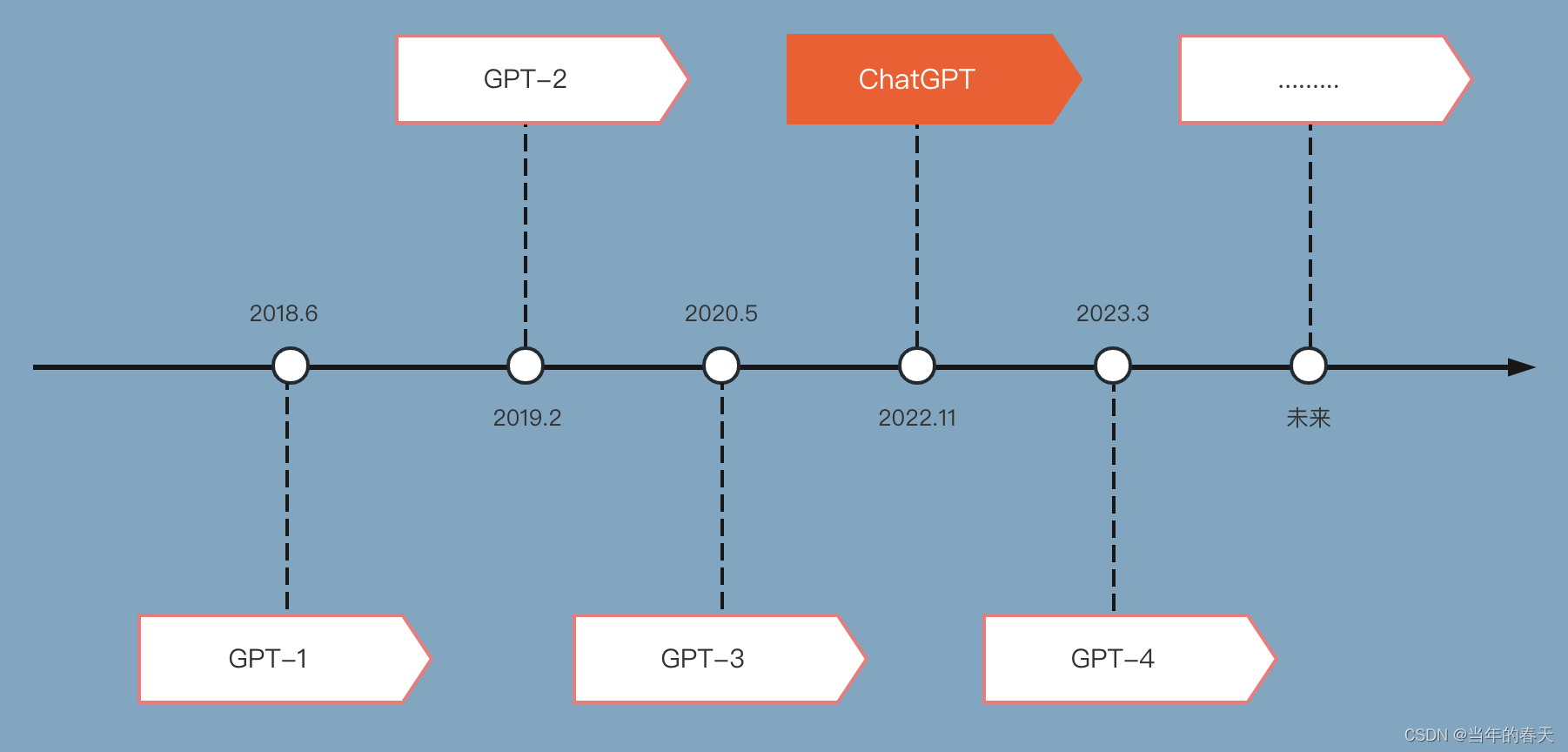
模型发展史
-
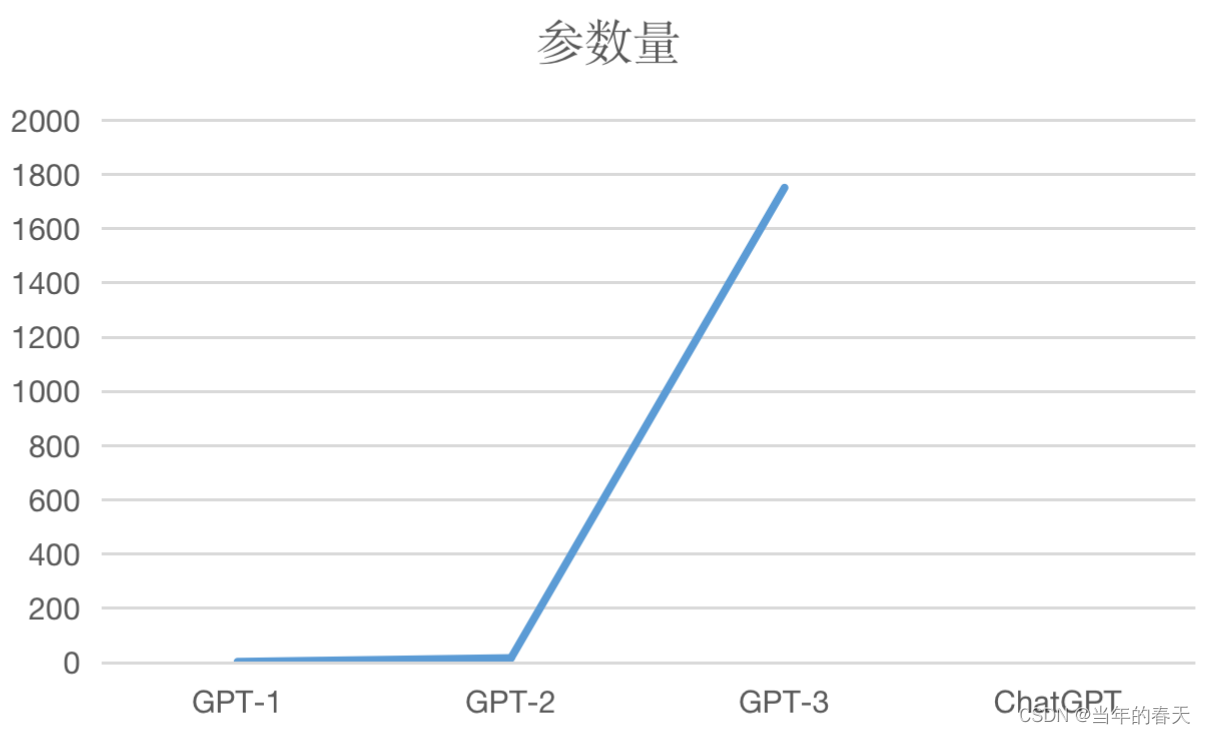
参数量(单位:亿)
-
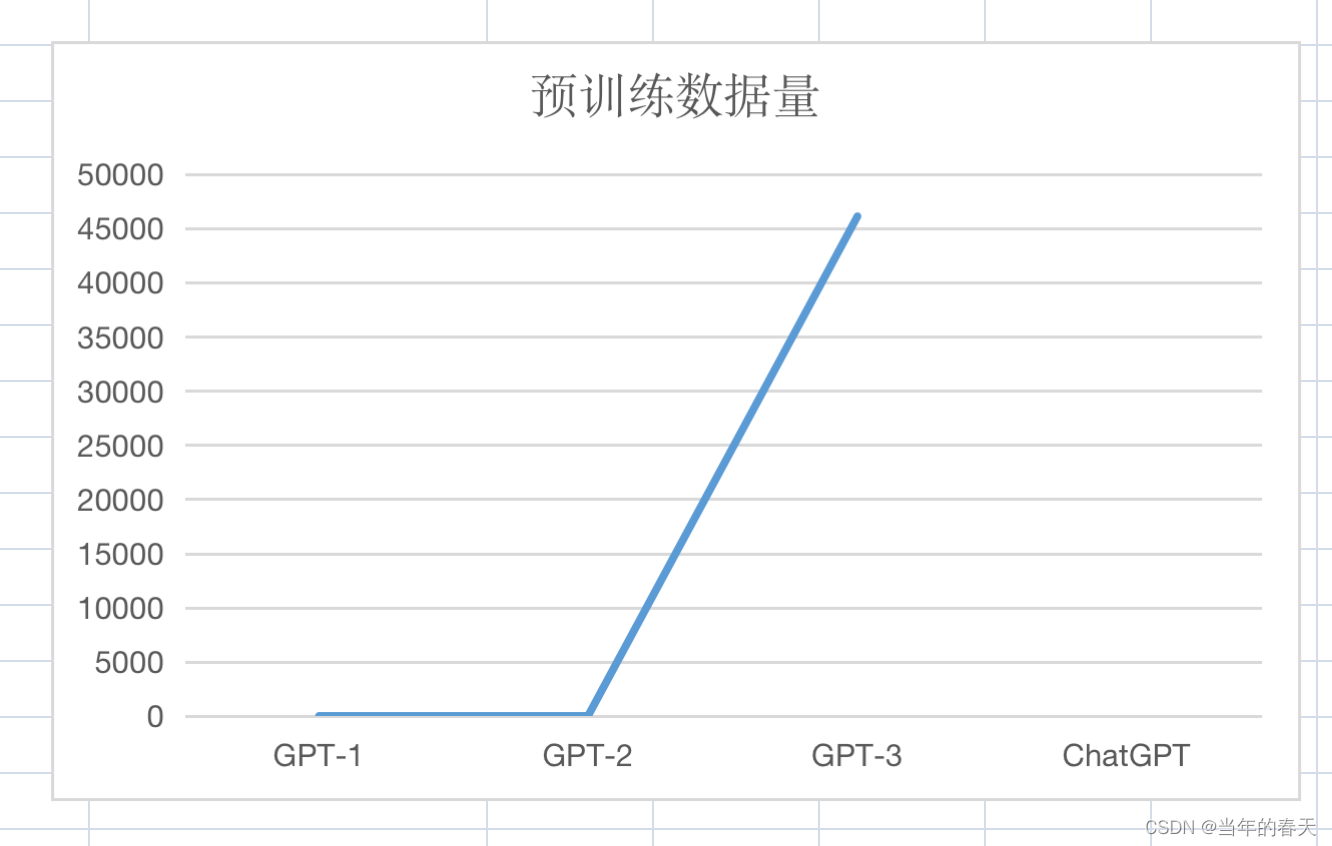
预训练数据量(单位:GB)
原理解析
训练过程总览
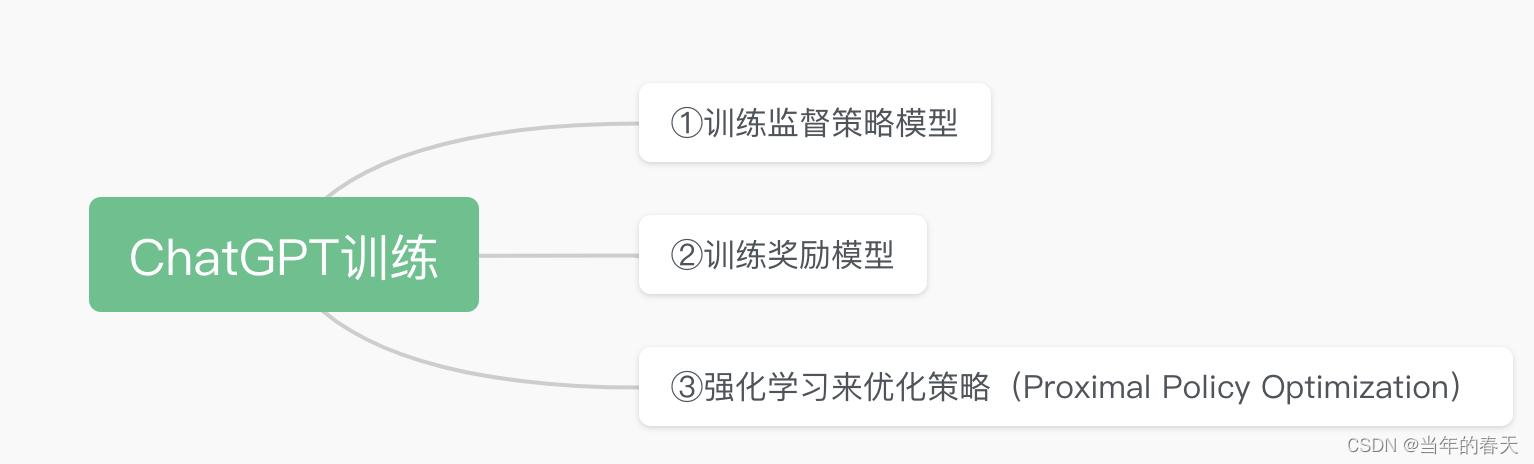
训练过程详解
训练监督策略模型
作为技术人员都知道,一直有两个难题困扰我们:
- 让机器理解人类通用指令下的意图
- 生成内容是否是高质量
ChatGPT如何解难题?
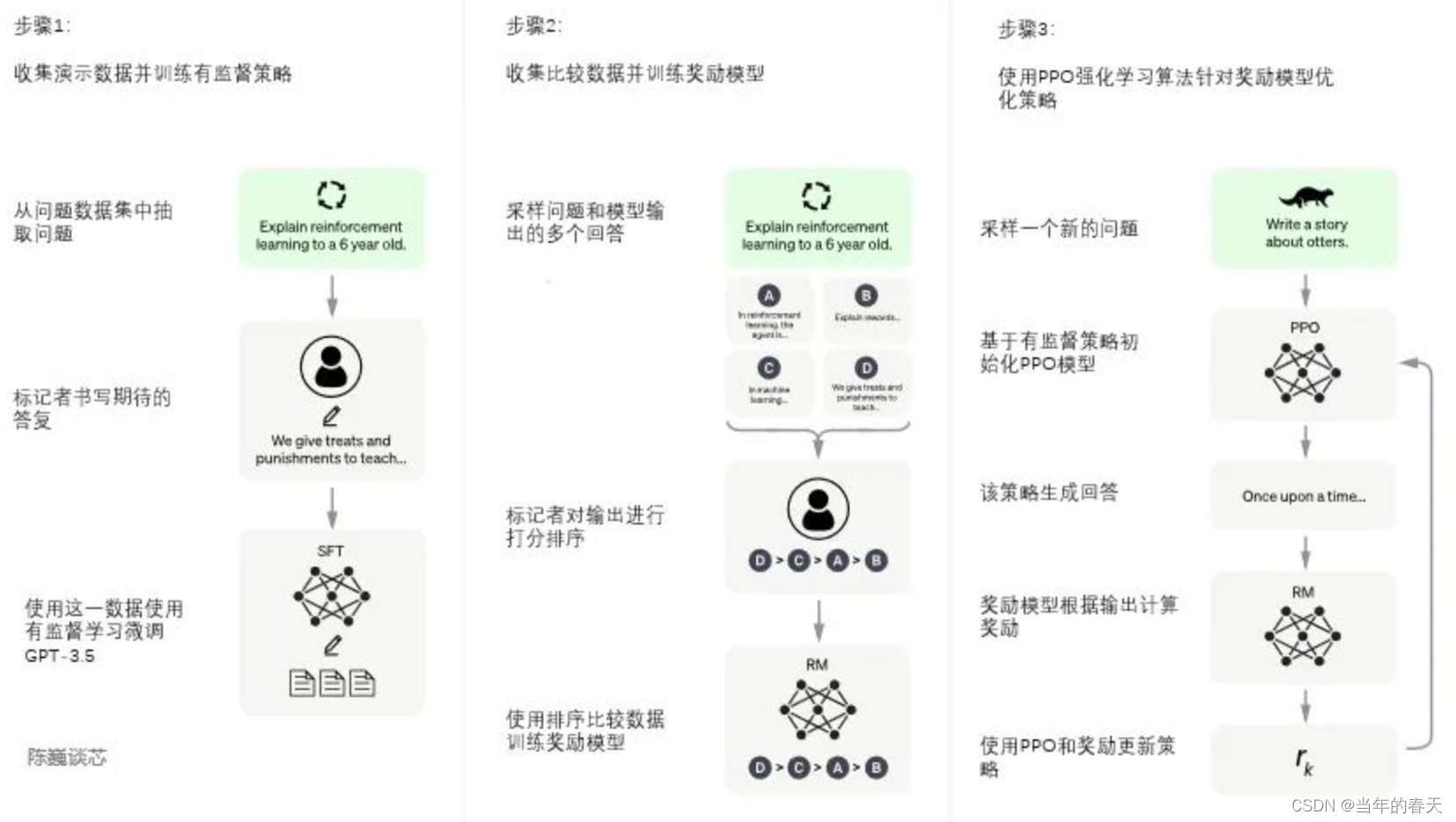
- 数据集中随机抽取问题,由人类标注人员给出高质量答案,得到多轮对话的数据,然后用这些人工标注好的数据来微调 GPT模型;由于数据来源于网上海量数据,通过监督学习可以让模型生成出更加符合我们预期的答案
训练奖励模型(RM)
- 叠加效应:通过人工标注训练数据,来训练回报模型,从而使模型不断地自我迭代完善;
- 具体如下:
- 在上一步微调后,在数据集中随机抽取问题,使用第一阶段生成的模型,对于每个问题,生成多个不同的回答
- 人类标注者对输出结果从好到差排序
- 用这个排序结果数据来训练奖励模型
- RM模型接受一个输入,给出评价回答质量的分数,从而使ChatGPT从命令驱动转向意图驱动,引导ChatGPT输出符合人类预期的内容。
强化学习来优化策略(PPO)
- 使用PPO强化模型优化奖励模型
- 具体步骤如下:
- 利用上段训练好的奖励模型,靠奖励打分来更新预训练模型参数
- 在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的RM模型给出质量分数
- 将回报分数依次传递,从而产生策略梯度,通过强化学习的方式来更新PPO模型参数
- 不断迭代,从而训练出更高质量的模型
更多原理内容解析
背景
ChatGPT还有很多精湛的原理,值得我们每个人去认真的学习,从而不断的丰富自己知识体系;该领域还有几个关键点因文章篇幅有限等原因未能将其他的关键点解析在此强烈为大家推荐一个学习直播
思考题
- 国内生成式人工智能还有哪些前沿研究成果?
- 跨模态、异构数据爆发式增长,如何高效处理?
- 大型语言模型未来的优化趋势是怎样的?
- 牵动多个应用领域的底层视觉技术有哪些优化空间?
更多详细内容
希望热爱学习的读者朋友带着以上思考题,"CSIG企业行"的精彩直播去寻找答案
活动相关内容:
-
主题:“图文智能处理与多场景应用技术展望”
-
目标:聚焦图像文档处理中的结构建模、底层视觉技术、跨媒体数据协同应用、生成式人工智能及对话式大型语言模型等热门话题,
-
嘉宾:特邀来自上海交大、复旦、厦门大学、中科大的顶尖学府的学者与合合信息技术团队一道,以直播的形式分享文档处理实践经验及NLP发展趋势,探讨ChatGPT在未来的落地潜能
-
活动组织方:该活动由中国图象图形协会 (CSIG) 主办 ,合合信息、CSIG文档图像分析与识别专业委员 会联合承办
-
时间:3⽉18日 14:00
-
直播预约入口
-
活动内容

活动干货多多,全程亮点,欢迎大家关注!
总结
- 当前阶段ChatGPT已经大大的降低了很多行业的门槛,可以辅助专业人士大大提高效率,它很有可能成为改变世界的一项技术
- 我们每个人都应该学习ChatGPT,它的解决问题方式完全符合大数据思维,生活在当今的信息社会,有了大数据思维会让我们如虎添翼
- GPT-4在3月15日发布,多模态一个模型,支持了强大的识图能力,回答准确性提升明显,从发布的时间来看,迭代速度越来越快,我们要积极拥抱它,将其作为我们生活和工作的重要伙伴,让它为我们生活带来更多的便利和快乐,同时我们也要充分了解人工智能这项技术,掌握它的优点和不足,不断提高自己的技能和素质,让我们能够更好的应对未来的挑战



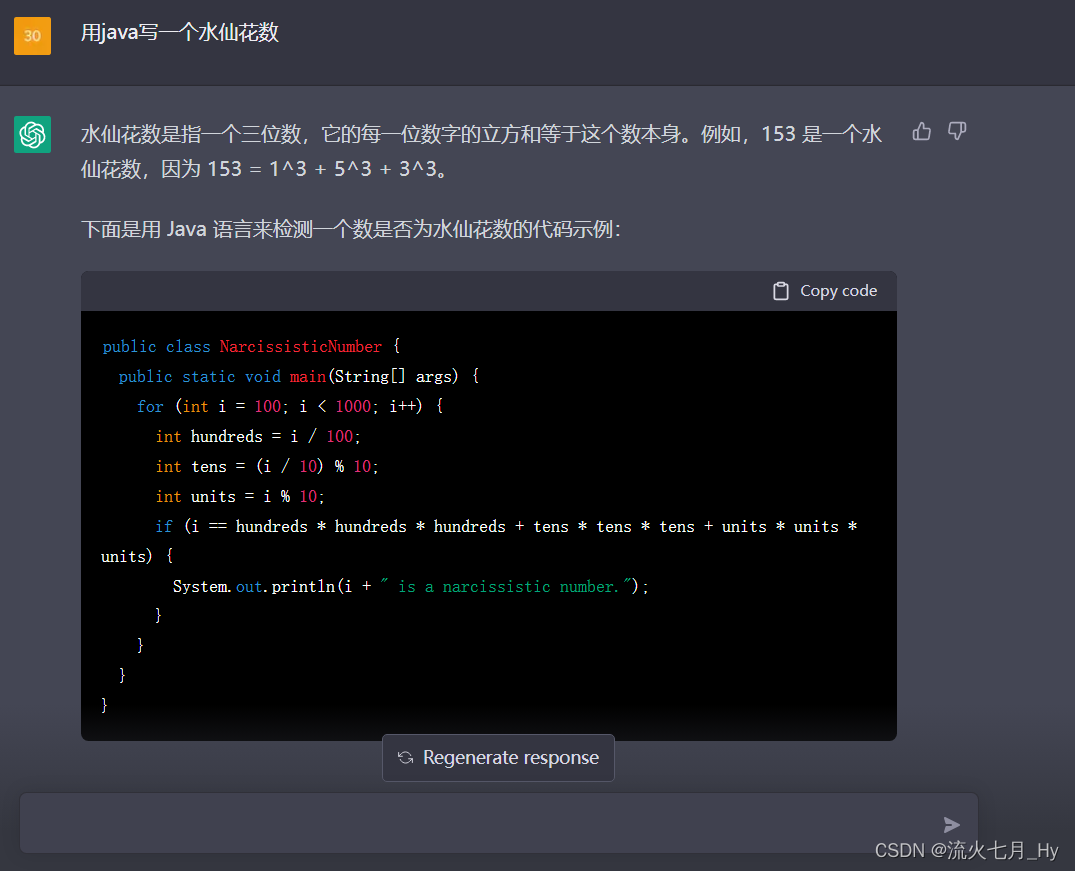

![[人工智能-综述-11]:ChatGPT, 通用人工智能还是要来了](https://img-blog.csdnimg.cn/img_convert/cb4a3c4dbca3dcba9a8bdd8da1396d79.png)